自从GPDB闭源后,HashData接手举起了GPDB开源的大旗,由GPDB衍生而来的CloudberryDB于近期加入了Apache软件基金会孵化器,给GPDB开源社区带来了热度和活力。
昨天在CC群里看到GPDB中EXPLAIN ANALYZ比直接执行SQL慢的讨论。一般情况下,EXPLAIN ANALYZE由于不会向客户端输出元组,没有网络传输代价和IO转换代价(除非指定了SERIALIZE)所以比直接执行SQL快。但是EXPLAIN ANALYZE调用了gettimeofday()系统调用,在比较慢的机器上,这个代价就有点大了,可能会冲掉EXPLAIN ANALYZE上面省掉的动作节省的时间。在GPDB中还有另外一种场景导致EXPLAIN ANALYZE执行很慢:比如GPDB集群数据很不均衡,执行加了limit的SQL。
原因:在GPDB中执行explain analyze时,master执行了ExecutorRun后会等所有QE结束后才继续向下执行ExecutorEnd;而SQL正常执行时,一旦有的SEGMENT数据比较少执行的比较快,将数据发送给master后,master发现数据量够了,就会在ExecutorEnd中向SEGMENT发送消息,终止没有执行玩完的SEGMENT。
接下来,我们看下执行的流程,来充分理解下。
1、explain analyze流程

1)Explain analyze流程中,master执行ExecutorRun函数开始执行计划的执行
2)然后master就会通过函数cdbdisp_checkDispatchResult函数等待所有QE执行完。注意这里waitMode入参为DISPATCH_WAIT_NONE
3)2)中的执行函数指针为cdbdisp_checkDispatchResult_async,它调用函数checkDispatchResult,注意它的入参timeout_sec为-1
4)checkDispatchResult函数中当timeout_sec为-1,且waiMode为DISPATCH_WAIT_NONE时,poll的超时时间为DISPATCH_WAIT_TIMEOUT_MSEC。
5)checkDispatchResult函数的循环中,需要接收到所有QE完成后,才会退出循环
由此,了解到Explain analyze会等待所有QE完成。
2、SQL正常执行流程
SQL正常执行时,走的是执行器三部曲:ExecutorStart-ExecutorRun-ExecutorEnd
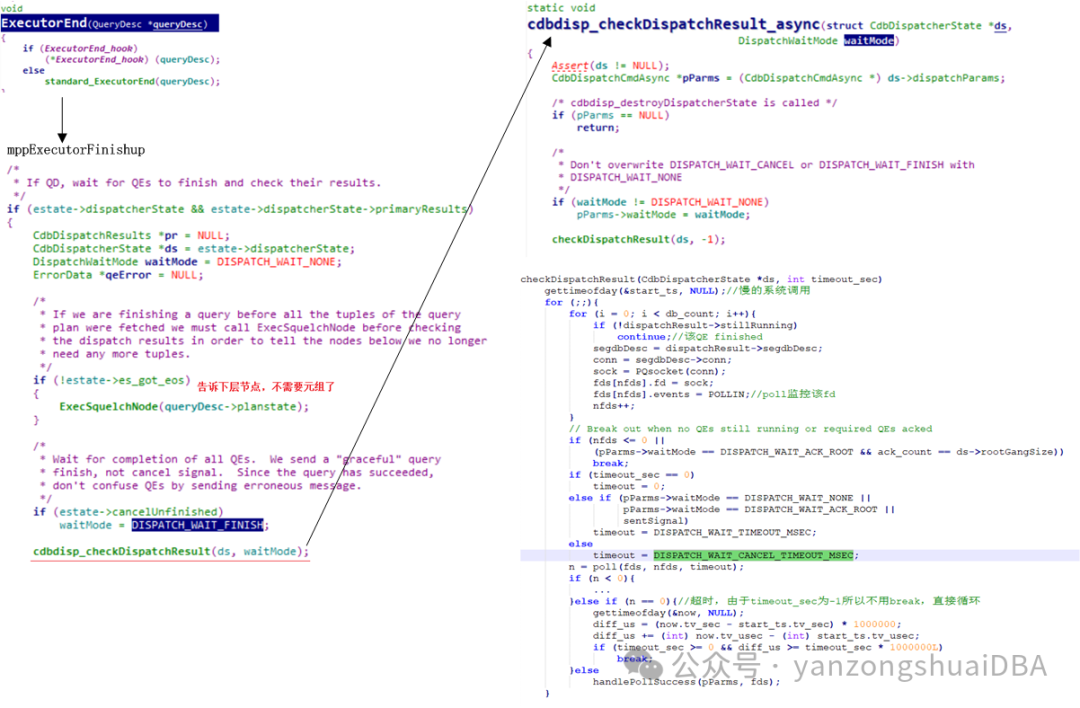
1)master不用等所有QE全部执行完,它得到需要行数的元组后,就可以执行到ExecutorEnd
2)ExecutorEnd通过ExecSquelchNode告诉子节点,通过ExecSquelchMotion通知QE不用执行了
3)Master然后进入checkDispatchResult等待QE反馈消息,注意他这里的timeout_sec为-1,waitMode为DISPATCH_WAIT_FINISH,由此poll的超时时间为DISPATCH_WAIT_CANCEL_TIMEOUT_MSEC
由此,正常执行时,master不用等待所有QE结束,它得到需要的行数后就可以进入ExecutorEnd,向QE发送终止执行命令,然后结束。
3、参考
https://www.postgresql.org/docs/current/using-explain.html#USING-EXPLAIN-ANALYZE