人工智能学习-AI-MIT公开课-10. 学习介绍、最近邻
- 1-前言
- 2-课程链接
- 3-具体内容解释说明
- 一、这一节在课程中的位置(为什么突然讲"学习")
- 二、什么是「学习(Learning)」?
- [三、最近邻(Nearest Neighbor, NN)是什么?](#三、最近邻(Nearest Neighbor, NN)是什么?)
-
- [1️⃣ 一句话版定义(考试能直接用)](#1️⃣ 一句话版定义(考试能直接用))
- [2️⃣ 最近邻是怎么工作的?](#2️⃣ 最近邻是怎么工作的?)
- [3️⃣ 常见的距离定义(必考)](#3️⃣ 常见的距离定义(必考))
- 四、最近邻的优点与缺点(超高频)
-
- [✅ 优点](#✅ 优点)
- [❌ 缺点(考试重点)](#❌ 缺点(考试重点))
- [五、最近邻 vs 你前面学过的搜索](#五、最近邻 vs 你前面学过的搜索)
- 六、入试常见出题方式(你会怎么被问)
- 七、这一节的真正目的(老师没明说)
- 4-课后练习(日语版本)
- 5-课后答案解析(日语版本)
- 6-总结
1-前言
为了应对大学院考试,我们来学习相关人工智能相关知识,并且是基于相关课程。使用课程为MIT的公开课。
通过学习,也算是做笔记,让自己更理解些。
2-课程链接
是在B站看的视频,链接如下:
https://www.bilibili.com/video/BV1dM411U7qK?spm_id_from=333.788.videopod.episodes&vd_source=631b10b31b63df323bac39281ed4aff3&p=10
3-具体内容解释说明
这一节 「10. 学习介绍、最近邻」 ,在整门 AI 课程里的位置和意义非常关键。下面我按入试理解优先的方式给你讲清楚。
一、这一节在课程中的位置(为什么突然讲"学习")
你前面已经学过:
- 搜索(BFS、DFS、A*)
- 约束满足
- 视觉对象识别
👉 这些方法有一个共同点:
规则和模型是人"提前设计好的"。
而从这一节开始,课程进入一个新阶段:
让计算机"从数据中学会规则"
这就是 机器学习(Learning)。
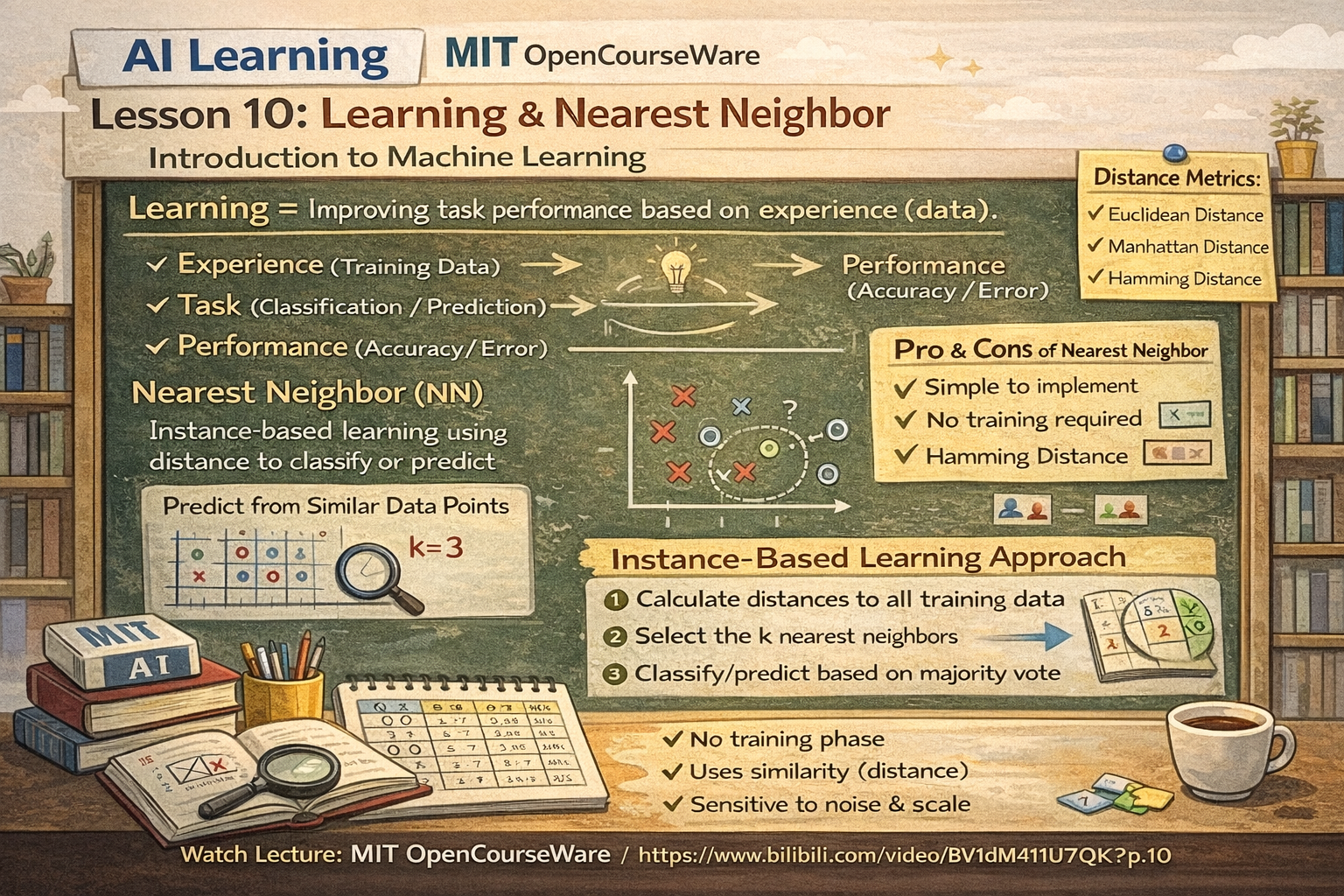
二、什么是「学习(Learning)」?
在 AI 里的定义(考试版):
学习是根据经验(数据),改善系统在任务上的性能的过程
拆开来看:
| 词 | 含义 |
|---|---|
| 经验 | 数据(训练样本) |
| 任务 | 分类、预测、识别 |
| 性能 | 准确率、误差 |
📌 重点:
不是写死规则,而是通过样本"归纳"规律
三、最近邻(Nearest Neighbor, NN)是什么?
1️⃣ 一句话版定义(考试能直接用)
最近邻法是一种基于实例的学习方法,根据与输入样本最相似的已知样本进行分类或预测
关键词一定要记住:
- 基于实例(instance-based)
- 相似度(距离)
- 不需要显式训练模型
2️⃣ 最近邻是怎么工作的?
假设:
- 已知一堆"已标注"的样本(点)
- 来了一个新样本
步骤:
- 计算新样本和所有训练样本的"距离"
- 找到距离最近的那个(或 k 个)
- 用它们的标签来决定新样本的类别
👉 没有训练过程,计算都发生在预测时
3️⃣ 常见的距离定义(必考)
| 距离 | 说明 |
|---|---|
| 欧几里得距离 | 连续数值特征 |
| 曼哈顿距离 | 网格/路径问题 |
| 汉明距离 | 离散/符号特征 |
📌 考试常问:
「距离的定义会影响分类结果」
四、最近邻的优点与缺点(超高频)
✅ 优点
- 算法非常简单
- 不需要训练
- 对复杂分布也能工作
❌ 缺点(考试重点)
- 计算量大(每次预测都要算)
- 对噪声敏感
- 对特征尺度敏感(需要归一化)
👉 常见判断题:
「最近邻法适合大规模数据集吗?」
❌ 不适合
五、最近邻 vs 你前面学过的搜索
这是老师故意放在这里讲的原因。
| 搜索 | 最近邻 |
|---|---|
| 在状态空间中找路径 | 在特征空间中找相似样本 |
| 明确目标状态 | 已知样本标签 |
| 有启发式函数 | 有距离函数 |
👉 你可以理解为:
最近邻 = 在特征空间做"最短距离搜索"
六、入试常见出题方式(你会怎么被问)
选择题
- 最近邻是否需要训练阶段?
- 距离定义改变会发生什么?
- 最近邻属于哪类学习方法?
简答题
- 说明最近邻法的优缺点
- 与决策树/神经网络的区别
七、这一节的真正目的(老师没明说)
老师想让你意识到:
学习 = 表示 + 距离 + 数据
后面的内容:
- 决策树
- 神经网络
- 遗传算法
都在回答同一个问题:
👉 怎么表示?怎么比较?怎么更新?
总结一句话(考试记忆版)
最近邻法是一种基于实例、利用距离度量进行分类的学习方法,不需要训练过程,但计算成本高、对噪声和尺度敏感。
4-课后练习(日语版本)
問題1(学習の定義)
人工知能における「学習(Learning)」の説明として最も適切なものはどれか。
A. 人があらかじめ与えた規則に従って問題を解く過程
B. 経験(データ)に基づいて、タスクに対する性能を向上させる過程
C. 探索空間をすべて列挙して最適解を求める方法
D. 問題ごとに評価関数を設計する手法
問題2(最近傍法の性質)
最近傍法(Nearest Neighbor)に関する説明として正しいものはどれか。
A. 明示的な学習(訓練)段階が必要である
B. 予測時にすべての訓練データとの距離計算を行う
C. ノイズに対して非常に頑健である
D. データ量が増えるほど計算量は減少する
問題3(距離尺度の影響)
最近傍法において、距離尺度の選択が分類結果に与える影響として最も適切なものはどれか。
A. 距離尺度を変更しても分類結果は常に同じである
B. 距離尺度は計算速度のみに影響し、結果には影響しない
C. 距離尺度の選択により、最近と判断されるデータが変わる場合がある
D. 距離尺度は学習済みモデルによって自動的に決定される
問題4(他手法との比較)
最近傍法と決定木やニューラルネットワークとの違いに関する説明として正しいものはどれか。
A. 最近傍法は学習データから明示的なモデルを構築する
B. 最近傍法はデータが少ないほど性能が必ず低下する
C. 最近傍法は予測時の計算量が比較的大きい
D. 最近傍法は特徴量の尺度に影響されない
5-课后答案解析(日语版本)
全問正解です。🎯
1:B / 2:B / 3:C / 4:C → 4/4 点
簡潔な確認(本番用の思考ルート)
-
問題1(学習の定義)
学習=データ(経験)に基づき性能を向上。規則固定や全探索ではない。
-
問題2(最近傍法)
訓練なし ・予測時に全データと距離計算。ノイズや大規模には不利。 -
問題3(距離尺度)
距離の定義が変われば**「近い」の判断が変わる**→結果も変わる。
-
問題4(他手法比較)
最近傍法は予測時コストが大。明示的モデルを作らない、尺度に敏感。
6-总结
知识一点点记录吧,最后应对考试,打下基础