目录
[二、GaussDB Ustore存储引擎](#二、GaussDB Ustore存储引擎)
本文将介绍GaussDB中的Ustore存储引擎,包括Ustore的设计背景、特点介绍和适用业务场景等。
一、数据库存储引擎
数据库的存储引擎负责在内存和磁盘上存储、检索和管理数据,确保每个节点的数据能够长久保存。
存储引擎主要分为行存储(Row-Store)和列存储(Column-Store)两种方式。其中,行存储主要适合于在线交易型的OLTP场景;而列存储主要用于海量静态数据的分析,一般应用于OLAP场景。
二、GaussDB Ustore存储引擎
1. 背景介绍
在Ustore存储引擎出现之前,GaussDB的行存储引擎是Astore。Astore引擎采用了优化的Append Update(追加更新)存储格式设计,其元组(数据)的存储方式如图1所示。
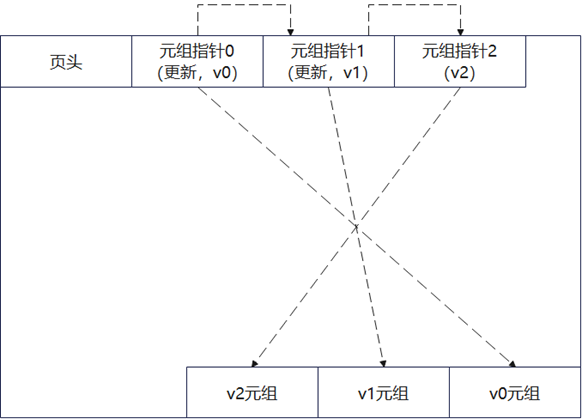
图1 Astore引擎元组(数据)的存储方式
当一个更新操作将 v0 版本元组更新为v1 版本元组后,如果 v0 元组所在页面有空闲空间,则直接在该页面内插入更新后的v1元组,并将v0的元组指针指向v1的元组指针。在此过程中,新版本元组以追加写的方式和被更新的老版本元组混合存放,从而可以减少更新操作的I/O开销。
Astore在处理业务中的插入、删除及Hot-Update(同一页面内的更新)场景时表现出色。然而,对于跨数据页面更新的非Hot-Update场景,新数据需插入到新的页面,并插入新的索引,这不仅会引入额外的I/O操作,还可能导致索引膨胀。
由于新旧版本元组混合存放,需要通过vacuum操作遍历表数据并清理其中的死元组。vacuum操作不仅会占用一定系统资源,且在清理时需要对页面加写锁,读写锁的冲突也会影响用户的读写业务。因此,如果频繁vacuum操作可能会导致性能问题;反之,但如果vacuum操作频率太低,清理元组不及时,又会导致存储空间膨胀。
可以看出,Astore更适用于插入较多而更新较少的业务场景。为了应对频繁更新的业务场景,Ustore存储引擎应运而生。Ustore也是行存储引擎,又名In-place Update(原地更新)存储引擎,特别适用于频繁更新的业务场景。
2. 核心目标
Ustore存储引擎的核心目标为:
第一,针对OLTP场景,降低Append-Update存储引擎由于频繁更新导致的数据页空间膨胀,以及由此引起的索引空间膨胀。
第二,去除vacuum依赖,vacumm不再清理ustore的页面,从而减少大量页面I/O操作,节省系统资源,同时避免因vacuum操作引起的性能波动。
3. 原理介绍
In-place Update
Ustore存储引擎将新旧版本的数据分开存储,最新版本的数据被存储在数据页上,并且单独开辟一段Undo空间,专门用来统一管理历史版本的旧数据。因此,数据空间不会由于频繁更新而膨胀,旧版本的垃圾数据回收效率也会更高。
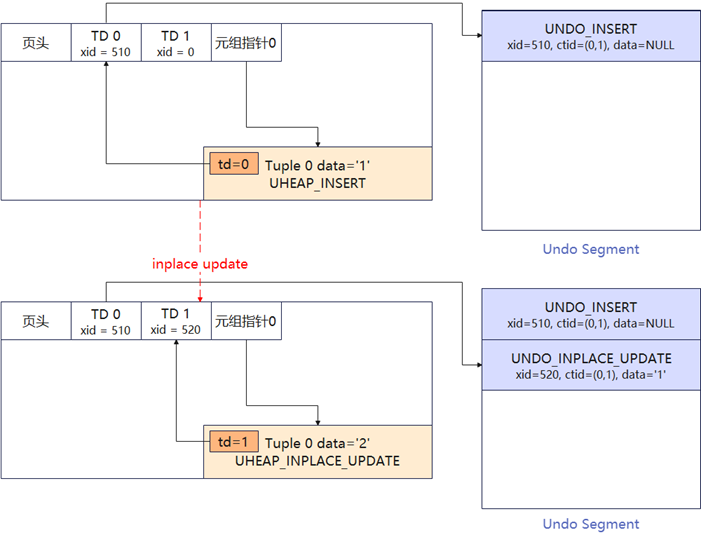
图2 Ustore的原地更新操作
Ustore的原地更新操作,如图2所示,当对数据页上的Tuple(元组)进行更新时,系统会将页面上的旧版本Tuple采用追加写的方式写入到Undo空间,这样旧版本数据的读取和写入不会发生冲突,同时在数据页上对Tuple的位置进行原地更新;当需要查询旧版本数据时,系统会检查TD(事务目录),然后从Undo空间中取出旧版本数据。
Ustore的原地更新机制保证了元组RowId稳定,对于在多个事务并发更新同一行的场景,更新时延相对稳定。同时,由于数据的最新版本和历史版本被分离存储,历史版本的批量回收不影响数据页的读写操作,因此,对最新版本的堆表数据空间膨胀友好。
多版本索引
Ustore实现了多版本索引Ubtree,Ubtree叶子节点的页面结构如图3所示。
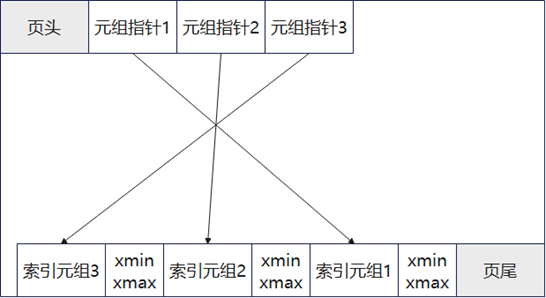
图3 Ubtree叶子节点的页面结构
Ubtree的叶子结点中,每个索引元组的尾部附加了对应的xmin和xmax(插入和删除的事务ID)。通过检查xmin和xmax,可以判断这个索引元组是否对当前事务可见,这种机制允许进行独立的多版本并发控制(MVCC)。索引可见性检查使得Index Scan和IndexOnly Scan的性能有所提升,还增加了IndexOnly Scan的比例,大大减少回表操作的次数。
空间管理和回收
Ustore不依赖vacuum清理机制,实现了自治式的空间管理机制,堆表和索引的空间分配和回收都在业务运行的时候平稳进行,可以减少由于vacuum异步数据清理带来的大量页面I/O。
当页面上的数据元组被删除时,系统会在页面上记录对应的潜在空闲空间(Potential Free Space),用于估计页面上的空闲空间。在执行DML语句时,如果发现空间不足或者潜在空闲空间达到某个阈值,会尝试对页面进行清理。在执行DQL查询语句时,若检测到页面上潜在空闲空间达到阈值,此时会尝试申请页面的写锁,一旦拿到了页面的写锁,同样会尝试对页面进行清理。
对于那些一直不被访问的页面,也可能存在可清理的元组。清理这些元组的机制如下:
当DML业务通过FSM(Free Space Map,自由空间映射)发现没有足够的可用空间,并且在对堆表的物理文件进行扩展前,会随机选取一些页面进行清理。经过多次尝试后,选取的页面会覆盖整个表的全部页面。
支持NUMA-aware
Ustore采用了NUMA-aware(非统一内存访问感知)的Undo子系统设计,这使得Undo子系统可以在多核平台上实现有效扩展。Undo空间被划分为多个逻辑区域(UndoZone) ,线程会在自己的逻辑区域上进行分配,确保与其他线程完全隔离,从而写入旧数据分配空间时就不会有额外的锁开销。同时,UndoZone可以按照CPU的NUMA核进行划分,每个线程会从当前的NUMA核上的UndoZone进行分配,进一步提升分配效率。
4. Ustore 闪回功能介绍
数据备份恢复是保护数据安全的重要手段之一。备份恢复类型一般可以分为物理恢复、逻辑恢复、闪回恢复。
物理恢复是通过物理文件拷贝的方式来备份数据库,通过备份的数据文件和归档日志(Redo Log),可以完全恢复数据库。这种恢复方式一般用于全量备份,能够恢复整个数据库到备份时的状态。
逻辑恢复是通过逻辑导出操作对数据库进行备份,但只能恢复到备份时保存的数据状态,无法恢复到具体某个时间点。由于逻辑恢复需要重建数据库并导入备份数据,因此,需要恢复的时间太长,这种恢复方式通常会用于数据迁移场景。
闪回恢复也是数据库恢复技术的一种,如图4所示。它可以有选择性地高效撤销一个已提交事务的影响,将数据从人为的不正确的操作中恢复出来。闪回恢复具有高效、可靠、精确的特点,通过恢复操作使得数据表可以回溯到某个历史状态,而不需要还原整个数据库。

图4 闪回恢复,快速回溯到历史状态
Ustore提供了闪回查询、闪回表、闪回Drop、闪回Truncate四类闪回功能,对于误操作数据后恢复十分有效。
闪回查询和闪回表
闪回查询:基于MVCC机制,定时捕获并存储快照作为闪回点,并且保留一定期限内的元组旧版本。通过使用保存的闪回点快照,可以检索出指定的旧版本数据,可以查询某个表在过去某个时间点的快照数据。这一特性可以用于查看和逻辑重建因意外删除或更改而受损的数据。
闪回表:基于MVCC机制,通过删除指定时间点和该时间点之后的增量数据,可以将表恢复至特定时间点,实现表级的数据还原。当逻辑损坏仅限于一个或一组表,而非整个数据库时,此特性可以快速恢复表的数据。
闪回Drop/Truncate
闪回Drop和闪回Truncate都是基于回收站(Recycle Bin)机制实现的,这一机制类似于windows系统的回收站,将已删除的表信息保存到回收站中,通过还原回收站中记录的表的物理文件,实现已Drop/Truncate表的恢复。
-
闪回Drop:可以恢复因意外而被删除的表,从回收站中恢复被删除的表及其附属结构,如索引、表约束等。
-
闪回Truncate:可以恢复因误操作或意外而被进行Truncate的表,从回收站中恢复被Truncate的表及索引的物理数据。
采用闪回技术后,恢复已提交的数据库修改前的数据只需要秒级,而且恢复时间和数据库大小无关,可以快速有效的进行数据恢复。
5. 核心优势
1)高性能
对插入、更新、删除等不同负载的业务,系统可以做到性能和资源使用表现相对均衡,相比Append Update 引擎性能提升10%。
对于更新操作,由于采用原地更新策略,系统在频繁更新类的业务场景下,拥有更高、更平稳的性能表现。
通过DML操作中执行动态页面清理,系统成功去除对Vacuum依赖,减少由于异步数据清理而产生的大量读写I/O操作,适合事务短、更新频繁、性能要求高的OLTP类业务场景。
2)高效存储
支持原地更新机制,通过将数据页面和回滚段分离存储,具备更高效、平稳的I/O处理能力,TPCC负载平均节约空间15%~20%。
Undo空间采用统一分配,集中回收的方式,复用效率更高,使得存储空间使用更加高效、平稳。
3)细粒度资源控制
通过Undo子系统,实现事务级的空间管控,可基于事务运行时长、单事务使用Undo空间大小以及整体Undo空间限制等方式监管事务运行,防止异常行为出现,方便数据库管理员对数据库系统资源使用进行规范和约束。
总结
GaussDB的Ustore存储引擎在数据频繁更新场景下,依旧保持性能平稳,抖动范围缩减了81%,因此,适应更多业务场景和工作负载;同时,还支持闪回功能,可以恢复因误操作而丢失的数据,这使得Ustore存储引擎更适用于对性能和稳定性有更高要求的金融核心业务场景。