一、介绍selenium爬虫工具
selenium 是一个自动化测试工具,可以用来进行 web 自动化测试、爬虫
selenium 本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
相对于普通的爬虫工具:request、scrapy,selenium 了解决它们无法直接执行 JavaScript 代码等问题
下面就来介绍下 selenium 基础用法
二、前期安装配置工作
1、下载浏览器驱动器的网址
#Firefox浏览器驱动: https://github.com/mozilla/geckodriver/releases #Chrome浏览器驱动: #【114版本之前的】 https://registry.npmmirror.com/binary.html?path=chromedriver/ #【115版本之后的】 https://googlechromelabs.github.io/chrome-for-testing/ #IE浏览器驱动:IEDriverServer https://selenium-release.storage.googleapis.com/index.html #Edge浏览器驱动:MicrosoftWebDriver https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver?form=MA13LH
2、例子:
【谷歌浏览器】
1、查找浏览器版本
;
2、我的是115版本以上的,所以对应到谷歌第二个驱动器安装网站
找到对应的版本,然后复制跳转它给的网址链接,就能自动下载了




【Microsoft Edge】
这个浏览器不需要看版本,直接进入驱动器安装网址之后,点下面图片的位置即可

3、配置浏览器驱动器
安装完成之后我们要解压压缩包才能用
第一种配置,这里我们可以直接解压到python编译器的安装主目录下**(不推荐,写代码麻烦)**
记得是把含有exe程序的那一层根目录解压下来,别多套一层目录了



第二种配置,我们可以直接配到系统环境变量里,全局使用**(推荐,写代码方便)**
往path里添加你驱动器的【根目录】
测试【谷歌驱动器】的命令是
pythonchromedriver --version #或者 chromedriver -v;
测试【Edge驱动器】的命令是
pythonmsedgedriver --version #或者 msedgedriver -v



4、安装
打开Python编译器的命令行程序,运行下面 pip 命令::
pythonpip install selenium如果安装不了,可能是网络问题,可以指定使用国内的清华大学源
pythonpip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
三、 启用浏览器驱动器打开网站
现在配置完毕,我们就可以写代码来试一下启动了
1、创建驱动器其对象
首先seleium的导入头文件
python
from selenium import webdriver如果你没有配置系统变量,只是单纯解压了,那么你在写代码时创建浏览器驱动器,就需要手动导入你驱动器的exe程序文件的路径
;
用【webdriver.浏览器()】方法来创建驱动器的对象,然后假如参数【service=Service(去驱动器exe的路径)】(Service对象需要导入头文件)
pythonfrom selenium import webdriver from selenium.webdriver.chrome.service import Service # 如果只是解压了驱动器,那么这里要启动驱动器就得手动把各个驱动器的.exe文件的路径,写到Service参数里 # 谷歌浏览器的驱动器对象 ChromeDriver = webdriver.Chrome(service=Service(r'F:\python\chromedriver-win64\chromedriver.exe')) # Edge浏览器的驱动器对象 EdgeDriver = webdriver.Edge(service=Service(r'F:\python\edgedriver_win64\msedgedriver.exe'))
如果你已经配置好系统变量,检查无误,那么就可以直接用【webdriver.浏览器()】方法来创建驱动器的对象
pythonfrom selenium import webdriver # 如果驱动器已经注册到环境变量Path里了,那么就不需要写路径了,selenium会自动全局找到驱动器的位置 # 谷歌浏览器的驱动器对象 ChromeDriver = webdriver.Chrome() # Edge浏览器的驱动器对象 EdgeDriver = webdriver.Edge()
2、用驱动器打开一个网址
【驱动器对象.get( 网址 )】就能打开一个浏览器并进入到这个网址页面了
不过注意,用一个浏览器的驱动器打开就行,别一次性用多种浏览器打开
还有,selenium默认执行完脚本就自动结束,就会马上关闭浏览器,想要打开浏览器之后先留住,那就在最后随便一个代码,然后打个断点,用【调试】来运行程序。用【运行】的话就一次性运行结束脚本了。
python
from selenium import webdriver
# 创建驱动器对象
ChromeDriver = webdriver.Chrome()
# 用【驱动器对象 .get()】打开网站
ChromeDriver.get('https://www.baidu.com')
# pass是一个没用的代码,当你不知道写什么就可以塞一个pass,比如循环体里加pass就是啥也不做,纯循环
# 在这打个断点,然后调试
pass
四、基础操作
这里会涉及到http的知识点和HTML、CSS的知识点,我就不细讲了,因为我觉得学计算机的应该都会
那么学过爬虫的应该知道,网页的结构就是HTML网页代码,我们要获取的就是HTML的代码里的元素
1、最基础的用dom元素、id、class获取元素
这些步骤应该不用我说了,检查网页元素,右键检查或者F12,然后选择元素,就能看到这个元素的HTML的代码
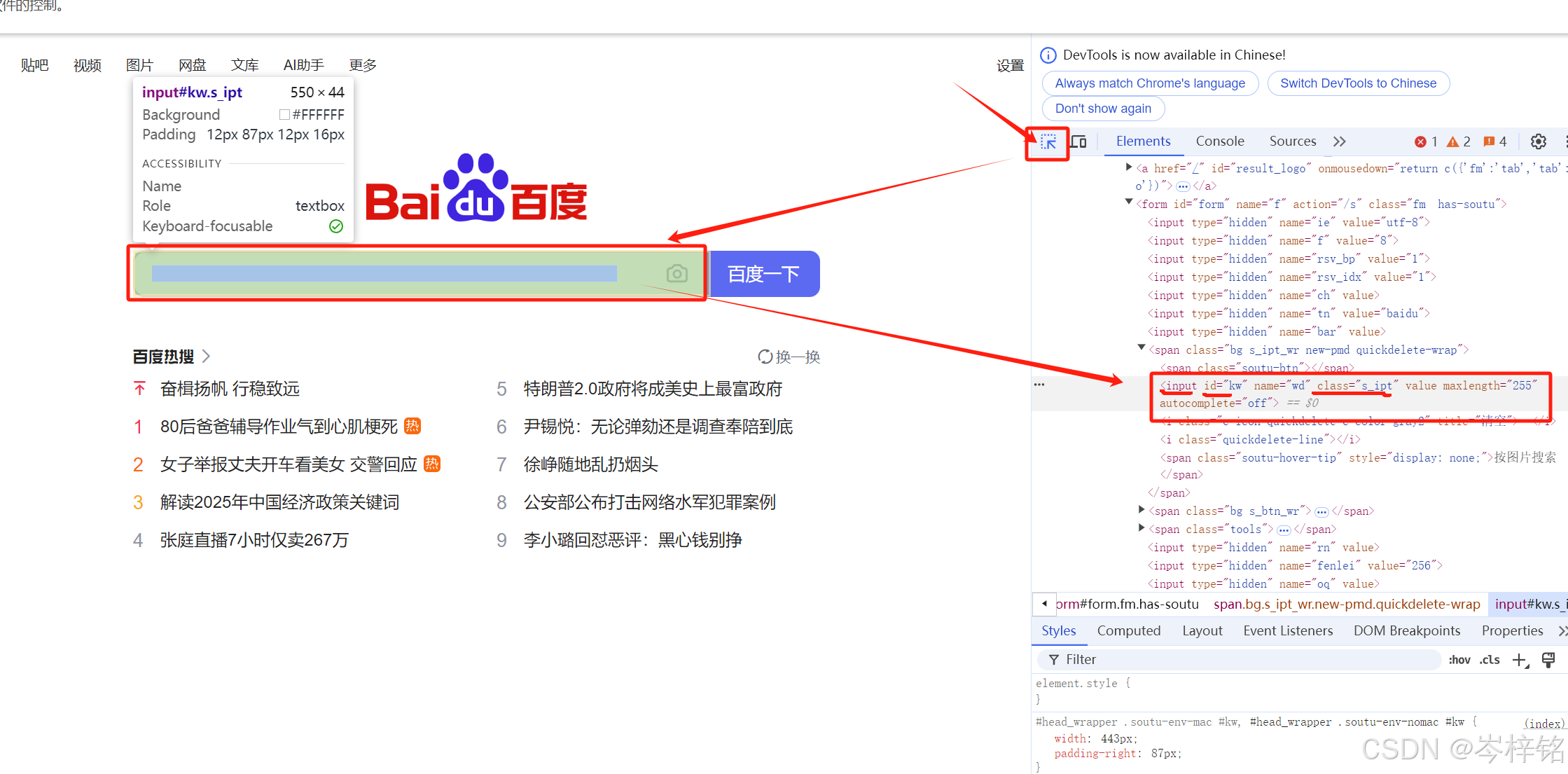
那么标签名、id选择器、class选择器我也懒得讲了,不会的自己上网查,是最基础的web前端开发基础,当我们找到了我们要的某一个元素,并且看到了他的"标签名、id名、class名"之后,我们就可以到代码里定位这个元素了:
首先获取单独一个元素就是:【驱动器对象.find_element( )】
当你已知一个元素的某个标签名、id名、class名,然后用这个方法能获得这种元素的第一个
;
获取同名的所有元素是:【驱动器对象.find_elements( )】
当你已知一个元素的某个标签名、id名、class名,然后用这个方法能获得所有叫这名的元素
不管是【驱动器对象.find_element( ) 】还是【驱动器对象.find_elements( )】都需要2个参数:
- 第一个是【通过标签名、id选择器、class选择器】哪一个方式来选择元素
- 需要用By这个对象,需要另外导入By的头文件
- 通过标签名就是:By.TAG_NAME
- 通过id名就是:By.ID
- 通过类名就是:By.CLASS_NAME
- 第二个是就是具体的【标签名、id名、class名】,直接写名字
例子:
pythonfrom selenium.webdriver.common.by import By #By对象的头文件 # 根据标签名获取div的第一个元素(很少用!!!) divElement = ChromeDriver.find_element(By.TAG_NAME, 'div') # 根据id名获取id叫"kw"的第一个元素(就是输入框) inputElement = ChromeDriver.find_element(By.ID, 'kw') # 根据id名获取id叫"su"的第一个元素(就是回车按钮) enterButton = ChromeDriver.find_element(By.ID, 'su') # 根据类名叫"title-content-title"获取所有这样的元素 titleList = ChromeDriver.find_elements(By.CLASS_NAME, 'title-content-title')


2、获取元素文字、属性、html结构
1)标签结构内的文字
前面我们已经获取简单的元素了,然后我们现在需要获取里面的文字,这才是我们要的东西
很简单 ------------【元素对象.text】
pythonelement = ChromeDriver.find_element(By.CLASS_NAME, 'mnav') print(enterButton.text)注意**class="类名1 类名2 ......"**类名是可以用空格带多个类名的,每一个类名都可以作为这个元素的类名


【提示】
如果【元素.text】没有获取到文字,还可以试一下【元素.innerText】或【元素.textContent】
2)元素的属性
但是我们会发现有的元素的文字并不是在它的标签结构里的:<标签>文字</标签>,而是嵌在元素里的:<标签 target="文字" xxx="文字" value="文字" ...></标签>
那么在标签里的这些就是【属性】了,用 ---------【元素对象.get_attribute( '属性名' ))】可获取
pythonenterButton = ChromeDriver.find_element(By.CLASS_NAME, 's_btn') print(enterButton.get_attribute('value'))


3)元素的HTML代码
那么有的时候我们想看看这个元素是不是我要的,可以看一下他的HTML结构------【元素对象.outHTML】
pythonenterButton = ChromeDriver.find_element(By.CLASS_NAME, 's_btn') print(enterButton.get_attribute('outerHTML'))

五、创建驱动器对象时优化处理问题
为了加快我们爬虫程序的速度,我们需要在创建驱动器的时候,加入下面的写法来优化我们的程序
1、页面加载慢用【隐式等待】
隐式等待又叫全局等待
有的时候我们获取元素明明代码是对的,但是就是返回找不到......???
那这个时候就可能因为页面加载太慢了,一个页面加载需要发送请求到服务器、后端,还要操作浏览器驱动器,然而我们的程序是以极快的速度来执行脚本代码的,当页面还在加载的时候,程序可能已经开始执行【查找元素】的代码了,那这个时候页面啥也没有那肯定就啥也找不到啊
那么selenium的解决办法就是用【隐式等待】,用一句代码来解决【驱动器对象.implicitly_wait( 等待时间 )】。他的意思就是在尝试访问一个元素时等待一段时间,直到该元素出现,再等一段时间再找下一个元素......
这段等待时间就是我们往【驱动器对象.implicitly_wait( 等待时间 )】传入的参数,单位是秒,通常都是用10s
python
from selenium import webdriver
ChromeDriver = webdriver.Chrome()
ChromeDriver.implicitly_wait(10) # 隐式等待、全局等待
ChromeDriver.get('网址')反正你加上就对了,也不会少块肉
2、另一种优化方式
1)DesiredCapabilities对象
【DesiredCapabilities】是 Selenium WebDriver 的一个类,用于设置【驱动器(webdriver)的行为】如浏览器类型、版本、平台等。通过这个类,我们能够配置【驱动器(webdriver)】在指定的环境执行我们的脚本,可以在不同的环境中运行Selenium测试脚本,支持并行运行多个测试用例在不同的浏览器、操作系统和机器上。
【
DesiredCapabilities对象】包含了一系列的键值对,每个键值对都表示一个特定的【驱动器的行为】 设置:
- 浏览器名称:broswerName
- 版本:version
- 操作系统平台:platform
- 驱动器是否等待页面加载完成:pageLoadStrategy
- ......
例子:
pythonfrom selenium.webdriver import DesiredCapabilities #头文件 # 创建DesiredCapabilities对象的写法 capabilities = DesiredCapabilities.EDGE #适用于Edge浏览器的驱动器 # capabilities = DesiredCapabilities.FIREFOX #适用于火狐浏览器的驱动器 # capabilities = DesiredCapabilities.Chrome #适用于谷歌浏览器的驱动器 # 设置它的一些行为属性 capabilities['browserName'] = 'EDGE' #指定是EDGE浏览器的环境 capabilities['browserVersion'] = 'latest' #指定是最新版本 capabilities['platformName'] = 'WINDOWS' #指定是window操作系统平台 # 都设置好之后,在创建驱动器对象的时候,把DesiredCapabilities参数加进去 driver = webdriver.EDGE(desired_capabilities=capabilities)
2)Options对象
webdriver.Edge() 方法本身并不接受任何参数,它只是创建一个 Edge 浏览器的驱动器,并使用默认的设置。
Options对象用于操作【浏览器驱动器的各种属性】,Option类通常与DesiredCapabilities一起使用。
使用【驱动器Options( )】可以设置各个浏览器的不同选项和参数,例如:
- 设置浏览器窗口大小
- 设置浏览器的启动位置
- 配置浏览器的代理服务器
- 设置浏览器的用户代理字符串
- 启用或禁用浏览器的javascript执行等。
下面是ChromeOptions类可用的和最常用的参数列表:
- start-maximized: 最大化模式打开
- Chrome incognito: 无痕浏览打开浏览器
- headless: 无头模式(后台运行)
- disable-extensions: 禁用Chrome浏览器上现有的扩展
- disable-popup-blocking: 禁用弹窗
- make-default-browser: 设置Chrome为默认浏览器
- version: 打印chrome浏览器版本
- disable-infobars: 防止Chrome显示"Chrome正在被自动化软件控制"的通知
例子:
注意,.add_argument('--参数') 等于.add_argument('参数'),通常来说推荐用.add_argument('--参数') ,因为前面的"--"表示这是一个选项,可选可不选,有冲突时以适配的优先,更灵活
pythonfrom selenium.webdriver.firefox.options import Options # 创建FirefoxOptions对象 options = Options() options.add_argument('--headless') # 设置无头模式 options.add_argument('--disable-extensions') # 禁用浏览器扩展 options.add_argument("--window-size=1920,1080") # 设置浏览器窗口大小 options.add_argument("--disable-images") # 禁用图片加载
3)搭配优化脚本执行速率
前面讲得比较细,其实我们用不到那么多参数,所以我就没有给太多使用案例
我们只讲平时爬虫我么们常用的几个写法
1、DesiredCapabilities对象设置【不等待页面加载完成,立即返回】
在默认情况下,WebDriver 会等待页面完全加载完成,然后再继续执行脚本。这可能会导致脚本执行速度较慢,特别是在加载大型页面或网络条件较差的情况下。
;
这可以提高脚本的执行速度,但可能会导致脚本在页面加载完成之前尝试访问页面元素。但是一般加了没错,加了就对了
pythonfrom selenium.webdriver import DesiredCapabilities # 创建一个【EDGE的驱动器】的【capabilities对象】 desired_capabilities = DesiredCapabilities.EDGE # 直接返回,不再等待界面加载完成 desired_capabilities["pageLoadStrategy"] = "none"2、搭配option不加载图片,加快页面加载速度
pythonoptions = webdriver.EdgeOptions() options.add_argument("--disable-images") # 禁用图片加载 # 下面这种写法也是禁用图片加载,一样效果 # options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
3、完整例子
(结合两个优化,反正你以后创建webdriver你就这么复制就行)
python
from selenium import webdriver
from selenium.webdriver import DesiredCapabilities
# 这行代码创建了一个 DesiredCapabilities 对象,用于设置 Edge 驱动器的行为
desired_capabilities = DesiredCapabilities.EDGE
# 直接返回,不再等待界面加载完成
desired_capabilities["pageLoadStrategy"] = "none"
# 设置webdriver的option选项对象
options = webdriver.EdgeOptions()
options.add_argument("--disable-images") # 禁用图片加载
# options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
driver = webdriver.Edge(options=options)
driver.implicitly_wait(10) # 隐式等待、全局等待
driver.get('https://kns.cnki.net/kns8s/AdvSearch?crossids=YSTT4HG0%2CLSTPFY1C%2CJUP3MUPD%2CMPMFIG1A%2CWQ0UVIAA%2CBLZOG7CK%2CPWFIRAGL%2CEMRPGLPA%2CNLBO1Z6R%2CNN3FJMUV')六、CSS选择器
前面我们选择的元素都是很基础很基础的,直接用当前元素的【标签名、id名、class名】来选
但是如果有多个元素都叫同名怎么办,例如:<div class="content"></div>、<ul class="content"></ul>、<span class="content"></span>......
那么有过开发经验的应该知道,css的层级结构还是比较可靠的,这里我具体就不展开叙述了,有兴趣自己查 "css选择器语法",基本和爬虫这里大差不差,常用的我说一下吧:
- ">" 跟着上一元素的直系子元素:
- 元素 > 直系后代元素1 > 直系后代元素2 > ......
- "空格" 跟着上一元素的任意子元素,隔代后代元素也行:
- 元素 后代元素1 后代元素2......
- 要同时选择1个以上的元素,那就用逗号
- 元素1,元素2,......
- 但是注意,要选一个父元素里的两个子元素,逗号后面不能漏了层级关系
- 例子:#main下的ul和p标签元素:#main ul, p ×错 #main ul, #main p √对
- 要选一个元素和紧挨着的下一个元素,比如<h3>...</h3><span>...</span>
- 元素1 + 元素2,例子:h3 + span
- 要选一个元素后面的所有元素,比如<h3>...</h3><span>...</span><span>...</span>
- 元素1 ~ 元素2,例子:h3 ~ span
- 父元素的第n个子节点,比如<span><div>...</div><div>...</div></span>
- 元素:nth-child(n),例子:span:nth-child(2)
- 也可根据属性值来选,比如:<div data-md-component="container"></div>
- 元素属性="属性值",例子:divdata-md-component="container"
【重点】
这都不是重点,重点是以前我一直傻傻自己在代码测试自己有没有找到这个元素
;
殊不知在检查页面可以直接搜索查找我们的定位元素有没有定位到
;
在HTML部分【Ctrl + F】查找,把你猜想到的css选择器写法写上去,看看有没有定位到,没有就一直试,直到定位上去,这样就不用再到代码里一遍一遍试错了

【语法】
就是把【.find_element( )】或【.find_elements( )】的第一个参数写成【By.CSS_SELECTOR】
pythontitleList = ChromeBrowser.find_elements(By.CSS_SELECTOR, ".result div div .c-title a") for title in titleList: print(title.text)
七、鼠标、键盘事件
现在我们前面的基础其实跟request、scrapy差不多,重点来了,selenium如何做到自动化检测、爬虫网站的?
那就是模仿鼠标的点击事件、键盘事件......等等
1、(常用的)输入、鼠标左键点击
键盘输入事件:【元素.sent_keys("要输入的内容")】
- 要先用【元素.clean()】清空一下输入框的内容,以免有别的文字
- 这里留意,如果你的文字输入内容是"...\n"后带上"换行符",就代表摁下【回车】了 (但是如果有的输入框没有写摁下回车事件,那就没用,就还得点击【发送按钮】才行)
python# 获取输入框元素 inputElement = ChromeBrowser.find_element(By.ID, 'kw') # 先清空输入框里的文字 inputElement.clear() # 然后填入文字,并同时回车 inputElement.send_keys('岑梓铭\n')
鼠标点击事件:【元素.click()】
pythoninputElement = ChromeBrowser.find_element(By.ID, 'kw') inputElement.clear() inputElement.send_keys('岑梓铭') # 获取【发送按钮】元素 enterButton = ChromeBrowser.find_element(By.ID, 'su') # 输入框没有自动摁回车,这里用点击事件来点击发送按钮 enterButton.click()
【小例子】
python
from selenium import webdriver
from selenium.webdriver.common.by import By
ChromeBrowser = webdriver.Chrome()
ChromeBrowser.implicitly_wait(10) # 隐式等待、全局等待
ChromeBrowser.get('https://www.baidu.com')
inputElement = ChromeBrowser.find_element(By.ID, 'kw')
enterButton = ChromeBrowser.find_element(By.ID, 'su')
inputElement.clear()
inputElement.send_keys('岑梓铭')
enterButton.click()
titleList = ChromeBrowser.find_elements(By.CSS_SELECTOR, ".result div div .c-title a")
for title in titleList:
print(title.text)2、(偶尔用)其他的事件
之前我们对web元素做的操作主要是:选择元素 ,然后 点击元素 或者 输入 字符串。
还有没有其他的操作了呢?有。
比如:鼠标右键点击、双击、移动鼠标到某个元素、鼠标拖拽等。这些操作,可以通过 Selenium 提供的 ActionChains 类来实现。常用有:
- 单击元素:actions.click( 元素 ).perform( )
- 在当前聚焦元素输入框输入内容:actions.send_keys("内容").perform( )
- **鼠标悬停不点击:**actions.move_to_element( 元素 ).perform( )
- 双击元素:actions.double_click( 元素 ).perform( )
- **右键点击元素:**actions.context_click( 元素 ).perform( )
- **拖拽元素:**actions.drag_and_drop( 拖拽元素, 目标元素 ).perform( )
- **鼠标摁住不放:**actions.click_and_hold( 元素 ).perform( )
- **摁下Enter键并释放:**actions.key_down( Keys.ENTER ).key_up( Keys.ENTER ).perform( )
例子:
百度的"更多"就是要鼠标悬停上去不点击,才会出现这些元素
pythonfrom selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.implicitly_wait(5) driver.get('https://www.baidu.com/') # 开始使用action_chains来进行鼠标事件 #导入头文件 from selenium.webdriver.common.action_chains import ActionChains # 创建action_chains对象 ac = ActionChains(driver) # 鼠标移动到 元素上 ac.move_to_element( #这里填入获取的元素对象,而且用的是属性选择 driver.find_element(By.CSS_SELECTOR, '[name="tj_briicon"]') ).perform()


3、冻结窗口
像刚刚那个情况我们要鼠标悬停,隐藏的东西才会出现;但是当鼠标一离开,隐藏元素马上消失,那这样我们怎么找到这隐藏元素呢?
我们可以使用一个技巧,当我们在浏览器控制台输入【debugger】,网页就会冻住,进行调试模式
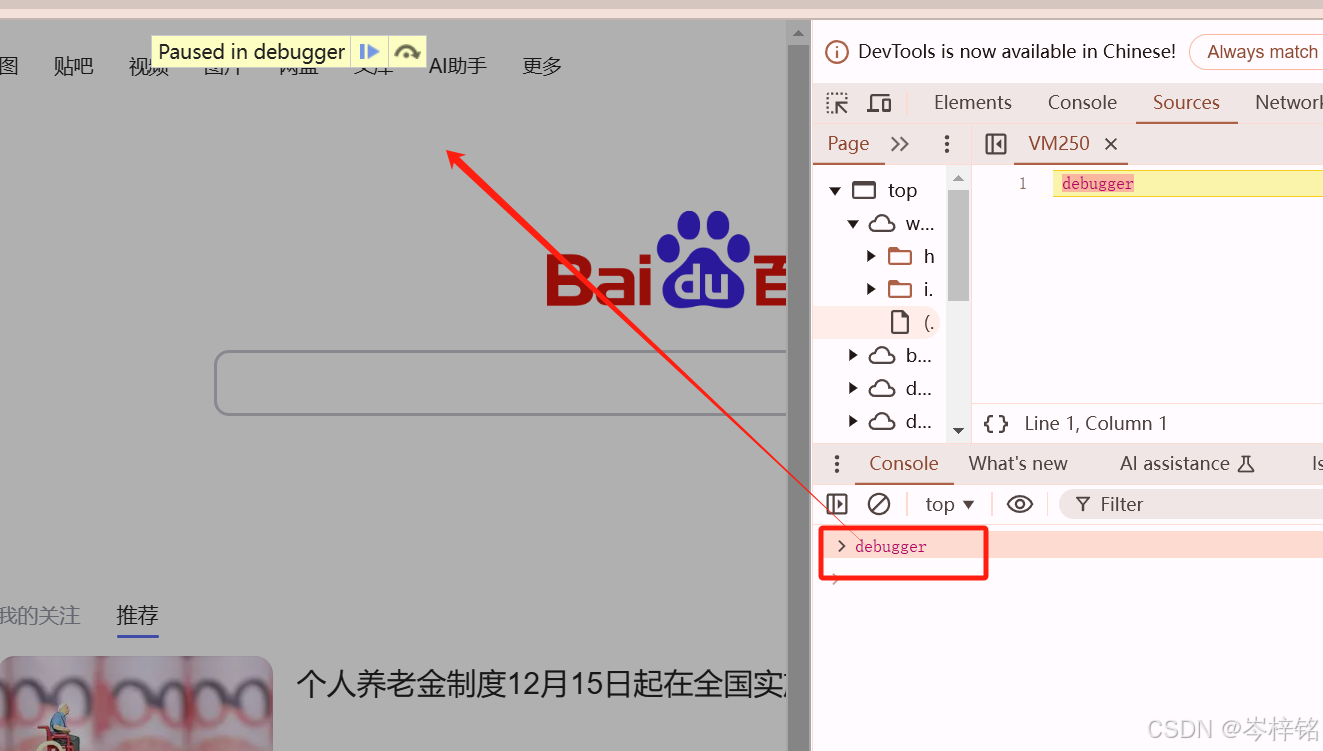
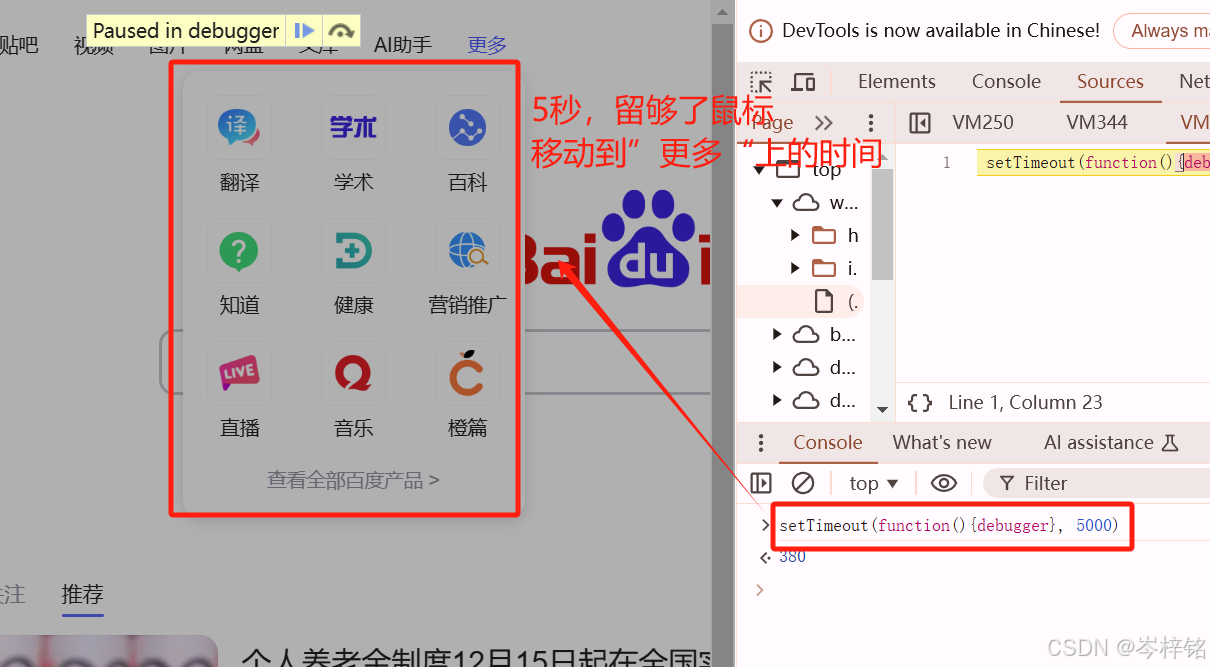
那么我们再写一个这样的一行代码:
python
setTimeout(function(){debugger}, 5000)学过前端的应该明白,意思就是说用setTimeout这个定时器函数,在设定的时间内再触发debbug事件
八、切换页面窗口
当我们在一个页面点击某个链接跳转到一个新页面的时候,我们的脚本程序并不会自动切换到新页面,这时候我们如果还想在新的窗口进行一些操作,就会报错
错误例子:
pythonfrom selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.implicitly_wait(10) # 隐式等待、全局等待 driver.get('https://www.byhy.net/cdn2/files/selenium/sample3.html') # 这是一个超链接元素,我们在原页面点击这个元素进行跳转新页面 link = driver.find_element(By.TAG_NAME, 'a') link.click() # 这里我们以为自己跳转到了一个搜索网页,我们希望获取搜索框并输入内容 # input = driver.find_element(By.ID, 'sb_form_q') # input.send_keys('岑梓铭') # 但是很明显是错的,因为我们并没有切换到新的页面,我们还在原来的页面,所以不可能找到这个新页面的元素
那么selenium提供一个工具:【驱动器.current_window_handle】
【驱动器.current_window_handle】能返回包含这个驱动器打开的浏览器的所有窗口信息的对象数组,每个窗口对象的信息包括【窗口标题】、【窗口url】
那么我们就可以再搭配【驱动器.switch_to.window( 窗口对象 )】来切换窗口了,只需要设置一个循环,用【驱动器.switch_to.window( 窗口对象 )】一直切换,直到当前窗口的【驱动器.title】或【驱动器.current_url】是我们要的页面,就退出切换窗口循环
pythonfrom selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.implicitly_wait(10) # 隐式等待、全局等待 driver.get('https://www.byhy.net/cdn2/files/selenium/sample3.html') # 这是一个超链接元素,我们在原页面点击这个元素进行跳转新页面 link = driver.find_element(By.TAG_NAME, 'a') link.click() #----------------------------【原窗口】-------------------------------- #---------------------------【跳转窗口】-------------------------------- # 获取所有窗口句柄 all_windows = driver.window_handles # 切换到新窗口 for window in all_windows: driver.switch_to.window(window) # 通过窗口标题字符串判断 if "必应" in driver.title: break # 通过窗口url判断 if "https://cn.bing.com/" in driver.current_url: break # 现在就可以获取新窗口元素并操作了 input = driver.find_element(By.ID, 'sb_form_q') input.send_keys('岑梓铭\n')

如果我们还要回到原来的窗口页面,那么就在切换新窗口之前,用【驱动器.current_window_handle】保存当前原页面的窗口对象
然后最后再用【驱动器.switch_to.window( 窗口对象 )】切换回去就行
完整代码
pythonfrom selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.implicitly_wait(10) # 隐式等待、全局等待 driver.get('https://www.byhy.net/cdn2/files/selenium/sample3.html') # 这是一个超链接元素,我们在原页面点击这个元素进行跳转新页面 link = driver.find_element(By.TAG_NAME, 'a') link.click() #----------------------------【原窗口】-------------------------------- #---------------------------【跳转窗口】-------------------------------- # 获取当前窗口句柄 current_window = driver.current_window_handle # 获取所有窗口句柄 all_windows = driver.window_handles # 切换到新窗口 for window in all_windows: driver.switch_to.window(window) # 通过窗口标题字符串判断 if "必应" in driver.title: break # 通过窗口url判断 if "https://cn.bing.com/" in driver.current_url: break # 现在就可以获取新窗口元素并操作了 input = driver.find_element(By.ID, 'sb_form_q') input.send_keys('岑梓铭\n') #---------------------------【回到原窗口】-------------------------------- driver.switch_to.window(current_window)
九、selenuim操作JS
有的时候我们还需要通过操作JS来实现一些复杂业务
基本语法就是(不传参数):【驱动器对象.execute_script( "JS的操作,要字符串形式" )】
还有一种写法是(要传参):【驱动器对象.execute_script( "JS的操作" ),参数1,参数2,......】
比如我们只需要简单用JS在控制台输出1个字符串,不用参数就【驱动器对象.execute_script( "JS的操作,要字符串形式" )】
pythonjs = "console.log('hello')" driver.execute_script(js)
那么有时我们需要指定操作某一个元素,就需要把这个对象当成参数传给JS用参数,就【驱动器对象.execute_script( "JS的操作" ),参数1,参数2,......】



例子1:
假设我们想点一个 "不在视觉范围的一个元素",如果单纯只是想获取这个元素是可以的;但是如果那你想自动化去点击,就不行了,因为这个元素要往下划才能显示在屏幕,才能看到才能点击
直接点击这个元素报错
pythonfrom selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome( ) driver.get('https://www.douban.com/') # 点击一个在很下面的屏幕往下滑才看得到的元素 link = driver.find_element(By.CSS_SELECTOR,'#anony-movie .sidenav .section-title a') link.click()那么现在就要利用JS,让屏幕下划,直到这个元素出现在屏幕视野
pythonfrom selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome( ) driver.get('https://www.douban.com/') # 利用selenuim操控JS让滚动条的拖动1500 js = 'scrollTo(0,1500)' driver.execute_script(js) # 现在元素在视线范围,可以获取并点击了 link = driver.find_element(By.CSS_SELECTOR,'#anony-movie .sidenav .section-title a') link.click() 那如果我们实在不好确定到底该往下划多少,可以这样写
python from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome( ) driver.get('https://www.douban.com/') # 如果不确定到底要滑动多少才找得到元素,可以这样写 link = driver.find_element(By.CSS_SELECTOR,'#anony-movie .sidenav .section-title a') driver.execute_script("arguments[0].scrollIntoView({block:'center',inline:'center'})", link ) # 其中 arguments[0] 就指代了后面的第一个参数link对应的js对象, # js对象的 scrollIntoView 方法,就是让元素滚动到可见部分 # block:'center' 指定垂直方向居中 # inline:'center' 指定水平方向居中 # 现在元素在视线范围,可以获取并点击了 link.click()


例子2:
知网上当我们点击【高级搜索】之后的搜索页面,我们会发现那些下拉选项元素要鼠标点击才会出现,点击的时候我们会发现,原理是这个元素的css的样式【display: none】就是消失;【display: block】就是出现
;
那么我们只需要用【驱动器对象.execute_script( "" )】
pythonfrom selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome( ) driver.get('https://kns.cnki.net/kns8s/AdvSearch?crossids=YSTT4HG0%2CLSTPFY1C%2CJUP3MUPD%2CMPMFIG1A%2CWQ0UVIAA%2CBLZOG7CK%2CPWFIRAGL%2CEMRPGLPA%2CNLBO1Z6R%2CNN3FJMUV') # 获取到下拉菜单的元素 optionSelect = driver.find_element(By.CSS_SELECTOR, ".sort .sort-list") # 使用 JavaScript 将元素的 display 样式设置为 block driver.execute_script("arguments[0].style.display = 'block';", optionSelect) #可打个断点看效果 driver.quit()


还有很多知识点,我将分几篇来讲述,先到这吧