今天我们从一个真实案例角度来探讨这个问题。
1. 案例背景和问题
最近我在进行云原生系统中RRD数据向VictoriaMetrics迁移的任务设计。
RRD和VictoriaMetrics都是时序数据库,非常适合用来搭建监控系统,存储以时间驱动的监控采集数据。但是RRD仅仅基于磁盘文件IO,性能极其堪忧,而VictoriaMetrics则高效利用了内存,可以有效解决RRD的性能问题。这次的迁移重构任务就是基于这点出发的。
我们采用的是VM的集群版本,存在vmauth、vmagent、vminsert、vmselect和vmstorage等服务。
vminsert专精于数据插入,底层会维护一个缓冲区,当缓冲区数据填满,或者离上次插入数据有一定时间间隔,则会向专精于数据持久化的vmstorage服务推送这一批数据。至于vmauth、vmagent和vmselect则是用于鉴权、数据采集和查询数据的组件,这里就不细讲了。
这种异步写入的设计,主要目的是通过一次性批量插入代替反复插入,从而避免在数据量较大时,产生大量建立和销毁HTTP连接的开销。
很多常见的互联网业务也是这样做的,特别是高并发业务场景下,手搭一个数据插入缓冲池,再异步把数据批量插入MySQL这种DB是可以明显提高性能的,这种做法简直太过于常见了,只不过VM通过自己提供的组件代替开发者完成了这一点。
但真正实操过这种异步插入方案,或是背过相关八股文的朋友,肯定清楚,这种方案会存在数据完整性的问题。
把数据流分析一下,其实整体数据走向无非就是上游业务->缓冲插入服务->DB,在上游业务把数据推入缓冲插入服务时,缓冲插入服务只能返回一个HTTP 2xx,表示我收到了数据。比如,vminsert就会向调用它的上游服务返回204 No Content。
但收到数据并非意味着我已经将数据落入磁盘持久化了,这得看缓冲插入服务和DB之间是否有插入成功的校验机制。一般来说,由于缓冲插入服务是同步写入DB的,只要DB返回插入成功的信息,那么数据肯定就已经落盘了;反之,插入服务也可以基于自己的容灾策略,决定如何重试插入,除非数据格式不正确,否则只有在断网、弱网、断电、下游服务进程崩溃结束等最极端的情况下才会放弃插入丢弃数据,然而这种丢弃数据的极端情况才是我们业务中最需要处理的部分。
在电商、外卖这种系统设计中,每一条数据都极其重要,因此我们必须设计一套校验机制保证即便插入服务出现数据丢弃的情况,也能记录这一条数据,便于后续重传。
绝大部分系统针对这种情况的兜底方案是采用持久化MQ:上游服务先将数据推入MQ当中,MQ自己持久化一遍,然后把数据推给插入服务,服务把数据推入DB并得到插入成功的消息后,向MQ返回ACK,MQ收到ACK就可以删除持久化数据了,否则就可以基于MQ持久化的数据继续重复推送,直至插入成功。
画成时序图的话,大概就是这个流程:
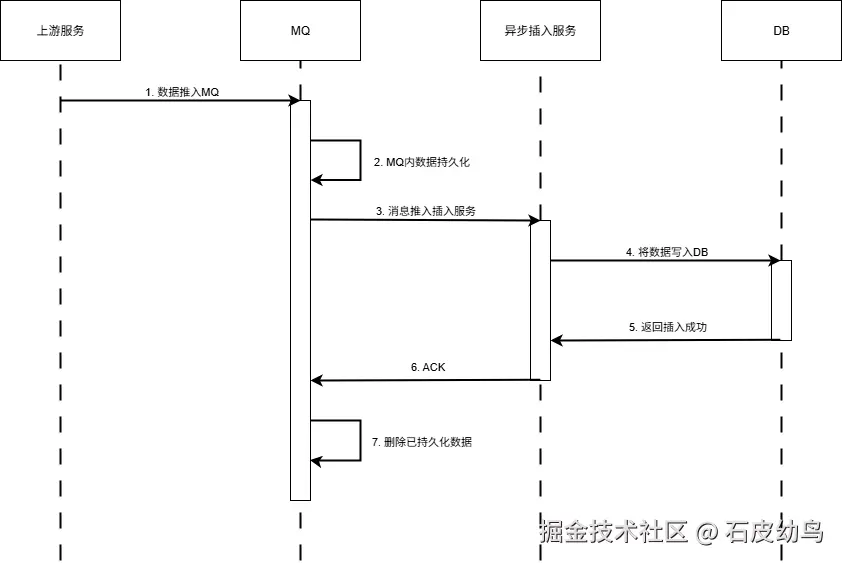
然而,这需要插入服务支持向MQ发送数据,但vminsert作为三方服务,原生能力肯定是不足以完成这项任务的。能不能设计方案去解决这个问题呢?
2. 方案设计
2.1. 方案一(兜底方案):修改vminsert源码,让其支持MQ推送
这是一种走投无路的兜底方案,需要我熟读vminsert的源码,深知这个服务的所有业务流程,然后针对我的业务需求进行客制化。这个方案在人力资源和时间上的消耗都是极大的,我认为绝大部分人都不会选择这个方案。
2.2. 方案二:查询DB中该批次数据的数量,作为ACK与缓存中该批次数量进行比对
我们在做数据迁移时,本身也会按批次多协程并发插入数据,不妨为这批次数据生成一个UUIDv7的冗余标签(字段),在保证并发安全且有顺序性的情况下作为这批数据的唯一标识。
当数据推入vminsert后,我们可以开启一个轮询时间窗口(如10s),窗口期间内反复查询标签等于该UUID值的数据的数据量作为ACK,只要数据量等于内存中该批次数据量,则代表该批次数据迁移成功,可以进行下一批次的迁移,否则重传这一批数据。
该方案的时序图如下图所示:
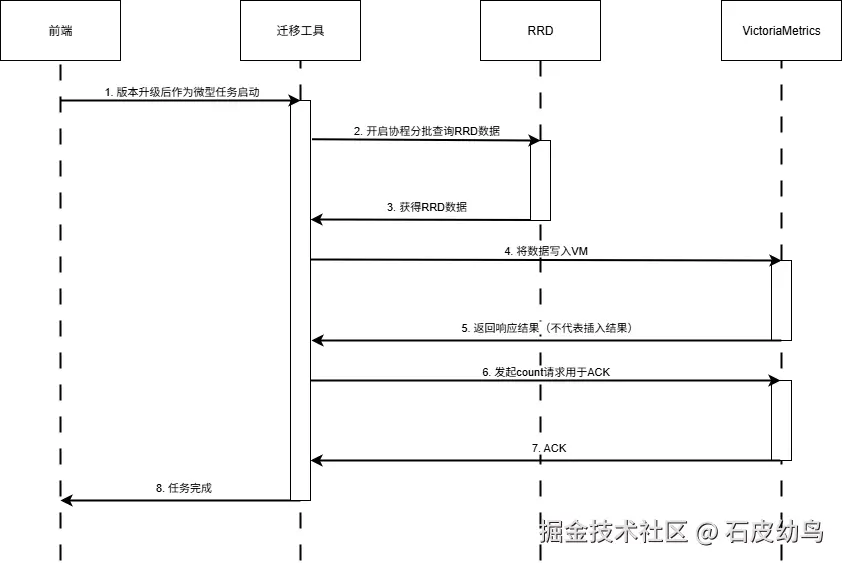
然而这个方案只能保证插入数据的数量是正确的,不能保证插入数据与原有数据是否一致,会不会存在数据损坏的问题,不过可以定为一个优先级较高的候选方案。
2.3. 方案三:直接校验DB中数据与缓存中数据是否一致
这是一种基于方案二的方案。
我们可以先保证数量是正确的,然后查出这一批数据与内存中的数据进行比对,保证数据的完整性。内存中的数据可以用一些唯一标识(比如资源ID、指标项、时间戳)作为key,对应的数据作为value,在字典(Dictionary、Map这种键值对数据结构)中进行存储,通过这种索引方案降低比对时的时间消耗,做到近乎为O(n)的时间复杂度。
这种方案的缺点主要在于查询大量数据会带来极大的IO瓶颈和内存占用(网络IO、文件IO、vmselect的缓存占用以及上游服务内存区域的空间占用),不论是时间还是空间上都是极差的一种方案。
3. 从业务和工具自身设计角度看问题
在遇到困难时,不妨换一个角度去看看问题,没准能得到其他的结果。
不如向自己发问:在监控场景中,单条数据的完整性相比于数据的趋势性真的很重要吗?
首先要明确一点,即使fsync也可能撒谎,WAL也可能失败,在系统设计中本身就没有绝对的持久化保证,否则就不会出现拜占庭故障,以及对应的BFT容错算法,以及k8s采用的CFT轻量级容错算法。
针对这一点,VM采用的方案很有趣。
VM本身会按照用户查询的起止时间和步长查找数据库中对应的时间点,比如,如果用户查询1:40开始到2:40结束,每5分钟一条的数据,那么VM就会查询1:40、1:45、1:50...的数据,直到2:40为止。
但假如数据库中并没有准确落在这几个时间点上的数据,那么此时VM就会取离该点最近的数据点,如下图所示。
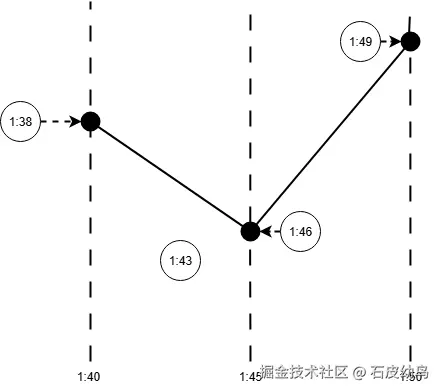
换句话说,VM认为监控场景下,用户最需要关注的应该是数据的趋势,数据波动如何,峰值是什么,而不是单条数据的完整性。
那么回到这个数据迁移的场景下,数据完整性真的还很重要么?很明显,答案是并不重要。
因此我们大可以选择相信基础设施的工作能力,在异步写入这一块交由vminsert处理------倘若真的要做一次校验,采用方案二这种粗略校验的手段就已经很不错了。
4. 假如把目标从必须完整换成尽可能完整,是否还有更好的解决方案?
简明扼要地说:有,但仅限于集群模式。
实际上对于这个需求,在单机下方案二已经是最快最稳妥的方法了,因为出问题的概率可能真的不到1%。不过如果我们采用集群模式,情况就会变得截然不同。
我们可以采用多数派容错算法,假设要允许n个节点挂掉,我们可以将相同一条数据按照哈希算法平均分配后,同时写入n+1个节点。
譬如说,假设我们有三个vmstorage节点,我们让同一条数据经过vminsert的哈希算法选出两个vmstorage节点同时写入,在确保所有数据平均写入三个节点且写了两次的情况下,是能够保证即便有1台设备丢数据或宕机的情况下,所有数据也能够完整保存的。
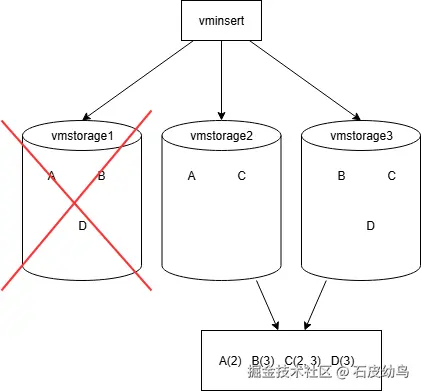
当然,这种方案的缺点是需要占用数倍的存储空间,且需要很多个分布式节点予以支持。
在能够接受这种存储占用的情况下,我认为方案二的简易ACK机制+数据多写是一个完美的解决方案。