文章目录
-
-
- [1. SQL 分类](#1. SQL 分类)
- [2. 数据库操作](#2. 数据库操作)
- [3. 数据表操作](#3. 数据表操作)
- [4. 增删改操作](#4. 增删改操作)
- [5. 查询操作](#5. 查询操作)
- [6. 用户管理](#6. 用户管理)
- [7. 权限控制](#7. 权限控制)
-
1. SQL 分类

2. 数据库操作
sql
#创建数据库
create database if not exists test;
#查询所有数据库
show databases;
#查询当前数据库
select database();
#删除数据库
drop database if exist test;
#使用数据库
use test;3. 数据表操作
sql
#创建表
create table db_user (
id int comment '编号',
name varchar(50) comment '姓名',
gender char(1) comment '性别'
) comment '用户表注释';
#查询当前数据库的所有表
show tables;
#查询表结构
desc db_user;
#查询指定表的建表语句
show create table db_user;
#修改数据类型
alter table db_user modify id char(10);
#修改字段名和数据类型
alter table db_user change name age int comment '年龄';
#删除字段
alter table db_user drop id;
#修改表名
alter table db_user rename to new_user;
#删除表
drop table db_user;
#删除表,并重新创建该表
truncate table db_user;char 和 varchar 都属于字符串的数据类型,char 长度固定,效率高,varchar 长度可伸缩,但效率低,对于长度固定的字符串(如性别),我们可直接选择 char 来存储。
在删除表时,表中的全部数据也会被删除!
4. 增删改操作
sql
#给指定字段添加数据
insert into db_user(id, name) values(2, 'zxe');
#给全部字段添加数据
insert into db_user values(2, 'zxe', '女');
#批量添加数据
insert into db_user(id, name) values(2, 'zxe'), (3, 'ldh');
#全部字段批量添加数据
insert into db_user values(2, 'zxe', '女'), (3, 'ldh', '男');
#修改数据
update db_user set name = 'zyz', gender = '女' where id = 3;
#删除数据
delete from db_user where id = 2;注意:
① 插入数据时,指定的字段顺序需要与值的顺序一一对应;
② 字符串和日期型数据应包含在引导中;
③ 插入的数据大小应在字段的规定范围内。
5. 查询操作
sql
#查询多个字段
select id, name from db_user;
#查询全部字段
select * from db_user;
#根据条件查询数据,顺序不可颠倒
select * from db_user
where gender = '女'
group by address
having count(*) >= 3
order by id desc
limit 10, 10;
#设置别名,as可以省略
select id as uId, name as uName from db_user;
select d.id, d.name from db_user d;
#去除重复记录
select distinct * from db_user;① 条件查询,where


② 聚合函数,count、max、min、avg、sum

null 是不参与聚合函数的计算的!
③ 分组查询,group by
sql
#根据性别分组,统计男女的数量
select gender, count(*) emp_count from emp
group by gender;
#查询年龄小于45的员工,并根据工作地址进行分组,获取员工数量大于等于3的工作地址
select address, count(*) emp_count from emp
where age < 45
group by address
having count(*) >= 3;where 与 having 的区别:
执行时机不同,where 是分组之前进行过滤,不满足 where 条件的数据将不参与分组,而 having 是对分组之后的结果进行过滤;
判断条件不同,where 不能对聚合函数进行判断,而 having 可以。
执行顺序 where > 聚合函数 > having,分组是为了统计,所以查询的结果一般为分组字段和聚合函数(统计结果),查询其他字段无任何意义。
④ 排序查询,order by
sql
#asc升序排序,desc降序排序,默认为升序
select * from emp order by id asc, age desc;如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序!
⑤ 分页查询,limit
sql
#查询第2页数据,每页展示10条记录
select * from emp limit 10, 10;
#查询第一页数据,每页展示10条记录
select * from emp limit 0, 10;
#查询性别为男,姓名为三个字,且年龄在20~40岁以内的前5个员工信息,对查询的结果按年龄升序排序,年龄相同的按入职时间升序排序
select * from emp
where gender = '男' and name like '___' and age between 20 and 40
order by age, entrydata
limit 5; 第一个参数为起始索引,第二个参数为要查询的记录数,起始索引最小为 0,如果查询的是第一页数据,起始索引可以省略。
6. 用户管理
sql
#查询用户
use mysql;
select * from user;
#创建用户
create user '用户名'@'主机名' identified by '密码';
#修改用户密码
alter user '用户名'@'主机名' identified with mysql_native_password by '新密码';
#删除用户
drop user 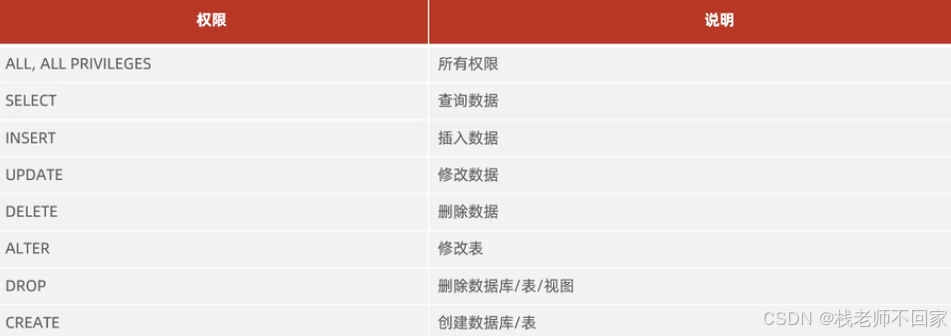
; 7. 权限控制

sql
#查询权限
show grants for '用户名'@'主机名';
#授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
#撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';注意:
① 多个权限之间,使用逗号分隔;
② 授权时,数据库名和表名可以使用 * 进行通配,代表所有。