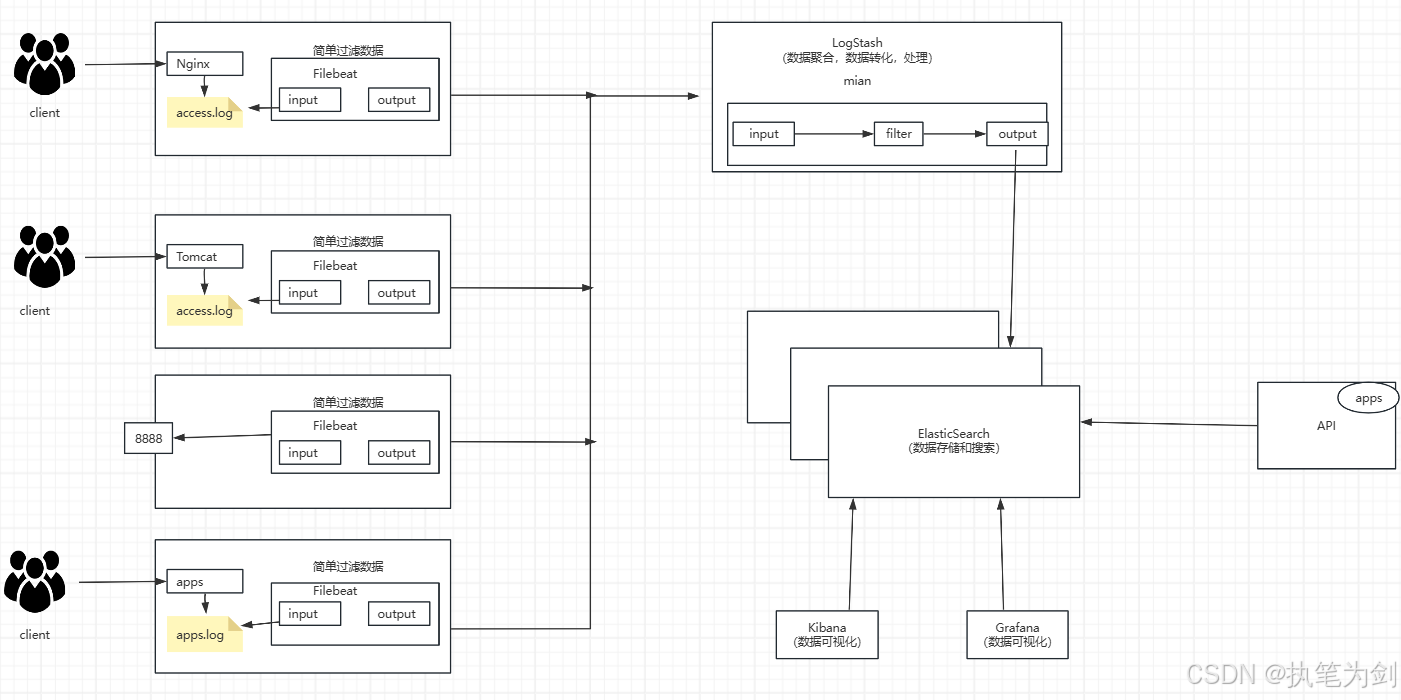
ElasticStack-数据库
bash
#官网https://www.elastic.co/cn/
#下载7.17版环境准备
| 主机名 | IP | 系统版本 | VMware版本 |
|---|---|---|---|
| elk1 | 10.0.0.91 | Ubuntu 22.04.4 | 17.5.1 |
| elk2 | 10.0.0.92 | Ubuntu 22.04.4 | 17.5.1 |
| elk3 | 10.0.0.93 | Ubuntu 22.04.4 | 17.5.1 |
单机部署ES
bash
1.下载ES软件包,放到/usr/local下
[14:59:25 root@elk1:~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.23-amd64.deb
2.安装ES软件包
[15:26:21 root@elk1:/usr/local]# dpkg -i elasticsearch-7.17.23-amd64.deb
3.添加别名(可选操作)
[15:28:06 root@elk1:~]#vim .bashrc
...
alias yy='egrep -v "^.*#|^$"'
...
[15:28:59 root@elk1:~]#source .bashrc
4.修改ES的配置文件
[root@elk91 ~]# vim /etc/elasticsearch/elasticsearch.yml
...
# 指定集群的名称
cluster.name: Cloud Native
# 指定数据的路径
path.data: /var/lib/elasticsearch
# 指定日志的路径
path.logs: /var/log/elasticsearch
# 指定监听的IP地址
network.host: 0.0.0.0
# 指定监听的端口号
http.port: 9200
# 指定当前节点是一个单点而非集群
discovery.type: single-node
[15:35:54 root@elk1:~]# yy /etc/elasticsearch/elasticsearch.yml
cluster.name: Cloud Native
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.type: single-node
5.启动ES服务
[15:35:55 root@elk1:~]# systemctl enable --now elasticsearch.service
[15:40:27 root@elk1:~]# ss -ntl | egrep "9200|9300"
LISTEN 0 4096 *:9300 *:*
LISTEN 0 4096 *:9200 *:*
`--------------------------#说明------------------------`
--now 即时生效
ss 显示网络连接状态的工具
-n 表示不进行域名解析
-t 表示只显示 TCP 协议的连接
-l 表示只显示处于监听状态(LISTEN)的连接
`------------------------------------------------------`
6.访问测试
[15:44:23 root@elk1:~]# curl 10.0.0.91:9200
{
"name" : "elk1",
"cluster_name" : "Cloud Native",
"cluster_uuid" : "0JGTAahZR5Kwx1Na5psicQ",
"version" : {
"number" : "7.17.23",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "61d76462eecaf09ada684d1b5d319b5ff6865a83",
"build_date" : "2024-07-25T14:37:42.448799567Z",
"build_snapshot" : false,
"lucene_version" : "8.11.3",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
[15:44:43 root@elk1:~]# curl 10.0.0.91:9200/_cat/nodes
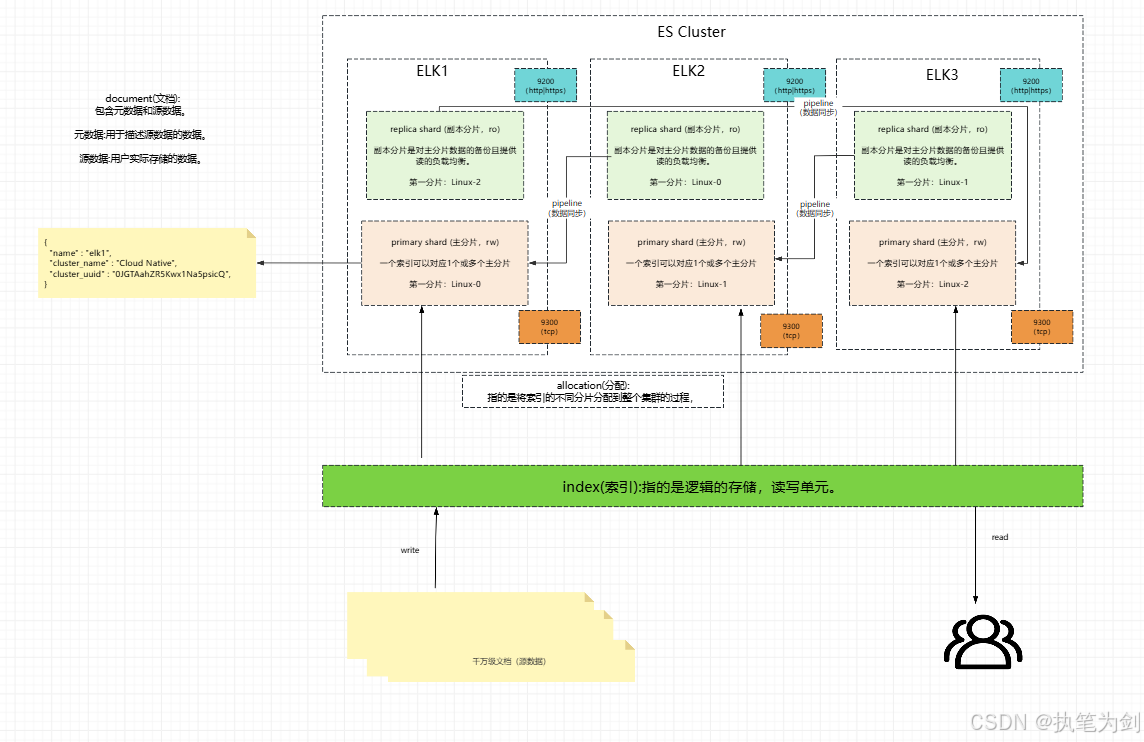
10.0.0.91 42 97 1 0.01 0.02 0.02 cdfhilmrstw * elk1扩容单点ES成集群
bash
#将我们的单点扩容成ES集群模式
1.拷贝安装包到其他节点
[16:25:26 root@elk1:/usr/local]# scp elasticsearch-7.17.23-amd64.deb 10.0.0.92:/usr/local
[16:25:26 root@elk1:/usr/local]# scp elasticsearch-7.17.23-amd64.deb 10.0.0.93:/usr/local
2.其他节点安装ES服务
[16:27:23 root@elk2:/usr/local]#dpkg -i elasticsearch-7.17.23-amd64.deb
[16:27:50 root@elk3:/usr/local]# dpkg -i elasticsearch-7.17.23-amd64.deb
3.elk93节点停止服务
[16:29:15 root@elk1:~]# systemctl stop elasticsearch.service
4.修改配置文件,其实就是改变了discovery。
[16:39:02 root@elk1:~]# yy /etc/elasticsearch/elasticsearch.yml
cluster.name: Cloud Native
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.0.0.91", "10.0.0.92","10.0.0.93"]
5.将配置文件同步到其他节点
[16:32:34 root@elk1:~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.92:/etc/elasticsearch/
[16:33:17 root@elk1:~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.93:/etc/elasticsearch/
6.启动服务
[16:39:27 root@elk1:~]# systemctl enable --now elasticsearch
[16:29:18 root@elk2:~]# systemctl enable --now elasticsearch
[16:29:20 root@elk3:~]# systemctl enable --now elasticsearch
7.验证服务是否启动成功
[16:46:45 root@elk1:~]# curl 10.0.0.93:9200/_cat/nodes
10.0.0.91 16 97 2 0.00 0.08 0.09 cdfhilmrstw * elk1
10.0.0.92 9 96 2 0.00 0.07 0.06 cdfhilmrstw - elk2
10.0.0.93 7 97 4 0.03 0.17 0.10 cdfhilmrstw - elk3
[16:50:15 root@elk1:~]# for i in 91 92 93;do curl -s 10.0.0.$i:9200|grep cluster_uuid;done
"cluster_uuid" : "0JGTAahZR5Kwx1Na5psicQ",
"cluster_uuid" : "0JGTAahZR5Kwx1Na5psicQ",
"cluster_uuid" : "0JGTAahZR5Kwx1Na5psicQ",
`-----------------------#说明----------------------------`
curl 命令
-s #只输出请求的结果内容
-X #选项用于指定 HTTP 方法,这里指定为PUT,表示发送一个 HTTP PUT 请求。"PUT" 是一种 HTTP 请求方法。它的主要作用是请求服务器存储一个资源,并用请求中的数据来更新服务器上指定资源的全部内容。
`-------------------------------------------------------`ES常见术语
bash
1.索引:index
一个ES集群可以有多个索引,索引是用户进行数据读写的逻辑单元。
2.分片:shard
一个索引最少对应一个分片,但实际工作中一个索引尽量对应多个分片,以便于数据的分布式存储。
同一个分片只能属于一个节点。
3.副本:replica
对分片进行备份。
4.文档:document
实际用户存储的数据。
源数据:用户实际存储的数据。
元数据:用于描述源数据的数据。
5.分配:allocation
指的是将索引的不同分片分配到整个集群的过程。ES的索引API管理实战
bash
1.创建索引:
#ES默认创建一个分片和一个副本
[17:43:30 root@elk1:~]# curl -X PUT 10.0.0.92:9200/linux01
{"acknowledged":true,"shards_acknowledged":true,"index":"linux01"}
#查看创建的索引(查看全部)
[17:45:47 root@elk1:~]# curl 10.0.0.92:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .geoip_databases HC7IMR4IQt2lzPHNQJLdTg 1 1 38 0 73.5mb 36.7mb
green open linux01 ja9sklLWTRmgRdrEuGNmxA 1 1 0 0 454b 227b
#ES创建索引时可以自定义分片和副本
[17:49:43 root@elk1:~]# curl -X PUT 'http://10.0.0.91:9200/linux02' \
-H 'Content-Type: application/json' \
-d '{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}'
2.查看索引
[17:49:52 root@elk1:~]#curl 10.0.0.92:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .geoip_databases HC7IMR4IQt2lzPHNQJLdTg 1 1 38 0 73.5mb 36.7mb
green open linux02 hdq2U9YxQz2ScGa7U3JJcQ 3 0 0 0 681b 681b
green open linux01 ja9sklLWTRmgRdrEuGNmxA 1 1 0 0 454b 227b
3.删除索引
[17:51:30 root@elk1:~]#curl -X DELETE 'http://10.0.0.91:9200/linux01'
4.修改索引
[17:52:22 root@elk1:~]# curl -X PUT 'http://10.0.0.91:9200/linux02/_settings' \
-H 'Content-Type: application/json' \
-d '{
"number_of_replicas": 1
}'
[17:52:23 root@elk1:~]# curl 10.0.0.92:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .geoip_databases HC7IMR4IQt2lzPHNQJLdTg 1 1 38 0 73.5mb 36.7mb
green open linux02 hdq2U9YxQz2ScGa7U3JJcQ 3 1 0 0 1.3kb 681b
`删除所有索引:(生产环境中要禁用此功能!)`
[17:52:43 root@elk1:~]# curl -X DELETE 'http://10.0.0.91:9200/*' ES的API验证数据的存储和读取
bash
#写入数据
[17:55:10 root@elk1:~]# curl --location --request POST 'http://10.0.0.91:9200/_bulk' \
-H 'Content-Type: application/json' \
-d '{"index" : { "_index" : "xiyouji"} }
{"name": "孙悟空","hobby": ["蟠桃","紫霞仙子","人参果"]}
{"index" : { "_index" : "xiyouji"} }
{"name": "猪八戒","hobby": ["嫦娥","高小姐","蜘蛛精"]}
{"index" : { "_index" : "xiyouji"} }
{"name": "沙和尚","hobby": ["唐僧肉","挑行李"]}
{"index" : { "_index" : "xiyouji"} }
{"name": "唐三藏","hobby": ["女儿国","人参果"]}
'
`---------------------------------------------------------`
#观察信息
{"took":473,"errors":false,"items"
`---------------------------------------------------------`
3.#查询数据
[18:43:41 root@elk1:~]#curl 10.0.0.92:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .geoip_databases HC7IMR4IQt2lzPHNQJLdTg 1 1 38 0 73.5mb 36.7mb
green open xiyouji k3WHbwpYQYuygDXQ8WWyIQ 1 1 4 0 10.4kb 5.2kb
#查看详细数据
[18:04:26 root@elk1:~]#apt -y install jq
[18:44:31 root@elk1:~]#curl -s http://10.0.0.91:9200/xiyouji/_search|jq
{
"took": 35, #整个搜索操作花费的时间(单位通常是毫秒)
"timed_out": false, #搜索是否超时
"_shards": { #索引分片的信息
"total": 1, #索引中的总分片数量
"successful": 1, #成功处理搜索请求的分片数量
"skipped": 0, #被跳过的分片数量
"failed": 0 #处理搜索请求失败的分片数量
},
"hits": { #搜索结果的命中信息
"total": {
"value": 4, #搜索结果的总数。
"relation": "eq" #表示总数的关系,这里 "eq" 可能表示精确匹配
},
"max_score": 1, #在当前搜索结果中最高的相关性得分。得分越高,说明文档与搜索条件的匹配程度越高。
"hits": [
{
"_index": "xiyouji",
"_type": "_doc",
"_id": "oGlGw5IBa8Bmw7JlXVC6",
"_score": 1,
"_source": {
"name": "孙悟空",
"hobby": [
"蟠桃",
"紫霞仙子",
"人参果"
]
}
},
{
"_index": "xiyouji",
"_type": "_doc",
"_id": "oWlGw5IBa8Bmw7JlXVC6",
"_score": 1,
"_source": {
"name": "猪八戒",
"hobby": [
"嫦娥",
"高小姐",
"蜘蛛精"
]
}
},
{
"_index": "xiyouji",
"_type": "_doc",
"_id": "omlGw5IBa8Bmw7JlXVC6",
"_score": 1,
"_source": {
"name": "沙和尚",
"hobby": [
"唐僧肉",
"挑行李"
]
}
},
{
"_index": "xiyouji",
"_type": "_doc",
"_id": "o2lGw5IBa8Bmw7JlXVC6",
"_score": 1,
"_source": {
"name": "唐三藏",
"hobby": [
"女儿国",
"人参果"
]
}
}
]
}
}
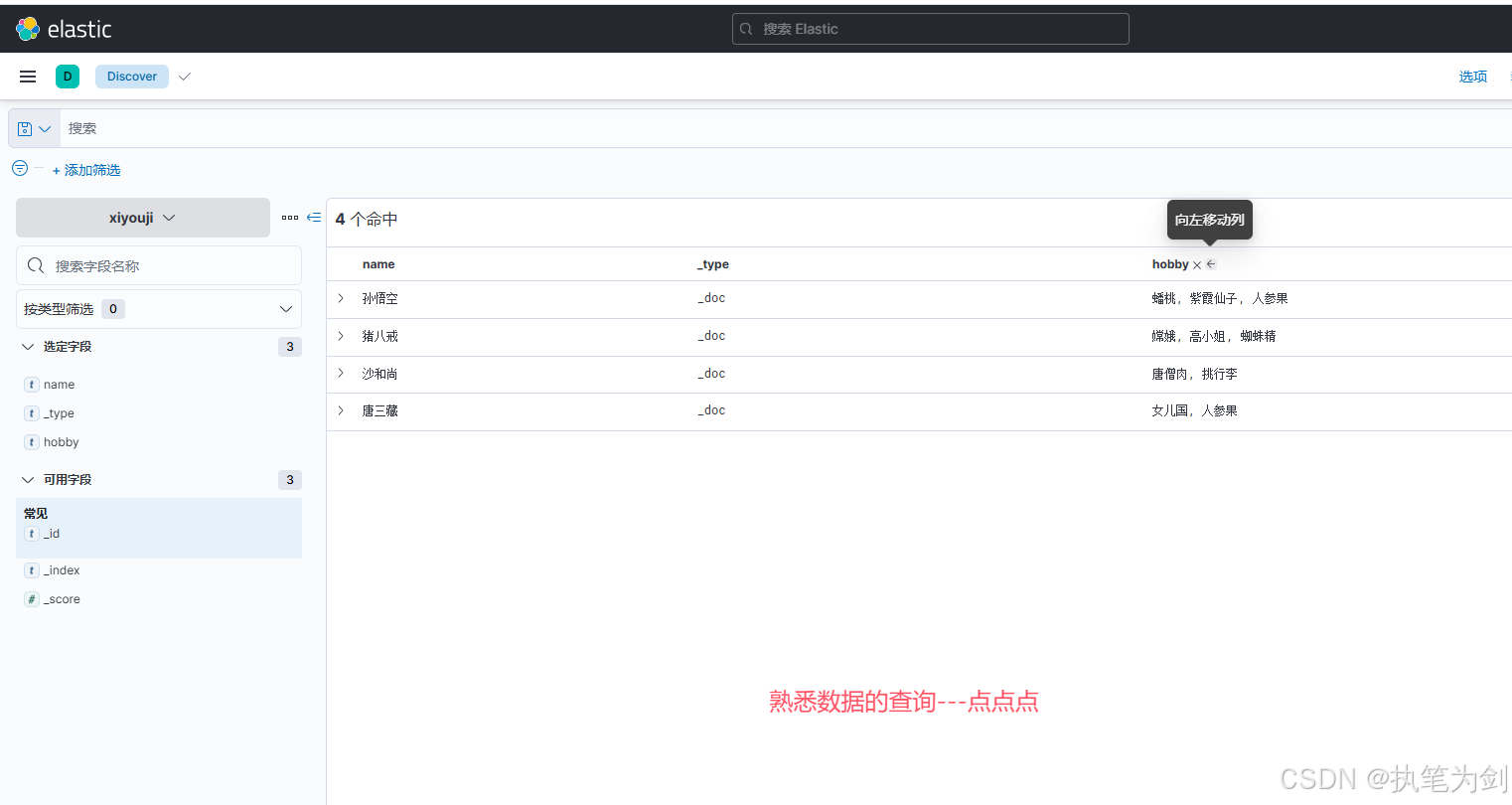
#查询指定数据(例如:查询爱好包含"人参果"的人物有哪些)
[18:52:13 root@elk1:~]# curl -s -X GET 'http://10.0.0.91:9200/xiyouji/_search' \
-H 'Content-Type: application/json' \
-d '{
"query": {
"match": {
"hobby": "人参果"
}
}
}' | jq
{
"took": 53,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.2372408,
"hits": [
{
"_index": "xiyouji",
"_type": "_doc",
"_id": "o2lGw5IBa8Bmw7JlXVC6",
"_score": 2.2372408,
"_source": {
"name": "唐三藏",
"hobby": [
"女儿国",
"人参果"
]
}
},
{
"_index": "xiyouji",
"_type": "_doc",
"_id": "oGlGw5IBa8Bmw7JlXVC6",
"_score": 1.8925586,
"_source": {
"name": "孙悟空",
"hobby": [
"蟠桃",
"紫霞仙子",
"人参果"
]
}
}
]
}
}Kibana-数据可视化
部署Kibana
bash
1.下载软件包到/usr/local下
[18:52:13 root@elk1:/usr/local]# wget http://192.168.13.253/Resources/ElasticStack/softwares/kibana-7.17.23-amd64.deb
2.安装Kibana
[18:55:54 root@elk1:/usr/local]#dpkg -i kibana-7.17.23-amd64.deb
3.修改Kibana配置文件
[18:59:10 root@elk1:~]#yy /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://10.0.0.91:9200","http://10.0.0.92:9200","http://10.0.0.93:9200"]
i18n.locale: "zh-CN"
4.启动Kibana
[18:59:20 root@elk1:~]#systemctl enable --now kibana.service
[18:59:42 root@elk1:~]#ss -ntl |grep 5601
LISTEN 0 511 0.0.0.0:5601 0.0.0.0:*
5.浏览器访问Kibana(WebUI)
http://10.0.0.91:5601/
基于Kibana查询数据
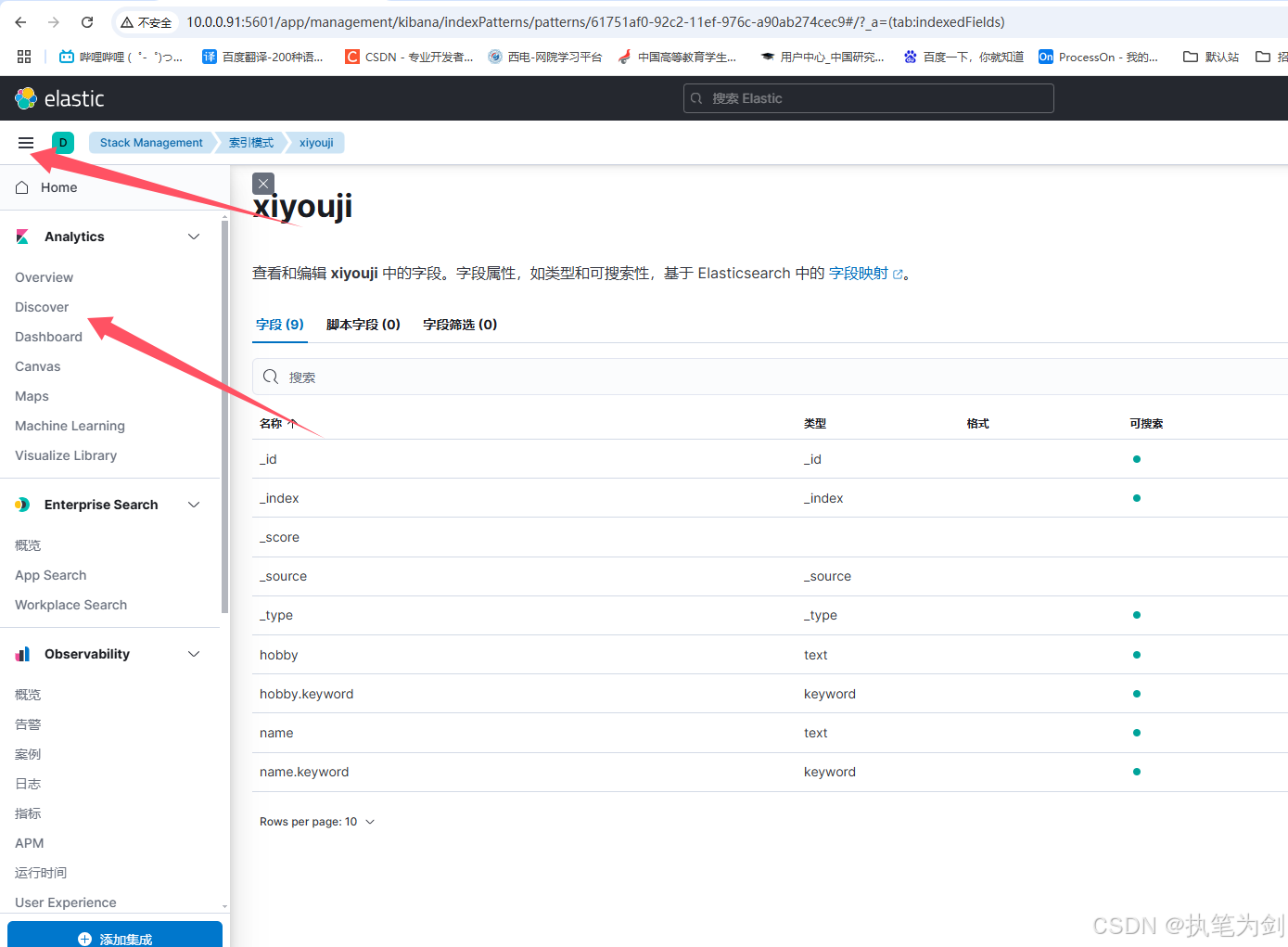
查看
索引模式:可以匹配多个索引。