我自己的原文哦~https://blog.51cto.com/whaosoft/12207173
#HE-Drive
地平线&港大最新端到端进展!VLM+扩散模型发大力
本文提出了HE-Drive:首个模仿人类驾驶为核心的端到端自动驾驶系统,旨在生成同时具备时间一致性和舒适性的轨迹。近期研究表明,基于模仿学习的规划器和基于学习的轨迹评分器能够有效生成并选择高度模仿专家演示的准确轨迹。然而这类轨迹规划和评分器面临生成时间不一致且不舒适的轨迹的困境。为了解决上述问题,HE-Drive首先通过稀疏感知提取关键的三维空间表示,这些表示随后作为条件输入,传递给基于条件去噪扩散概率模型(DDPM)的运动规划器,生成具备时间一致性的多模态轨迹。随后,基于视觉语言模型(VLM)引导的轨迹评分器从这些候选轨迹中选择最舒适的轨迹来控制车辆,确保类人的端到端驾驶体验。实验结果表明,HE-Drive在nuScenes和OpenScene数据集上实现了SOTA性能(即比VAD减少了71%的平均碰撞率)和效率(即比SparseDrive快1.9倍),同时在真实世界数据中提供了最舒适的驾驶体验。
代码链接:https://github.com/jmwang0117/HE-Drive
总结来说,本文的主要贡献如下:
- 基于扩散的运动规划:本文提出了一种基于扩散的运动规划器,通过以稀疏感知网络提取的3D表示为条件,并结合历史预测轨迹的速度、加速度和偏航角,生成时间一致性和多模态的轨迹。
- 即插即用的轨迹评分:本文引入了一种新颖的基于视觉语言模型(VLMs)引导的轨迹评分器及舒适度指标,弥补了类人驾驶的不足,使其能够轻松集成到现有的自动驾驶系统中。
- 优秀的开环和闭环测试结果:HE-Drive在nuScenes和OpenScene数据集上实现了最先进的性能(即相比VAD减少了71%的平均碰撞率)和效率(即比SparseDrive快1.9倍),同时在真实世界数据集上将舒适度提升了32%,展示了其在各种场景中的有效性。
文章简介
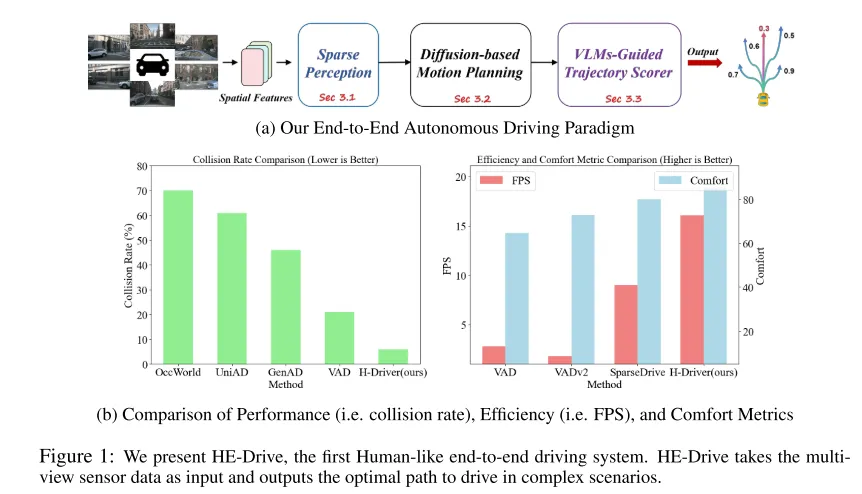
图1:本文展示了HE-Drive,这是首个类人端到端驾驶系统。HE-Drive将多视角传感器数据作为输入,并在复杂场景中输出最优行驶路径。
端到端范式将感知、规划和轨迹评分任务集成到一个统一模型中,以规划目标进行优化,最近在推动自动驾驶技术发展方面展示了显著的潜力(图1a)。最新研究提出了基于模仿学习的运动规划器,它们通过大规模驾驶演示学习驾驶策略,并使用基于学习的轨迹评分器从多个预测候选轨迹中选择最安全、最准确的轨迹来控制车辆。然而,尽管现有的规划器和评分器在预测准确性方面取得了显著进展,它们仍面临生成时间不一致轨迹的挑战,即连续的预测在时间上不稳定且不一致,以及选择不舒适轨迹的问题,这些轨迹表现为连续制动,导致车辆停顿或过大的转弯曲率。
本文提出了HE-Drive,这是首个以类人驾驶为核心的端到端自动驾驶系统,旨在解决上述两个问题,如图2所示。具体而言,本文发现由基于模仿学习的规划器生成的轨迹在时间一致性方面存在的问题主要源于两个因素:时间相关性和泛化能力。首先,这些规划器依赖当前帧过去几秒的信息来预测未来轨迹,忽略了连续预测之间的相关性。其次,它们的性能受到离线收集的专家轨迹质量的限制,导致在系统动态变化和分布外状态下,所学的策略缺乏应对未见场景的泛化能力。受扩散策略在机器人操作中取得成功的启发,该策略采用视觉条件的扩散模型来精确表示多模态分布以生成动作序列,本文提出了一种基于扩散的规划器,能够生成具有强时间一致性的多模态轨迹。
此外,导致预测轨迹不舒适的关键原因在于次优轨迹评分器无法实现持续评估,并且缺乏衡量轨迹舒适度的通用指标。近期研究表明,基于学习的评分器在闭环场景中不如基于规则的评分器,而后者由于依赖手工设计的后处理方式,泛化能力有限。其他研究者探索了使用视觉语言模型(VLMs)来感知周围代理的运动和交通表示,从而决定下一步行动。然而,直接将VLMs作为驾驶决策者面临解释性差和严重幻觉问题。为了解决这些问题,本文提出了一种新颖的轨迹评分器和通用的舒适度指标,结合了基于规则评分器的可解释性与VLMs的适应性,能够根据驾驶风格(例如,激进或保守)进行调整,从而实现持续评估。
综上所述,HE-Drive是一种新颖的以类人驾驶为核心的端到端自动驾驶系统。该系统利用稀疏感知技术,通过稀疏特征来检测、跟踪并映射驾驶场景,生成三维空间表示。这些表示作为条件输入到基于扩散的运动规划器中,该规划器由条件去噪扩散概率模型(DDPM)驱动。最后,基于视觉语言模型(如Llama 3.2V)引导的轨迹评分器从候选轨迹中选择最舒适的轨迹来控制车辆,确保类人风格的端到端驾驶体验。
相关工作回顾
端到端自动驾驶
端到端自动驾驶旨在直接从原始传感器生成规划轨迹。在该领域,根据其评估方法对进步进行了分类:开环和闭环系统。在开环系统中,UniAD提出了一个统一的框架,该框架将全栈驱动任务与查询统一接口集成在一起,以改善任务之间的交互。VAD提高了规划的安全性和效率,其在nuScenes数据集上的性能证明了这一点,而SparseDrive利用稀疏表示来减轻模块化系统中固有的信息丢失和错误传播,提高了任务性能和计算效率。对于闭环评估,VADv2通过概率规划推进了矢量化自动驾驶,使用多视图图像生成车辆控制的动作分布,在CARLA Town05基准中表现出色。
扩散模型用于轨迹生成
扩散模型最初在图像合成中备受赞誉,现已被巧妙地用于轨迹生成。基于Potential的扩散运动规划通过使用学习到的势函数来构建适用于杂乱环境的自适应运动规划,进一步增强了该领域,展示了该方法的可扩展性和可转移性。NoMaD和SkillDiffuser都提出了统一的框架,分别简化了面向目标的导航和基于技能的任务执行,其中NoMaD实现了更好的导航结果,SkillDiffusion实现了可解释的高级指令遵循。总之,扩散模型为基于模仿学习的端到端自动驾驶框架的轨迹规划提供了一种有前景的替代方案。由于固有的因果混淆,模仿学习模型可能会错误地将驾驶员的行为归因于错误的因果因素。相比之下,扩散模型可以通过学习场景特征和驾驶员动作在潜在空间中的联合分布,更好地捕捉潜在的因果关系,使模型能够正确地将真实原因与适当的动作相关联。
大模型用于轨迹评测
轨迹评分在自动驾驶决策中起着至关重要的作用。基于规则的方法提供了强有力的安全保证,但缺乏灵活性,而基于学习的方法在开环任务中表现良好,但在闭环场景中表现不佳。最近,DriveLM将VLM集成到端到端的驾驶系统中,通过感知、预测和规划问答对对对图结构推理进行建模。然而,大型模型的生成结果可能包含幻觉,需要进一步的策略来安全应用于自动驾驶。VLM的出现提出了一个问题:VLM能否根据轨迹评分器自适应地调整驾驶风格,同时确保舒适性?
HE-Drive方法详解
稀疏感知
HE Drive首先采用视觉编码器从输入的多视图相机图像中提取多视图视觉特征,表示为F。随后稀疏感知同时执行检测、跟踪和在线地图任务,为周围环境提供更高效、更紧凑的3D表示(见图2)。
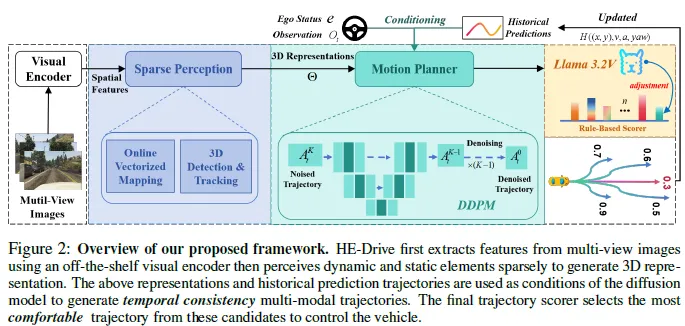
基于扩散模型的运动规划
图2展示了我们基于扩散的运动规划器的整体流程。我们采用基于CNN的扩散策略作为基础,该策略由一个由1D卷积层、上采样层和FiLM(特征线性调制)层组成的条件U-Net组成。
运动规划器扩散策略:本文的方法(图7)采用了条件去噪扩散概率模型(DDPM),这是一个通过参数化马尔可夫链定义的生成模型,使用变分推理训练来模拟条件分布p(At | Ot)。DDPM由一个正向过程和一个反向过程组成,正向过程逐渐将高斯噪声添加到输入数据中,将其转换为纯噪声,反向过程迭代地对噪声数据进行去噪以恢复原始数据。

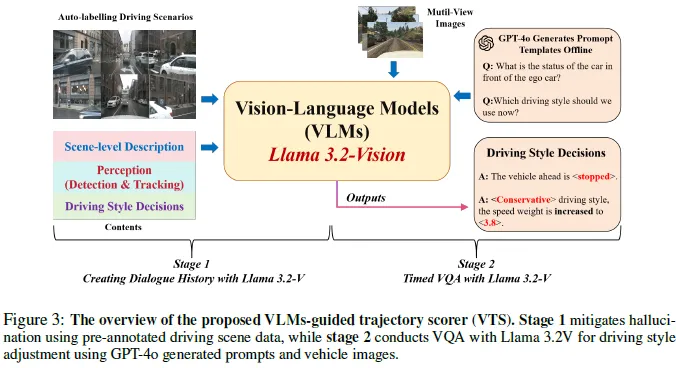
大模型指导下的轨迹评分
为了从DDPM生成的多模态轨迹中选择最合适的路径,我们引入了VLMs制导轨迹评分器(VTS),如图3所示。据我们所知,VTS是第一个结合了可解释性和零样本驾驶推理能力的轨迹评分器。通过利用视觉语言模型(VLM),悉尼威立雅运输公司可以根据各种驾驶因素(如碰撞概率和舒适度)有效地评估轨迹,从而实现透明的决策和对新驾驶场景的适应性,而无需进行广泛的微调(即终身评估)。
实验结果

图4:Llama 3.2V在nuScenes上的定性结果。本文展示了问题(Q)、上下文(C)和答案(A)。通过结合环视图像和文本数据,基于规则的评分器通过针对性的权重修改,实现了驾驶风格的微调。
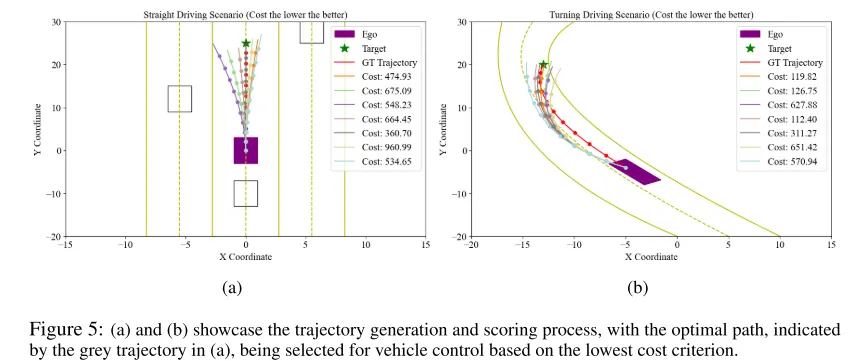
图5:(a) 和 (b) 展示了轨迹生成和评分过程,其中(a) 中的灰色轨迹表示为最优路径,基于最低成本标准被选中用于车辆控制。
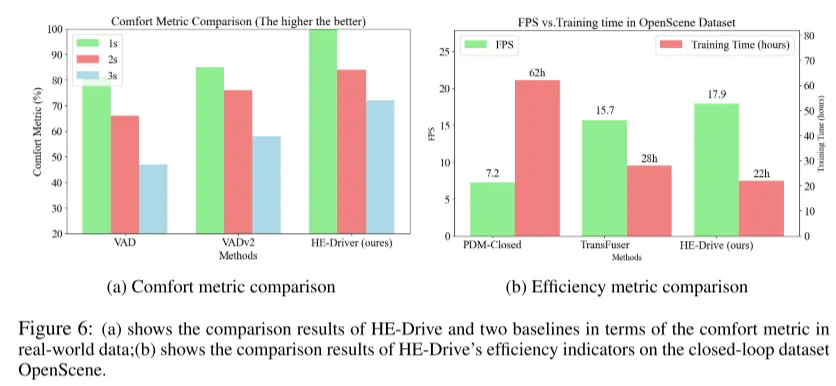
图6:(a) 显示了HE-Drive与两个基线模型在真实世界数据中舒适度指标的比较结果;(b) 显示了HE-Drive在闭环数据集OpenScene上的效率指标比较结果。
总结
本文介绍了HE-Drive,一种新颖的以类人驾驶为核心的端到端自动驾驶系统,旨在解决现有方法在实现时间一致性和乘客舒适度方面的局限性。HE-Drive集成了稀疏感知模块、基于扩散的运动规划器以及Llama 3.2V引导的轨迹评分系统。稀疏感知模块通过统一检测、跟踪和在线映射,实现了完全稀疏的场景表示。基于扩散的运动规划器在连续空间中生成多模态轨迹,确保时间一致性并模拟人类的决策过程。轨迹评分模块结合了基于规则的方法和Llama 3.2V,提升了系统的泛化能力、可解释性、稳定性和舒适度。广泛的实验表明,HE-Drive在开放环和闭环数据集上相较于最先进的方法表现出色,生成了具备更好时间一致性和乘客舒适度的类人轨迹。
#国内外高校具身智能实验室汇总
1 国内
清华大学智能技术与系统实验室
主页:https://www.cs.tsinghua.edu.cn/szzk/jzgml/znjsyxtsys.htm
导师:刘华平、陈挺、冯元等人
研究成果:
来源:https://roboticsproceedings.org/rss18/p032.pdf
来源:https://arxiv.org/pdf/2003.04641
论文:
- DGPO: Discovering Multiple Strategies with Diversity-Guided Policy Optimization , https://arxiv.org/abs/2207.05631
- Embodied multi-agent task planning from ambiguous instruction, in: Proc. of Robotics: Science and Systems (RSS), 2022
- Continual learning with recursive gradient optimization, in: Prof. of International Conference on Learning Representation (ICLR), 2022
ReThinkLab-上海交通大学严骏驰老师实验室
主页:https://thinklab.sjtu.edu.cn/
上海交通大学交ReThinkLab的愿景是开发用于解决现实世界问题的前沿技术,从而可以充分探索和应用数据驱动方法与领域知识相结合的方式。特别是近年来的研究集中在组合优化、偏微分方程、量子计算和人工智能科学(AI4Science)领域。
研究方向:
自动驾驶与机器人(环境感知与定位、决策与规划、机器人操作与控制)、图与组合优化的机器学习(组合优化问题求解、算法设计与分析、应用研究)、面向科学、工程和艺术的学习(电子设计自动化、密码学、药物研发、偏微分方程、神经科学、艺术领域)、量子机器学习(量子电路合成与编译优化、量子图表示学习、量子组合优化)、图学习(动态图学习、图神经网络的泛化性和鲁棒性、图表示学习方法)、离散时间空间(时间序列分析、多变量时间序列分析、音频源分离)、连续时间空间(时间点过程建模、顺序推荐、事件序列分析)、视觉(旋转)目标检测(旋转目标检测算法、目标检测的泛化性和鲁棒性、3D目标检测)等。
研究成果:
来源:https://thinklab-sjtu.github.io/CornerCaseRepo/ , Think2Drive: Efficient Reinforcement Learning by Thinking with Latent World Model for Autonomous Driving (in CARLA-v2)
来源:https://arxiv.org/pdf/2309.05527, ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation
论文:
- Q. Li, X. Jia, S. Wang, Junchi Yan (correspondence). Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2). European Conference on Computer Vision ( ECCV ), 2024. https://arxiv.org/pdf/2402.16720
- Z. Zhao, F. Fan, W. Liao, Junchi Yan .
Grounding and Enhancing Grid-based Models for Neural Fields. IEEE Conference on Computer Vision and Pattern Recognition ( CVPR ), 2024 Best Paper Candidate - Y. Li, J. Guo (本科生), R. Wang, H. Zha, Junchi Yan (correspondence)
OptCM: The Optimization Consistency Models for Solving Combinatorial Problems in Few Shots , Neural Information Processing Systems ( NeurIPS ), 2024
西湖机器人科技、西湖大学机器智能实验室(Machine Intelligence Laboratory, MiLAB)
西湖机器人主页:https://www.westlake.edu.cn/Innovation/StartupsPortfolio/IntelligentManufacturing/WestlakeRobotics/
MiLAB主页:https://milab.westlake.edu.cn/
西湖机器人科技(杭州)有限公司是由王东林博士团队创办的新一代智能机器人科技公司。基于深度学习和机器人学理论基础,研发具有通用行为智能的足式机器人。
公司在西湖大学机器智能实验室(MiLAB)理论研究基础上,高度融合深度强化学习、深度元学习和机器人学,研发下一代具有通用行为智能的足式机器人,可广泛应用于1)教育科研行业、2)电力建筑畜牧等垂直行业、3)商场机场家用等服务行业。
研究成果:
来源:https://www.westlake.edu.cn/Innovation/StartupsPortfolio/IntelligentManufacturing/WestlakeRobotics/
论文:
- PiTe: Pixel-Temporal Alignment for Large Video-Language Model, https://arxiv.org/abs/2409.07239
- Latent Diffusion Prior Enhanced Deep Unfolding for Snapshot Spectral Compressive Imaging , https://github.com/Zongliang-Wu/LADE-DUN
- PathMMU: A Massive Multimodal Expert-Level Benchmark for Understanding and Reasoning in Pathology , https://arxiv.org/pdf/2401.16355
2 北美、欧洲
Stanford AI Lab (SAIL)
斯坦福人工智能实验室(SAIL)的研究领域涵盖生物医学与健康、计算认知与神经科学、计算教育、计算机视觉、经验机器学习、以人为本和创造性人工智能、自然语言处理和语音、强化学习、机器人技术以及统计或理论机器学习等人工智能的各个领域。
联合教师实验室及团队:(详见 https://ai.stanford.edu/research-groups/)
- 斯坦福自然语言处理(NLP)组:成员包括 Chris Manning、Dan Jurafsky、Percy Liang 等。
- 斯坦福视觉与学习实验室(SVL):由李飞飞、Juan Carlos Niebles、Silvio Savarese、Jiajun Wu 组成。
- 斯坦福统计机器学习(statsml)组:有 Emma Brunskill、John Duchi、Stefano Ermon 等成员。
研究成果:
来源:https://arxiv.org/pdf/2401.18059, RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
来源:https://arxiv.org/pdf/2404.13026 , PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation
论文:
- TRANSIC: Sim-to-Real Policy Transfer by Learning from Online Correction, CoRL 2024, Yunfan Jiang, Chen Wang, Ruohan Zhang, Jiajun Wu, Li Fei-Fei, https://arxiv.org/abs/2405.10315
- D3Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Rearrangement, CoRL 2024 (Oral), Yixuan Wang*, Mingtong Zhang*, Zhuoran Li*, Tarik Kelestemur, Katherine Rose Driggs-Campbell, Jiajun Wu, Li Fei-Fei, Yunzhu Li, https://robopil.github.io/d3fields/d3fields.pdf
- PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation, ECCV 2024 (Oral), Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y. Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, William T. Freeman, https://arxiv.org/abs/2404.13026
CSAIL Embodied Intelligence Labs - MIT
主页:https://ei.csail.mit.edu/labs.html
简介:实验室的目标是通过对人类智能的研究以及智能机器人的设计和实现,来理解物理世界中智能行为的本质。我们在感知、传感、语言、学习和规划方面拥有专业知识,目标是整合这些学科,以打造具有类人智能的物理实体。实验室下分许多子实验室,包括算法对齐组、协作学习和自主研究实验室(CLEAR实验室)、计算认知科学实验室、计算设计与制造组(CDFG)等多个研究方向的实验室。
导师:Ted Adelson, Pulkit Agrawal, Jacob Andreas, Sara Beery, Andreea Bobu, Wojciech Matusik等人
研究成果:
【图片:CSAIL-1.gif】
图注:CSAIL下CLEAR实验室成果,强化学习从人类反馈中学习 (RLHF),探索从有噪声、不完整或不一致的数据中有效学习人类目标,使得自主系统能够更好地理解和预测人类需求。
图注:来源:From Imitation to Refinement -- Residual RL for Precise Visual Assembly, https://arxiv.org/abs/2407.16677
图注:A Multimodal Automated Interpretability Agent, https://arxiv.org/pdf/2404.14394
论文:
- Adaptive Language-Guided Abstraction from Contrastive Explanations, https://arxiv.org/abs/2409.08212
- Towards real-time photorealistic 3D holography with deep neural networks, https://www.nature.com/articles/s41586-020-03152-0
- Aligning Human and Robot Representations, https://dl.acm.org/doi/abs/10.1145/3610977.3634987
- Training Neural Networks from Scratch with Parallel Low-Rank Adapters, https://arxiv.org/abs/2402.16828
Quest for Intelligence (MIT)
主页:https://quest.mit.edu/about/vision-statement
简介:麻省理工学院的智能探索计划旨在理解智能 ------ 大脑如何产生智能以及如何在人工系统中复制智能。为了实现这一愿景,必须发展关于自然智能的科学理论,必须创建计算模型,并且这些模型必须与自然智能的能力和神经机制进行比较,并在现实世界的问题上进行测试。智能探索计划的方法不仅需要跨越边界,还需要真正实现跨学科的整合。
导师:Pulkit Agrawal、Cynthia Breazeal、James DiCarlo等人
研究成果:
图注:Quest 工程团队与 EI Mission 合作开发了一个系统,该系统可促进 Quest Robotics/Embodied Intelligence 开发周期中的实验和基准测试。
QREI 程序实验创建和基准测试基础设施。显示了两个配置选项:1) 并行远程执行多个实验,但不进行基准测试,以及 2) 本地执行单个实验,其中根据一个或多个基准测试评估结果。
代表性论文:
- Towards Practical Multi-object Manipulation using Relational Reinforcement Learning, https://richardrl.github.io/relational-rl/
- Adversarially trained neural representations may already be as robust as corresponding biological neural representations, https://proceedings.mlr.press/v162/guo22d/guo22d.pdf
- Diagnosis, Feedback, Adaptation: A Human-in-the-Loop Framework for Test-Time Policy Adaptation, https://arxiv.org/pdf/2307.06333
Bio-Inspired Robotics Laboratory (BIRL) -剑桥
简介:生物启发实验室(BIRL)的研究着眼于如何从自然中汲取灵感来改进机器人技术,无论是学习智能,还是寻找改进机器人运动的方法。BIRL由布鲁塞尔自由大学(VUB)领导,成员包括剑桥大学工程系、巴黎市高等工业物理化学学院(ESPCI)、瑞士联邦材料科学与技术实验室(Empa)以及荷兰聚合物制造商 SupraPolix。团队的一项开发成果 ------"无椅之椅",是一种可穿戴设备,允许用户锁定膝关节并在任何地方 "坐下",无需椅子。
导师:Iida Fumiya, Egorova Veronica, Hosseini Narges Khadem等人
研究成果:
图注:"无椅之椅",是一种可穿戴设备,允许用户锁定膝关节并在任何地方 "坐下",无需椅子。来源:BIRL主页 https://birlab.org/42
图注:富米娅・饭田博士领导的剑桥团队正在研究将自修复材料整合到软机械臂中。来源:BIRL主页 https://birlab.org/
论文:
- Ishida, M., Berio, F., Di Santo, V., Shubin, NH., Iida, F. (2024). Paleo-inspired robotics as an experimental approach to the history of life, Science Robotics, (accepted).
- Fan, C., Chu, KF., Wang, X., Kwok, KW., Iida, F. (2024). State transition learning with limited data for safe control of switched nonlinear systems, Neural Networks, (accepted).
- Xu, J., Anvo, NZR., Taha-Abdalgadir, H., d'Avigneau, AL., Palin, D., Wei, F., Hadjidemetriou, F., Iida, F., Al-Tabbaa, A., De Silva, L., Brilakis, I. (2024). Highway digital twin-enabled Autonomous Maintenance Plant (AMP): A perspective, Data-Centric Engineering, (accepted).
- Almanzor, E., Sugiyama, T., Abdulali, A., Hayashibe, M., Iida, F., (2024). Utilising redundancy in musculoskeletal systems for adaptivestiffness and muscle failure compensation: A model-free inverse statics approach, Bioinspiration & Biomimetics 19: 046015.
Affective Intelligence and Robotics Laboratory (AFAR)-剑桥
主页:https://cambridge-afar.github.io/#:\~:text=I am a first year PhD student at the Computer
简介:AFAR 实验室的研究兴趣在于情感计算和社会信号处理领域,该领域处于包括计算机视觉、信号处理、机器学习、多模态交互和人机交互等多个学科的交叉点。AFAR 实验室的研究方向:(具身化的)人工情感智能、自主的,具有社会情感智能的系统和社交机器人、长期的,自适应的和个性化的交互(虚拟现实 / 人机交互和人机交互)
项目:用于幸福感的自适应机器人情感智能、用于情感计算和机器人技术的持续学习、儿童心理健康的机器人化评估、仿人服务机器人的情感智能、机器人心理健康教练的用户研究、用于幸福感的自适应机器人教练、用于面部动作单元、抑郁和个性分析的深度学习、情感计算的偏差分析和实现公平性、工作年龄。
导师:Hatice Gunes, Sinan Kalkan, Siyang Song等人
论文:
- Learning Socially Appropriate Robo-waiter Behaviours through Real-time User Feedback, https://dl.acm.org/doi/10.5555/3523760.3523831
- Domain-Incremental Continual Learning for Mitigating Bias in Facial Expression and Action Unit Recognition, https://ieeexplore.ieee.org/document/9792455
- Latent Generative Replay for Resource-Efficient Continual Learning of Facial Expressions, https://www.repository.cam.ac.uk/items/ca5b5996-350c-4354-9f5c-941bcc16224b
Oxford Robotics Institute
ORI 致力于拓展机器人的能力,为人类带来更多价值。该研究所的研究兴趣极为广泛,涵盖了从飞行到抓取、从检查到奔跑、从触觉到驾驶、从探索到规划等众多领域。在技术研究方面,ORI 涉及机器学习与人工智能、计算机视觉、制造、多光谱传感、感知、系统工程等多个前沿主题。
研究成果:
论文:
- Textual explanations for automated commentary driving, https://ieeexplore.ieee.org/document/10186611
- Motion planning in dynamic environments using context-aware human trajectory prediction, https://www.sciencedirect.com/science/article/pii/S0921889023000891?via%3Dihub
- EDAMS: An Encoder-Decoder Architecture for Multi-grasp Soft Sensing Object Recognition, https://ieeexplore.ieee.org/document/10121962
Harvard Microrobotics Laboratory
该实验室由罗伯特・伍德教授在哈佛约翰・A・保尔森工程与应用科学学院内创立。它拥有设计、制造和评估具有独特尺寸、形状和材料成分的机器人所需的所有工具。该实验室采用高度实验性的方法来开发机器人,并且我们将这些机器人用作工具,以探索微力学、驱动、流体力学、控制和微电子学中的基本问题。
研究成果:
论文:
- Marter, P., Khramova, M., Duvigneau, F., Wood, R.J., Juhre, D. and Orszulik, R., 2024. Bidirectional motion of a planar fabricated piezoelectric motor based on unimorph arms. Sensors and Actuators A: Physical, 377, p.115642. October 2024, https://doi.org/10.1016/j.sna.2024.115642
- Burns, J.A., Daniels, J., Becker, K.P., Casagrande, D., Roberts, P., Orenstein, E., Vogt, D.M., Teoh, Z.E., Wood, R., Yin, A.H. and Genot, B., 2024. Transcriptome sequencing of seven deep marine invertebrates. Scientific Data, 11(1), p.679. June 2024, https://doi.org/10.1038/s41597-024-03533-4
- Maalouf, A., Jadhav, N., Jatavallabhula, K.M., Chahine, M., Vogt, D.M., Wood, R.J., Torralba, A. and Rus, D., 2024. Follow Anything: Open-set detection, tracking, and following in real-time. IEEE Robotics and Automation Letters, 9(4), pp.3283-3290, April 2024, doi: 10.1109/LRA.2024.3366013.
Rajpurkar Lab
Rajpurkar Lab 是一个致力于推动医学人工智能发展的实验室。研究方向包括:
(1)基础模型:开发自适应医疗基础模型的自我监督和预训练技术,减少对大量数据标注的需求。例如开发了能在无明确标签情况下检测胸部 X 光疾病的 AI 模型,还成功构建并利用了包括胸部 X 光、心电图、心肺音、CT 等医学领域的基础模型。
(2)多模态学习开发结合不同数据源(如图像、传感器和语言)的方法,以提高医学决策和泛化能力。从生理数据开发模型以监测急诊科的高危患者,还开发了能通过学习配对医学图像和放射学报告来解释图像的模型,并建立了跨医学图像和传感器数据的模态不可知学习基准。
(3)生成式 AI:构建生成式 AI 模型,使模型能够用自然语言解释医学图像,并实现与临床医生的交互通信。引入数据集以解决自动报告生成的一些重大挑战,还开创了放射学报告生成的辅助方法,研究为临床医生提供 AI 辅助的影响以及可解释性方法的可信度。
论文:
- Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning, https://www.nature.com/articles/s41551-022-00936-9
- MoCo-CXR: MoCo Pretraining Improves Representation and Transferability of Chest X-ray Models, https://arxiv.org/abs/2010.05352
- Predicting patient decompensation from continuous physiologic monitoring in the emergency department, https://www.nature.com/articles/s41746-023-00803-0
Robotics and Embodied Artificial Intelligence Lab (REAL)
主页:https://real.stanford.edu/index.html
研究方向:多机器人协作与语言模型、机器人技能学习与获取、机器人操作研究、机器人导航与场景理解
研究成果:
来源:https://maniwav.github.io/, ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data
来源:https://umi-on-legs.github.io/, https://www.youtube.com/watch?v=4Bp0q3xHTxE. UMI 是一个带有 GoPro 相机的手持式夹具。有了 UMI,我们可以在任何地方为任何操作技能收集现实世界中的机器人演示数据,而且不需要任何机器人。所以,只要带着 UMI 走到户外,就可以开始收集数据啦!
论文:
- GET-Zero: Graph Embodiment Transformer for Zero-shot Embodiment Generalization, https://arxiv.org/abs/2407.15002, https://get-zero-paper.github.io/
- Dynamics-Guided Diffusion Model for Robot Manipulator Design, https://dgdm-robot.github.io/ , https://arxiv.org/abs/2402.15038
- Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots, https://umi-gripper.github.io/ , https://arxiv.org/abs/2402.10329
Multi-Scale Embodied Intelligence Lab - Imperial College London
主页:https://www.intelligentrobotics-acrossscales.com/
导师:Dr. Dandan Zhang
Multi - Scale Embodied Intelligence Lab 由 Dandan Zhang 博士领导,专注于多尺度的具身智能研究,将机器学习与机器人技术相结合,主要针对医疗应用领域,目标是开发具有超人类能力的下一代机器人。
研究方向:(1)多模态感知(传感):研究如何让机器人在不同尺度下精确地感知环境,例如针对微尺度手术工具的感知研究。(2)交互学习(决策):通过机器学习等技术,探索机器人如何在复杂环境中进行决策,如结合人工操作指令和基于机器学习的自主控制实现高效的人机共享控制。(3)灵巧操作(执行):研究机器人在不同尺度下的灵巧操作能力,包括开发微手术工具以实现精确的微操作,以及研究在 3D 空间中对微工具的灵巧操作控制策略和视觉技术。
应用领域:包括医疗机器人、家用机器人和辅助机器人等。
研究成果:
来源:https://arxiv.org/pdf/2303.02708 , Tac-VGNN: A Voronoi Graph Neural Network for Pose-Based Tactile Servoing
来源:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=\&arnumber=10155191 , TacMMs: Tactile Mobile Manipulators for Warehouse Automation
来源:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=\&arnumber=10182274 , Sim-to-Real Model-Based and Model-Free Deep Reinforcement Learning for Tactile Pushing
论文:
- D. Zhang *, J. Zheng, "Towards the New Generation of Smart Homecare with IoHIRT: Internet of Humans and Intelligent Robotic Things ", under review.
- D. Zhang *, Z. Wu, J. Zheng, Y. Li, Z. Dong, J. Lin, "HuBotVerse: A Mixed Reality-Aided Cloud-Based Framework ", under revision.
- W. Fan*, H. Li*, W. Si, S. Luo, N. Lepora, D. Zhang, * "ViTacTip: Design and Verification of a Novel Biomimetic Physical Vision-Tactile Fusion Sensor ", under review.
Sensing, Interaction & Perception Lab - SIPLAB - ETH Zürich
SIPLAB 是苏黎世联邦理工学院的一个跨学科研究小组,专注于计算交互、具身感知和移动健康领域的研究,涉及混合现实、机器人技术、人机交互和机器学习等多个学科。
研究方向:计算交互(研究自适应系统中的输入意图解码)、具身感知(包括以自我为中心的多模态跟踪,如用于动作和运动捕捉的可扩展方法,以及在不同条件下的姿态估计等)、移动健康(进行生理数据的信号处理,例如心血管监测(每秒测量血压))
研究成果:
论文:
- EgoPoser: Robust Real-Time Egocentric Pose Estimation from Sparse and Intermittent Observations Everywhere. Jiaxi Jiang, Paul Streli, Manuel Meier, and Christian Holz.European Conference on Computer Vision 2024 (ECCV).
- Ultra Inertial Poser: Scalable Motion Capture and Tracking from Sparse Inertial Sensors and Ultra-Wideband Ranging. Rayan Armani, Changlin Qian, Jiaxi Jiang, and Christian Holz.Proceedings of ACM SIGGRAPH 2024.
- Robust Heart Rate Detection via Multi-Site Photoplethysmography. Manuel Meier and Christian Holz.Proceedings of IEEE EMBC 2024.
Robot Perception and Learning Lab
主页:https://rpl-as-ucl.github.io/
Robot Perception and Learning Lab 是一个专注于机器人研究的实验室,工作重点是为关节式机器人(四足、人形、类动物、移动操作器等)开发前沿算法,使它们能够在不可预测的自然环境中高效导航和操作。通过结合感知、决策和运动控制方面的见解,旨在使机器人能够以更高的自主性和精确性处理现实世界场景的复杂性。
研究方向:
- 为关节式机器人(四足、人形、类动物、移动操作器等)开发前沿算法。
- 使机器人能够在不可预测的自然环境中高效导航和操作。
- 提高机器人在处理现实世界复杂场景时的自主性和精确性。
研究成果:
机器人描述:Spot 是波士顿动力公司的旗舰四足机器人,旨在导航和检查具有挑战性的地形。这个强大的平台支持多种研究应用,尤其侧重于高级路径规划和感知系统。Spot 被设计用于在传统轮式或履带式机器人面临局限的现实环境中提供帮助,具备在不平坦表面上进行检查、数据收集和移动的能力。
机器人描述:ANYmal 平台支持低级控制,使其成为推进运动算法、环境感知和规划技术的理想研究工具。研究人员利用 ANYmal 探索在崎岖和动态表面上机器人运动和导航的新方法,为自主探索、检查和监测等领域做出贡献。
论文:
- Active Sensing for Data Quality Improvement in Model Learning. Napolitano, O., Cognetti, M., Pallottino, L., Kanoulas, D., Salaris, P., & Modugno, V. IEEE Control Systems Letters (L-CSS). 2024.
- Real-Time Metric-Semantic Mapping for Autonomous Navigation in Outdoor Environments. Jiao, J., Geng, R., Li, Y., Xin, R., Yang, B., Wu, J., Wang, L., Liu, M., Fan, R., & Kanoulas, D. IEEE Transactions on Automation Science and Engineering (T-ASE). 2024.
- Reinforcement Learning Grasping with Force Feedback from Modelling of Compliant Fingers. Beddow, L., Wurdemann, H., & Kanoulas, D. IEEE/ASME Transactions on Mechatronics (T-Mech). 2024.
Berkeley Artificial Intelligence Research Lab (BAIR)
伯克利人工智能研究实验室(BAIR)成立于 2017 年,汇集了加州大学伯克利分校计算机视觉、机器学习、自然语言处理、规划、控制和机器人等领域的研究人员。该实验室隶属于 CITRIS 人与机器人(CPAR)倡议。
研究成果:
来源:https://www.youtube.com/watch?v=l9pwlXXsi7Q
来源:https://arxiv.org/pdf/2402.15169
论文:
- Ruiqi Zhang, Spencer Frei, and Peter L. Bartlett. Trained transformers learn linear models in-context. Journal of Machine Learning Research, 25(49):1--55, 2024.
- Covert Malicious Finetuning: Challenges in Safeguarding LLM Adaptation , By Danny Halawi, Alex Wei, Eric Wallace, Tony Wang, Nika Haghtalab, and Jacob Steinhardt. ICML 2024: Proc. International Conference in Machine Learning, 2024.
- Jinkyu Kim, John Canny Interpretable Learning for Self-Driving Cars by Visualizing Causal Attention, International Conference on Computer Vision (ICCV) 2017
#PPAD端到端算法
港科大联合元戎启行共同提出
目前随着深度学习技术的快速蓬勃发展为自动驾驶领域的研发提供了强大的助力。目前的自动驾驶系统由于其方便解耦和可解释性的离散化模块设计使得自动驾驶领域产生了很多令我们兴奋的成绩。自动驾驶系统中的传统方法通常将系统分解为模块化组件,包括定位、感知、跟踪、预测、规划和控制,以实现更好的可解释性和可见性。然而这类系统却存在着一些问题:(1)随着系统复杂度的增加,模块之间的误差积累变得更加显著,存在很大的误差累计效应;(2)下游任务所表现出来的性能与上游模块变得高度相关,从而使得构建统一的数据驱动网络模型框架变得非常困难。
最近,端到端自动驾驶因其简单性而受到欢迎。基于学习架构提出了两条主线。第一种方法以原始传感器数据作为输入,直接输出规划轨迹或控制命令,无需任何视图变换,作为场景理解的中间表示。另外一类算法模型则是建立在BEV空间表示的基础上,充分利用查询来生成中间输出作为生成规划结果的指导。其中一个最显著的优势在于可解释性。
受到端到端自动驾驶工作VAD的启发,本文工作的目标是将逐步预测规划引入基于学习的框架当中。直观地说,预测和规划模块可以建模为运动预测任务,根据给定的历史信息预测未来的路径点。每个时间戳时刻的预测和规划模块的结果高度相互依赖。因此,我们需要迭代和双向地考虑代理和代理之间以及代理和环境之间的相互作用,在给定其他代理观测下实现代理预测期望的最大化。基于此,本文提出了PPAD端到端自动驾驶框架,可以逐步规划自车代理的未来轨迹,在矢量学习框架下基于时间实现双向交互,如下图所示。

提出的PPAD算法模型的概括示意图
论文链接:https://arxiv.org/pdf/2311.08100
官方仓库链接:https://github.com/zlichen/PPAD;
网络模型的整体架构&细节梳理
在详细介绍本文提出的PPAD端到端算法模型细节之前,下图展示了我们提出的PPAD算法的整体网络结构图。
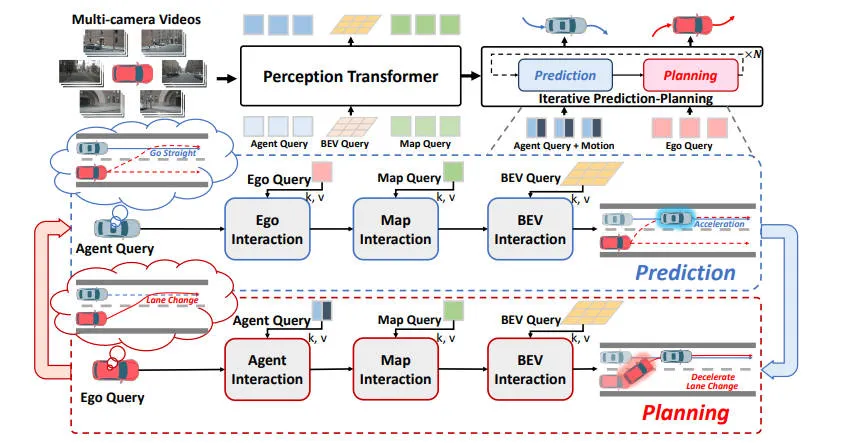
提出的PPAD算法模型的整体网络结构图
通过上图的整体网络结构可以看出,提出的PPAD算法模型主要包括感知Transformer和我们提出的迭代预测规划模块。整体而言,感知Transformer将场景上下文信息编码为BEV空间特征图,并进一步解码为矢量化代理和地图表示。迭代预测规划模块通常由预测和规划两个过程组成。它剖析了自车和其他代理在时间维度上的动态交互。最终,该模块预测代理的运动并规划自车的未来行驶轨迹。
具体而言,对于输入到网络模型中的环视图像特征,我们采用一个共享的图像主干网络来提取每个视角的图像特征。再得到每个视角的图像特征之后,我们采用了BEVFormer中的Encoder模块来得到统一的BEV空间特征。此外,受到端到端自动驾驶框架VAD的启发,我们也通过解码器和地图元素解码器将场景上下文信息完成矢量化的表示,进而得到可学习的代理查询和可学习的地图查询。单独的基于多层感知机的解码器通过采用学习到的查询作为输入,并使用代理的属性和地图属性进行预测得到最终的输出。此外,代理查询将与可学习的运动嵌入相结合,以对代理的各种运动进行建模。具有运动的代理表示为。类似的,自车采用三种方式进行建模,代表直行、左转和右转的高级驾驶命令,表示为。
然后我们采用迭代预测规划模块以交错的方式预测自车和其他代理的未来轨迹。与一次性预测所有轨迹的传统做法不同,我们提出的PPAD算法框架通过迭代代理运动预测和自车规划过程来表示运动规划的每个步骤。借助提出的PPAD框架,我们可以进行深入设计,以精修的方式在场景上下文中执行关键对象的交互过程。
预测和规划的迭代交互
在现实世界中,驾驶交通状况不断变化。驾驶员通过不断推理场景中交通参与者之间的关系来规划和执行他们的决策。规划任务需要自动驾驶系统对场景有很好的理解,并能够解决时空因果因素。因此,我们对提出的PPAD进行了创新,将规划任务分解为代理预测和自车规划过程的多步骤,并最终促进自车和代理的未来轨迹达成共识。提出的PPAD框架将交通交互体现为沿时空的游戏,为自车提供更准确的规划轨迹。具体而言,自车和代理继承了相同的理念,即在每个未来时间戳时刻中根据彼此的运动预测交替优化其运动行为。
预测过程
代理在预测过程中预测其后续的运动,以自车在先前规划过程中的结果输出为条件。具体而言,代理查询的初始状态包括其驾驶意图。然后,它将与从先前规划过程更新的自车查询进行交互,这表明自车当前最新驾驶规划。然后,它将与地图元素交互以选择驾驶路径。最后,它通过与BEV空间特征进行交互来收集详细的几何信息,并得出其精确的下一步运动。
规划过程
我们用来表示历史时期,来代表未来时期。自车的未来轨迹可以表示为。对于每一个代理,其轨迹可以表示为。检测到的地图元素位置可以表示为。
代理交互
预测过程中得到的代理运动位于,包含截止到时间戳时刻的运动状态。将自车从移动到未来一步,自车应该从全局和局部的角度考虑代理的交通状况。从更全局的角度来看,更大范围内的代理可以提供更广泛的交通流量信息,这对于长期轨迹规划至关重要。关于空间局部性,附近的代理被视为关键代理,它们应该与自车的驾驶决策密切相关。
因此,我们建议通过注意力机制与代理进行分层交互,从而为自车学习由粗糙到精细的交通上下文特征。以自车的时空位置为中心,我们初步定义一个距离集合,覆盖了从粗糙到细致的感知范围。我们通过应用具有不同范围的来形成多尺度代理集。然后,自车查询通过多头交叉注意与代理进行分层交互。我们将学习到的分层注意结果的总和作为最终值
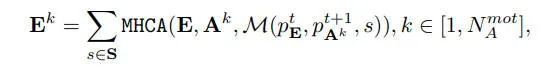
其中,自车独立地从代理的不同模式中查询信息,然后我们将不同模式输出的结果堆叠起来。此外,我们应用集合运算来压缩特征
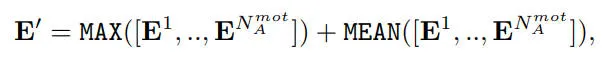
其中和被用于聚合代理模式维度的特征,并使用更新后的自车查询进行输出。
地图交互
现有的一些研究工作试图通过简单地应用一次全局级别的交互来总结规划所需的所有地图信息。但他们忽略了不断发展的运动动态的复杂性,高估了自车可以通过与地图信息的单次交互进行长期精确规划。
利用我们提出的PPAD算法框架,我们可以根据自车的最新位置考虑其本地道路状况,从而丰富自车与地图的交互。这样可以更好地识别规划每个步骤所需的有用地图信息。自车查询与地图查询的交互方式与代理的交互方式类似。不同之处在于地图实例在未来的时间步骤中不可移动。多头交叉注意力机制可以将本地和全局地图信息抽象到自车查询中:
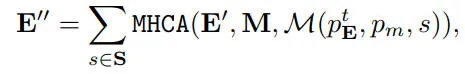
其中,是使用关键地图信息更新的自车查询,用于下一步的规划。
BEV交互
BEV 是整个系统的基本表示,是多摄像头特征的抽象。除了矢量化表示之外,还有其他非结构化环境信息,包括道路和围栏。我们提出了 BEV 交互,可以动态查询周围环境的每个可能的未来步骤。这个查询过程可以帮助代理理解和学习其行为的影响。具体而言,在应用上述交互后,自车可以更好地了解动态代理的交通情况并了解其前方道路状况。然而,规划更精确的运动需要自车理解局部细节几何信息。因此,自车查询进一步与 BEV 特征交互以提取低级几何信息。具体来说,我们通过可变形注意力实现这一过程

其中,是自车在时间时刻的位置,它是BEV特征上的参考点。可变形注意DeformAttn在参考点周围应用稀疏注意力,并学习从BEV中获取低级几何信息以进行规划
运动规划
PPAD使用高级驾驶命令的信息:直行、左转和右转。特征包含动态代理交通、地图语义和精确环境几何的信息。一个多层感知机网络将作为输入并且预测未来的一步路径点偏移。然后我们通过在上应用另一个多层感知机网络来更新自我状态,已进行下一步的处理。
分层特征学习
层次结构具有更好的捕捉和识别细粒度模式的能力。对于驾驶场景,驾驶行为基于对全局和局部场景的理解。驾驶往往只关注少数关键物体,这表明了空间局部性或局部注意力。因此,我们设计了分层关键对象注意力来利用由粗糙到精细的场景上下文。具体来说,给定一组距离范围,我们首先找到给定范围内的关键对象。因此,我们应用动态局部注意力,它只考虑局部区域中代理或地图元素之间的相互作用。下面展示的伪代码描述了动态关键对象注意力的实现。

噪声轨迹作为预测
PPAD算法模型将预测和规划过程交错起来,逐步规划自车和代理的轨迹。然后通过模仿学习将专家驾驶知识强化到模型中。在训练过程中,将噪声轨迹作为预测引入PPAD框架。具体来说,我们通过添加噪声来扰乱真值目标自车轨迹的每一步。然后训练自车预测自车的原始下一步路径点偏移,而不管其起始噪声位置受到何种干扰。即使系统从不准确的位置开始,它也会通过与矢量化实例和环境交互来学习预测准确的路径点偏移。这种策略提高了规划性能。
实验结果&评价指标
为了验证我们提出算法模型的有效性,我们在nuScenes数据集上进行了开环实验,相关的实验结果如下表所示。
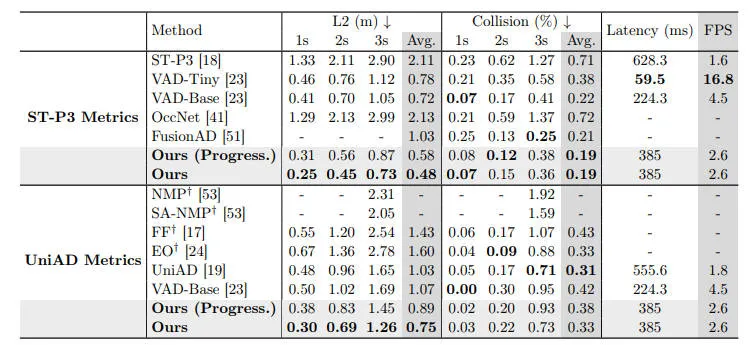
在nuScenes 数据集上的开环规划结果
通过实验结果可以看出,我们提出的PPAD算法模型大大超越了当前最先进算法的表现性能。特别是对于L2距离指标,在时间范围内可以观察到约20%的持续提升。得益于提出的预测和规划的迭代交互,PPAD算法模型可以帮助避免碰撞,与其他端到端自动驾驶算法模型VAD相比,在碰撞率方面取得了更好的结果。
此外,我们也在Argoverse2数据集上进行了实验进一步公平地比较我们的方法和基线算法模型,相关的实验结果如下表所示。
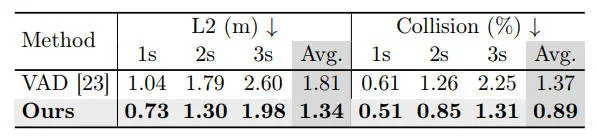
在Argoverse 数据集上的开环规划结果
通过实验结果也可以看出,我们的方法可以在 L2 距离和碰撞率指标方面始终以明显优势超越基线。
此外,为了展示我们的PPAD整体性能,我们还在下表中提供了传统感知和运动预测任务的规划指标之外的评估结果。我们的 PPAD 在上游感知和预测任务中也取得了令人鼓舞的性能,这表明整个系统是联合优化的。
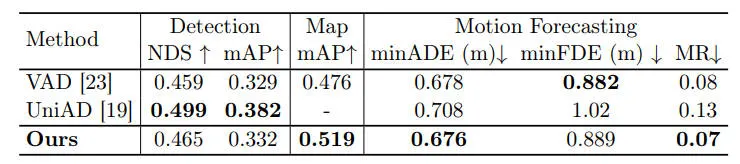
规划任务以外的任务的结果比较
为了更加直观的展示我们提出算法模型的表现性能,下图是相关的可视化结果。PPAD 可以精确地感知场景,并以合理和多样化的动作预测周围的代理。它还为自身车辆规划了一条平滑而准确的轨迹。

结论
在本文中,我们提出了一种新颖的自动驾驶框架 PPAD。与以前缺乏深入交互建模的方法不同,我们将规划问题提出为自我车辆和代理之间的多步骤预测和规划过程,并且实现了SOTA的效果。
#扩散模型去伪求真
Straightness Is Not Your Need?!
23年以来,基于rectified flow1和flow-matching2的扩散模型在生成领域大展异彩,许多基于flow-matching的模型和文章如雨后春笋般涌现,仿佛"直线"已经成为一种政治正确。
该blog的动机,是源于网络平台,诸如知乎,小红书,乃至许多论文中都出现了很多对于rectified flow (flow-matching) 的错误理解和解读。本文希望能够提供一个相对合理的视角来重新思考关于rectified flow相关的话题, 抛砖引玉。
该blog基于最近的论文:
Rectified Diffusion: Straightness is Not Your Need
单位: MMLab-CUHK, Peking University, Princeton University
Technical Report
GitHub
Weights
直观对比,FMs和一般的DMs有本质区别吗?

这种表达式的好处,在于他提供了一个统一的form来看待很多diffusion的形式。下面我们举几个例子:



以这种视角我们看到,flow-matching,它只是general 扩散模型表达式的一种特例,他并不比其他的形式包括VP, VE, Sub-VP更加特殊。要说为什么有很多文章诸如sd3,flow-matching等文章中的效果要比其他form好,我个人认为更多是超参数导致的问题,例如如何分配时间t的采样,时间 t的weigthing,还有prediction type的差异等等。论文中通常为了表现自己方法的优越性,都会对自己的方法进行比较精细的超参数搜索。而对于一种diffusion form的最优超参数设置,未必适用于其他的diffusion forms。
FMs的轨迹真的直吗?
关于这点的误解是最多的,其实所有的diffusion模型训练结束后,它们的采样轨迹几乎必然是curved。我们来看flow- matching的形式
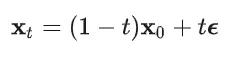
因此
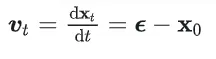
从上面的式子可能会误认为,永远都是
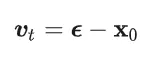

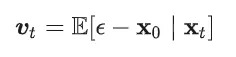
并且注意到,对于不同时间刻,这种期望并不相同,因此不同时间刻t对应的 总是不同的。因此,虽然flow-matching的每次denoise一小步的范围可以认为是以直线前进,但是由于这些小的直线的方向并不相同,总体的采样曲线就是曲线 (或者说很多小折线近似出来的曲线)。
我们用下面一张图更加形象的说明这个例子,红色的点,代表离散采样过程中每一步的, 虽然每步模型denoise都是走直线,但是由于并不相同,因此整体的轨迹为曲线。如果你训练一个flow-matching模型,打印他的轨迹,大概率会发现几乎所有的采样轨迹都是曲线(折线),而非直线。
Rectified Flow是怎么让轨迹变直的?
通读rectified flow189的相关文章,我们可以看到rectified flow相较于一般的DDPM,主要有三点核心的观点:



Rectified flow的采样轨迹,只有在执行了多次(一次)的rectification的操作之后,才会慢慢的变为直线,这也正是rectified flow中实现单步生成的重要操作。
Rectified flow包括后续的诸多工作,都强调Rectification这个操作,仅适用于基于v-prediction的flow-matching形式的diffusion模型。也就是说他们认为前两点~(1和2)是采用Rectification并实现采样加速的的基础,并强调修正过程(Rectification)将ODE路径"拉直"。如果是其他的diffusion forms,如VP, VE, sub-VP6等,则无法采用rectification的操作来实现加速。
这就导致,在InstaFlow10中 (Rectified Flow的后续工作,其作者尝试将rectified flow拓展到stable diffusion上的文生图任务),rectified flow的作者使用stable diffusion的原始权重初始化,但是将SD转变为flow-matching的form,并采用v-prediction来进行重新训练。
所以,rectified flow中的这种观点真的正确吗?在加速sd的过程中,真的有必要首先将其转化为flow-matching的形式和v-prediction吗? Flow-matching的diffusion form真的显著比别的形式好吗?
Recfified Diffusion: 本质是使用配对的噪声样本对重训练。
Rectification实现采样加速的成功之处在于使用成对的噪声-样本进行训练。为了清晰地展示差异,我们可视化了标准的flow matching训练和rectified flow的rectification训练的过程,分别对应算法1和算法2。差异部分以红色标出。一个关键的观察点是,在标准流匹配训练中, 表示从训练集中随机采样的真实数据,而噪声是从高斯分布中随机采样的。这导致了噪声和样本之间的随机配对。相对的,在rectification的训练中,噪声是预先从高斯分布中采样的,图像则是通过预先采样的噪声由前一轮重整(预训练模型)生成的,形成了确定性的噪声与样本的配对。
Flow-matching Training是标准diffusion training的子集。此外,算法2 可视化了更一般的扩散模型的训练过程,与算法1的差异以蓝色和橙色标出。值得注意的是,流匹配是我们讨论的扩散形式的一个特殊情况。从算法中可以看出,它们之间的唯一区别在于扩散形式和预测类型。因此,流匹配训练只是特定扩散形式和预测类型下的标准扩散训练的特殊情况。
通过比较算法2 和算法3 与算法1,可以自然而然的推导出算法4。本质上,通过引入预训练模型来收集噪声-样本对,并在标准的扩散训练中用这些预先收集的配对替换随机采样的噪声和真实样本,我们就得到了Rectified Diffusion的训练算法。
以此为基础,我们提出rectified diffusion。如图下图所示,我们的总体设计非常简单。我们保留了预训练扩散模型的所有内容,包括噪声调度器、预测类型、网络架构,甚至训练和推理代码。唯一的不同在于用于训练的噪声和数据是由预训练扩散模型预先收集和生成的,而不是独立地从高斯分布和真实数据集中采样。也正因为,我们不改变任何原始diffusion的设置,我们在stable diffusion上的实验,具有更小的gap,我们只使用了Rectified flow 8%的trained images,就在一步生成的性能上获得了远超rectified flow的性能。
训练目标是轨迹一阶化
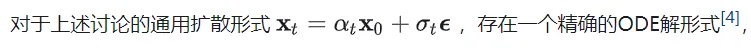
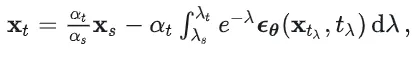

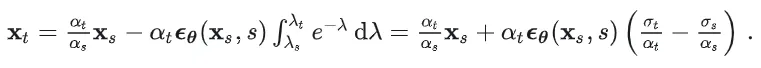
在文章中,我们证明了任意t和s的上述两个方程等价当且仅当ODE轨迹上的预测是常数。
一阶ODE与预定义扩散形式具有相同的形式
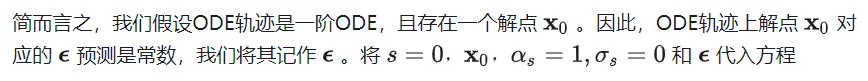
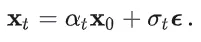
这与预定义的前向过程形式完全相同。因此,我们可以得出一阶ODE正是数据和噪声按预定义的前向扩散形式进行加权插值。唯一的区别在于,上述方程中的和是在同一ODE轨迹上的确定性对,而在标准扩散训练中,和是随机采样的。这意味着,如果我们在训练中实现了数据和噪声的完美耦合,并且不同路径之间不存在交叉(否则预测可能是不同路径的预测期望),则在理想情况下,训练出的扩散模型将获得一阶ODE。
一阶化轨迹可能是弯曲的

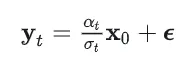

实验验证
我们进行了广泛的实验验证和方法对比,我们的方法取得了一致超越rectified flow相关方法的性能,并且与最先进的蒸馏加速算法1112也取得了comparable的结果。
#特斯拉以身入局!
马斯克的野心不止自动驾驶。。。
马斯克的L5级自动驾驶汽车原型Cybercab,刚刚震撼亮相!没有方向盘、没有电门、没有刹车,也没有后视镜,3万美元,预计在2027年之前量产。观众激动的声浪,要把全场掀翻了。
全球首款无方向盘全自动驾驶汽车,终于来了!
天空一声巨响,马斯克闪亮登场。乘坐着Cybercab自动驾驶汽车原型,他终于兑现了多年承诺。
自此,特斯拉到达新的里程碑。果然诚如马斯克所言,「这将是载入史册的一天」。
因为,机器人给我们开车的时代,真的来了!
Cybercab是一款专门用于自动驾驶的新型电动汽车。
我们坐在这样一辆车里,没有方向盘,没有踏板,只有智能座舱。
可以看到,Cybercab的设计极具未来感,门会像蝴蝶翅膀一样向上打开。不过座舱很小,只能容纳两名乘客。
而且也没有插头,它会以无线的方式感应充电。
如此科幻的产品,价格是多少?
马斯克表示------低于3万美元!
而且他现场承诺:在2027年之前,Cybercab将实现量产。
至此,特斯拉已经实现L5级自动驾驶。
而如果擎天柱驾驶Model 3,那就是L6了。
画饼多年,马斯克今天交出了让观众们满意的答案。
随后出场的自动驾驶「小巴」Robovan和擎天柱,更是把全场气氛推向高潮。



L5级自动驾驶,是这样的
在马斯克看来,全自动驾驶汽车,将使特斯拉跻身万亿美元行列。
他还表示,Cybercab将是「Uber和Airbnb」的某种结合,让车主充当无人驾驶汽车的房东,在城市中漫游,接送乘客。
在开场,马斯克再次提到自己深爱的科幻「银翼杀手」,并称这就是我们所追求的未来。
今天的交通,令我们承受了许多痛苦,并且习以为常,比如在洛杉矶遇到堵车,可能会连堵三个小时。
但是,马斯克表示,这不正常!
不过如果驾驶特斯拉,你就可以体验监督下的全自动驾驶了。
而现在,特斯拉已经从前者,过渡到了无监督的全自动驾驶。
在一个舒适的小休息室里,你可以玩手机、看电影、工作,做任何想做的事。睡一觉醒来,你就已经抵达了目的地。
左右滑动查看
更可贵的是,自动驾驶汽车会大大降低我们的养车成本。
考虑到汽车本身、车险、车贷、停车等所有开销,养车极其昂贵。而在一周的168小时中,普通家用汽车每周仅使用大约10小时。
如果是自动驾驶汽车,使用频率会提高五到十倍。
同样,在安全性上,自动驾驶汽车也比人类驾驶安全十倍。它可以挽救许多生命,预防伤害。
在发布会上,马斯克还给大家算了一笔账,结论就是:自动驾驶的运输成本极低。
Cybercab的运营成本,大概在每英里20美分,最终含税价格在每英里30或40美分。
而Uber或Lyft的司机,可以像牧羊人照看羊群一样,管理一个20辆车的车队。
虽然Cybercab还未量产,但马斯克表示,在美国监管机构批准的地方,比如加州,Model 3、Model Y、Model S、Model X和Cybertruck上,已经可以实现无监督自动驾驶了!
现在,特斯拉有数百万辆车正在接受训练,仿佛是活了数百万次的生命,看到了一个人一生中不会遇到的罕见情况。
正是有大量的训练数据,他们性能出色,能朝各个方向看,且从不疲惫。

而且正因特斯拉的自动驾驶方案是基于AI和视觉,所以不需要昂贵设备。
他们还会提供类似AWS服务,提供大量分布式推理算力。如果汽车每周驾驶50小时,剩下还有超100小时可以利用。
如果有一个1亿辆汽车组成的车队,和每辆车1千瓦的高效推理算力,就相当于拥有了100吉瓦的算力,这是非常可观的资源。
马斯克畅想道,未来城市会是这样的:自动驾驶的世界里不再有停车场(parking lot),而是一个个公园(park),未来人类生活在绿色空间城市中。
按照马斯克的说法,AGI能很可能会从我们的自动驾驶汽车和人形机器人中涌现。
我是说,AGI似乎很可能是我们正在做的事情的一个涌现特性,因为我们正在创造这些自动驾驶汽车和自主人形机器人,它们产生了一个真正海量的数据流,正在被输入和处理。
这是迄今为止最大量的真实世界数据,而且这些数据不可能仅仅通过搜索互联网就能获得,因为你必须在现实世界中与人互动,与道路互动。
地球很大,现实世界错综复杂。
如果你有数千万或数亿辆自动驾驶汽车,甚至可能有相当数量的人形机器人,那么,这就是最大量的数据。
如果这些视频被处理,那么汽车肯定会变得比人类司机强得多,而人形机器人可能会越来越难以与人类区分。
所以,就像你说的,AGI就会作为一种涌现特性,自然而然地出现。
特斯拉 AI 日,2022年9月
Robotaxi试驾感受如何?现场的汽车媒体人开启了首次试驾,近距离展示了汽车内饰能力。
,时长03:51
特斯拉「小巴」Robovan,可坐20人
本以为Robotaxi已经是发布会上的最新品了。
没想到,马斯克还给我们送上了全自动驾驶「小巴」------Robovan。
外媒称,Robovan是当晚的惊喜
整体外观来看,Robovan有着像面包一样的车身,要比Model Y大很多。
它可以承载20多人,还能同时运送货物。
因此,Robovan可以城市内部进行货物运输,还能让我们的旅行成本大大降低,低至每英里5到10美分。
想象一下,走在街头,一辆电动巴士向你驶来的场景。然后下来一车「面包人」。
马斯克称,这就是未来该有的样子。
擎天柱热舞嗨翻天
最后上场的老熟人便是------特斯拉人形机器人擎天柱了。
马斯克先铺垫了一番,解释说为汽车开发的电池、变速器、AI推理计算机等一切,全部适用于机器人。
因此也可以说,自动驾驶汽车与机器人同根同生。
有胳膊和腿的机器人,替代了轮子的机器人。
只见,20多个擎天柱在人群中穿梭,现场观众掌声不断。
马斯克表示,「每个人都可以拥有自己个人的R2D2/C3PO」。
「星际大战」中的两个机器人角色
如果未来大规模生产的话,擎天柱成本大概会降到2万-3万美金。
更长远来看,它可能要比一辆汽车还要便宜。
不过,马斯克承认,我们还需要很长一段时间,才能实现规模效应。
擎天柱走进每个人家庭后,能做任何你想做的事情。
比如,它可以照看孩子老人、遛狗、修剪草坪、超市采购、端水。
它还可以成为你的老师、最好的朋友....只要你想,它都可以做到。
,时长00:39
马斯克坚信,「擎天柱将是最具有重大意义的一个产品。因为地球80亿人未来都需要一个机器人伙伴。甚至,生产线工厂,都将遍及机器人」。
接下来,就是撑起全场最炸裂的一幕了,擎天柱要开始热舞了!
马斯克一句let's party,直接开启了现场狂欢。
在漆黑一片的人群中,所有人视线全部转向身后的高台上,围绕玻璃屋的线性灯瞬间点亮。
现场DJ一起,5个擎天柱突然闪现,开启了动作一致的魔舞。
现场感别提有多嗨了。
,时长01:36
有的擎天柱,在人群中互动。马斯克请求道,「请大家一定要对擎天柱友好些」。
还有穿着西装、带着牛仔帽的擎天柱在调酒吧台前,娴熟地拿起杯子接满鸡尾酒。
然后,亲自为围观的客人们递上。
另一边,它与观众猜丁壳,教他们照自己手势比赞,并为其亲手递上了伴手礼。
还有一些观众高举手机,与擎天柱自拍记录下这一精彩时刻。
可以看出,马斯克正在将特斯拉的核心业务从电动汽车转向机器人和AI。
如今,特斯拉的市值几乎等于所有其他全球汽车制造商的市值,而它的股价很大程度上源于马斯克多年来的承诺:发布一款真正革命性的汽车。
在电动车领域,中国的强势崛起已经大大削弱了特斯拉的明星地位。今年上半年,特斯拉的销量大幅下滑。
对它来说,现在的时期非常关键。
接下来,让我们坐等特斯拉Robotaxi的表现了。
参考资料:
#迈向通用智能之路
全球首届协同具身智能@ECCV2024的一叶知秋
2024年9月30日,由清华AIR和港大MMLab,联合斯坦福大学、上海AI Lab、香港中文大学、慕尼黑工业大学、北航以及嬴彻科技等多家国内外单位,在意大利米兰的ECCV 2024大会上,成功举行了以"协同智能"为主题的自动驾驶与机器人Workshop。本次Workshop邀请了来自中国、美国、德国、日本等国家的专家,分享了协同自动驾驶领域的最新科研成果和产业进展。同时,还邀请了NVIDIA和Google的研究人员,介绍了在Foundation Model方面的最新研究进展。Workshop从提交论文中遴选了20篇高质量Poster论文(其中包括6篇Oral展示),并颁发了Best Paper和Outstanding Paper奖项。活动采用线上线下相结合的形式,吸引了大量观众参与,取得了非常好的反响和效果。
Workshop Event
会议伊始,来自清华AIR和港大MMLab的俞海宝博士简要回顾了Workshop的举办背景、论文接受情况以及会议流程。他指出,协同智能正逐渐成为人工智能领域的研究热点之一。
随后,来自德国慕尼黑工业大学的Alois Knoll教授分享了他的团队在德国车路协同示范区的建设和科研成果,重点介绍了近期发布的真实场景协同数据集------A9数据集。该数据集包含了路端和车端视角的图像和点云数据,均采自车路协同示范区。A9数据集与DAIR-V2X等数据集一道,将极大推动协同智能的研究进展。接着,美国UCLA的Jiaqi Ma教授展示了其Mobiltiy Lab团队在协同智能驾驶领域的一系列研究成果,包括开源框架OpenCDA和多个开源数据集如V2X-Real等。他还介绍了团队将V2X研究成果应用于实车测试的结果,这些研究成果和实车测试吸引了观众的极大关注。
来自中国清华大学的Sheng Zhou教授从通信角度分享了其团队在V2X领域的最新进展,并提出了V2X科研需要与工业应用紧密结合的观点,得到了观众的广泛认同。随后,来自日本东京大学的Manabu Tsukada教授分享了其团队在东京开展的一系列车路协同和V2X研究成果,并展示了基于团队开发的Autoware仿真平台的测试结果。
NVIDIA的Boris博士分享了Nvidia自动驾驶团队近期在world model和foundation model上的进展,并介绍了生成数据在实车测试中的实际应用。这一系列令人激动的成果给与会者留下了深刻的印象。随后,来自Google的Federico博士介绍了团队在3D场景理解方面的最新进展,强调了这一技术对自动驾驶和机器人发展的促进作用。
最后,来自香港大学的Robotwin团队获得了本次Workshop的Best Paper奖项。他们的工作发布了双臂协作的真实数据集,为协同机器人领域的发展带来了重要贡献。来自华南理工大学的RP3D团队则获得了Outstanding Paper奖项,他们提出了新颖的协同感知框架,并发布了适用于高速公路场景的真实协同数据集。清华大学助理教授赵昊博士及香港大学助理教授李弘扬博士为获奖团队颁奖。
在现场的Poster展示环节,讨论异常热烈。与会者们积极交流,深入探讨了各自的研究成果和见解,现场氛围十分活跃。
组织和赞助
最后,特别感谢各位Organizer和Program Committee对本次活动的大力支持。
相关链接和材料
Workshop Talk Record链接: https://hku.zoom.us/rec/share/_K9PGGUvFm_akJCvDfw8_MR98T5xcKx3y_vL3wrVT5qJVsbV9XSAEPG9tLvFFM57.pebGd72LWmOGw-eF(Passcode: 7TdLnjQ=)
Workshop主页:https://coop-intelligence.github.io/
#3DGS原理解析
前言:作为一个连传统计算机图形学都没有完全学透的学生,NeRF论文的阅读难度对我而言还是较为简单;但3DGS的论文难度要高得多(难怪相比于NeRF,3DGS的速度与质量都要高很多),为了高效地完成对3DGS的学习,我在网上找了多篇博客帮助我理解3DGS,再回过头看论文了解更细节的内容,这种方法十分奏效。反过头来,我也应该将总结的知识点分享出来(同时让大家帮忙纠错啦,这才是主要目的(大嘘
Neural Radiance Fields也就是NeRF,是一种新颖的view synthesis方法,通过优化一个MLP,并使用volumetric ray-marching方法实现了3D场景的隐式表示,但该方法要求costly训练和渲染才能得到较高质量的结果。
3D Gaussian Splatting的出现解决了NeRF的问题,并且同为Radiance Field,3D Gaussian实现了更快的训练和渲染并且能够保证渲染图象的质量(equal or better quality than the previous implicit radiance field approaches)。这个方法在某些数据集上实现了state-of-art质量的结果以及real-time rendering
3D Gaussian
首先需要着重理解3D Gaussian是什么
在光栅化方法中,我们会将点组装为一个个基本图元,其中最常用的图元就是三角形,也就是场景都是由多个三角形面片组成,我们通过光栅化方法将多个三角形画到屏幕上。
但在3DGS算法中,渲染的基本图元变为了3D Gaussian(想象成一个三维空间的椭球体)
多个3D Gaussian会组合重叠
物体表面法线对于场景渲染十分关键,传统的3D重建方法在使用稀疏数据估计物体表面法线上面临挑战,而使用3D Gaussian来表示场景时,可以不需要法线就可以捕获场景的结构。
3D Gaussian的简单公式表示是:
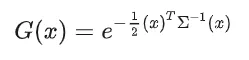
3D高斯函数的形式就是一个椭球体:
3D 高斯函数的中心点由 均值向量(mean vector)决定(上面的公式中默认均值是0,所以没有显示),椭球体的三个主轴对应着高斯分布的协方差矩阵的特征向量,而主轴的长度则对应着特征值的平方根。这也就是说,协方差矩阵决定了高斯分布在 3D 空间中的形状、大小以及方向。我们再给这个椭球颜色与透明度,来让多个3D Gaussian的组合能够形成高质量图像。然后我们就得到了3DGS算法中定义一个3D Gaussian的参数:
- Position (Mean μ): location (XYZ)
- Covariance Matrix (Σ): rotation and scaling
- Opacity ( ): Transparency,这个参数会在alpha blending阶段时与相乘
- Color (RGB) or Spherical Harmonics (SH) coefficients
3D Gaussian中,协方差矩阵只有在正半定时才有物理意义(或者说协方差矩阵必须是正半定的才行),但传统梯度下降方法很难去对矩阵施加此类约束,可能优化过程中打破了协方差矩阵的正半定性,所以不能用传统梯度下降法。或者说不能将协方差矩阵作为一个优化参数直接优化。
还有一点是,我们能够通过三维空间中的三个点定义任意的三角形一样,我们想要通过某种方式获取任意的椭球形状。
协方差矩阵的几何意义是,表示这个椭圆球在空间中的形状(缩放)和方向(旋转)。协方差矩阵是一个正定矩阵,可以通过某种方式进行矩阵分解。而3D Gaussian中有一种特征值分解,具体形式为:
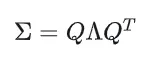
- 协方差矩阵是一个3 X 3 矩阵
- Q是由特征向量组成的正交矩阵(旋转矩阵)。

上面提到过,主轴的长度则对应着特征值的平方根,也就是说可以进一步分解,那么就得到了3DGS原论文中的形式:
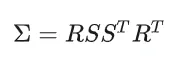

- R是四元数表示的旋转矩阵(此矩阵要保持normalization)
那么不直接对协方差矩阵优化,而是将R,S作为优化参数优化,就可以保持协方差矩阵的正半定。
通过定义R,S以及location(也就是均值),我们可以得到三维空间中所有形式的3D Gaussian。
NeRF的特点就是,它是一个隐式表达的连续的空间,可以使用神经网络进行优化,但无法完全利用GPU进行rendering的加速;传统的使用三角形等Mesh进行的渲染,是显式的离散的空间,可以利用GPU的并行计算来加速渲染,但无法使用神经网络进行优化。而对于3DGS来说,单个3D Gaussian是连续的,可以使用神经网络优化,多个3D Gaussian可以利用GPU进行并行渲染,在两者之间有一个平衡。
Splatting
3D Gaussian是3D物体,要生成图像(就像常规光栅化渲染一样)就需要将其投影到2D平面上。
我们需要实现某种方式,能够将多个3D Gaussian投影到2D image上来渲染结果。
而论文中给出的方式是,替换协方差矩阵为:
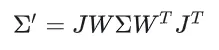
具体来说,仿照渲染管线的流程,假如一个初始的3D Gaussian是在模型空间的话,协方差矩阵就相当于模型变换,将3D Gaussian转换到了世界空间。然后W是View Transform Matrix,将3D Gaussian转换到了相机空间。J是Jocobian Matrix,是用来近似Project Transfor Matrix实现Project Transform。
FAST DIFFERENTIABLE RASTERIZER
假设现在我们已经得到了用于表示整个场景的大量3D Gaussian,现在我们要将其渲染到image上。
为了加速渲染,3DGS选择使用Tile-based rasterization,将Image切为一个个16 * 16的tile,每个tile像一个小image一样独立计算颜色值,最后多个Tile拼成image的颜色。
考虑到每个3D Gaussian投影到2D image时可能会投影到多个tile,处理方法是如果一个Gaussian投影与多个tile相交,就实例化多次Gaussian,每个Gaussian instance都会得到一个结合view space depth和tile ID得到的key。然后基于这些key,使用single fast GPU Radix sort进行排序。
如下图中,黄色Gaussian投影影响了Tile1和2,其他Guassian投影同理;在另一张图中,我们给出了一个Gaussian投影到多个Tile后,多次实例化以及排序的操作。
之后,每个Tile分别进行Alpha Blending,计算像素颜色值得到图像。
INITIALIZATION
假如我们已经有方法对3DGS模型进行一步步的优化,那我们要如何开始呢?
在3DGS中,使用的是一种cv算法,Structure from Motion SfM算法来从输入图像中得到一组点云。SfM的基本思路是利用多张包含相同场景不同部分的图像,通过追踪图像中的共同特征,估算出相机的运动路径(即相机的外参,包括位置和平移)以及场景的三维点云结构。而3DGS算法就要利用从SfM算法中得到的初始点云进行初始化。
得到三维点云结构后,算法会将每个点云转换为3D Gaussian,以此为基础训练模型优化。
OPTIMIZATION
Gradient Descent for Parameter OptimizationDesLoss的计算方法很容易想到,就是用同一个视角下,模型生成的图片与实际的训练集图片的对比。
使用随机梯度下降SGD,对Mean、Covariance Matrix、α、Color进行参数优化。
Loss结合了L1和D-SSIM(Structural Dissimilarity Index)。

原论文中,=0.2
Adaptive Densification
使用SfM算法初始化了一系列稀疏点之后,adaptive densification方法会动态调整3D Gaussians的数量和密度。

densify简单来说就是,under-reconstructed区域克隆small Gaussians以及在high-variance(我觉得就是Over-reconstructed)区域分离large Gaussian。
The Process behind 3D Gaussian Splatting
- 使用SfM(Structure from Motion)初步创建一组point cloud
- 将步骤1创建的point cloud转换为3D Gaussian
- 使用SGD训练。训练过程是将3D Gaussian使用differentiable Gaussian rasterization方法rasterize到图像上,通过生成图像与真实图像来计算loss值,调整参数,实现自动densification调整
- Differentiable Gaussian Rasterization
Conclusion
这篇文章对3DGS算法进行了简单的介绍,作为基础简单了解。
重要资源
https://github.com/MrNeRF/awesome-3D-gaussian-splatting
#非结构化环境中的自动驾驶
由于环境多样性和场景复杂性等挑战,非结构化室外环境中的自动驾驶研究不如结构化城市环境中的研究先进。这些环境,如农村地区和崎岖的地形,构成了结构化城市地区不常见的独特障碍。尽管存在这些困难,但在非结构化室外环境中的自动驾驶对于农业、采矿和军事行动的应用至关重要。我们的调查回顾了250多篇关于非结构化户外环境中自动驾驶的论文,涵盖了离线地图、姿态估计、环境感知、路径规划、端到端自动驾驶、数据集和相关挑战。我们还讨论了新兴趋势和未来的研究方向。本综述旨在巩固知识,并鼓励对非结构化环境中的自动驾驶进行进一步研究。
在本文的讨论中,我们将非结构化环境定义为具有非结构化或最低结构化道路的越野、郊区或农村地区,这些地区缺乏明确的路线和典型的驾驶提示,如道路标志和交通信号。非结构化环境中的自动驾驶可以满足农业、建筑和采矿、物流和交付、救援和勘探以及军事行动等不同领域的需求。与结构化环境相比,这些非结构化环境呈现出完全不同的环境特征,对车辆的自动驾驶技术提出了更严峻的挑战。具体来说,如图2所示,非结构化环境有六个固有特征:
本文对非结构化环境中的自动驾驶进行了全面的回顾,如图3所示。
传统模块化自动驾驶系统的工作流程可以总结如图4所示。在离线准备阶段,系统首先使用离线映射模块创建目标环境的高精度先验图。接下来,基于车辆的实际自主任务要求,全局路径规划模块生成全局路径,为自动驾驶提供方向引导。一旦在线驾驶阶段开始,系统就会接收车载传感器收集的实时数据。姿态估计模块确定车辆的瞬时位置和方向,而环境感知模块分析周围环境的实时情况。然后,局部路径规划模块生成车辆应遵循的本地行驶路径,运动控制模块将这些路径转换为特定的控制命令。
这些模块之间的密切协作实现了系统的自动驾驶功能。然而如图5所示,当面对复杂和未知的非结构化环境时,自动驾驶系统的每个核心模块都会遇到不同程度的挑战,严重阻碍了工作流程的正常运行。
总结来说,本文的主要贡献如下:
- 全面研究非结构化环境中自动驾驶的最新进展,包括深刻的哲学见解和详细的讨论。
- 详细分析与非结构化环境中自动驾驶各个方面相关的文献,如离线建图、姿态估计、环境感知、路径规划、运动控制、端到端自动驾驶和数据集。
- 评估非结构化环境中自动驾驶的现有挑战和局限性,并探索潜在的研究方向,以指导和刺激未来的进展。
离线建图
在自动驾驶系统中,地图构建模块使用离线预收集的数据来创建目标环境的高精度先验地图。这些地图有效地存储和表示了有关静态环境特征和道路拓扑的关键信息,为后续的姿态估计和全局路径规划模块提供了有价值的先验数据。然而,在复杂和未知的非结构化环境中,离线建图模块的可用性往往难以保证。
A.非结构化环境下离线建图的挑战
- 无法预先收集数据:在针对非结构化环境的自主任务中,例如战场侦察或瓦砾遍布地区的灾难恢复,一个常见的挑战是这些环境的未知性和局限性。这意味着在任务开始之前,车辆通常无法进入目标区域收集数据,从根本上限制了地图构建模块的可用性。
- 实用性显著降低:即使在可以预先收集数据的非结构化环境中,缺乏标志、标记和铺砌道路等关键交通要素也会导致先前地图中包含的有用信息量大幅减少。这严重降低了它们在自动驾驶系统中的实用价值。此外,非结构化环境中的自然地形和特征会随着季节和天气而发生显著变化,需要频繁收集数据以更新之前的地图。这大大增加了系统的运营和维护成本。
地图构建过程通常以SLAM为核心技术,辅以在线和离线应用的手动标签和精确测量技术。根据使用的传感器类型,自动驾驶的测绘方法可分为四种主要类型:基于激光雷达的方法、基于视觉的方法、基毫米波的方法和多传感器融合方法,如表一所示。
姿态估计
在自动驾驶系统中,姿态估计模块使用实时传感器数据和已知的先验信息来估计车辆的位置和方向,为后续的规划和决策模块提供必要的位置数据。然而,当在复杂和未知的非结构化环境中运行时,姿态估计模块在提供高精度全局定位方面经常面临重大挑战。
A.非结构化环境中姿态估计的挑战
- GNSS信号易受干扰:在复杂的非结构化环境中,GNSS信号极易受到山脉、树木和岩石等障碍物的干扰,导致反射或散射,引发多径效应,从而大大降低定位精度。此外,电磁干扰的存在对全球导航卫星系统的可用性构成了严重威胁。这种干扰会扭曲或完全阻挡GNSS信号,严重影响姿态估计结果的准确性和稳定性。
- 有限的高精度定位方法:在未知的非结构化环境中,由于缺乏高精度先验地图,基于地图匹配的定位方法无法使用。虽然可以在一定程度上采用基于航位推算的方法,但它们固有的累积误差问题仍然难以解决,非结构化环境的复杂性可能会进一步加剧这种误差累积。因此,姿态估计模块中的高精度定位选项非常有限,这使得实现稳健、高精度的定位变得具有挑战性。
目前,自动驾驶中使用的姿态估计方法可分为三种主要类型:基于GNSS的方法、基于地图匹配的方法和基于里程计的方法。基于GNSS的姿态估计方法可能会受到卫星障碍或多径传播效应的不利影响,导致输出姿态估计结果的显著漂移,并导致定位失败。基于地图匹配的姿态估计方法通过将实时传感器观测值与预先构建的高精度地图对齐,实现了对地面无人平台姿态的精确估计。这个过程主要涉及两个关键步骤:观测匹配和优化校正。基于里程计的姿态估计方法以地面无人平台的初始位置为原点,使用在线获得的传感器数据迭代计算相对于前一时间点的姿态变化。
环境感知
在自动驾驶系统中,环境感知模块使用传感器收集的观测数据分析周围环境的实时情况。该分析为后续的规划和决策模块提供了关键信息。然而,当在复杂和未知的非结构化环境中导航时,感知模块面临着许多挑战。
A.非结构化环境中的环境感知挑战
- 定义环境特征的困难:在非结构化环境中,使用手动预设规则或先验假设很难有效地定义环境特征,这对它们的识别和理解构成了重大挑战。例如,非结构化环境中的通航区域可能采取各种形式,如土壤、草地或砾石路径,通常伴随着混合材料成分和不明确的边界。这使得基于规则的识别通航区域的方法不足。同样,非结构化环境中的障碍物分类非常复杂和模糊。各种各样的潜在障碍物,每种障碍物都有不同的形状和特征,因此手动设置统一的检测标准是不切实际的。此外,某些环境特征的属性与车辆本身的物理特性密切相关,缺乏绝对性,这为定义环境特征增加了另一层复杂性。
- 对手动标记样本的依赖:尽管深度学习取得了重大进展,为环境感知模块提供了强大的工具,但它们的性能在很大程度上取决于大量手动标记的训练样本。然而,用于非结构化环境的公开数据集仍然非常稀缺,迫使研究人员投入大量时间和资源来构建数据集。此外,由于非结构化环境中特征的多样性和环境类型的多样性,现有的标记数据往往难以在不同环境中有效重用。因此,当面对新的非结构化环境时,需要大量的手动标记工作,导致数据注释成本很高。更复杂的是,非结构化环境中常见的语义类别的模糊性导致了环境特征分类的混乱,并使得区分特征边界变得困难。这进一步增加了手动标记的难度和错误率。
在环境感知模块中,识别可通行区域是确保自动驾驶安全的核心功能。此外,环境感知模块中的另一项关键任务是对树木、车辆和道路等关键环境因素进行细分。
地形可通行性分析更侧重于为无人驾驶车辆识别合适的路径,对于在非结构化环境中实现机器人自主性至关重要。与此过程密切相关的任务包括道路检测、地面分割、自由空间检测等。在非结构化环境中,许多为城市街道设计的方法都是不够的,因为没有人行道或车道标记、路缘石或其他人工边界来区分道路和非道路区域。相反,地形由具有复杂视觉和几何特性的自然物体组成。根据所使用的传感器,可通行性估计算法分为基于激光雷达、基于视觉和基于融合。
路径规划
路径规划和轨迹规划算法是创建通过通航区域成功到达目的地的最佳路线的过程。这种最优性可以反映在路径长度、能耗或操作员认为重要的任何其他指标上。路径规划方法分为全局路径规划和局部路径规划(图8)。由于实际应用场景的多样性和复杂性,不同场景对路径规划的要求各不相同,因此路径规划方法有很多种,如表九所示。
与结构化环境相比,非结构化环境中的路径规划面临着几个主要挑战。这些挑战包括高度的不确定性和动态变化、复杂的状态空间、有限的先验知识、实时操作要求以及长期规划的复杂性。本节将详细讨论这些挑战,并探索非结构化环境的路径规划算法。
A.非结构化环境中的路径规划挑战
1)全局路径规划的挑战:在自动驾驶系统中,全局路径规划模块可以根据目标环境的先验信息和车辆的特定任务要求生成引导自动驾驶车辆的路径。然而,在导航复杂和未知的非结构化环境时,缺乏先验信息严重限制了全局路径规划模块的功能。
- 卫星图像作为唯一数据源:在未知的非结构化环境中,缺乏高精度先验地图意味着只能通过卫星图像获得目标场景的先验信息。因此,全局路径规划模块仅依赖卫星数据来生成全局制导路径。然而,以这种方式生成的路径往往存在明显的不准确性,精度水平远不能满足后续局部路径规划模块的要求。2)局部路径规划的挑战:在自动驾驶系统中,局部路径规划模块整合了全局引导信息、姿态估计数据和环境感知,在短时间内动态生成车辆的局部行驶路径。然而,当面对复杂和未知的非结构化环境时,局部路径规划模块会遇到几个挑战。
- 对定位误差高度敏感:在非结构化环境中,由于可靠定位方法的可用性有限,车辆的准确和稳健定位尤其具有挑战性。局部路径规划模块通常对定位误差高度敏感。如果姿态估计模块失败或产生不准确的结果,计划的局部路径可能会严重偏离,增加不正确路线和不当驾驶行为的风险,这对自动驾驶的安全构成严重威胁。
- 对几何约束的依赖性:现有的局部路径规划算法往往严重依赖几何约束信息。然而,在非结构化环境中,自然地形特征占主导地位,无法为无人平台提供清晰有序的约束信息。此外,这些自然元素往往缺乏空间规律性,使几何约束变得混乱或无效,这大大增加了局部路径规划过程的复杂性和不确定性。例如,在沙漠或草原等特征稀少的环境中,几何约束信息的稀缺使局部路径规划模块的决策支持不足。相反,在丛林或山区等特征密集的环境中,大量不规则分布的特征会导致过度冗余的几何约束,使局部路径规划模块难以生成可行的局部路径。
常见的全局路径规划算法包括A*算法、Dijkstra算法和快速探索随机树(RRT)。局部路径规划侧重于机器人运动过程中的即时路径调整,考虑机器人当前位置周围的环境信息。常见的局部路径规划算法包括动态窗口法(DWA)、基于优化的方法和人工势场(APF)方法。数据驱动方法可用于全局和局部路径规划。
运动控制
在传统的模块化自动驾驶系统中,运动控制模块的功能类似于车辆的"手和脚"。尽管已经对城市自动驾驶汽车进行了大量研究,但车辆在非结构化环境中存在一系列独特的建模挑战。车辆在复杂和不可预测的地形中行驶,导致车辆和地面之间的复杂相互作用。此外这些车辆拥有自己复杂的动力学,这增加了另一层复杂性。这些挑战可能会阻碍有效的高速控制和规划过程。
A.非结构化环境中运动控制的挑战
在传统的模块化自动驾驶系统中,运动控制模块的功能类似于车辆的"手和脚"。尽管已经对城市自动驾驶汽车进行了大量研究,但车辆在非结构化环境中存在一系列独特的建模挑战。车辆在复杂和不可预测的地形中行驶,导致车辆和地面之间的复杂相互作用。此外,这些车辆拥有自己复杂的动力学,这增加了另一层复杂性。这些挑战可能会阻碍有效的高速控制和规划过程。
- 车辆和地面之间的复杂相互作用:车辆在复杂和不可预测的地形中行驶,如崎岖的地形、茂密的森林和不同的土壤类型,这些地形可能会因雨或雪等环境因素而突然变化。这些条件会导致车辆和地面之间的复杂相互作用,包括牵引力、打滑和负载分布不均的变化。这种动态会显著影响车辆的稳定性和控制,需要复杂的算法来实时准确地预测行为。
- 车辆具有复杂的动力学:每辆车都有不同的特征,包括重量分布、悬架设计和轮胎特性,所有这些都会影响它在非结构化环境中对输入和外力的反应。例如,在同一地形上行驶时,重型车辆的行为可能与轻型车辆不同,因为它的动量和惯性在其运动中起着至关重要的作用。了解这些个体动力学对于制定有效的控制策略至关重要,因为它们决定了车辆在加速、制动和转弯过程中的反应。这些挑战可能会阻碍有效的高速控制和规划过程,因此在建模阶段考虑外部地形和车辆的内部动力学至关重要。
基于车辆的自由度,其运动控制过程可以解耦为两个相对独立的过程:纵向控制和横向控制。纵向控制侧重于通过自动调整动力或制动执行器来精确管理车辆的速度和加速度,确保车辆以所需的速度行驶。另一方面,横向控制通过调节转向机构实时调整车辆的方向,确保精确跟踪计划路径。目前,地面无人机运动控制模块中使用的主要控制算法包括比例积分微分(PID)控制、预见跟踪控制、滑模控制和模型预测控制(MPC)。目前,非结构化环境中自动驾驶运动控制的研究主要围绕MPC方法展开。
端到端自动驾驶
自动驾驶的本质问题在于探索和建立传感器观测数据与车辆控制命令之间的映射关系。鉴于自动驾驶系统的固有复杂性,直接描述这种映射关系极具挑战性。越来越多的研究开始探索数据驱动概念从深度学习到自动驾驶的直接应用,从而为非结构化环境端到端自动驾驶带来了一种新的范式。
端到端自动驾驶方法摒弃了传统模块化自动驾驶方法中繁琐的任务划分和规则设计,而是利用深度神经网络直接学习从传感器观测数据到大量数据中的车辆控制命令的复杂映射关系。该方法的输入端可以包括多模态信息,如视觉数据、LiDAR点云数据、平台运动状态和任务命令,而输出端主要为转向机构、动力执行器和制动执行器生成相应的控制命令。
端到端自动驾驶方法的研究起源可以追溯到1988年,当时卡内基梅隆大学发起了开创性的ALVINN项目。在这个项目中,研究人员利用浅层全连接神经网络来处理输入图像和雷达数据,实现了车辆运动方向的端到端控制。随后,在DARPA发起的DAVE项目中,使用六层神经网络将立体摄像头获得的视觉信息映射为无人驾驶车辆转向角的控制信号,首次成功实现了端到端的自主避障。尽管这些早期研究在一定程度上揭示了神经网络在自动驾驶系统中的潜力,但在实现完全的自动驾驶功能之前,它们仍有很大的差距需要弥合。
2016年,NVIDIA在DAVE项目的基础上进一步推出了DAVE-2项目,通过训练大规模深度卷积神经网络,成功实现了基于高速公路和城市道路视觉信息的端到端全过程自动驾驶。这一突破性的成就不仅验证了端到端自动驾驶研究范式的有效性,而且真正将这一研究范式推向了学术界的前沿。
随着深度学习技术的不断进步和硬件计算能力的不断提高,端到端的自动驾驶方法已成为非结构化环境中自动驾驶的热门研究课题。根据网络模型的不同学习方法,该方法逐渐分为两个主要研究方向:模仿学习方法和在线强化学习方法,如表十七所示。
数据集
展望
非结构化环境中自动驾驶的未来研究工作应集中在增强模块化自动驾驶和端到端自动驾驶,收集更多数据,提高自动驾驶系统的安全性和效率。这些努力将推动自动驾驶技术在更广泛、更复杂的非结构化环境中的进步和应用。
离线地图。非结构化环境中自动驾驶离线地图的未来前景侧重于创建详细、高分辨率的地图,以解释不同的地形和动态的环境变化。先进的传感器技术,如激光雷达和摄影测量,可以捕捉到景观的复杂特征,从而生成全面的数字双胞胎。此外,整合时间数据将使这些地图能够适应季节和天气变化,最终增强导航能力。
姿态估计。在非结构化环境中进行姿态估计的挑战需要开发利用多种传感器模态的鲁棒算法,包括相机、激光雷达和IMU。未来的进步可以深入研究机器学习技术,以提高对复杂空间关系的理解,并补偿特征的模糊性,从而在混乱的地形中实现更准确的实时定位。
环境感知。在环境感知领域,未来的创新应侧重于多模态传感器融合,整合视觉、听觉和触觉数据,以更好地识别和分类自然物体。通过采用先进的深度学习模型,系统可以更有效地识别非结构化环境中的各种元素,从而更好地理解复杂环境,并能够适应新的、看不见的挑战。
路径规划。未来非结构化环境的路径规划技术可能会利用自适应算法,该算法能够根据环境的实时反馈动态调整路线。通过结合强化学习和预测建模,自主系统可以有效地导航无序的场景结构和复杂的道路状况,在不确定的地形中优化安全性和效率。
运动控制。运动控制的进步将优先发展能够处理非结构化环境的不可预测性的高响应系统。未来的前景包括使车辆能够平稳地穿过不同的表面和斜坡,同时适应地形的突然变化,最终在具有挑战性的条件下增强稳定性和控制力的算法。
端到端自动驾驶。非结构化环境中端到端自动驾驶的未来将强调从大量数据集和现实世界经验中学习的先进模型的集成。这种整体方法可以使系统能够自主导航复杂的场景,识别和适应环境变化,而无需严重依赖预定义的规则或结构。
数据集。构建包含非结构化环境多样性和复杂性的强大数据集至关重要。未来的工作应侧重于创建合成和真实世界的数据集,以捕捉各种场景,包括季节变化和不同的地形,从而训练机器学习模型。解决语义类别模糊性的增强标记技术对于提高这些不可预测环境中自主系统的准确性和可靠性也至关重要。
结论
由于农村道路、山地和荒野地区等自然环境的多样性和复杂性,非结构化环境中的自动驾驶带来了许多挑战。这些环境缺乏标准化的道路标记,容易受到野生动物和动态天气条件等不可预测的障碍物的影响。本综述概述了非结构化环境中自动驾驶的当前进展,涵盖了离线映射、姿态估计、环境感知、路径规划、运动控制、端到端驾驶和数据集等领域。它有助于快速了解该领域的研究进展。虽然在非结构化环境中实现完全自动驾驶存在重大障碍,但正在进行的研究和技术进步继续为能够在世界上最具挑战性的地形中导航的更安全、适应性更强的自动驾驶汽车铺平道路。
#E2E自动驾驶的关键技术分享
Mobileye CEO and CTO reveal stealth developments inAI for achieving full autonomy 2024 Mobileye Driving AI Day,ME的AI DAY,油管链接
Part2是CTO Shai 的分享
主要关注在感知(sense)和规划(plan)部分。
高效的AI系统是ME重点研发迭代的方向。
主要分为四个部分:
- 感知和规划中transformer 100倍加速
- 推理芯片EyeQ6H的高效设计
- 高效自动标注系统
- 高效模型蒸馏框架
6个AI技术革命:
ME成立1999年,最早使用机器学习应用在产品公司之一。
2012 深度学习技术兴起,ME也是最早使用该技术栈的公司之一。(题外话,据说最新的EyeQ6产品中仍然还有一些重点模块是传统机器学习方案,没有采用深度学。还是依赖强大的早期技术积累,作为产品能work好就行,不讲究技术方案)
2018 以来,生成式AI,通用学习,sim2real,逻辑推理技术发生革命,都是基于Transformer。
ME关注这些技术如何影响自动驾驶
Transformer时代之前的障碍物检测pipeline:
检测2D框,抑制重叠框,通过2D恢复3D(手段有很多,可以去搜索下,感兴趣的话),给到下游PNC
讲到GPT,后面大量内容都在这个部分:
GPT可以Tokenize 一切
输入:把多模态数据变成一序列tokens
输出:输出也是tokens序列,生成式,自回归模型
支持复杂的输入和输出结构,数据集,序列,树
障碍物检测ppl实例:
输入:单帧图片
将图片patches序列编码,
输出:图像坐标中多个障碍物坐标序列
之前方案:输入是固定规模下的输出
现在方案:学习任意序列长度的概率
关键特性:
链式法则,建模序列依赖性
生成式:使用最大似然拟合数据
工具:自监督,处理不确定性
解释链式法则:
4个车,16个坐标,32个位置,每个位置10个可能性(图像分为100patches,这里就是一个分类,不是准确坐标回归)
所以
不使用链式法则同时预测4个目标坐标维度需要 Dim = 10^32
使用链式法则,每个目标相互独立,只预测10个行*10个列可能性?
(感觉就是一个粗略比喻,不太严谨)
self attention:互相倾听
self reflecton:自我思考
transformer非常高效:
相对FCN,更加sparse,
相对cnn,支持多模态
相对LSTM/RNN,更稠密,但是只选择过去几个token
可处理所有类别输入
可处理不确定性,gpt可以输出很多合理答案,正确答案不唯一
可以输出所有类别输出,比如chatgpt可以描述很多场景
transformer终极学习机器
常规transformer不够高效,ME的方案可以无损情况下加速100倍
其中也提到ME也有尝试直接输出控制信号的端到端方案
回归主题,如何加速transformer100倍
提出STAT,在TOKEN类别,维度,连接性,增加link token
应该就是每个图像patch,降低分辨率,300用32个link token表示,cross attention在32个link token之间。
听下来是做了近似,应该有精度损失,talk说不带有精度损失?
实际应用中并行结果输出,检测结果之间没有前后顺序关系,PAR不是ME的独创,由于IO的限制,串行对芯片推理不利
Detr不是很好的处理不确定性问题
每个query有自己的输出结果,query之间是独立的,并行的
灵活和高效需要折中
EyeQ6有5种不同结构,分别处理不同算法
6比5功耗增加7w,效率增加十倍,magic就是XNN模块
总结:
- 展示了ME的方法论,尤其是在技术开发,芯片设计,产品定义上有不少谈及
- 建模方案,理论分享,能有实际上车视频结果就更好了
- 相对国内AI Day的"全国都能开","年底200城","无图端到端","VLM慢系统"等,这个talk显得非常内敛,更偏向科普性质
- 期待ME能够推出更多优秀产品,特别是城区NOA
#DrivingSphere
闭环仿真杀器!理想提出直接构建高保真4D世界
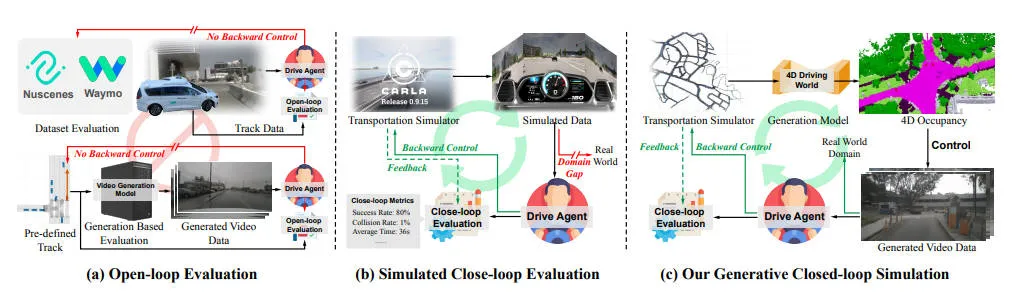
近年来,端到端自动驾驶算法取得了重大进展,准确评估这些模型是一项非常紧迫的任务。为了安全、负责任地进行评估,必须有一个精确的模拟环境,准确反映现实世界的驾驶条件。这个要求通常包括两个方面:一是高保真传感数据的生成,二是闭环反馈机制的实现。
当前最常使用的评估方法是开环仿真方法。虽然这些基准测试提供了真实的驾驶数据,但它们的分布相对固定,且缺乏多样性,限制了它们评估自动驾驶算法的泛化能力。总而言之,尽管具有高保真传感数据,但这些开环评估解决方案无法提供评估自主系统如何响应动态变化和决策所需的动态反馈。
另外一种即闭环仿真方法,其提供反馈驱动系统,其中代理的行为会影响其他代理和环境,并受其影响。然而,由于缺乏处理视觉传感器输入的能力,限制了它们与基于视觉的端到端模型的相互作用。基于游戏引擎的模拟器创造了可扩展且物理上逼真的环境,但它们的输出通常与现实世界的传感器数据不同,限制了它们在验证基于实际输入的算法方面的作用。
针对上述提到的相关问题,为了应对这些挑战,我们提出了一种新颖的几何感知闭环模拟框架,可捕捉二维视觉和三维几何特性,同时与基于视觉的端到端驱动代理无缝集成,它利用几何先验信息来生成逼真且可控的驾驶场景,称之为DrivingSphere。与现有的相关仿真框架相比,我们提出的DrivingSphere。与现有的仿真算法框架相比,DrivingSphere 有三个显著特点
- 丰富的仿真粒度:与过去仅对道路和汽车进行建模的方法不同,我们的方法允许包括以前未建模的元素,例如建筑物、植被和其他环境结构。虽然这些非交通元素并不直接参与交通流,但它们的存在会显著影响驾驶模型的输入,从而影响复杂驾驶场景中的决策过程。
- 物理和空间真实感:由于我们的模型明确地表示了 4D 空间中的场景和交通参与者,因此它能够精确地描绘不同交通元素之间的物理相互作用和遮挡关系。这确保每个视点和位置自然地遵循深度和遮挡等物理原理,从而实现全球道路布局、交通参与者及其行为的结构化协调。
- 高视觉一致性和保真度:我们的模型更加努力地将场景中每个交通参与者的外观和唯一 ID 关联起来,从而跨帧和视图提供稳定且高保真的时间和空间一致性。
下图是我们的算法模型和开环与闭环仿真的整体框架进行对比
论文链接:https://arxiv.org/pdf/2411.11252
算法模型网络结构&技术细节梳理
在详细介绍本文提出的DrivingSphere算法框架之前,下图展示了DrivingSphere的整体网络结构图。
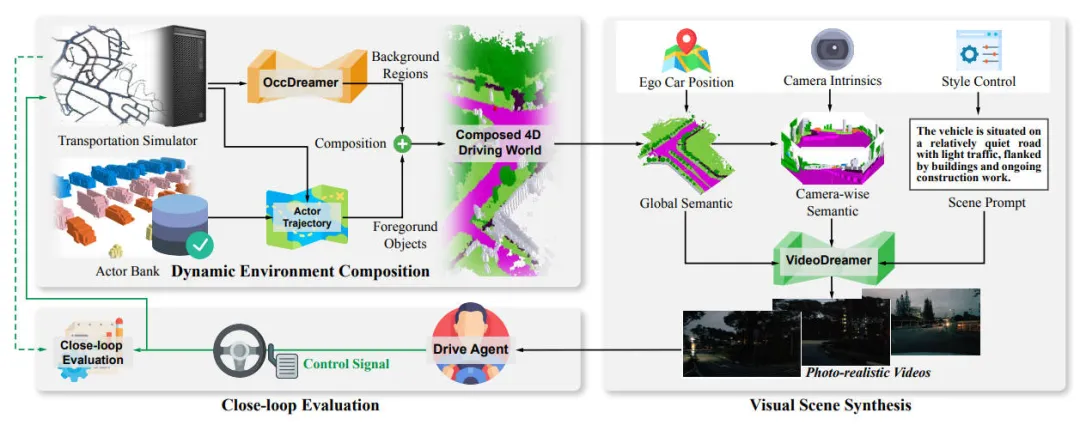
DrivingSphere 是一个生成闭环模拟框架,它将基于占用的 4D 世界建模与先进的视频渲染技术相结合,提供高保真视觉输出,增强自动驾驶场景中的仿真真实感和代理与环境的相互作用。具体来说,DrivingSphere 从动态环境合成开始,从地图草图生成静态背景,从参与者库中选择交通参与者,并更新参与者位置,以构成具有占用格式的 4D 驾驶环境。接下来,视觉场景合成调节自车周围的占用数据,准确捕捉遮挡关系和细粒度语义信息,以生成高保真多视图视频。最后,闭环反馈机制实现动态、响应调整,其中自主代理不断接收更新的视觉数据并生成修改模拟环境的控制信号,为算法测试和改进提供全面的平台。
Dynamic Environment Composition
以前的驾驶模拟方法经常忽略建筑物、障碍物和植被等静态和多样化元素。虽然这些元素不是直接的交通参与者,但它们是自动驾驶系统感知输入的一部分,影响最终的驾驶决策。例如,建筑物等静态物体可能会阻挡传感器的视线,导致其他车辆或行人的遮挡。障碍物或植被会给自动驾驶系统带来传感器伪影或误报。这两种情况都可能导致错误的决策,例如不必要的刹车或车道变换。为了解决这个问题,我们提出了一种动态环境组合来构建一个配备复杂数字资产的综合自动驾驶驾驶世界。
4D驾驶世界表达:我们的4D驾驶世界表示包括三个关键数字资产,分别是:静态背景场景、动态前景参与者以及这些参与者的空间位置。我们采用来表达。其中,是多个区域静态场景的复合体。每个是第个静态背景场景,捕捉区域内的空间布局和静态元素。是第个参与者,例如车辆和行人,由 3D 坐标和语义标签定义。
静态场景生成:一种生成静态3D场景的直接方法是直接使用现有数据集中的真值占用数据,例如 nuScenes中的波士顿地区。然而,这种方法仅限于数据收集期间捕获的特定区域,限制了其对其他城市地区的适用性。为了解决这一限制,我们提出了一个占用扩散模型 OccDreamer,该模型以 BEV 地图和文本描述为条件,能够为任何所需的城市区域生成静态场景。OccDreamer 的框架集成了以下组件,如下图所示。
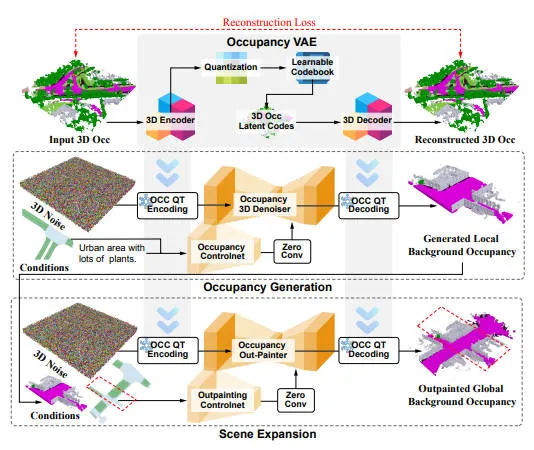
首先,为了高效地训练扩散模型,同时解决处理 3D 数据的计算复杂性,我们采用 VQVAE 作为占用标记器,将映射到潜在特征。重建的场景被定义为。使用组合损失进行训练。
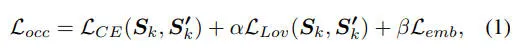
其次,考虑到不同的道路结构和复杂的区域地形,我们提出了一个可控的区域占用生成模块。它接受捕捉道路结构的区域 BEV 地图和描述抽象特征的语言提示(如植被丰富的郊区或两侧有建筑物的商业区)作为输入,并输出区域占用。遵循扩散模型的原理,CLIP 编码器将文本提示转换为embedding,记作。然后,通过交叉注意机制注入到降噪器中。同时,通过预训练图像 VAE处理 BEV图以提取相应的道路embedding,记作,作为 ControlNet 分支的输入。这可以精确控制潜在空间中的扩散学习过程:
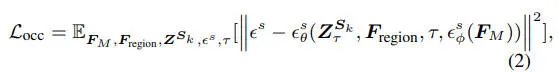
第三,为了实现整个 3D 场景的空间一致性,我们提出了一种场景扩展机制,用于构建连贯的城市级静态场景,其核心思路是扩展一个初始化的区域到相邻的区域通过使用这些区域之间的重叠作为条件约束。为了生成,我们首先创建一个部分掩码的场景。然后采用扩散过程生成邻近区域和部分掩码场景。整个扩散过程可以用采用下式进行表示。
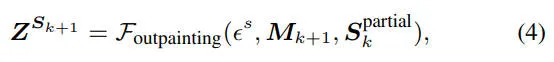
获得潜在表示后,我们使用占用 VAE 解码器对其进行解码,得到扩展区域,然后通过合并操作将两个区域组合成更大的场景
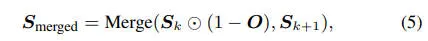
动态参与者选择:为了补充静态场景,我们在 4D 驾驶世界中填充了动态参与者,从而创建了逼真的交通流。我们构建了一个参与者库,根据与用户通过 CLIP 提供的描述的语义相似性来选择参与者,如果未指定,则从相关类别中随机抽样,以确保上下文多样性。这种灵活的选择过程允许在 4D 驾驶世界中动态地集成相关和多样化的参与者,支持现实和适应性强的交通模拟。
4D 世界构成:通过计算静态背景、动态前景参与者及其位置,我们将它们整合到综合 4D 驾驶世界中。任意时间 t 的世界状态由以下公式表示:
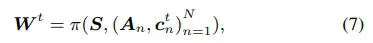
Visual Scene Synthesis
先前的生成模型倾向于采用 2D 视觉条件,无法准确捕捉现实世界驾驶场景中固有的几何和语义复杂性。因此,我们的视觉场景合成采用了 VideoDreamer,将上一步构建的占用驱动的 4D 驾驶世界转换为高保真视觉结果。整体框架如下图所示。
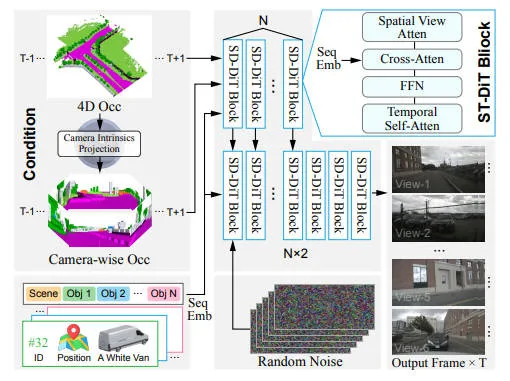
具体来说,我们引入了一种双路径条件编码策略,该策略专注于将占用数据编码为其主要条件。我们通过开发一种 ID 感知的参与者编码方法,进一步增强了视图和帧之间外观的一致性。最后,我们集成了 OpenSora 的时空扩散变换器 (ST-DiT) 作为基础技术,以确保视觉一致性并生成无伪影的帧。
双路径条件编码。我们设计了一种双路径条件编码策略,旨在有效地捕获占用数据。给定一组跨越从0到T帧的驾驶世界数据,我们首先将它们编码为全局特征,捕捉场景内的综合几何信息和时空关系。其中,是来自占用VAE 的训练好的 4D 编码器,负责捕捉场景的全局几何形状。这确保了场景的整体结构和空间布局得到准确呈现。同时,对于第帧的数据,3D占用数据根据每个视角相机的内参和外参映射到2D的语义图上,其转换公式如下
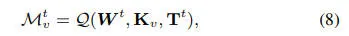
具备ID意识的参与者编码。为了确保场景中每个参与者的外观和ID信息的一致性,我们提取了一个融合序列嵌入如下
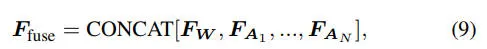
每一个参与者的embedding可以按照如下的公式进行定义
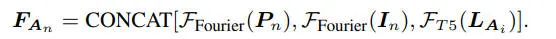
ControlNet-DiT:为了增强生成视频的视觉保真度和时间一致性,我们将 STDiT集成为我们的去噪器,利用堆叠有视图感知空间自注意力 (VSSA)、时间自注意力、交叉注意力和 FFN 的 ST-DiT 块。这种方法可确保对空间和时间连贯性的细粒度控制,从而生成无伪影的帧,满足自动驾驶模拟的高保真度要求。
Agent Interplay and Closed-Loop Simulation
我们实现了 DrivingSphere 模拟环境中自动驾驶代理的无缝协调,将代理分为两种主要类型:自车代理和环境代理。
自车代理:自车代理代表正在评估的自动驾驶系统。它由端到端模型驱动,接收视觉输入帧并每次输出预测的控制信号
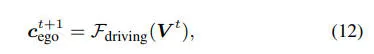
环境代理:环境代理负责控制模拟世界中所有其他参与者的行为和动作。为了实现真实的信息交换,我们使用支持多代理模拟的流量引擎。环境代理从模拟状态接收输入并输出控制信号,指示环境中参与者的移动和相互作用。整个过程可以描述如下
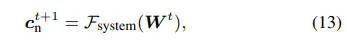
实验结果&评价指标
我们首先根据真实的 nuScenes 数据评估 OccDreamer 中基于体素的场景和 VideoDreamer 中的视频序列的保真度,以评估领域差距。
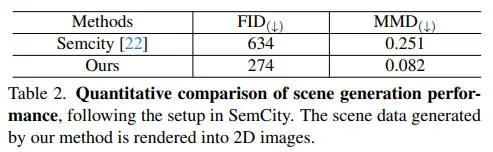
我们进行定量和定性分析,以评估 OccDreamer 生成的占用数据的保真度。我们的方法在定量上优于现有方法,如下表所示。
下图更加直观的展现了我们的方法在保持连贯性和保真度方面表现出了显著的优越性,远远优于其他方法。这一成功主要归功于几何感知占用编码和实例编码,它们确保了外观一致性,凸显了 VideoDreamer 在创建视觉一致、详细的驾驶环境以捕捉真实场景动态方面的稳健性。

开环实验结果
在开环设置中,自动驾驶代理被动接收环境输入而不影响模拟动态,我们评估了 UniAD 在 DrivingSphere 和其他仿真器上的性能,如下表所示。
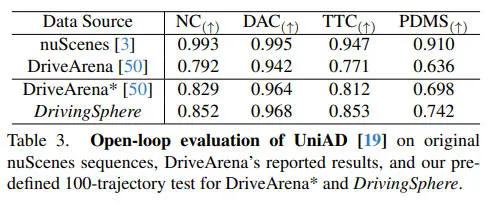
相关的实验结果展示了自动驾驶代理在 DrivingSphere 上取得的优异 PDMS分数,表明其更高的视觉保真度减少了可能误导代理决策的感知不准确性。这一改进凸显了 DrivingSphere 适用于在紧密模拟真实世界条件的环境中测试自动驾驶系统。
闭环实验结果
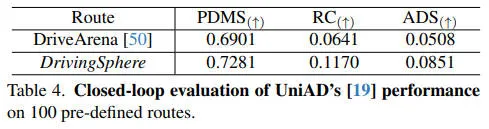
在闭环评估中,自动驾驶代理接收视觉输入和输出控制信号,从而以交互方式塑造模拟。此评估设置涉及 100 条预定义轨迹,用于在受控但多样的场景中进行测试。相关实验结果如下表所示,UniAD的路线完成度 (RC) 得分相对较低,平均每条路线的完成度仅为 11.7%。与 DriveArena相比,我们的模拟始终能获得更好的性能指标,并且还表现出卓越的视觉保真度。
结论
在本文中,我们提出了DrivingSphere,一个生成式闭环模拟框架,它弥补了传统闭环模拟和开环生成模型之间的差距。通过先进的基于占用的建模和可控的生成机制,DrivingSphere 为自动驾驶创建了逼真的高保真模拟。我们的实验展示了卓越的视觉质量、时间一致性以及在动态环境中有效测试自动驾驶算法的能力。
#蘑菇车联独家提供自动驾驶接驳服务
为世界互联网大会增添科技亮色
11月19日-22日,2024年世界互联网大会乌镇峰会在浙江桐乡举行。作为乌镇峰会的重头戏,2024年"互联网之光"博览会同期举办,车路云一体化作为连接智能网联汽车、通信、人工智能等核心技术的代表性产业,其规模化落地应用受到政府、行业以及企业的高度关注,成为本次大会的核心议题之一。
大会期间,近千家参会媒体肩负着传播大会精神和展示科技创新成果的重任。蘑菇车联为这些媒体提供的自动驾驶接驳服务,不仅为他们的参会行程带来了便利,更让他们亲身感受到了自动驾驶技术的魅力和潜力。此次负责接驳任务的自动驾驶巴士 MOGOBUS B2 无疑是整个服务的核心亮点。
MOGOBUS B2 搭载了蘑菇车联自研的 MOGO AP 自动驾驶系统,这一系统代表了蘑菇车联在自动驾驶领域的顶尖技术水平。它创新性地将高阶自动驾驶技术与车路云系统网络进行了深度融合,实现了实时感知、计算、决策能力的全面提升。在车辆行驶过程中,MOGO AP 自动驾驶系统通过多种传感器,如激光雷达、摄像头、毫米波雷达等,对周围环境进行全方位、高精度的感知。这些传感器如同车辆的 "眼睛" 和 "耳朵",实时获取道路信息、交通标志、其他车辆和行人的位置等关键数据。

基于这些丰富而精准的数据,MOGO AP 自动驾驶系统的计算单元迅速进行复杂的计算和分析,模拟不同行驶策略的风险和效益,并在瞬间做出最为合理的决策。例如,当遇到前方车辆突然减速或行人横穿马路时,系统能够根据实时感知到的信息,快速计算出最佳的避让路径和减速策略,确保车辆的行驶安全性。这种实时感知、计算和决策能力的紧密结合,使得 MOGOBUS B2 在各种复杂的交通场景下都能表现出色,全面提升了行驶安全性和效率。
值得一提的是,MOGOBUS B2 作为国内首款前装量产的 L4 级车路云一体化自动驾驶巴士,其在技术和应用方面的领先性不言而喻。L4 级自动驾驶意味着车辆在特定场景下能够实现高度自动化的驾驶,无需驾驶员进行干预。而车路云一体化的设计理念更是为这种自动驾驶能力提供了坚实的支撑。通过与路侧设施和云端平台的实时通信,MOGOBUS B2 能够获取更广泛的交通信息,进一步增强对周围环境的感知能力,从而更好地应对各种突发情况。

截至目前,MOGOBUS B2 已在北京、上海、天津、沈阳、鄂尔多斯、大理、青海等多地安全运营超 11 万公里。这一令人瞩目的运营成绩不仅证明了 MOGO AP 自动驾驶系统的可靠性和稳定性,也为其在未来的大规模推广应用积累了宝贵的实践经验。在不同城市的运营过程中,MOGOBUS B2 面临了各种各样的路况和交通环境挑战,从繁华都市的拥堵街道到高原地区的复杂地形,它都能顺利应对,为当地乘客提供安全、便捷的出行服务。

蘑菇车联在世界互联网大会上作为独家自动驾驶接驳服务商,不仅仅是一项简单的交通服务,更是对自动驾驶技术的一次生动展示和有力推广。它向全球参会者展示了自动驾驶技术在实际应用中的可行性和优势,为自动驾驶技术的未来发展营造了积极的舆论氛围。同时,这一服务也为行业内的技术交流和合作提供了契机,促进了自动驾驶技术的不断创新和进步。
随着科技的不断发展和社会对智能交通需求的日益增长,自动驾驶技术必将在未来交通领域发挥越来越重要的作用。蘑菇车联凭借其在自动驾驶接驳服务中的出色表现,已经在这一领域占据了重要的一席之地。相信在未来,蘑菇车联将继续加大技术研发投入,不断优化自动驾驶系统,拓展应用场景,为推动全球自动驾驶产业的发展做出更大的贡献。