1合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
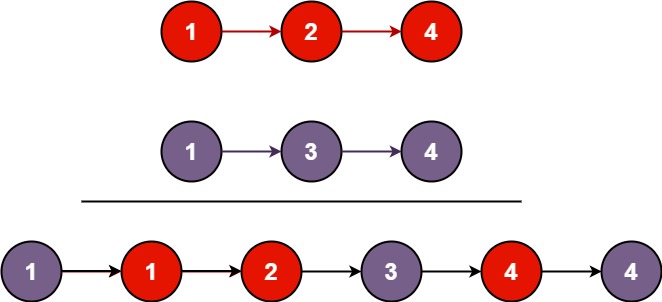
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]示例 2:
输入:l1 = [], l2 = []
输出:[]示例 3:
输入:l1 = [], l2 = [0]
输出:[0]提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
思路:
-
初始检查:
- 首先检查两个链表是否为空。如果其中一个链表为空,直接返回另一个链表。
-
创建哑节点:
- 创建一个哑节点(dummy node),用于简化链表的插入操作。哑节点的
next指针将最终指向新链表的头结点。
- 创建一个哑节点(dummy node),用于简化链表的插入操作。哑节点的
-
合并链表:
- 使用
while循环,在list1和list2都不为空时,比较两个链表当前节点的值,将较小的节点添加到新链表的尾部,并移动相应的指针。 newtail始终指向新链表的最后一个节点,以便于插入新节点。
- 使用
-
处理剩余节点:
- 循环结束后,可能其中一个链表还剩下一些节点。将剩余的节点直接添加到新链表的尾部。
-
返回结果:
- 返回哑节点的
next指针,即新链表的头结点,跳过哑节点本身。
- 返回哑节点的
代码:
cs
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
// 如果 list1 为空,直接返回 list2
if(list1 == NULL){
return list2;
}
// 如果 list2 为空,直接返回 list1
if(list2 == NULL){
return list1;
}
// 创建一个哑节点(dummy node),用于简化链表操作
struct ListNode dummy;
// 新链表的尾部始终指向哑节点
struct ListNode* newtail = &dummy;
// 初始化哑节点的 next 指针
dummy.next = NULL;
// 当 list1 和 list2 都不为空时,循环比较并合并
while(list1 && list2){
// 如果 list1 的值小于 list2 的值
if(list1->val < list2->val){
// 将 list1 的节点添加到新链表的尾部
newtail->next = list1;
// 移动 list1 指针
list1 = list1->next;
} else {
// 如果 list2 的值小于或等于 list1 的值
// 将 list2 的节点添加到新链表的尾部
newtail->next = list2;
// 移动 list2 指针
list2 = list2->next;
}
// 移动新链表的尾部指针
newtail = newtail->next;
}
// 处理剩余的节点
// 如果 list1 不为空,将剩余的 list1 节点添加到新链表的尾部
if(list1){
newtail->next = list1;
} else {
// 如果 list2 不为空,将剩余的 list2 节点添加到新链表的尾部
newtail->next = list2;
}
// 返回新链表的头结点(跳过哑节点)
return dummy.next;
}2环形链表的约瑟夫问题
题目背景:著名的Josephus问题 据说著名犹太 Josephus有过以下的故事:在罗⻢⼈占领乔塔帕特后,39个犹太⼈与 Josephus及他的朋友躲到⼀个洞中,39个犹太⼈决定宁愿死也不要被⼈抓到,于是决定了⼀个⾃杀 ⽅式,41个⼈排成⼀个圆圈,由第1个⼈开始报数,每报数到第3⼈该⼈就必须⾃杀,然后再由下⼀ 个重新报数,直到所有⼈都⾃杀⾝亡为⽌。 历史学家 然⽽Josephus和他的朋友并不想遵从,Josephus要他的朋友先假装遵从,他将朋友与⾃⼰安排在 第16个与第31个位置,于是逃过了这场死亡游戏。
题目描述
编号为 1 到 n 的 n 个人围成一圈。从编号为 1 的人开始报数,报到 m 的人离开。
下一个人继续从 1 开始报数。
n-1 轮结束以后,只剩下一个人,问最后留下的这个人编号是多少?
数据范围: 1≤n,m≤100001≤n,m≤10000
进阶:空间复杂度 O(1)O(1),时间复杂度 O(n)O(n)
示例1
输入:
5,2 复制返回值:
3 复制说明:
开始5个人 1,2,3,4,5 ,从1开始报数,1->1,2->2编号为2的人离开
1,3,4,5,从3开始报数,3->1,4->2编号为4的人离开
1,3,5,从5开始报数,5->1,1->2编号为1的人离开
3,5,从3开始报数,3->1,5->2编号为5的人离开
最后留下人的编号是3 思路:
-
创建环形链表:
- 调用
createList(n)函数创建一个包含n个节点的环形链表。
- 调用
-
初始化指针和计数器:
pre指针指向链表的最后一个节点。cur指针指向pre的下一个节点(即头节点)。- 初始化计数器
count为 1。
-
遍历链表并删除节点:
- 当链表中还有多个节点时,循环遍历链表。
- 如果计数器
count等于m,则删除当前节点,并重置计数器。
-
约瑟夫环问题求解:
ysf(int n, int m)函数用于解决约瑟夫环问题。- 创建一个包含
n个节点的环形链表。 - 使用
pre指针指向当前节点的前一个节点,cur指针指向当前节点。 - 当链表中还有多个节点时,循环遍历链表,并使用计数器
count记录当前的位置。 - 当计数器达到
m时,销毁当前节点,并调整指针,重新开始计数。 - 当链表中只剩下一个节点时,返回该节点的值。
代码:
cs
#include <stdlib.h>
// 定义链表节点结构
typedef struct ListNode ListNode;
// 购买新节点
ListNode* buyNode(int x) {
ListNode* node = (ListNode*)malloc(sizeof(ListNode));
if (node == NULL) {
exit(1); // 内存分配失败,退出程序
}
node->val = x;
node->next = NULL;
return node;
}
// 创建带环的链表
ListNode* createList(int n) {
ListNode* head = buyNode(1); // 创建头节点
ListNode* tail = head;//刚开始只有一个结点,即是头结点也是为节点
for (int i = 2; i <= n; i++) {//开始尾插
tail->next = buyNode(i); // 创建并链接新节点
tail = tail->next; // 移动尾指针
}
tail->next = head; // 最后一个节点的 next 指针指向头节点,形成环
return tail; // 返回尾节点,方便操作
}
// 约瑟夫环问题求解
int ysf(int n, int m) {
// 创建一个有 n 个节点的环形链表
ListNode* pre = createList(n);先知道尾结点
ListNode* cur = pre->next; // 当前节点是前一个结点的next域处
int count = 1;
// 当链表中还有多个节点时
while (cur->next != cur) {
if (count == m) {
// 销毁当前节点
pre->next = cur->next;//销毁结点的前一个结点,指向销毁结点的后一个结点
free(cur);
cur = pre->next; // 重新定位当前节点
count = 1; // 因为销毁 m 节点后要从其下一个节点接着开始
} else {
// 此时不需要删除节点
pre = cur;
cur = cur->next;
count++;
}
}
// 返回最后剩下的节点的值
return cur->val;
}3.04. 分割链表
给你一个链表的头节点 head 和一个特定值x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你不需要 保留 每个分区中各节点的初始相对位置。
示例 1:
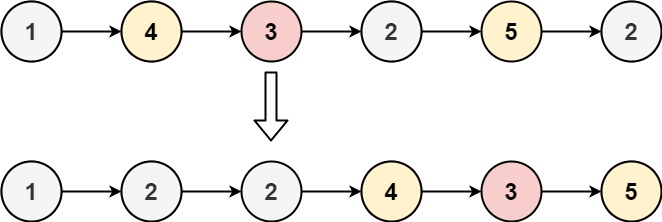
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]示例 2:
输入:head = [2,1], x = 2
输出:[1,2]提示:
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
思路:
-
初始检查:
- 首先检查链表是否为空。如果链表为空,直接返回头节点。
-
创建哑节点:
- 创建两个哑节点
lessHead和bigHead,分别用于存放小于x和大于等于x的节点。 lessTail和bigTail分别指向各自链表的尾部,用于插入新节点。
- 创建两个哑节点
-
遍历链表并分区:
- 遍历原链表,根据当前节点的值将节点插入到相应的链表中。
- 如果当前节点的值小于
x,则将其插入到较小值链表的尾部。 - 如果当前节点的值大于等于
x,则将其插入到较大值链表的尾部。
-
连接两个链表:
- 将较大值链表的尾部指向
NULL,防止成环。 - 将较小值链表的尾部指向较大值链表的头部,完成分区。
- 将较大值链表的尾部指向
-
返回结果:
- 释放哑节点占用的内存。
- 返回最终链表的头节点(跳过较小值链表的哑节点)。
代码:
cs
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x) {
// 如果链表为空,直接返回
if (head == NULL) {
return head;
}
// 创建两个哑节点分别用于存放小于 x 和大于等于 x 的节点
ListNode* lessHead = (ListNode*)malloc(sizeof(ListNode));
ListNode* lessTail = lessHead;
ListNode* bigHead = (ListNode*)malloc(sizeof(ListNode));
ListNode* bigTail = bigHead;
// 遍历原链表
ListNode* cur = head;
while (cur) {
if (cur->val < x) {
// 如果当前节点的值小于 x,将其添加到较小值链表的尾部
lessTail->next = cur;
lessTail = lessTail->next;
} else {
// 如果当前节点的值大于等于 x,将其添加到较大值链表的尾部
bigTail->next = cur;
bigTail = bigTail->next;
}
cur = cur->next; // 移动到下一个节点
}
// 在原来链表中大链表的的值可能指向的是数据域的,所有将较大值链表的尾部指向 NULL,防止成环 若不加这项代码会出现死循环
bigTail->next = NULL;
// 将较小值链表的尾部指向较大值链表的头部
lessTail->next = bigHead->next;
// 获取最终链表的头节点
ListNode* ret = lessHead->next;
// 释放哑节点占用的内存
free(lessHead);
free(bigHead);
lessHead=bigHead=NULL;
// 返回最终链表的头节点
return ret;
}