sd文生图
- [前言:从"零件"到"成品"------Stable Diffusion的集成时刻](#前言:从“零件”到“成品”——Stable Diffusion的集成时刻)
- [第一章:Stable Diffusion的完整工作流:从Prompt到图像](#第一章:Stable Diffusion的完整工作流:从Prompt到图像)
-
- [1.1 宏观总览:四大核心组件的"接力赛"](#1.1 宏观总览:四大核心组件的“接力赛”)
- [1.2 工作流程图:数据在模型中的"旅程地图"](#1.2 工作流程图:数据在模型中的“旅程地图”)
- 第二章:核心组件准备:集齐炼金术的"法器"
-
- [2.1 Text Encoder (CLIP):Prompt的"语义翻译官"](#2.1 Text Encoder (CLIP):Prompt的“语义翻译官”)
- 第三章:【代码实战】文生图的炼金过程:逐层驱动生成器
-
- [3.1 Step 1: 文本编码------Prompt到prompt_embeds](#3.1 Step 1: 文本编码——Prompt到prompt_embeds)
- [3.2 Step 2: 初始噪声------生成潜在空间画布](#3.2 Step 2: 初始噪声——生成潜在空间画布)
- [3.3 Step 3: 迭代去噪------U-Net与Scheduler的"画笔起舞"](#3.3 Step 3: 迭代去噪——U-Net与Scheduler的“画笔起舞”)
- [3.4 Step 4: 图像解码------从Latent到像素的"还原术"](#3.4 Step 4: 图像解码——从Latent到像素的“还原术”)
- [第四章:CFG (Classifier-Free Guidance):图像生成中的"指令强度"](#第四章:CFG (Classifier-Free Guidance):图像生成中的“指令强度”)
-
- [4.1 为什么需要CFG?------"有条件"与"无条件"的博弈](#4.1 为什么需要CFG?——“有条件”与“无条件”的博弈)
- [4.2 CFG原理:预测噪声的"方向盘"微调](#4.2 CFG原理:预测噪声的“方向盘”微调)
- [4.3 guidance_scale参数的调整与效果对比](#4.3 guidance_scale参数的调整与效果对比)
- 第五章:运行与验证:生成你的第一幅AI画作
-
- [5.1 完整的文生图Python脚本](#5.1 完整的文生图Python脚本)
- Seed的魔力:如何让AI每次生成都"一模一样"?
- 总结与展望:你已掌握文生图的"核心钥匙"
前言:从"零件"到"成品"------Stable Diffusion的集成时刻
在《模型架构全景拆解》的旅程中,我们已经像一位技艺高超的"AI机械师",拆解并理解了Stable Diffusion的每一个核心"零件":
我们懂得了VAE如何压缩和解压图像
我们了解了U-Net如何作为核心画笔进行去噪
我们还学习了Prompt Embedding如何通过CLIP Text Encoder进行语义导航

现在,是时候将这些独立的、功能强大的"零件",按照Stable Diffusion的完整设计蓝图,组装成一个可以工作的"超级机器"了! 这就像你掌握了CPU、显卡、内存的原理,现在要亲手组装一台能够运行游戏的电脑。
今天,我们将扮演一位"AI系统集成工程师",亲手驱动这个强大的文生图引擎,从你输入Prompt的那一刻起,一步步追踪数据在模型中的奇妙旅程,直到最终生成惊艳的图像。
第一章:Stable Diffusion的完整工作流:从Prompt到图像
从宏观层面,概览Stable Diffusion是如何将文字Prompt转化为图像的,并提供一个直观的流程图。
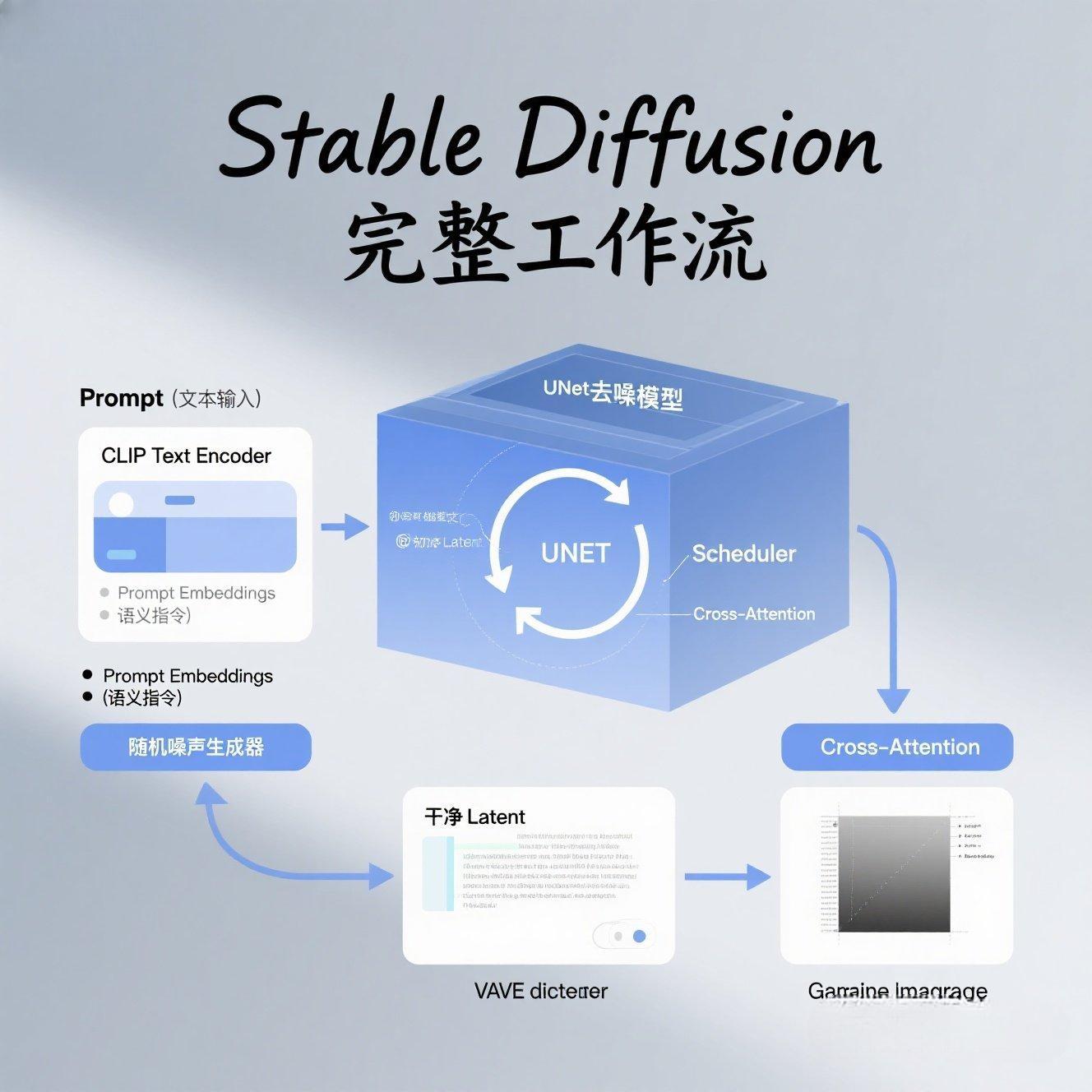
1.1 宏观总览:四大核心组件的"接力赛"
Stable Diffusion的整个文生图过程,可以看作是以下四大核心组件之间的一场"接力赛":
CLIP Text Encoder (文本编码器):接收你的Prompt,将文字"翻译"成AI能理解的语义指令(prompt_embeds)。
VAE (Variational Autoencoder):负责图像与潜在空间之间的转换。"Encoder"将图像压缩,"Decoder"将潜在表示解码回图像。
UNet (去噪器):Stable Diffusion的"大脑",负责在潜在空间中迭代地预测并移除噪声。
Scheduler (调度器):控制去噪过程的步数和去噪算法(如DDIM, PNDM等)。
1.2 工作流程图:数据在模型中的"旅程地图"
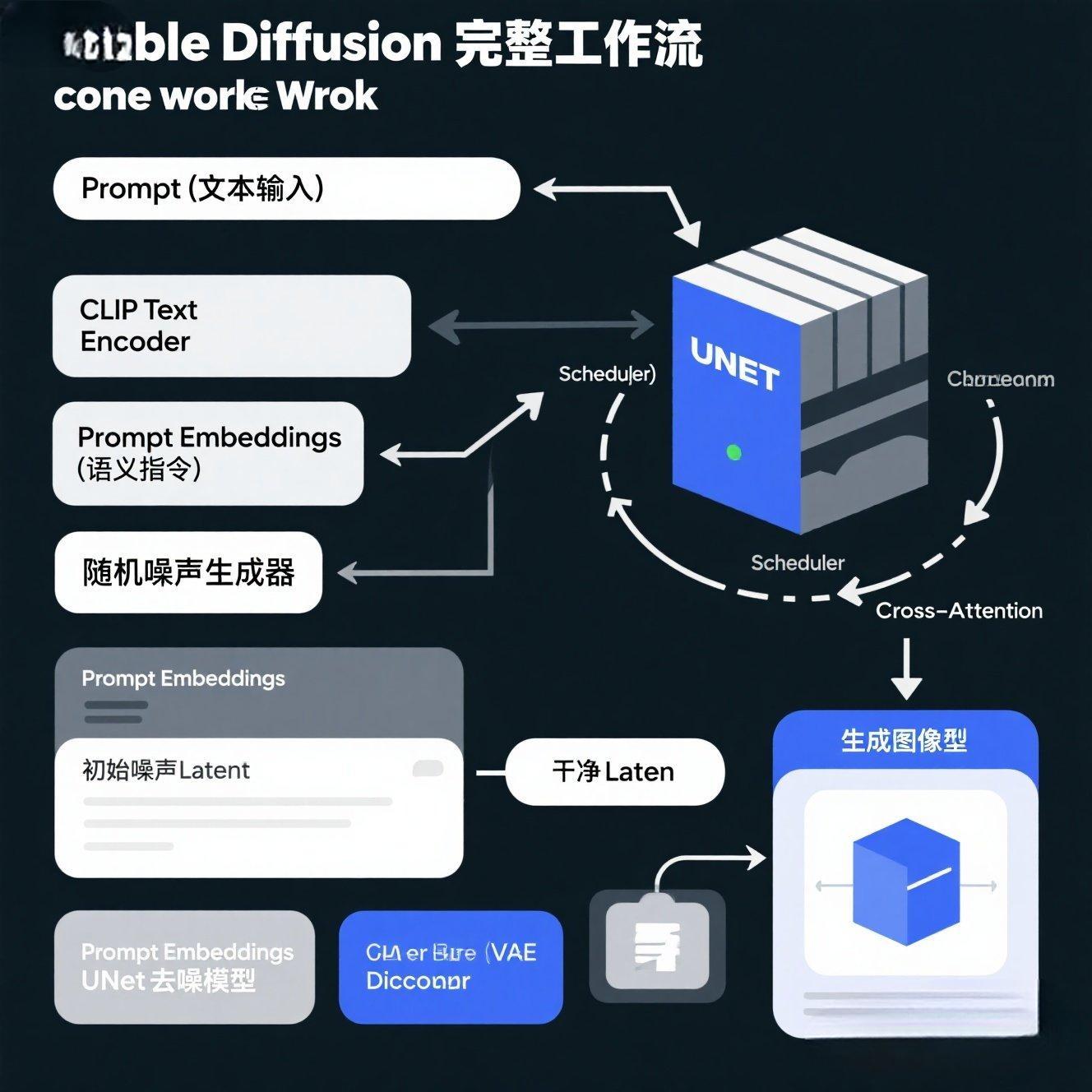
从Prompt到图像,数据在Stable Diffusion中遵循一个清晰的流程:
Prompt -> (CLIP Text Encoder) -> Prompt Embeddings
随机噪声 -> (U-Net) 在Prompt Embeddings引导下,通过Scheduler迭代去噪 -> 干净的潜在表示 (Latent)
干净的Latent -> (VAE Decoder) -> 最终图像
第二章:核心组件准备:集齐炼金术的"法器"
在实际代码中,我们需要加载Stable Diffusion预训练好的所有子模块。diffusers库为我们提供了极其方便的API。
2.1 Text Encoder (CLIP):Prompt的"语义翻译官"
VAE (Encoder/Decoder):图像与潜在空间的"任意门"
UNet:潜在空间的"去噪画师"
Scheduler (调度器):去噪过程的"节奏大师"
dart
【代码骨架】加载预训练组件
# stable_diffusion_full_pipeline.py
import torch
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
from transformers import CLIPTokenizer, CLIPTextModel
# from diffusers import StableDiffusionPipeline # 暂时不加载Pipeline,我们手动组装
# --- 1. 定义模型ID和设备 ---
MODEL_ID = "runwayml/stable-diffusion-v1-5"
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- 2. 加载核心预训练组件 ---
print("--- 准备核心组件:加载预训练模型 ---")
# 2.1 加载 CLIP Tokenizer
# 负责将文本 Prompt 转换为 Token IDs
print("1. 加载 CLIP Tokenizer...")
tokenizer = CLIPTokenizer.from_pretrained(MODEL_ID, subfolder="tokenizer")
# 2.2 加载 CLIP Text Encoder
# 负责将 Token IDs 转换为 Prompt Embeddings
print("2. 加载 CLIP Text Encoder...")
text_encoder = CLIPTextModel.from_pretrained(MODEL_ID, subfolder="text_encoder").to(DEVICE)
# 2.3 加载 UNet 模型 (核心去噪画师)
# 负责在潜在空间进行噪声预测
print("3. 加载 UNet 模型...")
unet = UNet2DConditionModel.from_pretrained(MODEL_ID, subfolder="unet").to(DEVICE)
# 2.4 加载 VAE (AutoencoderKL,作为解码器)
# 负责将潜在向量解码为最终图像
print("4. 加载 VAE Decoder...")
vae = AutoencoderKL.from_pretrained(MODEL_ID, subfolder="vae").to(DEVICE)
# 2.5 加载调度器 (PNDMScheduler)
# 负责管理去噪过程的时间步和噪声量
print("5. 加载调度器 (PNDMScheduler)...")
scheduler = PNDMScheduler.from_pretrained(MODEL_ID, subfolder="scheduler")
print("\n所有核心组件加载完成!")【代码解读】
这段代码作为起点,利用diffusers库,从runwayml/stable-diffusion-v1-5这个预训练模型中,精确地提取了我们需要的所有"法器":tokenizer、text_encoder、unet、vae(作为解码器)和scheduler。它们都已被加载到内存并移到正确的DEVICE上,为后续的炼金过程做好准备。
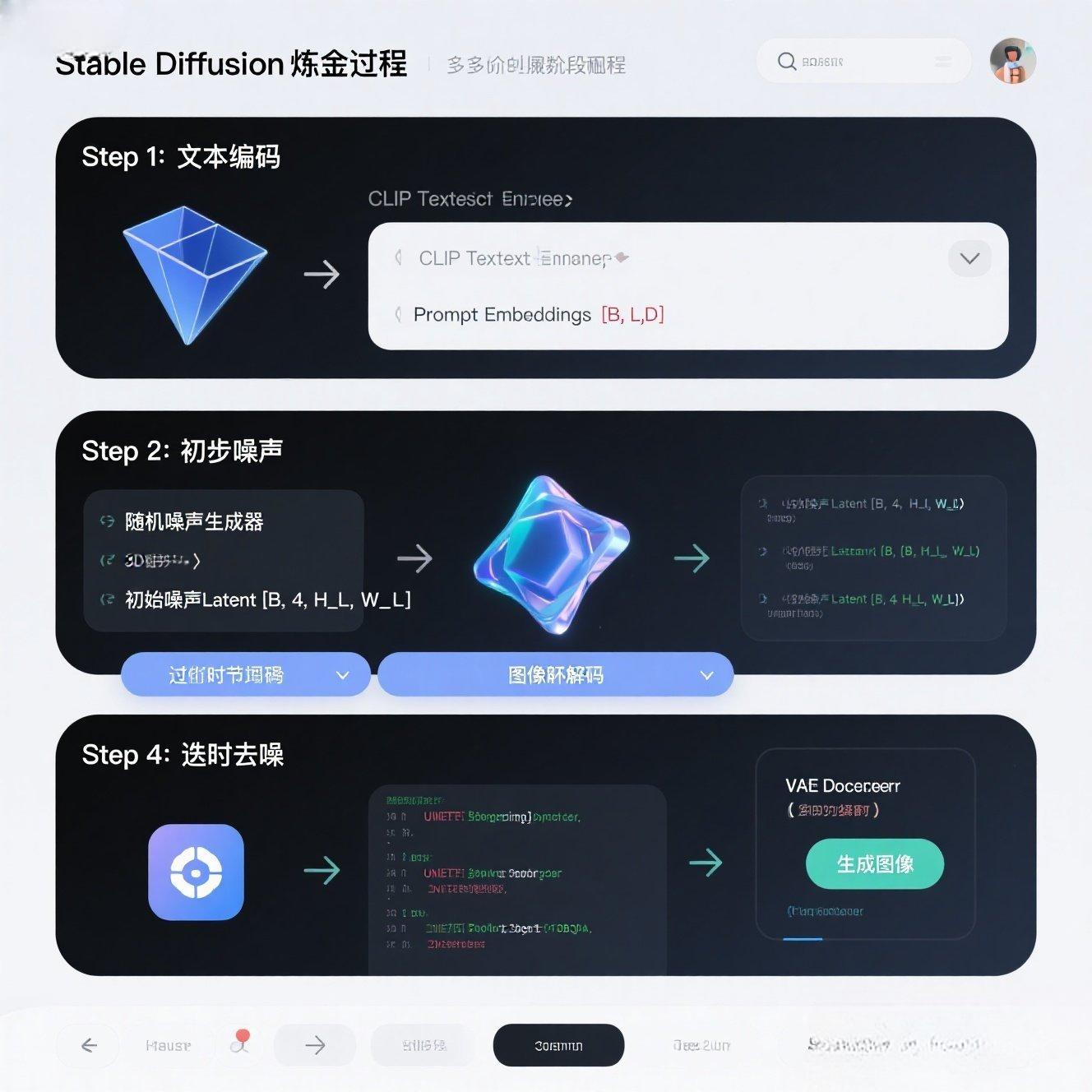
第三章:【代码实战】文生图的炼金过程:逐层驱动生成器
我们将把所有加载的组件,按照Stable Diffusion的生成流程,一步步地驱动它们完成文本到图像的转换。
3.1 Step 1: 文本编码------Prompt到prompt_embeds
将用户输入的Prompt,通过tokenizer转换为input_ids,再通过text_encoder转换为最终的prompt_embeds(语义指令)。
dart
# (接上面的代码)
# --- 3.1 Step 1: 文本编码 ---
prompt = "A majestic dragon flying over a futuristic city, cinematic, highly detailed, 4k" # 你的创意指令
guidance_scale = 7.5 # CFG强度,控制Prompt对图像的影响力
# 1.1 Tokenize Prompt
text_input_ids = tokenizer(
prompt,
padding="max_length", # 填充到最大长度 (77)
truncation=True, # 如果Prompt过长,截断
return_tensors="pt" # 返回PyTorch Tensor
).input_ids.to(DEVICE)
# 1.2 获取 Prompt Embeddings
with torch.no_grad(): # 推理阶段,不需要计算梯度
prompt_embeds = text_encoder(text_input_ids)[0] # [batch_size, seq_len, embed_dim]
# 为了Classifier-Free Guidance (CFG),我们需要一个无条件的 Prompt Embeddings (通常是空字符串)
uncond_input_ids = tokenizer(
"", padding="max_length", truncation=True, return_tensors="pt"
).input_ids.to(DEVICE)
with torch.no_grad():
uncond_prompt_embeds = text_encoder(uncond_input_ids)[0]
# 将条件和无条件 Embeddings 拼接起来,以便U-Net并行处理
# 形状: [2 * batch_size, seq_len, embed_dim]
prompt_embeds = torch.cat([uncond_prompt_embeds, prompt_embeds])
print(f"\nPrompt Embeddings 形状: {prompt_embeds.shape}")【代码解读】
这段代码将你的文本Prompt,通过CLIP Text Encoder,转换为了2, 77, 768形状的
prompt_embeds。其中的第一行代表无条件引导(CFG需要),第二行代表条件引导。
3.2 Step 2: 初始噪声------生成潜在空间画布
生成一个与潜在空间分辨率匹配的随机噪声张量作为生成过程的"初始画布"。
dart
# (接上面的代码)
# --- 3.2 Step 2: 准备初始噪声 Latent ---
height = 512 # 图像分辨率
width = 512
latent_channels = unet.config.in_channels # U-Net的输入通道数决定了潜在空间的通道数 (通常是4)
latent_height = height // vae.config.scaling_factor # 512/8 = 64
latent_width = width // vae.config.scaling_factor # 512/8 = 64
# 创建随机噪声 Latent (初始画布)
generator = torch.Generator(device=DEVICE).manual_seed(42) # 固定种子,保证结果可复现
latents = torch.randn(
(1, latent_channels, latent_height, latent_width), # Batch=1, C=4, H=64, W=64
generator=generator,
device=DEVICE
) * scheduler.init_noise_sigma # 乘以调度器建议的初始噪声标准差
print(f"初始噪声Latent形状: {latents.shape}")【代码解读】
我们生成了一个与潜在空间分辨率(例如64x64)匹配的、形状为1, 4, 64, 64的随机噪声张量。这是AI进行创作的起点。
3.3 Step 3: 迭代去噪------U-Net与Scheduler的"画笔起舞"
这是Stable Diffusion的核心循环。U-Net和Scheduler在这里协同工作,一步步地移除噪声,将混沌的Latent转化为清晰的Latent。
dart
# (接上面的代码)
# --- 3.3 Step 3: 迭代去噪循环 (U-Net核心) ---
num_inference_steps = 25 # 去噪步数,推荐20-50步
# 设置调度器的时间步
scheduler.set_timesteps(num_inference_steps, device=DEVICE)
timesteps = scheduler.timesteps # 获取所有时间步,例如 [999, 974, ..., 0]
print(f"\n🚀 开始 {num_inference_steps} 步去噪循环...")
for t in tqdm(timesteps): # 遍历调度器生成的时间步
# 扩展Latent为两个(用于Classifier-Free Guidance)
# 一个用于无条件预测,一个用于条件预测
latent_model_input = torch.cat([latents] * 2)
# 根据时间步 t 缩放输入,这是扩散模型的标准操作
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
# UNet 预测噪声
with torch.no_grad():
# UNet接收带噪Latent, 时间步t, Prompt Embeddings
# sample 是U-Net预测的噪声残差
noise_pred = unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds # 传入Prompt Embeddings作为条件
).sample
# Classifier-Free Guidance (CFG)
# 将预测结果分为无条件和有条件两部分
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
# CFG核心公式:最终预测噪声 = 无条件噪声 + guidance_scale * (条件噪声 - 无条件噪声)
# guidance_scale 越大,图像越贴合Prompt,但多样性可能降低
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# 使用调度器更新Latent (去噪一步)
# scheduler.step() 根据预测的噪声和当前时间步,计算下一个更干净的Latent
latents = scheduler.step(noise_pred, t, latents).prev_sample
print("去噪循环完成!")【代码解读】
这是整个Stable Diffusion的核心,一个迭代的去噪循环。
scheduler.set_timesteps():初始化调度器,生成所有去噪的时间步。
torch.cat(latents*2):为了CFG,将Latent复制一份,一份用于无条件引导,一份用于条件引导。
unet(...):U-Net接收带噪Latent、时间步和prompt_embeds,预测噪声。
CFG:noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond),这是控制生
成质量和Prompt贴合度的关键公式。
scheduler.step(...):调度器根据预测的噪声,计算出下一个更干净的Latent。
3.4 Step 4: 图像解码------从Latent到像素的"还原术"
经过去噪循环后,我们得到了一个干净的Latent。最后一步就是通过VAE Decoder,将其还原成我们能看到的像素图像。
dart
# (接上面的代码)
# --- 3.4 Step 4: 解码 Latent 为最终图像 (VAE Decoder) ---
# Latent 在送入VAE解码器前需要反缩放
# 原始的Stable Diffusion模型在编码时会对Latent进行缩放,解码时需要反向操作
latents = 1 / vae.config.scaling_factor * latents
with torch.no_grad(): # 解码是推理,不需要梯度
# vae.decode() 方法将潜在向量解码为原始像素空间图像
image = vae.decode(latents).sample # sample() 获取解码后的图像Tensor
# 将图像从 [-1, 1] 归一化范围转换到 [0, 255] 的整数范围,并转换为PIL Image
image = (image / 2 + 0.5).clamp(0, 1) # 将 [-1, 1] 反归一化到 [0, 1]
image = image.cpu().permute(0, 2, 3, 1).numpy()[0] # [B, C, H, W] -> [H, W, C] -> numpy,并取第一个样本
image = (image * 255).round().astype("uint8") # 转换到 [0, 255] 整数,并转为 uint8 类型
pil_image = Image.fromarray(image) # 从NumPy数组创建PIL Image对象
print("生成完成!")【代码解读】
latents = 1 / vae.config.scaling_factor * latents:反缩放Latent,因为VAE在编码时对其进行了缩放。
vae.decode(latents).sample:调用VAE的解码器,将干净的潜在向量转换回像素空间图像。
image = (image / 2 + 0.5).clamp(0, 1):将图像像素值从模型输出的-1, 1范围,反归一化回0, 1。
image.cpu().permute(0, 2, 3, 1).numpy()0:将Tensor移到CPU,将B, C, H, W重排为H, W, C,转
换为NumPy数组,并取出Batch中的第一个样本。
pil_image = Image.fromarray(image):最终将NumPy数组转换为PIL Image对象,方便显示和保存。
第四章:CFG (Classifier-Free Guidance):图像生成中的"指令强度"

深入讲解CFG的原理,理解它如何通过"有条件"与"无条件"的预测博弈,精确控制Prompt对生成结果的影响力。
4.1 为什么需要CFG?------"有条件"与"无条件"的博弈
如果只使用文本Prompt来引导生成,模型有时会变得过于"听话",生成结果缺乏多样性和创造性;或者,如果Prompt不够清晰,模型就会"迷失"。
CFG (Classifier-Free Guidance) 的思想是:让模型同时做两种预测,然后将它们巧妙地结合起来。
有条件预测 (noise_pred_text):U-Net在Prompt的严格指导下预测的噪声。
无条件预测 (noise_pred_uncond):U-Net在没有Prompt(或用一个空Prompt)指导下预测的噪声。
这种博弈,让模型在"听话"和"自由发挥"之间找到了一个平衡。
4.2 CFG原理:预测噪声的"方向盘"微调
CFG通过一个简单的公式,来组合这两种预测的噪声:
最终预测噪声 = 无条件预测噪声 + guidance_scale * (有条件预测噪声 - 无条件预测噪声)
guidance_scale (指导强度):这是一个超参数,通常在 5 到 15 之间。
-
guidance_scale = 1.0:只使用无条件预测(或条件与无条件预测等权),生成结果多样性高,但可能不贴合Prompt。
-
guidance_scale > 1.0:增强"条件预测"的影响力,使生成结果更贴合Prompt。
-
guidance_scale越大,生成结果越符合Prompt,但可能失去细节,甚至出现"伪影"。
4.3 guidance_scale参数的调整与效果对比
目标:通过调整guidance_scale参数,观察对生成图像质量和Prompt贴合度的影响。
【操作建议】:在simple_diffusion_full.py脚本中,修改guidance_scale的值(例如5.0, 7.5, 10.0, 15.0),分别运行,并比较生成图像的细节、风格与Prompt的匹配程度。你会发现,过低可能不符合Prompt,过高则可能出现伪影。
第五章:运行与验证:生成你的第一幅AI画作
5.1 完整的文生图Python脚本
代码展示:
dart
# simple_diffusion_full.py (完整脚本,可直接运行)
import torch
import torch.nn as nn
import torch.nn.functional as F
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
from transformers import CLIPTokenizer, CLIPTextModel
from PIL import Image
from tqdm.auto import tqdm
import os
# --- 0. 定义模型ID和通用参数 ---
MODEL_ID = "runwayml/stable-diffusion-v1-5" # Stable Diffusion 1.5 模型ID
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- 1. 加载核心预训练组件 ---
print("--- 1. 加载 Stable Diffusion 核心组件 ---")
tokenizer = CLIPTokenizer.from_pretrained(MODEL_ID, subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained(MODEL_ID, subfolder="text_encoder").to(DEVICE)
unet = UNet2DConditionModel.from_pretrained(MODEL_ID, subfolder="unet").to(DEVICE)
vae = AutoencoderKL.from_pretrained(MODEL_ID, subfolder="vae").to(DEVICE)
scheduler = PNDMScheduler.from_pretrained(MODEL_ID, subfolder="scheduler")
print("Stable Diffusion 核心组件加载完成!")
# --- 2. 定义 Prompt 和生成参数 ---
my_prompt = "A majestic dragon flying over a futuristic city, cinematic, highly detailed, 4k"
num_inference_steps = 25 # 去噪步数,常用20-50步
guidance_scale = 7.5 # CFG强度,常用7.5
seed = 42 # 固定随机种子,保证结果可复现
# 为保存图像创建目录
output_dir = "generated_images"
os.makedirs(output_dir, exist_ok=True)
# --- 3. 文生图炼金过程 ---
# 3.1 Step 1: 文本编码
text_input_ids = tokenizer(
my_prompt, padding="max_length", truncation=True, return_tensors="pt"
).input_ids.to(DEVICE)
with torch.no_grad():
prompt_embeds = text_encoder(text_input_ids)[0]
# 为CFG准备无条件 Prompt Embeddings
uncond_input_ids = tokenizer(
"", padding="max_length", truncation=True, return_tensors="pt"
).input_ids.to(DEVICE)
with torch.no_grad():
uncond_prompt_embeds = text_encoder(uncond_input_ids)[0]
prompt_embeds = torch.cat([uncond_prompt_embeds, prompt_embeds])
print(f"\nPrompt Embeddings 形状: {prompt_embeds.shape}")
# 3.2 Step 2: 准备初始噪声 Latent
height = 512
width = 512
latent_channels = unet.config.in_channels
latent_height = height // vae.config.scaling_factor # 64
latent_width = width // vae.config.scaling_factor # 64
generator = torch.Generator(device=DEVICE).manual_seed(seed)
latents = torch.randn(
(1, latent_channels, latent_height, latent_width),
generator=generator,
device=DEVICE
) * scheduler.init_noise_sigma
print(f"初始噪声Latent形状: {latents.shape}")
# 3.3 Step 3: 迭代去噪循环
scheduler.set_timesteps(num_inference_steps, device=DEVICE)
timesteps = scheduler.timesteps
print(f"\n🚀 开始 {num_inference_steps} 步去噪循环...")
for t in tqdm(timesteps):
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
with torch.no_grad():
noise_pred = unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds
).sample
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = scheduler.step(noise_pred, t, latents).prev_sample
print("去噪循环完成!")
# 3.4 Step 4: 解码 Latent 为最终图像
latents = 1 / vae.config.scaling_factor * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
image = (image * 255).round().astype("uint8")
pil_image = Image.fromarray(image)
# --- 4. 显示和保存生成结果 ---
output_image_path = os.path.join(output_dir, "generated_image.png")
pil_image.save(output_image_path)
print(f"\n🎉 恭喜!你的AI画作已生成并保存到: {output_image_path}")
pil_image.show() # 显示生成的图片 (可能需要安装Pillow的显示插件)【代码解读与见证奇迹】
运行这段脚本,第一次会下载Stable Diffusion模型(如果本地没有,约2.5GB)。然后,你将亲眼见证一个令人惊叹的过程:你的AI画笔将根据你输入的文本Prompt,从一片随机噪声中,一步步"雕刻"出一幅符合描述的、高质量的图像!
这幅画,是文本Prompt、CLIP Text Encoder、VAE、U-Net、调度器等所有组件完美协同工作,最终炼成的结晶。它证明了你已经能够将零散的AI模块集成为一个功能完整的系统,并亲手驱动它进行创造。
Seed的魔力:如何让AI每次生成都"一模一样"?
解释随机种子在可重复性生成中的重要性。
在扩散模型中,图像生成的起点是随机噪声。这意味着每次运行,即使Prompt和参数完全相同,生成的图像也会不同。
如果你希望AI每次都生成一模一样的图像,你需要固定随机种子(Seed)。
dart
import torch
my_seed = 42 # 可以是任何整数
torch.manual_seed(my_seed) # 设置CPU上的随机种子
if torch.cuda.is_available():
torch.cuda.manual_seed_all(my_seed) # 设置所有GPU上的随机种子在我们的脚本中,generator = torch.Generator(device=DEVICE).manual_seed(42) 这行代码就起到
了固定种子的作用。它确保了每次生成的初始噪声是完全相同的,从而保证了后续的去噪过程也是完全相同的,最终生成一致的图像。
总结与展望:你已掌握文生图的"核心钥匙"
恭喜你!今天你已经成功地扮演了一位"AI系统集成工程师",亲手搭建并驱动了一个强大的Stable Diffusion文生图引擎。
✨ 本章惊喜概括 ✨
| 你掌握了什么? | 对应的核心能力 |
|---|---|
| Stable Diffusion完整工作流 | ✅ 从Prompt到图像的端到端"炼金术" |
| 核心组件的集成 | ✅ 成功连接Text Encoder, VAE, UNet, Scheduler |
| 驱动AI绘画 | ✅ 亲手代码实现Stable Diffusion图像生成 |
| CFG深度解析 | ✅ 理解并实现了CFG公式,控制生成质量与贴合度 |
| 生成可复现性 | ✅ 掌握了随机种子(Seed)在AI生成中的应用 |
| 你现在已经不仅理解了Stable Diffusion的原理,更拥有了将理论转化为可运行系统的实战能力。你手中的,是文生图领域的"核心钥匙"。 | |
| 🔮 敬请期待! 在下一章中,我们将继续深入**《模型架构全景拆解》,探索如何实现对生成图像的精细控制**------《图生图:ControlNet的结构与调控方式》。我们将看到AI绘画如何从"自由发挥"走向"精准控制"! |