合理设计多列索引:
很多人对多列索引的理解都不够。一个常见的错误就是,为每个列创建独立的索引,或 者按照错误的顺序创建多列索引。 我们遇到的最容易引起困惑的问题就是索引列的顺序。正确的顺序依赖于使用该索引的 查询,并且同时需要考虑如何更好地满足排序和分组的需要。反复强调过,在一个多列 B-Tree索引中,索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列,等 等。所以,索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的ORDER BY、 GROUP BY和DISTINCT等子句的查询需求。 所以多列索引的列顺序至关重要。对于如何选择索引的列顺序有一个经验法则:将选择 性最高的列放到索引最前列。当不需要考虑排序和分组时,将选择性最高的列放在前面 通常是很好的。这时候索引的作用只是用于优化WHERE条件的查找。在这种情况下,这样 设计的索引确实能够最快地过滤出需要的行,对于在WHERE子句中只使用了索引部分前缀 列的查询来说选择性也更高。 然而,性能不只是依赖于索引列的选择性,也和查询条件的有关。可能需要根据那些运 行频率最高的查询来调整索引列的顺序,比如排序和分组,让这种情况下索引的选择性 最高。 同时,在优化性能的时候,可能需要使用相同的列但顺序不同的索引来满足不同类型的 查询需求。
尽可能设计三星索引
三星索引概念
对于一个查询而言,一个三星索引,可能是其最好的索引。
如果查询使用三星索引,一次查询通常只需要进行一次磁盘随机读以及一次窄索引片的 扫描,因此其相应时间通常比使用一个普通索引的响应时间少几个数量级。 三星索引概念是在《Rrelational Database Index Design and the optimizers》 一书 (这本书也是《高性能MySQL》作者强烈推荐的一本书)中提出来的。原文如下: The index earns one star if it places relevant rows adjacent to each other, a second star if its rows are sorted in the order the query needs, and a final star if it contains all the columns needed for the query. 索引将相关的记录放到一起则获得一星; 如果索引中的数据顺序和查找中的排列顺序一致则获得二星; 如果索引中的列包含了查询中需要的全部列则获得三星。 二星(排序星): 在满足一星的情况下,当查询需要排序,group by、 order by,如果查询所需的顺序与 索引是一致的(索引本身是有序的),是不是就可以不用再另外排序了,一般来说排序 可是影响性能的关键因素。 三星(宽索引星): 在满足了二星的情况下,如果索引中所包含了这个查询所需的所有列(包括 where 子句 和 select 子句中所需的列,也就是覆盖索引),这样一来,查询就不再需要回表了, 减少了查询的步骤和IO请求次数,性能几乎可以提升一倍。 一星按照原文稍微有点难以理解,其实它的意思就是:如果一个查询相关的索引行是相 邻的或者至少相距足够靠近的话,必须扫描的索引片宽度就会缩至最短,也就是说,让 索引片尽量变窄,也就是我们所说的索引的扫描范围越小越好。 这三颗星,哪颗最重要?第三颗星。因为将一个列排除在索引之外可能会导致很多磁盘 随机读(回表操作)。第一和第二颗星重要性差不多,可以理解为第三颗星比重是50%, 第一颗星为27%,第二颗星为23%,所以在大部分的情况下,会先考虑第一颗星,但会根 据业务情况调整这两颗星的优先度。
达成三星索引
现在有表 create table customer( cno int, lname varchar(10), fname varchar(10), sex int, weight int, city varchar(10));
建立索引 create index idx_cust on customer(city,lname,fname,cno); 对于下面的SQL而言,这是个三星索引 select cno,fname from customer where lname ='xx' and city ='yy' order by fname; 来评估下: 第一颗星:所有等值谓词的列,是组合索引的开头的列,可以把索引片缩得很窄,符 合。 第二颗星:order by的fname字段在组合索引中且是索引自动排序好的,符合。 第三颗星:select中的cno字段、fname字段在组合索引中存在,符合。
达不成三星索引
现在有表 CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_name` varchar(100) DEFAULT NULL, `sex` int(11) DEFAULT NULL, `age` int(11) DEFAULT NULL, `c_date` datetime DEFAULT NULL, PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8; SQL语句如下: select user_name,sex,age from test where user_name like 'test%' and sex =1 ORDER BY age 如果我们建立索引(user_name,sex,age): 第三颗星,满足 第一颗星,满足 第二颗星,不满足,user_name 采用了范围匹配,sex 是过滤列,此时age 列无法保证 有序的。 上述我们看到,此时索引(user_name,sex,age)并不能满足三星索引中的第二颗星(排 序)。 于是我们改改,建立索引(sex, age,user_name): 第一颗星,不满足,只可以匹配到sex,sex选择性很差,意味着是一个宽索引片, 第二颗星,满足,等值sex 的情况下,age是有序的, 第三颗星,满足,select查询的列都在索引列中,
对于索引(sex,age,user_name)我们可以看到,此时无法满足第一颗星,窄索引片的需 求。 以上2个索引,都是无法同时满足三星索引设计中的三个需求的,我们只能尽力满足2 个。而在多数情况下,能够满足2颗星,已经能缩小很大的查询范围了,具体最终要保留 那一颗星(排序星 or 窄索引片星),这个就需要看查询者自己的着重点了,无法给出 标准答案。
主键尽量是很少改变的列
我们知道,行是按照聚集索引物理排序的,如果主键频繁改变(update),物理顺序会改 变,MySQL要不断调整B+树,并且中间可能会产生页面的分裂和合并等等,会导致性能会 急剧降低。
处理冗余和重复索引
MySQL允许在相同列上创建多个索引,无论是有意的还是无意的。MySQL需要单独维护重 复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能。重复 索引是指在相同的列上按照相同的顺序创建的相同类型的索引。应该避免这样创建重复 索引,发现以后也应该立即移除。 有时会在不经意间创建了重复索引,例如下面的代码: CREATE TABLE test ( ID INT NOT NULL PRIMARY KEY, A INT NOT NULL, B INT NOT NULL, UNIQUE(ID), INDEX(ID) ) ENGINE=InnoDB; 这里创建了一个主键,又加上唯一限制,然后再加上索引以供查询使用。事实上,MySQL 的唯一限制和主键限制都是通过索引实现的,因此,上面的写法实际上在相同的列上创 建了三个重复的索引。通常并没有理由这样做,除非是在同一列上创建不同类型的索引 来满足不同的查询需求。 冗余索引和重复索引有一些不同。如果创建了索引(A B),再创建索引(A)就是冗余索 引,因为这只是前一个索引的前缀索引。因此索引(AB)也可以当作索引(A)来使用(这种 冗余只是对B-Tree索引来说的)。但是如果再创建索引 (B,A),则不是冗余索引,索引 (B)也不是,因为B不是索引(A,B)的最左前缀列。 已有的索引(A),扩展为(A,ID),其中ID是主键,对于InnoDB来说主键列已经包含在二 级索引中了,所以这也是冗余的。
解决冗余索引和重复索引的方法很简单,删除这些索引就可以,但首先要做的是找出这 样的索引。可以通过写一些复杂的访问INFORMATION_SCHEMA表的查询来找。
删除未使用的索引
除了冗余索引和重复索引,可能还会有一些服务器永远不用的索引。这样的索引完全是 累赘,建议考虑删除。
补充资料:磁盘和B+树
为什么关系型数据库都选择了B+树,这个和磁盘的特性有着非常大的关系。
 一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同步转动)。在磁 盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不 能转动,但是可以沿磁盘半径方向运动。 盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁 道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁 盘的最小存储单元也是最小读写单元。现在磁盘扇区一般是512个字节~4k个字节。 磁盘上数据必须用一个三维地址唯一标示:柱面号、盘面号、扇区号。 读/写磁盘上某一指定数据需要下面步骤: (1) 首先移动臂根据柱面号使磁头移动到所需要的柱面上,这一过程被称为定位或查找。 (2)所有磁头都定位到磁道上后,这时根据盘面号来确定指定盘面上的具体磁道。 (3) 盘面确定以后,盘片开始旋转,将指定块号的磁道段移动至磁头下。 经过上面步骤,指定数据的存储位置就被找到。这时就可以开始读/写操作了。
一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同步转动)。在磁 盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不 能转动,但是可以沿磁盘半径方向运动。 盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁 道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁 盘的最小存储单元也是最小读写单元。现在磁盘扇区一般是512个字节~4k个字节。 磁盘上数据必须用一个三维地址唯一标示:柱面号、盘面号、扇区号。 读/写磁盘上某一指定数据需要下面步骤: (1) 首先移动臂根据柱面号使磁头移动到所需要的柱面上,这一过程被称为定位或查找。 (2)所有磁头都定位到磁道上后,这时根据盘面号来确定指定盘面上的具体磁道。 (3) 盘面确定以后,盘片开始旋转,将指定块号的磁道段移动至磁头下。 经过上面步骤,指定数据的存储位置就被找到。这时就可以开始读/写操作了。

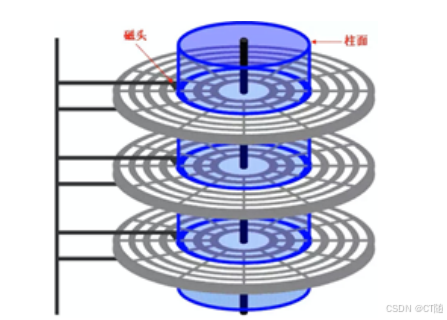 可以看见,磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三 个部分耗时相加就是一次磁盘IO的时间,一般大概9ms左右。寻道时间(seek)是将读写磁头 移动至正确的磁道上所需要的时间,这部分时间代价最高;旋转延迟时间(rotation)是磁盘 旋转将目标扇区移动到读写磁头下方所需的时间,取决于磁盘转速;数据传输时间 (transfer)是完成传输数据所需要的时间,取决于接口的数据传输率,在纳秒级,远小于前 两部分消耗时间。磁盘读取时间成本是访问内存的几百倍到几万倍之间。 为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每 次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据 放入内存,这个称之为预读。这样做的理论依据是计算机科学中著名的局部性原理:
可以看见,磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三 个部分耗时相加就是一次磁盘IO的时间,一般大概9ms左右。寻道时间(seek)是将读写磁头 移动至正确的磁道上所需要的时间,这部分时间代价最高;旋转延迟时间(rotation)是磁盘 旋转将目标扇区移动到读写磁头下方所需的时间,取决于磁盘转速;数据传输时间 (transfer)是完成传输数据所需要的时间,取决于接口的数据传输率,在纳秒级,远小于前 两部分消耗时间。磁盘读取时间成本是访问内存的几百倍到几万倍之间。 为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每 次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据 放入内存,这个称之为预读。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。 程序运行期间所需要的数据通常比较集中
大家可以试运行下面这段代码: public static void main(String\[\] args) { int\[\]\[\] arr = new int1000010000; int sum = 0; long startTime = System.currentTimeMillis(); for (int i = 0; i < arr.length; i++) { for (int j = 0; j < arr0.length; j++) { /*按行访问数组*/ sum += arrij; }
} System.out.println("按行耗时:" + (System.currentTimeMillis() - startTime) + "ms"); sum = 0; startTime = System.currentTimeMillis(); for (int i = 0; i < arr.length; i++) { for (int j = 0; j < arr0.length; j++) { /*按列访问数组*/ sum += arrji; } } System.out.println("按列耗时:" + (System.currentTimeMillis() - startTime) + "ms"); }