一、pg_filedump工具介绍
PostgreSQL数据库里如果只是一般的数据文件损坏,++首选通过备份恢复,做pitr等,最保险,最可靠++ 。
数据页损坏,可以使用zero_damaged_pages=on来跳过损坏的数据块来读取数据,然后将数据导到新表中,当然,这部分损坏的数据可能找不回来的。
++如果是没有可用备份的情况++,而且数据目录下的某些文件损坏,可能需要结合其他的环境拷贝相应文件尝试是否能拉起数据库,但是如果这种方式也无法拉起库,数据库无法启动了。这种情况我们可能需要通过工具直接从数据文件中读取数据,例如使用Oracle中的ODU等等的工具。PostgreSQL里有着类似的pg_filedump工具,读取物理数据文件,获取数据。
二、pg_filedump工具安装
下载pg_filedump工具
postgres@ubuntu-linux-22-04-desktop:~$ git clone git://git.postgresql.org/git/pg_filedump.git
Cloning into 'pg_filedump'...
remote: Enumerating objects: 442, done.
remote: Counting objects: 100% (442/442), done.
remote: Compressing objects: 100% (422/422), done.
remote: Total 442 (delta 267), reused 0 (delta 0), pack-reused 0
Receiving objects: 100% (442/442), 138.35 KiB | 1024 bytes/s, done.
Resolving deltas: 100% (267/267), done.编译安装pg_filedump
postgres@ubuntu-linux-22-04-desktop:~/pg_filedump$ cd pg_filedump
...
postgres@ubuntu-linux-22-04-desktop:~/pg_filedump$ make -j 24
...
postgres@ubuntu-linux-22-04-desktop:~/pg_filedump$ make install -j 24
...
三、pg_filedump工具选项
postgres@ubuntu-linux-22-04-desktop:~/pg_filedump$ pg_filedump --help
Error: Missing file name to dump.
Usage: pg_filedump [-abcdfhikxy] [-R startblock [endblock]] [-D attrlist] [-S blocksize] [-s segsize] [-n segnumber] file
Display formatted contents of a PostgreSQL heap/index/control file
Defaults are: relative addressing, range of the entire file, block
size as listed on block 0 in the file
The following options are valid for heap and index files:
-a Display absolute addresses when formatting (Block header
information is always block relative)
-b Display binary block images within a range (Option will turn
off all formatting options)
-d Display formatted block content dump (Option will turn off
all other formatting options)
-D Decode tuples using given comma separated list of types
Supported types:
bigint bigserial bool char charN date float float4 float8 int
json macaddr name numeric oid real serial smallint smallserial text
time timestamp timestamptz timetz uuid varchar varcharN xid xml
~ ignores all attributes left in a tuple
-f Display formatted block content dump along with interpretation
-h Display this information
-i Display interpreted item details
-k Verify block checksums
-o Do not dump old values.
-R Display specific block ranges within the file (Blocks are
indexed from 0)
[startblock]: block to start at
[endblock]: block to end at
A startblock without an endblock will format the single block
-s Force segment size to [segsize]
-t Dump TOAST files
-v Ouput additional information about TOAST relations
-n Force segment number to [segnumber]
-S Force block size to [blocksize]
-x Force interpreted formatting of block items as index items
-y Force interpreted formatting of block items as heap items
The following options are valid for control files:
-c Interpret the file listed as a control file
-f Display formatted content dump along with interpretation
-S Force block size to [blocksize]
Additional functions:
-m Interpret file as pg_filenode.map file and print contents (all
other options will be ignored)
Report bugs to <pgsql-bugs@postgresql.org>命令解析如下:
-a 格式化时显示绝对地址(块头
信息总是块相关的)
-b 显示一个范围内的二进制块图像(选项将打开
关闭所有格式选项)
-d 显示格式化的块内容转储(选项将关闭
所有其他格式选项)
-D 使用给定的逗号分隔类型列表解码元组。
支持的类型列表:
* 大整数
* 大连载
*布尔
* 字符
* 字符 N -- 字符(n)
* 日期
* 漂浮
* 浮动4
* 浮动8
* 整数
* JSON
* MAC地址
* 姓名
* 数字
* 对象
* 真实的
* 串行
* smallint
* 小系列
* 文本
* 时间
* 时间戳
*时间
* uuid
* 变量
* 变量 N -- 变量(n)
* xid
* XML
* ~ -- 忽略元组中剩余的所有属性
-f 显示格式化的块内容转储以及解释
-h 显示此信息
-i 显示已解释的项目详细信息
-k 验证块校验和
-R 显示文件中特定的块范围(块是
从 0 开始索引)
[startblock]:开始的块
[endblock]:块结束于
没有结束块的起始块将格式化单个块
-s 强制段大小为 [segsize]
-n 强制段号为 [segnumber]
-S 强制块大小为 [blocksize]
-x 强制将块项的格式解释为索引项
-y 强制将块项的格式解释为堆项
以下选项对控制文件有效:
-c 解释列为控制文件的文件
-f 显示格式化的内容转储以及解释
-S 强块大小为 [blocksize]
附加功能:
-m 将文件解释为 pg_filenode.map 文件并打印内容
(所有其他选项将被忽略)四、一些使用举例
4.1初始化测试环境
//创建测试数据
postgres=# create table tab_testdump(id int,info text,crt_time timestamp);
CREATE TABLE
postgres=# insert into tab_testdump select generate_series(1,10),left(md5(random()::text),8),clock_timestamp();
INSERT 0 10
postgres=# select * from tab_testdump;
id | info | crt_time
----+----------+----------------------------
1 | 9514a4d8 | 2024-01-10 13:36:25.998179
2 | 0b05a4c8 | 2024-01-10 13:36:25.998652
3 | 5e3cac92 | 2024-01-10 13:36:25.998659
4 | 26b50a38 | 2024-01-10 13:36:25.998662
5 | f7dd5e12 | 2024-01-10 13:36:25.998666
6 | 34916ff9 | 2024-01-10 13:36:25.998669
7 | 15ae6253 | 2024-01-10 13:36:25.998672
8 | db21b153 | 2024-01-10 13:36:25.998675
9 | dd34afae | 2024-01-10 13:36:25.998678
10 | 7f85d207 | 2024-01-10 13:36:25.998681
(10 rows)
//查看表对应的文件位置
postgres=# select pg_relation_filepath('tab_testdump');
pg_relation_filepath
----------------------
base/13008/33120
(1 row)
//确保数据刷到磁盘
postgres=# checkpoint;
CHECKPOINT4.2 使用举例
4.2.1 直接使用
读取到的东西除了表头的相关结构,显示的是数据所处的偏移量,数据部分不能直接让我们知道所存储的具体数据。
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump base/13008/33120
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility
*
* File: base/13008/33120
* Options used: None
*******************************************************************
Block 0 ********************************************************
<Header> -----
Block Offset: 0x00000000 Offsets: Lower 64 (0x0040)
Block: Size 8192 Version 4 Upper 7712 (0x1e20)
LSN: logid 0 recoff 0x11286460 Special 8192 (0x2000)
Items: 10 Free Space: 7648
Checksum: 0x0000 Prune XID: 0x00000000 Flags: 0x0000 ()
Length (including item array): 64
<Data> -----
Item 1 -- Length: 48 Offset: 8144 (0x1fd0) Flags: NORMAL
Item 2 -- Length: 48 Offset: 8096 (0x1fa0) Flags: NORMAL
Item 3 -- Length: 48 Offset: 8048 (0x1f70) Flags: NORMAL
Item 4 -- Length: 48 Offset: 8000 (0x1f40) Flags: NORMAL
Item 5 -- Length: 48 Offset: 7952 (0x1f10) Flags: NORMAL
Item 6 -- Length: 48 Offset: 7904 (0x1ee0) Flags: NORMAL
Item 7 -- Length: 48 Offset: 7856 (0x1eb0) Flags: NORMAL
Item 8 -- Length: 48 Offset: 7808 (0x1e80) Flags: NORMAL
Item 9 -- Length: 48 Offset: 7760 (0x1e50) Flags: NORMAL
Item 10 -- Length: 48 Offset: 7712 (0x1e20) Flags: NORMAL
*** End of File Encountered. Last Block Read: 0 ***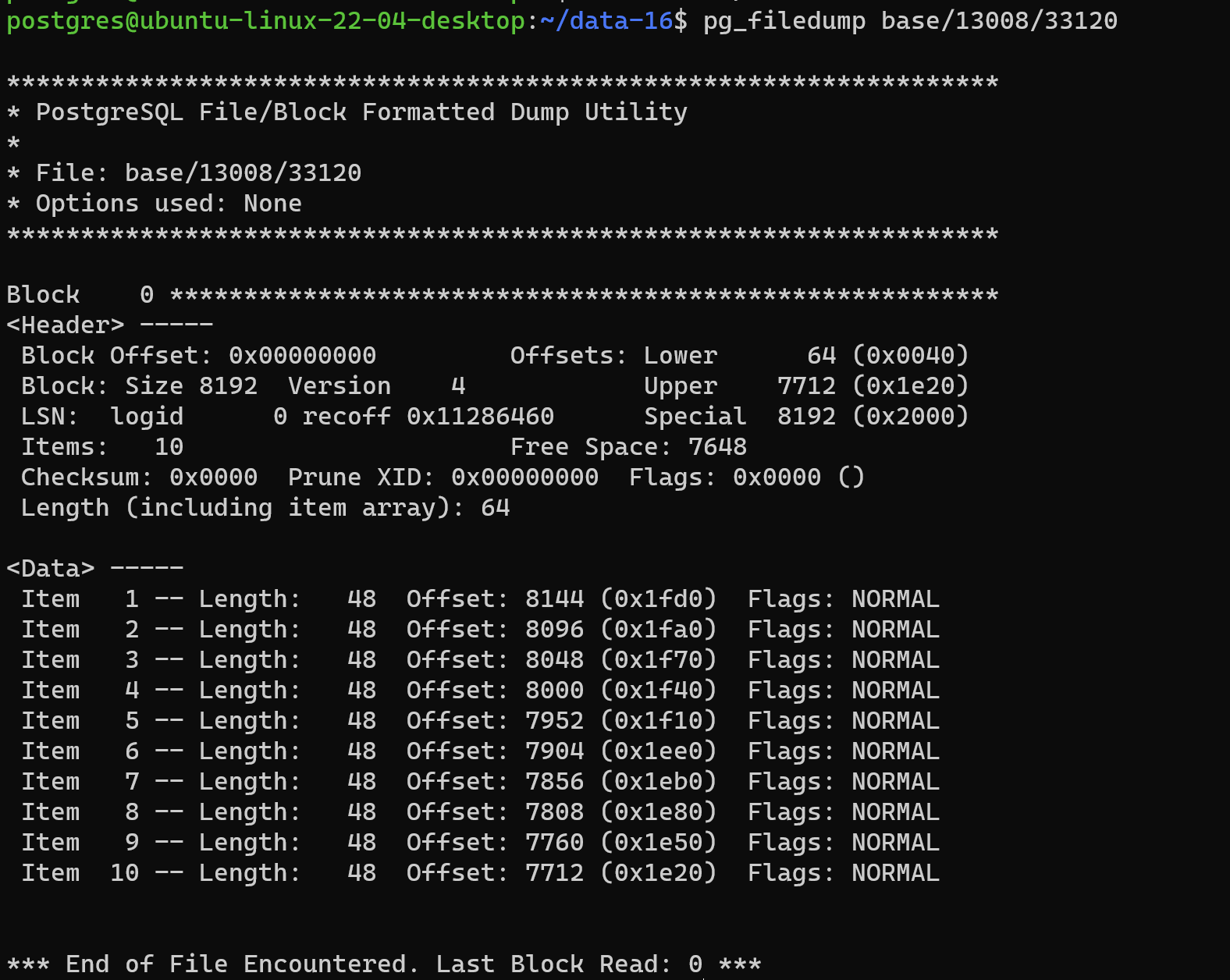
4.2.2 进一步带上 -D选项(读取所有的数据,包含未清理的死元组)
使用-D选项将其转换成可以直观读取的格式,COPY:XXX部分显示的便是表中的实际数据,但是PostgreSQL数据库的MVCC是基于多版本的,这样查看出的数据是包含死元组数据的,并不是数据库里查询的显示的数据。
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D int,text,timestamp base/13008/33120
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility
*
* File: base/13008/33120
* Options used: -D int,text,timestamp
*******************************************************************
Block 0 ********************************************************
<Header> -----
Block Offset: 0x00000000 Offsets: Lower 64 (0x0040)
Block: Size 8192 Version 4 Upper 7712 (0x1e20)
LSN: logid 0 recoff 0x11286460 Special 8192 (0x2000)
Items: 10 Free Space: 7648
Checksum: 0x0000 Prune XID: 0x00000000 Flags: 0x0000 ()
Length (including item array): 64
<Data> -----
Item 1 -- Length: 48 Offset: 8144 (0x1fd0) Flags: NORMAL
COPY: 1 9514a4d8 2024-01-10 13:36:25.998179
Item 2 -- Length: 48 Offset: 8096 (0x1fa0) Flags: NORMAL
COPY: 2 0b05a4c8 2024-01-10 13:36:25.998652
Item 3 -- Length: 48 Offset: 8048 (0x1f70) Flags: NORMAL
COPY: 3 5e3cac92 2024-01-10 13:36:25.998659
Item 4 -- Length: 48 Offset: 8000 (0x1f40) Flags: NORMAL
COPY: 4 26b50a38 2024-01-10 13:36:25.998662
Item 5 -- Length: 48 Offset: 7952 (0x1f10) Flags: NORMAL
COPY: 5 f7dd5e12 2024-01-10 13:36:25.998666
Item 6 -- Length: 48 Offset: 7904 (0x1ee0) Flags: NORMAL
COPY: 6 34916ff9 2024-01-10 13:36:25.998669
Item 7 -- Length: 48 Offset: 7856 (0x1eb0) Flags: NORMAL
COPY: 7 15ae6253 2024-01-10 13:36:25.998672
Item 8 -- Length: 48 Offset: 7808 (0x1e80) Flags: NORMAL
COPY: 8 db21b153 2024-01-10 13:36:25.998675
Item 9 -- Length: 48 Offset: 7760 (0x1e50) Flags: NORMAL
COPY: 9 dd34afae 2024-01-10 13:36:25.998678
Item 10 -- Length: 48 Offset: 7712 (0x1e20) Flags: NORMAL
COPY: 10 7f85d207 2024-01-10 13:36:25.998681
*** End of File Encountered. Last Block Read: 0 ***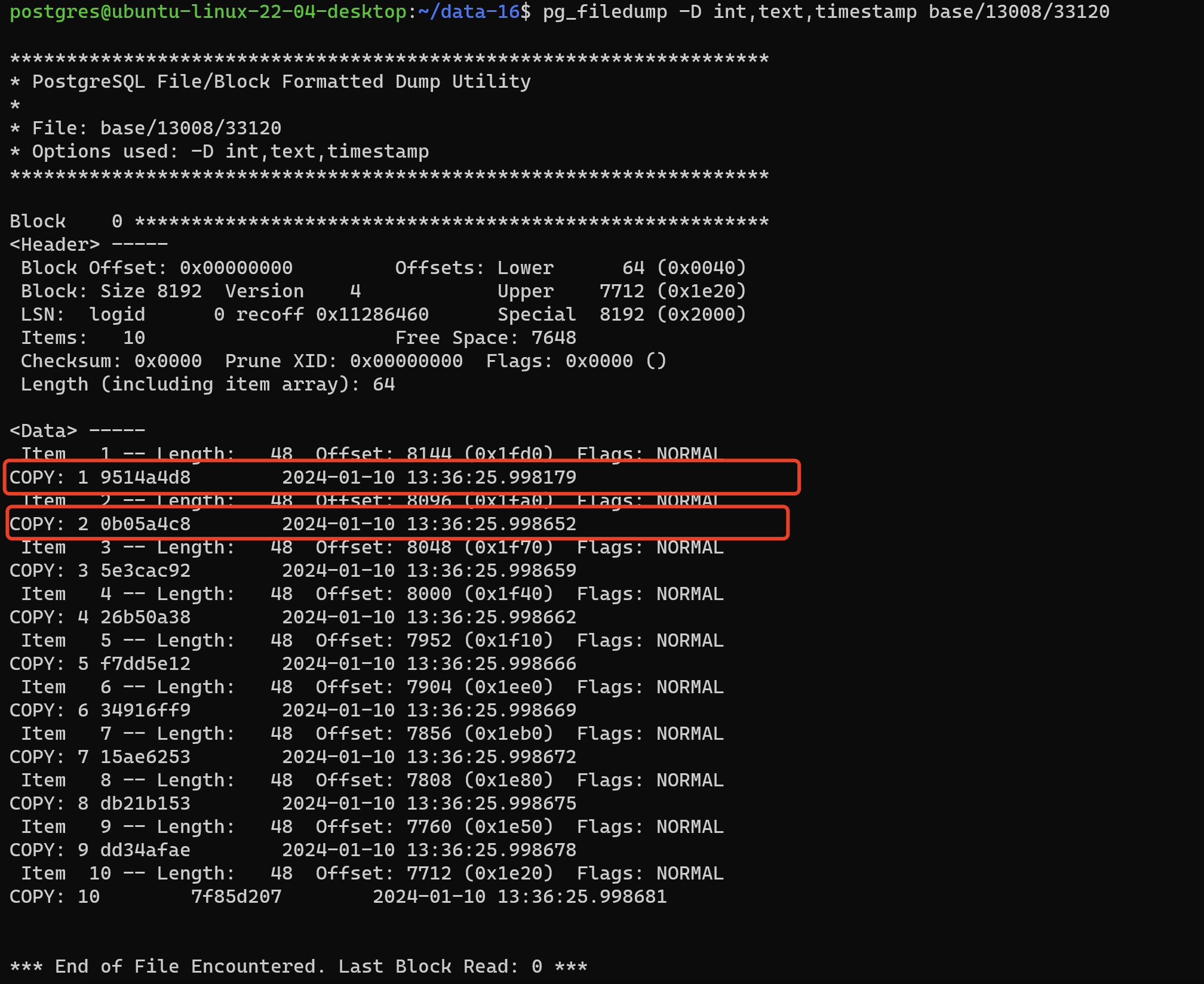
4.2.3 筛选实际数据部分(读取所有的数据,包含未清理的死元组)
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D int,text,timestamp base/13008/33120 | grep 'COPY'
COPY: 1 9514a4d8 2024-01-10 13:36:25.998179
COPY: 2 0b05a4c8 2024-01-10 13:36:25.998652
COPY: 3 5e3cac92 2024-01-10 13:36:25.998659
COPY: 4 26b50a38 2024-01-10 13:36:25.998662
COPY: 5 f7dd5e12 2024-01-10 13:36:25.998666
COPY: 6 34916ff9 2024-01-10 13:36:25.998669
COPY: 7 15ae6253 2024-01-10 13:36:25.998672
COPY: 8 db21b153 2024-01-10 13:36:25.998675
COPY: 9 dd34afae 2024-01-10 13:36:25.998678
COPY: 10 7f85d207 2024-01-10 13:36:25.998681
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D int,text,timestamp base/13008/33120 | grep 'COPY'| awk '{print $2,$3,$4}'
1 9514a4d8 2024-01-10
2 0b05a4c8 2024-01-10
3 5e3cac92 2024-01-10
4 26b50a38 2024-01-10
5 f7dd5e12 2024-01-10
6 34916ff9 2024-01-10
7 15ae6253 2024-01-10
8 db21b153 2024-01-10
9 dd34afae 2024-01-10
10 7f85d207 2024-01-10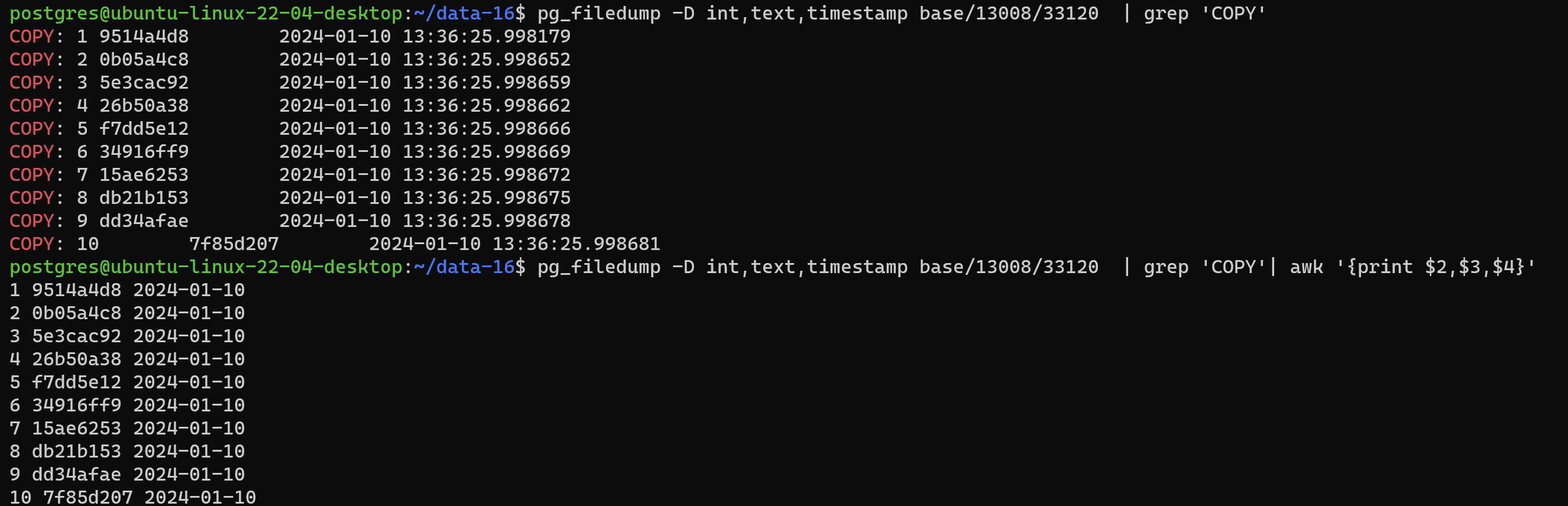

4.2.4 读取表中数据(排除死元组)
上面已经提到了,如果仅仅使用 -D选项,是会包含live_tup和dead_tup的,这样我们就没办法得到准确的表里的数据。
所以我们需要过滤出死元组。
4.2.4.1 创造含死元组的表
先进行一个更新,创造死元组的数据。
postgres=# update tab_testdump set info='ysladeadtup' where id=10;
UPDATE 1
postgres=# select * from tab_testdump;
id | info | crt_time
----+-------------+----------------------------
1 | 9514a4d8 | 2024-01-10 13:36:25.998179
2 | 0b05a4c8 | 2024-01-10 13:36:25.998652
3 | 5e3cac92 | 2024-01-10 13:36:25.998659
4 | 26b50a38 | 2024-01-10 13:36:25.998662
5 | f7dd5e12 | 2024-01-10 13:36:25.998666
6 | 34916ff9 | 2024-01-10 13:36:25.998669
7 | 15ae6253 | 2024-01-10 13:36:25.998672
8 | db21b153 | 2024-01-10 13:36:25.998675
9 | dd34afae | 2024-01-10 13:36:25.998678
10 | ysladeadtup | 2024-01-10 13:36:25.998681
(10 rows)
postgres=# select n_tup_upd,n_live_tup,n_dead_tup from pg_stat_all_tables where relname='tab_testdump';
n_tup_upd | n_live_tup | n_dead_tup
-----------+------------+------------
1 | 10 | 1
(1 row)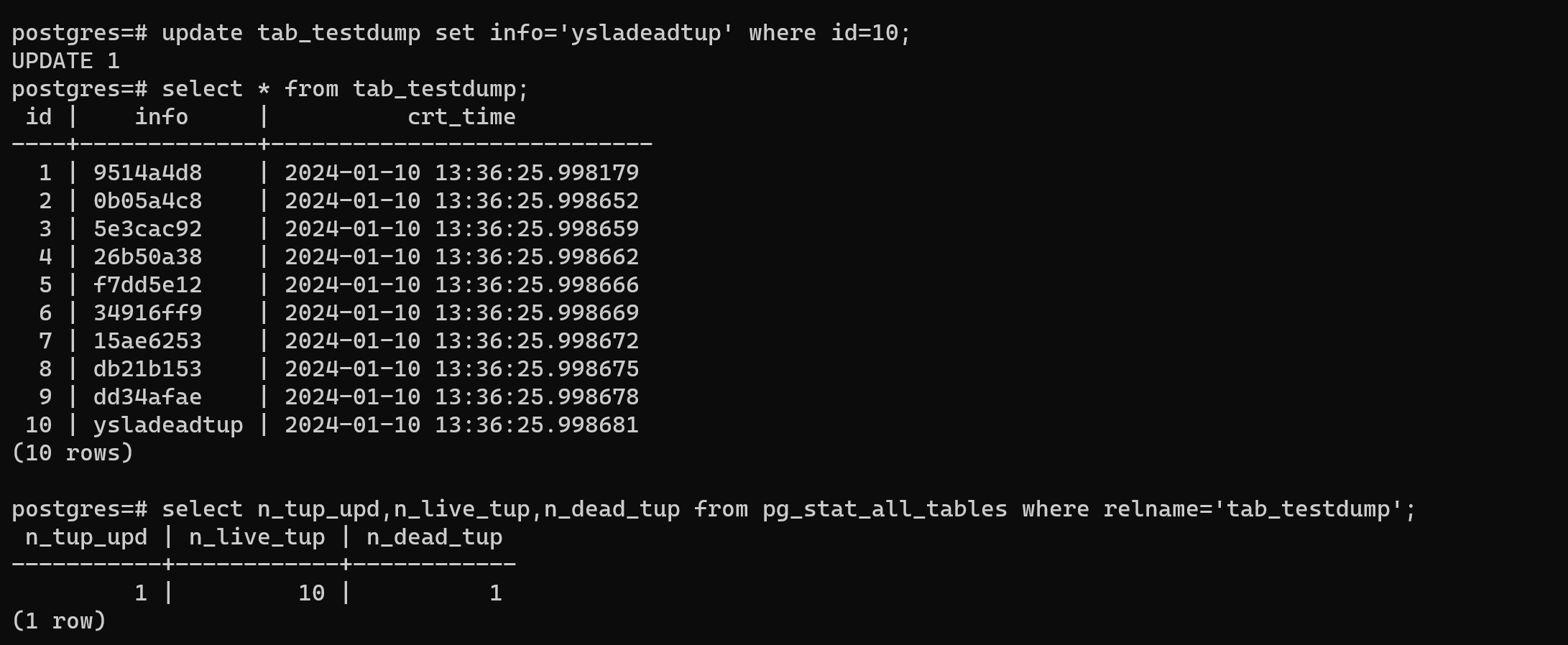
此时用上边pg_filedump去看包含死元组的数据,这样其实无法分出死元组和活跃的元组。无法找到真实的数据。
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D int,text,timestamp base/13008/33120 | grep 'COPY'
COPY: 1 9514a4d8 2024-01-10 13:36:25.998179
COPY: 2 0b05a4c8 2024-01-10 13:36:25.998652
COPY: 3 5e3cac92 2024-01-10 13:36:25.998659
COPY: 4 26b50a38 2024-01-10 13:36:25.998662
COPY: 5 f7dd5e12 2024-01-10 13:36:25.998666
COPY: 6 34916ff9 2024-01-10 13:36:25.998669
COPY: 7 15ae6253 2024-01-10 13:36:25.998672
COPY: 8 db21b153 2024-01-10 13:36:25.998675
COPY: 9 dd34afae 2024-01-10 13:36:25.998678
COPY: 10 7f85d207 2024-01-10 13:36:25.998681
COPY: 10 ysladeadtup 2024-01-10 13:36:25.998681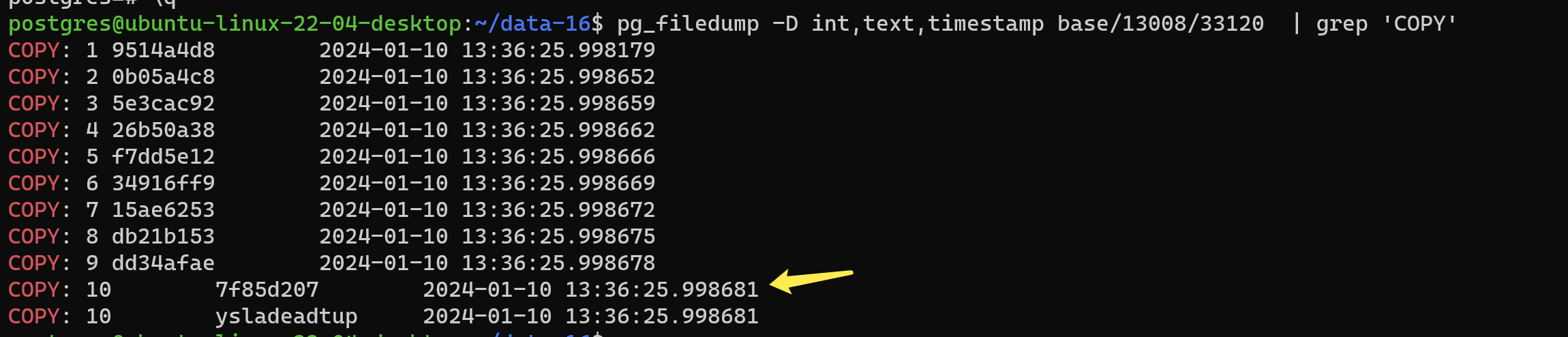
4.2.4.2 pg_filedump查看解析后的元组的xmin和xmax
这个时候使用pg_filedump的时候需要带上 -i选项。这个时候
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -i -D int,text,timestamp base/13008/33120
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility
*
* File: base/13008/33120
* Options used: -i -D int,text,timestamp
*******************************************************************
Block 0 ********************************************************
<Header> -----
Block Offset: 0x00000000 Offsets: Lower 68 (0x0044)
Block: Size 8192 Version 4 Upper 7664 (0x1df0)
LSN: logid 0 recoff 0x112868f0 Special 8192 (0x2000)
Items: 11 Free Space: 7596
Checksum: 0x0000 Prune XID: 0x000006c6 Flags: 0x0000 ()
Length (including item array): 68
<Data> -----
Item 1 -- Length: 48 Offset: 8144 (0x1fd0) Flags: NORMAL
XMIN: 1733 XMAX: 0 CID|XVAC: 0
Block Id: 0 linp Index: 1 Attributes: 3 Size: 24
infomask: 0x0902 (HASVARWIDTH|XMIN_COMMITTED|XMAX_INVALID)
COPY: 1 9514a4d8 2024-01-10 13:36:25.998179
Item 2 -- Length: 48 Offset: 8096 (0x1fa0) Flags: NORMAL
XMIN: 1733 XMAX: 0 CID|XVAC: 0
Block Id: 0 linp Index: 2 Attributes: 3 Size: 24
infomask: 0x0902 (HASVARWIDTH|XMIN_COMMITTED|XMAX_INVALID)
COPY: 2 0b05a4c8 2024-01-10 13:36:25.998652
Item 3 -- Length: 48 Offset: 8048 (0x1f70) Flags: NORMAL
XMIN: 1733 XMAX: 0 CID|XVAC: 0
Block Id: 0 linp Index: 3 Attributes: 3 Size: 24
infomask: 0x0902 (HASVARWIDTH|XMIN_COMMITTED|XMAX_INVALID)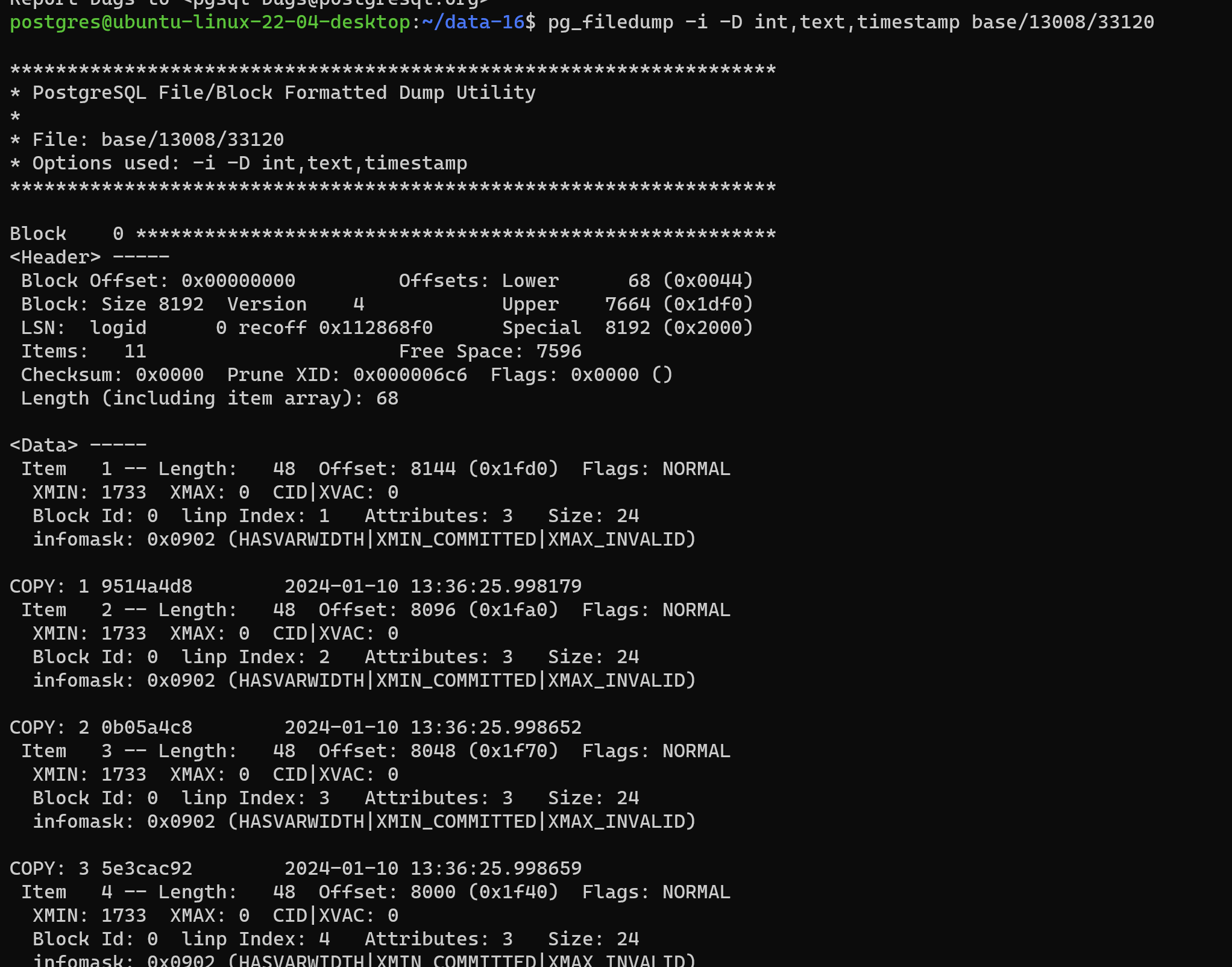
4.2.4.3 命令行语句过滤
暂时处理
10 ysladeadtup 2024-01-10 13:36:25.998681
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX'
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 1 9514a4d8 2024-01-10 13:36:25.998179
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 2 0b05a4c8 2024-01-10 13:36:25.998652
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 3 5e3cac92 2024-01-10 13:36:25.998659
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 4 26b50a38 2024-01-10 13:36:25.998662
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 5 f7dd5e12 2024-01-10 13:36:25.998666
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 6 34916ff9 2024-01-10 13:36:25.998669
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 7 15ae6253 2024-01-10 13:36:25.998672
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 8 db21b153 2024-01-10 13:36:25.998675
XMIN: 1733 XMAX: 0 CID|XVAC: 0
COPY: 9 dd34afae 2024-01-10 13:36:25.998678
XMIN: 1733 XMAX: 1734 CID|XVAC: 0
COPY: 10 7f85d207 2024-01-10 13:36:25.998681
XMIN: 1734 XMAX: 0 CID|XVAC: 0
COPY: 10 ysladeadtup 2024-01-10 13:36:25.998681去掉COPY字段。
pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'
1733 XMAX: 0 CID|XVAC: 0
1 9514a4d8 2024-01-10 13:36:25.998179
1733 XMAX: 0 CID|XVAC: 0
2 0b05a4c8 2024-01-10 13:36:25.998652
1733 XMAX: 0 CID|XVAC: 0
3 5e3cac92 2024-01-10 13:36:25.998659
1733 XMAX: 0 CID|XVAC: 0
4 26b50a38 2024-01-10 13:36:25.998662
1733 XMAX: 0 CID|XVAC: 0
5 f7dd5e12 2024-01-10 13:36:25.998666
1733 XMAX: 0 CID|XVAC: 0
6 34916ff9 2024-01-10 13:36:25.998669
1733 XMAX: 0 CID|XVAC: 0
7 15ae6253 2024-01-10 13:36:25.998672
1733 XMAX: 0 CID|XVAC: 0
8 db21b153 2024-01-10 13:36:25.998675
1733 XMAX: 0 CID|XVAC: 0
9 dd34afae 2024-01-10 13:36:25.998678
1733 XMAX: 1734 CID|XVAC: 0
10 7f85d207 2024-01-10 13:36:25.998681
1734 XMAX: 0 CID|XVAC: 0
10 ysladeadtup 2024-01-10 13:36:25.998681合并到一行
pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'
1733 XMAX: 0 CID|XVAC: 0 1 9514a4d8 2024-01-10 13:36:25.998179
1733 XMAX: 0 CID|XVAC: 0 2 0b05a4c8 2024-01-10 13:36:25.998652
1733 XMAX: 0 CID|XVAC: 0 3 5e3cac92 2024-01-10 13:36:25.998659
1733 XMAX: 0 CID|XVAC: 0 4 26b50a38 2024-01-10 13:36:25.998662
1733 XMAX: 0 CID|XVAC: 0 5 f7dd5e12 2024-01-10 13:36:25.998666
1733 XMAX: 0 CID|XVAC: 0 6 34916ff9 2024-01-10 13:36:25.998669
1733 XMAX: 0 CID|XVAC: 0 7 15ae6253 2024-01-10 13:36:25.998672
1733 XMAX: 0 CID|XVAC: 0 8 db21b153 2024-01-10 13:36:25.998675
1733 XMAX: 0 CID|XVAC: 0 9 dd34afae 2024-01-10 13:36:25.998678
1733 XMAX: 1734 CID|XVAC: 0 10 7f85d207 2024-01-10 13:36:25.998681
1734 XMAX: 0 CID|XVAC: 0 10 ysladeadtup 2024-01-10 13:36:25.998681分别查看数据部分和区分
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| awk '{print $1,$2,$3,$4,$5}'
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 0 CID|XVAC: 0
1733 XMAX: 1734 CID|XVAC: 0
1734 XMAX: 0 CID|XVAC: 0
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| awk '{print $6,$7,$8}'
1 9514a4d8 2024-01-10
2 0b05a4c8 2024-01-10
3 5e3cac92 2024-01-10
4 26b50a38 2024-01-10
5 f7dd5e12 2024-01-10
6 34916ff9 2024-01-10
7 15ae6253 2024-01-10
8 db21b153 2024-01-10
9 dd34afae 2024-01-10
10 7f85d207 2024-01-10
10 ysladeadtup 2024-01-10过滤语句如下,这部分根据xmax过滤掉了一部分语句,如果xmax为0,说明它从未被删除,并且是可见的。一条的元组创建的时候,xmax是0,而当这条数据记录被修改的时候,会把修改这条记录的xid写入xmax,然后创建一个新的元组来存放这条记录的新副本。当这个事务提交的时候,我们就只能看到这个新的元组的数据,而看不见老的元组了。
这里可以根据需求做调整。解析xlog,获取对应重点操作的位置,再结合xid过滤数据。
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'
1733 XMAX: 0 CID|XVAC: 0 1 9514a4d8 2024-01-10 13:36:25.998179
1733 XMAX: 0 CID|XVAC: 0 2 0b05a4c8 2024-01-10 13:36:25.998652
1733 XMAX: 0 CID|XVAC: 0 3 5e3cac92 2024-01-10 13:36:25.998659
1733 XMAX: 0 CID|XVAC: 0 4 26b50a38 2024-01-10 13:36:25.998662
1733 XMAX: 0 CID|XVAC: 0 5 f7dd5e12 2024-01-10 13:36:25.998666
1733 XMAX: 0 CID|XVAC: 0 6 34916ff9 2024-01-10 13:36:25.998669
1733 XMAX: 0 CID|XVAC: 0 7 15ae6253 2024-01-10 13:36:25.998672
1733 XMAX: 0 CID|XVAC: 0 8 db21b153 2024-01-10 13:36:25.998675
1733 XMAX: 0 CID|XVAC: 0 9 dd34afae 2024-01-10 13:36:25.998678
1734 XMAX: 0 CID|XVAC: 0 10 ysladeadtup 2024-01-10 13:36:25.998681
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{print $6,$7,$8}'
1 9514a4d8 2024-01-10
2 0b05a4c8 2024-01-10
3 5e3cac92 2024-01-10
4 26b50a38 2024-01-10
5 f7dd5e12 2024-01-10
6 34916ff9 2024-01-10
7 15ae6253 2024-01-10
8 db21b153 2024-01-10
9 dd34afae 2024-01-10
10 ysladeadtup 2024-01-104.2.4.4 最终过滤死元组的命令行语句
其中 -D后要跟上表数据的类型 ,最后的awk输出的列和表的列要对上,其中前5行为我合并的带有xmin,xmax的行,最终不需要打印出来(我是为了根据xmax来筛除掉死元组)。具体根据什么进行分割需要根据数据情况进行,灵活变化。
以空格分割(时间戳可能有问题)
pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{print $6,$7,$8,$9}'
1 9514a4d8 2024-01-10 13:36:25.998179
2 0b05a4c8 2024-01-10 13:36:25.998652
3 5e3cac92 2024-01-10 13:36:25.998659
4 26b50a38 2024-01-10 13:36:25.998662
5 f7dd5e12 2024-01-10 13:36:25.998666
6 34916ff9 2024-01-10 13:36:25.998669
7 15ae6253 2024-01-10 13:36:25.998672
8 db21b153 2024-01-10 13:36:25.998675
9 dd34afae 2024-01-10 13:36:25.998678
10 ysladeadtup 2024-01-10 13:36:25.998681以逗号分隔
pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{print $6","$7","$8,$9}'>/home/postgres/dumptest_data.csv
1,9514a4d8,2024-01-10 13:36:25.998179
2,0b05a4c8,2024-01-10 13:36:25.998652
3,5e3cac92,2024-01-10 13:36:25.998659
4,26b50a38,2024-01-10 13:36:25.998662
5,f7dd5e12,2024-01-10 13:36:25.998666
6,34916ff9,2024-01-10 13:36:25.998669
7,15ae6253,2024-01-10 13:36:25.998672
8,db21b153,2024-01-10 13:36:25.998675
9,dd34afae,2024-01-10 13:36:25.998678
10,ysladeadtup,2024-01-10 13:36:25.9986814.2.5 使用copy命令把数据导入到有表结构的表里
postgres=#
postgres=# select * from tab_1;
id | info | crt_time
----+------+----------
(0 rows)
postgres=# copy tab_1 from '/home/postgres/dumptest_data.csv' with (FORMAT csv,DELIMITER ',' ,escape '\',header false,encoding ' UTF8');
COPY 10
postgres=# select * from tab_1;
id | info | crt_time
----+-------------+----------------------------
1 | 9514a4d8 | 2024-01-10 13:36:25.998179
2 | 0b05a4c8 | 2024-01-10 13:36:25.998652
3 | 5e3cac92 | 2024-01-10 13:36:25.998659
4 | 26b50a38 | 2024-01-10 13:36:25.998662
5 | f7dd5e12 | 2024-01-10 13:36:25.998666
6 | 34916ff9 | 2024-01-10 13:36:25.998669
7 | 15ae6253 | 2024-01-10 13:36:25.998672
8 | db21b153 | 2024-01-10 13:36:25.998675
9 | dd34afae | 2024-01-10 13:36:25.998678
10 | ysladeadtup | 2024-01-10 13:36:25.998681
(10 rows)五、从一个起不来的库找回数据究竟需要做什么?
5.1 相关几个问题思考
1.有哪些库(读取pg_database系统表的物理文件,去除死元组)
2.库的属性(读取pg_database系统表的物理文件)
3.库里有哪些对象,表,索引(读取pg_class等系统表的物理文件,读取pg_indexes系统表文件,indexdef字段包含创建索引的定义,直接创建即可)
4.表的列名如何获取(读取pg_attribute系统表)
5.表的列类型如何获取(读取pg_attribute和pg_type系统表进行关联)
6.数据怎么读取(读取表文件,结合上边的列类型筛出实际数据)
7.导入数据(copy导入)
5.2 数据库结构分析
•pg_database:包含了有哪些数据库
•pg_class:包含了所有表的重要元数据
•pg_namespace:包含了模式的元数据
•pg_attribute:包含了所有的列定义
•pg_type:包含了类型的名称
5.3 关于oid和relfilenode的映射关系
pg_class视图里,通过reltablespace字段我们也可以发现分为两类:一类是pg_type、pg_attribute、pg_proc和pg_class,它们是非共享的表,在内核中我们称为Nail表。而另一类则是reltablespace为1664的,即在pg_global表空间里的共享表。
PostgreSQL中的每张表在磁盘上都有与之相关的文件,而这些文件的名字便是relfilenode,我们可以通过pg_class的relfilenode字段去查询。有一部分特殊的表我们会发现其对应的表relfilenode为0,官方文档的解释为:0表示这是一个"映射"关系,其磁盘文件名取决于底层状态。对于这种访问十分频繁的系统表,不希望每次都是从一些其它的系统表去查询,这样性能便会非常低,它们便是通过pg_filenode.map文件去进行管理的。pg_filenode.map在base的目录每个库的目录以及global目录下均有一个。
postgres@ubuntu-linux-22-04-desktop:~/data-16$ ll global/pg_filenode.map
-rw------- 1 postgres postgres 524 Dec 26 01:06 global/pg_filenode.map
postgres@ubuntu-linux-22-04-desktop:~/data-16$ ll base/*/pg_filenode.map
-rw------- 1 postgres postgres 524 Dec 26 01:06 base/1/pg_filenode.map
-rw------- 1 postgres postgres 524 Jan 17 10:40 base/13008/pg_filenode.map
-rw------- 1 postgres postgres 524 Dec 26 01:06 base/16385/pg_filenode.map
-rw------- 1 postgres postgres 524 Dec 26 01:06 base/4/pg_filenode.map对于一张普通表,其relfilenode和oid默认是一样的。系统表有的也是。当我们对该表进行了例如vacuum full、truncate之类的操作后,那么relfilenode便会发生变化。
postgres=# select relname,oid,relfilenode,reltablespace from pg_class where relname in ('pg_database','pg_class','pg_type','pg_namespace','pg_attribute','tab_1');
relname | oid | relfilenode | reltablespace
--------------+-------+-------------+---------------
pg_type | 1247 | 0 | 0
tab_1 | 33125 | 33136 | 0
pg_namespace | 2615 | 2615 | 0
pg_database | 1262 | 0 | 1664
pg_attribute | 1249 | 0 | 0
pg_class | 1259 | 0 | 0
(6 rows)5.3.1 pg_filenode.map(非共享)
每个数据库的目录下都有一个pg_filenode.map,在pg_filenode.map文件中,将这些系统表的oid与relfileno做映射,文件的大小为512,刚好是一个OS disk sector的大小。这个文件最多存放62条系统catalog表的记录
5.3.1.1数据库非共享系统表
postgres@ubuntu-linux-22-04-desktop:~/data-16/base/13008$ pg_filedump -m pg_filenode.map
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility
*
* File: pg_filenode.map
* Options used: -m
*******************************************************************
Magic Number: 0x592717 (CORRECT)
Num Mappings: 17
Detailed Mappings list:
OID: 1259 Filenode: 41317
OID: 1249 Filenode: 1249
OID: 1255 Filenode: 1255
OID: 1247 Filenode: 1247
OID: 2836 Filenode: 2836
OID: 2837 Filenode: 2837
OID: 4171 Filenode: 4171
OID: 4172 Filenode: 4172
OID: 2690 Filenode: 2690
OID: 2691 Filenode: 2691
OID: 2703 Filenode: 2703
OID: 2704 Filenode: 2704
OID: 2658 Filenode: 2658
OID: 2659 Filenode: 2659
OID: 2662 Filenode: 41320
OID: 2663 Filenode: 41321
OID: 3455 Filenode: 41322取所有的OID
postgres@ubuntu-linux-22-04-desktop:~/data-16/base/13008$ pg_filedump -m pg_filenode.map | grep OID| awk '{print "or oid="$2}'|awk 'ORS=NR%17?" ":"\n"{print}'
or oid=1259 or oid=1249 or oid=1255 or oid=1247 or oid=2836 or oid=2837 or oid=4171 or oid=4172 or oid=2690 or oid=2691 or oid=2703 or oid=2704 or oid=2658 or oid=2659 or oid=2662 or oid=2663 or oid=3455
原本数据库里系统表和oid的对应关系如下,其中pg_toast_1255和pg_toast_1247分别为pg_proc和pg_type的toast表
postgres=# select relname,oid,relfilenode,reltablespace from pg_class where oid=1259 or oid=1249 or oid=1255 or oid=1247 or oid=2836 or oid=2837 or oid=4171 or oid=4172 or oid=2690 or oid=2691 or oid=2703 or oid=2704 or oid=2658 or oid=2659 or oid=2662 or oid=2663 or oid=3455;
relname | oid | relfilenode | reltablespace
-----------------------------------+------+-------------+---------------
pg_type | 1247 | 0 | 0
pg_toast_1255 | 2836 | 0 | 0
pg_toast_1247 | 4171 | 0 | 0
pg_toast_1255_index | 2837 | 0 | 0
pg_toast_1247_index | 4172 | 0 | 0
pg_proc_oid_index | 2690 | 0 | 0
pg_proc_proname_args_nsp_index | 2691 | 0 | 0
pg_type_oid_index | 2703 | 0 | 0
pg_type_typname_nsp_index | 2704 | 0 | 0
pg_attribute_relid_attnam_index | 2658 | 0 | 0
pg_attribute_relid_attnum_index | 2659 | 0 | 0
pg_class_oid_index | 2662 | 0 | 0
pg_class_relname_nsp_index | 2663 | 0 | 0
pg_class_tblspc_relfilenode_index | 3455 | 0 | 0
pg_attribute | 1249 | 0 | 0
pg_proc | 1255 | 0 | 0
pg_class | 1259 | 0 | 0
(17 rows)5.3.1.1.1命令
得出脚本命令
pg_filedump -m pg_filenode.map | grep OID | grep 1247 | awk '{print "Relname:pg_type " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2836 | awk '{print "Relname:pg_toast_1255 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4171 | awk '{print "Relname:pg_toast_1247 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2837 | awk '{print "Relname:pg_toast_1255_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4172 | awk '{print "Relname:pg_toast_1247_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2690 | awk '{print "Relname:pg_proc_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2691 | awk '{print "Relname:pg_proc_proname_args_nsp_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2703 | awk '{print "Relname:pg_type_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2704 | awk '{print "Relname:pg_type_typname_nsp_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2658 | awk '{print "Relname:pg_attribute_relid_attnam_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2659 | awk '{print "Relname:pg_attribute_relid_attnum_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2662 | awk '{print "Relname:pg_class_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2663 | awk '{print "Relname:pg_class_relname_nsp_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 3455 | awk '{print "Relname:pg_class_tblspc_relfilenode_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1249 | awk '{print "Relname:pg_attribute " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1255 | awk '{print "Relname:pg_proc " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1259 | awk '{print "Relname:pg_class " $1" "$2" "$3" "$4}'我的结果如下
Relname:pg_type OID: 1247 Filenode: 1247
Relname:pg_toast_1255 OID: 2836 Filenode: 2836
Relname:pg_toast_1247 OID: 4171 Filenode: 4171
Relname:pg_toast_1255_index OID: 2837 Filenode: 2837
Relname:pg_toast_1247_index OID: 4172 Filenode: 4172
Relname:pg_proc_oid_index OID: 2690 Filenode: 2690
Relname:pg_proc_proname_args_nsp_index OID: 2691 Filenode: 2691
Relname:pg_type_oid_index OID: 2703 Filenode: 2703
Relname:pg_type_typname_nsp_index OID: 2704 Filenode: 2704
Relname:pg_attribute_relid_attnam_index OID: 2658 Filenode: 2658
Relname:pg_attribute_relid_attnum_index OID: 2659 Filenode: 2659
Relname:pg_class_oid_index OID: 2662 Filenode: 41320
Relname:pg_class_relname_nsp_index OID: 2663 Filenode: 41321
Relname:pg_class_tblspc_relfilenode_index OID: 3455 Filenode: 41322
Relname:pg_attribute OID: 1249 Filenode: 1249
Relname:pg_proc OID: 1255 Filenode: 1255
Relname:pg_class OID: 1259 Filenode: 413175.3.1.2数据库global共享系统表
postgres@ubuntu-linux-22-04-desktop:~/data-16/global$ pg_filedump -m pg_filenode.map | grep OID| awk '{print "or oid="$2}'|awk 'ORS=NR%17?" ":"\n"{print}'
or oid=1262 or oid=2964 or oid=1213 or oid=1260 or oid=1261 or oid=1214 or oid=2396 or oid=6000 or oid=3592 or oid=6243 or oid=6100 or oid=4177 or oid=4178 or oid=2966 or oid=2967 or oid=4185 or oid=4186
or oid=4175 or oid=4176 or oid=2846 or oid=2847 or oid=4181 or oid=4182 or oid=4060 or oid=4061 or oid=6244 or oid=6245 or oid=4183 or oid=4184 or oid=2671 or oid=2672 or oid=2965 or oid=2697 or oid=2698
or oid=2676 or oid=2677 or oid=6303 or oid=2694 or oid=2695 or oid=6302 or oid=1232 or oid=1233 or oid=2397 or oid=6001 or oid=6002 or oid=3593 or oid=6246 or oid=6247 or oid=6114 or oid=6115取对应包含的系统表。
postgres=# select relname,oid,relfilenode,reltablespace from pg_class where oid=1262 or oid=2964 or oid=1213 or oid=1260 or oid=1261 or oid=1214 or oid=2396 or oid=6000 or oid=3592 or oid=6243 or oid=6100 or oid=4177 or oid=4178 or oid=2966 or oid=2967 or oid=4185 or oid=4186 or oid=4175 or oid=4176 or oid=2846 or oid=2847 or oid=4181 or oid=4182 or oid=4060 or oid=4061 or oid=6244 or oid=6245 or oid=4183 or oid=4184 or oid=2671 or oid=2672 or oid=2965 or oid=2697 or oid=2698 or oid=2676 or oid=2677 or oid=6303 or oid=2694 or oid=2695 or oid=6302 or oid=1232 or oid=1233 or oid=2397 or oid=6001 or oid=6002 or oid=3593 or oid=6246 or oid=6247 or oid=6114 or oid=6115;
relname | oid | relfilenode | reltablespace
-----------------------------------------+------+-------------+---------------
pg_toast_1262_index | 4178 | 0 | 1664
pg_toast_2964_index | 2967 | 0 | 1664
pg_toast_1213_index | 4186 | 0 | 1664
pg_toast_1260_index | 4176 | 0 | 1664
pg_toast_2396_index | 2847 | 0 | 1664
pg_toast_6000_index | 4182 | 0 | 1664
pg_toast_3592_index | 4061 | 0 | 1664
pg_toast_6243_index | 6245 | 0 | 1664
pg_toast_6100_index | 4184 | 0 | 1664
pg_database_datname_index | 2671 | 0 | 1664
pg_database_oid_index | 2672 | 0 | 1664
pg_db_role_setting_databaseid_rol_index | 2965 | 0 | 1664
pg_tablespace_oid_index | 2697 | 0 | 1664
pg_tablespace_spcname_index | 2698 | 0 | 1664
pg_authid_rolname_index | 2676 | 0 | 1664
pg_authid_oid_index | 2677 | 0 | 1664
pg_auth_members_oid_index | 6303 | 0 | 1664
pg_auth_members_role_member_index | 2694 | 0 | 1664
pg_auth_members_member_role_index | 2695 | 0 | 1664
pg_auth_members_grantor_index | 6302 | 0 | 1664
pg_shdepend_depender_index | 1232 | 0 | 1664
pg_shdepend_reference_index | 1233 | 0 | 1664
pg_shdescription_o_c_index | 2397 | 0 | 1664
pg_replication_origin_roiident_index | 6001 | 0 | 1664
pg_replication_origin_roname_index | 6002 | 0 | 1664
pg_shseclabel_object_index | 3593 | 0 | 1664
pg_parameter_acl_parname_index | 6246 | 0 | 1664
pg_parameter_acl_oid_index | 6247 | 0 | 1664
pg_subscription_oid_index | 6114 | 0 | 1664
pg_subscription_subname_index | 6115 | 0 | 1664
pg_authid | 1260 | 0 | 1664
pg_toast_6243 | 6244 | 0 | 1664
pg_toast_6100 | 4183 | 0 | 1664
pg_toast_1262 | 4177 | 0 | 1664
pg_toast_2964 | 2966 | 0 | 1664
pg_toast_1213 | 4185 | 0 | 1664
pg_toast_1260 | 4175 | 0 | 1664
pg_toast_2396 | 2846 | 0 | 1664
pg_toast_6000 | 4181 | 0 | 1664
pg_toast_3592 | 4060 | 0 | 1664
pg_database | 1262 | 0 | 1664
pg_db_role_setting | 2964 | 0 | 1664
pg_tablespace | 1213 | 0 | 1664
pg_auth_members | 1261 | 0 | 1664
pg_shdepend | 1214 | 0 | 1664
pg_shdescription | 2396 | 0 | 1664
pg_replication_origin | 6000 | 0 | 1664
pg_shseclabel | 3592 | 0 | 1664
pg_parameter_acl | 6243 | 0 | 1664
pg_subscription | 6100 | 0 | 1664
(50 rows)5.3.1.2.1命令
使用的命令
pg_filedump -m pg_filenode.map | grep OID | grep 4178| awk '{print "Relname:pg_toast_1262_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2967| awk '{print "Relname:pg_toast_2964_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4186| awk '{print "Relname:pg_toast_1213_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4176| awk '{print "Relname:pg_toast_1260_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2847| awk '{print "Relname:pg_toast_2396_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4182| awk '{print "Relname:pg_toast_6000_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4061| awk '{print "Relname:pg_toast_3592_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6245| awk '{print "Relname:pg_toast_6243_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4184| awk '{print "Relname:pg_toast_6100_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2671| awk '{print "Relname:pg_database_datname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2672| awk '{print "Relname:pg_database_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2965| awk '{print "Relname:pg_db_role_setting_databaseid_rol_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2697| awk '{print "Relname:pg_tablespace_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2698| awk '{print "Relname:pg_tablespace_spcname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2676| awk '{print "Relname:pg_authid_rolname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2677| awk '{print "Relname:pg_authid_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6303| awk '{print "Relname:pg_auth_members_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2694| awk '{print "Relname:pg_auth_members_role_member_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2695| awk '{print "Relname:pg_auth_members_member_role_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6302| awk '{print "Relname:pg_auth_members_grantor_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1232| awk '{print "Relname:pg_shdepend_depender_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1233| awk '{print "Relname:pg_shdepend_reference_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2397| awk '{print "Relname:pg_shdescription_o_c_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6001| awk '{print "Relname:pg_replication_origin_roiident_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6002| awk '{print "Relname:pg_replication_origin_roname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 3593| awk '{print "Relname:pg_shseclabel_object_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6246| awk '{print "Relname:pg_parameter_acl_parname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6247| awk '{print "Relname:pg_parameter_acl_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6114| awk '{print "Relname:pg_subscription_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6115| awk '{print "Relname:pg_subscription_subname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1260| awk '{print "Relname:pg_authid " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6244| awk '{print "Relname:pg_toast_6243 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4183| awk '{print "Relname:pg_toast_6100 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4177| awk '{print "Relname:pg_toast_1262 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2966| awk '{print "Relname:pg_toast_2964 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4185| awk '{print "Relname:pg_toast_1213 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4175| awk '{print "Relname:pg_toast_1260 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2846| awk '{print "Relname:pg_toast_2396 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4181| awk '{print "Relname:pg_toast_6000 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4060| awk '{print "Relname:pg_toast_3592 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1262| awk '{print "Relname:pg_database " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2964| awk '{print "Relname:pg_db_role_setting " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1213| awk '{print "Relname:pg_tablespace " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1261| awk '{print "Relname:pg_auth_members " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1214| awk '{print "Relname:pg_shdepend " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2396| awk '{print "Relname:pg_shdescription " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6000| awk '{print "Relname:pg_replication_origin " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 3592| awk '{print "Relname:pg_shseclabel " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6243| awk '{print "Relname:pg_parameter_acl " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6100| awk '{print "Relname:pg_subscription " $1" "$2" "$3" "$4}'结果如下
Relname:pg_toast_1262_index OID: 4178 Filenode: 4178
Relname:pg_toast_2964_index OID: 2967 Filenode: 2967
Relname:pg_toast_1213_index OID: 4186 Filenode: 4186
Relname:pg_toast_1260_index OID: 4176 Filenode: 4176
Relname:pg_toast_2396_index OID: 2847 Filenode: 2847
Relname:pg_toast_6000_index OID: 4182 Filenode: 4182
Relname:pg_toast_3592_index OID: 4061 Filenode: 4061
Relname:pg_toast_6243_index OID: 6245 Filenode: 6245
Relname:pg_toast_6100_index OID: 4184 Filenode: 4184
Relname:pg_database_datname_index OID: 2671 Filenode: 2671
Relname:pg_database_oid_index OID: 2672 Filenode: 2672
Relname:pg_db_role_setting_databaseid_rol_index OID: 2965 Filenode: 2965
Relname:pg_tablespace_oid_index OID: 2697 Filenode: 2697
Relname:pg_tablespace_spcname_index OID: 2698 Filenode: 2698
Relname:pg_authid_rolname_index OID: 2676 Filenode: 2676
Relname:pg_authid_oid_index OID: 2677 Filenode: 2677
Relname:pg_auth_members_oid_index OID: 6303 Filenode: 6303
Relname:pg_auth_members_role_member_index OID: 2694 Filenode: 2694
Relname:pg_auth_members_member_role_index OID: 2695 Filenode: 2695
Relname:pg_auth_members_grantor_index OID: 6302 Filenode: 6302
Relname:pg_shdepend_depender_index OID: 1232 Filenode: 1232
Relname:pg_shdepend_reference_index OID: 1233 Filenode: 1233
Relname:pg_shdescription_o_c_index OID: 2397 Filenode: 2397
Relname:pg_replication_origin_roiident_index OID: 6001 Filenode: 6001
Relname:pg_replication_origin_roname_index OID: 6002 Filenode: 6002
Relname:pg_shseclabel_object_index OID: 3593 Filenode: 3593
Relname:pg_parameter_acl_parname_index OID: 6246 Filenode: 6246
Relname:pg_parameter_acl_oid_index OID: 6247 Filenode: 6247
Relname:pg_subscription_oid_index OID: 6114 Filenode: 6114
Relname:pg_subscription_subname_index OID: 6115 Filenode: 6115
Relname:pg_authid OID: 1260 Filenode: 1260
Relname:pg_toast_6243 OID: 6244 Filenode: 6244
Relname:pg_toast_6100 OID: 4183 Filenode: 4183
Relname:pg_toast_1262 OID: 4177 Filenode: 4177
Relname:pg_toast_2964 OID: 2966 Filenode: 2966
Relname:pg_toast_1213 OID: 4185 Filenode: 4185
Relname:pg_toast_1260 OID: 4175 Filenode: 4175
Relname:pg_toast_2396 OID: 2846 Filenode: 2846
Relname:pg_toast_6000 OID: 4181 Filenode: 4181
Relname:pg_toast_3592 OID: 4060 Filenode: 4060
Relname:pg_database OID: 1262 Filenode: 1262
Relname:pg_db_role_setting OID: 2964 Filenode: 2964
Relname:pg_tablespace OID: 1213 Filenode: 1213
Relname:pg_auth_members OID: 1261 Filenode: 1261
Relname:pg_shdepend OID: 1214 Filenode: 1214
Relname:pg_shdescription OID: 2396 Filenode: 2396
Relname:pg_replication_origin OID: 6000 Filenode: 6000
Relname:pg_shseclabel OID: 3592 Filenode: 3592
Relname:pg_parameter_acl OID: 6243 Filenode: 6243
Relname:pg_subscription OID: 6100 Filenode: 61005.4读取pg_tablespace系统表(全局)
pg_tablespace属于共享表,文件位于global目录下。可以看看有没有自定义表空间
pg_filedump -D 'oid,name,oid,~' -i global/1213|grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{$1=""; $2="";$3=""; $4="";print $0}'
0 1663 pg_default 10 \N
0 1664 pg_global 10 \N5.5 读取pg_database系统表(全局)
5.5.1读取pg_database文件的意义
为什么要读取pg_database表?
pg_database 中。这是一张系统层面的表,位于 global 目录中,在集群初始化时会分配固定的 OID 1262,所以对应的物理文件通常是: global/1262。因为初始情况下,oid和relfilenode是相同的,但是执行truncate、vacuum full等操作后,表数据被重写,并且表文件的relfilenode也会改变。此时oid和relfilenode可能不一致。这个时候用pg_filenode.map取映射关系。
vonng=# select 'pg_database'::RegClass::OID;
oid
------
1262这张系统视图里有不少字段,但我们主要关心的是前两个: oid 和 datname ,datname 是数据库的名称,oid 则可以用于定位数据库目录位置。由于随着版本的变化,默认的数据库的oid也总是变化,最好读取global下的pg_filenode.map找到pg_database
16.1版本
postgres@ubuntu-linux-22-04-desktop:~/data-16/base$ ls
1 13008 16385 4
postgres=# select oid,datname from pg_database;
oid | datname
-------+--------------
4 | template0
1 | template1
13008 | postgres
16385 | test_upgrade
(4 rows)15.1版本
postgres=# select oid,datname from pg_database;
oid | datname
-------+-----------
5 | postgres
1 | template1
4 | template0
16439 | db1
16513 | pwinfodb
16639 | vb
16655 | db6
16656 | db06
33055 | mj_db
16643 | db666
49451 | phecda-cm
(11 rows)14.1版本
postgres@ubuntu-linux-22-04-desktop:~/data/base$ ls
1 13007 13008 16385
postgres=# select oid,datname from pg_database;
oid | datname
-------+--------------
13008 | postgres
16385 | test_upgrade
1 | template1
13007 | template0
(4 rows)5.5.2 读取有哪些库
cd $PGDATA/global
pg_filedump -D 'oid,name,~' -i global/11262|grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{$1=""; $2="";$3=""; $4="";print $0}'结果如下,有三个库,三个默认的库和一个自己建的库。和base下的目录相对应。
postgres@ubuntu-linux-22-04-desktop:~/data-16/global$ pg_filedump -D 'oid,name,~' -i global/11262|grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{$1=""; $2="";$3=""; $4="";print $0}'
0 4 template0
1 1 template1
0 13008 postgres
0 16385 test_upgrade
postgres@ubuntu-linux-22-04-desktop:~/data-16/base$ ls
1 13008 16385 45.5.3 读取库的属性信息
pg_filedump -D 'oid,name,oid,int,char,bool,bool,int,xid,xid,oid,text,text,text,text,text,~' -i global/1262|grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";print $0}'结果如下
postgres@ubuntu-linux-22-04-desktop:~/data-16/global$ pg_filedump -D 'oid,name,oid,int,char,bool,bool,int,xid,xid,oid,text,text,text,text,text,~' -i global/1262|grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";print $0}'
0 4 template0 10 6 c t f -1 745 1 1663 C.UTF-8 C.UTF-8 \N \N \N
1 1 template1 10 6 c t t -1 726 1 1663 C.UTF-8 C.UTF-8 \N \N \N
0 13008 postgres 10 6 c f t -1 726 1 1663 C.UTF-8 C.UTF-8 \N \N \N \N
0 16385 test_upgrade 10 6 c f t -1 726 1 1663 C.UTF-8 C.UTF-8 \N \N \N \N可以获取库的oid,对应目录,以及对应的库的字符集、排序规则等。
过滤出自定义数据库
pg_filedump -D 'oid,name,oid,int,char,bool,bool,int,xid,xid,oid,text,text,text,text,text,~' -i global/1262|grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";print $0}'| egrep -v 'template|postgres'
//主要的几个字段为datname,encoding,dattablespace,datcollate,datctype,
//encoding从数字到具体编码的转换在 src/include/mb/pg_wchar.h下的 typedef enum pg_enc查看。5.6读取pg_authid获取用户(全局)
5.6.1 读取pg_authid文件分析
正常通过数据库的pg_authid视图里查询的结果应该是如下部分。
postgres@ubuntu-linux-22-04-desktop:~$ psql -c " select * from pg_authid ;" -A -t
6171|pg_database_owner|f|t|f|f|f|f|f|-1||
6181|pg_read_all_data|f|t|f|f|f|f|f|-1||
6182|pg_write_all_data|f|t|f|f|f|f|f|-1||
3373|pg_monitor|f|t|f|f|f|f|f|-1||
3374|pg_read_all_settings|f|t|f|f|f|f|f|-1||
3375|pg_read_all_stats|f|t|f|f|f|f|f|-1||
3377|pg_stat_scan_tables|f|t|f|f|f|f|f|-1||
4569|pg_read_server_files|f|t|f|f|f|f|f|-1||
4570|pg_write_server_files|f|t|f|f|f|f|f|-1||
4571|pg_execute_server_program|f|t|f|f|f|f|f|-1||
4200|pg_signal_backend|f|t|f|f|f|f|f|-1||
4544|pg_checkpoint|f|t|f|f|f|f|f|-1||
4550|pg_use_reserved_connections|f|t|f|f|f|f|f|-1||
6304|pg_create_subscription|f|t|f|f|f|f|f|-1||
10|postgres|t|t|t|t|t|t|t|-1||
16384|repl|f|t|f|f|t|t|f|-1|SCRAM-SHA-256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=|需要过滤出XMIN: 1的数据,因为这种XMIN: 1的数据是初始化的预置角色。
即如下部分
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,bool,bool,bool,bool,bool,bool,bool,int,text' -i global/1260 |grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'| grep 'XMIN: 1'| grep 'XMAX: 0'| grep COPY
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 6171 pg_database_owner f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 6181 pg_read_all_data f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 6182 pg_write_all_data f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 3373 pg_monitor f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 3374 pg_read_all_settings f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 3375 pg_read_all_stats f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 3377 pg_stat_scan_tables f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 4569 pg_read_server_files f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 4570 pg_write_server_files f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 4571 pg_execute_server_program f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 4200 pg_signal_backend f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 4544 pg_checkpoint f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 4550 pg_use_reserved_connections f t f f f f f -1 \N
XMIN: 1 XMAX: 0 CID|XVAC: 0 COPY: 6304 pg_create_subscription f t f f f f f -1 \N剩余部分如下
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,bool,bool,bool,bool,bool,bool,bool,int,text' -i global/1260 |grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'| grep -v 'XMIN: 1'
XMIN: 755 XMAX: 0 CID|XVAC: 0 COPY: 10 postgres t t t t t t t -1 \N
XMIN: 756 XMAX: 757 CID|XVAC: 0 COPY: 16384 repl f t f f f f f -1 \N
XMIN: 757 XMAX: 0 CID|XVAC: 0 COPY: 16384 repl f t f f t t f -1 SCRAM-SHA-256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=再过滤掉旧版本垃圾数据( grep 'XMAX: 0')和没有记录加密密码到pg_authid的postgres用户。
I9w8iHVB78Kk=
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,bool,bool,bool,bool,bool,bool,bool,int,text' -i global/1260 |grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'| grep -v 'XMIN: 1'|grep 'XMAX: 0'
XMIN: 755 XMAX: 0 CID|XVAC: 0 COPY: 10 postgres t t t t t t t -1 \N
XMIN: 757 XMAX: 0 CID|XVAC: 0 COPY: 16384 repl f t f f t t f -1 SCRAM-SHA-256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,bool,bool,bool,bool,bool,bool,bool,int,text' -i global/1260 |grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'| grep -v 'XMIN: 1'|grep 'XMAX: 0'| grep -v postgres|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print $0}'
16384 repl f t f f t t f -1 SCRAM-SHA-256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=可以看到从文件读取的rolpassword部分的值,和通过pg_authid查询的值一致。并且和pg_dump导出的时候的一致。
postgres@ubuntu-linux-22-04-desktop:~$ cat 2.sql
--
-- PostgreSQL database cluster dump
--
SET default_transaction_read_only = off;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
--
-- Roles
--
CREATE ROLE postgres;
ALTER ROLE postgres WITH SUPERUSER INHERIT CREATEROLE CREATEDB LOGIN REPLICATION BYPASSRLS;
CREATE ROLE repl;
ALTER ROLE repl WITH NOSUPERUSER INHERIT NOCREATEROLE NOCREATEDB LOGIN REPLICATION NOBYPASSRLS PASSWORD 'SCRAM-SHA256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=';因此,虽然我们不知道存储在数据库里加密前的密码是什么,但是可以通过拼接生成创建用户的SQL,使用SCRAM-SHA-256或MD5算法加密后的密码完成原来用户的创建。从而完成用户的恢复,因为PostgreSQL里用户创建密码后,是把密码按照SCRAM-SHA-256或MD5算法处理后的值写入数据库,等到用户登陆的时候,再把输入的密码进行相应的算法处理,把两个值进行比较,一致的话则密码输入正确允许用户进行数据库的登陆。(MD5算法属于单向散列算法,无法通过反推获得原始输入数据,但是MD5不算严格意义上的加密算法,可用暴力穷举法破解。SCRAM-SHA-256生成的密文长度为256位,MD5生成的密文长度为128位。SCRAM-SHA-256算法的碰撞概率比MD5更小,因为SCRAM-SHA-256使用了更复杂的哈希算法和更长的输出长度。而且SCRAM-SHA-256相对于MD5更加安全,因为SCRAM-SHA-256有随机salt的加入,同样的密码, 修改后存储内容也会变化,而MD5的salt是用户名字符串,密码一致根据算法生成的字符也是一致的。MD5加密方式为:MD5码 = md5(pwd+username))
SCRAM-SHA-256密码分析(待详细分析)
SCRAM-SHA-256
$
4096
:
fWK6w0/oDX42HJeYaPkIWA==
$
P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=
:
GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=
//存储格式:
SCRAM-SHA-256
$
<iteration count>
:
<salt>
$
<StoredKey>
:
<ServerKey>
postgres=# select rolname,rolpassword from pg_authid where rolname='repl';
rolname | rolpassword
---------+---------------------------------------------------------------------------------------------------------------------------------------
repl | SCRAM-SHA-256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=
(1 row)
postgres=# SELECT rolname, regexp_replace(rolpassword, '(SCRAM-SHA-256)\$(\d+):([a-zA-Z0-9+/=]+)\$([a-zA-Z0-9+=/]+):([a-zA-Z0-9+/=]+)', '\1$\2:<salt>$<storedkey>:<serverkey>') as rolpassword_masked
FROM pg_authid where rolname='repl';
rolname | rolpassword_masked
---------+---------------------------------------------------
repl | SCRAM-SHA-256$4096:<salt>$<storedkey>:<serverkey>
(1 row)5.6.2 拼接创建用户命令脚本
拼接创建用户语句的命令如下
//可以先用pg_filedump命令取出用户的数据
pg_filedump -D 'oid,name,bool,bool,bool,bool,bool,bool,bool,int,text' -i global/1260 |grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'| grep -v 'XMIN: 1'|grep 'XMAX: 0'| grep -v postgres|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print $0}'
16384 repl f t f f t t f -1 SCRAM-SHA-256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=//使用如下data2crquery.sh脚本,拼接创建用户命令
#!/bin/bash
if [[ $3 = 't' ]];
then
a1=SUPERUSER
else
a1=NOSUPERUSER
fi
if [[ $4 = 't' ]];
then
a2=INHERIT
else
a2=NOINHERIT
fi
if [[ $5 = 't' ]];
then
a3=CREATEROLE
else
a3=NOCREATEROLE
fi
if [[ $6 = 't' ]];
then
a4=CREATEDB
else
a4=NOCREATEDB
fi
if [[ $7 = 't' ]];
then
a5=LOGIN
else
a5=NOLOGIN
fi
if [[ $8 = 't' ]];
then
a6=REPLICATION
else
a6=NOREPLICATION
fi
if [[ $9 = 't' ]];
then
a7=BYPASSRLS
else
a7=NOBYPASSRLS
fi
echo "CREATE ROLE" ${2}";"
echo ALTER ROLE ${2} WITH ${a1} ${a2} ${a3} ${a4} ${a5} ${a6} ${a7} PASSWORD "'"${11}"';"使用方式如下,bash执行脚本,后边跟上上边pg_filedump命令取出结果。每次只能对一个用户一行记录进行拼接。(后续可以进行优化,变成批量读取并处理生成恢复用户的SQL)
postgres@ubuntu-linux-22-04-desktop:~$ bash data2crquery.sh 16384 repl f t f f t t f -1 SCRAM-SHA-256$4096:fWK6w0/oDX42HJeYaPkIWA==$P7K5YHTAjRW4JHm/6aY4vP
A549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=
CREATE ROLE repl;
ALTER ROLE repl WITH NOSUPERUSER INHERIT NOCREATEROLE NOCREATEDB LOGIN REPLICATION NOBYPASSRLS PASSWORD 'SCRAM-SHA-256096:fWK6w0/oDX42HJeYaPkIWA==/6aY4vPA549WepjUCdQzudRm/QtE=:GG/TgXZAiSuJqLBa1e7E7q2CFJJU106I9w8iHVB78Kk=';5.7 获取每个库下schema以及对象(非共享)
5.7.1 读取有几个schema以及schema的oid(pg_class比较麻烦,建议获取pg_namespace后,直接读取pg_namespace)
pg_class是非共享的,每个库单独维护一个
postgres@ubuntu-linux-22-04-desktop:~/data-16$ ll base/*/1259
-rw------- 1 postgres postgres 131072 Jan 19 18:01 base/1/1259
-rw------- 1 postgres postgres 131072 Jan 19 18:01 base/16385/1259
-rw------- 1 postgres postgres 131072 Jan 19 18:01 base/4/1259
//语句如下
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/16385/1259
//结果如下
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/16385/1259|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print $0}'
2619 pg_statistic 11 10029 0 10 2 2619 0 35 409.000000000000 35 2840 t f p r 31 0 f f f f f t n f 0 1682 1
1247 pg_type 11 71 0 10 2 0 0 15 613.000000000000 15 4171 t f p r 32 0 f f f f f t n f 0 745 1
2836 pg_toast_1255 99 0 0 10 2 0 0 1 3.000000000000 1 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
4171 pg_toast_1247 99 0 0 10 2 0 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
2830 pg_toast_2604 99 0 0 10 2 2830 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
2832 pg_toast_2606 99 0 0 10 2 2832 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
4157 pg_toast_2612 99 0 0 10 2 4157 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
4159 pg_toast_2600 99 0 0 10 2 4159 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
2840 pg_toast_2619 99 0 0 10 2 2840 0 3 14.000000000000 3 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
3439 pg_toast_3381 99 0 0 10 2 3439 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
3430 pg_toast_3429 99 0 0 10 2 3430 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
2838 pg_toast_2618 99 0 0 10 2 2838 0 65 287.000000000000 65 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
2336 pg_toast_2620 99 0 0 10 2 2336 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
4145 pg_toast_3466 99 0 0 10 2 4145 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
2834 pg_toast_2609 99 0 0 10 2 2834 0 0 0.000000000000 0 0 t f p t 3 0 f f f f f t n f 0 745 1 \N
3118 pg_foreign_table 11 10082 0 10 2 3118 0 0 0.000000000000 0 4153 t f p r 3 0 f f f f f t n f 0 745 1
//打印pg_class下的对象名,schema,和类型
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/16385/1259|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print $9" " $10" "$11}'
pg_statistic 11 10029
pg_type 11 71
pg_toast_1255 99 0
pg_toast_1247 99 0
pg_toast_2604 99 0
pg_toast_2606 99 0
pg_toast_2612 99 0
pg_toast_2600 99 0
pg_toast_2619 99 0
pg_toast_3381 99 0
pg_toast_3429 99 0
pg_toast_2618 99 0
pg_toast_2620 99 0
pg_toast_3466 99 0
pg_toast_2609 99 0
pg_foreign_table 11 10082
pg_shadow 11 12007
pg_toast_3456 99 0
pg_authid 11 2842//查看当前的数据库下有多少个schema,
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/16385/1259|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print $10}' |sort|uniq -c | awk '{print $2}'
11 ----11对应pg_catalog的schema存储系统表
1 ----12400对应information_schema的schema存储数据库相关元数据
2200 ----2200对应public的schema
99 ----99对应pg_toast的schema 5.7.2 读取schema的名字以及owner(pg_namespace)
读取pg_namespace的文件位置,pg_namespace文件在pg_filenode.map中找不到。需要读取pg_class获取文件存储的位置。
//语句如下
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/16385/1259|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'| grep pg_namespace|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print $0}'
//结果如下
2615 pg_namespace 11 10047 0 10 2 2615 0 1 4.000000000000 0 4163 t f p r 4 0 f f f f f t n f 0 745 1
------------------
//拼接一下关键的信息,打印表的文件名,文件和读取的pg_class处于统一路径下
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/16385/1259|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'| grep pg_namespace|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "table ["$9 "] filepath is "$15}'
//结果如下
table [pg_namespace] filepath is 2615 读取pg_namespace,获取schema的名字以及owner
pg_filedump -D 'oid,name,oid,~' -i base/16385/2615 |grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0' |awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print $0}'
//结果如下(第一列是schema的oid,第二列是schema名,第三列是owner的oid,10是postgres的oid)
11 pg_catalog 10
12440 information_schema 10
2200 public 105.7.3 读取schema下有几个对象
5.7.3.1 方式一:获取pg_class的结构后,把pg_class数据恢复到一张临时表里(SQL处理较方便)
此处暂不做举例。
5.7.3.2 方式二:直接脚本筛选解析文件的数据(处理较麻烦)
获取schema和对象
//获取数据库里所有的schema和对象
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/16385/1259|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " relname: "$9" reloid: "$8" relfilenode: "$15" relowner: "$13" relkind: "$24}'| egrep 'schema|relname|reloid|relfilenode|relowner|relkind'
//结果如下
schema: 11 relname: pg_sequence reloid: 2224 relfilenode: 2224 relowner: 10 relkind: r
schema: 11 relname: pg_publication reloid: 6104 relfilenode: 6104 relowner: 10 relkind: r
schema: 11 relname: pg_publication_namespace reloid: 6237 relfilenode: 6237 relowner: 10 relkind: r
schema: 11 relname: pg_publication_rel reloid: 6106 relfilenode: 6106 relowner: 10 relkind: r
schema: 11 relname: pg_subscription_rel reloid: 6102 relfilenode: 6102 relowner: 10 relkind: r
schema: 99 relname: pg_toast_12629 reloid: 12632 relfilenode: 12632 relowner: 10 relkind: t
schema: 12440 relname: sql_implementation_info reloid: 12629 relfilenode: 12629 relowner: 10 relkind: r
schema: 99 relname: pg_toast_12634 reloid: 12637 relfilenode: 12637 relowner: 10 relkind: t
schema: 12440 relname: sql_parts reloid: 12634 relfilenode: 12634 relowner: 10 relkind: r
schema: 99 relname: pg_toast_12624 reloid: 12627 relfilenode: 12627 relowner: 10 relkind: t
schema: 99 relname: pg_toast_12639 reloid: 12642 relfilenode: 12642 relowner: 10 relkind: t
schema: 12440 relname: sql_sizing reloid: 12639 relfilenode: 12639 relowner: 10 relkind: r
schema: 11 relname: pg_largeobject_loid_pn_index reloid: 2683 relfilenode: 2683 relowner: 10 relkind: i
schema: 11 relname: pg_largeobject reloid: 2613 relfilenode: 2613 relowner: 10 relkind: r
--------------
//排除系统的schema后,schema和对象(包含public的schema)
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/13008/41317|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " relname: "$9" reloid: "$8" relfilenode: "$15" relowner: "$13 " relkind: "$24}'| grep -v "schema: 99"|grep -v "schema: 11"|grep -v "schema: 12440"| egrep 'schema|relname|reloid|relfilenode|relowner|relkind'
schema: 2200 relname: tab_test_1 reloid: 24925 relfilenode: 24925 relowner: 10 relkind: r
schema: 2200 relname: tab_testdump reloid: 33120 relfilenode: 33120 relowner: 10 relkind: r
schema: 2200 relname: tab_test_2 reloid: 24929 relfilenode: 24929 relowner: 10 relkind: r
schema: 2200 relname: idx_1 reloid: 24935 relfilenode: 24935 relowner: 10 relkind: i
schema: 16400 relname: hints_pkey reloid: 16446 relfilenode: 16446 relowner: 10 relkind: i
schema: 16400 relname: hints_id_seq reloid: 16439 relfilenode: 16439 relowner: 10 relkind: S
schema: 16400 relname: hints_norm_and_app reloid: 16448 relfilenode: 16448 relowner: 10 relkind: i
schema: 16400 relname: hints reloid: 16440 relfilenode: 16440 relowner: 10 relkind: r
schema: 2200 relname: pg_stat_statements reloid: 16409 relfilenode: 0 relowner: 10 relkind: v
schema: 2200 relname: pg_stat_statements_info reloid: 16404 relfilenode: 0 relowner: 10 relkind: v
//排除系统的schema后,schema和对象(不包含public的schema)
pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/13008/41317|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " relname: "$9" reloid: "$8" relfilenode: "$15" relowner: "$13 " relkind: "$24}'| grep -v "schema: 99"|grep -v "schema: 11"|grep -v "schema: 12440"|grep -v "schema: 2200"| egrep 'schema|relname|reloid|relfilenode|relowner|relkind'
schema: 16400 relname: hints_pkey reloid: 16446 relfilenode: 16446 relowner: 10 relkind: i
schema: 16400 relname: hints_id_seq reloid: 16439 relfilenode: 16439 relowner: 10 relkind: S
schema: 16400 relname: hints_norm_and_app reloid: 16448 relfilenode: 16448 relowner: 10 relkind: i
schema: 16400 relname: hints reloid: 16440 relfilenode: 16440 relowner: 10 relkind: r//可以再加grep"schema: 2200"分别查看各个schema的对象然后统计数量
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/13008/41317|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " reloid: "$11 " relkind:"$24}'| grep -v "schema: 99"|grep -v "schema: 11"|grep -v "schema: 12440"| grep "schema: 2200"
schema: 2200 reloid: 24927 relkind:r
schema: 2200 reloid: 33122 relkind:r
schema: 2200 reloid: 24931 relkind:r
schema: 2200 reloid: 0 relkind:i
schema: 2200 reloid: 16411 relkind:v
schema: 2200 reloid: 16406 relkind:v
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/13008/41317|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " relname: "$9" reloid: "$8" relfilenode: "$15" relowner: "$13 " relkind: "$24}'| grep -v "schema: 99"|grep -v "schema: 11"|grep -v "schema: 12440"| egrep 'schema|relname|reloid|relfilenode|relowner|relkind'|grep "schema: 2200"|grep "relkind: v"
schema: 2200 relname: pg_stat_statements reloid: 16409 relfilenode: 0 relowner: 10 relkind: v
schema: 2200 relname: pg_stat_statements_info reloid: 16404 relfilenode: 0 relowner: 10 relkind: v
--------------
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/13008/41317|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " relname: "$9" reloid: "$8" relfilenode: "$15" relowner: "$13 " relkind: "$24}'| grep -v "schema: 99"|grep -v "schema: 11"|grep -v "schema: 12440"| egrep 'schema|relname|reloid|relfilenode|relowner|relkind'|grep "schema: 2200"|grep "relkind: v"|wc -l
2
--------------
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/13008/41317|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " relname: "$9" reloid: "$8" relfilenode: "$15" relowner: "$13 " relkind: "$24}'| grep -v "schema: 99"|grep -v "schema: 11"|grep -v "schema: 12440"| egrep 'schema|relname|reloid|relfilenode|relowner|relkind'|grep "schema: 2200"|grep "relkind: r"
schema: 2200 relname: tab_test_1 reloid: 24925 relfilenode: 24925 relowner: 10 relkind: r
schema: 2200 relname: tab_testdump reloid: 33120 relfilenode: 33120 relowner: 10 relkind: r
schema: 2200 relname: tab_test_2 reloid: 24929 relfilenode: 24929 relowner: 10 relkind: r
--------------
postgres@ubuntu-linux-22-04-desktop:~/data-16$ pg_filedump -D 'oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,~' -i base/13008/41317|grep -v 'infomask'| egrep 'COPY|XMAX|Partial data'|awk 'ORS=NR%2?" ":"\n"{print}'|grep -v 'XMIN: 1'|grep 'XMAX: 0'|awk '{$1=""; $2="";$3=""; $4="";$5="";$6="";$7="";print "schema: " $10 " relname: "$9" reloid: "$8" relfilenode: "$15" relowner: "$13 " relkind: "$24}'| grep -v "schema: 99"|grep -v "schema: 11"|grep -v "schema: 12440"| egrep 'schema|relname|reloid|relfilenode|relowner|relkind'|grep "schema: 2200"|grep "relkind: r"|wc -l
35.9 读取pg_attribute查看表都包含哪些列(非共享)
5.10 读取pg_type,把列和列的类型做映射,生成建表语句(非共享)
更简单做法可以导出pg_attribute数据后,取atttypid列,使用::regtype转换。
例如导出一个col1 列,atttypid为20,然后在同样版本的数据库里,执行如下查询。
postgres=# select 20::regtype col1_type ;
col1_type
-----------
bigint
(1 row)
可以使用条件查询,对应attrelid为表名。
postgres=# select attname,attnum,atttypid::regtype from pg_attribute where attrelid='pg_database'::regclass and attnum >0;
attname | attnum | atttypid
----------------+--------+-----------
oid | 1 | oid
datname | 2 | name
datdba | 3 | oid
encoding | 4 | integer
datlocprovider | 5 | "char"
datistemplate | 6 | boolean
datallowconn | 7 | boolean
datconnlimit | 8 | integer
datfrozenxid | 9 | xid
datminmxid | 10 | xid
dattablespace | 11 | oid
datcollate | 12 | text
datctype | 13 | text
daticulocale | 14 | text
daticurules | 15 | text
datcollversion | 16 | text
datacl | 17 | aclitem[]
(17 rows)
//临时拼接语句如下
postgres@ubuntu-linux-22-04-desktop:~$ psql -c "select attname,atttypid::regtype from pg_attribute where attrelid='pg_database'::regclass and attnum >0 order by attnum;" -t -A | awk -F'|' '{print $1 " "$2","}'
oid oid,
datname name,
datdba oid,
encoding integer,
datlocprovider "char",
datistemplate boolean,
datallowconn boolean,
datconnlimit integer,
datfrozenxid xid,
datminmxid xid,
dattablespace oid,
datcollate text,
datctype text,
daticulocale text,
daticurules text,
datcollversion text,
datacl aclitem[],附:常规类型转换举例(用作pg_filedump解析列时候的映射)
integer --> int
boolean --> bool
name --> name
oid --> oid
char -->char
xid -->xid
text --> text
aclitem[] --> text##############语句整理###########
1.导出数据
其中 -D后要跟上表数据的类型 ,最后的awk输出的列和表的列要对上,其中前5行为我合并的带有xmin,xmax的行,最终不需要打印出来(我是为了根据xmax来筛除掉死元组)。具体根据什么进行分割需要根据数据情况进行,灵活变化。
以空格分割(时间戳可能有问题)
pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{print $6,$7,$8,$9}'
1 9514a4d8 2024-01-10 13:36:25.998179
2 0b05a4c8 2024-01-10 13:36:25.998652
3 5e3cac92 2024-01-10 13:36:25.998659
4 26b50a38 2024-01-10 13:36:25.998662
5 f7dd5e12 2024-01-10 13:36:25.998666
6 34916ff9 2024-01-10 13:36:25.998669
7 15ae6253 2024-01-10 13:36:25.998672
8 db21b153 2024-01-10 13:36:25.998675
9 dd34afae 2024-01-10 13:36:25.998678
10 ysladeadtup 2024-01-10 13:36:25.998681以逗号分隔
pg_filedump -i -D int,text,timestamp base/13008/33120 |grep -v 'infomask'| egrep 'COPY|XMAX' |awk '{$1=null;print $0}'|awk 'ORS=NR%2?" ":"\n"{print}'| grep ' XMAX: 0'| awk '{print $6","$7","$8,$9}'>/home/postgres/dumptest_data.csv
1,9514a4d8,2024-01-10 13:36:25.998179
2,0b05a4c8,2024-01-10 13:36:25.998652
3,5e3cac92,2024-01-10 13:36:25.998659
4,26b50a38,2024-01-10 13:36:25.998662
5,f7dd5e12,2024-01-10 13:36:25.998666
6,34916ff9,2024-01-10 13:36:25.998669
7,15ae6253,2024-01-10 13:36:25.998672
8,db21b153,2024-01-10 13:36:25.998675
9,dd34afae,2024-01-10 13:36:25.998678
10,ysladeadtup,2024-01-10 13:36:25.9986812.使用copy命令把数据导入到有表结构的表里
postgres=#
postgres=# select * from tab_1;
id | info | crt_time
----+------+----------
(0 rows)
postgres=# copy tab_1 from '/home/postgres/dumptest_data.csv' with (FORMAT csv,DELIMITER ',' ,escape '\',header false,encoding ' UTF8');
COPY 10
postgres=# select * from tab_1;
id | info | crt_time
----+-------------+----------------------------
1 | 9514a4d8 | 2024-01-10 13:36:25.998179
2 | 0b05a4c8 | 2024-01-10 13:36:25.998652
3 | 5e3cac92 | 2024-01-10 13:36:25.998659
4 | 26b50a38 | 2024-01-10 13:36:25.998662
5 | f7dd5e12 | 2024-01-10 13:36:25.998666
6 | 34916ff9 | 2024-01-10 13:36:25.998669
7 | 15ae6253 | 2024-01-10 13:36:25.998672
8 | db21b153 | 2024-01-10 13:36:25.998675
9 | dd34afae | 2024-01-10 13:36:25.998678
10 | ysladeadtup | 2024-01-10 13:36:25.998681
(10 rows)3.解析pg_filenode.map文件
3.1 global表空间下共享系统表
pg_filedump -m pg_filenode.map | grep OID | grep 4178| awk '{print "Relname:pg_toast_1262_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2967| awk '{print "Relname:pg_toast_2964_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4186| awk '{print "Relname:pg_toast_1213_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4176| awk '{print "Relname:pg_toast_1260_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2847| awk '{print "Relname:pg_toast_2396_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4182| awk '{print "Relname:pg_toast_6000_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4061| awk '{print "Relname:pg_toast_3592_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6245| awk '{print "Relname:pg_toast_6243_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4184| awk '{print "Relname:pg_toast_6100_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2671| awk '{print "Relname:pg_database_datname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2672| awk '{print "Relname:pg_database_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2965| awk '{print "Relname:pg_db_role_setting_databaseid_rol_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2697| awk '{print "Relname:pg_tablespace_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2698| awk '{print "Relname:pg_tablespace_spcname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2676| awk '{print "Relname:pg_authid_rolname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2677| awk '{print "Relname:pg_authid_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6303| awk '{print "Relname:pg_auth_members_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2694| awk '{print "Relname:pg_auth_members_role_member_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2695| awk '{print "Relname:pg_auth_members_member_role_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6302| awk '{print "Relname:pg_auth_members_grantor_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1232| awk '{print "Relname:pg_shdepend_depender_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1233| awk '{print "Relname:pg_shdepend_reference_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2397| awk '{print "Relname:pg_shdescription_o_c_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6001| awk '{print "Relname:pg_replication_origin_roiident_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6002| awk '{print "Relname:pg_replication_origin_roname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 3593| awk '{print "Relname:pg_shseclabel_object_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6246| awk '{print "Relname:pg_parameter_acl_parname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6247| awk '{print "Relname:pg_parameter_acl_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6114| awk '{print "Relname:pg_subscription_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6115| awk '{print "Relname:pg_subscription_subname_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1260| awk '{print "Relname:pg_authid " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6244| awk '{print "Relname:pg_toast_6243 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4183| awk '{print "Relname:pg_toast_6100 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4177| awk '{print "Relname:pg_toast_1262 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2966| awk '{print "Relname:pg_toast_2964 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4185| awk '{print "Relname:pg_toast_1213 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4175| awk '{print "Relname:pg_toast_1260 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2846| awk '{print "Relname:pg_toast_2396 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4181| awk '{print "Relname:pg_toast_6000 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4060| awk '{print "Relname:pg_toast_3592 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1262| awk '{print "Relname:pg_database " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2964| awk '{print "Relname:pg_db_role_setting " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1213| awk '{print "Relname:pg_tablespace " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1261| awk '{print "Relname:pg_auth_members " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1214| awk '{print "Relname:pg_shdepend " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2396| awk '{print "Relname:pg_shdescription " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6000| awk '{print "Relname:pg_replication_origin " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 3592| awk '{print "Relname:pg_shseclabel " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6243| awk '{print "Relname:pg_parameter_acl " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 6100| awk '{print "Relname:pg_subscription " $1" "$2" "$3" "$4}'3.2 数据库私有的系统表
pg_filedump -m pg_filenode.map | grep OID | grep 1247 | awk '{print "Relname:pg_type " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2836 | awk '{print "Relname:pg_toast_1255 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4171 | awk '{print "Relname:pg_toast_1247 " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2837 | awk '{print "Relname:pg_toast_1255_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 4172 | awk '{print "Relname:pg_toast_1247_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2690 | awk '{print "Relname:pg_proc_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2691 | awk '{print "Relname:pg_proc_proname_args_nsp_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2703 | awk '{print "Relname:pg_type_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2704 | awk '{print "Relname:pg_type_typname_nsp_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2658 | awk '{print "Relname:pg_attribute_relid_attnam_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2659 | awk '{print "Relname:pg_attribute_relid_attnum_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2662 | awk '{print "Relname:pg_class_oid_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 2663 | awk '{print "Relname:pg_class_relname_nsp_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 3455 | awk '{print "Relname:pg_class_tblspc_relfilenode_index " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1249 | awk '{print "Relname:pg_attribute " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1255 | awk '{print "Relname:pg_proc " $1" "$2" "$3" "$4}'
pg_filedump -m pg_filenode.map | grep OID | grep 1259 | awk '{print "Relname:pg_class " $1" "$2" "$3" "$4}'参考文章
https://github.com/digoal/blog/blob/master/202107/20210715_03.md
https://github.com/digoal/blog/blob/master/201703/20170310_03.md
https://blog.csdn.net/jycjyc/article/details/125145027
https://www.modb.pro/db/1739828416076144640?utm_source=index_ori