
前一篇:《探索训练人工智能模型的词汇大小与模型的维度》
**序言:**Dropout 是神经网络设计领域的一种技术,通常我们把它翻译成 随机失活 或者 丢弃法。如果训练神经网络的时候不用 Dropout,模型就很容易"读死书",也就是过拟合,结果可能导致项目失败。
那 Dropout 到底在干什么呢?其实很简单,就是在训练模型的时候,随机关掉隐藏层中的一些神经元,不让它们输出结果。没什么玄乎的,就是这么直接。比如说,在每一轮(epoch)训练中,会随机挑一些神经元"闭麦",让它们暂时休息,输出值设为 0。但需要注意的是,哪些神经元会被关掉是随机的,每次都不一样,而不是每次关掉一批固定的神经元。这样操作的好处是,模型必须依赖所有神经元协同工作,去学习更普遍的规律,而不是只死记硬背几个特定特征。所以 Dropout 能很好地解决模型的"读死书"问题,让它更灵活、更聪明,也更有能力去识别它从未见过的新知识。
使用 Dropout
在减少过拟合方面,一个常用的技巧是在全连接神经网络中加入 Dropout。我们在第 3 章中探讨了它在卷积神经网络中的应用。这时可能会很想直接使用 Dropout 来看看它对过拟合的效果,但在这里我选择先不急着用,而是等到词汇表大小、嵌入维度和架构复杂度都调整好之后再试。毕竟,这些调整往往比使用 Dropout 对模型效果的影响更大,而我们已经从这些调整中看到了不错的结果。
现在,我们的架构已经简化到中间的全连接层只有 8 个神经元了,因此 Dropout 的作用可能会被最小化,但我们还是来试一试吧。以下是更新后的模型代码,加入了 0.25 的 Dropout(这相当于我们 8 个神经元中丢弃了 2 个):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(8, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(1, activation='sigmoid')
])
图 6-14 显示了训练 100 个周期后的准确率结果。这次我们看到训练集的准确率开始超过之前的阈值,而验证集的准确率则在慢慢下降。这表明我们又进入了过拟合的区域。
这一点通过图 6-15 的损失曲线得到了验证。
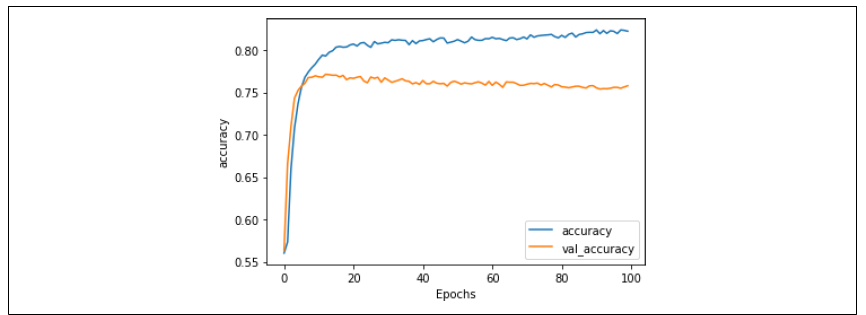
图 6-14:加入 Dropout 后的准确率

图 6-15:加入 Dropout 后的损失
从这里你可以看到,模型的验证损失又开始呈现出之前那种随着时间增加的趋势。虽然情况没有之前那么糟糕,但显然方向是不对的。
在这种情况下,由于神经元的数量非常少,加入 Dropout 可能并不是一个合适的选择。不过,Dropout 仍然是一个很好的工具,要记得把它放进你的工具箱,在比这个更复杂的架构中使用它。
总结:本节示例演示了在网络中引入 Dropout 的效果。从实验中我们可以看到,Dropout 是一个有效的工具,但它的作用依赖于模型架构和具体场景。对于像本例中这种简化的模型,Dropout 的影响较小。但在更复杂的模型中,它往往是防止过拟合的关键手段。接下来,我们还会介绍几种优化技术,帮助进一步解决模型过拟合的"读死书"问题