论文:https://arxiv.org/abs/2410.05963
代码:暂未提供
摘要
本文介绍了一种名为VL-SAM的训练免费框架,用于解决开放性物体检测和分割任务。该框架结合了通用对象识别模型 (MLLM)和通用对象定位模型(SAM),并通过使用注意力映射作为提示连接这两个通用模型。实验结果表明,VL-SAM在LVIS数据集上的表现优于之前的方法,并且可以在真实世界应用中提供额外的实例分割掩模。此外,VL-SAM具有良好的模型泛化能力,可以集成各种VLM和SAM。
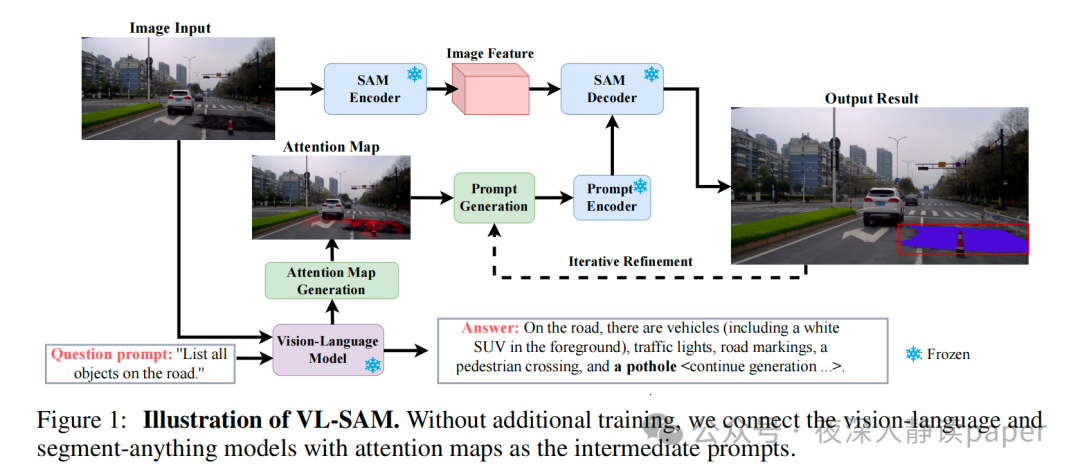
论文速读
方法描述
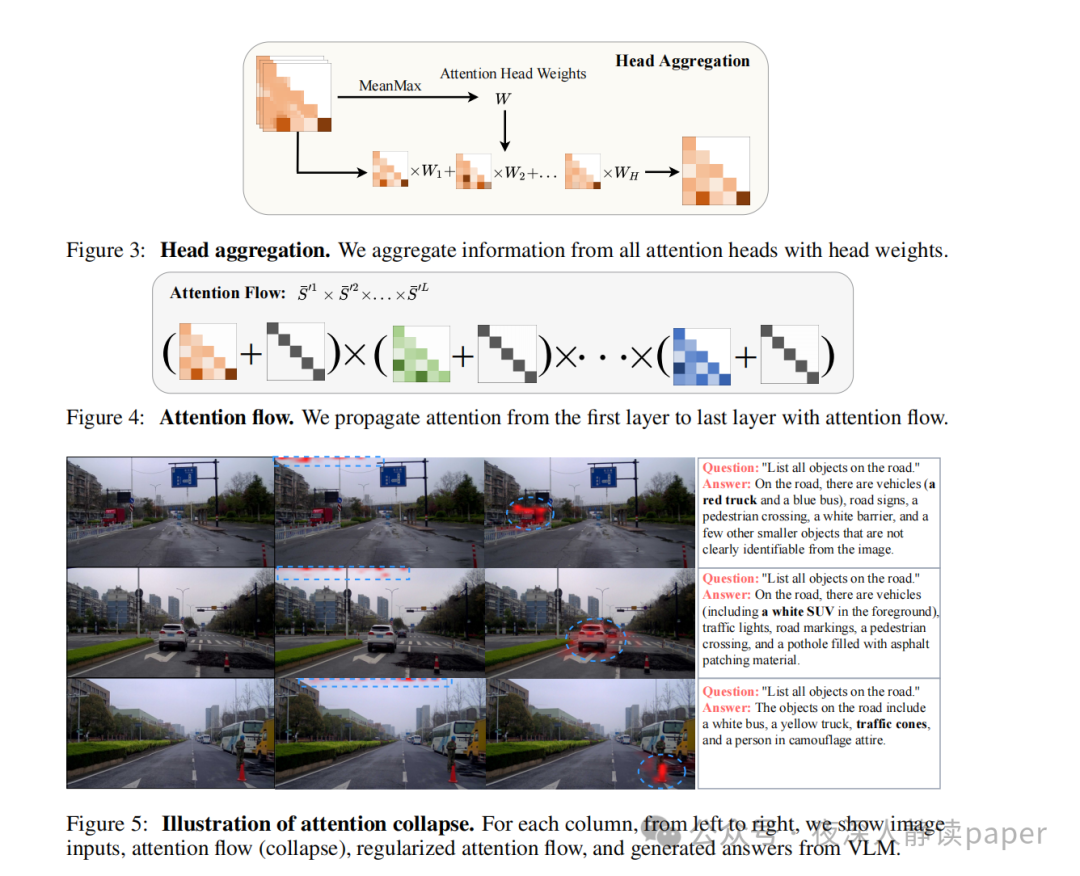
本文提出的VL-SAM框架是一种基于视觉语言模型(VLM)和场景分割模型(SAM)的对象识别与定位方法。首先使用VLM来描述图像并列出所有可能存在的对象,然后针对每个对象使用注意力生成模块结合头聚合和注意力流来获取高质量的关注图,并将其转换为点提示发送给SAM以获得位置预测。该方法的关键在于如何生成高质量的关注图,因此引入了注意力流来聚合和传播注意力图通过VLM中的所有transformer头部和层。在注意力流中,先将查询和键乘以因果掩码和SoftMax归一化,得到相似度矩阵S,再通过选择每列的最大相似权重来进行注意力头权重计算。最后,使用注意力滚动方法来进一步聚合来自所有层的注意力,并选择最后一层的注意力图作为对象关注图。
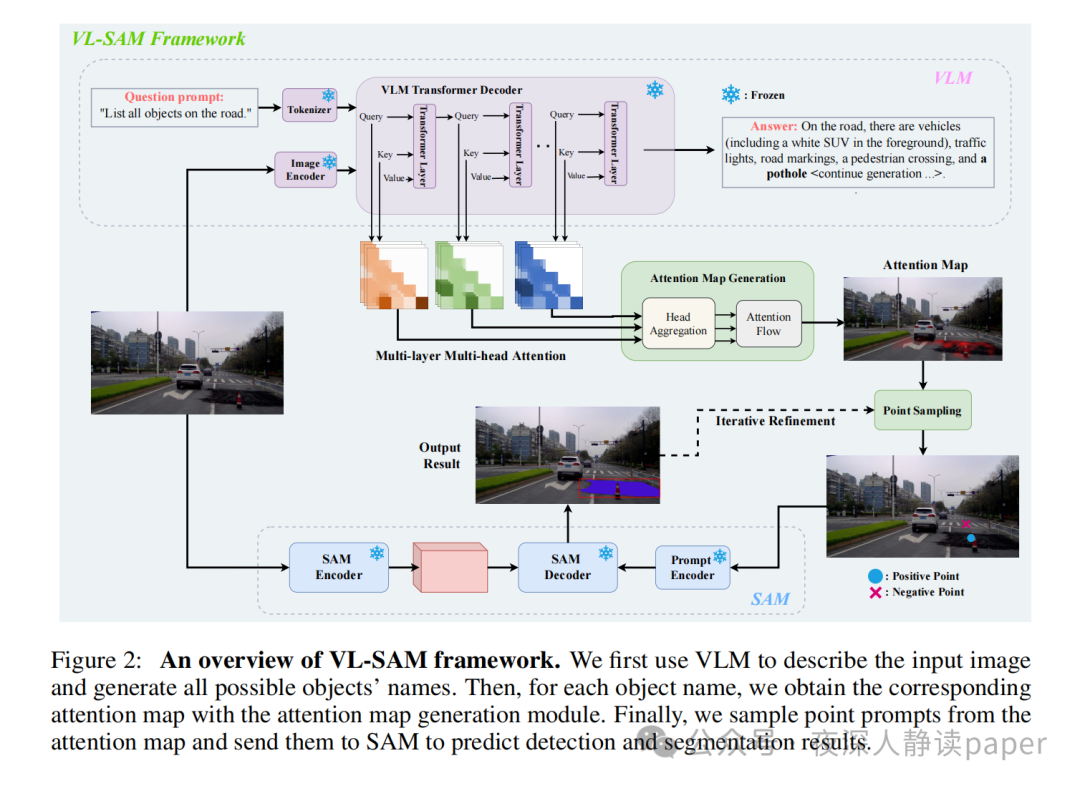
方法改进
为了解决VLM自动回归生成方法导致的注意力塌陷问题,提出了一个简单的正则化项,可以有效地缓解这个问题。此外,在使用SAM进行物体分割时,由于可能存在不稳定的假阳性区域,因此需要对其进行过滤。为此,首先使用阈值滤除弱激活区域,并找到最大连通区域作为正区域,其余区域作为负区域。然后,从正区域中随机采样一个正点,从负区域中随机采样一个负点,作为SAM的点提示对。对于迭代策略,采用了两次迭代来进一步细化分割结果,分别采用了PerSAM中的级联后处理和利用先前生成的分割掩模来遮挡注意力图,并不断迭代生成新的正负对,然后将它们送入SAM解码器,最终通过NMS进行聚合。
另外,为了克服VLM低分辨率输入图像可能导致无法识别小物体的问题,采用了SPHINX中的多尺度融合方法,将图像分成四个子图像,并独立地将每个子图像发送到VL-SAM中,最后将四个子图像的输出和整个图像的输出进行融合。此外,还使用了VLM生成的十个问题提示来描述输入图像,以获得更全面的图像描述,并将其用于VL-SAM中的对象识别和定位。
解决的问题
本文提出的VL-SAM框架主要解决了两个问题:对象识别和定位。对于对象识别,通过使用VLM来描述图像并列出所有可能存在的对象,可以准确地识别出图像中存在的对象。而对于对象定位,则通过使用注意力生成模块结合头聚合和注意力流来获取高质量的关注图,并将其转换为点提示发送给SAM以获得位置预测,从而实现了精确的对象定位。同时,本文也提出了一些改进措施,如使用正则化项缓解注意力塌陷问题、使用阈值过滤假阳性区域以及采用多尺度融合和问题提示等方法来提高对象识别和定位的准确性。
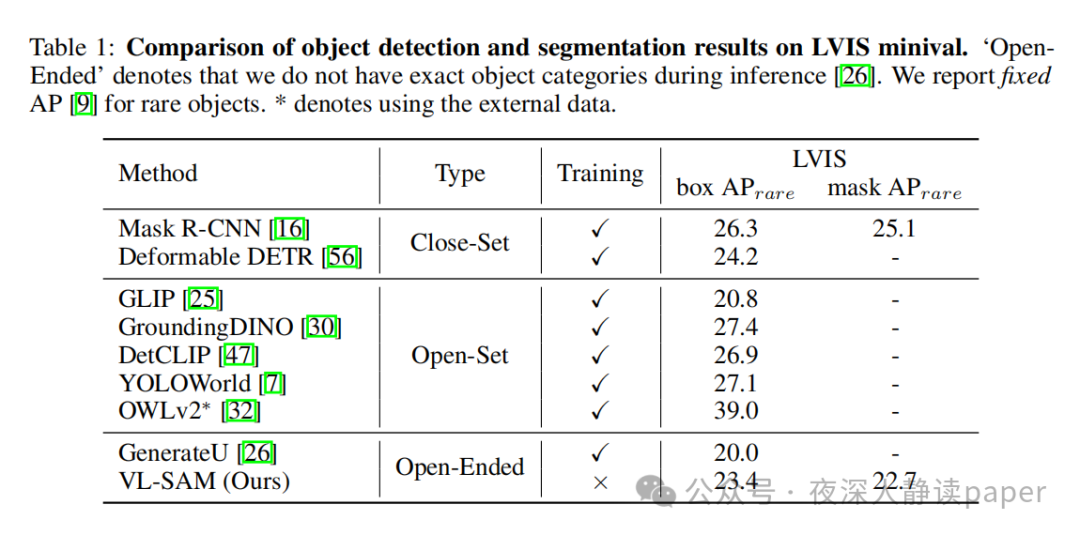
论文实验
本文主要介绍了VL-SAM(Vision-Language Segmentation Model)这一训练免费的零样本检测框架,并通过多个实验对其性能进行了评估和比较。
首先,在LVIS数据集上,作者将VL-SAM与GenerateU等其他方法进行了比较。他们使用了固定AP来衡量罕见物体的检测性能,并发现VL-SAM在该任务中表现优于GenerateU,具有更好的检测和分割性能。此外,VL-SAM还能够在不需要预先定义对象类别的情况下生成这些类别,因此更加实用。
其次,在CODA数据集上,作者将VL-SAM与其他开放域检测器进行了比较。结果表明,当前基于对象提议的开放域检测器难以处理角落情况,而依靠CLIP作为对象类别预测器的方法则表现更好。然而,LLaVA-Grounding等最近的开放域检测器需要联合训练两个模型,增加了训练成本。相比之下,VL-SAM是一种训练免费的框架,可以在没有额外训练成本的情况下显著提高性能。
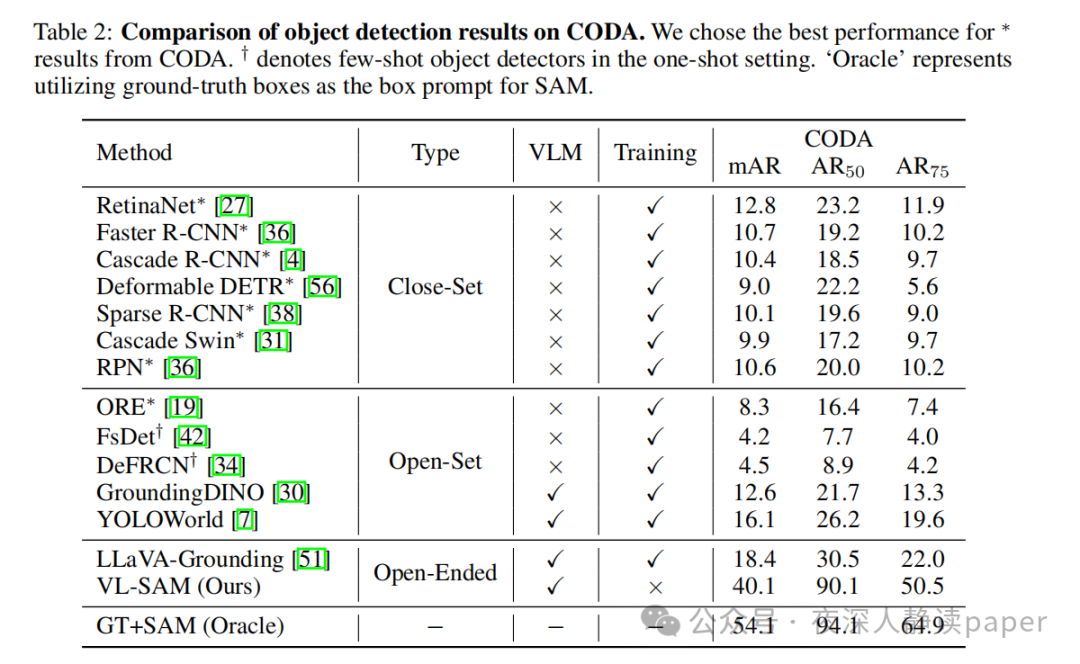
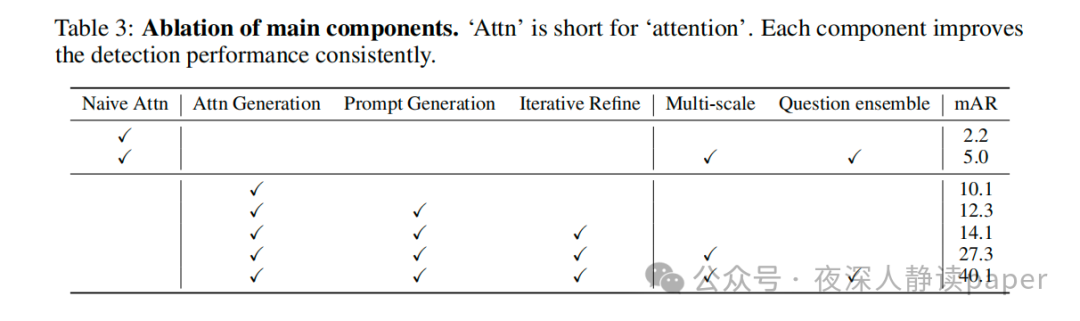
最后,作者还进行了消融研究,分析了VL-SAM各个组件的效果。结果显示,每个组件都对最终性能有重要影响。例如,引入注意力生成模块可以显著提高基线性能,而迭代精炼模块则可以进一步提高检测性能。同时,多尺度图像输入和问题提示的组合也能够带来显著的性能提升。
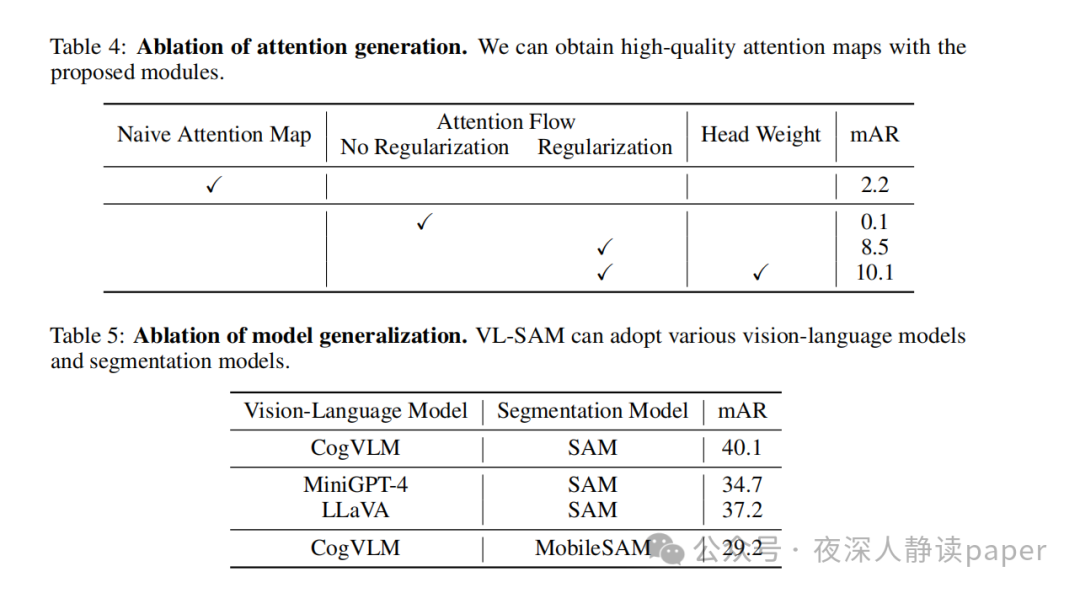
总的来说,VL-SAM在各种实验中都表现出色,证明了其作为一种零样本检测框架的有效性和实用性。