1.需要安装chromedriver
Chrome下载地址
ChromeDriver官网下载地址:https://sites.google.com/chromium.org/driver/downloads
ChromeDriver官网最新版下载地址:https://googlechromelabs.github.io/chrome-for-testing/
ChromeDriver国内镜像下载地址:https://registry.npmmirror.com/binary.html?path=chromedriver/
ChromeDriver国内镜像最新版下载地址:https://registry.npmmirror.com/binary.html?path=chrome-for-testing/
本地Chrome版本
确认你的Chrome浏览器版本。你可以在Chrome浏览器中打开 chrome://settings/help 查看版本号。
2.配置环境变量
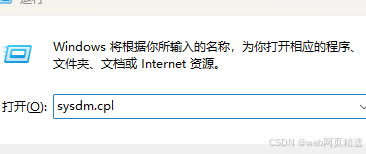
使用 sysdm.cpl 打开环境变量
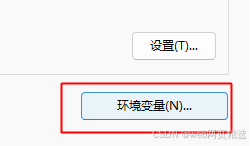
编辑 系统变量 中的 Path 变量,把 ChromeDriver 解压路径追加在Path变量中。
3.python pip命令导包
python
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import pandas as pd
import chardet
import requests
import time
# 定义保存图片的文件夹路径
save_folder = 'jd_item_images'
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 检测并读取CSV文件编码
def detect_encoding(file_path):
with open(file_path, 'rb') as file:
raw_data = file.read(1000)
result = chardet.detect(raw_data)
return result['encoding']
csv_file_path = 'jd_sku2.csv' # 确保这是你的CSV文件的正确路径
encoding = detect_encoding(csv_file_path)
# 使用检测到的编码来读取整个文件
df = pd.read_csv(csv_file_path, encoding=encoding)
# 获取商品ID列表(假设商品编号在第三列,即索引为2)
product_ids = df.iloc[:, 2].dropna().astype(str).tolist()
# 设置Chrome选项
chrome_options = Options()
chrome_options.add_argument("--headless") # 不打开浏览器窗口
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
# 指定ChromeDriver路径
service = Service(executable_path=r'D:\chromedriver\chromedriver-win64\chromedriver.exe') # 替换为你的chromedriver路径
# 初始化WebDriver
driver = webdriver.Chrome(service=service, options=chrome_options)
for product_id in product_ids:
try:
url = f'https://item.jd.com/{product_id}.html'
driver.get(url)
time.sleep(5) # 等待页面加载完成,可以根据实际情况调整等待时间
# 获取并解析HTML结构
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
# 查找charset为gbk的<script>标签
# script_gbk_tag = soup.find('script', {'charset': 'gbk'})
# if script_gbk_tag:
#
# print(f"Content of <script charset='gbk'> for product ID {product_id}:")
#
# print("首图链接") # 分隔线
#
# print(script_gbk_tag.string.strip())
#
# # 666666666666666
#
# print("-" * 80) # 分隔线
#
# else:
# print(f"No <script charset='gbk'> found for product ID: {product_id}")
# 尝试获取商品图片链接并保存图片
img_tag = soup.find('img', {'id': 'spec-img'}) or soup.find('img', {'class': 'jqzoom'})
if img_tag and 'src' in img_tag.attrs:
img_url = 'https:' + img_tag['src'] if img_tag['src'].startswith('//') else img_tag['src']
img_response = requests.get(img_url, timeout=10)
img_response.raise_for_status()
img_save_path = os.path.join(save_folder, f'{product_id}.jpg')
with open(img_save_path, 'wb') as img_file:
img_file.write(img_response.content)
print(f'Successfully saved image for product ID: {product_id}')
else:
print(f'Failed to find image URL for product ID: {product_id}')
except Exception as e:
print(f'Error processing product ID {product_id}: {e}')
# 关闭浏览器
driver.quit()