Hello,大家好,我是南枫,今天带来什么项目呢?就是------爬B站视频。
刷过B站的都知道,B站并没有下载功能,连官网都没有下载功能的话,那我们还能正常爬取吗?当然~
首先我们要知道B站视频是分为视频和音频两部分,所以我们抓下来还不行,还需要把视频和音频给拼接起来。
工作量乍一看感觉很大,其实很简单,那么现在,跟着我的步伐一起来瞅瞅吧!
进行抓取之前,想问大家一个问题,请看图:

大家觉得整个页面,这两个部分谁占用的内存最大?最多?
毋庸置疑的就是第一个部分(视频),请大家记住这一点,接下来,我们一起打开检查来进行常规操作。

总共有429个请求,并且还在不断增加,那我们如何从这么多文件里找到视频的文件呢?
我们上面说了,整个页面哪个部分占的内容最多?那就是视频!
那我们直接来进行排序,把所有文件按照从大到小进行排序(你想从小到大也没人拦你),怎么排序呢?如图:

点大小就行,so ez。那第一个就是视频文件吗?其实并不是,而是这三个文件:
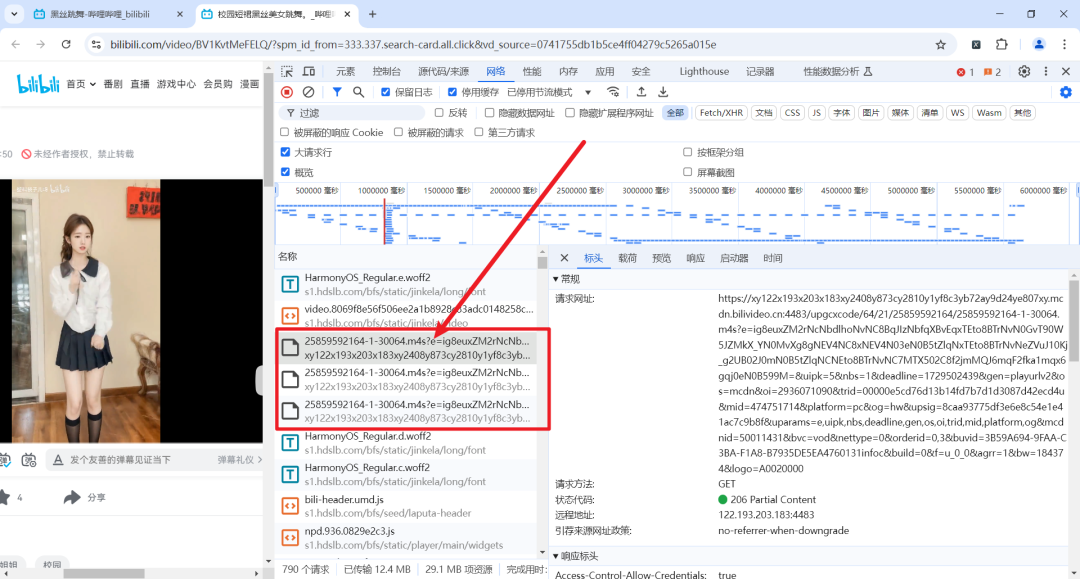
这三个文件都是视频文件,不相信我的你接着看好了~,开始写代码:
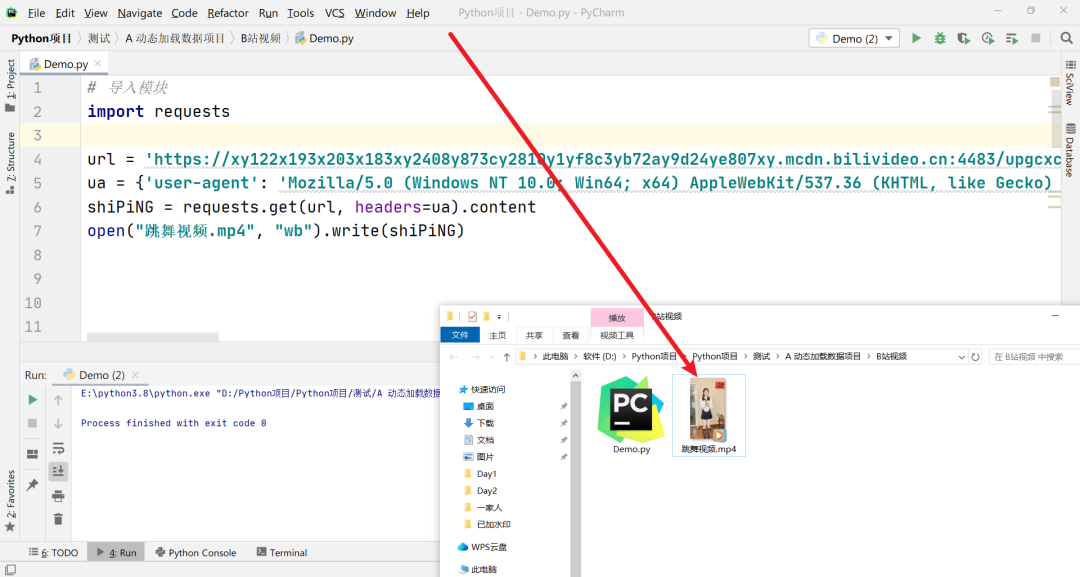
成功爬取下来,接下来看看能不能进行播放:
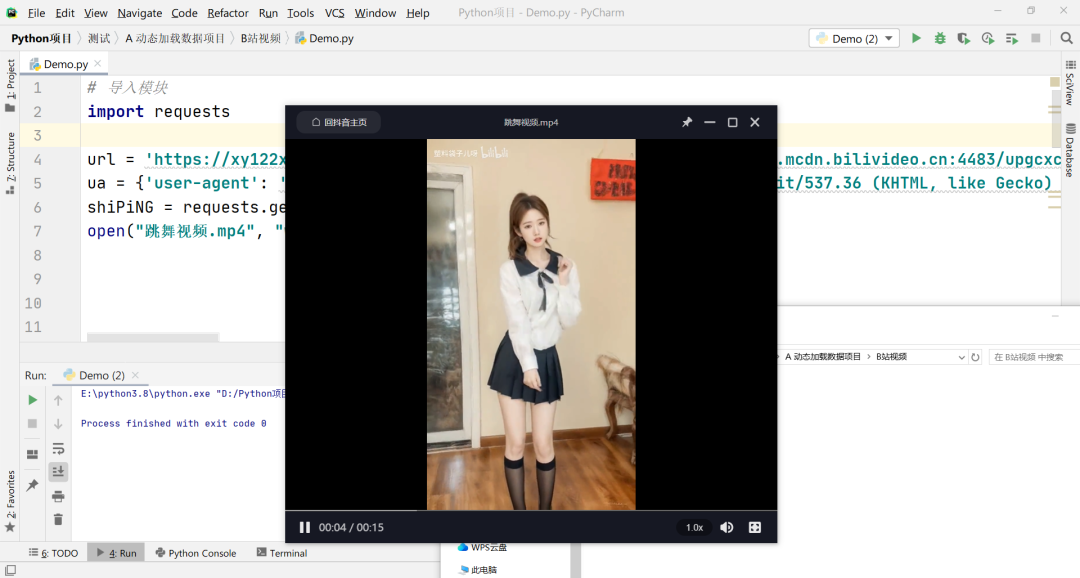
播放正常,但,有个问题,只有视频,并没有声音,那我们是不是还得抓音频呢?对的没错,那么音频在哪呢?回到网站,往下滑:

可以看到,这里又有三个文件,他们仨和视频文件不一样,不一样的点在哪?
这是视频的文件,数字是:30064

我们看音频的文件,数字是:30232

所以视频文件和音频文件的区别,肉眼可见的就是数字而已哈哈哈哈哈,直接上代码:
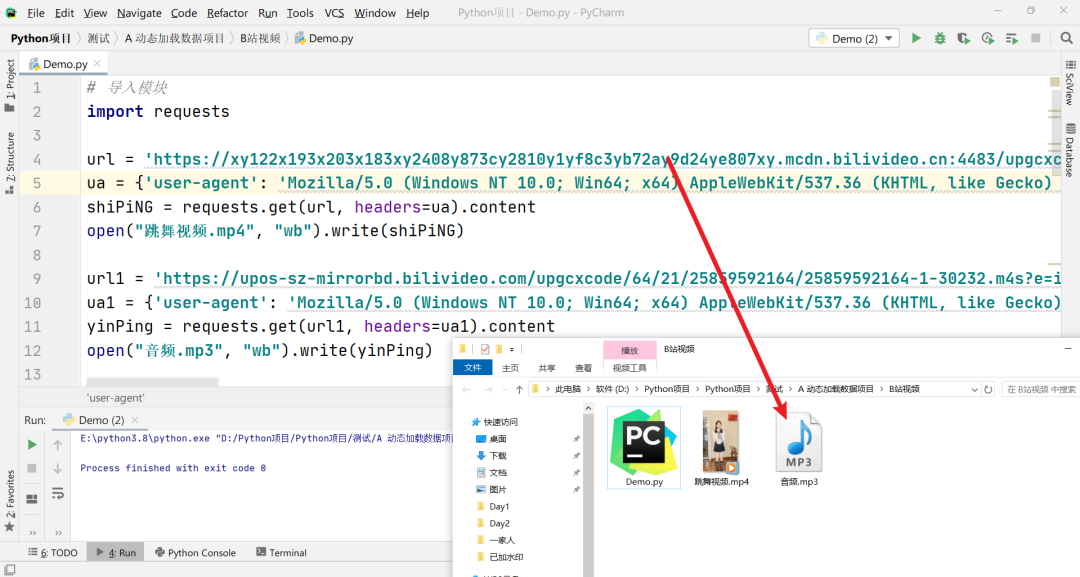
那么这里要注意一点,视频文件的格式是 .mp4;音频文件的格式是 .mp3,大家注意不要搞混咯。
|-------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------|
|  |
|  |
|
播放音频看有没有问题:
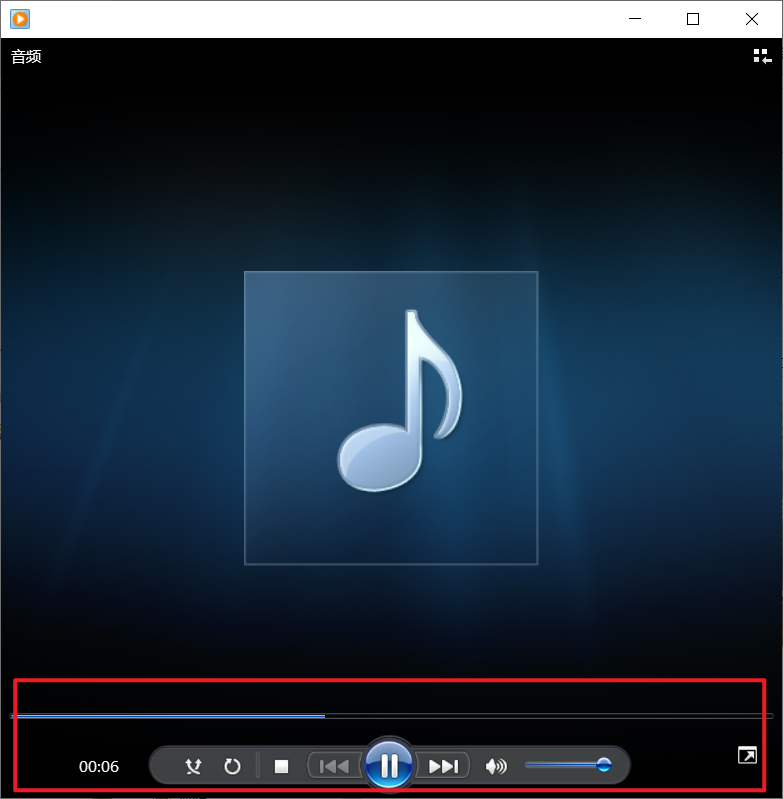
没有问题,那么我们B站的视频和音频就爬取下来了~非常的ez是吧,但有个问题,既然视频和音频都爬下来了,但我们又该怎么把他们俩合并在一起形成正常的视频呢?
带着这个疑问,请看下一篇文章~