Shuffle优化利器|聚簇优化推荐
在MaxCompute每日EB级规模的计算场景中,Join、Group By、Window等算子所产生的Shuffle数据流量已占据整体网络传输的60%以上,成为影响大数据计算成本的核心因素。以阿里内部某业务为例,单日Shuffle数据量高达2 PB,直接消耗7000+ CU资源------这一数字仅是问题的冰山一角。
MaxCompute 哈希聚簇(Hash Clustering)表功能通过设置表的Shuffle和Sort属性,可对数据进行重新组织与排列,从而在后续的数据处理链路中显著减少IO消耗,加速查询与计算任务的执行,进而提升整体作业效率并降低资源使用成本。
然而,在业务初期,很多表并未预先定义Hash Cluster。随着业务规模的不断扩大和数据消费链路的日益复杂,回溯进行数据治理将面临巨大的挑战,需要基于详尽的历史数据统计与分析才能做出科学的治理决策。
为帮助用户更高效地优化数据处理流程,MaxCompute全新推出了聚簇优化推荐功能。该功能基于 31 天历史运行数据,每日自动输出全局最优 Hash Cluster Key,对于10 GB以上的大型Shuffle场景,这一功能将直接带来显著的成本优化。
实测成果|技术揭秘
聚簇优化推荐功能已在阿里内部得到广泛应用,并取得了显著的优化效果。我们相信,随着更多业务采用这一推荐方案,将能够实现整体业务的大幅提速,释放数据处理的无限潜能。

那么,为什么聚簇优化推荐功能能够带来如此显著的成本节省?让我们为您揭秘这一功能的核心优势:
- 全局 DAG 感知:该功能能够一次性分析横跨数千作业的 Shuffle 依赖图,帮助我们全面了解数据流动的全局性问题,从而精准定位优化方向。
- 动态倾斜检测:提前识别热点 key,避免「优化后更慢」的情况发生,确保优化方案的稳定性和高效性。
- 智能收益评估:通过智能算法,功能仅对「高 Shuffle + 低风险」的表提供改造建议,避免无效改造,确保优化建议的高效性和可靠性。
- 一键脚本生成:自动输出 ALTER TABLE 语句,并提供回滚方案,极大简化了用户操作流程,让用户能够快速、安全地实施优化。
这一功能不仅能够显著降低 Shuffle 场景的成本,更能为您的业务带来更快的查询速度和更高的资源利用率。

快速使用聚簇优化推荐
聚簇优化推荐功能已在阿里云MaxCompute控制台上正式发布,您可轻松查看和使用,只需三步即可完成推荐方案的应用。通过智能化和自动化的分析,该功能能够帮助您快速完成优化治理,提升作业效率。
- 查看推荐列表并应用推荐。
-
登录 MaxCompute 控制台 → 智能优化→ 数据排布优化 → 聚簇优化。
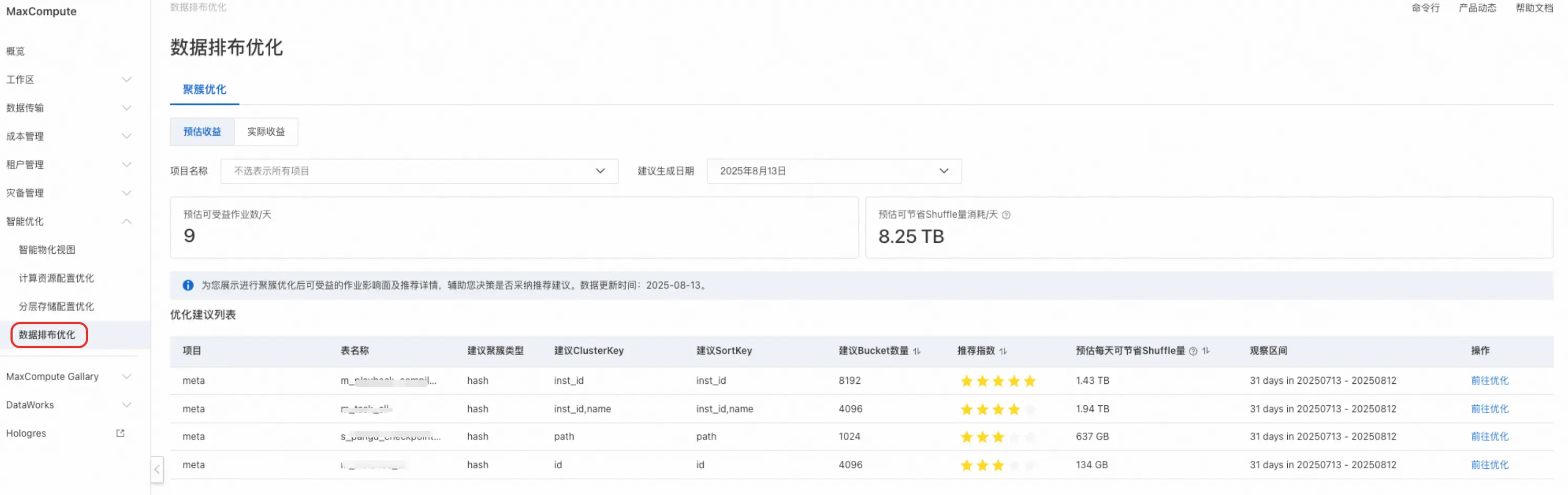 通过预估收益查看待优化的推荐列表,通过这个推荐列表您可以明确了解什么项目的什么表,可以把哪个列作为ClusterKey、SortKey以及Bucket的设置量,并预估出采用改推荐方案后可节省的Shuffle量。
通过预估收益查看待优化的推荐列表,通过这个推荐列表您可以明确了解什么项目的什么表,可以把哪个列作为ClusterKey、SortKey以及Bucket的设置量,并预估出采用改推荐方案后可节省的Shuffle量。 -
选择查看想要优化的表点击"前往优化"进入查看更详细的优化方案。
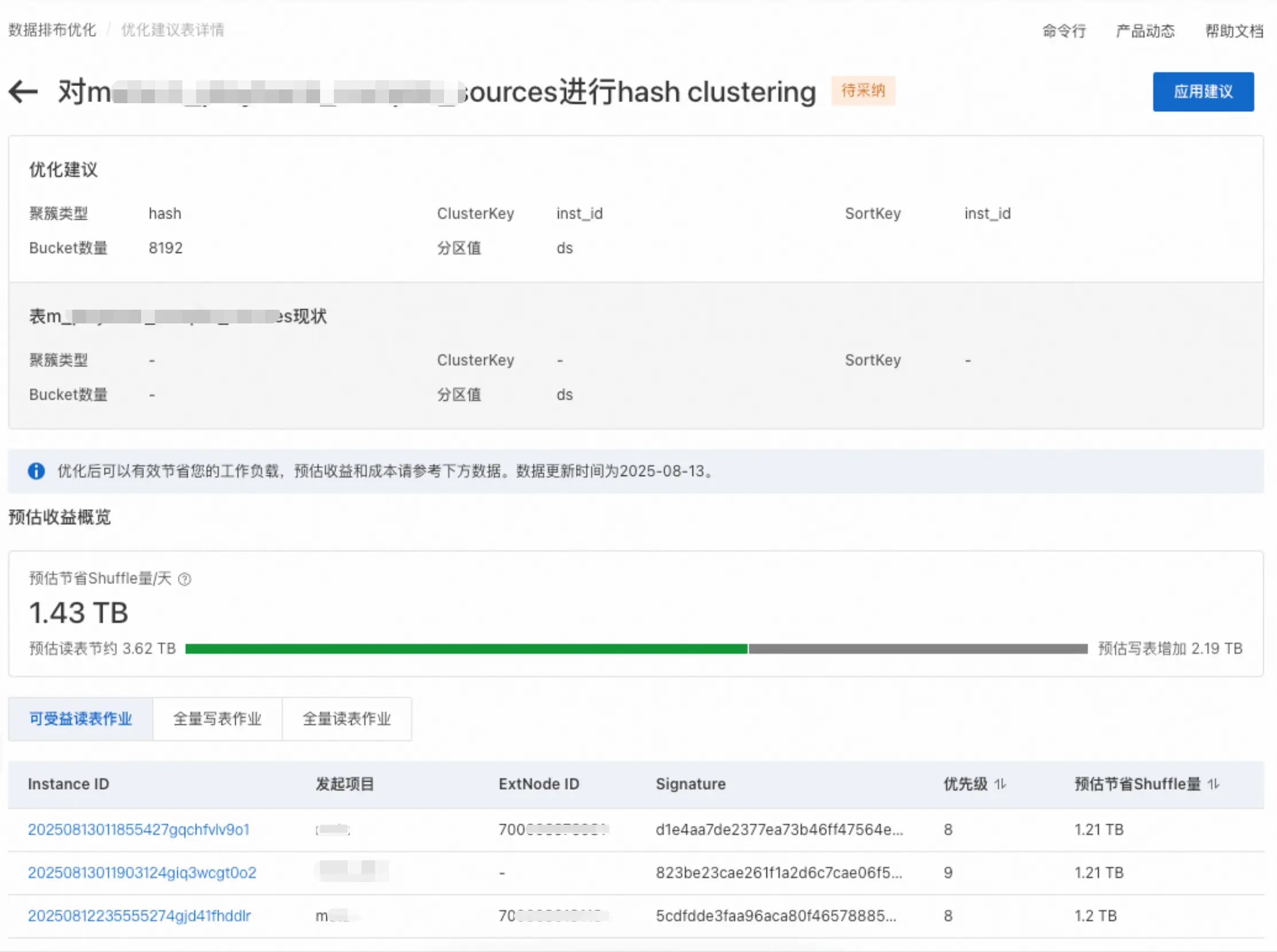 可以查看详细预估可收益的相关周期作业列表,包括读表作业、全量写表作业、全量读表作业。
可以查看详细预估可收益的相关周期作业列表,包括读表作业、全量写表作业、全量读表作业。 -
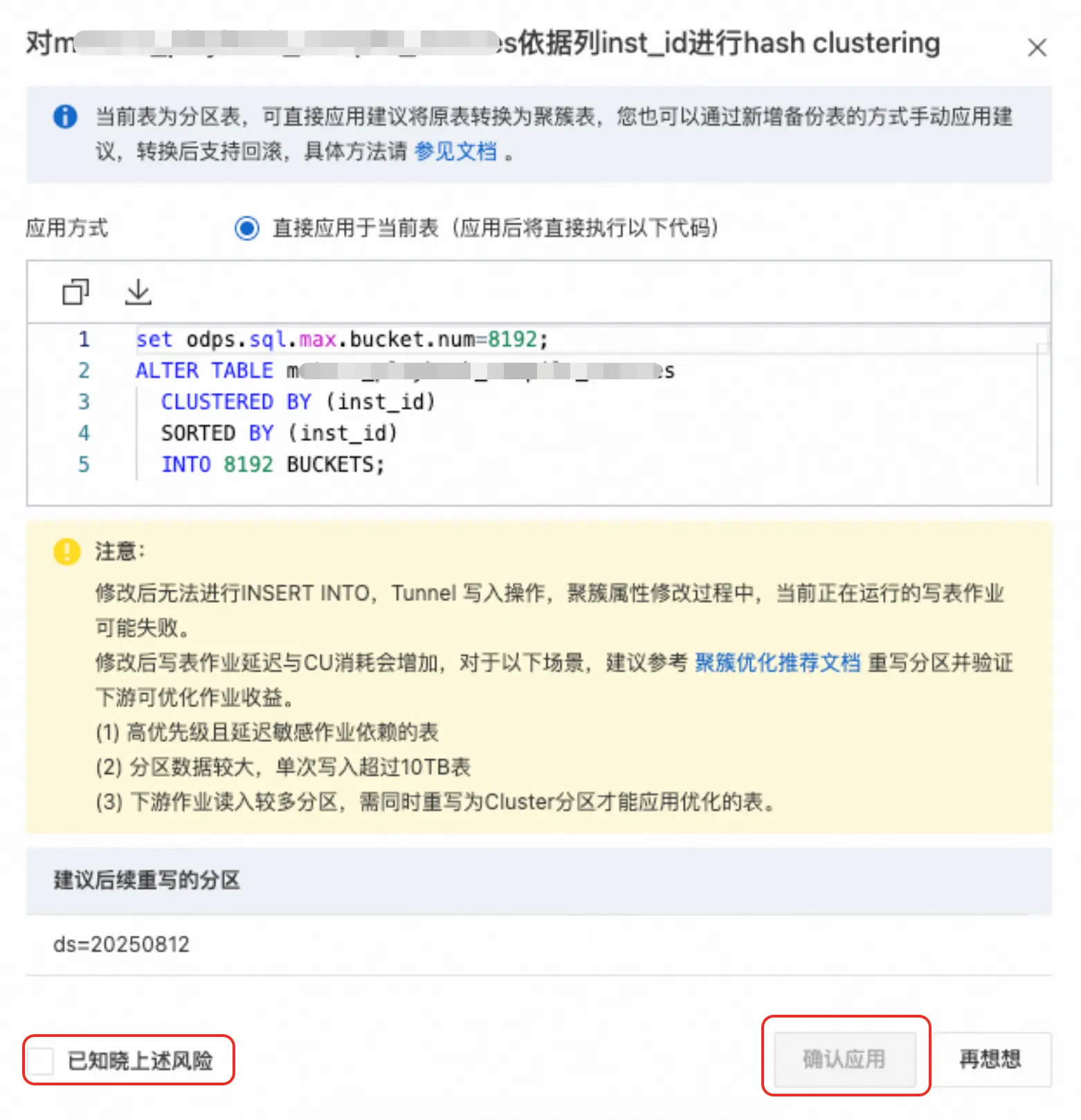
点击"应用建议"生成对应的ALTER TABLE 语句 + 回滚方案 。点击"确认应用"直接将当前表完成Hash Cluster 转换。
- 查看聚簇优化收益。在聚簇优化 页签,选择实际收益 ,选择分析时间 ,可以查看修改过聚簇属性的聚簇表带来的收益汇总和收益详情。
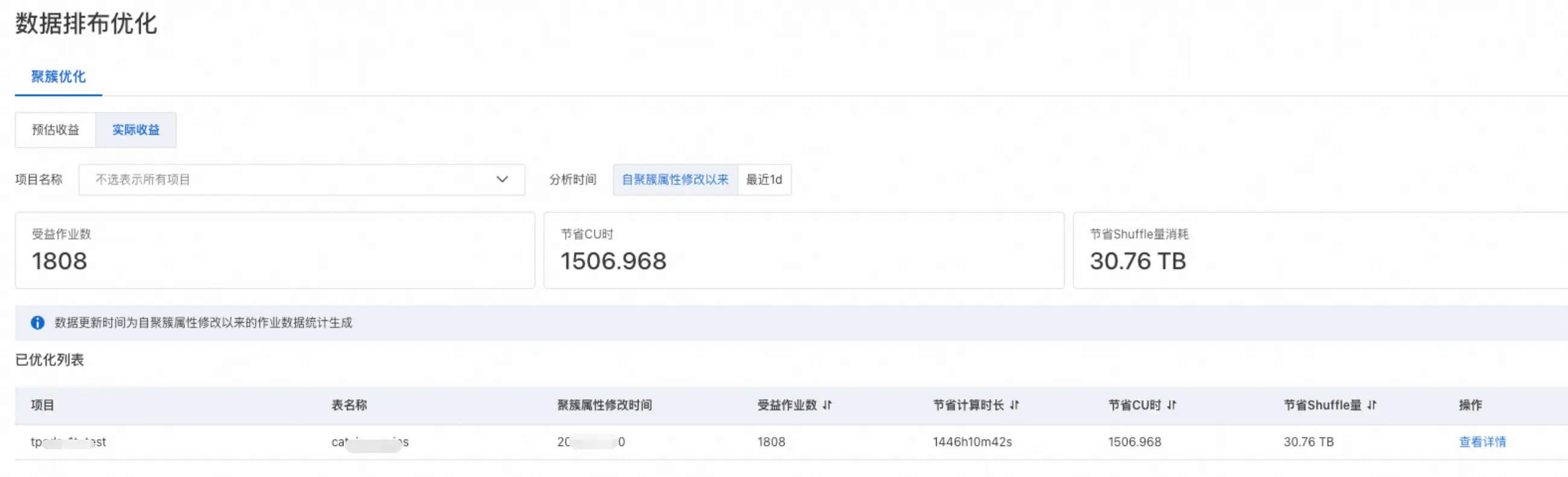
- 总的收益:受益作业数主要统计最近修改的聚簇表在收益统计区间内的被读取次数;节省的CU时是所有读取最近修改的聚簇表的作业在收益统计区间内的CU时消耗相较于表修改为聚簇表之前CU时消耗的节省值;节省Shuffle量消耗是所有读取最近修改的聚簇表的作业在收益统计区间内的Shuffle量消耗相较于表修改为聚簇表之前Shuffle量的节省值。
- 已优化列表:查看已经优化过的table详细list,每个表修改时间、收益的作业数,节省的计算时长、CU时、Shuffle量。
- 查看已优化表的优化效果详情。
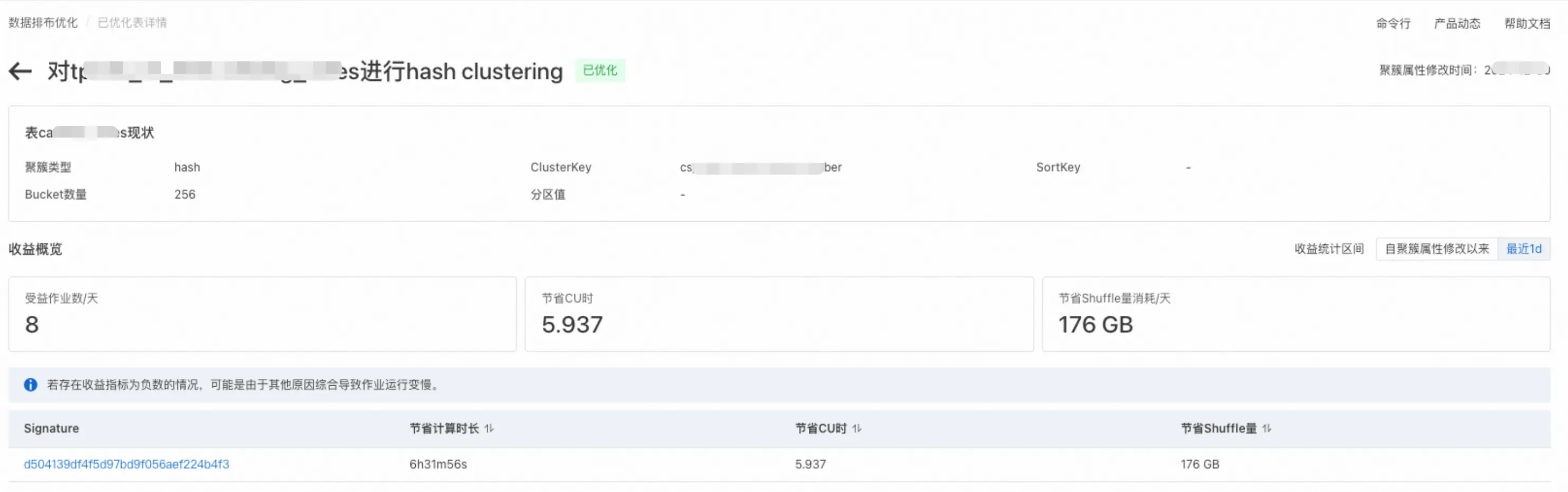
更详细的使用说明请参考文档聚簇优化推荐>>
更多MaxCompute优化推荐
MaxCompute已经推出了一系列优化推荐能力,同时还持续不断的挖掘并总结各种场景的改进点,未来还会继续推出更多的优化利器: