一、Kafka集群的概念
1、目的
高并发、高可用、动态扩展。
主备数据架构、双活节点、灾备数据中心。
如果是服务的地理范围过大也可以使不同的集群节点服务不同的区域,降低网络延迟。
2、Kafka集群的基本概念
1)复制(镜像)
kafka的分区数据支持复制操作。
2)天生的集群功能
搭建集群的能力使Kafka在消息中间件市场上有很强的竞争力。
Kafka天生支持分布式、集群、动态扩容。
RocketMQ和Kafka比较相似,在Kafka的功能基础上做了一些增强。
二、搭建Kafka集群
1、修改配置文件参数
配置文件名称:config/server.properties
broker.id=0
kafka broker 在集群中的唯一标识,每一个broker节点的id都不同。
由于所有kafka节点都注册到了相同的ZooKeeper集群中,所以需要一个唯一标识做区分。
listeners=PLAINTEXT://127.0.0.1:9092配置为本机的IP地址
zookeeper.connect=127.0.0.1:2181配置ZooKeeper的连接地址,所有kafka节点都配置相同的ZooKeeper集群。
如果ZooKeeper有多个节点,那么就需要配置多个ZooKeeper地址。
2、启动ZooKeeper
启动一台kafka自带的ZooKeeper。
nohup ./zookeeper-server-start.sh ../config/zookeeper.properties -> zk.log &3、启动Kafka
nohup ./kafka-server-start.sh ../config/server.properties -> kafka.log & 4、集群的结构

三、Kafka集群的特点
1、集群创建主题
./kafka-topics.sh --bootstrap-server 127.0.0.1:9020 --create --topic allwe_1 --partitions 2 --replication-factor 2./kafka-topics.sh // 创建主题脚本
--bootstrap-server 127.0.0.1:9020 // 指定连接的Kafka节点,实际上连接的是集群
--create --topic allwe_1 // 指定要创建的主题名称
--partitions 2 // 指定分区数,这里是2个分区
--replication-factor 2 // 指定复制因子,表示每个分区复制几份,一般有几台kafka节点就设置为几,如果超过就会让相同的分区分布在同一台kafka节点上,没什么实际作用。
2、集群创建的主题结构

可以看到,在每一个kafka节点中,保存的数据都是一样的,在相同主题中,每一个分区都有几个备份(复制体),并且是一主多从的结构。
但是,每一个分区的首领副本分布的位置却不同,有的在broker 1上,有的在broker 2上,这是因为kafka自动将分区的首领副本做了离散操作,避免一台kafka掉线影响过大。
3、控制器

控制器的本质:
在启动kafka集群的时候,会选择一个控制器,本质就是一个broker节点。
在集群中所有broker指向的控制器是同一个,可以看到图片里选择的控制器就是broker.id=0。
控制器的作用:1、被选择为控制器的broker不但需要做broker的工作,还要做【首领副本】的选举工作。
4、首领副本(Leader)
首领副本的本质:
首领的本质是一个数据副本。
在集群中创建主题的时候,针对一个主题的不同分区,会选举一个首领副本,每个分区只有一个首领副本。
相同主题不同分区的首领副本一般会岔开分布到不同的broker,这样就能维持高可用。
客户端在生产、消费消息的时候,只会和首领副本交互,跟随者副本仅仅是复制首领副本的数据。这一点类似Redis的主从架构。
5、跟随者副本(Follower)
跟随者副本的数量被参数--replication-factor(复制因子)决定,replication-factor减去 1 (首领副本的数量)就是跟随者副本的数量。
跟随者副本不会与客户端做交互,只是额外保存了一份首领副本的数据。如果首领副本所在的broker掉线,跟随者副本才有可能会转正为首领副本与外界交互。
6、查询Topic的详细信息
bash
./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe
主题信息
Topic:laoli // 主题名称
TopicId: // 主题ID
PartitionCount:2 // 主题分区数
RepliocationFactor:2 // 主题复制因子 - 每一个分区复制的份数
分区信息Topic:laoli // 所属主题名称
Partition:0 // 分区序号
Leader:0 // 此分区的Leader副本存储在哪个broker上,这里的broker_id=0
Replicas:0,1 // 分区副本保存在哪些broker上
Isr:0,1 //
如果一个kafka集群有2个broker,创建一个3分区的主题,复制因子为1,那么主题的分区副本如何分布?
由于每一个分区只有一个Leader副本,那么就要看这三个Lader副本分别分布在哪个Broker上。
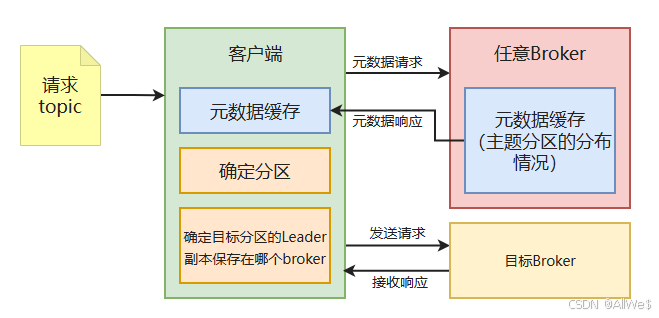
四、Kafka集群处理请求的内部机制
1、连接kafka集群中的哪一台?
在kafka客户端中,连接任意一台kafka服务器都可以实现消息的发送、消费。
比如生产者连接的是服务器A,消费者连接的是服务器B,也是可以正常工作的。
2、消息生产的ACKS
1)生产者角度
发送确认的ACK机制,用来表示发出去一条消息后,生产者需要接收到多少条发送成功的确认回复才认为发送成功。
ACKS = 0:默认配置下,生产者发送消息的ACKS数量为0,表示只要发送出去了,就认为发送成功了。
ACKS = 3:表示需要有最少三个分区副本收到该消息,且返回了成功的回复后,才认为发送成功了。
ACKS = all / -1:表示需要所有的分区副本都回复成功。(数量=min.insync.replicas参数配置的数值,默认=3)
2)消费者角度
站在消费者的角度,只有生产者消息确认数达到ACKS,消费者才能接收这条消息。
如果追求性能:min.insync.replicas = 1。leader同步成功了就返回成功。但是如果leader宕机必然会丢失数据。
如果追求数据安全:min.insync.replicas = 副本数。如果出现任意一台broker掉线,那么发送消息返回失败。
如果追求均衡:min.insync.replicas = 中间数。实际上broker掉线是一个小概率事件,多台broker掉线的概率更小,所以没必要配置很大的ACKS。
Kafka以权衡的方式配置ACKS的数值。数值越大,消息丢失概率小,消费者接收数据越慢。
数值越小,消息丢失概率大,消费者接收数据越快。
3)消费者客户端的重要参数
group.id :消费者所加入的消费者群组id。
auto.offset.reset:首次消费的偏移量,earliest-最早的偏移量,latest-最近的偏移量。
enable.auto.commit:true-自动提交(默认),false-手动提交(.commitAsync()-异步提交不重试;.commitSync()-同步提交一直重试)。
auto.commit.interval.ms:自动提交的间隔时间,默认5000ms。
3、消息获取的ISR
五、Kafka的存储机制
kafka的最小存储单元是"分区"。