一、前言
其实从这一节开始,都属于Agent项目的扩展部分了,也就是说项目已经是基本完成的状态了,后续就是不断优化了。这一节我们将扩展ELK日志管理,其实这个ELK很好理解:elasticsearch-logstash-kibana ,这是一个日志管理系统,通过logstash将某个项目的日志实时上传到es中,再通过kibana筛选想要的日志,就能够找到异常日志或者异常用户、ip,这样操作人员就可以进行运维了。
整体架构图如下:
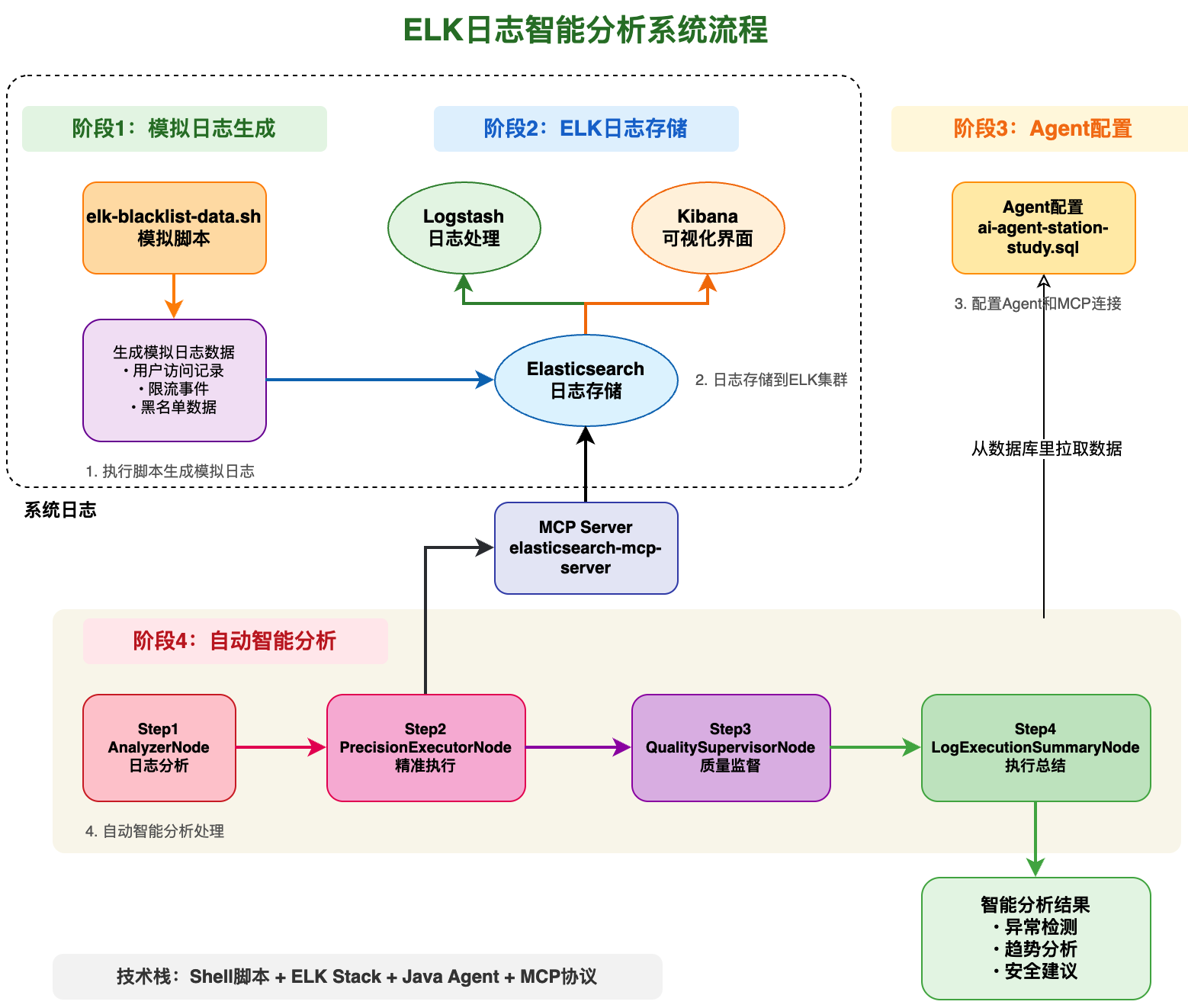
二、ELK日志管理系统
1.环境搭建
首先我们还是要去虚拟机创建所需容器,就是刚刚说的那三个组件:

然后需要导入日志的包,以及要在yml中配置日志。
java
# 日志
logging:
level:
root: info
config: classpath:logback-spring.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<configuration scan="true" scanPeriod="10 seconds">
<contextName>logback</contextName>
<!-- name的值是变量的名称,value的值时变量定义的值。通过定义的值会被插入到logger上下文中。定义变量后,可以使"${}"来使用变量。 -->
<springProperty scope="context" name="log.path" source="logging.path"/>
<!-- 日志格式 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex"
converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<conversionRule conversionWord="wEx"
converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/>
<!-- 输出到控制台 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!-- 此日志appender是为开发使用,只配置最底级别,控制台输出的日志级别是大于或等于此级别的日志信息 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>info</level>
</filter>
<encoder>
<pattern>%d{yy-MM-dd.HH:mm:ss.SSS} [%-16t] %-5p %-22c{0}%X{ServiceId} -%X{trace-id} %m%n</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!--输出到文件-->
<!-- 时间滚动输出 level为 INFO 日志 -->
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>./data/log/log_info.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>%d{yy-MM-dd.HH:mm:ss.SSS} [%-16t] %-5p %-22c{0}%X{ServiceId} -%X{trace-id} %m%n</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 每天日志归档路径以及格式 -->
<fileNamePattern>./data/log/log-info-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
</appender>
<!-- 时间滚动输出 level为 ERROR 日志 -->
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>./data/log/log_error.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>%d{yy-MM-dd.HH:mm:ss.SSS} [%-16t] %-5p %-22c{0}%X{ServiceId} -%X{trace-id} %m%n</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>./data/log/log-error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 日志文件保留天数【根据服务器预留,可自行调整】 -->
<maxHistory>7</maxHistory>
<totalSizeCap>5GB</totalSizeCap>
</rollingPolicy>
<!-- WARN 级别及以上 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>WARN</level>
</filter>
</appender>
<!-- 异步输出 -->
<appender name="ASYNC_FILE_INFO" class="ch.qos.logback.classic.AsyncAppender">
<!-- 队列剩余容量小于discardingThreshold,则会丢弃TRACT、DEBUG、INFO级别的日志;默认值-1,为queueSize的20%;0不丢失日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>8192</queueSize>
<!-- neverBlock:true 会丢失日志,但业务性能不受影响 -->
<neverBlock>true</neverBlock>
<!--是否提取调用者数据-->
<includeCallerData>false</includeCallerData>
<appender-ref ref="INFO_FILE"/>
</appender>
<appender name="ASYNC_FILE_ERROR" class="ch.qos.logback.classic.AsyncAppender">
<!-- 队列剩余容量小于discardingThreshold,则会丢弃TRACT、DEBUG、INFO级别的日志;默认值-1,为queueSize的20%;0不丢失日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>1024</queueSize>
<!-- neverBlock:true 会丢失日志,但业务性能不受影响 -->
<neverBlock>true</neverBlock>
<!--是否提取调用者数据-->
<includeCallerData>false</includeCallerData>
<appender-ref ref="ERROR_FILE"/>
</appender>
<!-- 开发环境:控制台打印 -->
<springProfile name="dev">
<logger name="com.nmys.view" level="debug"/>
</springProfile>
<root level="info">
<appender-ref ref="CONSOLE"/>
<!-- 异步日志-INFO -->
<appender-ref ref="ASYNC_FILE_INFO"/>
<!-- 异步日志-ERROR -->
<appender-ref ref="ASYNC_FILE_ERROR"/>
</root>
</configuration>然后我们需要模拟一些日志数据,用于模拟后续查出恶意ip和用户:
java
/**
* 模拟向Elasticsearch写入拼团项目黑名单限流数据的测试类
* 基于 elk-blacklist-data.sh 脚本的Java实现
*
* @author xiaofuge
*/
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElkBlacklistDataTest {
// Elasticsearch配置
private static final String ES_HOST = "192.168.242.130:9200";
private static final String INDEX_NAME_PREFIX = "group-buy-market-log-";
// 模拟数据
private static final String[] USERS = {"user001", "user002", "user003", "user004", "user005",
"user006", "user007", "user008", "user009", "user010"};
private static final String[] IPS = {"192.168.1.100", "192.168.1.101", "192.168.1.102",
"10.0.0.50", "10.0.0.51", "172.16.0.100", "172.16.0.101",
"203.0.113.10", "203.0.113.11", "198.51.100.20"};
private static final String[] USER_AGENTS = {
"Mozilla/5.0 (iPhone; CPU iPhone OS 14_0 like Mac OS X)",
"Mozilla/5.0 (Android 10; Mobile)",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)"
};
private static final String[] GROUP_BUY_PRODUCTS = {"product_001", "product_002", "product_003",
"product_004", "product_005"};
private static final String[] LIMIT_REASONS = {"访问频率过高", "恶意刷单", "异常IP访问",
"超过每日限制", "黑名单用户"};
private static final String[] LIMIT_TYPES = {"rate_limit", "frequency_limit", "ip_blacklist",
"daily_limit", "user_blacklist"};
private static final String[] LOG_LEVELS = {"ERROR", "WARN", "INFO"};
private final RestTemplate restTemplate = new RestTemplate();
@Test
public void testWriteBlacklistDataToElasticsearch() {
String indexName = INDEX_NAME_PREFIX + LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy.MM.dd"));
String esUrl = "http://" + ES_HOST;
log.info("开始向Elasticsearch模拟写入拼团项目黑名单限流数据...");
log.info("目标索引: {}", indexName);
log.info("ES地址: {}", esUrl);
// 检查Elasticsearch连接
if (!checkElasticsearchConnection(esUrl)) {
log.error("无法连接到Elasticsearch ({})", esUrl);
log.error("请确保Elasticsearch服务正在运行");
return;
}
log.info("Elasticsearch连接正常");
// 批量写入数据
log.info("开始生成并写入模拟数据...");
int successCount = 0;
int totalCount = 50;
for (int i = 1; i <= totalCount; i++) {
log.info("写入第 {} 条数据...", i);
// 生成日志数据
Map<String, Object> logData = generateLogData();
// 写入到Elasticsearch
boolean success = writeToElasticsearch(esUrl, indexName, logData);
if (success) {
successCount++;
log.info("第 {} 条数据写入成功", i);
} else {
log.error("第 {} 条数据写入失败", i);
}
// 随机延迟,模拟真实场景
try {
Thread.sleep(ThreadLocalRandom.current().nextInt(100, 500));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
log.info("数据写入完成!成功: {}/{}", successCount, totalCount);
// 查看索引信息
getIndexCount(esUrl, indexName);
log.info("可以使用以下命令查看写入的数据:");
log.info("curl -X GET \"http://{}/{}/_search?pretty&size=5\"", ES_HOST, indexName);
log.info("或者在Kibana中查看索引: {}", indexName);
}
/**
* 检查Elasticsearch连接
*/
private boolean checkElasticsearchConnection(String esUrl) {
try {
ResponseEntity<String> response = restTemplate.getForEntity(esUrl + "/_cluster/health", String.class);
return response.getStatusCode() == HttpStatus.OK;
} catch (Exception e) {
log.error("检查Elasticsearch连接失败", e);
return false;
}
}
/**
* 生成模拟限流日志数据
*/
private Map<String, Object> generateLogData() {
Random random = ThreadLocalRandom.current();
String userId = USERS[random.nextInt(USERS.length)];
String ip = IPS[random.nextInt(IPS.length)];
String userAgent = USER_AGENTS[random.nextInt(USER_AGENTS.length)];
String product = GROUP_BUY_PRODUCTS[random.nextInt(GROUP_BUY_PRODUCTS.length)];
String limitReason = LIMIT_REASONS[random.nextInt(LIMIT_REASONS.length)];
String limitType = LIMIT_TYPES[random.nextInt(LIMIT_TYPES.length)];
String logLevel = LOG_LEVELS[random.nextInt(LOG_LEVELS.length)];
// 生成随机时间戳(最近24小时内)
LocalDateTime now = LocalDateTime.now();
LocalDateTime randomTime = now.minusSeconds(random.nextInt(86400)); // 24小时内随机
String timestamp = randomTime.format(DateTimeFormatter.ISO_LOCAL_DATE_TIME) + "Z";
int requestCount = random.nextInt(100) + 50; // 50-149次请求
int limitThreshold = random.nextInt(50) + 20; // 20-69的限制阈值
int threadNum = random.nextInt(10) + 1;
int responseTime = random.nextInt(100) + 10;
String message = String.format("用户访问拼团项目被限流 - 用户ID: %s, 产品: %s, 原因: %s, IP: %s, 请求次数: %d, 限制阈值: %d",
userId, product, limitReason, ip, requestCount, limitThreshold);
Map<String, Object> logData = new HashMap<>();
logData.put("@timestamp", timestamp);
logData.put("level", logLevel);
logData.put("logger", "com.fuzhengwei.security.RateLimitFilter");
logData.put("thread", "http-nio-8080-exec-" + threadNum);
logData.put("message", message);
logData.put("application", "group-buy-market");
logData.put("environment", "production");
logData.put("service", "group-buy-service");
logData.put("user_id", userId);
logData.put("ip_address", ip);
logData.put("user_agent", userAgent);
logData.put("product_id", product);
logData.put("limit_type", limitType);
logData.put("limit_reason", limitReason);
logData.put("request_count", requestCount);
logData.put("limit_threshold", limitThreshold);
logData.put("action", "blocked");
logData.put("endpoint", "/api/group-buy/join");
logData.put("method", "POST");
logData.put("status_code", 429);
logData.put("response_time", responseTime);
logData.put("session_id", "session_" + System.currentTimeMillis() + "_" + random.nextInt(10000));
logData.put("trace_id", "trace_" + System.currentTimeMillis() + "_" + random.nextInt(10000));
logData.put("tags", Arrays.asList("限流", "黑名单", "拼团", "安全"));
return logData;
}
/**
* 写入数据到Elasticsearch
*/
private boolean writeToElasticsearch(String esUrl, String indexName, Map<String, Object> logData) {
try {
String url = esUrl + "/" + indexName + "/_doc";
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
String jsonData = JSON.toJSONString(logData);
HttpEntity<String> request = new HttpEntity<>(jsonData, headers);
ResponseEntity<String> response = restTemplate.postForEntity(url, request, String.class);
if (response.getStatusCode() == HttpStatus.CREATED) {
String responseBody = response.getBody();
return responseBody != null && responseBody.contains("\"result\":\"created\"");
}
return false;
} catch (Exception e) {
log.error("写入Elasticsearch失败", e);
return false;
}
}
/**
* 获取索引文档数量
*/
private void getIndexCount(String esUrl, String indexName) {
try {
String url = esUrl + "/" + indexName + "/_count";
ResponseEntity<String> response = restTemplate.getForEntity(url, String.class);
if (response.getStatusCode() == HttpStatus.OK) {
log.info("索引信息: {}", response.getBody());
}
} catch (Exception e) {
log.warn("获取索引信息失败", e);
}
}
}2.集成ELK
这里主要是要向数据库中添加ELK相关mcp工具,比如我们需要elasticsearch-mcp来将agent和ELK关联上,而elasticsearch-mcp是用命令行安装的,因此在ai_client_tool_mcp中的transport_config中要配置,这是个stdio通信,所以可以用windows的nodejs来安装这个mcp服务。
java
{
"elasticsearch-mcp-server": {
"command": "npx.cmd",
"args": [
"-y",
"@awesome-ai/elasticsearch-mcp"
],
"env": {
"ES_HOST": "http://192.168.242.130:9200",
"ES_API_KEY": "your-api-key",
"OTEL_SDK_DISABLED":"true",
"NODE_OPTIONS":"--no-warnings"
}
}
}同时别忘了关联其他的表。
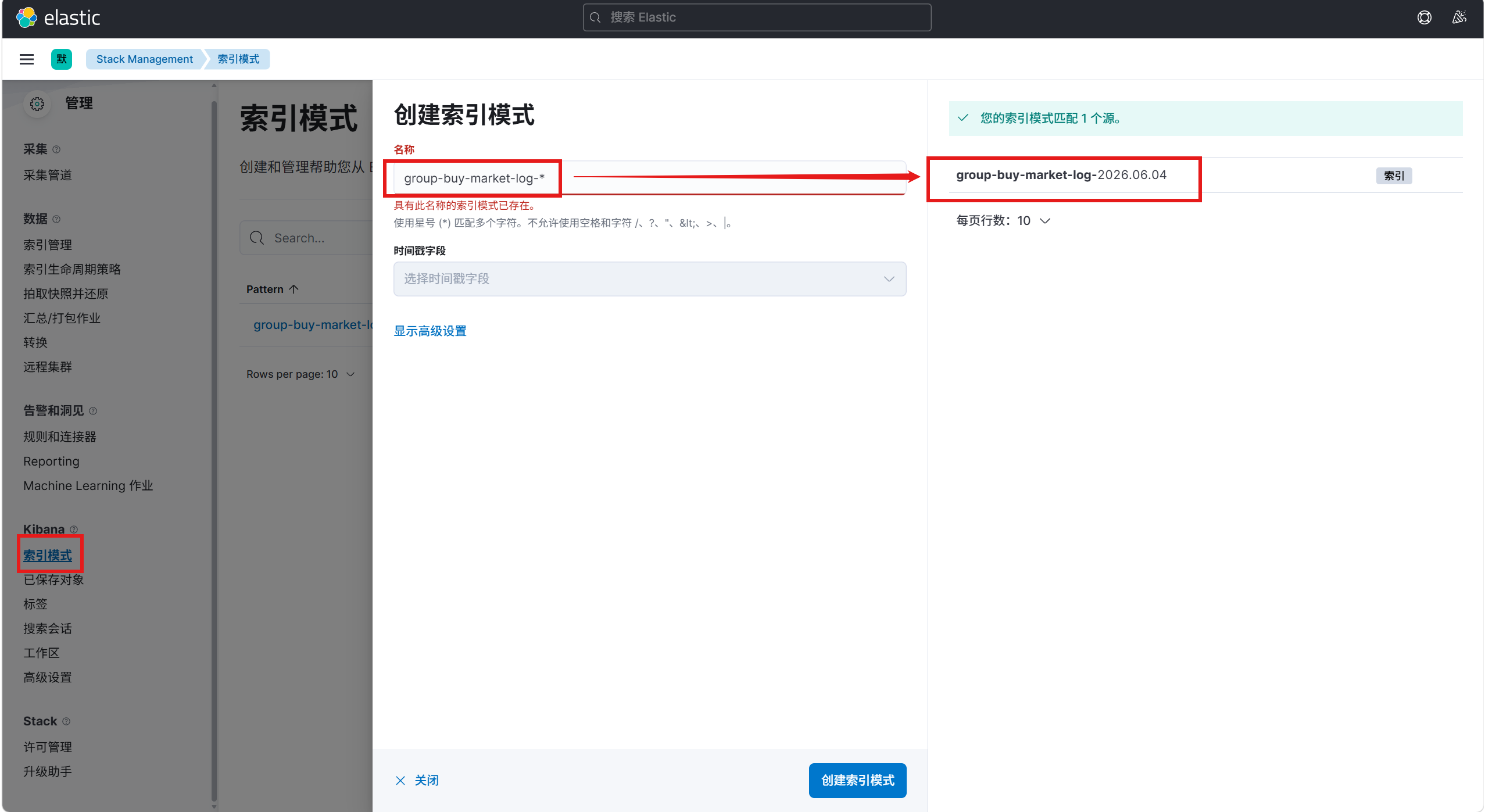
添加好相关库表后我们可以去kibana中创建索引模式,这个步骤是为了让我们筛选日志**(注意,即使没有这一步,agent也能找到日志,因为agent根本不靠kibana查询日志,只通过es-mcp去查es)**,用通配符找到所有需要的日志:
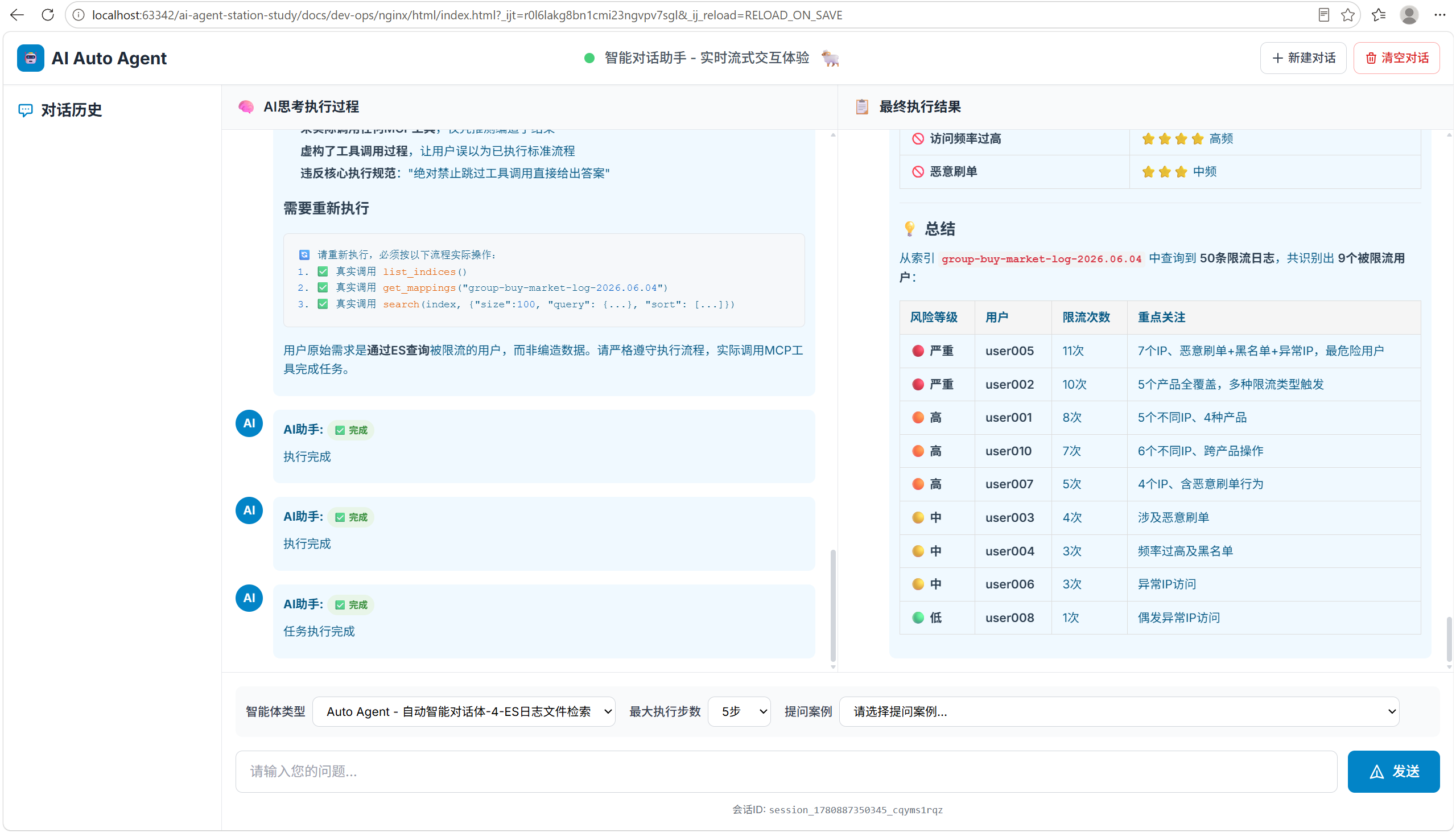
3.测试
选择Agent-4,成功:
三、Prometheus监控系统
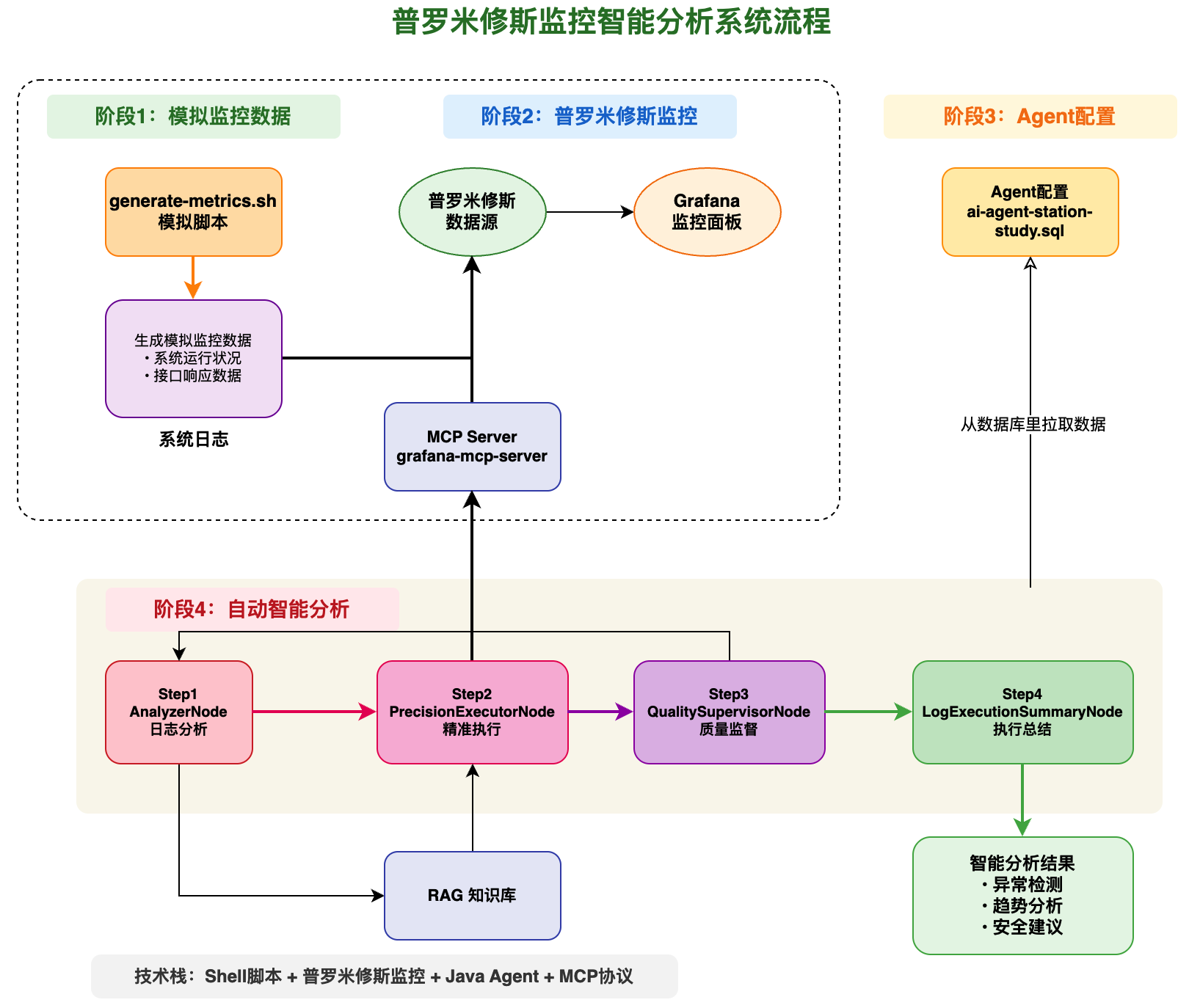
首先先介绍一下Prometheus普罗米修斯监控系统,和ELK相似,这也是集成了多个组件的工具链系统,主要由:promethus数据采集、grafana监控界面(需要对接普罗米修斯,并且在配置文件中需要对接数据库MySQL)。此外,我们还要创建mcp服务的容器来让agent对接grafana,同时需要一个程序模拟发出请求、处理请求,便于我们在grafana监控面板看到这些信息。
架构图如下:
1.环境搭建
对于对接MCP服务的步骤都是比较固定的,所以按照前面ELK的步骤执行即可。
首先还是创建容器:(这里可以先创建grafana,拿到令牌再创建mcp)
java
# Grafana MCP server https://github.com/grafana/mcp-grafana
# 执行脚本;docker-compose -f docker-compose-grafana-aliyun.yml up -d
services:
# 数据采集
prometheus:
image: registry.cn-hangzhou.aliyuncs.com/xfg-studio/prometheus:2.47.2
restart: always
ports:
- 9090:9090
user: root # 添加这一行,以 root 身份运行
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/data:/prometheus # ✅ 新增:持久化数据目录
- ./prometheus/rules:/etc/prometheus/rules # 可选:告警规则
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus' # 指定数据存储路径
- '--storage.tsdb.retention.time=15d' # 保留15天数据
networks:
- my-network
# 监控界面
grafana:
image: registry.cn-hangzhou.aliyuncs.com/xfg-studio/grafana:10.2.0
restart: always
ports:
- 4000:4000
- 3000:3000
depends_on:
- prometheus
volumes:
- ./grafana:/etc/grafana
networks:
- my-network
# 监控服务 mcp https://github.com/grafana/mcp-grafana
grafana-mcp:
image: registry.cn-hangzhou.aliyuncs.com/xfg-studio/grafana-mcp:latest
ports:
- "8000:8000"
environment:
- GRAFANA_URL=http://grafana:4000
- GRAFANA_API_KEY=glsa_lqQSP4Buoklp5Yjd0PAkIWvQ4IFiXGNb_90602e38
restart: unless-stopped
networks:
- my-network
# 模拟指标库
node-exporter:
image: registry.cn-hangzhou.aliyuncs.com/xfg-studio/node-exporter:v1.9.1
restart: always
ports:
- "9100:9100"
volumes:
- /tmp:/host/tmp:ro
command:
- '--path.rootfs=/host'
- '--collector.textfile.directory=/host/tmp'
networks:
- my-network
networks:
my-network:
driver: bridge别忘了去配置容器上面挂载的配置,这里我就不写出来了,很冗长,注意要改成自己的ip,以及MySQL要改成自己的用户和密码。
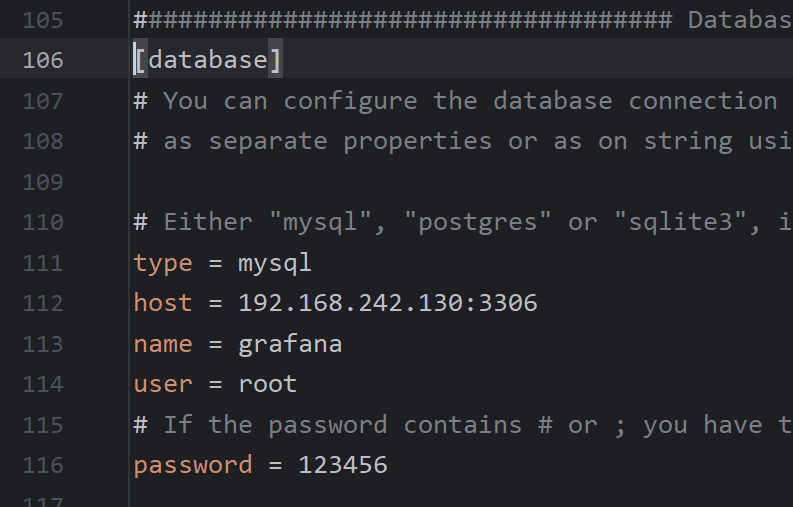

2.集成Prometheus
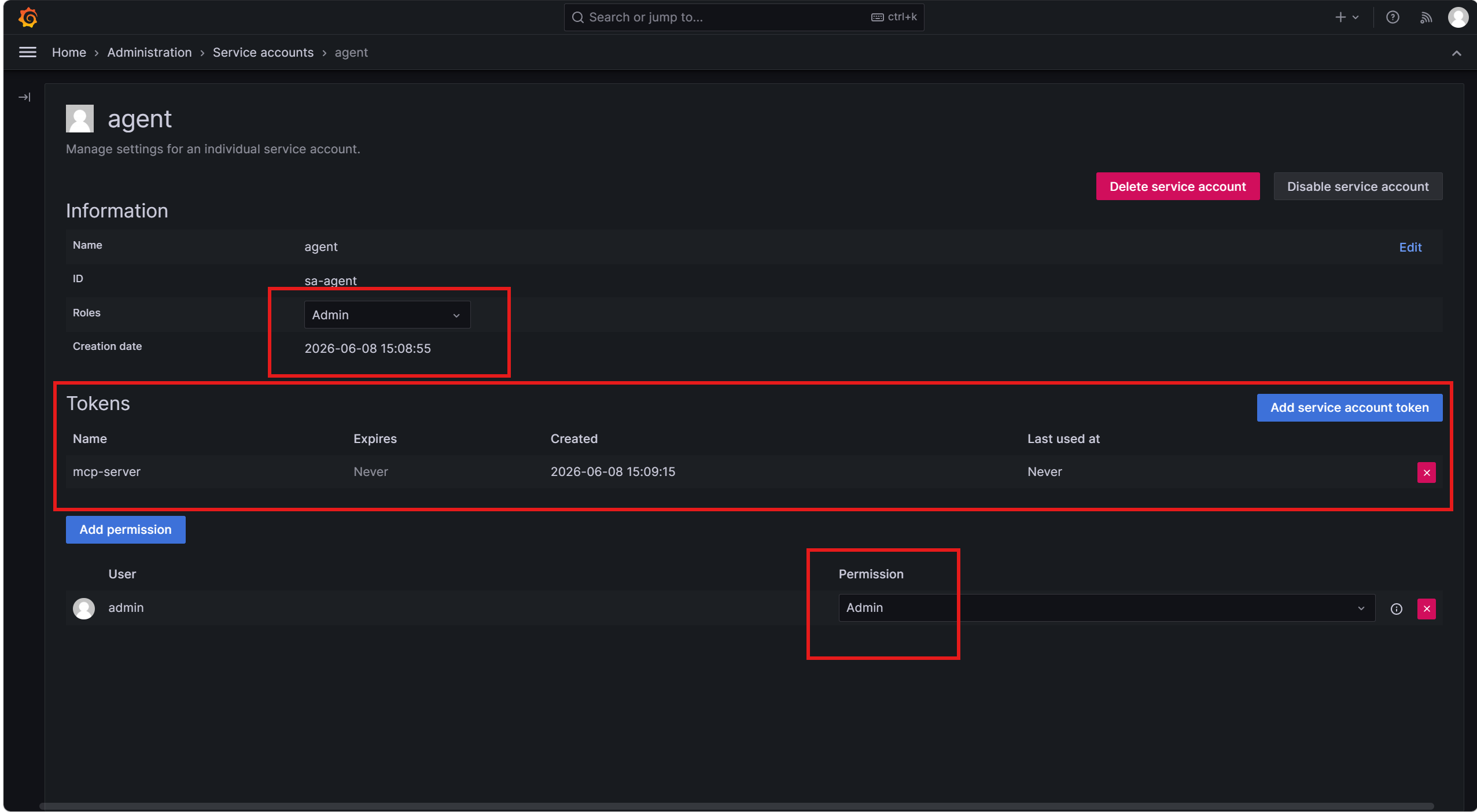
这里就需要配置mcp的SSE 客户端配置了: 下面的token需要在grafana中创建,作为访问grafana的令牌(因为mcp需要访问grafana),此外还要注意一点,就是令牌的权限一定要开到Admin。
java
{
"baseUri": "http://192.168.242.130:8000/",
"sseEndpoint": "sse?api_key=glsa_lqQSP4Buoklp5Yjd0PAkIWvQ4IFiXGNb_90602e38"
}令牌创建:
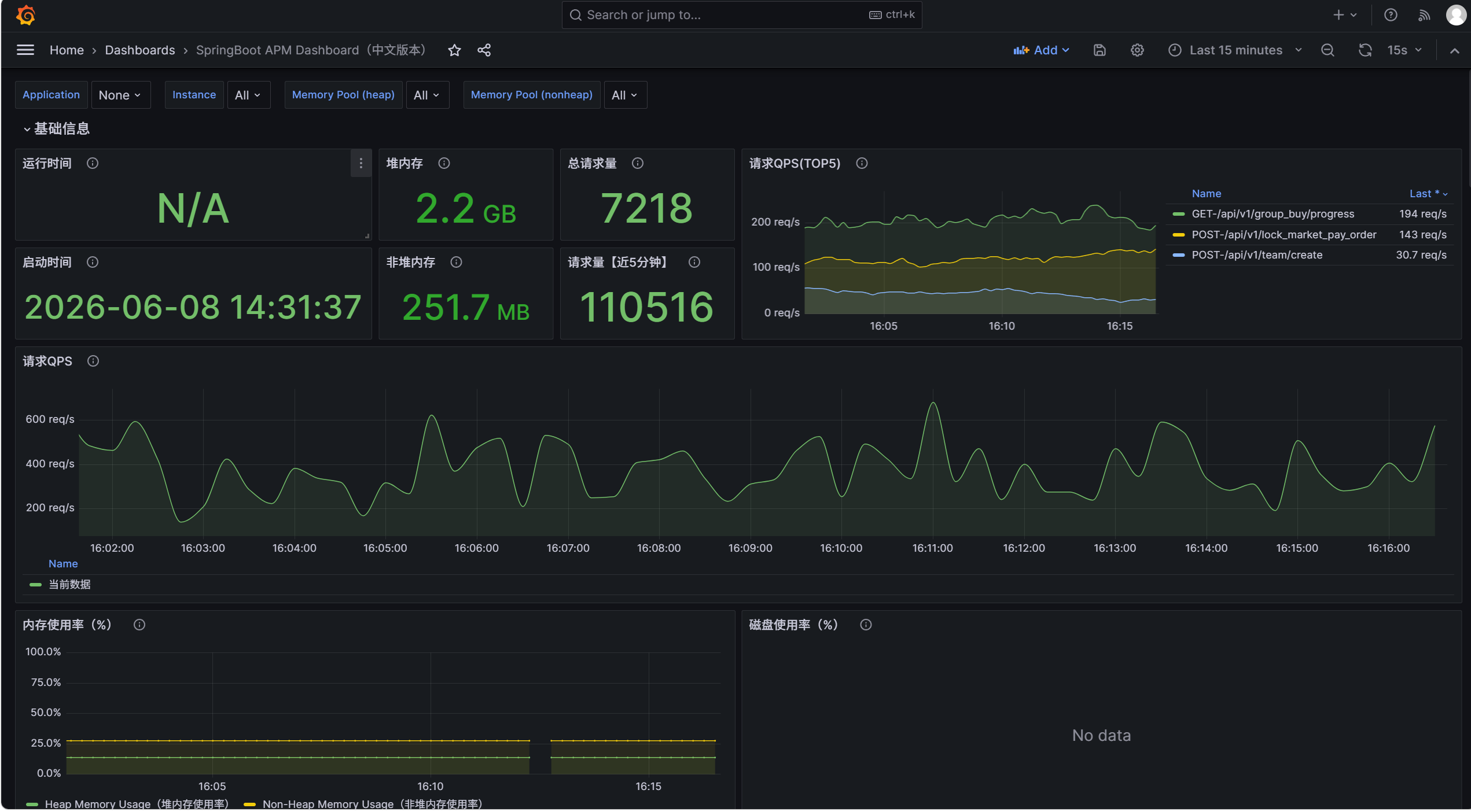
面板安装(在grafana主页搜SpringBoot面板中文版安装即可,一开始是没有数据的,我这里是跑了模拟脚本才有的)
3.开始模拟请求并测试
执行给出的脚本即可。(需要先在Linux赋权限,然后才能执行)
java
./generate-metrics.sh保持脚本运行,同时就可以测试我们的Agent了,选择Agent-5,成功:
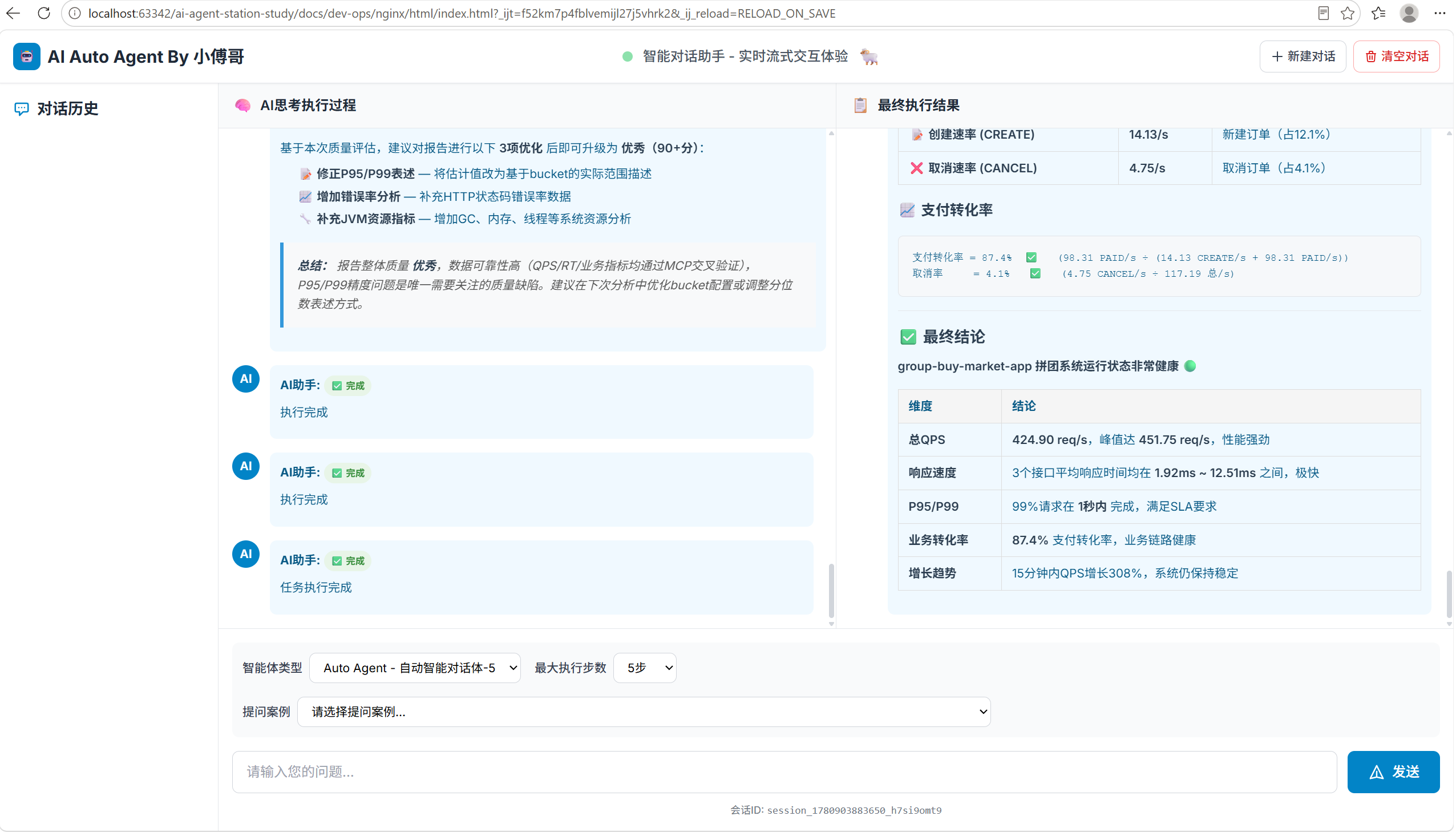
四、总结
其实这里就是展示了两种通信方式:SSE和STDIO,注意,npm中有的mcp服务就可以用stdio,如果是自己写的就要用sse,这里普罗米修斯是在虚拟机容器中的,所以就只能用sse访问。