人工智能(AI)中,机器学习(ML)领域有多个密切相关但各有侧重的"专业类别"或子领域。它们常常被并列讨论,有时还会交叉融合。下面系统梳理这些相似或相邻的专业名词类别,并说明它们之间的关系与区别:
🌐 1. 机器学习(Machine Learning, ML)
定位:总纲性概念,深度学习和强化学习都属于它的子集。
定义:让计算机从数据中自动学习规律,而无需显式编程。
三大经典范式:
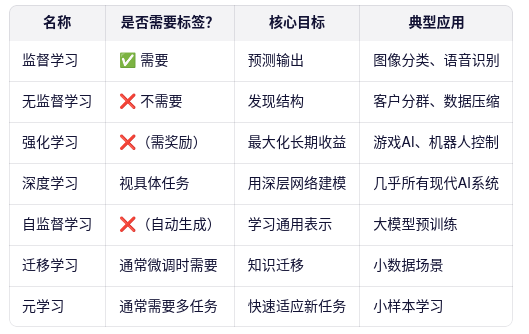
监督学习(Supervised Learning)
→ 有输入-输出对(标签),如分类、回归。
例子:垃圾邮件识别、房价预测
无监督学习(Unsupervised Learning)
→ 只有输入,无标签,目标是发现结构。
例子:聚类(K-means)、降维(PCA)、异常检测
强化学习(Reinforcement Learning)
→ 通过奖励信号学习策略(如前所述)
✅ 深度学习 ≈ 使用深度神经网络的机器学习方法,可应用于监督、无监督、强化等场景。🧠 2. 表示学习(Representation Learning)
核心思想:自动学习数据的有效特征表示(而不是人工设计特征)。
与深度学习关系:深度学习本质上是一种强大的表示学习方法(如 CNN 自动学图像特征)。
例子:自编码器(Autoencoder)、Word2Vec、对比学习(Contrastive Learning)🔍 3. 迁移学习(Transfer Learning)
目标:将在一个任务上学到的知识迁移到另一个相关任务上。
典型用法:用 ImageNet 预训练的 ResNet 微调做医学图像分类。
与深度学习结合紧密,是现代 DL 实践的标准流程之一。🤖 4. 元学习(Meta-Learning / "Learning to Learn")
目标:让模型学会如何快速适应新任务(通常只需少量样本)。
应用场景:小样本学习(Few-shot Learning)
例子:MAML(Model-Agnostic Meta-Learning)🔄 5. 自监督学习(Self-Supervised Learning)
特点:无标签,但通过设计"预文本任务"(pretext task)自动生成监督信号。
优势:可利用海量无标注数据(如所有网页文本、视频)。
代表工作:BERT(掩码语言建模)、SimCLR(图像对比学习)
地位:被视为通向通用人工智能的重要路径之一。📊 6. 在线学习(Online Learning)
特点:数据逐条到达,模型实时更新(而非批量训练)。
对比:传统 ML 是"离线/批量学习"。
应用:广告点击率预测、金融风控🎲 7. 因果推断(Causal Inference)
目标:不只是找相关性,而是推断因果关系(A 是否导致 B?)
与 ML 区别:传统 ML 关注预测,因果推断关注干预效果(如"吃药是否真的治病?")
新兴方向:因果机器学习(Causal ML)🧬 8. 生成模型(Generative Models)
目标:学习数据分布,生成新样本。
方法包括:
GAN(生成对抗网络)
VAE(变分自编码器)
扩散模型(Diffusion Models)
自回归模型(如 PixelRNN、GPT)
注意:生成模型可以基于深度学习,也可不用(如高斯混合模型)。🗺️ 关系图(简化版)
bash
人工智能 (AI)
└── 机器学习 (ML)
├── 监督学习
│ └── 深度学习(CNN, Transformer...)
├── 无监督学习
│ ├── 聚类
│ ├── 降维
│ └── 自监督学习 / 表示学习
├── 强化学习
│ └── 深度强化学习(DQN, PPO...)
├── 迁移学习
├── 元学习
└── 在线学习✅ 总结:常见"XX学习"术语速查表
如果你在做机器人轨迹生成、仿真控制等任务,未来可能会接触到:
模仿学习(Imitation Learning):从专家示范中学习(介于监督学习和强化学习之间)
逆强化学习(Inverse RL):从行为反推奖励函数这些也都是 RL 的重要变体。