Flink CDC讲解
1、何为CDC?
CDC全称是Chanage Data Capture(变动数据获取 )。其核心原理就是监测并捕获数据库的DML变动(例如增删改) ,将这些变更按照发生顺序捕获,并将**【捕获到的数据】**写入到消息中间件中。如mysql、kakfa(最为典型)等都能实现CDC的功能。
在实时数仓 中,通常使用**Flume(面向文件系统)以及 CDC工具(面向关系型数据库组件)**这两个来实现数据采集和ETL功能。
2、CDC分类与对比
| 基于查询的 CDC(历史数据) | 基于 Binlog(日志) 的 CDC(新数据) | |
|---|---|---|
| 开源产品 | Sqoop | Canal、Maxwell、Debezium(内置默认) |
| 捕获所有数据变化 | false | true |
| 延迟特性 | high | low |
| 提升数据库压力 | true | false |
| 执行模式 | Batch | Streaming |
-
Binlog认知:Binlog是二进制日志文件 ,主要是用来记录DML和DDL操作 的,存放未持久化的数据。Binlog类似于HBase中的WAL机制(数据先记录到日志中,然后进行数据持久化),数据先进入Binlog(二进制日志)中,然后进入数据库进行持久化。
主从复制 :在MySQL中,Binlog可以用于实现【读写分离 】。主数据库(主库)记录所有的更改操作先存放于Binlog,从数据库(从库)通过读取主库的binlog来同步这些更改 ,等到Binlog中更改的数据进入主库中进行持久化前,从库就已经读到数据了,这样,从库可以保持与主库数据的一致性。读操作可以在从库上进行 ,以减轻主库的负担【主库负责写操作,从库负责读操作】。
-
CDC的作用:
历史数据获取 :CDC可以通过定期执行查询操作来获取数据库中的历史数据,同时建立数据的初始快照。
实时数据捕捉 【✔】:CDC可以从Binlog中捕捉到数据库中的新数据变更,支持实时数据同步和处理。
3、Flink CDC概念
Flink CDC是基于Apache Flink的流式数据集成框架,专注于实时捕获和处理数据库中的变更数据,其工作原理主要基于日志的CDC技术。
选择Flink来实现CDC原因:
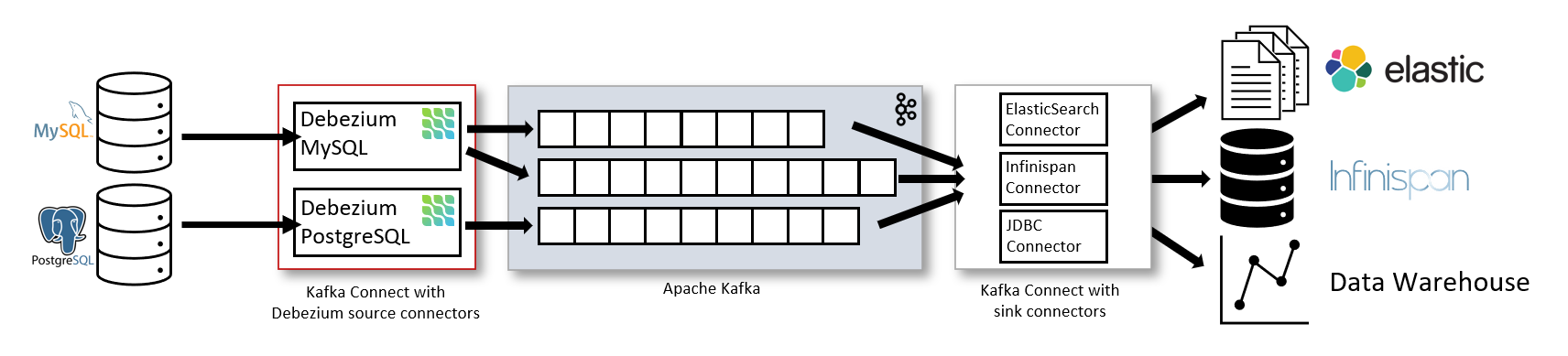
Debezium 官方架构图中,是通过 Kafka Streams 直接实现的 CDC 功能。但我们更建议使用 Flink CDC 模块,因为 Flink 相对 Kafka Streams 而言,有如下优势:
- 强大的流处理引擎:Flink作为一个高吞吐量、低延迟的流处理引擎,为Flink CDC提供了坚实的支撑。Flink通过基于事件时间的处理模型,支持准确和有序的数据处理,确保了CDC数据的实时性和准确性。
- 内置的CDC功能:Flink CDC提供了内置的CDC功能,可以直接连接到各种数据源(如MySQL、PostgreSQL等),捕获数据变化,并将其作为数据流进行处理。这消除了用户自行开发或集成CDC解决方案的需要,降低了实施成本。
- 多种数据源的支持:Flink CDC支持与多种数据源进行集成,包括关系型数据库、消息队列、文件系统等。这意味着无论数据存储在何处,Flink CDC都能够轻松地捕获其中的数据变化。
- 灵活的数据处理能力:Flink CDC提供了灵活且强大的数据处理能力,用户可以通过编写自定义的转换函数、处理函数等来对CDC数据进行各种实时计算和分析。同时,Flink还集成了SQL和Table API,为用户提供了使用SQL查询语句或Table API进行简单查询和分析的方式。
- 完善的生态系统:Flink拥有活跃的社区和庞大的生态系统,用户可以轻松地获取到丰富的文档、教程、示例代码和解决方案。此外,Flink还与其他流行的开源项目(如Apache Kafka、Elasticsearch等)深度集成,提供了更多的功能和灵活性。
4、Flink CDC实际演示
4.1.依赖组件
flink-cdc-connectors是一个可以从RDB直接读取全量和增量数据的组件,包含以下组件:
- flink-connector-mysql-cdc
- flink-connector-kafka-cdc
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>livewarehouse</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.1.3</hadoop.version>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<flink.version>1.13.2</flink.version>
<play.json.version>2.9.2</play.json.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<!-- flink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink-connector-kafka-cdc -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink-connector-mysql-cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<!-- mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 供状态后端数据写入用的 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- play-json:用于序列化与反序列化 -->
<dependency>
<groupId>com.typesafe.play</groupId>
<artifactId>play-json_${scala.binary.version}</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>
</project>4.2.Flink CDC读取Mysql数据
步骤一:开启Mysql的Binlog
在master01机器进行操作
shell# 建库 create database if not exists flink_cdc; # binlog监控flink_cdc库 vim /etc/my.cnf ---------------------------------- [mysqld] # 开启 binlog 并指定二进制日志文件前缀 log-bin=mysql-bin # 集群备份恢复需要每台机器有唯一的 ID server-id=1 # 执行哪些库开启 binlog【库名DATABASE_NAME】 👈 binlog-do-db=flink_cdc ---------------------------------- # 重启mysql服务 systemctl restart mysqld检验Binlog是否开启,可以进行一下操作:
shell# 查看 /etc/my.cnf中的datadir,可以看到binlog ll /var/lib/mysql通过插入数据,查看binlog是否发生变化【发生变化则表示成功】
shell# 插入数据 insert into test(id,name) values (4,'jack101'), (5,'mike102'), (6,'cheng103'); # 再次查看 /etc/my.cnf中的datadir,查看binlog变化,若有所改变,则表示配置成功。 ll /var/lib/mysql


步骤二:准备工作
配置mysql数据源(flink来监听变动数据)
scalaimport com.ververica.cdc.connectors.mysql.MySqlSource import com.ververica.cdc.connectors.mysql.table.StartupOptions import com.ververica.cdc.debezium.{DebeziumDeserializationSchema, DebeziumSourceFunction} object DataSources { //配置mysql数据源(CDC):监听数据变动,实现读写分离(数据进入mysql与数据从mysql中读出两个操作互不影响) def mysqlSource[T](serverId: Int = 1, hostname: String, port: Int = 3306, db: String, table: String, username: String = "root", password: String, schema: DebeziumDeserializationSchema[T]): DebeziumSourceFunction[T] = { /** StartupOptions: initial():首次启动时对受监视的数据库表执行初始快照,并继续读取最新的binlog。 earliest():永远不要在第一次启动时对受监视的数据库表执行快照,只需从binlog的开头读取即可。这应该谨慎使用,因为只有当binlog保证包含数据库的整个历史时,它才有效。 latest():永远不要在第一次启动时对受监视的数据库表执行快照,只需从binlog的末尾读取,这意味着只有自连接器启动以来的更改。 */ MySqlSource .builder[T]() .serverId(serverId) // 单机默认为1 .hostname(hostname) .port(port) .databaseList(db) .tableList(table) .username(username) // 远程连接用户为zhou,需要配置 .password(password) .startupOptions(StartupOptions.initial()) // initail: 最新数据。earliest: .deserializer(schema) .build() } }工具类
scalaobject Util { /** * 日期格式化工具 */ object TimeFormat { val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS") // 功能长整数(Long) 转换为 时间格式(String) def parse(timestamp: Long): String = { sdf.format(new Date(timestamp)) } } }
步骤三:Flink读取Mysql实时数据
完整代码:
scalapackage cases import com.ververica.cdc.debezium.{DebeziumSourceFunction, StringDebeziumDeserializationSchema} import modules.env.Environments import modules.sources.DataSources._ import modules.util.Util.TimeFormat.parse import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy} import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector import java.lang import java.time.Duration // Mysql(CDC) object CDCMySql { def main(args: Array[String]): Unit = { // 创建环境 val see: StreamExecutionEnvironment = Environments() .build() // 指定状态后端路径 .enableCheckpoint("file:///D:/phase/second_phase/Engineering/RealTimeDataWarehouse/flink_state_backend") .enableRetries() .enableStateBackend() .finish() // 数据源(通过Flink CDC来实时检测mysql中binlog,从而获取实时数据) val mysqlSourceFunc: DebeziumSourceFunction[String] = mysqlSource[String]( hostname = "master01", port = 3306, db = "flink_cdc", // binlog监听的库 table = "flink_cdc.test", username = "用户名", password = "远程密码", schema = new StringDebeziumDeserializationSchema() ) // 水位线策略 val watermark: WatermarkStrategy[String] = WatermarkStrategy .forMonotonousTimestamps() .withIdleness(Duration.ofSeconds(3)) .withTimestampAssigner(new SerializableTimestampAssigner[String] { override def extractTimestamp(t: String, l: Long): Long = System.currentTimeMillis() }) see.addSource(mysqlSourceFunc) // 对原生数据进行处理 .assignTimestampsAndWatermarks(watermark) .windowAll(TumblingEventTimeWindows.of(Time.seconds(3))) .process(new ProcessAllWindowFunction[String,String,TimeWindow] { override def process(context: ProcessAllWindowFunction[String, String, TimeWindow]#Context, elements: lang.Iterable[String], out: Collector[String]): Unit = { elements.forEach(println) val window: TimeWindow = context.window() val winRange = s"${parse(window.getStart)} , ${parse(window.getEnd)}" // 窗口区间 out.collect(winRange) elements.forEach(line=>{ out.collect(line) // 往下游送数据 }) } }) // 输出数据 .print() see.execute("mysql-cdc") } }检验代码:
1、对Mysql中被Binlog监控的库进行数据插入操作
sqlinsert into test(id,name) values (1,'jack4'), (2,'mike5'), (3,'cheng6');2、查看控制台输出情况,表示成功!
