传统的目标检测模型通常受到其训练数据和定义的类别逻辑的限制。随着语言-视觉模型的近期兴起,出现了不受这些固定类别限制的新方法。尽管这些开放词汇检测模型具有灵活性,但与传统的固定类别模型相比,仍然在准确性上存在不足。同时,更加准确的数据特定模型在需要扩展类别或合并不同数据集进行训练时面临挑战。后者通常由于逻辑或冲突的类别定义而无法组合,这使得在不损害模型性能的情况下提升模型变得困难。
CerberusDet是一个旨在处理多目标检测任务的多头模型框架,该模型基于YOLO架构,能够有效地共享来自主干和NECK部分组件的视觉特征,同时保持独立的任务头。这种方法使得CerberusDet能够高效地执行,同时仍然提供最佳结果。在
PASCAL VOC数据集和Objects365数据集上评估了该模型,以展示其能力。CerberusDet实现了最先进的结果,推理时间减少了36%。同时训练的任务越多,所提出的模型与顺序运行单独模型相比,效率越高。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: CerberusDet: Unified Multi-Dataset Object Detection

Introduction

向一个使用目标检测(OD)的现有实时应用程序中添加新类别涉及几个重大挑战。一个关键问题是,在一个数据集中标注的对象类别在另一个数据集中可能没有标注,即使这些对象本身出现在后者的图像中。此外,由于标注逻辑的不同和类别重叠的不完整,合并不同的数据集往往是不可能的。同时,这类应用程序需要高效的管道,这限制了独立的数据特定模型的使用。
论文的目标是构建一个在多个数据集上训练的统一模型,其准确性不会低于单独训练模型的表现,同时利用更少的计算资源。论文提出了CerberusDet,用于同时在多个数据集上训练单个检测神经网络。论文还展示了一种识别最佳模型架构的方法,因为并不是所有任务都可以一起训练。一个显著的挑战在于确定哪些参数在不同任务之间共享,任务的次优分组可能导致负迁移,即在无关任务之间共享信息的问题。此外,在计算资源有限的情况下,所提方法能够选择满足要求的架构。在开放数据的实验中,CerberusDet使用一个统一的神经网络获得的结果与分离数据特定的最先进模型相媲美。
扩展检测器模型以包含新类别的另一种方法是使用开放词汇目标检测器(OVDs),这一方法最近变得越来越流行。然而,OVDs通常缺乏数据特定检测器的准确性,需要大量的训练数据,并且容易对基础类别过拟合。论文优先考虑高准确性,而非OVDs的灵活性。论文提出的架构能够根据需要添加新类别,同时保持之前学习类别的准确性,更适合实际的需求。值得注意的是,这种方法已经在生产环境中部署并验证,证明了其在实际应用中的鲁棒性和可靠性。
论文的主要贡献如下:
-
对多数据集和多任务检测的各种方法进行了研究,探索了不同的参数共享策略和训练程序。
-
展示了使用开放数据集的几个实验结果,提供了各种方法有效性的见解。
-
提出了一种新的多分支目标检测模型
CerberusDet,可以根据不同的计算需求和任务进行定制。 -
公开发布了训练和推理代码,以及训练好的模型,鼓励该领域进一步的研究和发展。
Model
Method
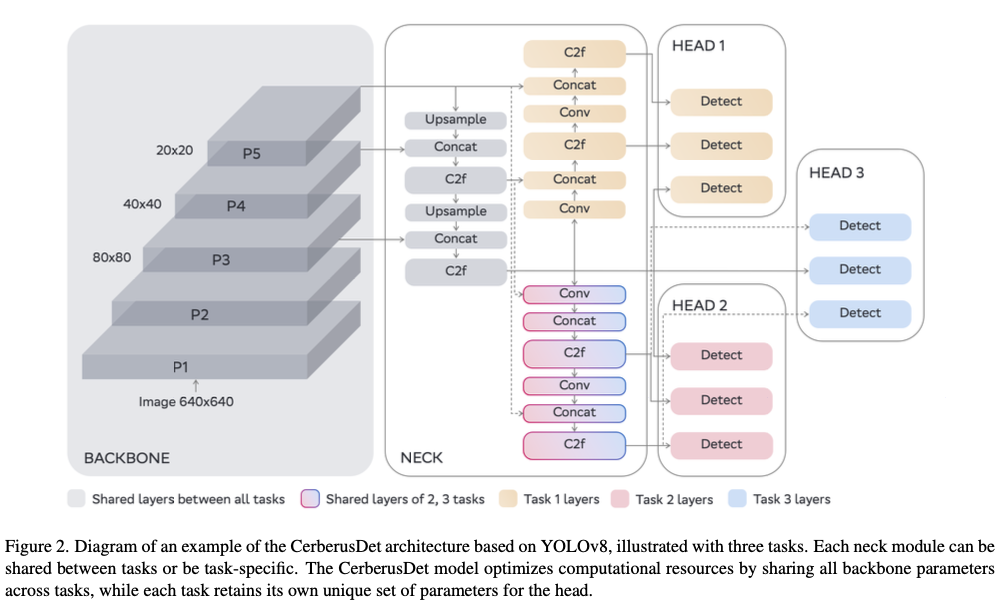
CerberusDet模型允许在一个共享模型中学习多个检测任务。每个检测任务都是一个独立的任务,使用其自己的数据集和独特的标签集。
CerberusDet模型建立在YOLO架构之上,通过在任务之间共享所有主干参数来优化计算资源,而每个任务保留其自己独特的HEAD部分参数集。NECK部分层可以是共享的,也可以是特定于任务的。图2展示了基于YOLOv8的CerberusDet架构在三个任务下的一个可能变体。使用标准的YOLOv8x架构和640的输入图像分辨率,该模型的主干由184层和3000万参数组成。NECK部份有6个可共享模块,包含134层和2800万参数。每个HEAD部分由54层和800万参数组成。
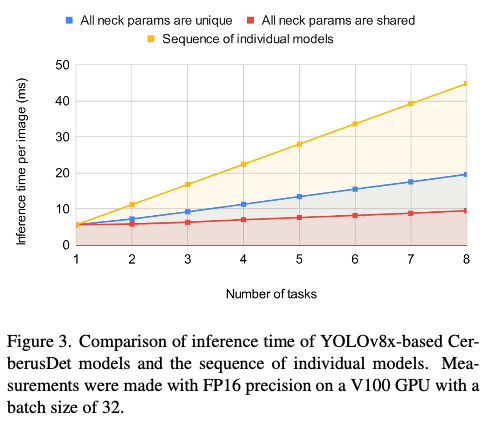
通过在多个任务之间共享主干,训练方法相比于对每个任务分别使用单独模型的顺序推理,实现了显著的计算预算节约。图3展示了基于YOLOv8x架构的CerberusDet的推理速度。该图比较了两种场景的推理时间:一种是所有NECK部分参数依赖于特定任务,另一种是这些参数在任务间共享。结果突出显示了通过参数共享所获得的计算效率。
Parameters sharing
鉴于硬参数共享技术在多任务学习中的高效性及其通过在训练过程中利用任务间的信息来增强每个任务的预测质量,论文决定采用该技术。硬参数共享允许任务之间共享一组参数,并保留一组任务特定的参数。基于YOLO架构,在模块级别具有可共享的参数集。例如,YOLOv8x有6个参数化的NECK部分模块,因此每个任务可以与另一个任务共享其中的任一模块。
为了决定哪些模块在不同任务之间共享,采用表示相似性分析(Representation Similarity Analysis,RSA)方法来估计每个NECK部分模块的任务相似性,这些模块可以是共享的或特定于任务的。然后,对于每个可能的架构变体,计算基于RSA的相似性评分( \(\mathit{rsa\ score}\) )和 \(\mathit{computational\ score}\) 。第一个评分显示了架构的潜在性能,而第二个评分评估了其计算效率。在可用的计算预算内,选择具有最佳 \(\mathit{rsa\ score}\) 的架构。设该架构包含 \(l\) 个可共享模块并且有 \(N\) 个任务,选择该架构的算法如下所示:
- 从每个任务的测试集中选择一个小的代表性图像子集。
- 使用特定于任务的模型,从每个模块中提取所选图像的特征。
- 根据提取的特征,计算双重性图相似性(
Duality Diagram Similarity,DDS)------计算每对选定图像的成对(不)相似性。矩阵的每个元素是(1 -皮尔逊相关系数)的值。 - 使用中心化核对齐(
Centered Kernel Alignment,CKA)方法对DDS矩阵进行计算,生成表示不相似度矩阵(Representation Dissimilarity Matrices,RDMs)------每个模块一个 \(N \times N\) 矩阵。矩阵的每个元素表示两个任务之间的相似性系数。 - 对于每种可能的架构,使用来自
RDM矩阵的值计算 \(\mathit{rsa\ score}\) ,即可共享模型层中每个位置的任务不相似度得分之和。定义为 \(\mathit{rsa\ score} = \sum_{m=1}^{l} S_m\) ,其中 \(S_m\) (公式 `ref`{eq:rsa})通过对模块 l 中共享任务的不相似度得分之间的最大距离取平均得到。 - 对于每种可能的架构,使用公式
2计算 \(\mathit{computational\ score}\) 。 - 选择具有最佳 \(\mathit{rsa\ score}\) 和 \(\mathit{computational\ score}\) 组合的架构(越低越好),或者在 \(\mathit{computational\ score}\) 的设定约束下选择具有最低 \(\mathit{rsa\ score}\) 的架构。
\\\begin{align} \\label{eq:rsa} S_m \&= \\frac{1}{\|\\tau_i, \\ldots, \\tau_k\\}\|} \\times \\\\ \&\\sum_{j=i}\^{k} \\max \\left\\{ RDM(j, i), \\ldots, RDM(j, k) \\right\\} \\notag \\end{align} \\
其中 \(\{\tau_i, \ldots, \tau_k\}\) 是模块 \(l\) 中的共享任务。
\\\begin{equation} \\label{eq:comp_score} \\mathit{computational\\ score} = \\frac{\\mathit{inference\\_time}}{(N \* \\mathit{single\\_inference\\_time})} \\end{equation} \\
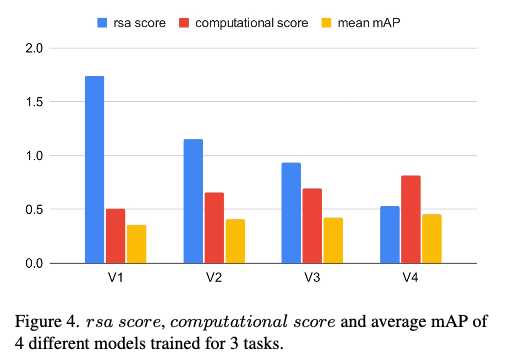
为了评估所选择的方法,选择了4个具有不同RSA分数和计算分数的架构,训练模型并比较了平均指标值。图4表明,随着RSA分数的下降和计算复杂度的增加,模型的准确性也在提高。为了计算计算分数,使用了V100 GPU,批处理大小为1。
Training procedure

考虑一组任务 \(\{\mathit{{\tau}1, \ldots, \tau_n}\}\) ,这些任务的不同组合可能共享一组模型参数。设 \(\theta{shared} = \{\theta_{i..k}, \ldots \theta_{j..m}\}\) 为不同任务组之间的共享参数集合 \(\{i, \ldots,k\}, \ldots, \{j, \ldots,m\}\) 。算法1展示了所提出的CerberusDet模型的端到端学习过程。在训练过程中,遍历任务,从相应的数据集中抽取小批量数据,计算与当前任务相关的参数的损失和梯度。接下来,对每个任务组的共享参数进行梯度平均,并根据公式3更新它们的值。
\\\begin{equation} \\label{eq:average} \\theta_{\\{i,\\ldots,k\\}} = \\theta_{\\{i,\\ldots,k\\}} - (\\alpha \* \\frac{1}{\|\\{i,\\ldots,k\\}\|} \* \\sum_{j \\in \\{i,\\ldots,k\\}} \\dfrac{\\partial L_j}{\\partial \\theta_{\\{i,\\ldots,k\\}}}) \\end{equation} \\
其中 \(\{i,\ldots,k\}\) 表示具有共享参数 \(\theta_{\{i,\ldots,k\}}\) 的任务组, \(\alpha\) 是学习率, \(L_j\) 是任务 \(j\) 的损失。
联合训练的速度和有效性受到各个任务损失函数的强烈影响。由于这些损失函数可能具有不同的性质和规模,因此正确权衡它们是至关重要的。为了找到损失函数的最佳权重以及其他训练超参数,采用超参数演化方法。
在训练过程中,如果每个批次中的样本没有经过仔细和全面的平衡,模型的性能会显著下降。为了解决这个问题,需要确保每个迭代中所有类别都根据它们在数据集中的频率得到充分表示。
The impact of training settings
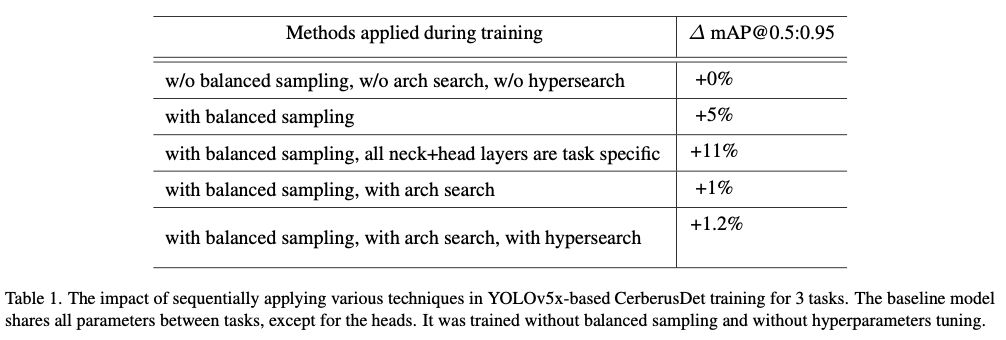
表1展示了前面所述的每种技术影响的结果。在这些实验中使用专有数据,因为它们展示了足够的任务间一致性,以确保实验的清晰性。模型被训练用于3个任务,其中基线是一个架构,在该架构中,模型的所有参数(除了HEAD部分)都是在各任务之间共享的。
第一个任务的数据集包含22个类别,训练集中有27,146张图像,验证集中有3,017张图像。第二个任务的数据集包含18个类别,训练集中有22,365张图像,验证集中有681张图像。第三个任务的数据集包含16个类别,训练集中有17,012张图像,验证集中有3,830张图像。为了比较架构搜索方法对结果的影响,论文还训练了一个模型,其中所有的NECK部分参数都是任务特定的,然后将发现的架构的准确性提升与之进行比较。
提到的模型是在YOLOv5x基础上构建的,输入图像分辨率为640x640,测量是在V100 GPU上以FP16精度进行的。
Open-source datasets experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
