1.Linux内核模块介绍
1.1. 内核模块的概念
1.1.1. 内核
内核,是一个操作系统的核心。是基于硬件的第一层软件扩充,提供操作系统的最基本的功能, 是操作系统工作的基础,决定着整个操作系统的性能和稳定性。
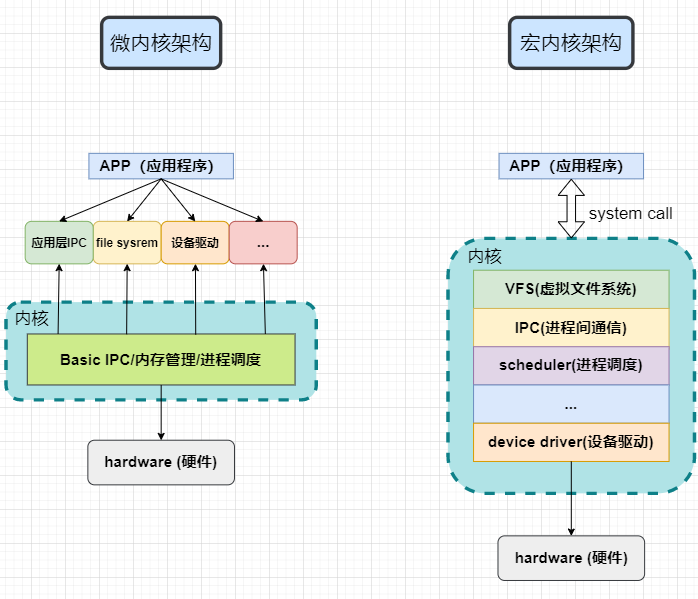
内核按照体系结构分为两类:微内核(Micro Kernel) 和 宏内核(Monolithic Kernel) 。 在微内核架构中,内核只提供操作系统核心 功能,如实现进程管理、存储器管理、进程间通信、I/O设备管理等, 而其它的应用层IPC、文件系统功能、设备驱动模块 则不被包含到内核功能中,属于微内核之外的模块,所以针对这些模块的修改不会影响到微内核的核心功能。 微内核具有动态扩展性强的优点。Windows操作系统、华为的鸿蒙操作系统就属于这类微内核架构。
而宏内核架构是将上述包括微内核以及微内核之外的应用层IPC、文件系统功能、设备驱动模块都编译成一个整体。 其优点是执行效率非常高,但缺点也是十分明显的,一旦我们想要修改、增加内核某个功能时(如增加设备驱动程序)都需要重新编译一遍内核。 Linux操作系统正是采用了宏内核结构。为了解决这一缺点,linux中引入了内核模块这一机制。
1.1.2. 内核模块机制引入
1.1.2.1. 内核模块引入原因
Linux是一个跨平台的操作系统,支持众多的设备,在Linux内核源码中有超过50%的代码都与设备驱动相关。 Linux为宏内核架构,如果开启所有的功能,内核就会变得十分臃肿。 内核模块就是实现了某个功能的一段内核代码,在内核运行过程,可以加载这部分代码到内核中, 从而动态地增加了内核的功能。基于这种特性,我们进行设备驱动开发时,以内核模块的形式编写设备驱动, 只需要编译相关的驱动代码即可,无需对整个内核进行编译。
1.1.2.2. 内核模块引入好处
内核模块的引入不仅提高了系统的灵活性,对于开发人员来说更是提供了极大的方便。 在设备驱动的开发过程中,我们可以随意将正在测试的驱动程序添加到内核中或者从内核中移除, 每次修改内核模块的代码不需要重新启动内核。 在开发板上,我们也不需要将内核模块程序,或者说设备驱动程序的ELF文件存放在开发板中, 免去占用不必要的存储空间。当需要加载内核模块的时候,可以通过挂载NFS服务器, 将存放在其他设备中的内核模块,加载到开发板上。 在某些特定的场合,我们可以按照需要加载/卸载系统的内核模块,从而更好的为当前环境提供服务。
1.1.3. 内核模块的定义和特点
了解了内核模块引入以及带来的诸多好处,我们可以在头脑中建立起对内核模块的初步认识, 下面让我们给出内核模块的具体的定义:内核模块全称 Loadable Kernel Module(LKM), 是一种在内核运行时,加载一组目标代码来实现某个特定功能的机制。
模块是具有独立功能的程序,它可以被单独编译,但不能独立运行, 在运行时它被链接到内核作为内核的一部分在内核空间运行,这与运行在用户空间的进程是不一样的。 模块由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序和其他内核上层功能。 因此内核模块具备如下特点:
-
模块本身不被编译入内核映像,这控制了内核的大小。
-
模块一旦被加载,它就和内核中的其它部分完全一样。
有了内核模块的概念,下面我们一起深入了解内核模块的工作机制吧。
1.2. 内核模块的工作机制
我们编写的内核模块,经过编译,最终形成.ko为后缀的ELF文件。我们可以使用file命令来查看它。

那么这样的文件是如何被内核一步一步拿到并且很好的工作的呢? 为了便于我们更好的理解内核模块的加载/卸载过程,可以先跟我一起学习ELF文件格式,了解ko究竟是怎么一回事儿。 再一同去看看内核源码,探究内核模块加载/卸载,以及符号导出的经过。
1.2.1. 内核模块详细加载/卸载过程
1.2.1.1. ko文件的文件格式
ko文件在数据组织形式上是ELF(Excutable And Linking Format)格式,是一种普通的可重定位目标文件。 这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类。
ELF 文件格式的可能布局如下图。
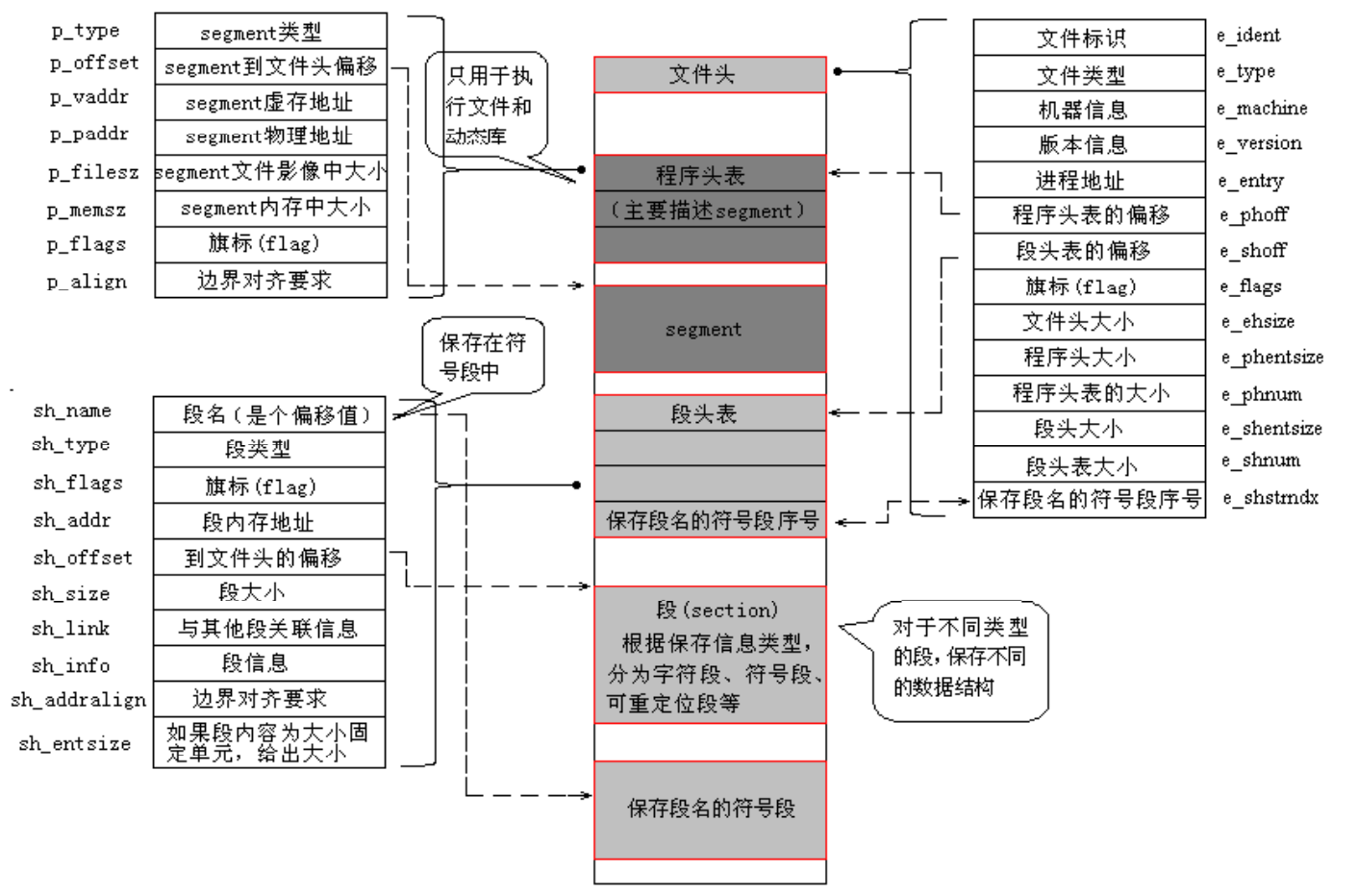
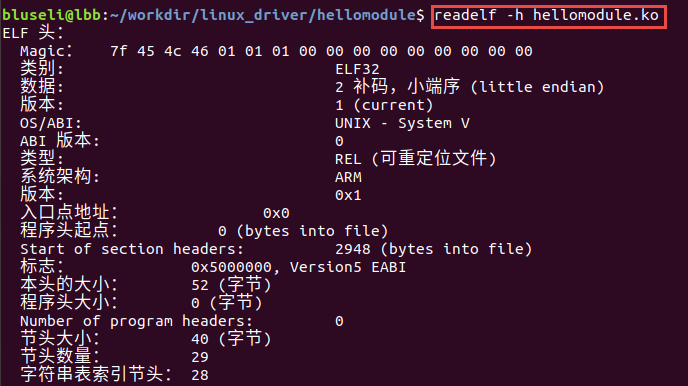
文件开始处是一个ELF头部(ELF Header),用来描述整个文件的组织,这些信息独立于处理器, 也独立于文件中的其余内容。我们可以使用readelf工具查看elf文件的头部详细信息。
程序头部表(Program Header Table)是个数组结构,它的每一个元素的数据结构如下每个数组元素表示:
-
一个"段":包含一个或者多个"节区",程序头部仅对于可执行文件和共享目标文件有意义
-
其他信息:系统准备程序执行所必需的其它信息"
节区头部表/段表(Section Heade Table) ELF文件中有很多各种各样的段,这个段表(Section Header Table)就是保存这些段的基本属性的结构, ELF文件的段结构就是由段表决定的,编译器、链接器、装载器都是依靠段表来定位和访问各个段的属性的 包含了描述文件节区的信息。
ELF头部中:
-
e_shoff:给出从文件头到节区头部表格的偏移字节数,
-
e_shnum:给出表格中条目数目,
-
e_shentsize: 给出每个项目的字节数。
从这些信息中可以确切地定位节区的具体位置、长度和程序头部表一样, 每一项节区在节区头部表格中都存在着一项元素与它对应,因此可知,这个节区头部表格为一连续的空间, 每一项元素为一结构体(思考这节开头的那张节区和节区头部的示意图)。
我们可以加上-S参数读取elf文件的节区头部表的详细信息。
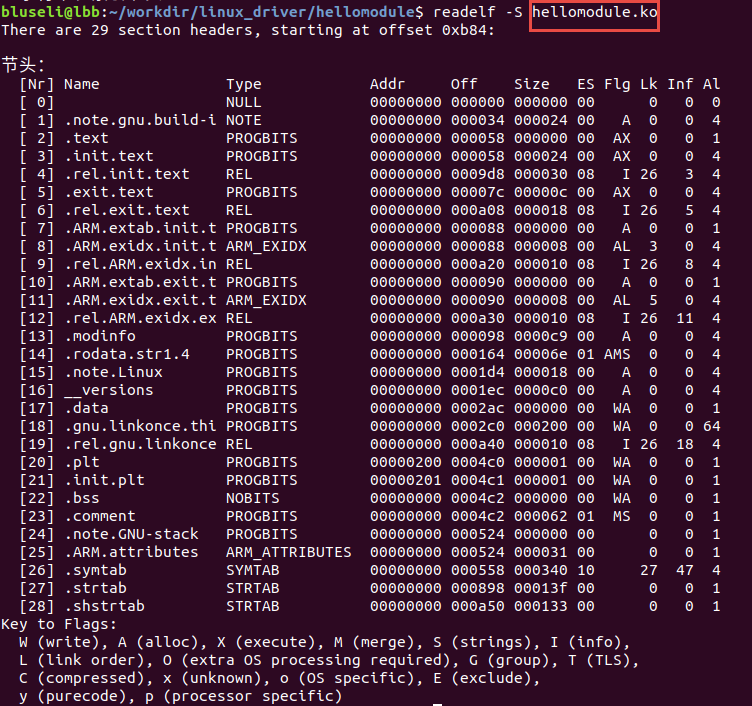
节区头部表中又包含了很多子表的信息,我们简单的来看两个。
重定位表:
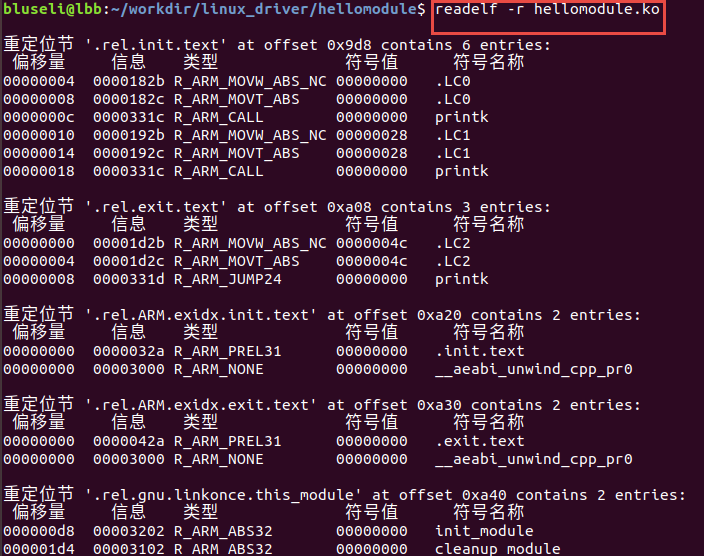
重定位表(".rel.text")位于段表之后,它的类型为(sh_type)为"SHT_REL",即重定位表(Relocation Table) 链接器在处理目标文件时,必须要对目标文件中某些部位进行重定位,即代码段和数据段中那些对绝对地址的引用的位置, 这些重定位信息都记录在ELF文件的重定位表里面,对于每个须要重定位的代码段或者数据段,都会有一个相应的重定位表 一个重定位表同时也是ELF的一个段,这个段的类型(sh_type)就是"SHT_REL"。读取重定位表如下:
字符串表:
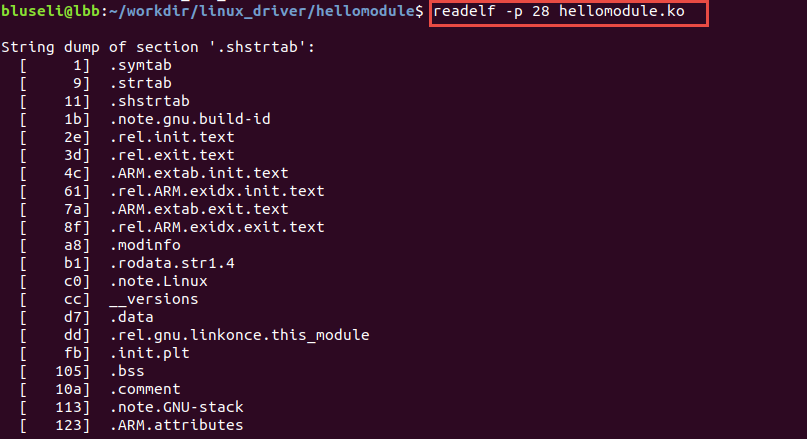
ELF文件中用到了很多字符串,比如段名、变量名等。因为字符串的长度往往是不定的, 所以用固定的结构来表示比较困难,一种常见的做法是把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串。 一般字符串表在ELF文件中也以段的形式保存,常见的段名为".strtab"(String Table 字符串表)或者".shstrtab"(Section Header String Table 段字符串表)。读取节区字符串表如下:
ELF文件格式相关的知识比较晦涩,我们只需要大概了解,有个初步印象即可,主要是为了理解内核模块的加载卸载以及符号导出,在后面提到相关名词不至于太陌生。
1.2.1.2. 内核模块加载过程
在前面我们了解了ko内核模块文件的一些格式内容之后, 我们可以知道内核模块其实也是一段经过特殊加工的代码, 那么既然是加工过的代码,内核就可以利用到加工时留在内核模块里的信息, 对内核模块进行利用。
所以我们就可以接着了解内核模块的加载过程了。
首先**insmod** 会通过文件系统将 .ko模块 读到用户空间的一块内存中, 然后执行系统调用 sys_init_module() 解析模组 ,这时,内核在vmalloc区 分配与ko文件大小相同的内存来暂存ko文件, 暂存好之后解析ko文件,将文件中的各个section分配到init 段和core 段 ,在modules区为init段和core段分配内存, 并把对应的section copy到modules区最终的运行地址,经过relocate函数地址等操作后,就可以执行ko的init操作了, 这样一个ko的加载流程就结束了。 同时,init段会被释放掉,仅留下core段来运行。
cpp
//sys_init_module() (内核源码/kernel/module.c)
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}-
第15行:通过vmalloc在vmalloc区分配内存空间,将内核模块copy到此空间,info->hdr 直接指向此空间首地址,也就是ko的elf header 。
-
第19行:然后通过load_module()进行模块加载的核心处理,在这里完成了模块的搬移,重定向等艰苦的过程。
下面是load_module()函数的详细过程,代码已经被我简化,主要包含setup_load_info()和layout_and_allocate()。
cpp
/* 分配并加载模块 */
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
...
err = setup_load_info(info, flags);
...
mod = layout_and_allocate(info, flags);
...
}-
第9行:setup_load_info()加载struct load_info 和 struct module, rewrite_section_headers,将每个section的sh_addr修改为当前镜像所在的内存地址, section 名称字符串表地址的获取方式是从ELF头中的e_shstrndx获取到节区头部字符串表的标号,找到对应section在ELF文件中的偏移,再加上ELF文件起始地址就得到了字符串表在内存中的地址。
-
第11行:在layout_and_allocate()中,layout_sections() 负责将section 归类为core和init这两大类,为ko的第二次搬移做准备。move_module()把ko搬移到最终的运行地址。内核模块加载代码搬运过程到此就结束了。
内核模块要工作起来还得进行符号导出,后面内核模块导出符号小节有较为详细的讲解。
1.2.1.3. 内核模块卸载过程
卸载过程相对加载比较简单,我们输入指令rmmod ,最终在系统内核中需要调用sys_delete_module进行实现。
具体过程如下:先从用户空间 传入需要卸载的模块名称 ,根据名称找到要卸载的模块指针 , 确保我们要卸载的模块没有被其他模块依赖 ,然后找到模块本身的exit函数实现卸载。 代码如下。
cpp
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
return -EFAULT;
name[MODULE_NAME_LEN-1] = '\0';
audit_log_kern_module(name);
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
mod = find_module(name);
if (!mod) {
ret = -ENOENT;
goto out;
}
if (!list_empty(&mod->source_list)) {
ret = -EWOULDBLOCK;
goto out;
}
/* Doing init or already dying? */
if (mod->state != MODULE_STATE_LIVE) {
/* FIXME: if (force), slam module count damn the torpedoes */
pr_debug("%s already dying\n", mod->name);
ret = -EBUSY;
goto out;
}
if (mod->init && !mod->exit) {
forced = try_force_unload(flags);
if (!forced) {
/* This module can't be removed */
ret = -EBUSY;
goto out;
}
}
ret = try_stop_module(mod, flags, &forced);
if (ret != 0)
goto out;
mutex_unlock(&module_mutex);
/* Final destruction now no one is using it. */
if (mod->exit != NULL)
mod->exit();
blocking_notifier_call_chain(&module_notify_list,MODULE_STATE_GOING, mod);
klp_module_going(mod);
ftrace_release_mod(mod);
async_synchronize_full();
/* Store the name of the last unloaded module for diagnostic purposes */
strlcpy(last_unloaded_module, mod->name, sizeof(last_unloaded_module));
free_module(mod);
return 0;
out:
mutex_unlock(&module_mutex);
return ret;
}-
第8行:确保有插入和删除模块不受限制的权利,并且模块没有被禁止插入或删除
-
第11行:获得模块名字
-
第20行:找到要卸载的模块指针
-
第26行:有依赖的模块,需要先卸载它们
-
第39行:检查模块的退出函数
-
第48行:停止机器,使参考计数不能移动并禁用模块
-
第56行:告诉通知链module_notify_list上的监听者,模块状态 变为 MODULE_STATE_GOING
-
第60行:等待所有异步函数调用完成
1.2.2. 内核是如何导出符号的
符号是什么东西?我们为什么需要导出符号呢?内核模块如何导出符号呢?其他模块又是如何找到这些符号的呢?
这是这一小节讨论的知识,实际上,符号指的就是内核模块中使用EXPORT_SYMBOL 声明 的函数和变量 。 当模块被装入内核 后,它所导出的符号都会记录在公共内核符号表中。 在使用命令insmod加载模块后,模块就被连接到了内核,因此可以访问内核的共用符号。
通常情况下我们无需导出任何符号,但是如果其他模块 想要从我们这个模块中获取某些方便的时候, 就可以考虑使用导出符号为其提供服务。这被称为模块层叠技术。 例如msdos文件系统依赖于由fat模块导出的符号;USB输入设备模块层叠在usbcore和input模块之上。 也就是我们可以将模块分为多个层,通过简化每一层来实现复杂的项目。
modprobe是一个处理层叠模块的工具,它的功能相当于多次使用insmod, 除了装入指定模块外还同时装入指定模块所依赖的其他模块。
当我们要导出模块的时候,可以使用下面的宏
cpp
EXPORT_SYMBOL(name)
EXPORT_SYMBOL_GPL(name) //name为我们要导出的标志符号必须在模块文件的全局部分导出,不能在函数中使用,_GPL使得导出的模块只能被GPL许可的模块使用。 编译我们的模块时,这两个宏会被拓展为一个特殊变量的声明,存放在ELF文件中。 具体也就是存放在ELF文件的符号表中:
-
st_name: 是符号名称在符号名称字符串表中的索引值
-
st_value: 是符号所在的内存地址
-
st_size: 是符号大小
-
st_info: 是符号类型和绑定信息
-
st_shndx: 表示符号所在section
当ELF的符号表被加载到内核后,会执行simplify_symbols来遍历整个ELF文件符号表。 根据st_shndx找到符号所在的section和st_value中符号在section中的偏移得到真正的内存地址。 并最终将符号内存地址,符号名称指针存储到内核符号表中。
simplify_symbols函数原型如下:
cpp
static int simplify_symbols(struct module *mod, const struct load_info *info)函数参数和返回值如下:
参数:
-
mod: struct module类型结构体指针
-
info: const struct load_info结构体指针
返回值:
- ret: 错误码
内核导出的符号表结构 有两个 字段,一个是符号在内存中的地址 ,一个是符号名称指针 , 符号名称被放在了**__ksymtab_strings**这个section中, 以EXPORT_SYMBOL举例,符号会被放到名为___ksymtab的section中。 这个结构体我们要注意,它构成的表是导出符号表而不是通常意义上的符号表 。
cpp
//kernel_symbol结构体 (内核源码/include/linux/export.h)
struct kernel_symbol {
unsigned long value;
const char *name;
};-
value: 符号在内存中的地址
-
name: 符号名称
其他的内核模块在寻找符号的时候会调用resolve_symbol_wait 去内核和其他模块中通过符号名称 寻址目标符号,resolve_symbol_wait会调用resolve_symbol ,进而调用 find_symbol。 找到了符号之后,把符号的实际地址赋值给符号表 symi.st_value = ksym->value;
cpp
//find_symbol函数 (内核源码/kernel/module.c)
/* 找到一个符号并将其连同(可选)crc和(可选)拥有它的模块一起返回。需要禁用抢占或模块互斥。 */
const struct kernel_symbol *find_symbol(const char *name,
struct module **owner,
const s32 **crc,
bool gplok,
bool warn)
{
struct find_symbol_arg fsa;
fsa.name = name;
fsa.gplok = gplok;
fsa.warn = warn;
if (each_symbol_section(find_symbol_in_section, &fsa)) {
if (owner)
*owner = fsa.owner;
if (crc)
*crc = fsa.crc;
return fsa.sym;
}
pr_debug("Failed to find symbol %s\n", name);
return NULL;
}
EXPORT_SYMBOL_GPL(find_symbol);-
第15行:在each_symbol_section中,去查找了两个地方,一个是内核的导出符号表,即我们在将内核符号是如何导出的时候定义的全局变量,一个是遍历已经加载的内核模块,查找动作是在each_symbol_in_section中完成的。
-
第25行:导出符号标志
至此符号查找完毕,最后将所有section借助ELF文件的重定向表进行重定向,就能使用该符号了。
到这里内核就完成了内核模块的加载/卸载以及符号导出,感兴趣的读者可以查阅 内核源码中 /kernel/module.c。
2. 驱动章节实验环境搭建
首先我们要明白程序最终是运行在开发板上,我们开发板主要使用i.MX6ULL系列处理器, 它包含一个Cortex-A7(ARM的一种高能效处理器架构)内核。开发板上已经移植好相关的环境, 我们只需要将我们写的代码交叉编译成arm架构下的可执行文件。
设备驱动是具有独立功能的程序,它可以被单独编译,但不能独立运行, 在运行时它被链接到内核作为内核的一部分在内核空间运行。也因此想要我们写的内核模块在某个版本的内核上运行, 那么就必须在该内核版本上编译它,如果我们编译的内核与我们运行的内核具备不相同的特性,设备驱动则可能无法运行。
首先我们需要知道内核版本,并准备好该版本的内核源码,使用交叉编译工具编译内核源码; 其次,依赖编译的内核源码编译我们的驱动模块以及设备树文件。最终将驱动模块和设备树拷贝到开发板上运行。
2.1. 环境准备
既然是编译内核模块,那么这项工作的开始,自然就是构建一遍完整的内核。 当内核能够完整构建之后,我们构建内核模块的操作才可以顺利进行。
2.1.1. 安装工具
在编译源码之前我们需要先准备好交叉编译的环境,安装必要的依赖和工具,
-
gcc-arm-linux-gnueabihf 交叉编译器
-
bison 语法分析器
-
flex 词法分析器
-
libssl-dev OpenSSL通用库
-
lzop LZO压缩库的压缩软件
执行下面的命令即可:
bash
sudo apt install make gcc-arm-linux-gnueabihf gcc bison flex libssl-dev dpkg-dev lzop2.1.2. 编译内核
注意: 野火的开发板已默认烧录4.19.35版本内核,本章节都不需要烧录我们编译的内核,编译内核是为了辅助编译驱动程序。 如果你有烧录内核的需求请参考 制作系统镜像 系列章节。我们编译的内核模块也是需要4.19.35版本的,才能被内核装载。
2.1.2.1. 获取内核源码
开发板内核使用 Linux npi 4.19.35-imx6 版本,可以使用命令'uname -a'查看。 我们可以从git克隆野火官方提供的Debian镜像内核源码。
克隆命令如下:
github:
bash
git clone -b ebf_4.19.35_imx6ul https://github.com/Embedfire/ebf_linux_kernel.gitgitee:
bash
git clone https://gitee.com/Embedfire/ebf_linux_kernel_6ull_depth1提示:因为网络原因从githu克隆困难的用户请使用下面gitee的地址, gitee仓库master分支作为github仓库ebf_4.19.35_imx6ul分支的只保存了最新提交内容(git clone 使用 --depth=1 参数),可以直接使用, 如果需要查看历史提交差异内容可以从github网页里面访问。
2.1.2.2. 进行编译
我们可以单独新建一个工作目录,将内核源码放置在该目录下,切换到内核源码目录,我们可以找到make_deb.sh脚本, 里面有配置好的参数,只需要执行脚本便可编译内核。编译出来的内核相关文件存放位置, 由脚本 make_deb.sh 中 build_opts="${build_opts} O=build_image/build" 指定。 示例源码指定编译好的内核存放在build_image/build,建议不修改此目录,方便后面编译驱动模块。

执行如下命令即可开始构建内核:
bash
./make_deb.sh
2.1.2.3. make_deb.sh脚本
bash
deb_distro=bionic
DISTRO=stable
build_opts="-j 6"
build_opts="${build_opts} O=build_image/build"
build_opts="${build_opts} ARCH=arm"
build_opts="${build_opts} KBUILD_DEBARCH=${DEBARCH}"
build_opts="${build_opts} LOCALVERSION=-carp-imx6"
build_opts="${build_opts} KDEB_CHANGELOG_DIST=${deb_distro}"
build_opts="${build_opts} KDEB_PKGVERSION=1${DISTRO}"
build_opts="${build_opts} CROSS_COMPILE=arm-linux-gnueabihf-"
build_opts="${build_opts} KDEB_SOURCENAME=linux-upstream"
make ${build_opts} npi_v7_defconfig
make ${build_opts}
make ${build_opts} bindeb-pkg-
第4行: 指定编译好的内核放置位置
-
第5行: 编译出来的目标是针对ARM体系结构的内核
-
第6行: 对于deb-pkg目标,允许覆盖deb-pkg部署的常规启发式
-
第7行: 使用内核配置选项"LOCALVERSION"为常规内核版本附加一个唯一的后缀。
-
第11行: 指定交叉编译器
-
第14行: 生成配置文件
-
第16行: 编译文件进行打包
更多内核编译可选的参数,可以参考linux内核官方网址: linux内核编译参数介绍![]() https://www.kernel.org/doc/html/latest/kbuild/kbuild.html
https://www.kernel.org/doc/html/latest/kbuild/kbuild.html
构建好内核之后,我们可以进行下面的内容学习了。
2.2. 如何编译和加载内核驱动模块
对于linux内核,可以通过两种方式将内核模块添加到内核中:
-
1、将内核模块编译成内核模块文件,在内核启动后由用户手动动态加载,
-
2、将模块直接编译到内核中去,内核启动时自动加载。
我们着重第一种方式的讲解。
首先我们需要,获取内核驱动模块示例源码。
github:
bash
git clone https://github.com/Embedfire/embed_linux_driver_tutorial_imx6_code.gitgitee:
bash
git clone https://gitee.com/Embedfire/embed_linux_driver_tutorial_imx6_code.git2.2.1. 在内核源码外编译
内核驱动模块对象所需的构建步骤和编译很复杂,它利用了linux内核构建系统的强大功能, 当然我们不需要深入了解这部分知识,利用简单的Make工具就能编译出我们想要的内核驱动模块。
进入我们要编译的内核模块代码的makefile文件:

该目录下的Makefile中指定的目录**"KERNEL_DIR=../../build_image/build"**要与前面编译的内核所在目录一致。
bash
KERNEL_DIR=............./build_image/build
ARCH=arm
CROSS_COMPILE=arm-linux-gnueabihf-
export ARCH CROSS_COMPILE
obj-m := hellomodule.o
all:
$(MAKE) -C $(KERNEL_DIR) M=$(CURDIR) modules
.PHONE:clean
clean:
$(MAKE) -C $(KERNEL_DIR) M=$(CURDIR) clean-
第1行: 指定编译内核存放位置
-
第2行: 针对ARM体系结构
-
第3行: 指定交叉编译工具链
-
第4行: 导入环境变量
-
第6行: 表示以模块编译
-
第8行: all只是个标号,可以自己定义,是make的默认执行目标。
-
第9行: (MAKE):MAKE是Makefile中的宏变量,要引用宏变量要使用符号。这里实际上就是指向make程序,所以这里也可以把(MAKE)换成make.-C:是make命令的一个选项,-C作用是changedirectory. -C dir 就是转到dir目录。M=(CURDIR):返回当前目录。这句话的意思是:当make执行默认的目标all时,-C(KVDIR)指明跳转到内核源码目录下去执行那里的Makefile,-C (KERNEL_DIR)指明跳转到内核源码目录下去执行那里的Makefile,M=(CURDIR)表示又返回到当前目录来执行当前的Makefile.
-
第11行: clean 就是删除后面这些由make生成的文件。
再切换到module/hellomodule目录下,直接执行make命令,即可编译程序。查看module/hellomodule/文件夹,新增hellomodule.ko,这就是我们自己编写、编译的内核驱动模块。
2.2.2. 和内核源码一起编译
- 待完善
2.2.3. 加载内核驱动模块
编译好内核驱动模块,可以通过多种方式将hellomodule.ko拷贝到开发板,我们这里主要使用NFS网络文件系统或者SCP命令。
NFS环境请搭建请参考Linux系列章节之 挂载MFS网络文件系统 章节。
scp 命令用于 Linux 之间复制文件和目录,scp命令格式如下:
bash
scp hellomodule.ko debian@192.168.0.109:/home/debian/将hellomodule.ko发送到192.168.0.109这个IP的Linux(这里是我的开发板IP)的/home/debian/目录下,开发板用户名为debian, 输入yes,然后验证密码,等待传输完成。这个时候我们开发板就有了hellomodule.ko 这个文件。
安装卸载内核驱动模块使用insmod和rmmod,后面章节有对这两个工具的详细介绍,这里不做展开。
bash
sudo insmod hellomodule.ko
sudo rmmod hellomodule.ko2.3. 设备树编译和加载
Linux3.x以后的版本才引入了设备树,设备树用于描述一个硬件平台的板级细节。 后面我们写的驱动需要依赖设备树,所以在这里先演示如何编译设备树、加载设备树。
这里不做代码讲解,具体原理请参考 Linux设备树 章节
2.3.1. 设备树编译
2.3.1.1. 使用内核中的dtc工具编译
首先我们需要编译好内核(通常只需一次编译好内核,编译内核的时候会生成的dtc工具),内核编译的位置在 内核源码/build_image/build/ ,内核中的dtc工具位置在 内核源码/build_image/build/scripts/dtc/dtc 。
dtc工具使用示例如下:
bash
# 编译 dts 为 dtb
内核目录/build_image/build/scripts/dtc/dtc -I dts -O dtb -o xxx.dtb xxx.dts实际使用示例,此处为伪代码,仅供参考使用,了解即可:
bash
内核目录/build_image/build/scripts/dtc/dtc -I dts -O dtb -o fire-dtb.dtb fire-dts.dts内核使用dtc工具的命令大致如上所示,实际上设备树中有非常多的依赖关系, 这些依赖关系通过Makefile文件去处理,所以一般情况下, 设备树不仅仅只是通过一个dtc命令就能将编译出来的。
2.3.1.2. 在内核源码中编译设备树(推荐使用)
我们可以尝试着通过内核的构建脚本 去编译设备树,我们所要用到的设备树文件 都存放在 **内核源码/arch/arm/boot/dts/**里面。
前面提到了编译内核时会自动去编译设备树,但是编译内核很耗时,所以我们推荐使用如下命令只编译设备树。
bash
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- npi_v7_defconfig
make ARCH=arm -j4 CROSS_COMPILE=arm-linux-gnueabihf- dtbs如果在内核源码中执行了**make distclean** 则必须执行第一条命令,它用于生成默认配置文件, 如果执行过一次就没有必要再次执行,当然再次执行也没有什么问题。 第二条命令开始编译设备树, 参数"-j4"指定多少个线程编译,根据自己电脑实际情况设置,越大编译越快,当然也可以不设置,设备树编译本来就很快。

编译成功后生成的设备树文件(.dtb) 位于源码目录下的 内核源码/arch/arm/boot/dts , 野火开发板适配的设备树文件名为**imx6ull-mmc-npi.dtb** 。
2.3.2. 加载设备树
2.3.2.1. 设备树加载方法
替换设备树有下面几种方法。
-
第一种,简单直接,设备树是在编译到内核中的,所以重新烧写内核这种方式肯定可行。但是烧写内核比较麻烦,可以参考制作系统镜像系列章节。不推荐也不做过多的讲解。
-
第二种,将我们编译好的设备树或者设备树插件替换掉开发板里面原有的。
我们只介绍第二种,将编译好的新设备树文件,替换开发板**/usr/lib/linux-image-4.19.35-imx6/**目录下的旧设备树文件即可。
2.3.2.2. 检查设备树加载情况
假设 我们在原来的设备树上添加了新的节点,led_test, 在该节点下有一个设备为 rgb_led_red,我们可以通过以下的方式加载并查看新的设备树是否生效了, 新节点是否添加。
通过SCP或NFS将编译的设备树拷贝到开发板上。替换 /usr/lib/linux-image-4.19.35-imx6/imx6ull-mmc-npi.dtb。
uboot在启动的时候负责该目录的设备文件加载到内存,供内核解析使用。输入 sudo reboot 命令重启开发板即可。
**设备树中的设备树节点在文件系统中有与之对应的文件,位于"/proc/device-tree"目录。**进入"/proc/device-tree"目录如下所示。

接着进入led 文件夹,可以发现led节点中定义的属性以及它的子节点,如下所示。

在节点属性中多了一个name,我们在led节点中并没有定义name属性,这是自从生成的,保存节点名。
这里的属性是一个文件,而子节点是一个文件夹,我们再次进入"rgb_led_red@0x0209C000"文件夹。 里面有compatible name reg status四个属性文件。 我们可以使用"cat"命令查看这些属性文件,如下所示。

至此,设备树加载成功。
2.4. 设备树插件的编译和加载
Linux4.4以后引入了动态设备树(Dynamic DeviceTree)。设备树插件被动态的加载到系统中,供被内核识别。 编译设备树插件的时候无需重新编译整个设备树插件,只需要编译我们修改的部分即可。
注意设备树插件和设备树不是互相替代的关系,而是互补的关系。设备树插件可以在主设备树定型的情况下, 再对主设备树未描述的功能进行动态的拓展。 比如A板的设备树没有开启串口1的功能,但B板需要开启串口1的功能,那么可以直接沿用A板的设备树, 并用设备树插件拓展出串口1,满足B板的需求。
2.4.1. 在内核编译设备树插件(推荐)
设备树插件与设备树一样都是使用DTC工具编译,只不过设备树编译为.dtb。而设备树插件需要编译为.dtbo。 我们可以使用DTC编译命令编译生成.dtbo,但是这样比较繁琐、容易出错。
我们将设备树插件dtbo的编译工作也放在了内核编译时来完成, 当然我们单独编译设备树的时候也是可以编译出设备树插件dtbo的。
我们在内核中提供了大量的设备树插件,野火的开发板许多外设硬件描述都是以dtbo插件的形式提供的。 这样使用起来非常灵活。
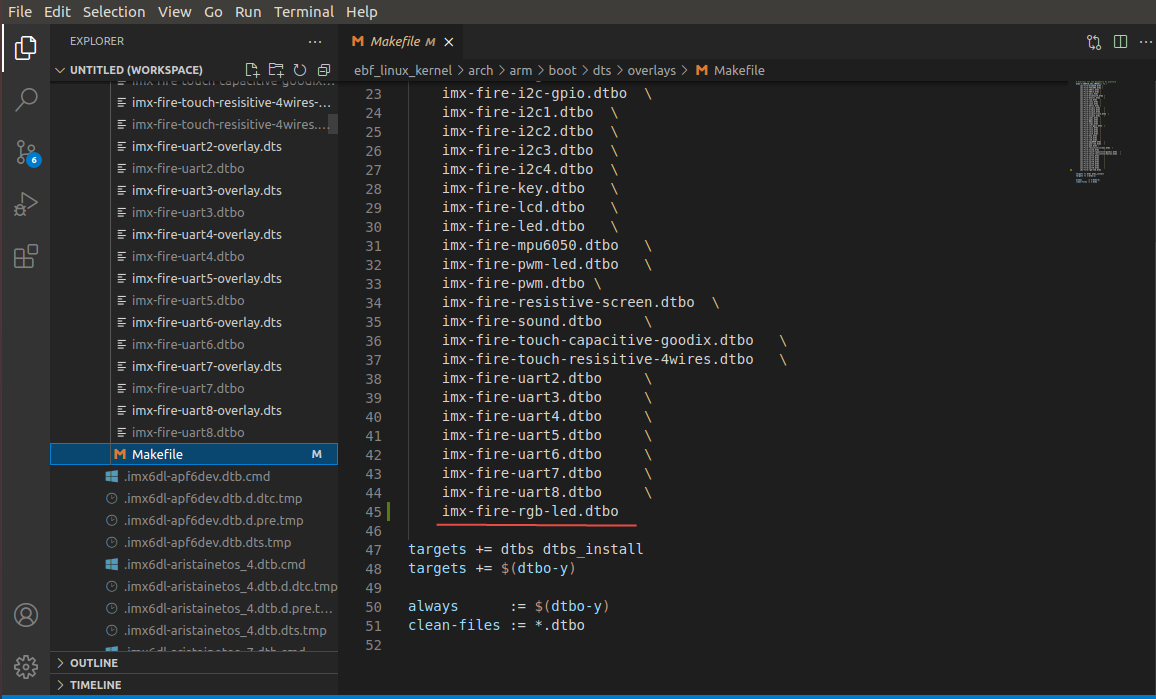
如上图,当大家尝试写设备树插件的时候,可以将自己的设备树插件添加到: arch/arm/boot/dts/overlays 目录下, 并修改 arch/arm/boot/dts/overlays/Makefile 文件, 添加编译选项,形如imx-fire-rgb-led.dtbo的添加形式。 将imx-fire-rgb-led.dtbo追加到imx-fire-uart8.dtbo后面即可。
添加好后,可以执行设备树 的编译命令,设备树插件的编译也会同步完成。
bash
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- npi_v7_defconfig
make ARCH=arm -j4 CROSS_COMPILE=arm-linux-gnueabihf- dtbs
可以看到,编译输出时,dtbo文件也有对应的打印信息。
2.4.2. 内核编译设备树插件过程(不推荐)
编译设备树插件和编译设备树类似,这里介绍内核中的dtc工具编译编译设备树插件的过程。
内核中将xxx.dts 编译为 xxx.dtbo的过程示例,仅供参考:
bash
内核构建目录/scripts/dtc/dtc -I dts -O dtb -o xxx.dtbo xxx.dts例如,将fire-rgb-led-overlay.dts编译为rgb.dtbo
bash
../ebf_linux_kernel/build_image/build/scripts/dtc/dtc -I dts -O dtb -o rgb.dtbo fire-rgb-led-overlay.dts编译好的设备树插件为rgb.dtbo。
当然和编译设备树一样,设备树插件的编译也涉及到依赖关系,所以编译过程也比较复杂。 不仅仅是使用一条命令就可以完成编译的。
2.4.3. 加载设备树插件
2.4.3.1. uboot加载(适用野火linux开发板)
1、可以通过SCP或NFS将.dtbo设备树插件拷贝到开发板 /usr/lib/linux-image-4.19.35-imx6/overlays/ 上,所以下面操作都在开发板上进行。
如下所示:
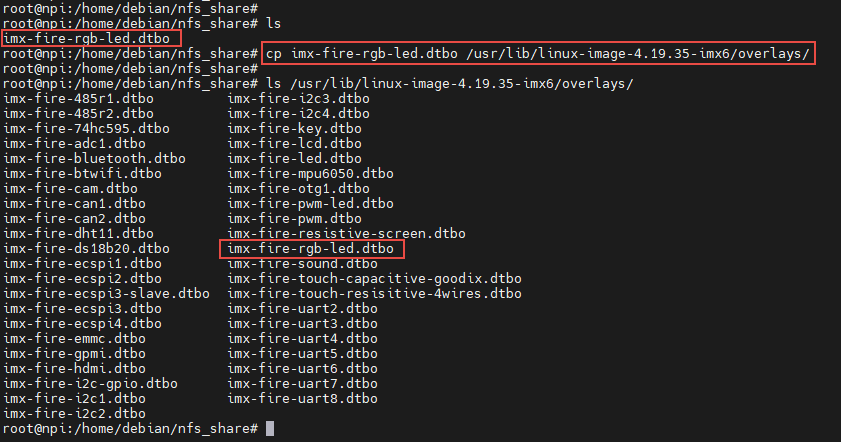
2、将对应的设备树插件加载配置,写入uEnv.txt配置文件,系统启动过程中会自动从uEnv.txt读取要加载的设备树插件,
打开位于"/boot"目录下的uEnv.txt文件,如下所示:
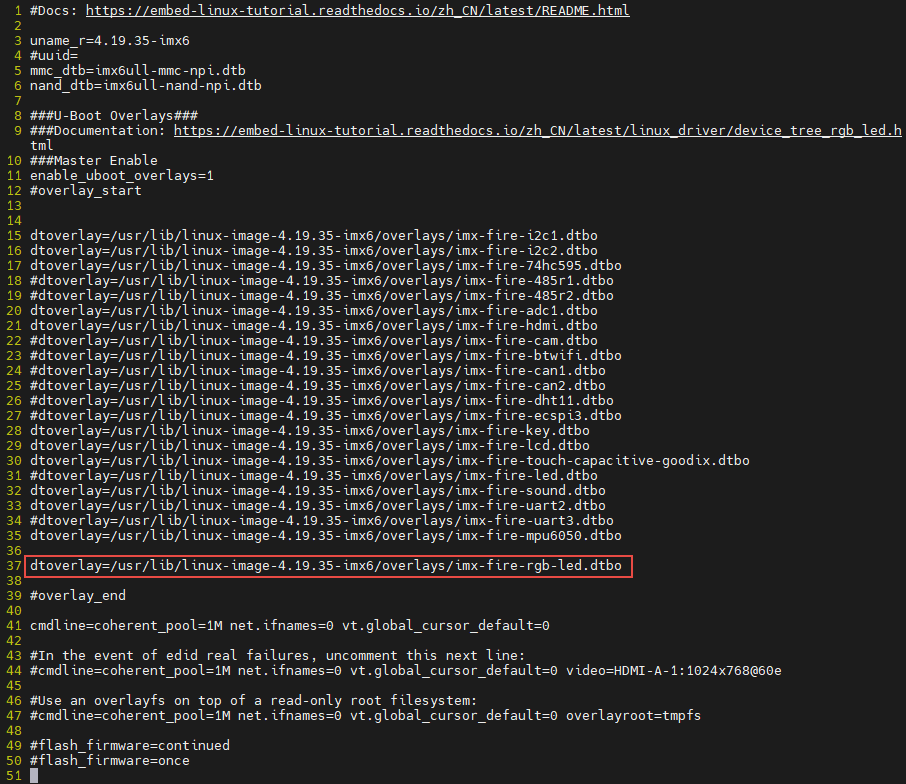
要将设备树插件写入uEnv.txt也很简单,参照着红框内容写即可。书写格式为"dtoverlay=<设备树插件路径>"。
从上图中可以看出在uEnv.txt文件夹下有很多被屏蔽的设备树插件,这些设备树插件是烧写系统时自带的插件, 为避免它们干扰我们的实验,这里可以把它们全部屏蔽掉。
修改完成后保存、退出。执行reboot命令重启系统。重启后正常情况下我们可以在**"/proc/device-tree"**找与插入的设备节点同名的文件夹。
在"/proc/device-tree"目录下找到与插入的设备树节点同名的文件夹, 进入该文件夹还可以看到该节点拥有的属性以及它的子节点,如下所示。
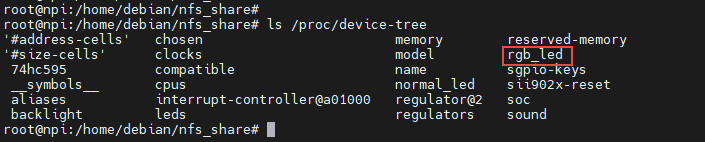
看到这些文件,证明已经加载成功了。
