第二篇大模型开发企业智能小助手应用上篇
自从2020年大模型被人熟知,到现在的人尽皆知的,基本上每个人都或多或少的使用过大模型的能力。由于知识点很多,我准备分4篇文章,从系统环境配置>知识库搭建>提示词优化>系统调优>对接web系统开发一个完整的大模型应用项目!
- 第一篇大模型应用开发系统环境配置
- 第二篇大模型应用知识库搭建上下篇
- 第三篇大模型应用模型及提示词优化
- 第四篇大模型应用与halo系统对接
原创不易,请关注公众号:【爬虫与大模型开发】,大模型的应用开发之路,整理了大模型在现在的企业级应用的实操及大家需要注意的一些RAG开发的知识点!持续输出爬虫与大模型的相关文章。
1 智能客服助手应用开发上篇
聊天助手开发
大语言模型的训练数据一般基于公开的数据,且每一次训练需要消耗大量算力,这意味着模型的知识一般不会包含私有领域的知识,同时在公开知识领域存在一定的滞后性。为了解决这一问题,目前通用的方案是采用 RAG(检索增强生成)技术,使用用户问题来匹配最相关的外部数据,将检索到的相关内容召回后作为模型提示词的上下文来重新组织回复。
实现原理
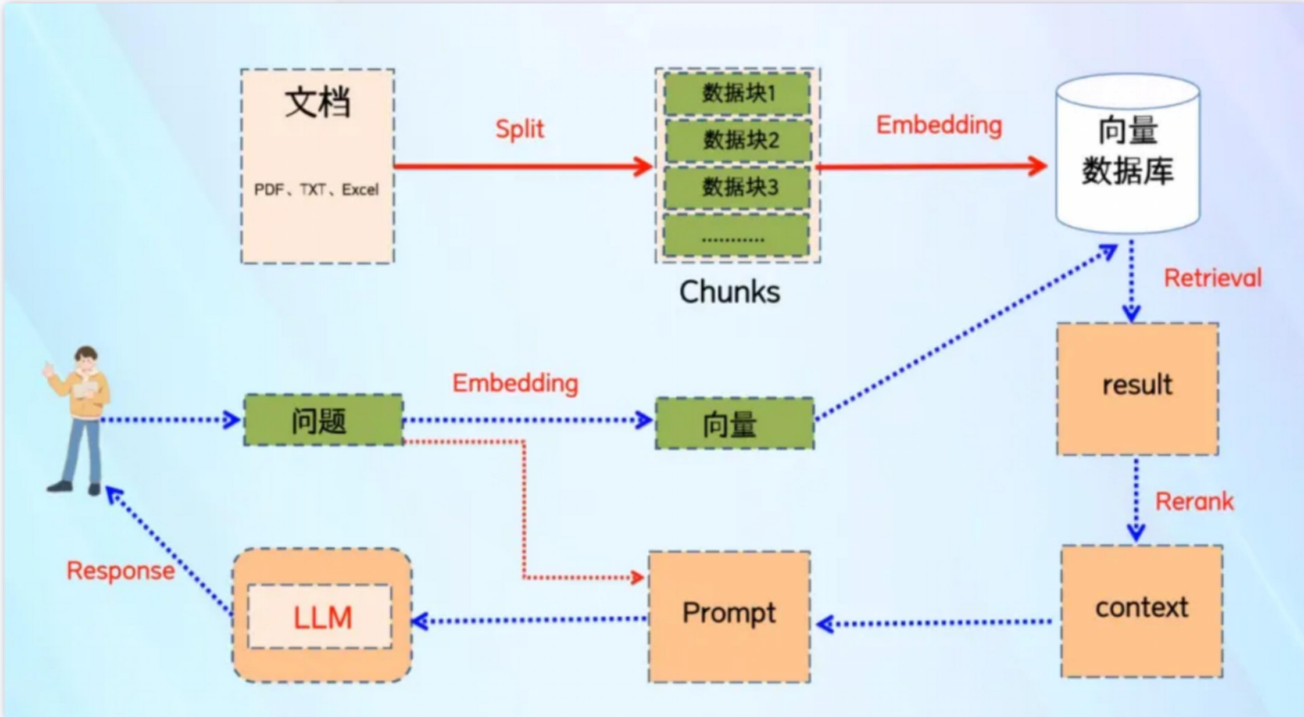
知识库(Knowledge)是一些文档(Documents)的集合。一个知识库可以被整体集成至一个应用中作为检索上下文使用。文档可以由开发者或运营人员上传,或由其它数据源同步(通常对应数据源中的一个文件单位)。
本次开发的大模型是聊天助手,实现产品垂直领域的知识库的搭建。主要解决客户经常提到的高频问题,提高售后的服务质量,提高客户的粘性,可以更好的服务客户,并减少一些不必要的重复人工的服务成本。
数据整理及清洗
从如下的格式中获取数据:
- Doc类文档:直接解析其实就能得到文本到底是什么元素,比如标题、表格、段落等等。这部分直接将文本段及其对应的属性存储下来,用于后续切分的依据。
- PDF类文档:可以使用多个开源模型进行协同分析来处理图片、表格、标题、段落等内容,形成一个文字版的文档。
- PPT类文档:将PPT转换成PDF形式,然后用上述处理PDF的方式来进行解析。
- web页面:使用爬虫全站抓取web端的指定的页面的内容。
数据清洗:对源数据进行去重、过滤、压缩和格式化等处理
数据提取:提提取数据中关键信息,包括文件名、时间、章节title、图片等信息。
数据索引一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。 主要包括:数据提取、文本分割、向量化(embedding)及创建索引等环节。
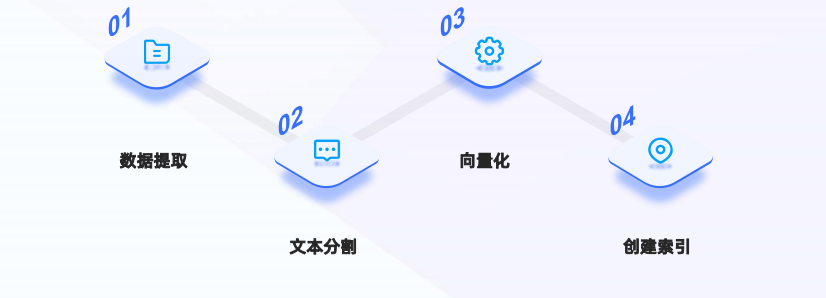
什么是数据的向量化(embedding)?
这是将文本、图像、音频和视频等转化为向量矩阵的过程,也就是变成计算机可以理解的格式。常见的向量模型有:
- ChatGPT-Embedding
- ERNIE-Embedding V1(百度千帆)
- M3E (huggingface)
- BGE (huggingface)
如何创建索引?
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程
- 常用的工具:FAISS、Chromadb、ES、milvus,pgvector等
文本分割的意义?
固定大小的分块方式:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解
- 句分割:以"句"的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等;
- 递归分割:通过分而治之的思想,用递归切分到最小单元的一种方式;
- 特殊分割:用于特殊场景。
如何使用LLM生成结果?
在数据生成过程中,我们能够利用多种框架,如Langchain和LlamaIndex。同时,Prompt工程和大型语言模型(LLM)在数据处理中扮演着至关重要的角色
Maxkb搭建一个智能聊天小助手
上篇中我们已经安装了maxkb,没有安装的参考上一篇的文章,首先我们创建一个应用和知识库,用来搭建提供给大模型学习,并根据提示词让大模型生成最终的结果!
1、创建应用 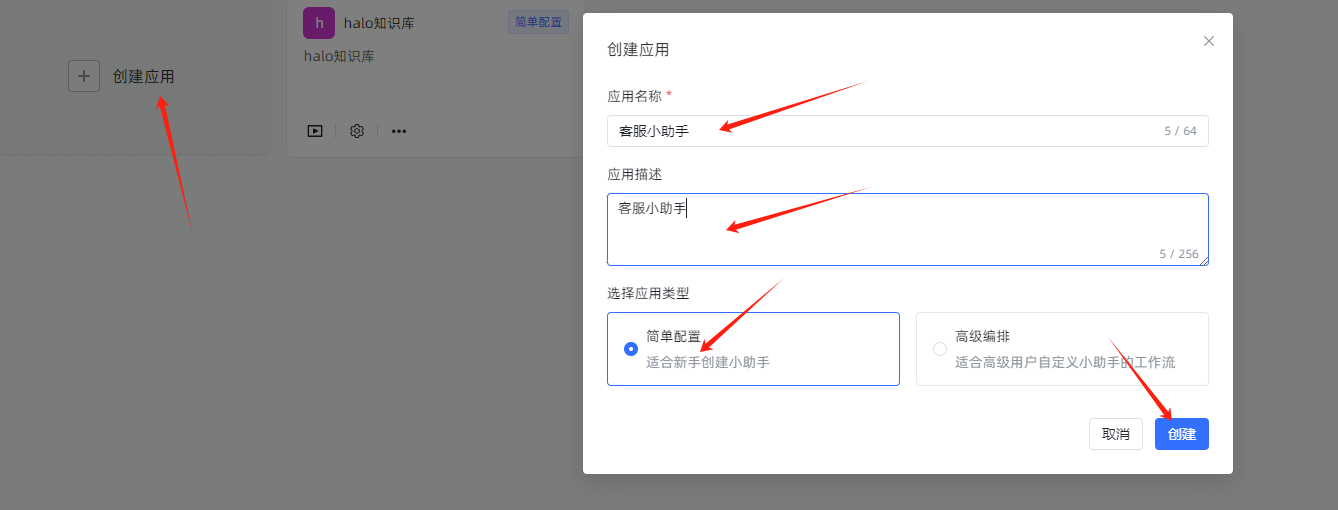 2、部署调用大模型
2、部署调用大模型
- 调用免费大模型
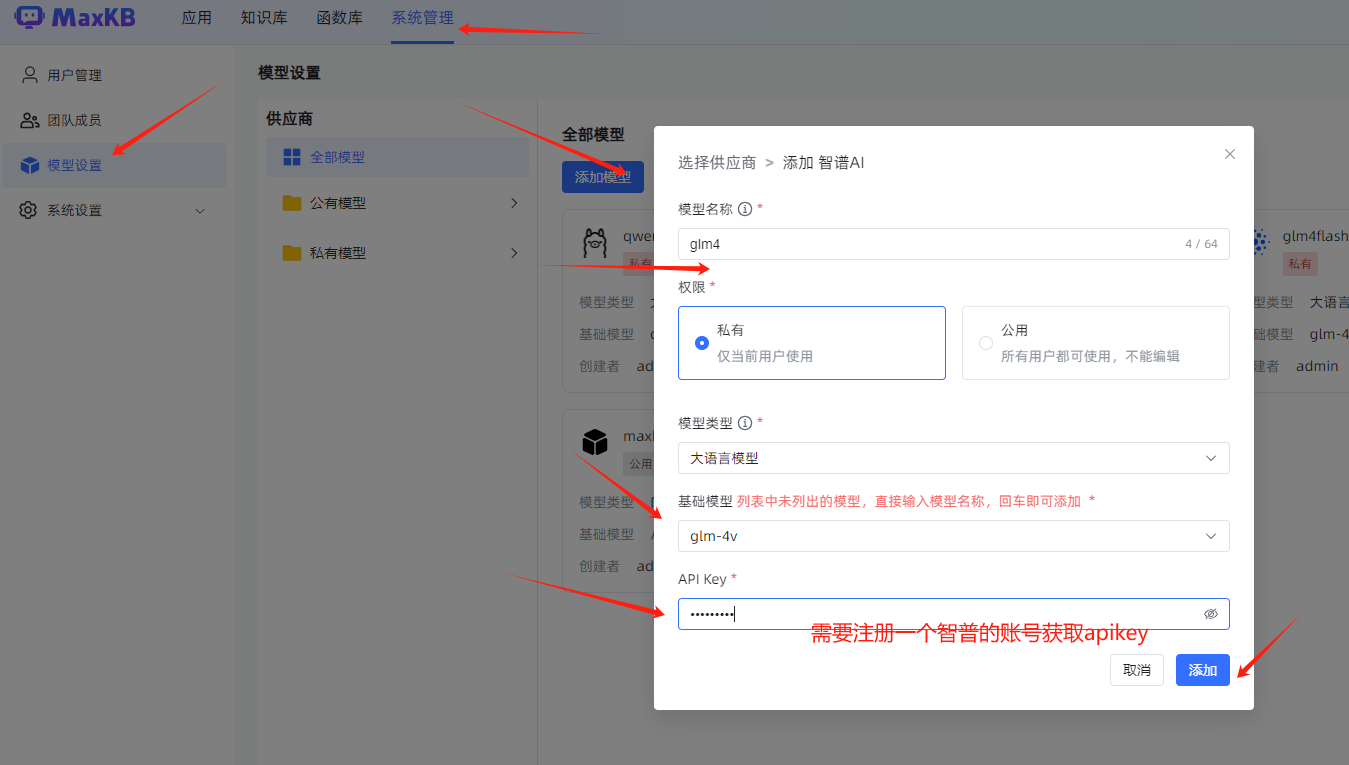
- 本地ollama部署
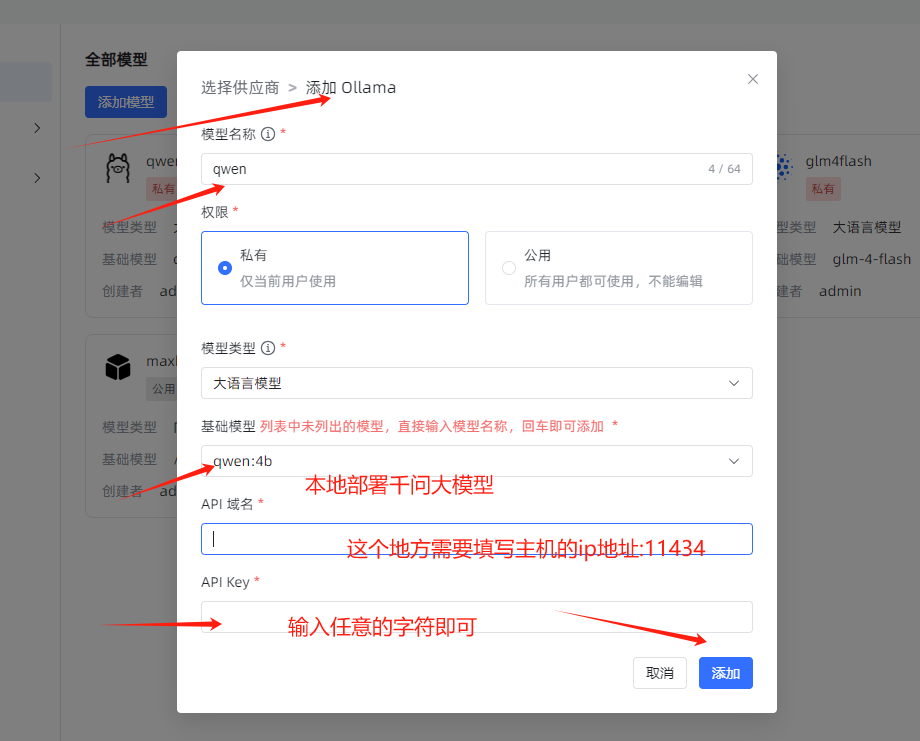 3、创建本地知识库
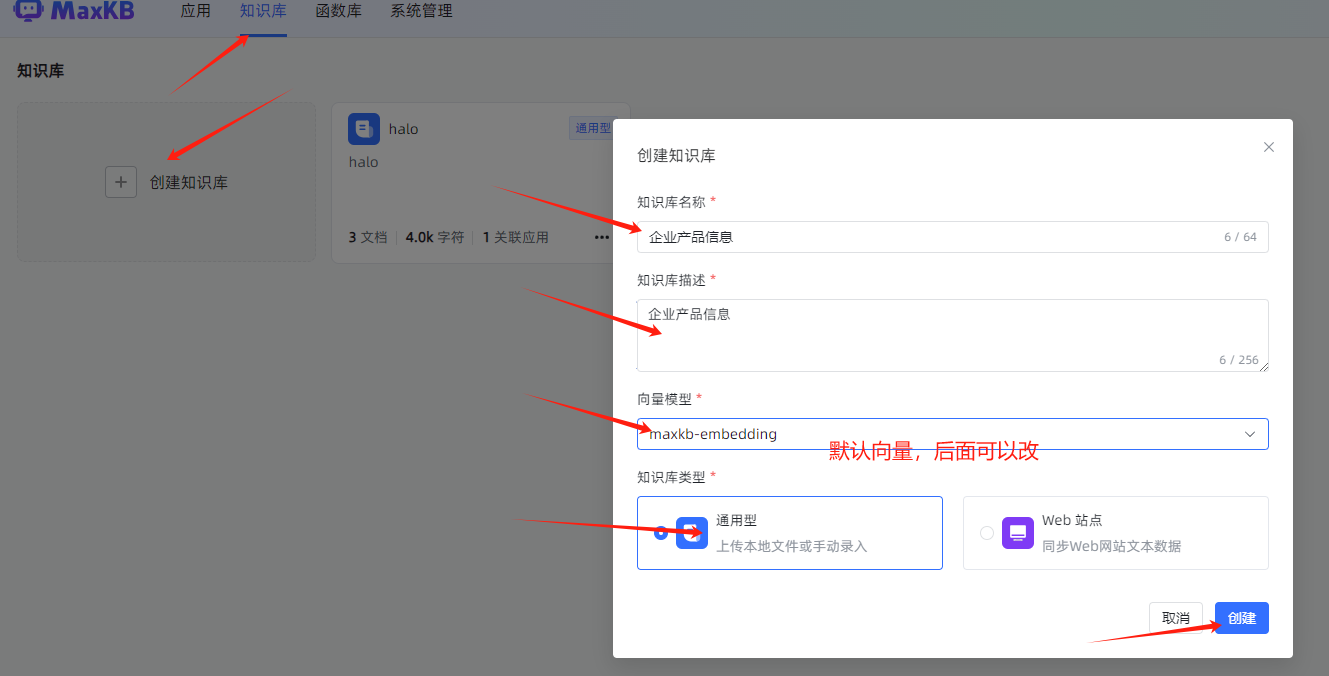
3、创建本地知识库
- 创建知识库
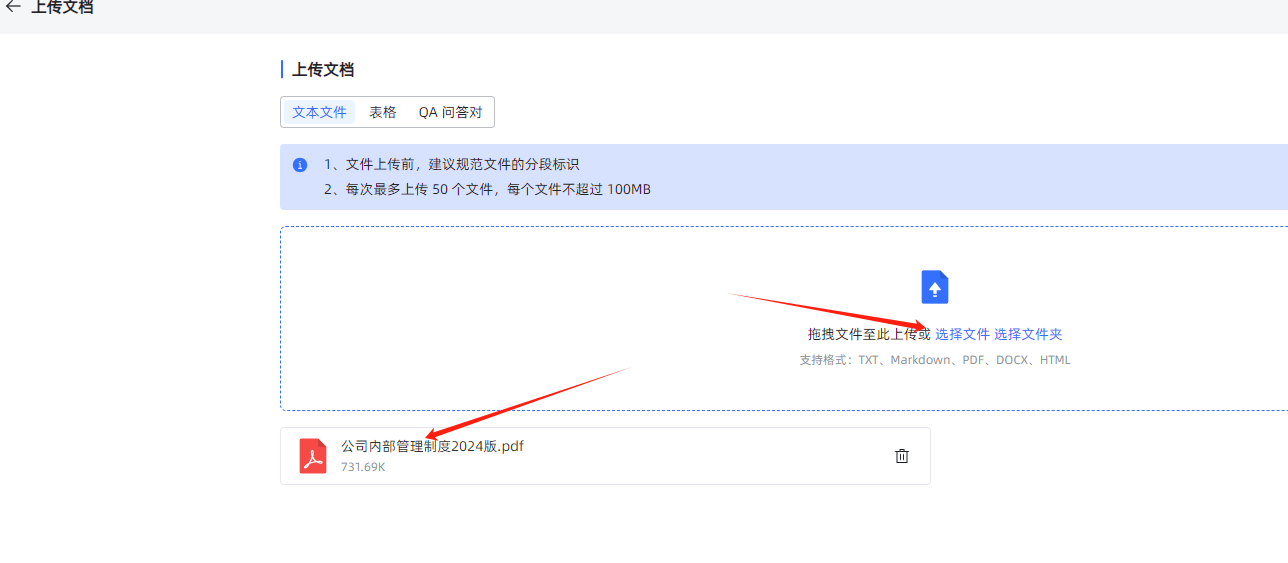
- 上传文档
- 选择智能分段
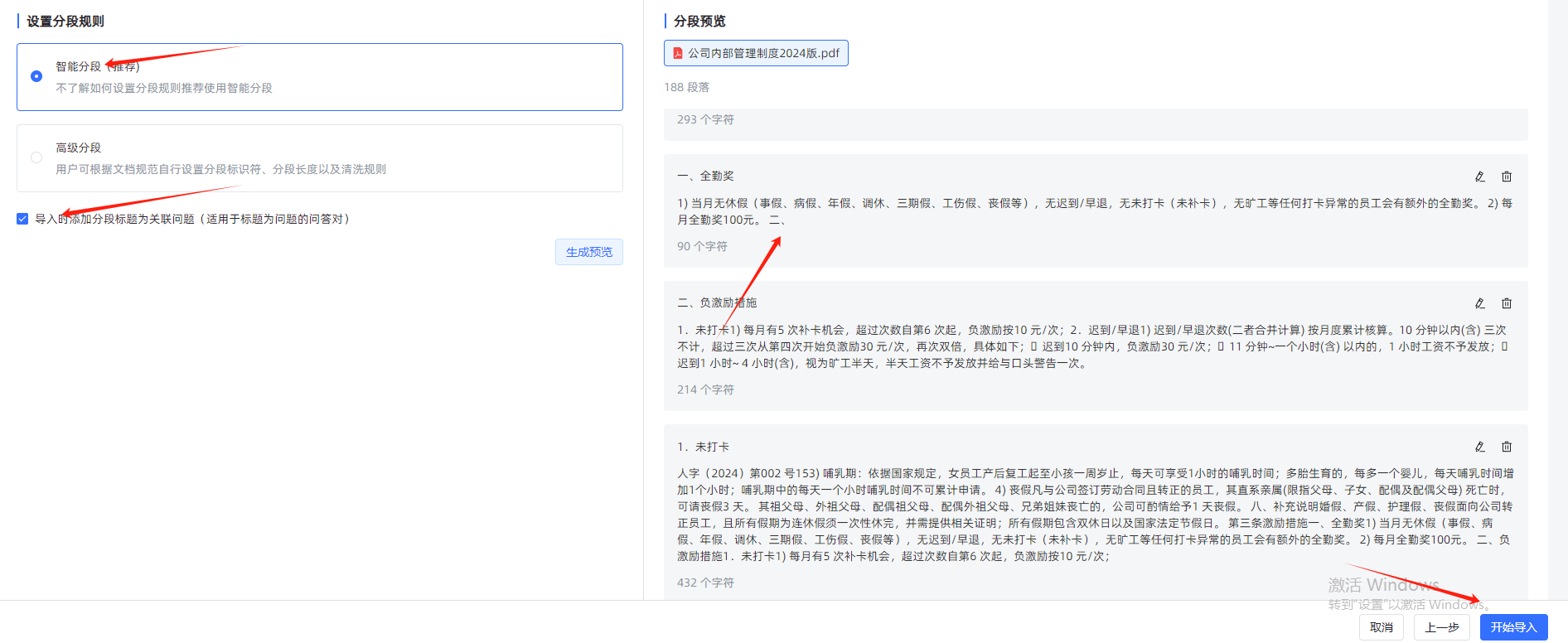
- 等待上传向量化完成

- 完成分段及向量化(这边可以再次人工审核下数据)
 应用开发测试
应用开发测试
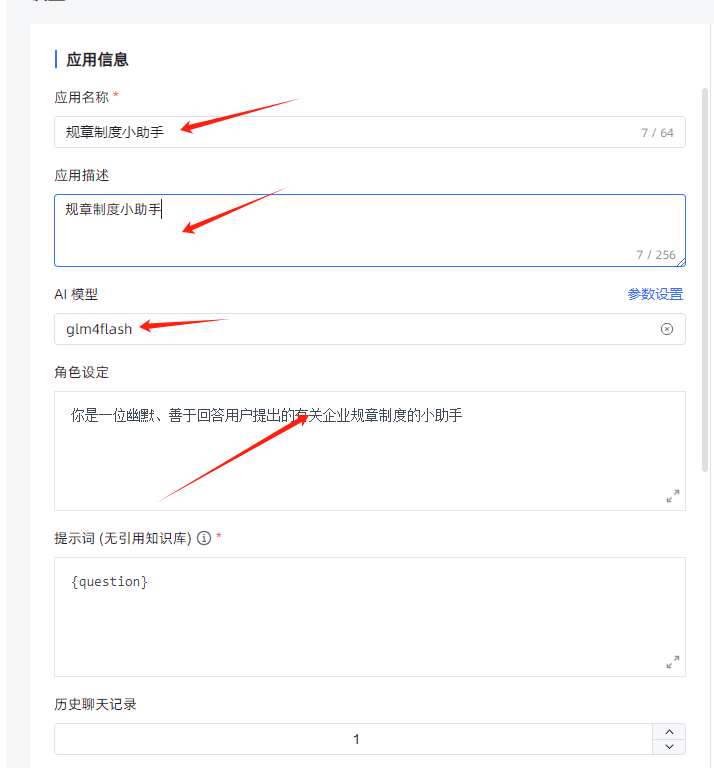
- 选择知识库
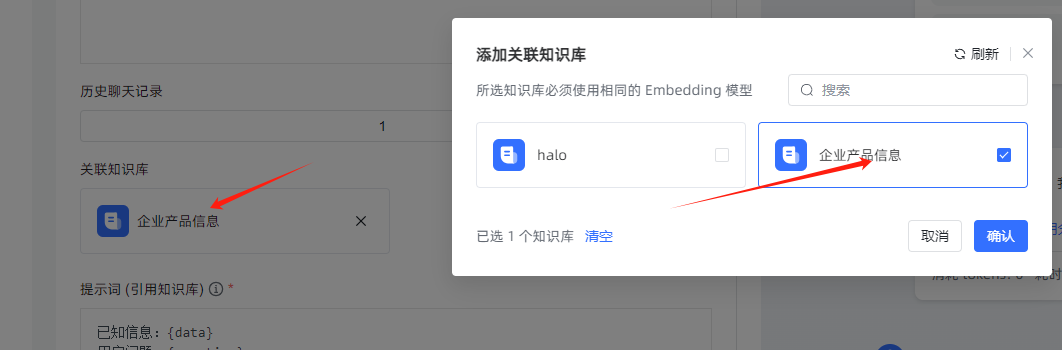
- 知识库及提示词
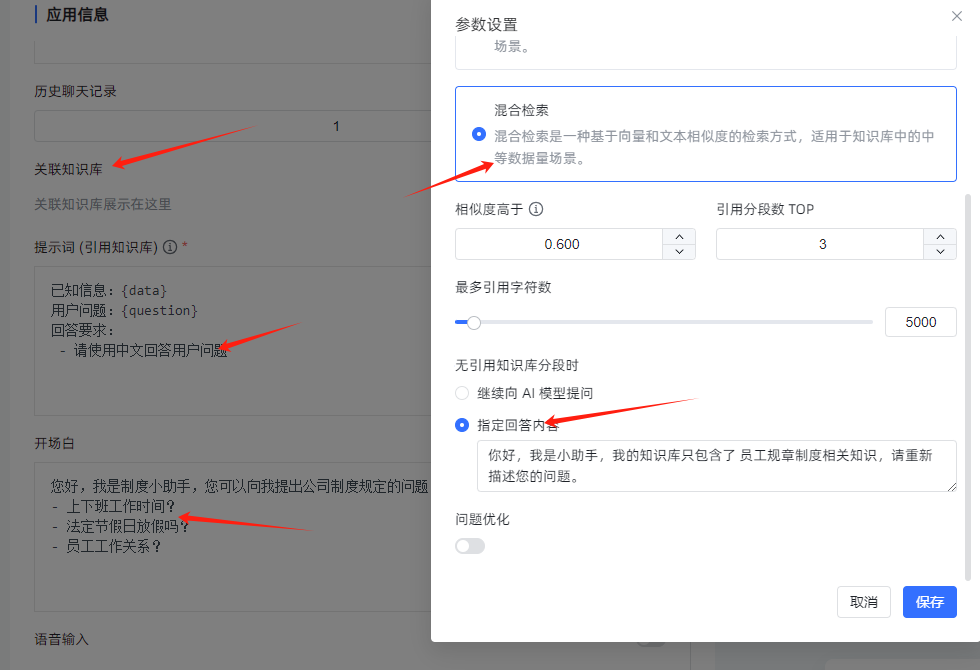
- 知识库命中测试结果如下图(效果非常的好)
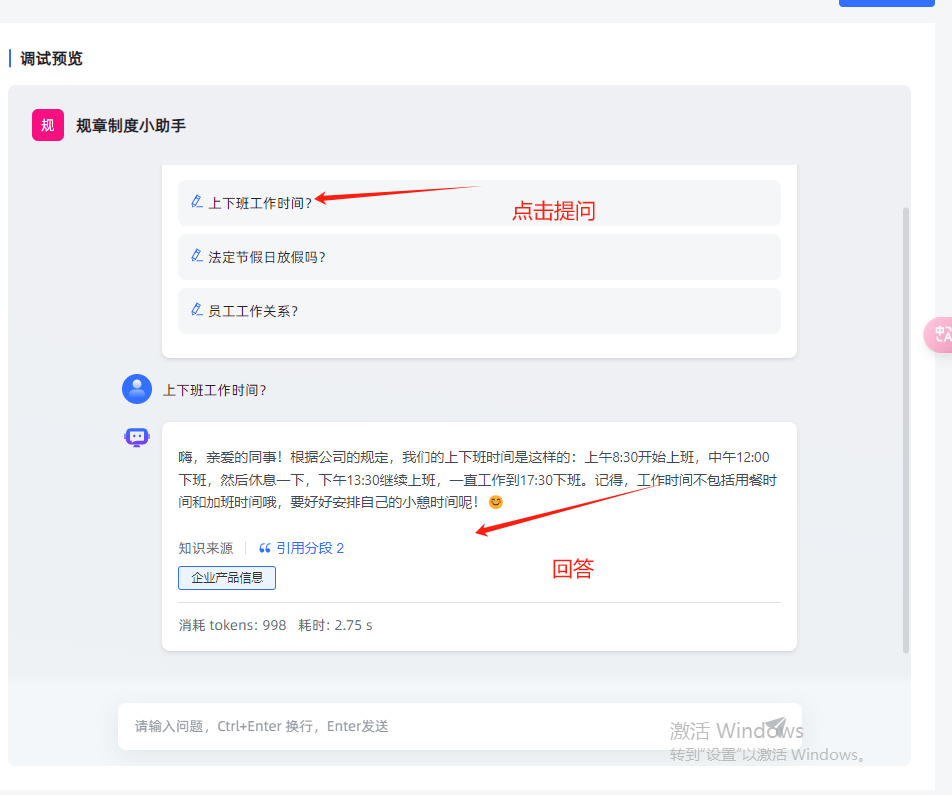
- 接着问下一个问题
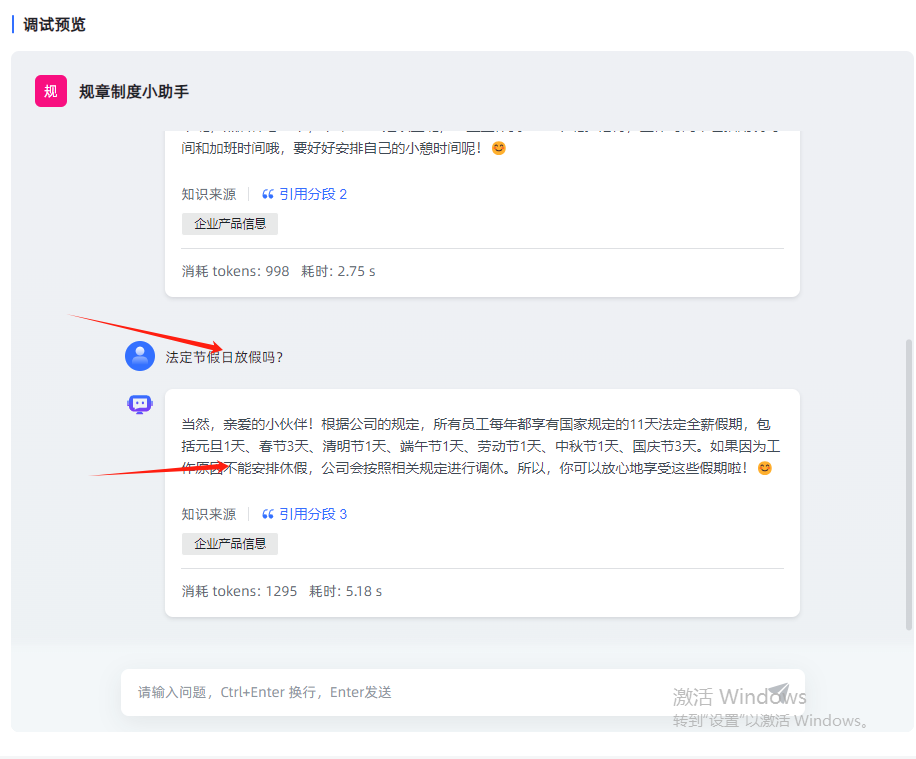
- 第三个预设问题
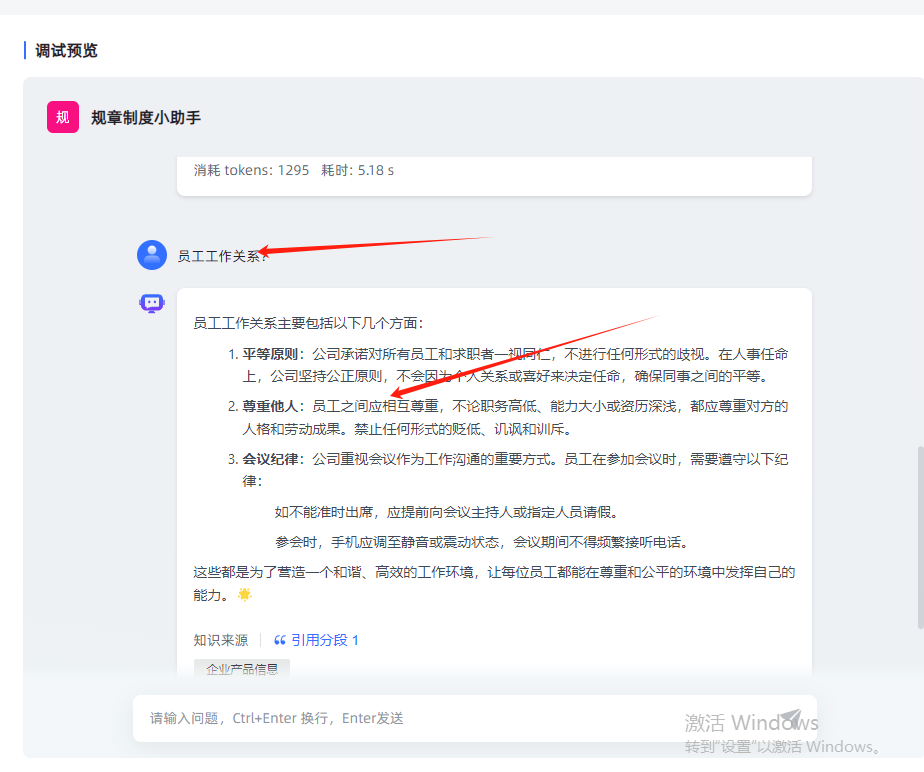
- 随机问一个复杂些的问题
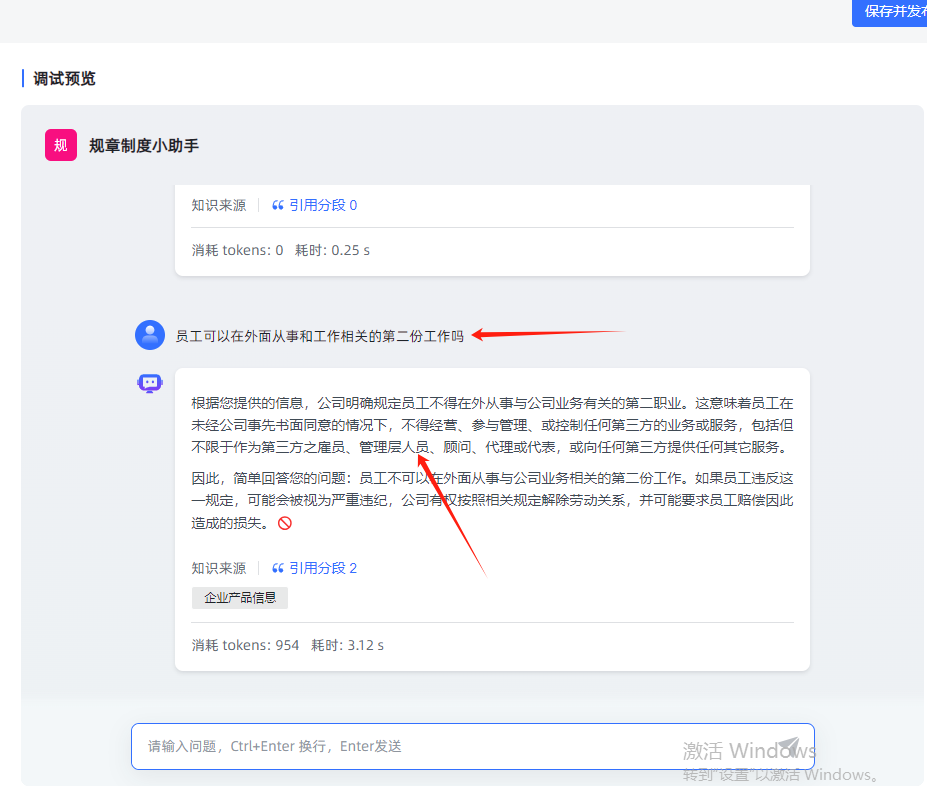
大模型落地的智能小助手,准确且幽默的回答了高频提问的3个问题,而且回答的结果都是对的。这就是大模型(RAG)的一次实际的落地应用开发。当然企业中我们的使用场景还有很多,聊天助手不过是其中的一种。
下一篇我们将会使用高级的编排工作流开发一个多场景的大模型应用,例如不仅回答员工的问题,还可以回答用户的问题,或者可以选择找客服解决问题。
小结
企业级大模型知识库开发涉及的比较的知识点多,公众号的篇幅有限,因此我决定分4个篇幅来为大家奉上!以上是大模型应用开发的第二篇上篇!
- 第一篇大模型应用开发系统环境配置
- 第二篇大模型应用知识库搭建上下篇
- 第三篇大模型应用模型及提示词优化
- 第四篇大模型应用与halo系统对接
完结
原创不易,点个关注!
不会错过后面的优质文章!
觉着写的不错的可以帮忙点点赞
关注公众号:爬虫与大模型开发
需要以上源代码的下面留言:"想要代码"
活跃在一线的爬虫工程师分享自己学习之路
我创建了爬虫与大模型开发的星球群
适合爱好爬虫及从事爬虫的同学
代码相关内容我放到了星球
本文由mdnice多平台发布