Hadoop 架构
Hadoop 是一个主从架构的分布式计算框架,采用主节点(Master)与从节点(Slave)的拓扑结构。在系统中,Master 节点负责资源管理和任务分配,而 Slave 节点负责执行计算和存储数据。以下是 Hadoop 的主要架构组成及其核心概念的详细介绍。
HDFS(分布式文件系统)
HDFS 提供 Hadoop 的数据存储功能,通过将大文件划分为多个块(Block),以分布式的方式存储在多个节点上。
- HDFS 架构
NameNode(运行在 Master 节点):负责命名空间管理、文件访问控制、文件块的元数据管理,以及块的存储和映射。
DataNode(运行在 Slave 节点):负责存储实际数据块并处理来自客户端的读写请求。 - 块的概念
HDFS 中的默认块大小为 128MB 或 256MB,远大于传统文件系统的块大小。
合理设置块大小非常重要:如果块太小,会导致 NameNode 存储的元数据膨胀,从而消耗大量内存并降低效率。 - 副本机制
HDFS 使用副本技术以保证容错性,每个块默认会被复制 3 次,存储在不同的节点上。
机架感知算法:在存储副本时,HDFS 优先选择本地机架存放一个副本,其他副本则分布在其他机架上,从而提高容错能力和读取效率。
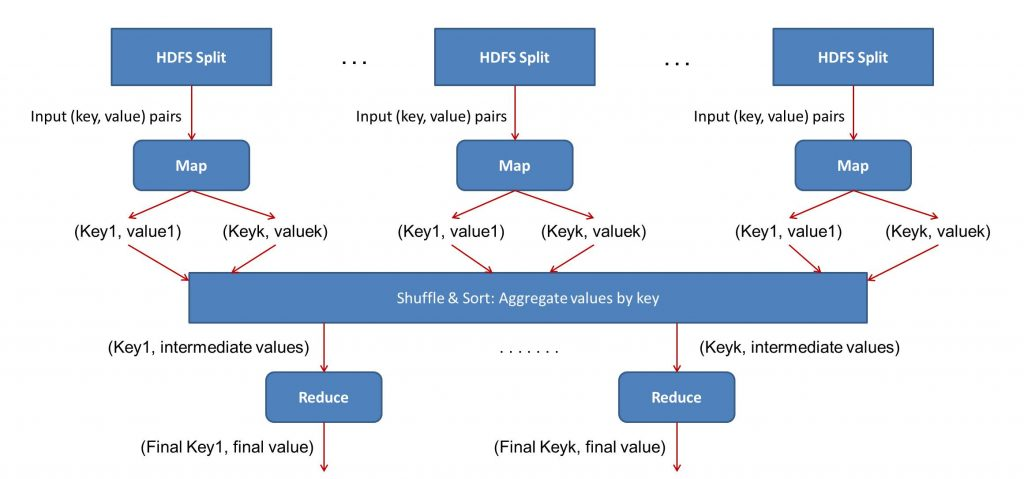
MapReduce(分布式计算框架)
MapReduce 是 Hadoop 的核心计算框架,用于处理海量数据。它将任务分为 Map 和 Reduce 两部分,以并行化方式运行在集群中。
- MapReduce 数据流
输入格式(InputFormat):定义如何分割输入文件为数据片段。
数据本地化:Map 任务尽量在数据所在节点执行,减少网络传输。 - Map 任务
RecordReader:将输入分片解析为记录,并以键值对形式(key-value)提供给 Mapper。
Mapper:用户自定义函数处理键值对,并生成中间键值对。
Combiner(可选):对中间键值对进行本地聚合,减少网络传输的数据量。
Partitioner:将 Mapper 输出的键值对分区,每个分区对应一个 Reducer。 - Reduce 任务
Shuffle 和排序:拉取分区数据并排序,将相同键的数据分组。
Reducer:用户自定义函数对每组键值对执行操作,生成最终结果。
OutputFormat:将 Reducer 输出的键值对写入 HDFS,支持自定义格式。
Partitioner 的工作流程
-1. 从 Mapper 获取键值对:
Partitioner 接收来自 Mapper 的中间键值对数据。
-2. 分区逻辑:
默认情况下,Partitioner 会对键计算哈希值,然后对 Reducer 的数量取模:
partition=key.hashcode()%reducer_数量
这个机制确保:
(1)均匀分布:键值对尽可能均匀分布到所有 Reducer 上。
(2)键的唯一性:相同键的所有值会被分配到同一个 Reducer。
-3. 分片数据的本地存储:
分区后的数据以文件形式写入本地文件系统,等待相应的 Reducer 拉取。
Yarn(资源管理框架)
Yarn 是 Hadoop 的资源管理和任务调度系统。
- Yarn 架构
ResourceManager(全局资源管理器):
Scheduler:分配资源,但不跟踪任务状态。
ApplicationManager:接收任务、分配第一个容器,重启失败的 ApplicationMaster。
NodeManager(节点资源管理器):监控节点上的资源使用情况。
ApplicationMaster:负责资源申请、任务监控和进度跟踪。 - Yarn 特性
多租户:支持多种访问引擎(如批处理、实时处理)。
高集群利用率:动态资源分配提升资源利用率。
可扩展性:支持扩展至数千节点并联结多个 Yarn 集群。
兼容性:Hadoop 1.x 的 MapReduce 应用可直接运行在 Yarn 集群上。
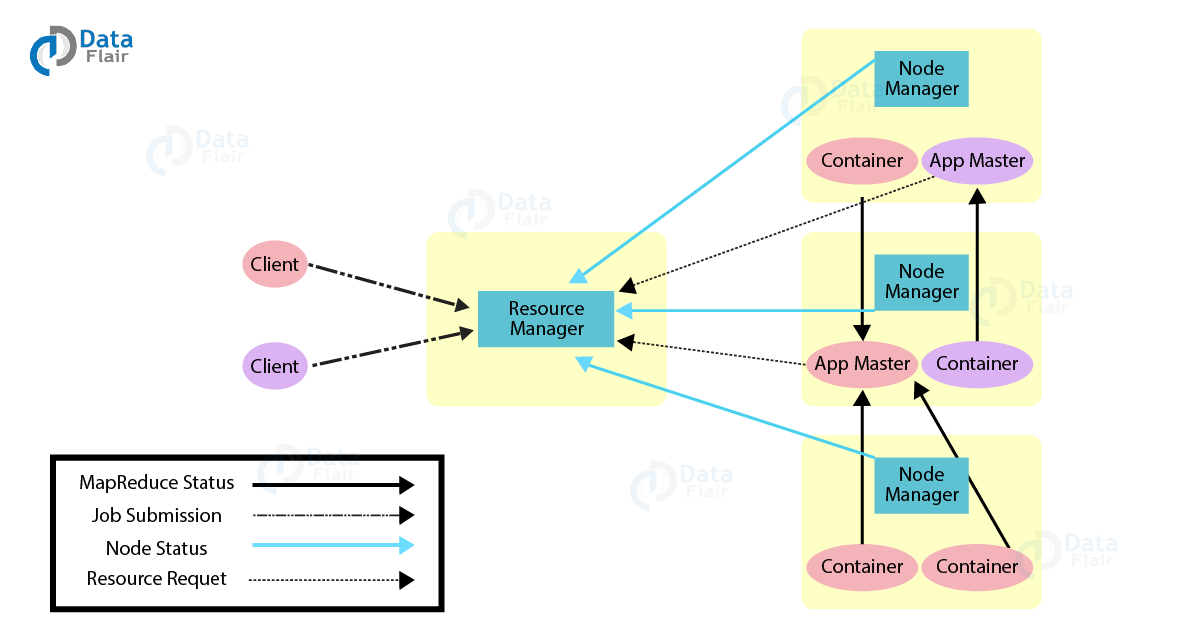
上图展示了 Yarn(Yet Another Resource Negotiator) 的架构及其工作流程。
- 任务提交:
Client 向 Resource Manager 提交任务请求,包含所需资源信息和任务描述。 - 资源分配:
Resource Manager 为任务分配第一个 Container,启动 Application Master。 - 任务管理:
Application Master 在分配的容器中启动,并与 Resource Manager 交互以申请更多资源。 - 任务执行:
Resource Manager 为 Application Master 分配多个 Container,这些 Container 运行具体的 MapReduce 或其他计算任务。
Application Master 与 Node Manager 通信以启动任务容器。 - 状态监控:
Node Manager 监控任务执行的容器资源使用情况,并向 Resource Manager 汇报。
Application Master 跟踪任务状态,并将任务执行结果反馈给客户端。 - 任务完成:
Client 接收任务执行状态(成功或失败),同时释放所有相关的资源。
Hadoop 架构整合了 HDFS 的分布式存储、MapReduce 的并行计算以及 Yarn 的资源管理能力,为海量数据的存储与处理提供了强大的支持。