第一章 Trino 简介
1. Trino 概述
Trino是一个分布式SQL查询引擎,旨在查询分布在一个或多个异构数据源上的大型数据集。如果使用的是数TB或数PB的数据,那么很可能使用的是与Hadoop和HDFS交互的工具。Trino被设计为使用MapReduce作业管道(如Hive或Pig)查询HDFS的工具的替代品,但Trino并不局限于访问HDFS。Trino可以而且已经扩展到对不同类型的数据源进行操作,包括传统的关系数据库和其他数据源,如Cassandra。
Trino旨在处理数据仓库和分析:数据分析,汇总大量数据并生成报告。这些工作负载通常被归类为联机分析处理(OLAP)。
**说明:**不要误解Trino理解SQL的事实,因为它提供了标准数据库的功能。Trino不是一个通用的关系数据库。它不能取代MySQL、PostgreSQL或Oracle等数据库。Trino不是为处理在线事务处理(OLTP)而设计的。对于为数据仓库或分析而设计和优化的许多其他数据库也是如此。
2. Trino架构
Trino是一个分布式查询引擎,可跨多个服务器并行处理数据。Trino服务器有两种类型,协调器(coordinators)和工作节点(workers)。以下部分介绍了这些服务器和Trino体系结构的其他组件。
Trino集群由一个coordinator和多个worker组成。用户通过SQL工具与coordinator连接。协调员与工人合作。coordinator管理workers。通过配置catalogs,coordinator 和 the workers访问已连接的数据源。
每个查询的执行都是状态操作,coordinator编排工作负载,它会将任务调度到workers中并行执行。每个Trino都运行在JVM实例中,并通过使用线程进一步将任务并行化。
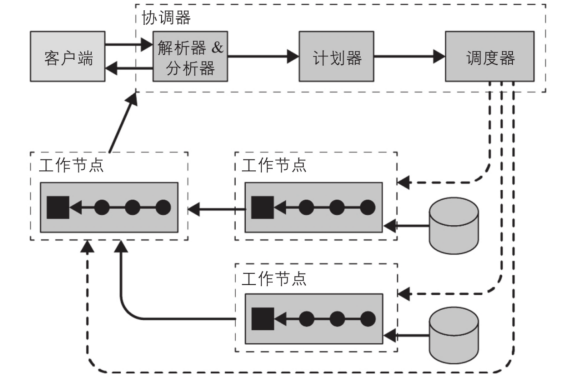
用户使用客户端工具(如JDBC驱动或Trino CLI)连接到集群中的协调器,然后协调器(coordinator)就可以协调工作节点(worker)访问数据源。
协调器(coordinator)是一类处理用户查询请求并管理工作节点执行查询工作的服务器。工作节点(worker)是一类负责执行任务和处理数据的服务器。
协调器(coordinator)通常会运行一个节点发现服务,工作节点(worker)通过注册到该服务来加入集群。客户端、协调器(coordinator)和工作节点(worker)之间所有的通信和数据传输,都通过基于HTTP/HTTPS的REST服务交互。
第二章 Trino安装
1. Trino环境要求
Linux操作系统:64位
Java运行时环境: Jdk21以及以上版本
Python版本: 2.6.x、2.7.x 或 3.x
2. Trino部署
Trino 服务器可以安装和部署在许多不同的服务器上平台。用户通常部署由一个具有一个协调器和多个工作节点的集群。Trino支持如何部署方式:
(1) 部署Trino
(2) Docker容器中的Trino
(3) Trino on Kubernetes with Helm
(4) RPM包
下文介绍RPM包的部署方式。
1、下载 Trino 的RPM 软件包
Trino Server 436下载地址 :
https://repo1.maven.org/maven2/io/trino/trino-server-rpm/436/trino-server-rpm-436.rpm
Trino Cli 436下载地址:
https://repo1.maven.org/maven2/io/trino/trino-cli/436/trino-cli-436-executable.jar
2、使用命令安装软件包:rpm
rpm -ivh trino-server-rpm-436.rpm --nodeps
3、启动服务
service trino start ;
安装后可以使用service命令管理Trino服务器:
service trino start\|stop\|restart\|status
|---------|---------------------------------------|
| 命令 | 动作 |
| start | 将服务器作为守护程序启动,并返回其进程 ID。 |
| stop | 关闭以 或 开头的服务器。发送 SIGTERM 信号。 |
| restart | 停止然后启动正在运行的服务器,或启动已停止的服务器, 分配新的进程 ID。 |
| status | 打印状态行,即"已停止 pid"或"作为 pid 运行"。 |
4、验证服务是否正常
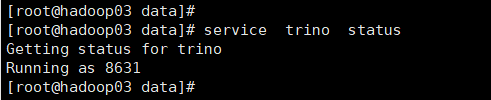
(1)在服务器上执行service trino status,看到Running as XXX说明服务启动成功。
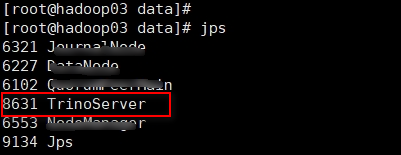
(2)在服务器上执行jps,如果看到TrinoServer的进程说明启动成功。
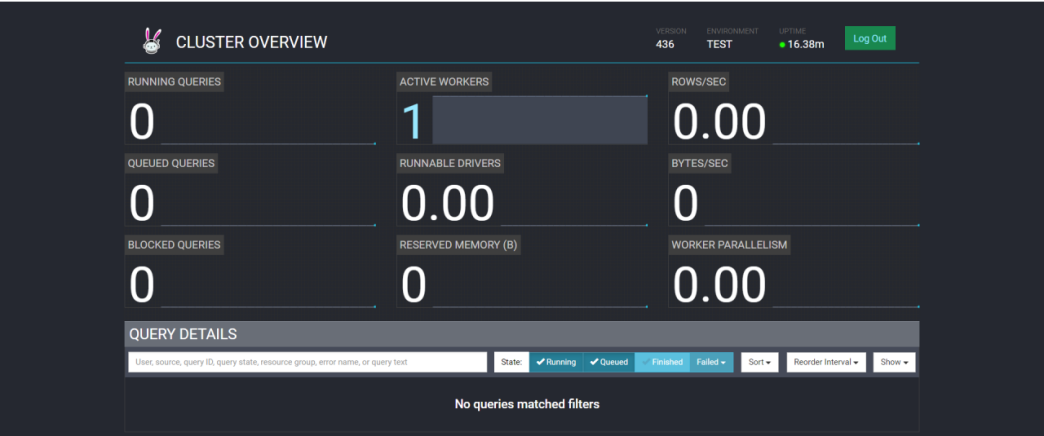
(3)在浏览器中输入:http://ip:8080,如果出现登录页面,随意输入用户root,登录可以看到如下页面。
5、安装Trino客户端
下载之后将trino-cli-436-executable.jar改成trino-cli,并给trino-cli添加可执行权限
mv trino-cli-436-executable.jar trino-cli
chmod +x trino-cli
./trino-cli --server localhost:8080
3. Trino目录结构
(1) /usr/lib/trino/lib/:包含运行产品所需的各种库。插件位于插件子目录中。
(2) /etc/trino:包含一般的trino配置文件,如node.properties、jvm.config、config.properties。目录配置位于目录子目录中。
(3) /etc/trino/env.sh:包含trino使用的Java安装路径,允许配置进程环境变量,包括secrets。
(4) /var/log/trino:包含日志文件。
(5) /var/lib/trino/data:数据目录的位置。Trino在此处存储日志和其他数据。
(6) /etc/rc.d/init.d/trino:包含用于控制服务器进程的服务脚本以及文件路径的启动器配置。
第三章 Trino连接器
1. MySQL连接器
MySQL连接器允许在外部MySQL实例中查询和创建表。这可以用于连接不同系统(如MySQL和Hive)之间的数据,或两个不同MySQL实例之间的数据。
1.1. 要求
(1) MySQL 5.7、8.0 或更高版本。
(2) 从 Trino 协调器和工作线程到 MySQL 的网络访问。 端口 3306 是默认端口。
1.2. 配置
在/etc/trino/catalog中创建一个example.properties的属性文件。
cd /etc/trino/catalog
vi mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://192.168.80.131:3306
connection-user=root
connection-password=Root@1234
这里主机要使用IP地址,不要使用主机名。
1.3. 登录客户端
(1)重启trino服务
service trino stop ; service trino start ;
或者
service trino restart ;
(2)登录客户端命令
./trino-cli --server localhost:8080
或者连接trino时可以设置默认的catalog(某个连接实例)和schema(数据库),这样可以直接查询表。
./trino-cli http://localhost:8080/mysql/test
说明:mysql为catalog中配置的connector.name,test为需要连接的数据库名称。
1.4. 操作MySQL
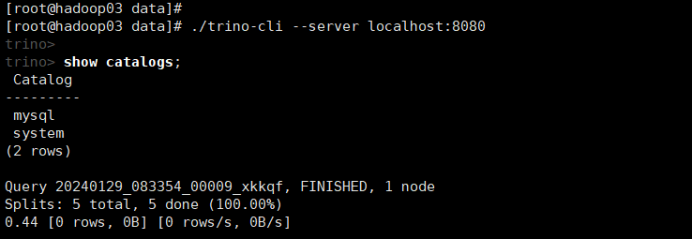
(1)显示所有的catalog (catalog目录下的properties文件名)
show catalogs;
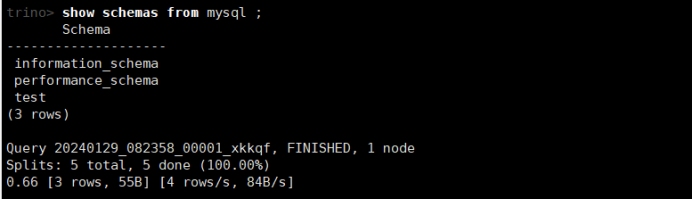
(2)查看mysql下所有的schemas (对应为数据库)
show schemas from mysql;
如果连接失败,可以查看日志/var/log/trino/server.log
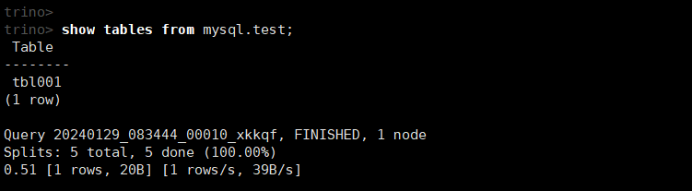
(3)查看数据库中的所有表
show tables from mysql.test;
(4)查询表数据
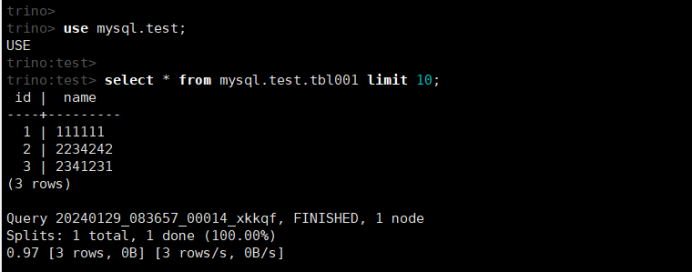
use mysql.test;
select * from mysql.test.tbl001 limit 10;
(5)插入数据
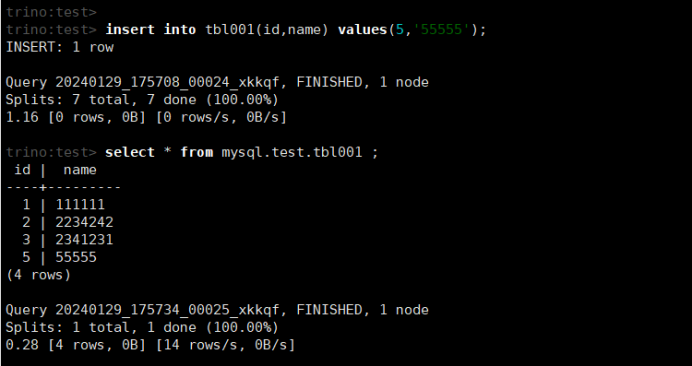
insert into tbl001(id,name) values(5,'55555');
select * from mysql.test.tbl001;
(5)修改数据
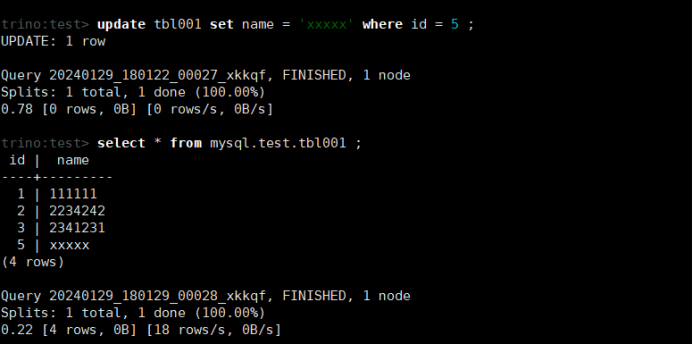
update tbl001 set name = 'xxxxx' where id = 5 ;
select * from mysql.test.tbl001 ;
(6)删除数据
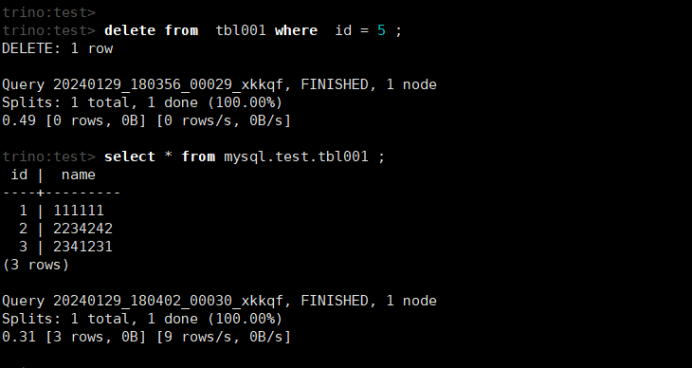
delete from tbl001 where id = 5 ;
select * from mysql.test.tbl001;
(7)查看表结构和建表语句
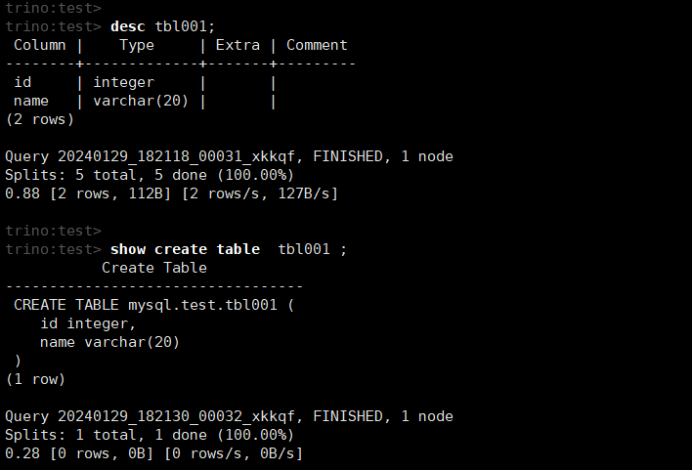
desc tbl001;
show create table tbl001 ;
(8)退出客户端
quit; 或者exit;
补充内容:
(9) 通过trino-cli直接执行SQL(使用--execute选项)
./trino-cli http://localhost:8080/mysql/test --execute 'select * from mysql.test.tbl001'

./trino-cli http://localhost:8080 --execute 'use mysql.test ; select * from mysql.test.tbl001'

(10) 通过trino-cli执行SQL文件(-f选项)
vi mysql_test.sql
use mysql.test;
select * from tbl001;
执行SQL文件:./trino-cli http://localhost:8080 -f mysql_test.sql

2. PostgreSQL连接器
PostgreSQL连接器允许在外部PostgreSQL数据库中查询和创建表。这可以用于连接不同系统(如PostgreSQL和Hive)之间的数据,或不同PostgreSQL实例之间的数据。
2.1. 要求
(1) PostgreSQL 11.x或更高版本。
(2) Trino协调员(coordinator)和工作节点(workers )对PostgreSQL的网络访问。默认端口是5432。
2.2. 配置
在/etc/trino/catalog中创建一个example.properties的属性文件。
cd /etc/trino/catalog
vi postgresql.properties
connector.name=postgresql
connection-url=jdbc:postgresql://192.168.80.131:5432/bdc01
connection-user=postgres
connection-password=postgres
这里主机要使用IP地址,不要使用主机名。
2.3. 登录客户端
重启trino服务:
service trino stop ; service trino start ;
或者
service trino restart ;
登录客户端命令:
./trino-cli --server localhost:8080
2.4. 操作PostgreSQL
(1)显示所有的catalog (catalog目录下的properties文件名)
show catalogs;
(2)查看postgresql下所有的schemas (对应为数据库)
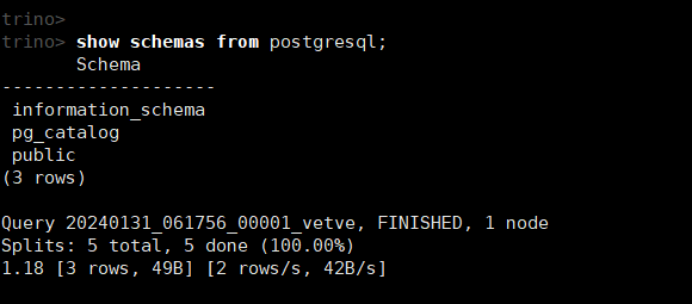
show schemas from postgresql;
如果连接失败,可以查看日志/var/log/trino/server.log
(3)查看数据库中的所有表
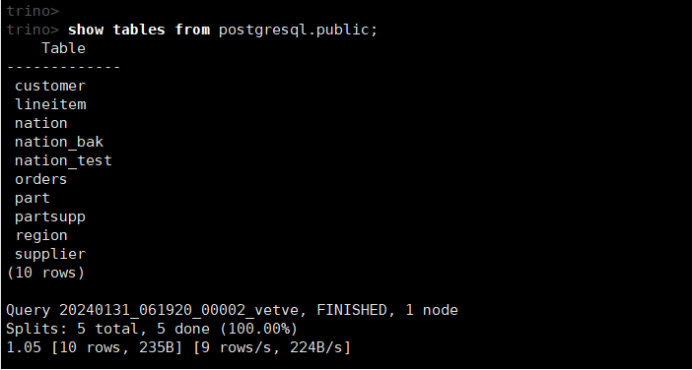
show tables from postgresql.public;
(4)查询表数据
use postgresql.public;
select * from postgresql.public.nation_test order by n_nationkey ;
(5)插入数据
insert into nation_test(n_nationkey,n_name,n_regionkey) values(99,'XXXXX',3);
select * from nation_test order by n_nationkey ;
(6)修改数据
update nation_test set n_name = 'YYYYY' where n_nationkey = 99 ;
select * from nation_test order by n_nationkey ;
(7)删除数据
delete from nation_test where n_nationkey = 99 ;
select * from nation_test order by n_nationkey ;
(8)查看表结构和建表语句
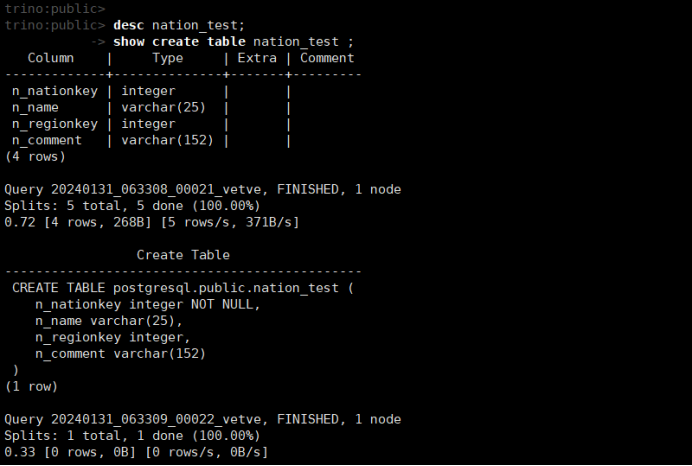
desc nation_test;
或者 show columns from nation_test ;
show create table nation_test ;
(9)退出客户端
quit; 或者exit;
3. Oracle连接器
Oracle连接器允许在外部Oracle数据库中查询和创建表。连接器允许Trino连接不同数据库(如Oracle和Hive)或不同Oracle数据库实例提供的数据。
3.1. 要求
(1) Oracle 19或更高版本。
(2) Trino协调员(coordinator)和工作节点(workers )对Oracle的网络访问。默认端口是1521。
3.2. 配置
在/etc/trino/catalog中创建一个example.properties的属性文件。
cd /etc/trino/catalog
vi oracle.properties
connector.name=oracle
connection-url=jdbc:oracle:thin:@192.168.80.134:1521/orclpdb1
connection-user=dsjzx
connection-password=Dsjzx123
这里主机要使用IP地址,不要使用主机名。
这里连接使用的是服务名orclpdb1,不是SID。
3.3. 登录客户端
重启trino服务:
service trino stop ; service trino start ;
或者
service trino restart ;
登录客户端命令:
./trino-cli --server localhost:8080
3.4. 操作Oracle
(1)显示所有的catalog (catalog目录下的properties文件名)
show catalogs;
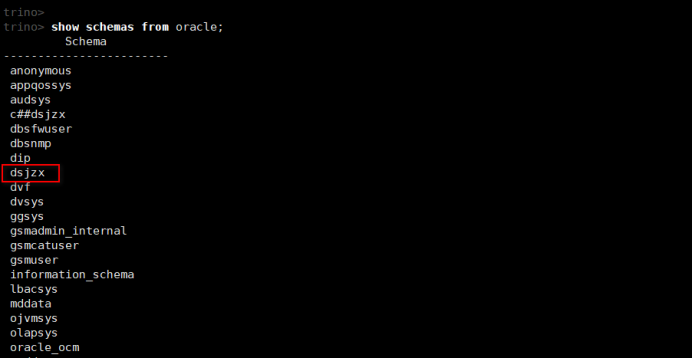
(2)查看oracle下所有的schemas (对应为用户)
show schemas from oracle;
如果连接失败,可以查看日志/var/log/trino/server.log
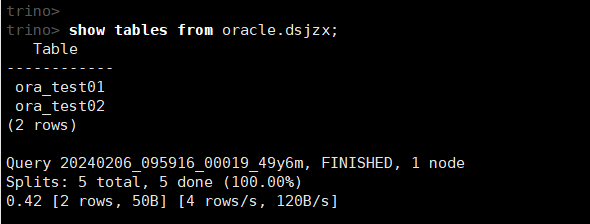
(3)查看数据库中的所有表
show tables from oracle.dsjzx;
(4)查询表数据
use oracle.dsjzx;
select * from oracle.dsjzx.ora_test01;
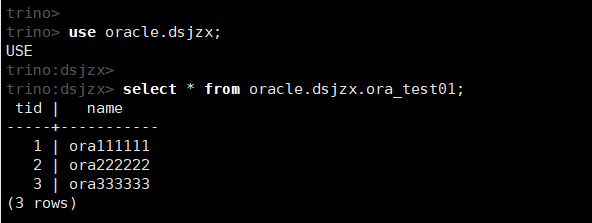
说明:在Oracle中使用Number字段类型时,必须指定精度,即NUMBER(p)或者NUMBER(p, s)。否则该字段在Tirno中无法识别。
(5)插入数据
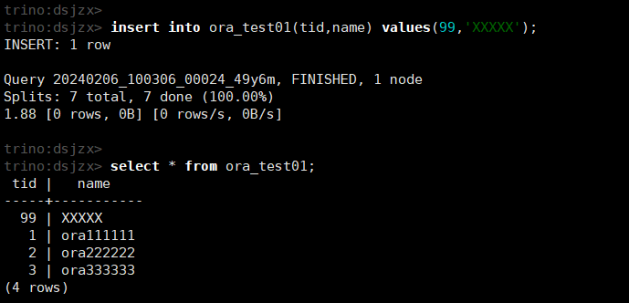
insert into ora_test01(tid,name) values(99,'XXXXX');
select * from ora_test01;
(6)修改数据
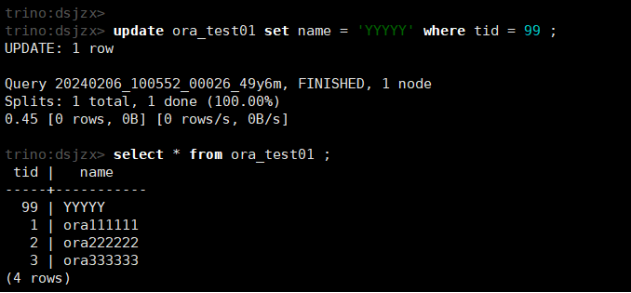
update ora_test01 set name = 'YYYYY' where tid = 99 ;
select * from ora_test01 ;
(7)删除数据
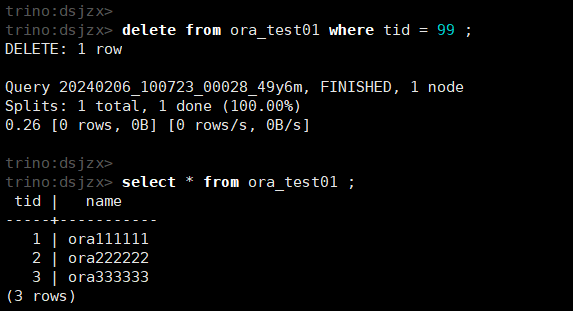
delete from ora_test01 where tid = 99 ;
select * from ora_test01 ;
(8)查看表结构和建表语句
desc ora_test01;
或者 show columns from ora_test01 ;
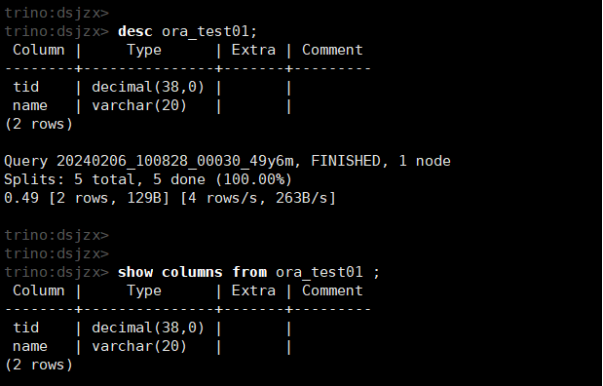
show create table ora_test01;
(9)退出客户端
quit; 或者exit;
4. Kafka连接器
Kafka连接器允许使用Apache Kafka主题作为Trino中的表。每条消息在Trino中显示为一行。
主题可以是实时的,当行在数据到达时显示,在数据段被丢弃时消失。如果在一个查询中多次访问同一个表(例如:自联接),这可能会导致奇怪的行为。
Kafka连接器跨Workers并行地读取和写入来自Kafka主题的消息数据,以实现显著的性能提升。这种并行化的数据集大小是可配置的,因此可以根据特定需求进行调整。
4.1. 要求
(1) Kafka broker 版本 0.10.0 或更高版本。
(2) 从 Trino 协调器(coordinator)和工作节点(Worker)到 Kafka 节点的网络访问。 默认端口是9092。
4.2. 配置
在/etc/trino/catalog中创建一个example.properties的属性文件。
cd /etc/trino/catalog
vi kafka.properties
connector.name=kafka
kafka.table-names=mytest
kafka.nodes=hadoop01:9092,hadoop02:9092,hadoop03:9092
kafka.table-description-dir=/etc/trino/kafka
#kafka.hide-internal-columns=false
说明:
(1)kafka.table-description-dir=/etc/trino/kafka :kafka的主题文件目录指定,需要配置参数。其中包含一个或多个JSON文件(必须以.json结尾),其中包含表描述文件。
(2)kafka.hide-internal-columns=false :用于显示Kakfa隐藏的内部列名。默认值为true,不显示Kafka隐藏的内部列名。
4.3. 登录客户端
重启trino服务:
service trino stop ; service trino start ;
或者
service trino restart ;
登录客户端命令:
./trino-cli --server localhost:8080
4.4. 操作Kafka
(1)显示所有的catalog (catalog目录下的properties文件名)
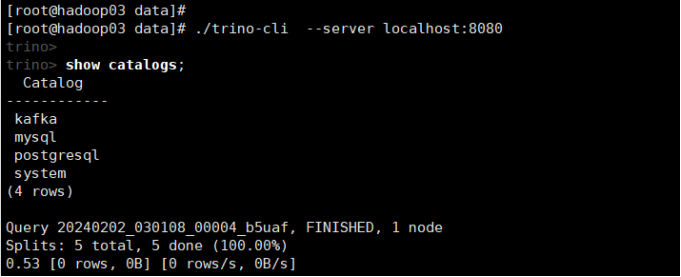
show catalogs
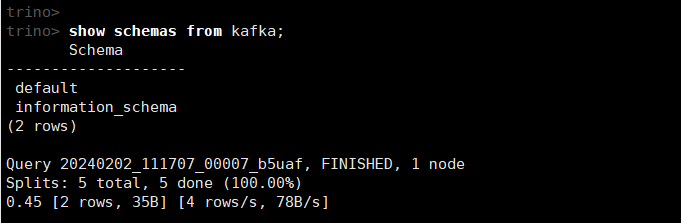
(2)查看kafka下所有的schemas
show schemas from kafka;
(3)查看kafka中的所有topic
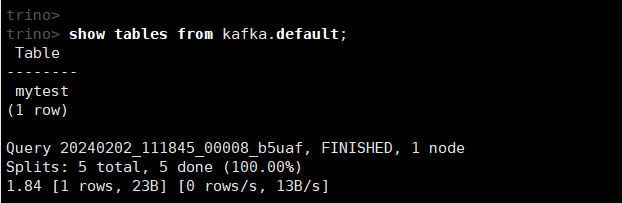
show tables from kafka.default;
(4)查看topic的信息
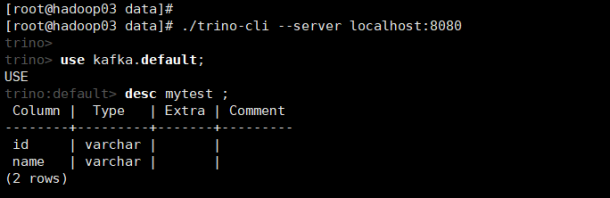
use kafka.default;
desc mytest ;
(5)查询Topic数据
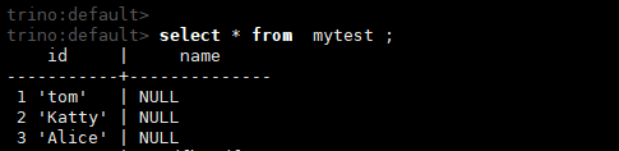
select * from mytest ;
(6)将Topic中的值映射到Trino的列
编辑表信息的json文件。
vi /etc/trino/kafka/default.mytest.json
{
"tableName": "mytest",
"schemaName": "default",
"topicName": "mytest",
"message": {
"dataFormat": "csv",
"fields": [
{
"name": "id",
"mapping": "0",
"type": "VARCHAR"
},
{
"name": "name",
"mapping": "1",
"type": "VARCHAR"
}
]
}
}
然后重启Trino服务。
service trino restart ;
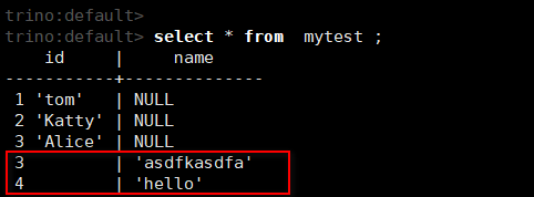
接着通过生产者向topic写入csv格式的数据,以逗号作为分隔符。
bin/kafka-console-producer.sh --broker-list hadoop01:9092 --topic mytest

最后查询topic中的数据。
插入数据(暂时未验证通过)
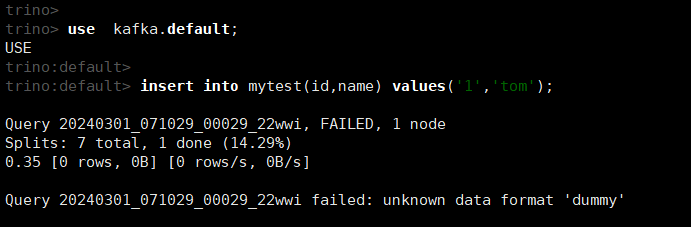
insert into mytest(id,name) values('1','tom');
5. Hive连接器
Hive 连接器允许查询存储在 Apache Hive 数据仓库中的数据。
Hive是三个组件的组合:
(1) 不同格式的数据文件,通常存储在Hadoop分布式文件系统(HDFS)或AmazonS3等对象存储系统中。
(2) 关于如何将数据文件映射到架构和表的元数据。这些元数据存储在数据库中,如MySQL,并通过Hive元存储服务进行访问。
(3) 一种称为HiveQL的查询语言。这种查询语言是在分布式计算框架(如MapReduce或Tez)上执行的。
Trino只使用前两个组件:数据和元数据。它不使用HiveQL或Hive执行环境的任何部分。
5.1. 要求
(1) Hive 连接器需要 Hive 元存储服务 (HMS) 或兼容的实现 Hive 元存储,例如 AWS Glue。
(2) 支持Apache Hadoop HDFS 2.x和3.x。
(3) 数据文件必须采用受支持的格式:ORC、Parquet、Avro、RCText (RCFile using ColumnarSerDe)、RCBinary (RCFile using LazyBinaryColumnarSerDe)、SequenceFile、JSON (using org.apache.hive.hcatalog.data.JsonSerDe)、CSV (using org.apache.hadoop.hive.serde2.OpenCSVSerde)、TextFile。
5.2. 配置
在/etc/trino/catalog中创建一个example.properties的属性文件。
cd /etc/trino/catalog
vi hive.properties
connector.name=hive
hive.metastore.uri=thrift://192.168.80.131:9083
hive.config.resources=/etc/trino/hadoop/core-site.xml,/etc/trino/hadoop/hdfs-site.xml
这里主机要使用IP地址,不要使用主机名。
5.3. Hive准备数据
!connect jdbc:hive2://192.168.80.131:10000
use default;
create table tbl001(id bigint, name string);
insert into tbl001(id,name) values(1,'111111'),(2,'222222'),(3,'333333');
select * from tbl001;
5.4. 登录客户端
重启trino服务:
service trino stop ; service trino start ;
或者
service trino restart ;
登录客户端命令:
./trino-cli --server localhost:8080
5.5. 操作Hive
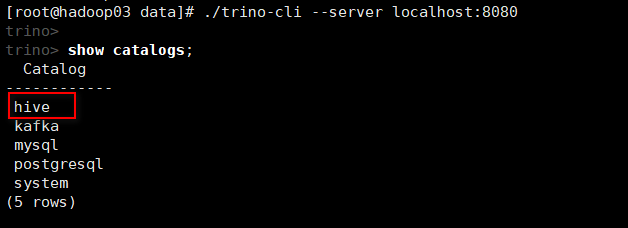
(1)显示所有的catalog (catalog目录下的properties文件名)
show catalogs;
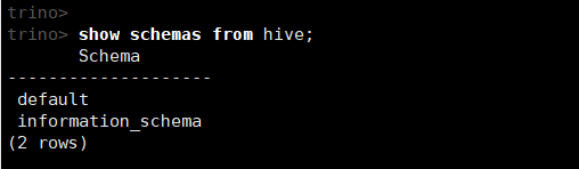
(2)查看hive下所有的schemas (对应为数据库)
show schemas from hive;
如果连接失败,可以查看日志/var/log/trino/server.log
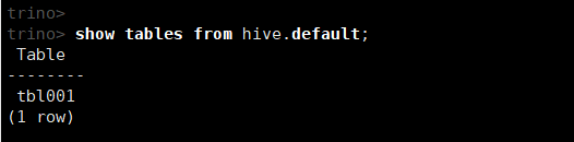
(3)查看数据库中的所有表
show tables from hive.default;
(4)查看表结构
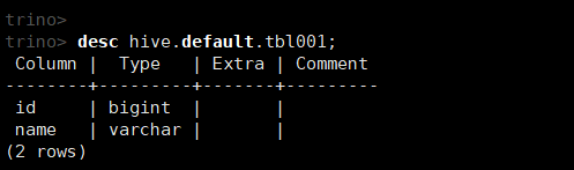
desc hive.default.tbl001;
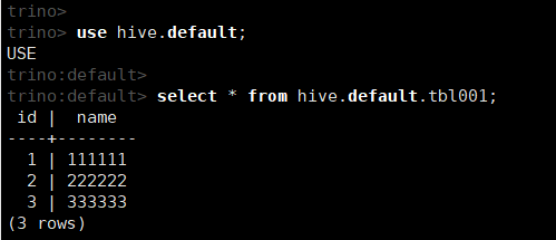
(5)查看表的数据
use hive.default;
select * from hive.default.tbl001;
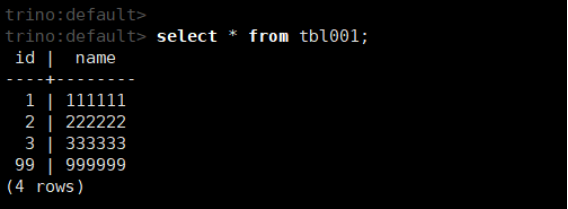
(6)插入数据
insert into tbl001 values(99,'999999');

select * from tbl001;
(7)修改表的数据
update tbl001 set name = 'XXXXXXX' where id = 99 ;

提示说明:只有Hive事务表支持修改表的行。
在Hive中创建事务表,并导入数据
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1;
create table trans_tbl001(
id bigint,
name string
)
clustered by (id) into 2 buckets
stored as orc
TBLPROPERTIES('transactional'='true');
insert into trans_tbl001(id,name) values(1,'111111');
insert into trans_tbl001(id,name) values(2,'222222');
insert into trans_tbl001(id,name) values(3,'333333');
insert into trans_tbl001(id,name) values(99,'999999');
通过trino客户端查询数据
select * from trans_tbl001 ;
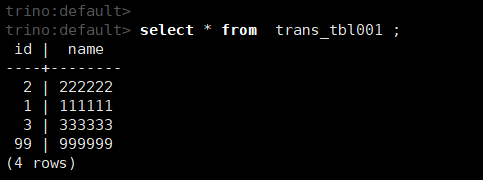
通过trino客户端修改数据
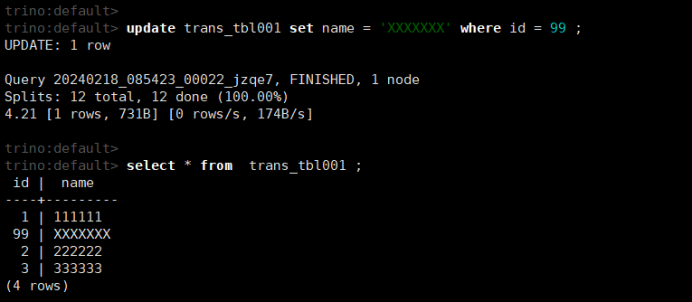
update trans_tbl001 set name = 'XXXXXXX' where id = 99 ;
select * from trans_tbl001 ;
(8)删除表的数据
delete from tbl001 where id = 99 ;

提示说明:只有Hive事务表支持修改表的行。
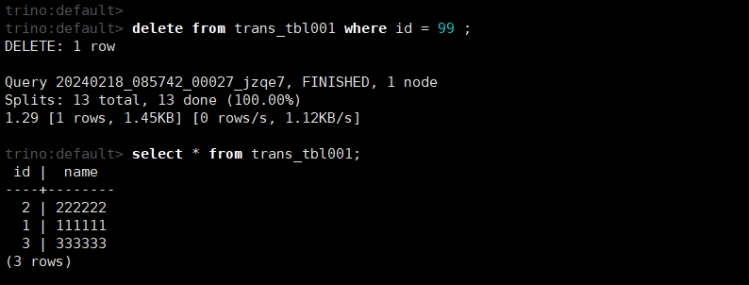
delete from trans_tbl001 where id = 99 ;
select * from trans_tbl001 ;
(9)查询建表语句
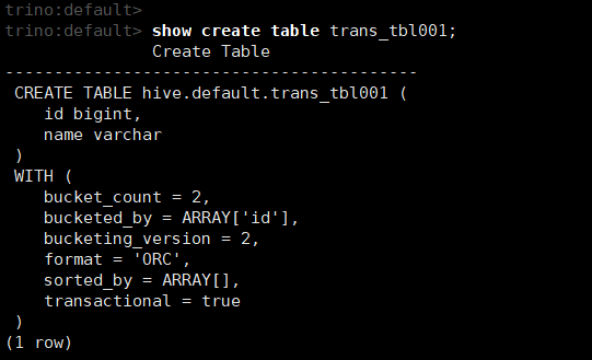
show create table trans_tbl001;
6. Hudi连接器
Hudi 连接器支持查询 Hudi 表,暂不支持插入、修改、删除操作。
6.1. 要求
(1) Hudi版本0.12.3或更高版本。
(2) Trino协调员(coordinator)和工作节点(workers )对对Hudi存储的网络访问。
(3) 访问Hive元存储服务(HMS)。
(4) Trino协调员(coordinator)到HMS的网络接入。
(5) 以Parquet文件格式存储在支持的文件系统中的数据文件。
6.2. 配置
在/etc/trino/catalog中创建一个example.properties的属性文件。
cd /etc/trino/catalog
vi hudi.properties
connector.name=hudi
hive.metastore.uri=thrift://192.168.80.131:9083
这里主机要使用IP地址,不要使用主机名。
6.3. Hudi准备数据
(1)Hudi与Spark集成(省略)
(2)启动Spark-sql
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
(3)创建Hudi表
create database hudi_db;
use hudi_db;
create table hudi_mor_tbl (
id int,
name string,
price double,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
);
(4)导入数据
insert into hudi_mor_tbl select 99, 'a99', 20.0, 900;
6.4. 登录客户端
重启trino服务:
service trino stop ; service trino start ;
或者
service trino restart ;
登录客户端命令:
./trino-cli --server localhost:8080
6.5. 操作Hudi
(1)显示所有的catalog (catalog目录下的properties文件名)
show catalogs;
(2)查看hudi下所有的schemas (对应为数据库)
show schemas from hudi;
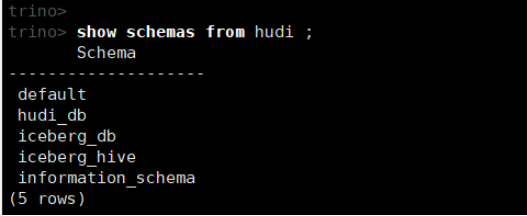
如果连接失败,可以查看日志/var/log/trino/server.log
(3)查看数据库中的所有表
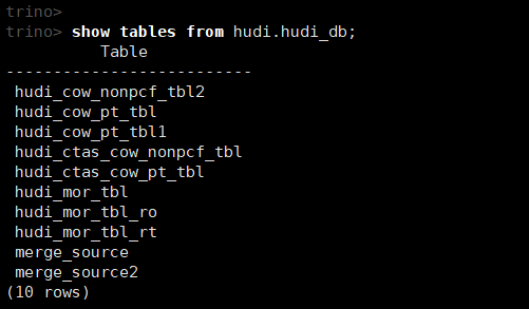
show tables from hudi.hudi_db;
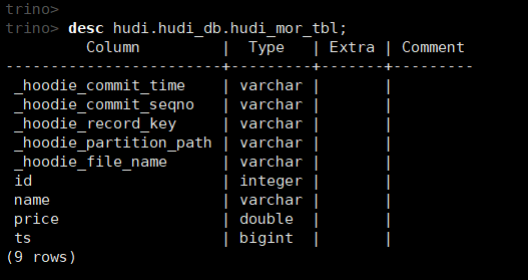
(10)查看表结构
desc hudi.hudi_db.hudi_mor_tbl;
(11)查看表的数据
use hudi.hudi_db;
select * from hudi_mor_tbl;

(12)查看元数据表
select * from "hudi_mor_tbl$timeline" ;
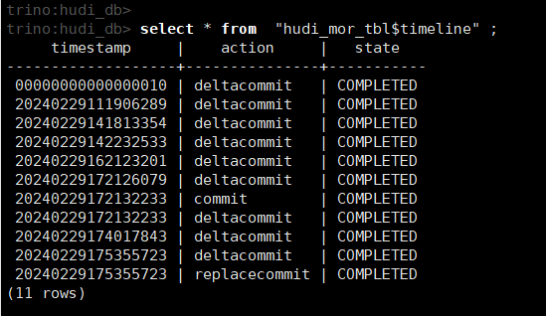
Hudi连接器为每个Hudi表公开一个元数据表。元数据表包含有关Hudi表的内部结构的信息。可以通过将元数据表名称附加到表名称上来查询每个元数据表:select * from "test_table$timeline"。
(13)Hudi连接器暂不支持insert、update、delete操作
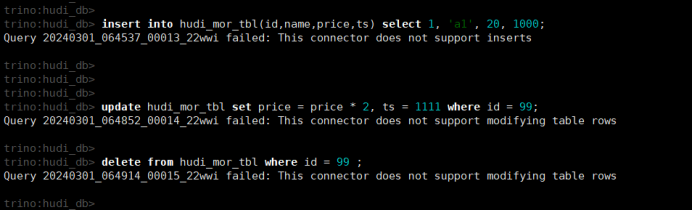
7. Iceberg连接器
Apache Iceberg是一种用于大型分析数据集的开放表格式。Iceberg连接器允许查询以Iceberg格式编写的文件中存储的数据,如Iceberg表规范中所定义的。
7.1. 要求
(1) Trino协调员(coordinator)和工作节点(workers )对分布式对象存储的网络访问。
(2) 访问Hive元存储服务(HMS)、AWS Glue目录、JDBC目录、REST目录或Nessie服务器。
(3) 在支持的文件系统上,以文件格式ORC或Parquet(默认)存储的数据文件。
7.2. 配置
在/etc/trino/catalog中创建一个example.properties的属性文件。
cd /etc/trino/catalog
vi iceberg.properties
connector.name=iceberg
iceberg.catalog.type=hive_metastore
hive.metastore.uri=thrift://192.168.80.131:9083
这里主机要使用IP地址,不要使用主机名。
7.3. Iceberg准备数据
##登录hive客户端
hive
##创建数据库
create database iceberg_db ;
use iceberg_db;
##创建Iceberg表
SET iceberg.catalog.iceberg_hive.type=hive;
SET iceberg.catalog.iceberg_hive.uri=thrift://192.168.80.131:9083;
SET iceberg.catalog.iceberg_hive.clients=10;
SET iceberg.catalog.iceberg_hive.warehouse=hdfs://192.168.80.131:8020/data/warehouse/iceberg-hive;
CREATE TABLE iceberg_test001 (
id int,
name string,
birthday date,
create_time timestamp
)
PARTITIONED BY(provincial string,ds string)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES('iceberg.catalog'='iceberg_hive');
##插入数据
INSERT INTO iceberg_test001 values
(10001, 'a10001', '2020-01-01', current_timestamp(),'99999999','20240226'),
(10002, 'a10002', '2012-04-18', current_timestamp(),'99999999','20240226'),
(10003, 'a10003', '2015-11-03', current_timestamp(),'99999999','20240226'),
(10004, 'a10004', '2013-08-27', current_timestamp(),'99999999','20240226');
##查询数据
select * from iceberg_test001 ;
7.4. 登录客户端
重启trino服务:
service trino stop ; service trino start ;
或者
service trino restart ;
登录客户端命令:
./trino-cli --server localhost:8080
7.5. 操作Iceberg
7.5.1. Trino自建表的操作
(1)显示所有的catalog (catalog目录下的properties文件名)
show catalogs;
(2)创建SCHEMA
CREATE SCHEMA iceberg.iceberg_hive
WITH (location='hdfs://192.168.80.131:8020/data/warehouse/iceberg-hive/');

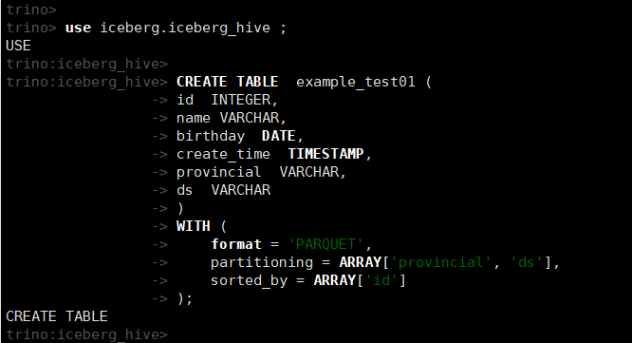
(3)创建表
use iceberg.iceberg_hive ;
CREATE TABLE example_test01 (
id INTEGER,
name VARCHAR,
birthday DATE,
create_time TIMESTAMP,
provincial VARCHAR,
ds VARCHAR
)
WITH (
format = 'PARQUET',
partitioning = ARRAY'provincial', 'ds',
sorted_by = ARRAY'id'
);
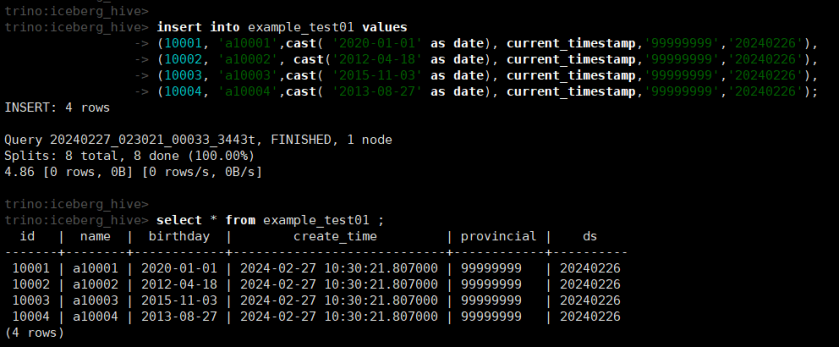
(4)插入数据
insert into example_test01 values
(10001, 'a10001',cast( '2020-01-01' as date), current_timestamp,'99999999','20240226'),
(10002, 'a10002', cast('2012-04-18' as date), current_timestamp,'99999999','20240226'),
(10003, 'a10003',cast( '2015-11-03' as date), current_timestamp,'99999999','20240226'),
(10004, 'a10004',cast( '2013-08-27' as date), current_timestamp,'99999999','20240226');
select * from example_test01 ;
(5)修改数据
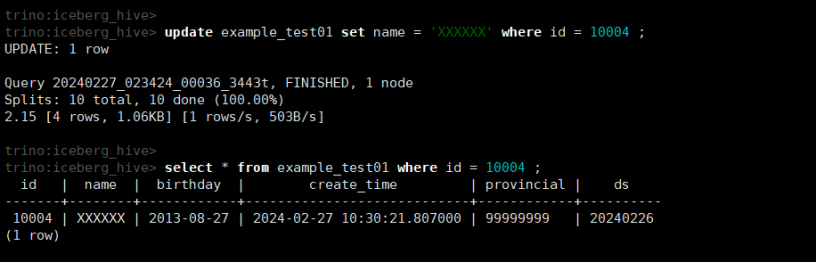
update example_test01 set name = 'XXXXXX' where id = 10004 ;
select * from example_test01 where id = 10004 ;
(6)删除数据
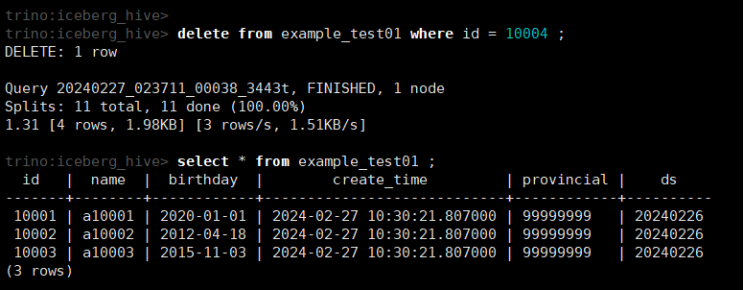
delete from example_test01 where id = 10004 ;
select * from example_test01 ;
(7)查看所有的表
show tables;
(8)查看表结构和建表语句
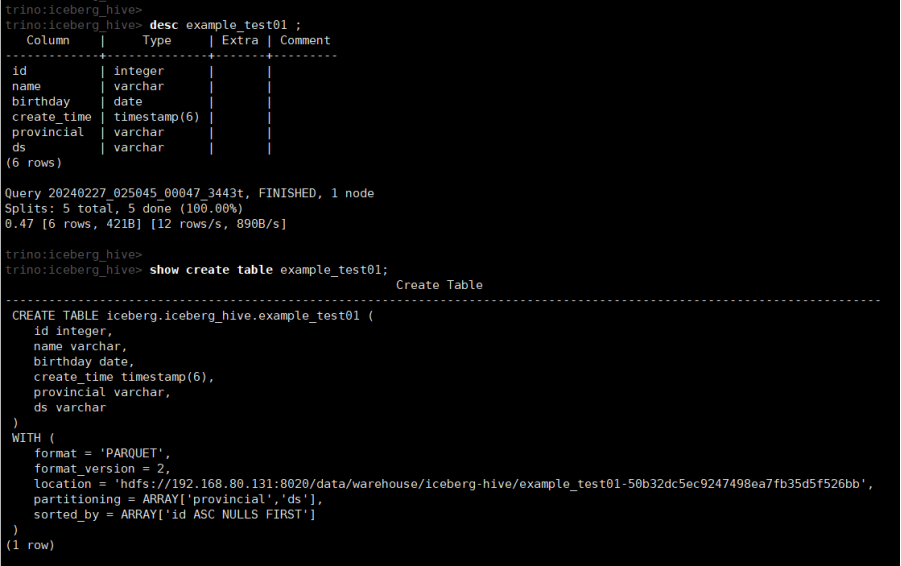
desc example_test01 ;
show create table example_test01;
测试在hive中是否可以读取该表的数据
select * from example_test01 ;
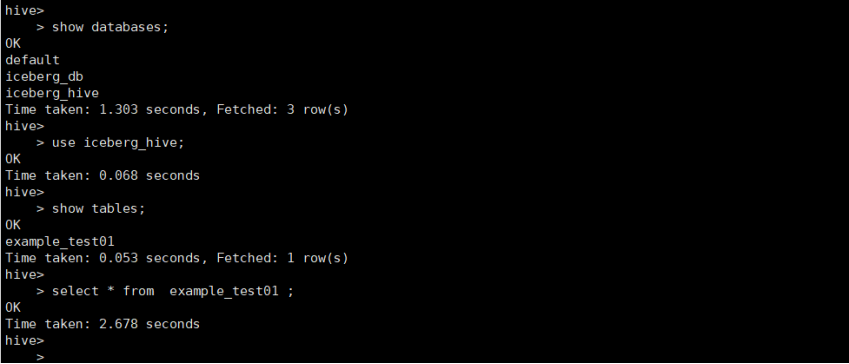
从中可以看到,通过Trino创建的表,在Hive中无法查询。
为什么?
Trino和Hive创建Iceberg表的序列化规则(ROW FORMAT SERDE)和存储格式(STORED BY)不同。
--通过Trino创建生成的Iceberg表:
CREATE EXTERNAL TABLE `example_test01`(
`id` int,
`name` string,
`birthday` date,
`create_time` timestamp,
`provincial` string,
`ds` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.FileInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.mapred.FileOutputFormat'
LOCATION 'hdfs://192.168.80.131:8020/data/warehouse/iceberg-hive/example_test01-50b32dc5ec9247498ea7fb35d5f526bb'
TBLPROPERTIES (
'metadata_location'='hdfs://192.168.80.131:8020/data/warehouse/iceberg-hive/example_test01-50b32dc5ec9247498ea7fb35d5f526bb/metadata/00004-cad950c2-57be-4550-9add-c363c70ef484.metadata.json',
'previous_metadata_location'='hdfs://192.168.80.131:8020/data/warehouse/iceberg-hive/example_test01-50b32dc5ec9247498ea7fb35d5f526bb/metadata/00003-a6d3f156-0f4a-4450-a70b-d02bb1a75e97.metadata.json',
'table_type'='ICEBERG',
'transient_lastDdlTime'='1709000455');
--通过Hive创建的Iceberg表
CREATE TABLE `iceberg_test001`(
`id` int COMMENT 'from deserializer',
`name` string COMMENT 'from deserializer',
`birthday` date COMMENT 'from deserializer',
`create_time` timestamp COMMENT 'from deserializer',
`provincial` string COMMENT 'from deserializer',
`ds` string COMMENT 'from deserializer')
ROW FORMAT SERDE 'org.apache.iceberg.mr.hive.HiveIcebergSerDe'
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://bdc01/user/hive/warehouse/iceberg_db.db/iceberg_test001'
TBLPROPERTIES (
'bucketing_version'='2',
'current-schema'='{"type":"struct","schema-id":0,"fields":{"id":1,"name":"id","required":false,"type":"int"},{"id":2,"name":"name","required":false,"type":"string"},{"id":3,"name":"birthday","required":false,"type":"date"},{"id":4,"name":"create_time","required":false,"type":"timestamp"},{"id":5,"name":"provincial","required":false,"type":"string"},{"id":6,"name":"ds","required":false,"type":"string"}}',
'current-snapshot-id'='2017496957845643908',
'current-snapshot-summary'='{"added-data-files":"1","added-records":"4","added-files-size":"1953","changed-partition-count":"1","total-records":"4","total-files-size":"1953","total-data-files":"1","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0"}',
'current-snapshot-timestamp-ms'='1708941864398',
'default-partition-spec'='{"spec-id":0,"fields":{"name":"provincial","transform":"identity","source-id":5,"field-id":1000},{"name":"ds","transform":"identity","source-id":6,"field-id":1001}}',
'engine.hive.enabled'='true',
'external.table.purge'='TRUE',
'iceberg.catalog'='iceberg_hive',
'last_modified_by'='root',
'last_modified_time'='1708941860',
'metadata_location'='hdfs://bdc01/user/hive/warehouse/iceberg_db.db/iceberg_test001/metadata/00001-29819742-3acb-46c0-8234-d16a350f132e.metadata.json',
'previous_metadata_location'='hdfs://bdc01/user/hive/warehouse/iceberg_db.db/iceberg_test001/metadata/00000-4cf17717-07ae-44c2-9079-9b2c8f3e2503.metadata.json',
'snapshot-count'='1',
'table_type'='ICEBERG',
'transient_lastDdlTime'='1708941860',
'uuid'='164870ac-489f-4434-a34c-3ed50340ed34')
7.5.2. 已存在Iceberg表的操作
(1)查看iceberg下所有的schemas (对应为数据库)
show schemas from iceberg;
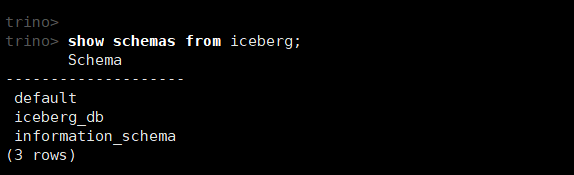
如果连接失败,可以查看日志/var/log/trino/server.log
(2)查看数据库中的所有表
show tables from iceberg.iceberg_db;
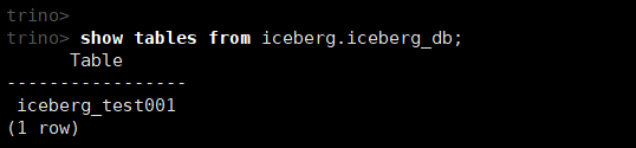
(3)查看表结构
desc iceberg.iceberg_db.iceberg_test001;

通过Hive创建的Iceberg表,在Trino中无法访问。为什么?
第四章 功能验证
1. 跨源关联计算
./trino-cli --server localhost:8080
--查询表数据
select * from mysql.test.tbl001
select * from postgresql.public.test001 ;
select * from kafka.default.mytest ;
select * from hive.default.tbl001;
select * from iceberg.iceberg_hive.example_test01;
--MySQL和postgreSQL关联
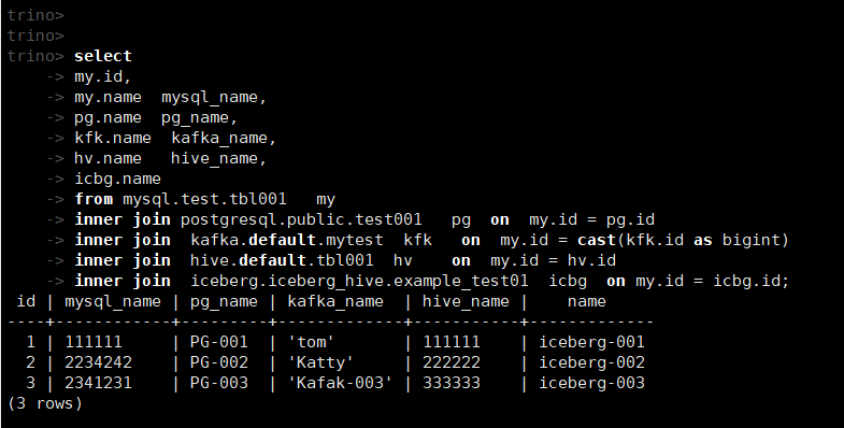
select
my.name mysql_name,
pg.name pg_name,
kfk.name kafka_name,
hv.name hive_name,
icbg.name iceberg_name
from mysql.test.tbl001 my
inner join postgresql.public.test001 pg on my.id = pg.id
inner join kafka.default.mytest kfk on my.id = cast(kfk.id as bigint)
inner join hive.default.tbl001 hv on my.id = hv.id
inner join iceberg.iceberg_hive.example_test01 icbg on my.id = icbg.id;