准备工作
- 下载秋叶炼丹器
- 整理自己的照片
- 下载底膜 https://rentry.org/lycoris-experiments

实操步骤
- 解压整合包 lora-scripts,先点击"更新"
- 训练图片收集
比如要训练一个自己头像的模型,就可以拍一些自己的照片(20-50张,最少15张),要求画质清晰,脸部轮廓清楚,背景较为简单的照片。
建议整理成512*512大小 , 推荐工具

- 使用WD1,4 标签器的预处理功能进行图片的预处理
将准备好的图片,放入目录 train/XXX自定义/ 数值, 图片数量_XXX自定义

这里可以根据自己的情况设置不同的宽高,以及相关的设置项,设置完成之后,点击"预处理"就可以进行图像的预处理了,预处理进度会在右侧显示。处理完成之后的文件夹内文件统一转成了512*512的png格式,并且多了一个txt文件,这个文件里面就是图片内容的提示词。
- 点击启动, 对照片打标签

执行完毕后, 照片文件夹会自动生成txt文件

- 使用lora训练-新手模式


lora-scripts环境搭建
若新手从零开始, 请参考本专栏基础知识, 此处简略说明下安装环境
-
先将lora-scripts项目(
GitHub - Akegarasu/lora-scripts: LoRA training scripts use kohya-ss's trainer, for diffusion model.
https://github.com/Akegarasu/lora-scripts
)克隆到本地,可以放在stable-diffusion下面,也可以放在其他目录下面。
-
克隆完之后,进入该目录删除sd-scripts文件夹,然后克隆sd-scripts项目(
GitHub - kohya-ss/sd-scripts
https://github.com/kohya-ss/sd-scripts
)到该目录下。
-
安装环境,有两种方式。一种是在lora-scripts下直接执行./install.ps1命令,自动安装相关环境。另外一种是进入到lora-scripts/sd-scripts中,使用以下命令进行安装(可以参考该项目下的说明文档)。
创建并激活虚拟环境
python -m venv venv
.\venv\Scripts\activate安装cuda
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
安装相关包,可以加上 -i 国内源 快一点儿!
pip install --upgrade -r requirements.txt
安装xformers,这里可以先用下载工具把文件下载下来,用本地路径安装,不然网络不稳定很容易中断
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
复制相关文件到虚拟环境
cp .\bitsandbytes_windows*.dll .\venv\Lib\site-packages\bitsandbytes
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py加速器配置
accelerate config
这里要注意的是,cuda和xformers的版本这里是对应好的,如果版本不对会报错。另外,后面的相关操作都是在venv的虚拟环境下操作的,所以如果重新进入的话,需要重新激活虚拟环境。
accelerate config这个命令进入之后,对于多项选择的可以用上下键,或者使用(0,1,2...)去选择相关的选项,yes or no的直接输入然后回车,大部分配置项选择默认就可以了,我这里没有使用DeepSpeed,所以这一项,我选择的No,根据自己的实际情况去选就行了,不知道啥意思的可以挨个查下。
- 准备训练
训练有两种方式,方式一:直接执行训练命令(执行 ./train.ps1),方式二:使用webui的方式(执行 ./run_gui.ps1 打开web页面)。
(1)将预处理过的图片目录(qige)拷贝到lora-scripts/train/qg_imgs目录下(train目录不存在可以新建一个,这里要注意,图片和文本存放的最终目录是lora-scripts/train/qg_imgs/qige)
(2)修改配置。
方式一,直接修改train.ps1文件,修改以下配置
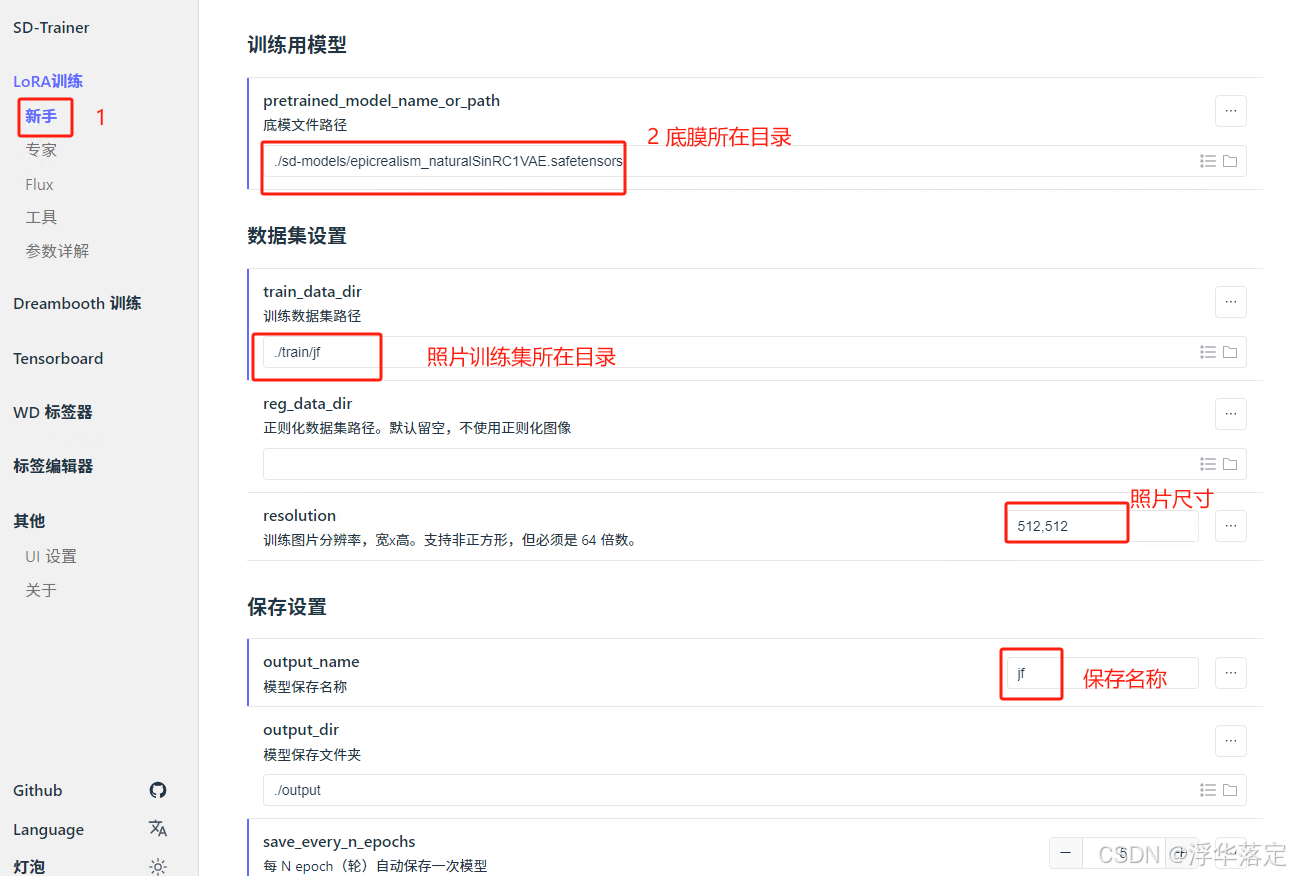
## Train data path | 设置训练用模型、图片
$pretrained_model = "./sd-models/chilloutmix_NiPrunedFp32Fix.safetensors" # base model path | 底模路径
$train_data_dir = "./train/qg_imgs" # train dataset path | 训练数据集路径
## Train related params | 训练相关参数
$resolution = "512,512" # image resolution w,h. 图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。
$batch_size = 2 # batch size
$max_train_epoches = 20 # max train epoches | 最大训练 epoch
$save_every_n_epochs = 2 # save every n epochs | 每 N 个 epoch 保存一次
$output_name = "qg" # output model name | 模型保存名称chilloutmix_NiPrunedFp32Fix.safetensors 的下载地址为:
naonovn/chilloutmix_NiPrunedFp32Fix at main
We're on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/naonovn/chilloutmix_NiPrunedFp32Fix/tree/main也可以使用其他的模型,上面的模型地址也可以改成stable-diffusion中已有的模型路径,可以节约点儿磁盘空间,毕竟单个模型都是好几个G。另外这个目录设置要注意,不是到最后那一层的目录,是到最后一层的上一层目录。
方式二,直接在webui上设置,比较直观
- 开始训练
本文最开始 的几个步骤
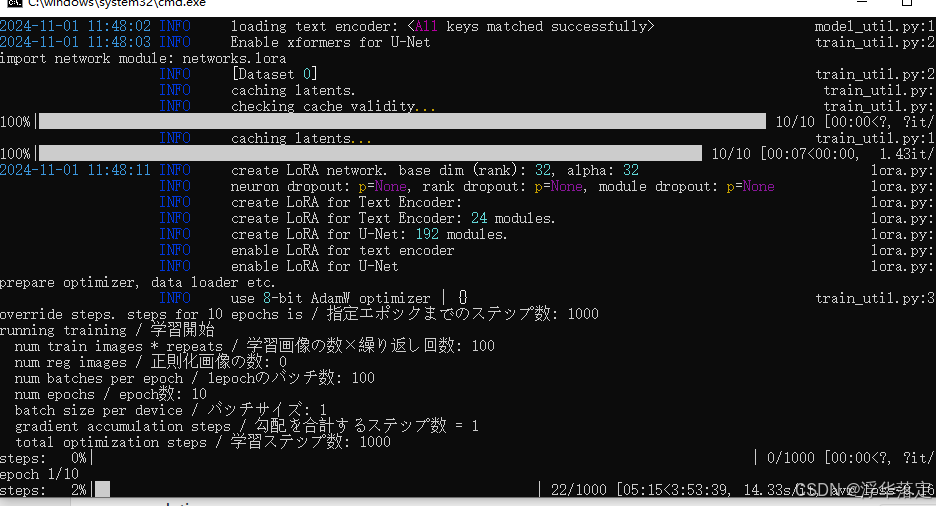
如果使用的是方式二,可以直接点击右侧的"直接开始训练"按钮就可以开始训练,与方式一一样,相关的输出信息可以在命令行终端上看到。一般不会一下就成功,可以根据相关的报错信息进行修改。我用的是3060的显卡,之前将batch_size和max_train_epoches设置得较大,中途会出现显存不够用的情况,然后逐步调整,才最终跑完。训练的过程见下图。
最后会在output目录中,输出训练好的模型文件。
- 模型使用
将训练好的模型.safetensors文件拷贝到stable-diffusion文件夹下的models/lora/文件夹下,在提示词中加入lora:训练的模型:权重就可以生成自己的图像了,效果还行。如果用更多图片,有更强悍的机器,训练出来的效果应该会更好...