Apache DolphinScheduler 是一个分布式、易扩展的可视化数据工作流任务调度系统,广泛应用于数据调度和处理领域。
在大规模数据工程项目中,数据质量的管理至关重要,而 DolphinScheduler 也提供了数据质量检查的计算能力。本文将对 Apache DolphinScheduler 的数据质量模块进行源码分析,帮助开发者深入理解其背后的实现原理与设计理念。
数据质量规则
Apache Dolphinscheduler 数据质量模块支持多种常用的数据质量规则,如下图所示。
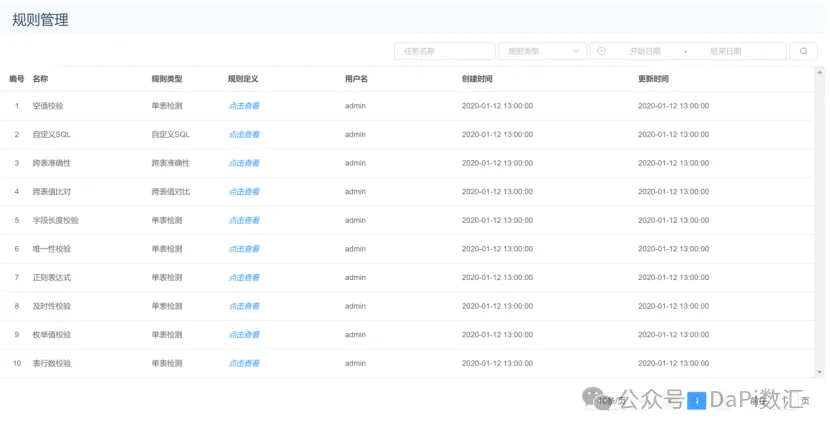
数据质量规则主要包括空值校验、自定义SQL、跨表准确性、跨表值比、字段长度校验、唯一性校验、及时性检查、枚举值校验、表行数校验等。
数据质量工作流程
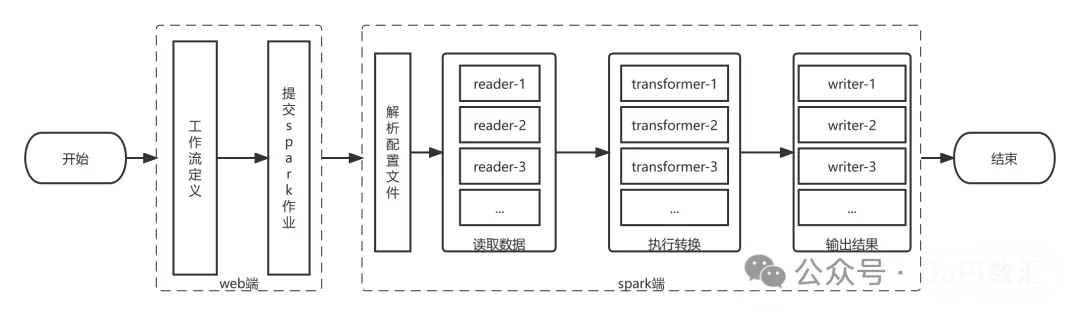
数据质量运行流程分为2个部分:
(1)在Web端进行数据质量检测的流程定义,通过DolphinScheduer进行调度,提交到Spark计算引擎;
(2)Spark端负责解析数据质量模型的参数,通过读取数据、执行转换、输出三个步骤,完成数据质量检测任务,工作流程如下图所示。
在Web端进行定义
数据质量定义如下图所示,这里只定义了一个节点。
以一个空值检测的输入参数为例,在界面完成配置后,会生产一个JSON文件。
这个JSON文件会以字符串参数形式提交给Spark集群,进行调度和计算。
JSON文件如下所示。
{
"name": "$t(null_check)",
"env": {
"type": "batch",
"config": null
},
"readers": [
{
"type": "JDBC",
"config": {
"database": "ops",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"output_table": "ops_ms_alarm",
"table": "ms_alarm",
"url": "jdbc:mysql://192.168.3.211:3306/ops?allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
}
}
],
"transformers": [
{
"type": "sql",
"config": {
"index": 1,
"output_table": "total_count",
"sql": "SELECT COUNT(*) AS total FROM ops_ms_alarm"
}
},
{
"type": "sql",
"config": {
"index": 2,
"output_table": "null_items",
"sql": "SELECT * FROM ops_ms_alarm WHERE (alarm_time is null or alarm_time = '') "
}
},
{
"type": "sql",
"config": {
"index": 3,
"output_table": "null_count",
"sql": "SELECT COUNT(*) AS nulls FROM null_items"
}
}
],
"writers": [
{
"type": "JDBC",
"config": {
"database": "dolphinscheduler3",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"table": "t_ds_dq_execute_result",
"url": "jdbc:mysql://192.168.3.212:3306/dolphinscheduler3?characterEncoding=utf-8&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql": "select 0 as rule_type,'$t(null_check)' as rule_name,0 as process_definition_id,25 as process_instance_id,26 as task_instance_id,null_count.nulls AS statistics_value,total_count.total AS comparison_value,7 AS comparison_type,3 as check_type,0.95 as threshold,3 as operator,1 as failure_strategy,'hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测' as error_output_path,'2022-11-16 03:40:32' as create_time,'2022-11-16 03:40:32' as update_time from null_count full join total_count"
}
},
{
"type": "JDBC",
"config": {
"database": "dolphinscheduler3",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"table": "t_ds_dq_task_statistics_value",
"url": "jdbc:mysql://192.168.3.212:3306/dolphinscheduler3?characterEncoding=utf-8&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql": "select 0 as process_definition_id,26 as task_instance_id,1 as rule_id,'ZKTZKDBTRFDKXKQUDNZJVKNX8OIAEVLQ91VT2EXZD3U=' as unique_code,'null_count.nulls'AS statistics_name,null_count.nulls AS statistics_value,'2022-11-16 03:40:32' as data_time,'2022-11-16 03:40:32' as create_time,'2022-11-16 03:40:32' as update_time from null_count"
}
},
{
"type": "hdfs_file",
"config": {
"path": "hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测",
"input_table": "null_items"
}
}
]
}Spark端源码分析
DataQualityApplication.java 是Spark程序入口
public static void main(String[] args) throws Exception {
//...
//从命令行获取参数
String dataQualityParameter = args[0];
// 将json参数转为DataQualityConfiguration对象
DataQualityConfiguration dataQualityConfiguration = JsonUtils.fromJson(dataQualityParameter,DataQualityConfiguration.class);
//...
//构建 SparkRuntimeEnvironment的参数Config对象
EnvConfig envConfig = dataQualityConfiguration.getEnvConfig();
Config config = new Config(envConfig.getConfig());
config.put("type",envConfig.getType());
if (Strings.isNullOrEmpty(config.getString(SPARK_APP_NAME))) {
config.put(SPARK_APP_NAME,dataQualityConfiguration.getName());
}
SparkRuntimeEnvironment sparkRuntimeEnvironment = new SparkRuntimeEnvironment(config);
//委托给 DataQualityContext执行
DataQualityContext dataQualityContext = new DataQualityContext(sparkRuntimeEnvironment,dataQualityConfiguration);
dataQualityContext.execute();
}数据质量配置类
public class DataQualityConfiguration implements IConfig {
@JsonProperty("name")
private String name; // 名称
@JsonProperty("env")
private EnvConfig envConfig; // 环境配置
@JsonProperty("readers")
private List<ReaderConfig> readerConfigs; // reader配置
@JsonProperty("transformers")
private List<TransformerConfig> transformerConfigs; // transformer配置
@JsonProperty("writers")
private List<WriterConfig> writerConfigs; // writer配置
//...
}DataQualityContext#execute从dataQualityConfiguration类中获取Readers、Transformers、Writers, 委托给SparkBatchExecution执行
public void execute() throws DataQualityException {
// 将List<ReaderConfig>转为List<BatchReader>
List<BatchReader> readers = ReaderFactory
.getInstance()
.getReaders(this.sparkRuntimeEnvironment,dataQualityConfiguration.getReaderConfigs());
// 将List<TransformerConfig>转为List<BatchTransformer>
List<BatchTransformer> transformers = TransformerFactory
.getInstance()
.getTransformer(this.sparkRuntimeEnvironment,dataQualityConfiguration.getTransformerConfigs());
// 将List<WriterConfig>转为List<BatchWriter>
List<BatchWriter> writers = WriterFactory
.getInstance()
.getWriters(this.sparkRuntimeEnvironment,dataQualityConfiguration.getWriterConfigs());
// spark 运行环境
if (sparkRuntimeEnvironment.isBatch()) {
// 批模式
sparkRuntimeEnvironment.getBatchExecution().execute(readers,transformers,writers);
} else {
// 流模式, 暂不支持
throw new DataQualityException("stream mode is not supported now");
}
}目前 Apache DolphinScheduler 暂时不支持实时数据的质量检测。
ReaderFactory类采用了单例和工厂方法的设计模式,目前支持JDBC和HIVE的数据源的读取, 对应Reader类HiveReader、JDBCReader。
WriterFactory类采用了单例和工厂方法的设计模式,目前支持JDBC、HDFS、LOCAL_FILE的数据源的输出,对应Writer类JdbcWriter、 HdfsFileWriter和 LocalFileWriter 。
TransformerFactory类采用了单例和工厂方法的设计模式,目前仅支持TransformerType.SQL的转换器类型。
结合JSON可以看出一个空值检测的Reader、Tranformer、 Writer情况:
1个Reader :读取源表数据
3个Tranformer: total_count 行总数 null_items 空值项(行数据) null_count (空值数)
计算SQL如下
-- SELECT COUNT(*) AS total FROM ops_ms_alarm
-- SELECT * FROM ops_ms_alarm WHERE (alarm_time is null or alarm_time = '')
-- SELECT COUNT(*) AS nulls FROM null_items3个Writer:第一个是JDBC Writer, 将比较值、统计值输出t\_ds\_dq\_execute\_result 数据质量执行结果表。
SELECT
//...
null_count.nulls AS statistics_value,
total_count.total AS comparison_value,
//...
'hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测' AS error_output_path,
//...
FROM
null_count
FULL JOIN total_count第二个是JDBC Writer,将statistics\_value写入到表 t\_ds\_dq\_task\_statistics\_value
SELECT
//...
//...
'null_count.nulls' AS statistics_name,
null_count.nulls AS statistics_value,
//...
FROM
null_count第3个是HDFS Writer,将空值项写入到HDFS文件目录
{
"type": "hdfs_file",
"config": {
"path": "hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测",
"input_table": "null_items"
}
}SparkBatchExecution#execute
public class SparkBatchExecution implements Execution<BatchReader, BatchTransformer, BatchWriter> {
private final SparkRuntimeEnvironment environment;
public SparkBatchExecution(SparkRuntimeEnvironment environment) throws ConfigRuntimeException {
this.environment = environment;
}
@Override
public void execute(List<BatchReader> readers, List<BatchTransformer> transformers, List<BatchWriter> writers) {
// 为每一个reader注册输入临时表
readers.forEach(reader -> registerInputTempView(reader, environment));
if (!readers.isEmpty()) {
// 取readers列表的第一个reader读取数据集合, reader的实现类有HiveReader、JdbcReader
Dataset<Row> ds = readers.get(0).read(environment);
for (BatchTransformer tf:transformers) {
// 执行转换
ds = executeTransformer(environment, tf, ds);
// 将转换后结果写到临时表
registerTransformTempView(tf, ds);
}
for (BatchWriter sink: writers) {
// 执行将转换结果由writer输出, writer的实现类有JdbcWriter、LocalFileWriter、HdfsFileWriter
executeWriter(environment, sink, ds);
}
}
// 结束
environment.sparkSession().stop();
}
}SparkBatchExecution#registerInputTempView
//注册输入临时表, 临时表表名为OUTPUT_TABLE的名字
private void registerInputTempView(BatchReader reader, SparkRuntimeEnvironment environment) {
Config conf = reader.getConfig();
if (Boolean.TRUE.equals(conf.has(OUTPUT_TABLE))) {// ops_ms_alarm
String tableName = conf.getString(OUTPUT_TABLE);
registerTempView(tableName, reader.read(environment));
} else {
throw new ConfigRuntimeException(
"[" + reader.getClass().getName() + "] must be registered as dataset, please set \"output_table\" config");
}
}调用Dataset.createOrReplaceTempView方法
private void registerTempView(String tableName, Dataset<Row> ds) {
if (ds != null) {
ds.createOrReplaceTempView(tableName);
} else {
throw new ConfigRuntimeException("dataset is null, can not createOrReplaceTempView");
}
}执行转换executeTransformer
private Dataset<Row> executeTransformer(SparkRuntimeEnvironment environment, BatchTransformer transformer, Dataset<Row> dataset) {
Config config = transformer.getConfig();
Dataset<Row> inputDataset;
Dataset<Row> outputDataset = null;
if (Boolean.TRUE.equals(config.has(INPUT_TABLE))) {
// 从INPUT_TABLE获取表名
String[] tableNames = config.getString(INPUT_TABLE).split(",");
// outputDataset合并了inputDataset数据集合
for (String sourceTableName: tableNames) {
inputDataset = environment.sparkSession().read().table(sourceTableName);
if (outputDataset == null) {
outputDataset = inputDataset;
} else {
outputDataset = outputDataset.union(inputDataset);
}
}
} else {
// 配置文件无INPUT_TABLE
outputDataset = dataset;
}
// 如果配置文件中配置了TMP_TABLE, 将outputDataset 注册到TempView
if (Boolean.TRUE.equals(config.has(TMP_TABLE))) {
if (outputDataset == null) {
outputDataset = dataset;
}
String tableName = config.getString(TMP_TABLE);
registerTempView(tableName, outputDataset);
}
// 转换器进行转换
return transformer.transform(outputDataset, environment);
}SqlTransformer#transform 最终是使用spark-sql进行处理, 所以核心还是这个SQL语句,SQL需要在web端生成好,参考前面的JSON文件。
public class SqlTransformer implements BatchTransformer {
private final Config config;
public SqlTransformer(Config config) {
this.config = config;
}
//...
@Override
public Dataset<Row> transform(Dataset<Row> data, SparkRuntimeEnvironment env) {
return env.sparkSession().sql(config.getString(SQL));
}
}将数据输出到指定的位置executeWriter
private void executeWriter(SparkRuntimeEnvironment environment, BatchWriter writer, Dataset<Row> ds) {
Config config = writer.getConfig();
Dataset<Row> inputDataSet = ds;
if (Boolean.TRUE.equals(config.has(INPUT_TABLE))) {
String sourceTableName = config.getString(INPUT_TABLE);
inputDataSet = environment.sparkSession().read().table(sourceTableName);
}
writer.write(inputDataSet, environment);
}总体来讲,Apache Dolphinscheduler的数据质量检测实现相对简单明了,只要采用Spark SQL进行计算。在本文中,我们深入分析了数据质量模块的源码结构和实现逻辑,Apache DolphinScheduler 数据质量模块的设计理念强调灵活性和扩展性,这使得它可以适应不同企业的多样化需求。
对于开发者而言,深入理解其源码不仅有助于更好地使用 DolphinScheduler,也为进一步扩展其功能提供了方向和灵感。希望本文能够为您在数据质量控制和开源项目深入探索方面提供帮助。
本文由 白鲸开源科技 提供发布支持!