引用:
首先需要安装 plotnine
pythonfrom plotnine import* import joypy
数据可视化进阶操作
3.1 类别数据可视化
【例3-1】------绘制简单条形图
【代码框3-1】------绘制简单条形图
python
# 图3-1的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
from cvxpy import length
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
df=pd.read_csv('./pydata/example/chap03/example3_1.csv')
# 图(a)北京各项支出的水平条形图
plt.subplots(1,2,figsize=(10,4)) # 设置子图和图形大小
plt.subplot(121)
plt.barh(y=df['支出项目'],width=df['北京'],alpha=0.6) # 绘制水平条形图
plt.xlabel('支出金额',size=12)
plt.ylabel('支出项目',size=12)
plt.title('(a) 北京各项支出的水平条形图',size=15)
plt.xlim(0,19000) # 设置x轴的范围
# 为条形图添加标签(可根据需要选择)
x=df['北京']
y=df['支出项目']
for a,b in zip(x,y):plt.text(a+800, b, '%.0f'% a, # 标签位置在x值+800处
ha='center', va='bottom',color='black',fontsize=10)
# 图(b)每个地区总支出的垂直条形图
plt.subplot(122)
labels= pd.Series(['北京','天津','上海','重庆'])
h=[sum(df['北京']),sum(df['天津']),sum(df['上海']),sum(df['重庆'])] # 各地区的总支出
plt.bar(x=labels,height=h, # 绘制垂直条形图
width=0.6,alpha=0.6, # 设置条的宽度和颜色透明度
align='center')# 默认align='center',x轴标签与条形中心对齐,'edge'表示x轴标签与条形左边缘对齐
plt.xlabel('地区',size=12)
plt.ylabel('总支出',size=12)
plt.title('(b) 每个地区总支出的垂直条形图',size=15)
plt.ylim(0,55000) # 设置y轴范围
# 为条形图添加数值标签
x=labels;y=h
for a,b in zip(x,y):
plt.text(a, b+500, '%.0f'% b, # 标签位置在y值+500处
ha='center', va= 'bottom',color='black',fontsize=10)
plt.tight_layout() # 紧凑布局
plt.show()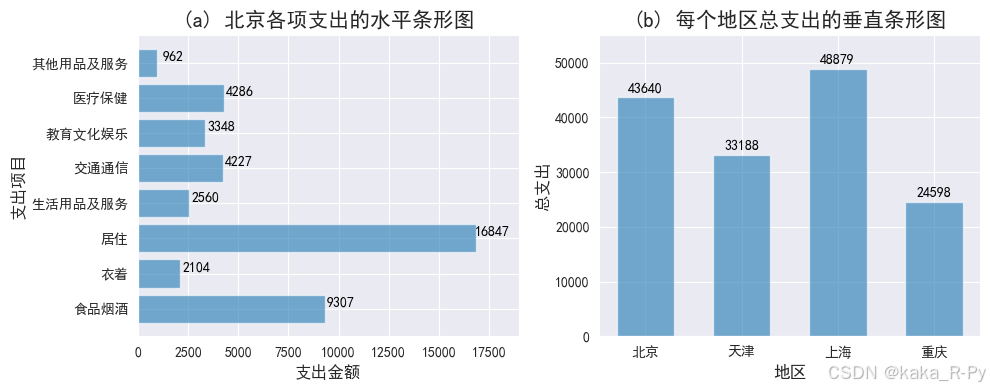
【代码框3-2】------绘制帕累托图
python
# 图3-2的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_1.csv')
# 处理数据
df=df.sort_values(by='北京', ascending=False) # 按北京支出金额降序排序数据框
p = 100*df['北京'].cumsum()/df['北京'].sum() # 计算累积百分比
df['累计百分比']=p # 在数据框中插入累计百分比列
# 绘制条形图
fig, ax = plt.subplots(figsize = (10,7)) # 设置子图和大小
ax.bar(df['支出项目'], df["北京"], color="steelblue") # 绘制条形图
ax.set_ylabel('支出金额',size=12) # 设置y轴标签
ax.set_xlabel('支出项目',size=12) # 设置x轴标签
#plt.xticks(range(8),df['支出项目'],rotation=30)
ax2 = ax.twinx() # 与条形图共享坐标轴
ax2.plot(df['支出项目'], df["累计百分比"], color="C1", marker="D", ms=7) # 绘制折线图
ax2.set_ylabel('累计百分比(%)',size=12) # 设置y轴标签
# 添加标签
for a,b in zip(df['支出项目'],df['累计百分比']):
plt.text(a, b+1, '%.0f'% b, # 标签位置在y值+1处
ha='center', va= 'bottom',color='black',fontsize=12)
plt.show()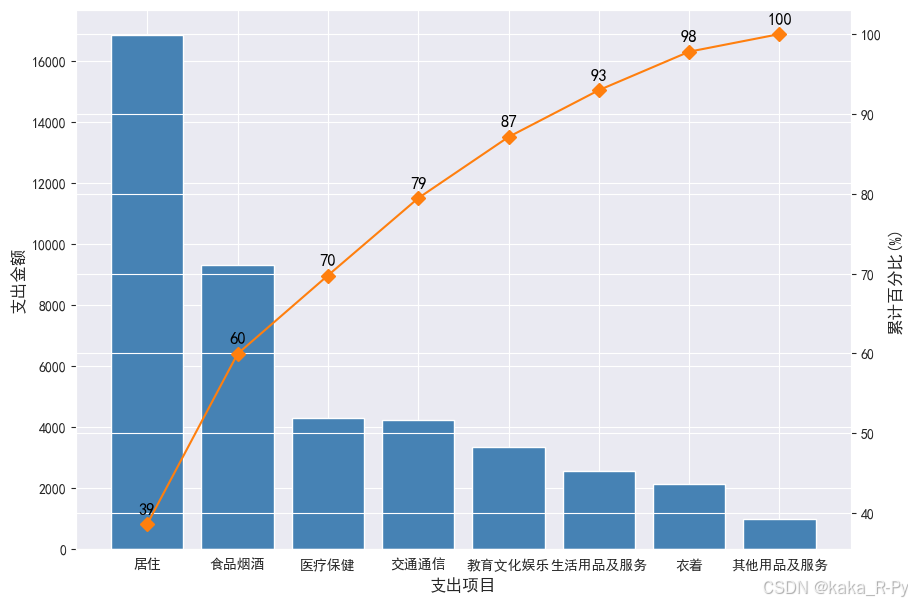
【代码框3-3】------绘制并列条形图和堆叠条形图
python
# 图3-3的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_1.csv')
plt.subplots(1,2,figsize=(10,4.2)) # 设置子图和图形大小
# 图(a)并列条形图
ax1=plt.subplot(121) # 设置子图1
df.plot(kind='bar',stacked=False,width=0.8,ax=ax1) # 绘制并列条形图
plt.xlabel('支出项目',size=12)
plt.ylabel('支出金额',size=12)
plt.xticks(range(8),df['支出项目'],rotation=30) # 添加x轴标签并设置旋转角度
plt.title('(a) 并列条形图',fontsize=13,color='black')
# 图(b)堆叠条形图
ax2=plt.subplot(122) # 设置子图2
df.plot(kind='bar',stacked=True,width=0.5,ax=ax2) # 绘制堆叠条形图
plt.xlabel('支出项目',size=12)
plt.ylabel('支出金额',size=12)
plt.xticks(range(8),df['支出项目'],rotation=30)
plt.title('(b) 堆叠条形图',fontsize=13,color='black')
plt.tight_layout() # 紧凑布局
plt.show()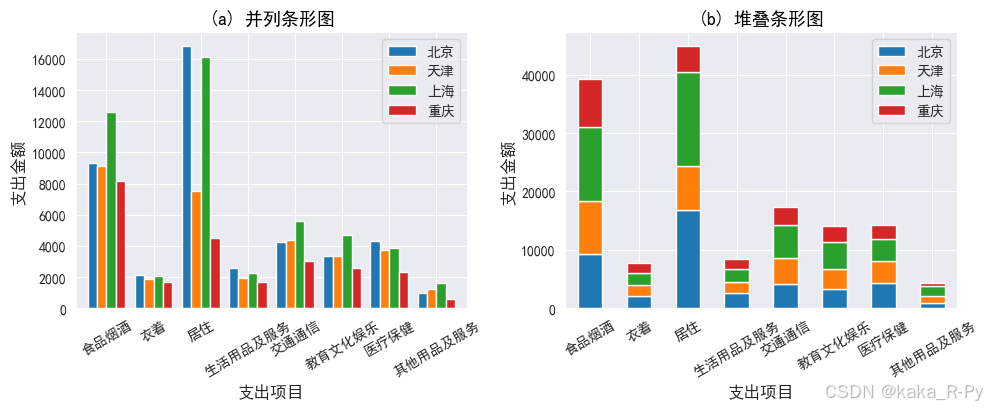
【代码框3-4】------绘制百分比条形图
python
# 图3-4的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
from plotnine import*
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_1.csv')
# 按支出项目排序并融合为长格式
my_type=pd.CategoricalDtype(categories=df['支出项目'],ordered=True) # 设置类别顺序
df['支出项目']=df['支出项目'].astype(my_type) # 转换数据框的支出项目为有序类
df= pd.melt(df, id_vars=['支出项目'],value_vars=['北京','天津', '上海','重庆'],
var_name='地区', value_name='支出比例') # 融合数据为长格式
# 绘制百分比条形图
ggplot(df,aes(x='地区',y='支出比例',fill='支出项目'))+\
geom_bar(stat='identity',color='black',alpha=1,position='fill',\
width=0.8,size=0.2)+scale_fill_brewer(palette='Reds')+\
theme_matplotlib()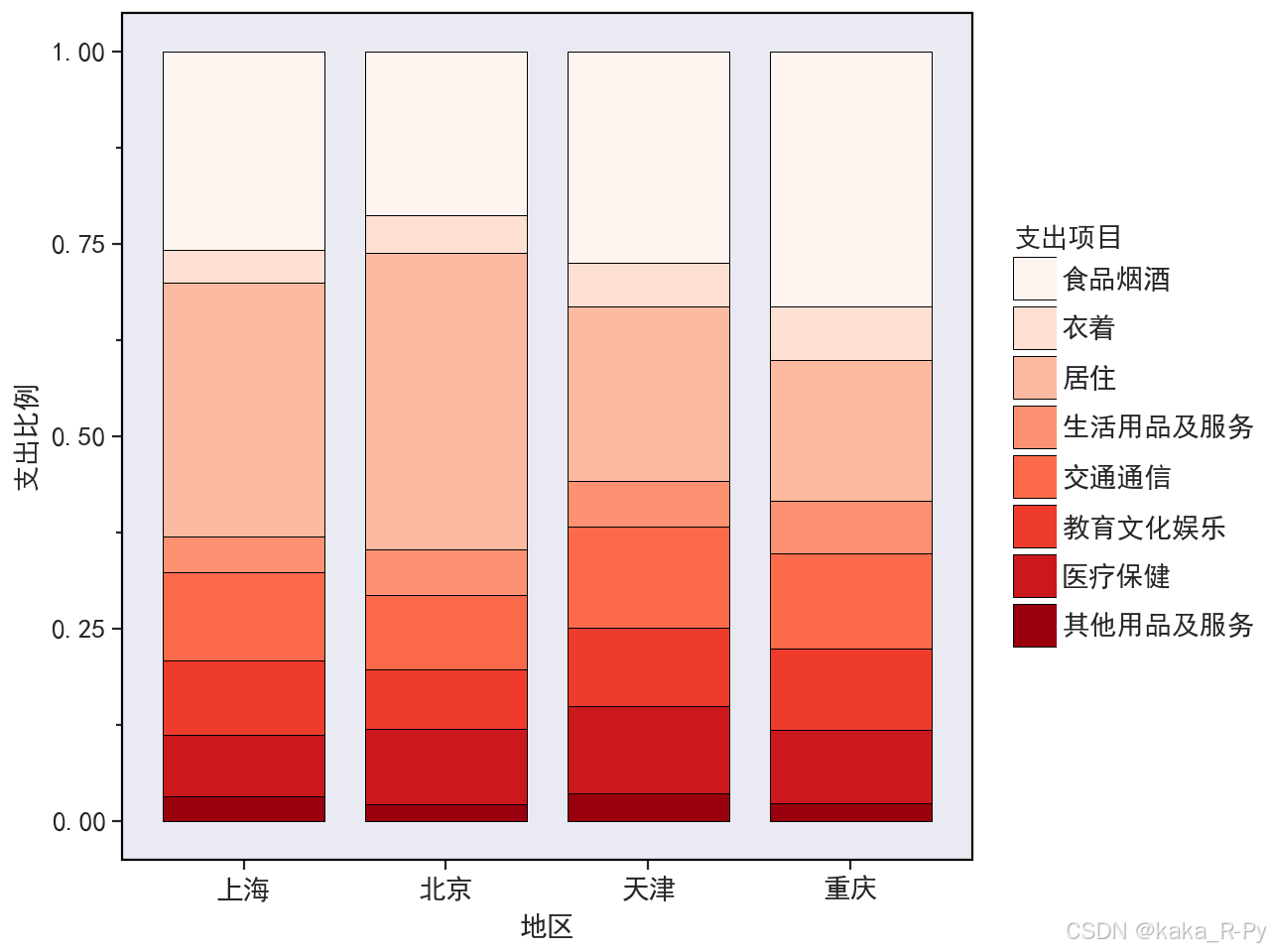
【代码框3-5】------绘制树状图
python
# 图3-5的绘制代码(以北京和上海为例)
import pandas as pd
import matplotlib.pyplot as plt
import squarify
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
example3_1= pd.read_csv('./pydata/example/chap03/example3_1.csv')
df= pd.melt(example3_1, id_vars=['支出项目'],value_vars=['北京', '上海'],
var_name='地区', value_name='支出金额') # 融合数据为长格式
#colors=sns.light_palette('brown',8) # 设置颜色
colors=sns.light_palette('steelblue',8)# 设置颜色
plt.figure(figsize=(9, 7)) # 创建图形并设置图像大小
squarify.plot(sizes=df['支出金额'], label=df['地区'],value=df['支出项目'],# 绘制地区支出的矩形
pad=True, # 画出各矩形之间的间隔size=0.5,
color=colors,alpha=1)<Axes: >

【代码框3-6】------绘制普通饼图和3D饼图
python
# 图3-6的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_1.csv')
# 图(a)绘制普通饼图(以北京为例)
plt.subplots(1,2,figsize=(9,5))
plt.subplot(121)
p1=plt.pie(df['北京'],labels=df['支出项目'],
autopct='%1.2f%%') # 显示数据标签为百分比格式,%1.2f表示保留2位小数
plt.title('(a) 2021年北京\n居民人均消费支出的普通饼图',size=13)
# 图(b)绘制3D饼图(以上海为例)
plt.subplot(122)
p2=plt.pie(df['上海'],labels=df['支出项目'],autopct='%1.2f%%',
shadow=True, # 绘制立体带阴影的饼图
explode=(0.11,0,0,0,0,0,0,0)) # 设置某一块与中心的距离
plt.title('(b) 2021年上海\n居民人均消费支出的3D饼图',size=13)
plt.subplots_adjust(wspace=0.1) #调整子图的间距
plt.tight_layout()
plt.show()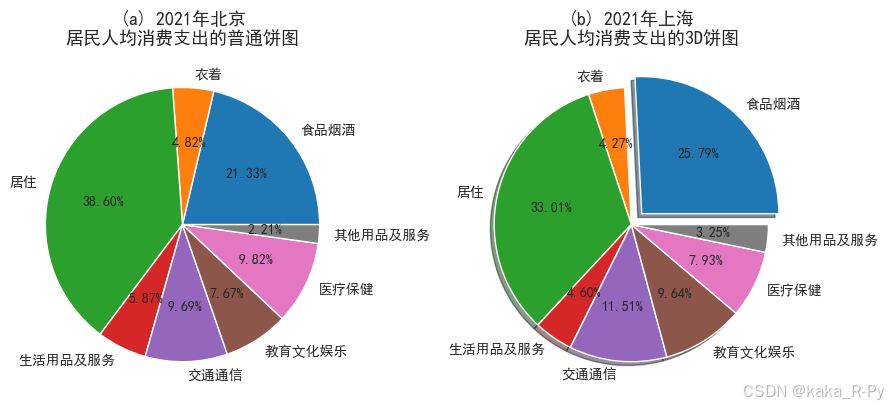
【代码框3-7】------绘制环形图
python
# 图3-7的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
df= pd.read_csv('./pydata/example/chap03/example3_1.csv')
# 图(a) 绘制单样本环形图(以北京的各项支出为例)
plt.subplots(1,2,figsize=(10,8))
plt.subplot(121)
p1=plt.pie(df['北京'],labels=df['支出项目'],startangle=0,
autopct='%1.2f%%',pctdistance=0.8,
wedgeprops={'width':0.5,'edgecolor':'w'}) # 环的宽度为0.5,边线颜色为白色
plt.title('(a) 北京各项支出的环形图',size=13)
# 图(b) 绘制多样本嵌套环形图(以北京、上海和天津为例)
plt.subplot(122)
colors=['red','yellow','slateblue','lawngreen','magenta',
'green','orange','cyan','pink','gold'] # 设置颜色向量
p2=plt.pie(df['北京'],labels=df['支出项目'],autopct='%1.2f%%',
radius=1,pctdistance=0.9, # 半径为1,标签距圆心距离为0.85
colors=colors,
wedgeprops=dict(linewidth=1.2,width=0.3,edgecolor='w'))
p3=plt.pie(df['上海'],autopct='%1.2f%%',
radius=0.75,pctdistance=0.85,colors=colors,
wedgeprops=dict(linewidth=1,width=0.3,edgecolor='w'))
p4=plt.pie(df['天津'],autopct='%1.2f%%',
radius=0.5,pctdistance=0.7,colors=colors,
wedgeprops=dict(linewidth=1,width=0.3,edgecolor='w'))
plt.title('(b) 北京、上海和天津各项支出的环形图',size=13)
plt.tight_layout()
plt.show()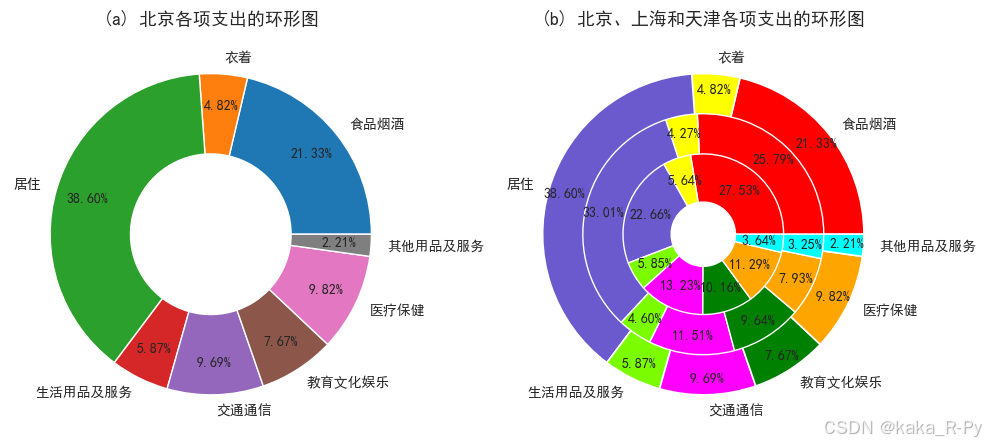
3.2 数据分布可视化
【例3-2】------绘制直方图
【代码框3-8】------绘制直方图
python
# 图3-8的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_2.csv')
plt.subplots(2,3,figsize=(9,5))
plt.subplot(231)
sns.histplot(df['北京'],element='bars') # 默认绘制,直方图为条形,y轴为计数(观测频数)
plt.title('(a) 默认绘制(y轴为频数)')
plt.subplot(232)
sns.histplot(df['上海'],kde=True, # 显示核密度曲线
stat='frequency') # y轴为频率(观测频数除以箱宽,即频数除以组距)
plt.title('(b) 显示核密度曲线(y轴为频率)')
plt.subplot(233)
sns.histplot(df['郑州'],bins=20, # 分成20组(箱子个数)
kde=True,stat= "density") # y轴为密度(直方图的面积为1)
plt.title('(c) 分成20组(y轴为密度)')
plt.subplot(234)
sns.histplot(df['武汉'],bins=30,kde=True,stat="probability") # y轴为概率,条的高度之和为1
plt.title('(d) 分成30组(y轴为概率)')
plt.subplot(235)
sns.histplot(df['西安'],bins=30,kde=True,stat= "density",element='poly')# 直方图为多边形
plt.title('(e) 直方图为多边形')
plt.subplot(236)
sns.histplot(df['沈阳'],bins=30,kde=True,stat= "density",element='step')# 直方图为阶梯状
plt.title('(f) 直方图为阶梯状')
plt.tight_layout()
plt.show()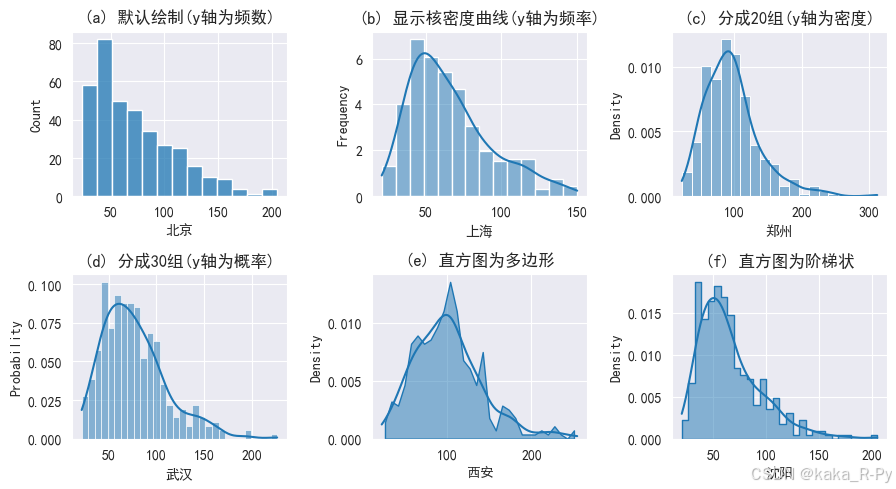
【图3-9】------绘制核密度图(bw的影响)---不放在书中
python
# 图3-9的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df= pd.read_csv('./pydata/example/chap03/example3_2.csv')
#sns.set_style('darkgrid') # 设置画图风格
plt.subplots(1,3,figsize=(8,2.5))
plt.subplot(131)
sns.kdeplot(df['北京'],bw_adjust=0.2)
plt.title('(a) bw_adjust = 0.2')
plt.subplot(132)
sns.kdeplot(df['北京'],bw_adjust=0.5)
plt.title('(b) bw_adjust = 0.5')
plt.subplot(133)
sns.kdeplot(x='北京',data=df,bw_method=0.5)
plt.title('(c) bw_method = 0.5')
plt.subplots_adjust(wspace=0.5) #调整子图的间距
plt.tight_layout()
plt.show()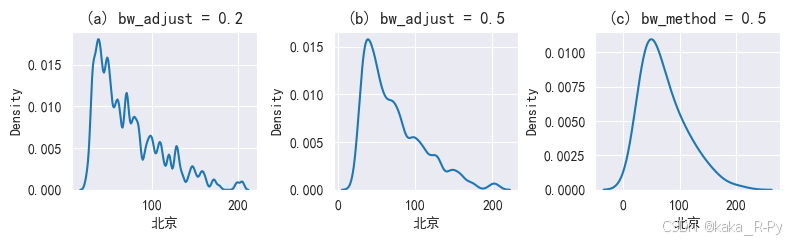
【代码框3-9】------绘制核密度图
python
# 图3-10的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Set font and other configurations for the plots
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read the data from the CSV file
example3_2 = pd.read_csv('./pydata/example/chap03/example3_2.csv')
# Transform the data into a long format
df = pd.melt(example3_2, value_vars=['北京', '上海', '郑州', '武汉', '西安', '沈阳'],
var_name='城市', value_name='AQI')
# Create subplots
plt.subplots(1, 2, figsize=(9, 3.5))
# Plot the first KDE plot without shading
plt.subplot(121)
sns.kdeplot(data=df, x='AQI', hue='城市', linewidth=0.6)
plt.title('(a) 曲线下无填充')
# Plot the second KDE plot with shading
plt.subplot(122)
sns.kdeplot(data=df, x='AQI', hue='城市', fill=True, alpha=0.2, linewidth=0.7)
plt.title('(b) 曲线下填充阴影')
# Adjust layout and show the plots
plt.tight_layout()
plt.show()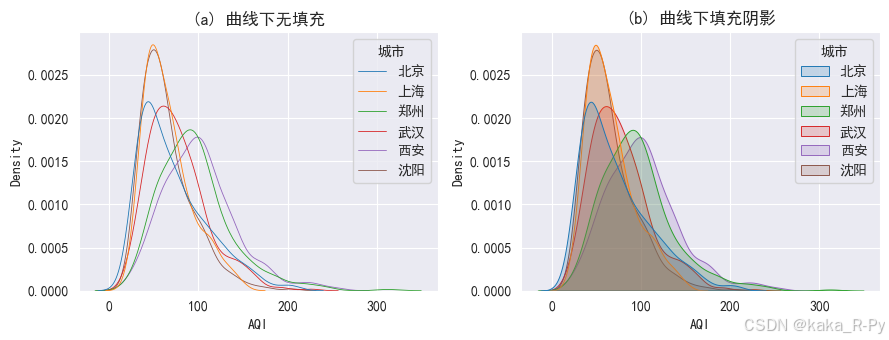
【代码框3-10】------6个城市AQI的核密度脊线图(山峦图)
python
# 图3-11的绘制代码
# 使用joypy包中的joyplot函数绘制按因子分类的核密度脊线图
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import cm
import joypy
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
example3_2 = pd.read_csv('./pydata/example/chap03/example3_2.csv')
df = pd.melt(example3_2, value_vars=['北京', '上海', '郑州', '武汉', '西安', '沈阳'],
var_name='城市', value_name='AQI') # Set observed=False
my_type = pd.CategoricalDtype(categories=['北京', '上海', '郑州', '武汉', '西安', '沈阳'], ordered=True)
df['城市'] = df['城市'].astype(my_type)
p = joypy.joyplot(df, column=['AQI'], by='城市', ylim='own',
colormap=cm.Spectral, alpha=0.6, figsize=(6, 5), grid=False)
plt.xlabel('AQI', fontsize=12)
plt.show()
# colormap=cm.Reds------cm.Spectral------Set2_可用颜色
#df.loc[[1,8,3],['北京','沈阳']] # 同时选择行和列D:\python\Lib\site-packages\joypy\joyplot.py:176: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.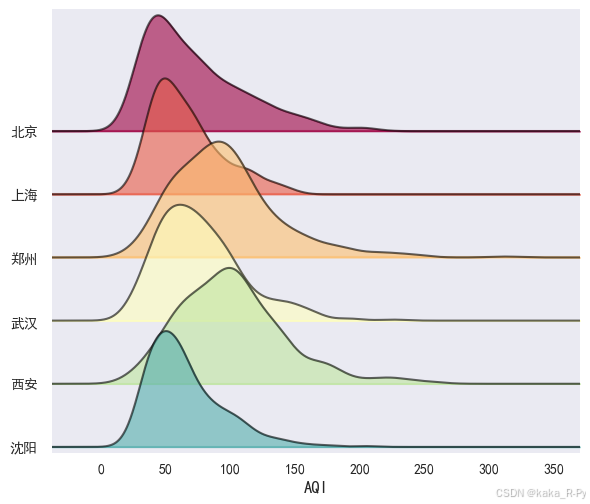
【代码框3-11】------绘制箱形图
python
# 图3-14的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
example3_2= pd.read_csv('./pydata/example/chap03/example3_2.csv')
df= pd.melt(example3_2, value_vars=['北京', '上海', '郑州','武汉','西安','沈阳'],
var_name='城市', value_name='AQI') # 融合数据
plt.figure(figsize=(8, 5))
sns.boxplot(data=df,x='城市',y='AQI',
width=0.6,linewidth=1.5, # 设置箱子的宽度和线宽
saturation=0.9, # 设置颜色的原始饱和度比例。1表示完全饱和
fliersize=3, # 设置离群点标记的大小
notch=False, # 设置notch可绘制出箱子的凹槽
palette="Set2", # 设置调色板
orient="v",hue='城市',legend=False) # 如果变量是在行的位置,可设置orient="h",绘制水平箱线图
plt.show()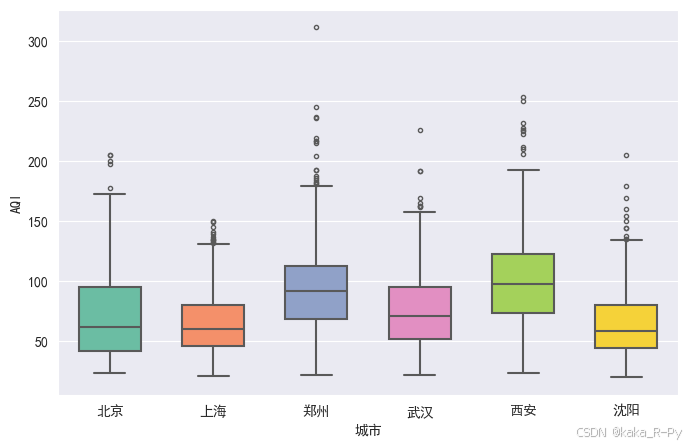
python
?sns.violinplot
'''
Signature:
sns.violinplot(
data=None,
*,
x=None,
y=None,
hue=None,
order=None,
hue_order=None,
orient=None,
color=None,
palette=None,
saturation=0.75,
fill=True,
inner='box',
split=False,
width=0.8,
dodge='auto',
gap=0,
linewidth=None,
linecolor='auto',
cut=2,
gridsize=100,
bw_method='scott',
bw_adjust=1,
density_norm='area',
common_norm=False,
hue_norm=None,
formatter=None,
log_scale=None,
native_scale=False,
legend='auto',
scale=<deprecated>,
scale_hue=<deprecated>,
bw=<deprecated>,
inner_kws=None,
ax=None,
**kwargs,
)
Docstring:
Draw a patch representing a KDE and add observations or box plot statistics.
A violin plot plays a similar role as a box-and-whisker plot. It shows the
distribution of data points after grouping by one (or more) variables.
Unlike a box plot, each violin is drawn using a kernel density estimate
of the underlying distribution.
See the :ref:`tutorial <categorical_tutorial>` for more information.
.. note::
By default, this function treats one of the variables as categorical
and draws data at ordinal positions (0, 1, ... n) on the relevant axis.
As of version 0.13.0, this can be disabled by setting `native_scale=True`.
Parameters
----------
data : DataFrame, Series, dict, array, or list of arrays
Dataset for plotting. If `x` and `y` are absent, this is
interpreted as wide-form. Otherwise it is expected to be long-form.
x, y, hue : names of variables in `data` or vector data
Inputs for plotting long-form data. See examples for interpretation.
order, hue_order : lists of strings
Order to plot the categorical levels in; otherwise the levels are
inferred from the data objects.
orient : "v" | "h" | "x" | "y"
Orientation of the plot (vertical or horizontal). This is usually
inferred based on the type of the input variables, but it can be used
to resolve ambiguity when both `x` and `y` are numeric or when
plotting wide-form data.
.. versionchanged:: v0.13.0
Added 'x'/'y' as options, equivalent to 'v'/'h'.
color : matplotlib color
Single color for the elements in the plot.
palette : palette name, list, or dict
Colors to use for the different levels of the ``hue`` variable. Should
be something that can be interpreted by :func:`color_palette`, or a
dictionary mapping hue levels to matplotlib colors.
saturation : float
Proportion of the original saturation to draw fill colors in. Large
patches often look better with desaturated colors, but set this to
`1` if you want the colors to perfectly match the input values.
fill : bool
If True, use a solid patch. Otherwise, draw as line art.
.. versionadded:: v0.13.0
inner : {"box", "quart", "point", "stick", None}
Representation of the data in the violin interior. One of the following:
- `"box"`: draw a miniature box-and-whisker plot
- `"quart"`: show the quartiles of the data
- `"point"` or `"stick"`: show each observation
split : bool
Show an un-mirrored distribution, alternating sides when using `hue`.
.. versionchanged:: v0.13.0
Previously, this option required a `hue` variable with exactly two levels.
width : float
Width allotted to each element on the orient axis. When `native_scale=True`,
it is relative to the minimum distance between two values in the native scale.
dodge : "auto" or bool
When hue mapping is used, whether elements should be narrowed and shifted along
the orient axis to eliminate overlap. If `"auto"`, set to `True` when the
orient variable is crossed with the categorical variable or `False` otherwise.
.. versionchanged:: 0.13.0
Added `"auto"` mode as a new default.
gap : float
Shrink on the orient axis by this factor to add a gap between dodged elements.
.. versionadded:: 0.13.0
linewidth : float
Width of the lines that frame the plot elements.
linecolor : color
Color to use for line elements, when `fill` is True.
.. versionadded:: v0.13.0
cut : float
Distance, in units of bandwidth, to extend the density past extreme
datapoints. Set to 0 to limit the violin within the data range.
gridsize : int
Number of points in the discrete grid used to evaluate the KDE.
bw_method : {"scott", "silverman", float}
Either the name of a reference rule or the scale factor to use when
computing the kernel bandwidth. The actual kernel size will be
determined by multiplying the scale factor by the standard deviation of
the data within each group.
.. versionadded:: v0.13.0
bw_adjust: float
Factor that scales the bandwidth to use more or less smoothing.
.. versionadded:: v0.13.0
density_norm : {"area", "count", "width"}
Method that normalizes each density to determine the violin's width.
If `area`, each violin will have the same area. If `count`, the width
will be proportional to the number of observations. If `width`, each
violin will have the same width.
.. versionadded:: v0.13.0
common_norm : bool
When `True`, normalize the density across all violins.
.. versionadded:: v0.13.0
hue_norm : tuple or :class:`matplotlib.colors.Normalize` object
Normalization in data units for colormap applied to the `hue`
variable when it is numeric. Not relevant if `hue` is categorical.
.. versionadded:: v0.12.0
formatter : callable
Function for converting categorical data into strings. Affects both grouping
and tick labels.
.. versionadded:: v0.13.0
log_scale : bool or number, or pair of bools or numbers
Set axis scale(s) to log. A single value sets the data axis for any numeric
axes in the plot. A pair of values sets each axis independently.
Numeric values are interpreted as the desired base (default 10).
When `None` or `False`, seaborn defers to the existing Axes scale.
.. versionadded:: v0.13.0
native_scale : bool
When True, numeric or datetime values on the categorical axis will maintain
their original scaling rather than being converted to fixed indices.
.. versionadded:: v0.13.0
legend : "auto", "brief", "full", or False
How to draw the legend. If "brief", numeric `hue` and `size`
variables will be represented with a sample of evenly spaced values.
If "full", every group will get an entry in the legend. If "auto",
choose between brief or full representation based on number of levels.
If `False`, no legend data is added and no legend is drawn.
.. versionadded:: v0.13.0
scale : {"area", "count", "width"}
.. deprecated:: v0.13.0
See `density_norm`.
scale_hue : bool
.. deprecated:: v0.13.0
See `common_norm`.
bw : {'scott', 'silverman', float}
.. deprecated:: v0.13.0
See `bw_method` and `bw_adjust`.
inner_kws : dict of key, value mappings
Keyword arguments for the "inner" plot, passed to one of:
- :class:`matplotlib.collections.LineCollection` (with `inner="stick"`)
- :meth:`matplotlib.axes.Axes.scatter` (with `inner="point"`)
- :meth:`matplotlib.axes.Axes.plot` (with `inner="quart"` or `inner="box"`)
Additionally, with `inner="box"`, the keywords `box_width`, `whis_width`,
and `marker` receive special handling for the components of the "box" plot.
.. versionadded:: v0.13.0
ax : matplotlib Axes
Axes object to draw the plot onto, otherwise uses the current Axes.
kwargs : key, value mappings
Keyword arguments for the violin patches, passsed through to
:meth:`matplotlib.axes.Axes.fill_between`.
Returns
-------
ax : matplotlib Axes
Returns the Axes object with the plot drawn onto it.
See Also
--------
boxplot : A traditional box-and-whisker plot with a similar API.
stripplot : A scatterplot where one variable is categorical. Can be used
in conjunction with other plots to show each observation.
swarmplot : A categorical scatterplot where the points do not overlap. Can
be used with other plots to show each observation.
catplot : Combine a categorical plot with a :class:`FacetGrid`.
Examples
--------
.. include:: ../docstrings/violinplot.rst
File: d:\python\lib\site-packages\seaborn\categorical.py
Type: function
'''【代码框3-12】------绘制小提琴图
python
# 图3-15的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#sns.set_style('darkgrid')
example3_2= pd.read_csv('./pydata/example/chap03/example3_2.csv')
df= pd.melt(example3_2, value_vars=['北京', '上海', '郑州','武汉','西安','沈阳'],
var_name='城市', value_name='AQI') # 融合数据
plt.figure(figsize=(8, 5))
sns.violinplot(data=df,x='城市',y='AQI',
density_norm='width', # 默认
width=1,linewidth=2, # 设置小提琴的宽度和线宽
saturation=0.9, # 设置颜色饱和度,1表示完全饱和
palette="Set2", # 设置调色板
#小提琴图内部距离箱线图的距离
split=False, # 设置为True,绘制分割的小提琴图
orient="v", # 设置为水平箱线图
inner='box',hue='城市') # 小提琴图内部绘制箱线图(默认)
plt.show()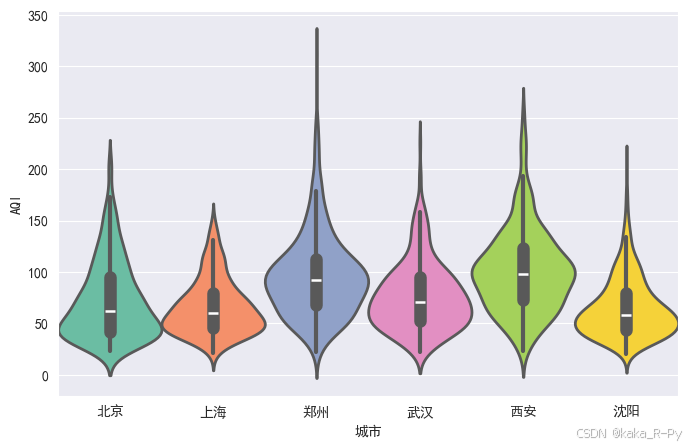
【代码框3-13】------绘制点图
python
# 图3-16的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
example3_2= pd.read_csv('./pydata/example/chap03/example3_2.csv')
df= pd.melt(example3_2, value_vars=['北京', '上海', '郑州','武汉','西安','沈阳'],
var_name='城市', value_name='AQI')
plt.subplots(1,2,figsize=(8, 3.5))
plt.subplot(121)
sns.stripplot(data=df,x='城市',y='AQI',
jitter=False, # 不扰动数据
size=3) # 设置点的大小
plt.title('(a) 原始数据的点图')
plt.subplot(122)
sns.stripplot(data=df,x='城市',y='AQI',jitter=True,size=2)
plt.title('(b) 数据扰动后的点图')
#plt.subplots_adjust(wspace=0.5) #调整两幅子图的间距
plt.tight_layout()
plt.show()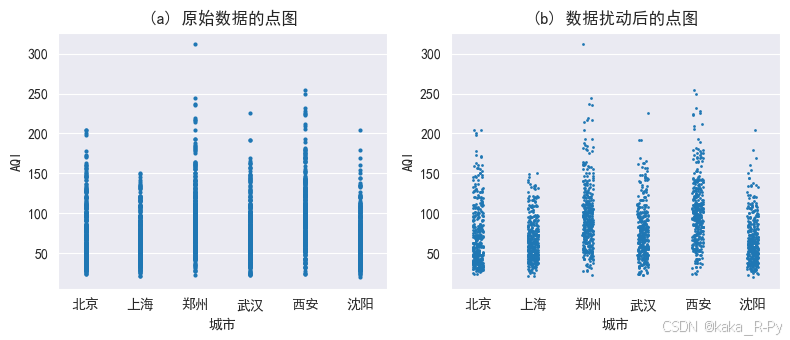
【代码框3-14】------绘制6个城市AQI的蜂群图(beeswarm chart)
python
# 图3-17的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
example3_2= pd.read_csv('./pydata/example/chap03/example3_2.csv')
df= pd.melt(example3_2, value_vars=['北京', '上海', '郑州','武汉','西安','沈阳'],
var_name='城市', value_name='AQI')
plt.subplots(1,2,figsize=(8, 8))
plt.subplot(211)
# 图(a)蜂群图
sns.swarmplot(x='城市',y='AQI',size=2,data=df) # 绘制蜂群图
plt.title('(a) 蜂群图')
# 图(b)小提琴图+蜂群图
plt.subplot(212)
sns.violinplot(data=df,x='城市',y='AQI', # 绘制小提琴图
width=0.8,linewidth=0.8, # 设置小提琴的宽度和线宽
saturation=0.9, # 设置颜色饱和度
palette="Set2", # 设置调色板
inner='box',hue='城市',legend=False) # 小提琴图内部绘制箱线图(默认)
sns.swarmplot(x='城市',y='AQI',size=2,color='black',alpha=0.6, data=df)
plt.title('(b) 小提琴图+蜂群图')
plt.tight_layout()
plt.show()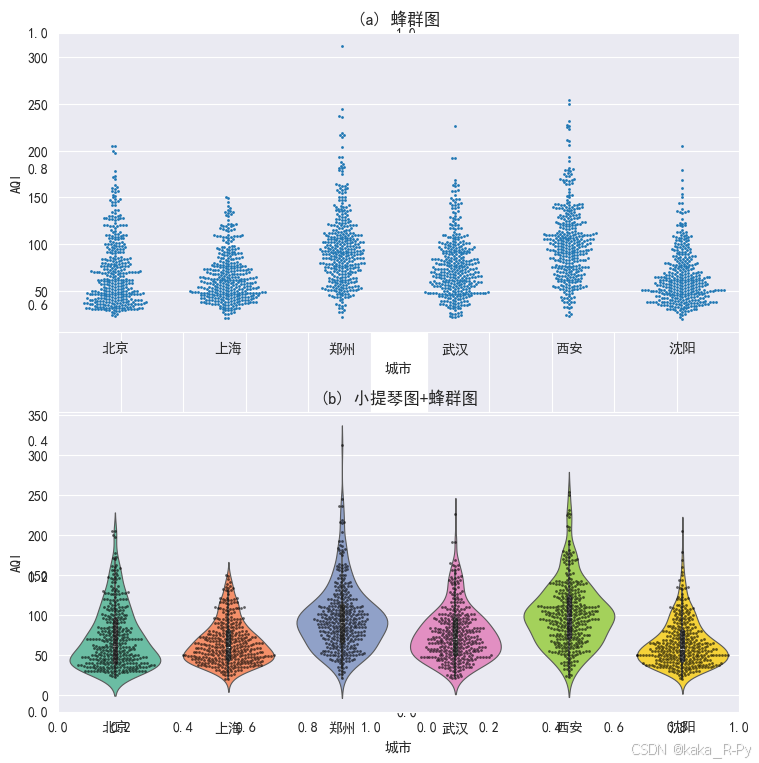
3.3 变量间关系可视化
【例3-3】------绘制散点图和散点图矩阵函数(sns.regplot)
【代码框3-15】------绘制散点图(函数sns.regplot)
python
## 图3-19的绘制代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df= pd.read_csv('./pydata/example/chap03/example3_3.csv')
plt.subplots(1,2,figsize=(8, 3.3))
# (a)普通散点图
plt.subplot(121)
sns.regplot(x=df['地区生产总值'],y=df['地方财政税收收入'],
fit_reg=False,marker='+',data=df)
plt.title('(a) 普通散点图')
# (b)添加回归线和置信带的散点图
plt.subplot(122)
sns.regplot(data=df,x=df['地区生产总值'],y=df['地方财政税收收入'],
fit_reg=True,marker='+') # 添加回归线
plt.title('(b) 添加回归线和置信带的散点图')
plt.tight_layout()
plt.show()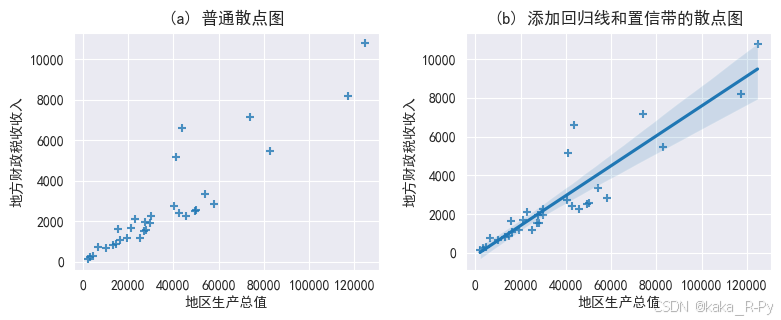
python
【代码框3-16】------绘制带有边际图的散点图
python
# 图3-20的绘制代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df= pd.read_csv('./pydata/example/chap03/example3_3.csv')
# (a)绘制带回归线和置信带的散点图
sns.jointplot(data=df,x=df['地区生产总值'],y=df['地方财政税收收入'],marker='*',
kind='reg', # 绘制回归线和置信带
height=4, # 设置图形的高度(正方形)
ratio=5) # 设置主图高度与边际图高度的比
# (b)绘制六边形分箱散点图
sns.jointplot(data=df,x=df['地区生产总值'],y=df['地方财政税收收入'],
kind='hex', height=4,ratio=5)
plt.show()
### 其他可选如(备用)
# sns.jointplot(x=df['总股本'],y=df['每股收益'],kind='scatter',data=df) # 添加边际图
# sns.jointplot(x=df['总股本'],y=df['每股收益'],kind='kde', data=df) # 二维核密度图
# sns.jointplot(x=df['总股本'],y=df['每股收益'],kind='hist', data=df) # 二维直方图
#sns.jointplot(x=df['总股本'],y=df['每股收益'],kind='resid',data=df) # 残差图

python
# 可选项:{ "scatter" | "kde" | "hist" | "hex" | "reg" | "resid" }【代码框3-17】------绘制 散点图矩阵
python
## 图3-21的绘制代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df= pd.read_csv('./pydata/example/chap03/example3_3.csv')
sns.pairplot(df[['地区生产总值','地方财政税收收入','社会消费品零售总额','年末总人口']],
height=2, # 设置子图的高度
diag_kind='kde', # 设置对角线的图形类型(默认为直方图)
markers='.', # 设置点型
kind='reg') # 设置子图类型,默认为scatter
plt.show()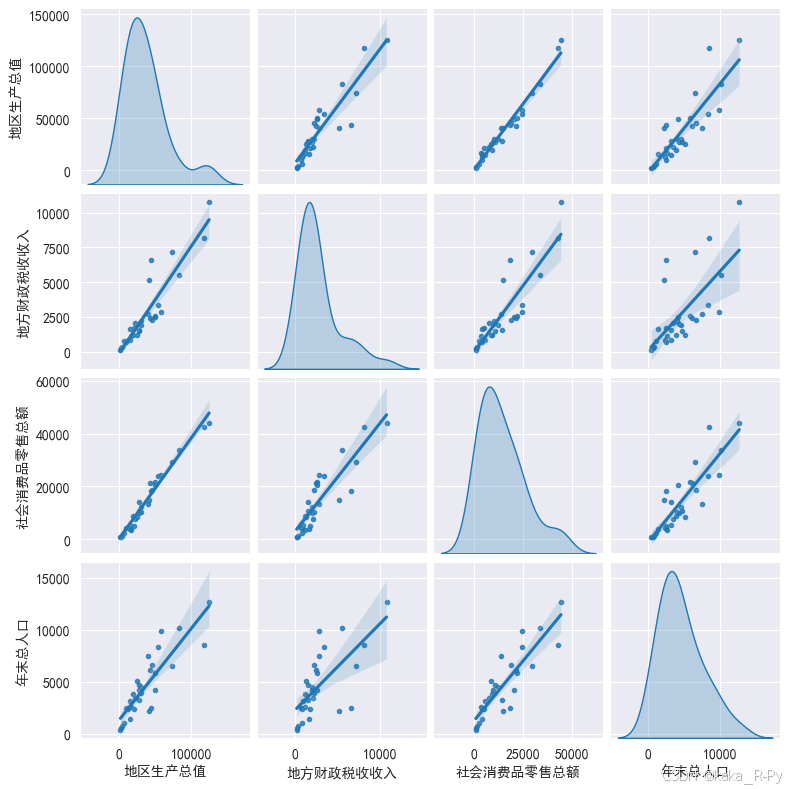
【代码框3-18】------绘制 散点图矩阵
python
# 图3-22的绘制代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Set font and other configurations for the plots
plt.rcParams['font.sans-serif'] = ['SimHei'] # Display Chinese characters
plt.rcParams['axes.unicode_minus'] = False # Display minus sign
# Read the data from the CSV file
df = pd.read_csv('./pydata/example/chap03/example3_3.csv')
# Set the figure size
plt.figure(figsize=(8, 6))
# Calculate the correlation matrix
df = df[['地区生产总值', '地方财政税收收入', '社会消费品零售总额', '年末总人口']]
corr = df.corr()
# Plot the heatmap
sns.heatmap(corr, cmap='Reds', alpha=0.8, annot=True, fmt='.4')
# Show the plot
plt.show()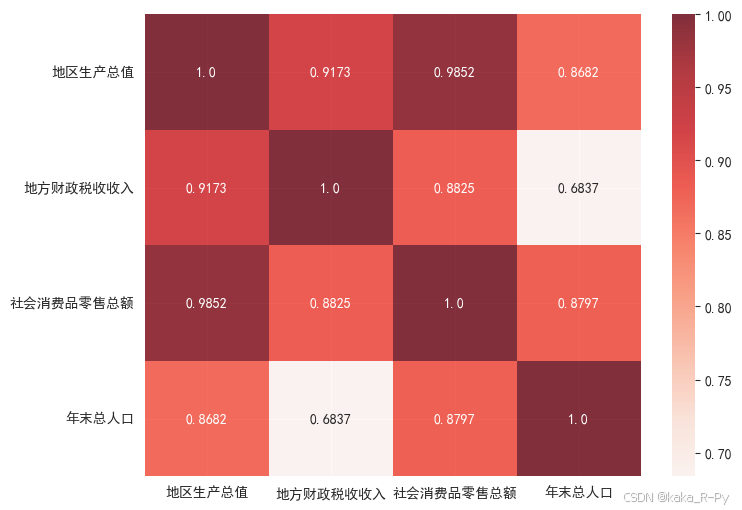
【代码框3-19】------3D散点图
python
# 图3-23的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df= pd.read_csv('./pydata/example/chap03/example3_3.csv')
ax3d=plt.figure(figsize=(25,16)).add_subplot(111,projection='3d')
ax3d.scatter(df['地区生产总值'],df['地方财政税收收入'],df['社会消费品零售总额'],
color='black',marker='*',s=50)
ax3d.set_xlabel('x = 地区生产总值',fontsize=12)
ax3d.set_ylabel('y = 地方财政税收收入',fontsize=12)
ax3d.set_zlabel('z = 社会消费品零售总额',fontsize=12)
plt.show()
【代码框3-20】------绘制气泡图
python
## 图3-25的绘制代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df= pd.read_csv('./pydata/example/chap03/example3_3.csv')
plt.figure(figsize=(8, 4.8))
plt.scatter(data=df,x='地区生产总值',y='地方财政税收收入',
c='社会消费品零售总额', # 设置气泡变量
s=df['社会消费品零售总额']/80, # 设置气泡大小
cmap='Blues', # 设置调色板
edgecolors='k', # 设置气泡边线的颜色
linewidths=0.5, # 设置气泡边线的宽度
alpha=0.6) # 设置颜色透明度
plt.colorbar() # 绘制表示总股本的颜色条(图例)
plt.xlabel('地区生产总值',fontsize=12)
plt.ylabel('地方财政税收收入',fontsize=12)
plt.title('社会消费品零售总额=气泡的大小',fontsize=13)Text(0.5, 1.0, '社会消费品零售总额=气泡的大小')
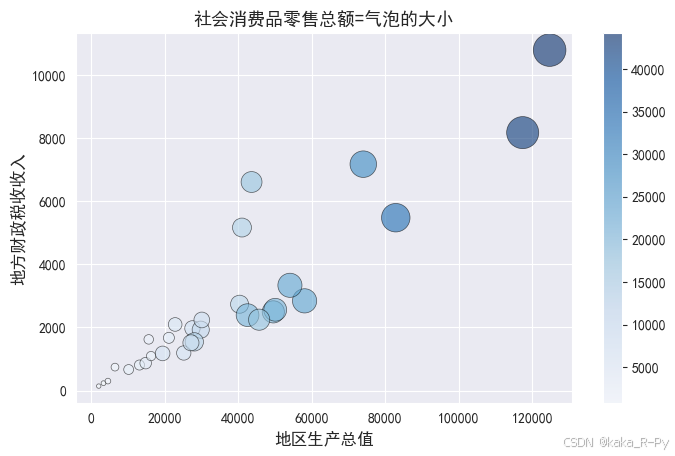
3.4 样本相似性可视化
【例3-4】------绘制平行坐标图
【代码框3-21】------绘制平行坐标图
python
# 图3-26的绘制代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_1.csv')
plt.figure(figsize=(8, 5))
dfs=[df['北京'],df['天津'],df['上海'],df['重庆']]
sns.lineplot(data=dfs,markers=True)
plt.xlabel('支出项目',size=12)
plt.ylabel('支出金额',size=12)
plt.xticks(range(8),df['支出项目']) # 添加x轴标签([<matplotlib.axis.XTick at 0x2b101e8d3d0>,
<matplotlib.axis.XTick at 0x2b101e83ed0>,
<matplotlib.axis.XTick at 0x2b101aed090>,
<matplotlib.axis.XTick at 0x2b101ecea90>,
<matplotlib.axis.XTick at 0x2b101ed8d50>,
<matplotlib.axis.XTick at 0x2b101edb050>,
<matplotlib.axis.XTick at 0x2b1020c9bd0>,
<matplotlib.axis.XTick at 0x2b101ee1450>],
[Text(0, 0, '食品烟酒'),
Text(1, 0, '衣着'),
Text(2, 0, '居住'),
Text(3, 0, '生活用品及服务'),
Text(4, 0, '交通通信'),
Text(5, 0, '教育文化娱乐'),
Text(6, 0, '医疗保健'),
Text(7, 0, '其他用品及服务')])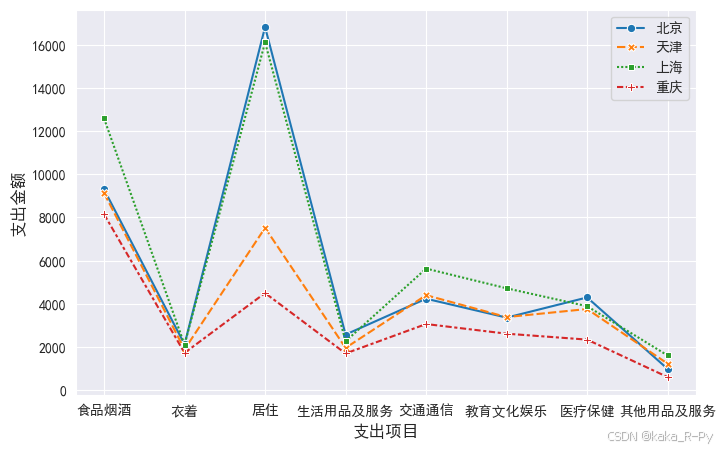
【例3-5】------绘制雷达图
【代码框3-22】------绘制雷达图
python
# 图3-27的绘制代码(转置数据df.T)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['patch.force_edgecolor'] = True
df= pd.read_csv('./pydata/example/chap03/df.T.csv') # 数据已转置
# 创建角度
attributes=list(df.columns[1:])
values=list(df.values[:,1:])
names=list(df.values[:,0])
angles=[n / float(len(attributes)) * 2 * np.pi for n in range(len(attributes))]
# 关闭画图
angles += angles[:1]
values=np.asarray(values)
values=np.concatenate([values,values[:,0:1]],axis=1)
# 创建图形
#sns.set_style('darkgrid') # 设置图形风格
plt.figure(figsize=(8,8))
for i in range(4):
ax=plt.subplot(2,2,i+1,polar=True)
ax.plot(angles,values[i] ,marker='o',markersize=5)
ax.set_yticks(np.arange(500,16000,3500))
ax.set_xticks(angles[:-1])
ax.set_xticklabels(attributes)
ax.set_title(names[i],fontsize=12,color='red')
plt.tight_layout()
plt.show()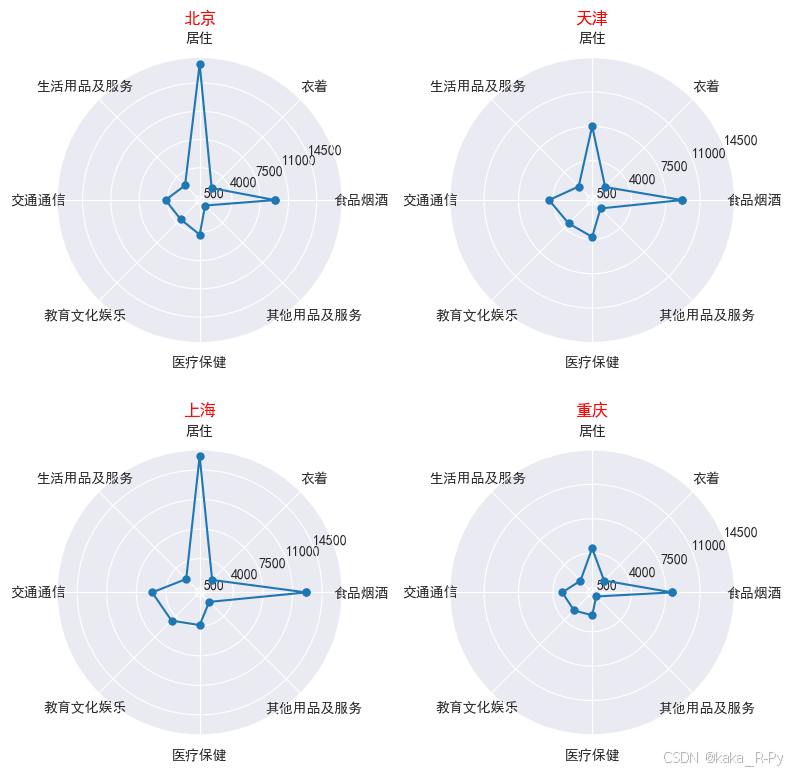
【代码框3-23】------绘制雷达图
python
# 图3-28的绘制代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_1.csv')
labels=np.array(df['支出项目']) # 设置标签
datalenth=8 # 数据长度
df1=np.array(df['北京']);df2=np.array(df['天津'])
df3=np.array(df['上海']);df4=np.array(df['重庆'])
angles=np.linspace(0,2*np.pi,datalenth,endpoint=False)
df1=np.concatenate((df1,[df1[0]])) # 使雷达图闭合
df2=np.concatenate((df2,[df2[0]]))
df3=np.concatenate((df3,[df3[0]]))
df4=np.concatenate((df4,[df4[0]]))
angles=np.concatenate((angles,[angles[0]]))
plt.figure(figsize=(6,6),facecolor='lightgray') # 画布背景色
plt.polar(angles,df1,'r--',linewidth=1,marker='o',markersize=5,label='北京') # 红色虚线
plt.polar(angles,df2,'b',linewidth=1,marker='+',markersize=5,label='天津') # 蓝色实线
plt.polar(angles,df3,'k',linewidth=1,marker='*',markersize=5,label='上海') # 黑色实线
plt.polar(angles,df4,'g',linewidth=1,marker='.',markersize=5,label='重庆') # 绿色实线
plt.thetagrids(range(0,360,45),labels) # 设置标签
plt.grid(linestyle='-',linewidth=0.5,color='gray',alpha=0.5) # 设置网格线
plt.legend(loc='upper right',bbox_to_anchor=(1.1,1.1)) # 绘制图例并设置图例位置
plt.show()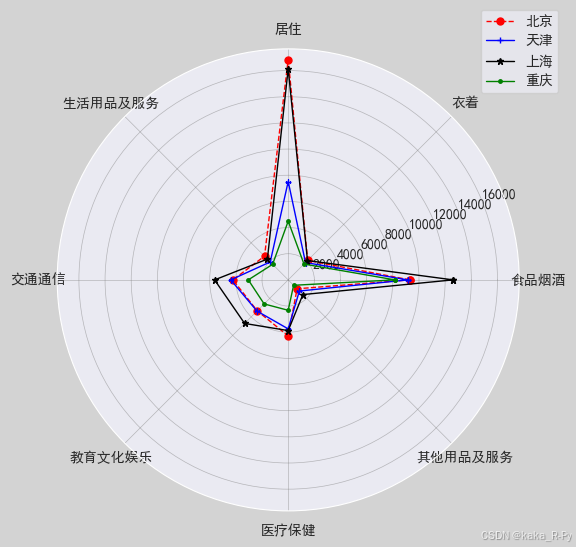
3.5 时间序列可视化
【例3-6】------城镇居民和农村居民的消费水平
【代码框3-24】------绘制折线图
python
# 图3-29的绘制代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
df= pd.read_csv('./pydata/example/chap03/example3_6.csv')
df['年份']=pd.to_datetime(df['年份'],format='%Y') # 将数据转换为日期类型
df=df.set_index('年份') # 将日期设置为索引(index)
# (a)绘制折线图
plt.subplots(1, 2, figsize=(8, 3.2))
ax1=plt.subplot(121)
df.plot(ax=ax1,kind='line',grid=True, # 设置网格线
stacked=False,
linewidth=1,marker='o',markersize=5,
xlabel='年份',ylabel='人均可支配收入(元)')
plt.title('(a) 折线图')
# (b)绘制面积图
ax2=plt.subplot(122)
df.plot(ax=ax2,kind='area',stacked=True,alpha=0.5,
xlabel='年份',ylabel='人均可支配收入(元)')
plt.title('(b) 面积图')
plt.tight_layout()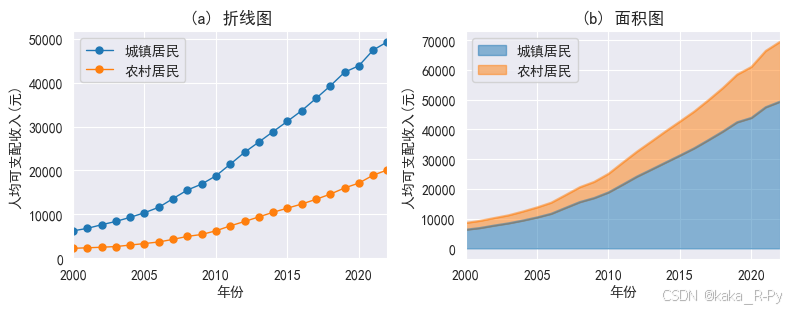
3.6 可视化的注意事项
数据可视化是将数据以图表、图形或其他视觉元素的形式呈现,以便更好地理解和分析数据的过程。虽然数据可视化是一个强大的工具,但在实践中也存在一些难点和需要注意的事项。以下是一些常见的难点和注意事项:
数据清洗和准备:数据可视化的第一步是清洗和准备数据。这包括处理缺失值、异常值和重复值,以及将数据转换为适合可视化的格式。数据清洗是一个耗时且复杂的过程,需要仔细处理以确保可视化结果准确。
数据的选择和精确性:选择适当的数据集对于有效的数据可视化至关重要。需要明确定义所需的指标和变量,并确保数据的准确性和完整性。不准确或不完整的数据可能会导致误导性的可视化结果。
视觉设计和布局:设计和布局是有效数据可视化的关键因素。需要选择适当的图表类型和视觉元素,以最佳方式传达数据的信息。颜色、字体、图例和标签的选择也对可视化的理解和可读性起着重要作用。
故事性和沟通:数据可视化应该是一个有意义的故事,能够有效地传达数据背后的洞察和信息。需要考虑观众的需求和背景,并使用合适的语言和图形来传达你的发现。清晰而简洁的注释和标题可以帮助观众更好地理解可视化结果。
跨平台和响应式设计:数据可视化应该能够在不同平台和设备上呈现,并保持良好的可读性和用户体验。响应式设计和优化是确保可视化在不同分辨率和屏幕尺寸上正确显示的关键因素。
用户互动和可操作性:可交互的数据可视化可以提供更深入的探索和分析。需要考虑添加交互元素,如过滤器、排序和缩放功能,以使用户能够自定义和操作可视化结果。
数据隐私和安全性:在进行数据可视化时,必须确保数据的隐私和安全性。敏感数据应该进行脱敏或匿名化处理,以防止数据泄露或滥用。
不同观众的需求:不同的观众可能对数据可视化有不同的需求和背景知识。在设计和呈现可视化结果时,需要考虑到不同观众的需求,并提供适当的解释和背景信息。
综上所述,数据可视化的难点包括数据准备、设计和布局、沟通和故事性,以及跨平台和用户互动等方面。在进行数据可视化时,需要注意数据的准确性、隐私安全、观众需求和用户体验等因素。