一、CPU与GPU体系架构
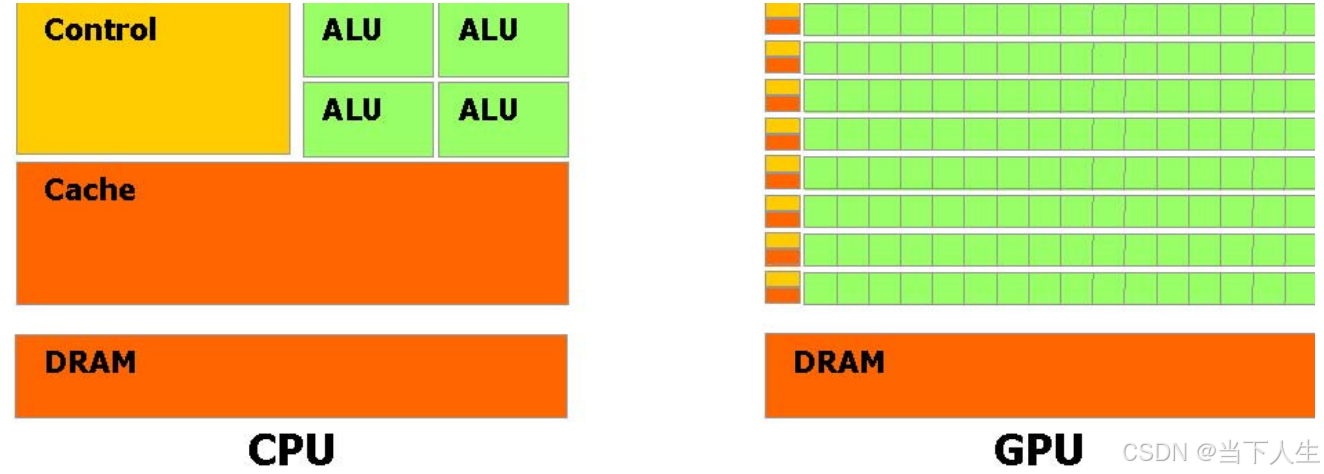
- 计算单元分布
- CPU: 少量强大的ALU(算术逻辑单元),通常4-8个核心
- GPU: 大量小型ALU,成百上千个计算核心
- 特点:GPU更适合并行计算,可以同时处理大量数据
- 控制单元(Control)
- CPU: 较大的控制单元,复杂的控制逻辑
- GPU: 较小的控制单元,多个计算单元共享一个控制单元
- 特点:GPU牺牲了控制灵活性,换取更多计算资源
- 缓存(Cache)
- CPU: 较大的缓存,多级缓存结构
- GPU: 相对较小的缓存
- 特点:GPU更依赖高带宽内存访问而不是缓存命中
- 内存(DRAM)
- CPU: 通用内存架构,延迟优化
- GPU: 高带宽内存架构,吞吐量优化
- 特点:GPU的内存系统设计偏重带宽而非延迟
二、GPU编程软件堆栈
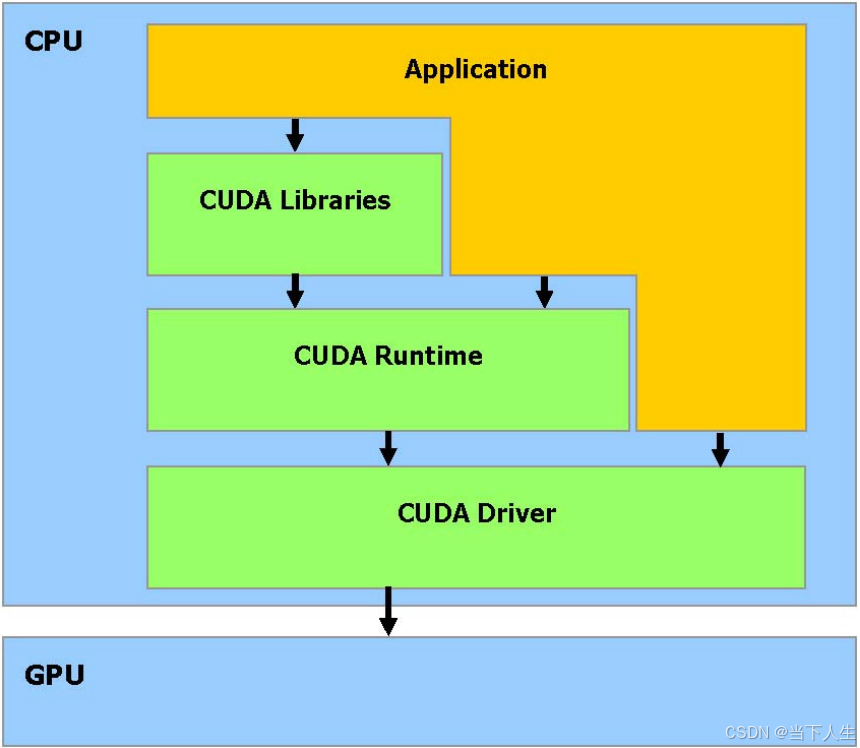
1、CPU视角的执行流程:
Application代码
↓
调用CUDA API
↓
CUDA Runtime处理
↓
Driver与GPU通信
↓
向GPU发送指令
2、GPU视角:
接收指令 → 执行计算 → 返回结果
从系统架构上来看:
应用程序 (CPU)
↓
CUDA Runtime/Driver (CPU系统空间)
↓
PCIe总线通信
↓
GPU执行单元
所以看出CPU用于控制运行application,做复杂控制,GPU只用于大规模并行计算,GPU不能离开CPU单独使用,由CPU来统一管理系统资源,GPU专注计算任务。
3、用伪代码表述如下:
int main() { // CPU上运行主程序
// CPU管理GPU资源
cudaSetDevice(0);
// CPU分配内存
float *d_data;
cudaMalloc(&d_data, size);
// CPU启动GPU计算
kernel<<<grid, block>>>(d_data);
// CPU等待GPU完成
cudaDeviceSynchronize();
}
CUDA组件必须运行在CPU上,作为CPU和GPU之间的桥梁,管理和协调两种处理器的工作。这也是为什么图中将CUDA组件放在CPU框中的原因
三、现实中英伟达的软件与软件栈对应关系

举个代码例子来理解这个框架:
当你运行一个PyTorch程序时
import torch
model = torch.nn.Linear(100, 10).cuda()
output = model(input_data)
实际发生了这些事:
-
PyTorch(应用层)调用cuDNN(Libraries层)的优化函数
-
cuDNN通过Runtime层申请GPU内存、创建计算流
-
Runtime层通过Driver层与GPU通信
-
Driver层发送指令给GPU执行计算
-
结果通过层层返回到PyTorch
类比你要网购一件商品的过程:
应用层 → 你在手机App下单
Libraries层 → 购物平台的各种服务(支付/物流)
Runtime层 → 快递公司的调度系统
Driver层 → 快递员实际配送
硬件层 → 商品实际到达你手中
四、所以安装单机多卡容器化训练环境
1、基础系统层
推荐使用Ubuntu 20.04/22.04 LTS服务器版
sudo apt update && sudo apt upgrade
安装基础开发工具
sudo apt install -y build-essential cmake git curl wget software-properties-common
2、nVidia驱动层
添加NVIDIA驱动仓库
sudo add-apt-repository ppa:graphics-drivers/ppa
安装NVIDIA驱动(适用于A800的最新驱动,如535)
sudo apt install nvidia-driver-535
验证驱动安装
nvidia-smi
3、NVIDIA CUDA工具层
下载并安装CUDA工具包(以12.2为例)
sudo sh cuda_12.2.0_525.60.13_linux.run
设置环境变量(添加到 ~/.bashrc)
export PATH=/usr/local/cuda-12.2/bin{PATH:+:{PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64{LD_LIBRARY_PATH:+:{LD_LIBRARY_PATH}}
4、Docker环境层
安装Docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
安装NVIDIA Container Toolkit
distribution=(. /etc/os-release;echo ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo systemctl restart docker
验证Docker GPU支持
sudo docker run --gpus all nvidia/cuda:12.2.0-base-ubuntu20.04 nvidia-smi
5、深度学习环境层
拉取NVIDIA优化的PyTorch容器(以最新版为例)
sudo docker pull nvcr.io/nvidia/pytorch:23.10-py3
创建容器启动脚本 start_container.sh
cat << 'EOF' > start_container.sh
#!/bin/bash
docker run --gpus all -it --rm \
--shm-size=1g \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
-v /path/to/your/data:/workspace/data \
-v /path/to/your/code:/workspace/code \
nvcr.io/nvidia/pytorch:23.10-py3
EOF
chmod +x start_container.sh
6、分布式训练配置
创建多卡训练启动脚本 launch_training.sh
cat << 'EOF' > launch_training.sh
#!/bin/bash
docker run --gpus all -it --rm \
--shm-size=1g \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--network=host \
-v /path/to/your/data:/workspace/data \
-v /path/to/your/code:/workspace/code \
--env NCCL_DEBUG=INFO \
--env NCCL_IB_DISABLE=0 \
--env NCCL_IB_GID_INDEX=3 \
--env NCCL_SOCKET_IFNAME=^docker0,lo \
nvcr.io/nvidia/pytorch:23.10-py3
EOF
chmod +x launch_training.sh