目录
[① 线性层](#① 线性层)
[② sigmoid激活函数](#② sigmoid激活函数)
[③ 手动实现MSE均方差损失函数](#③ 手动实现MSE均方差损失函数)
[④ 前向传播](#④ 前向传播)
[⑤ 手动实现梯度计算](#⑤ 手动实现梯度计算)
[⑤ 权重的更新:优化器函数](#⑤ 权重的更新:优化器函数)
[⑥ diy模型验证](#⑥ diy模型验证)
[⑦ 手动实现Adam优化器](#⑦ 手动实现Adam优化器)
[二、优化器 Adam](#二、优化器 Adam)
[step1 字符数值化](#step1 字符数值化)
[step2 矩阵转化为向量](#step2 矩阵转化为向量)
[step3 向量到数值](#step3 向量到数值)
[四、Embedding 嵌入层](#四、Embedding 嵌入层)
[① 声明需要多少个向量](#① 声明需要多少个向量)
[② 每个向量需要多少维](#② 每个向量需要多少维)
[③ 初始化权重](#③ 初始化权重)
[④ 构造字符表](#④ 构造字符表)
[⑤ 根据位置将字符串转化为输出的数字序列](#⑤ 根据位置将字符串转化为输出的数字序列)
[五、池化层 Pooling](#五、池化层 Pooling)
[Avg Pooling](#Avg Pooling)
[Max Pooling](#Max Pooling)
[六、网络结构 - RNN 循环神经网络](#六、网络结构 - RNN 循环神经网络)
[2.forward 前向传播](#2.forward 前向传播)
[3.对比试验 构建样本](#3.对比试验 构建样本)
[七、网络结构 - CNN 卷积神经网络](#七、网络结构 - CNN 卷积神经网络)
[3.对比试验 构建样本](#3.对比试验 构建样本)
[八、网络结构 - Normalization 归一化层](#八、网络结构 - Normalization 归一化层)
[batch Normalization 批归一化](#batch Normalization 批归一化)
[Layer Normalization 层归一化](#Layer Normalization 层归一化)
[Instance Normalization 实例化归一化](#Instance Normalization 实例化归一化)
[九、网络结构 - Dropout层](#九、网络结构 - Dropout层)
一切都在慢慢变好,而且会变得越来越好
------ 24.12.12
一、反向传播
反向传播是对链式求导法则的体现,先对外层求导再对内层函数求导
链式法则的体现叫做反向传播

sigmoid函数的导函数等于预测值 × (1 - 预测值)
1.反向传播运算过程
反向传播对模型函数的模型权重求梯度(求导)
反向传播: 对模型函数链式法则求导
更新权重:w - lr * grad

2.前向传播和反向传播的作用
前向传播
前向传播是用来计算返回值的,前向传播是指输入一个值,经过模型计算返回一个预测值
反向传播
反向传播是用来计算导数(梯度)的,通过前向传播拿到预测值之后,通过预测值与真实值对比计算损失loss,反向传播再对模型权重 (参数)计算导数(梯度),然后才能知道模型优化的方向,调整模型的权重(参数)
3.定义模型(torch包)
python
class TorchModel(nn.Module):
def __init__(self, hidden_size):
super(TorchModel, self).__init__()
# 线性层
self.layer = nn.Linear(hidden_size, hidden_size, bias=False) #w = hidden_size * hidden_size wx+b -> wx
# 激活层 sigmoid
self.activation = torch.sigmoid
# 损失函数 均方差损失函数
self.loss = nn.functional.mse_loss #loss采用均方差损失
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
# 线性层
y_pred = self.layer(x)
# 激活层
y_pred = self.activation(y_pred)
# 损失函数计算损失值
if y is not None:
return self.loss(y_pred, y)
else:
return self.activation(y_pred)4.手动实现
① 线性层
特征提取
**weignt:**模型中初始化的参数
python
def __init__(self, weight):
self.weight = weight
def forward(self, x, y=None):
# 线性层激活函数
x = np.dot(x, self.weight.T)② sigmoid激活函数
python
# 手动实现sigmoid激活函数
def diy_sigmoid(self, x):
return 1 / (1 + np.exp(-x))③ 手动实现MSE均方差损失函数
python
# 手动实现mse,均方差loss
def diy_mse_loss(self, y_pred, y_true):
return np.sum(np.square(y_pred - y_true)) / len(y_pred)④ 前向传播
前向传播用来计算预测值
反向传播通过前向传播得出的预测值,与标签真实值对比计算得出梯度,更新模型的权重(参数)
python
#自定义模型,接受一个参数矩阵作为入参
class DiyModel:
def __init__(self, weight):
self.weight = weight
def forward(self, x, y=None):
x = np.dot(x, self.weight.T)
y_pred = self.diy_sigmoid(x)
if y is not None:
return self.diy_mse_loss(y_pred, y)
else:
return y_pred⑤ 手动实现梯度计算
python
# 手动实现梯度计算
def calculate_grad(self, y_pred, y_true, x):
#前向过程
# wx = np.dot(self.weight, x)
# sigmoid_wx = self.diy_sigmoid(wx)
# loss = self.diy_mse_loss(sigmoid_wx, y_true)
#反向过程
# 均方差函数 (y_pred - y_true) ^ 2 / n 的导数 = 2 * (y_pred - y_true) / n , 结果为2维向量
grad_mse = 2/len(x) * (y_pred - y_true)
# sigmoid函数 y = 1/(1+e^(-x)) 导数 = y * (1 - y), 结果为2维向量
grad_sigmoid = y_pred * (1 - y_pred)
# wx矩阵运算,见ppt拆解, wx = [w11*x0 + w21*x1, w12*x0 + w22*x1]
#导数链式相乘
grad_w11 = grad_mse[0] * grad_sigmoid[0] * x[0]
grad_w12 = grad_mse[1] * grad_sigmoid[1] * x[0]
grad_w21 = grad_mse[0] * grad_sigmoid[0] * x[1]
grad_w22 = grad_mse[1] * grad_sigmoid[1] * x[1]
grad = np.array([[grad_w11, grad_w12],
[grad_w21, grad_w22]])
#由于pytorch存储做了转置,输出时也做转置处理
return grad.T⑤ 权重的更新:优化器函数
更新的过程:优化器函数
随机梯度下降(Stochastic Gradient Descent,SGD):随机梯度下降优化器是一种常用的优化算法,用于训练机器学习模型特别是神经网络。它通过迭代地更新模型参数来最小化损失函数。
公式: 权重 - 学习率 * 上一轮迭代的梯度
python
#梯度更新
def diy_sgd(grad, weight, learning_rate):
# 权重 - 学习率 * 梯度
return weight - learning_rate * grad⑥ diy模型验证
python
x = np.array([-0.5, 0.1]) #输入
y = np.array([0.1, 0.2]) #预期输出
#torch计算梯度
torch_model = TorchModel(2)
# 取出torch模型权重的初始化
torch_model_w = torch_model.state_dict()["layer.weight"]
print(torch_model_w, "初始化权重")
numpy_model_w = copy.deepcopy(torch_model_w.numpy())
#numpy array -> torch tensor, unsqueeze的目的是增加一个batchsize维度
torch_x = torch.from_numpy(x).float().unsqueeze(0)
torch_y = torch.from_numpy(y).float().unsqueeze(0)
#torch的前向计算过程,得到loss
torch_loss = torch_model(torch_x, torch_y)
print("torch模型计算loss:", torch_loss)
#手动实现loss计算
diy_model = DiyModel(numpy_model_w)
diy_loss = diy_model.forward(x, y)
print("diy模型计算loss:", diy_loss)
⑦ 手动实现Adam优化器
python
#adam梯度更新
def diy_adam(grad, weight):
#参数应当放在外面,此处为保持后方代码整洁简单实现一步
alpha = 1e-3 #学习率
beta1 = 0.9 #超参数 β1
beta2 = 0.999 #超参数 β2
eps = 1e-8 #超参数 ε
t = 0 #初始化
mt = 0 #初始化
vt = 0 #初始化
#开始计算
t = t + 1
gt = grad
mt = beta1 * mt + (1 - beta1) * gt
vt = beta2 * vt + (1 - beta2) * gt ** 2
mth = mt / (1 - beta1 ** t)
vth = vt / (1 - beta2 ** t)
weight = weight - (alpha * mth/ (np.sqrt(vth) + eps))
return weight二、优化器 Adam
作用: 在梯度计算完成后,通过优化器更新权重

Stepsize:α学习率(步长)
β1,β2: (0,1)之间的两个数,一般β1设置为0.9,一般β2设置为0.999
**f(θ):**目标函数(模型)的参数θ
**θ:**初始化的模型参数
**m0:**第一轮梯度的指数衰减平均,初始值为0
**v0:**第一轮梯度平方的指数衰减,初始值为0
**t:**时间步,初始值为0
**ε:**防止分母为0,值很小
进入循环,收敛时停止:
①  时间步+1(记录训练样本轮次数)
时间步+1(记录训练样本轮次数)
②  计算获取梯度的过程
计算获取梯度的过程
③  将前一轮的梯度与本轮梯度合在一起,而前一轮梯度又是之前梯度的组合,所以mt 就是前t轮梯度的组合
将前一轮的梯度与本轮梯度合在一起,而前一轮梯度又是之前梯度的组合,所以mt 就是前t轮梯度的组合
④  将前轮梯度的平方与本轮梯度合在一起,而前一轮梯度又是之前梯度的带平方项的组合,所以vt 就是前t轮带平方项梯度的组合
将前轮梯度的平方与本轮梯度合在一起,而前一轮梯度又是之前梯度的带平方项的组合,所以vt 就是前t轮带平方项梯度的组合
⑤  前n轮的梯度累计 / (1 - β1^t)
前n轮的梯度累计 / (1 - β1^t)
⑥  前n轮带平方项梯度累计 / ( 1 - β2^t**),**平衡梯度对学习率的影响
前n轮带平方项梯度累计 / ( 1 - β2^t**),**平衡梯度对学习率的影响
⑦  上一轮的权重 - 学习率 * 【前n轮的梯度累计 /( 1 - β1^t**)** 】/ ( 【前n轮带平方项梯度 / ( 1 - β2^t**)** 】^ 1/2 + ε**)**
上一轮的权重 - 学习率 * 【前n轮的梯度累计 /( 1 - β1^t**)** 】/ ( 【前n轮带平方项梯度 / ( 1 - β2^t**)** 】^ 1/2 + ε**)**
Adam优化器的特点
1.考虑前n轮的梯度
2.随着训练时间的增加,放缓学习的频率
3.根据梯度绝对值的大小,调整学习率的大小
**作用:**在拿到梯度之后,如何更新模型的权重
Adam优化器将之前轮数都进行考虑,再来根据前n轮的结果综合考虑预测下一个值,优化的步长逐轮应该减小,通过公式中参数的变化,调整学习率的变化
Adam优化器的优点
①实现简单,计算高效,对内存需求少
② 超参数具有很好的解释性,β1的大小决定了对历史数据的看重程度,β2同理,且通常无需调整或仅需很少的微调
③ 更新的步长能够被限制在大致的范围内(初始学习率)
④ 能够表现出自动调整学习率,通过公式中参数的变化,调整学习率的变化
⑤ 很适合应用于大规模的数据及参数的场景
⑥ 适用于不稳定目标函数
⑦ 适用于梯度稀疏或梯度存在很大噪声的问题
手动实现Adam
SGD优化器调用:
python
torch.optim.SGD(torch_model.parameters(), lr=learning_rate)Adam优化器调用:
python
torch.optim.Adam(torch_model.parameters())
python
#adam梯度更新
def diy_adam(grad, weight):
#参数应当放在外面,此处为保持后方代码整洁简单实现一步
alpha = 1e-3 #学习率
beta1 = 0.9 #超参数 β1
beta2 = 0.999 #超参数 β2
eps = 1e-8 #超参数 ε
t = 0 #初始化
mt = 0 #初始化
vt = 0 #初始化
#开始计算
t = t + 1
gt = grad
mt = beta1 * mt + (1 - beta1) * gt
vt = beta2 * vt + (1 - beta2) * gt ** 2
mth = mt / (1 - beta1 ** t)
vth = vt / (1 - beta2 ** t)
weight = weight - (alpha * mth/ (np.sqrt(vth) + eps))
return weight三、NLP任务
**任务:**字符串分类 -- 判断字符串中是否出现了指定字符
**当前输入:**字符串 如:abcd
**预期输出:**概率值 正样本=1,负样本=0,以0.5为分界
X = "abcd" Y = 1
X = "bcde" Y = 0
建模目标: 找到一个映射 f(x),使得 f("abcd") = 1, f("bcde") = 0
步骤
step1 字符数值化
将每个字符转化为同维度向量(embedding层)
矩阵形状 = 文本长度 * 向量长度
step2 矩阵转化为向量
对整句话做池化操作,求平均
由 4 * 5 矩阵 -> 1* 5 向量 形状 = 1 * 向量长度
step3 向量到数值
采取最简单的线性公式 y = w * x + b
w 维度为1 * 向量维度,b为实数
整体映射
"abcd" ---- 每个字符转化成向量 ----> 4 * 5矩阵
4 * 5矩阵 ---- 向量求平均 (池化层)----> 1 * 5向量
1 * 5向量 ---- w*x + b 线性公式 ---> 实数
实数 ---- sigmoid归一化函数 ---> 0-1之间实数,对应分类的类别
红色部分需要通过训练优化
四、Embedding 嵌入层
Embedding矩阵是可训练的参数,一般会在模型构建时随机初始化。也可以使用预训练的词向量来做初始化,此时也可以选择不训练Embedding层中的参数
输入的整数序列可以有重复,但取值不能超过Embedding矩阵的列数
核心价值:将离散值 转化为向量 在nlp任务和各类特征工程中应用广泛
① 声明需要多少个向量
python
num_embeddings = 8 # 通常对于nlp任务,此参数为字符集字符总数,需要多少个随机向量② 每个向量需要多少维
python
embedding_dim = 5 # 每个字符向量化后的向量维度③ 初始化权重
python
# embedding参数:需要多少个向量,及向量的维度
embedding_layer = nn.Embedding(num_embeddings, embedding_dim, padding_idx=0)
print("随机初始化权重")
print(embedding_layer.weight)④ 构造字符表
每个字符占第几个位置
pad
pad是占位补齐的功能,声明要补位的元素
在自然语言处理(NLP)任务中,由于不同句子长度可能不同,通常需要对句子进行填充(Padding)以确保它们具有相同的长度。pad 参数在嵌入层中用于处理这些填充的标记。
在NLP任务中,尽量少做截断,多做补0
python
def str_to_sequence(string,vocab):
# 到长度为5截断
seq = [vocab[s] for s in string][:5]
# 长度不足5则补0
if len(seq) < 5:
seq += [vocab["pad"]] * (5 - len(seq))
return sequnk
在自然语言处理(NLP)任务中,词汇表(Vocabulary)通常是有限的,这意味着某些词汇可能不在词汇表中。为了处理这些未登录词(Out-of-Vocabulary,OOV),通常会引入一个特殊的标记<unk>(Unknown)。<unk>标记用于表示词汇表中未包含的词汇
python
构造字符表
# 每一维对应哪个字符
vocab = {
"[pad]" : 0,
"a" : 1,
"b" : 2,
"c" : 3,
"d" : 4,
"e" : 5,
"f" : 6,
"[unk]":7
}
# 将字符转换为数字序列
def str_to_sequence(string, vocab):
# 到长度为5截断
seq = [vocab.get(s, 7) for s in string][:5]
# 长度不足5则补0
if len(seq) < 5:
seq += [vocab["pad"]] * (5 - len(seq))
return seq⑤ 根据位置将字符串转化为输出的数字序列
对于同一个词表,同一个字符串而言,数字序列是固定的
python
# 将字符转换为数字序列
def str_to_sequence(string, vocab):
# 到长度为5截断
seq = [vocab.get(s, vocab["[unk]"]) for s in string][:5]
# 长度不足5则补0
if len(seq) < 5:
seq += [vocab["pad"]] * (5 - len(seq))
return seq
string1 = "abcde" # 12345
string2 = "ddccb" # 44332
string3 = "fedaz" # 65417
sequence1 = str_to_sequence(string1, vocab)
sequence2 = str_to_sequence(string2, vocab)
sequence3 = str_to_sequence(string3, vocab)示例:Embedding层的处理
python
#coding:utf8
import torch
import torch.nn as nn
'''
embedding层的处理
'''
num_embeddings = 8 # 通常对于nlp任务,此参数为字符集字符总数,需要多少个随机向量
embedding_dim = 5 # 每个字符向量化后的向量维度
# embedding参数:需要多少个向量,及向量的维度
embedding_layer = nn.Embedding(num_embeddings, embedding_dim, padding_idx=0)
print("随机初始化权重")
print(embedding_layer.weight)
print("------------------------------------------------------------------------------------------------------------------------------")
# 构造字符表
# 每一维对应哪个字符
vocab = {
"pad" : 0,
"a" : 1,
"b" : 2,
"c" : 3,
"d" : 4,
"e" : 5,
"f" : 6,
"[unk]" : 7
}
# 将字符转换为数字序列
def str_to_sequence(string, vocab):
# 到长度为5截断
seq = [vocab.get(s, vocab["[unk]"]) for s in string][:5]
# 长度不足5则补0
if len(seq) < 5:
seq += [vocab["pad"]] * (5 - len(seq))
return seq
string1 = "abcdea" # 12345
string2 = "ddcc" # 44332
string3 = "fedaz" # 65417
sequence1 = str_to_sequence(string1, vocab)
sequence2 = str_to_sequence(string2, vocab)
sequence3 = str_to_sequence(string3, vocab)
print(sequence1)
print(sequence2)
print(sequence3)
x = torch.LongTensor([sequence1, sequence2, sequence3])
embedding_out = embedding_layer(x)
print(embedding_out)
# 为了让不同长度的训练样本能够放在同一个batch中,需要将所有样本补齐或截断到相同长度
# padding 补齐
# [1,2,3,0,0]
# [1,2,3,4,0]
# [1,2,3,4,5]
# 截断
# [1,2,3,4,5,6,7] -> [1,2,3,4,5]
五、池化层 Pooling
将一个矩阵转化为向量时,常用到池化
处理文本问题时,文本长度为制定的最长文本长度
Avg Pooling
Avg Pooling 平均值池化
**nn.AvgPool1d(4):**几d就是池化几维的向量,这里是1d,则代表池化为1维的向量

torch.rand(3, 4, 5):3条样本文本,每条样本文本长度为4,每个文本向量长度为5
池化的是第二个参数,即3条文本长度为4,每个文本长度为5的张量,经过池化后变为3条1 * 5的张量
nn.AvgPool() 网络层默认只会对输入张量的最后一维做池化,所以我们需要交换样本的顺序
x.transpose(1,2) # 交换第二、三维的顺序
squeeze() 会将3,5,1的样本转换为3,5的样本,去掉值为1的维度
python
#coding:utf8
import torch
import torch.nn as nn
'''
pooling层的处理
'''
#pooling操作默认对于输入张量的最后一维进行
#入参5,代表把五维池化为一维
# 池化有最大值max池化和average平均池化
# nn.maxPool1d(5) 最大池化
layer = nn.AvgPool1d(4) # 几d就是池化几维的向量
# 随机生成一个维度为3x4x5的张量
# 可以想象成3条样本,每条样本文本长度为4,一个文本向量长度为5
# 池化层是指对中间那维(文本长度层进行池化)进行求平均计算
# torch包中的pooling层默认是按照最后一维进行池化的
x = torch.rand([3, 4, 5])
print(x)
print(x.shape)
# 转置进行交换顺序
x = x.transpose(1,2)
print(x.shape, "交换后")
#经过pooling层
y = layer(x)
# 输入时是3,5,4;转换为3,5,1
print(y)
print(y.shape)
#squeeze方法去掉值为1的维度
# 最终转换为3 * 5的矩阵
y = y.squeeze()
print(y)
print(y.shape)
Max Pooling
Max Pooling 最大值池化,在图像任务上较为常见
**nn.MaxPool1d(4):**几d就是池化几维的向量,这里是1d,则代表池化为1维的向量
实际任务中,平均池化和最大值池化可以都进行实验,比较实验结果

池化层的作用
降低了后续网络层的输入维度,缩减模型大小,提高计算速度
减小不重要的输入对最终结果带来的影响
提高了特征的鲁棒性(泛化能力),防止过拟合
将一个矩阵转化为向量
六、网络结构 - RNN 循环神经网络
解决序列相关问题:预测某一步数的结果与前面n步预测的结果有关
主要思想:将整个序列划分成多个时间步,将每一个时间步的信息依次输入模型,同时将模型输出的结果传给下一个时间步
**公式:**逐渐把前面时间步的值通过记忆的方式不断传给下一个时间步(考虑顺序,本质也是由一系列矩阵乘得到)
每一个时间步都包含这个时间步的信息 和之前所有序列的信息
网络层传出的矩阵可以再与其他层进行配合,搭建模型
**缺点:**输入序列越长,所存储的序列信息就越局限,RNN的效果会随着处理数据的长度增长而衰减

h一开始为0,其作用只是为了存储,将各个时间步的信息进行存储,保持序列的完整性
一般用最后一个词代表的向量代表整句话,因为最后一个字代表的向量(1 × h)包含了整句话的信息
建立RNN模型
nn.RNN(): Pytorch库调用RNN激活函数
input_size: 输入数据的维度
hidden_size: RNN内部的维度,两个值可以相等
bias: 是否使用偏置项(b)
batch_first: 默认输入数据第一维是batch_size(建议添加)
python
class TorchRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(TorchRNN, self).__init__()
# batch_first层置batch_first=True,表示输入和输出的形状为(batch_size, seq_len, input_size)
# 在NLP任务中加上batch_size = true
# input_size 输入向量的维度 hidden_size 中间向量的维度 bias 是否使用偏置项 batch_first 是否将第一维设置成batch_size,一般都要加入
self.layer = nn.RNN(input_size, hidden_size, bias=False, batch_first=True)
def forward(self, x):
return self.layer(x)手动实现RNN循环神经网络
1.自定义RNN模型
w_ih: 代表从输入层到隐藏层其中的权重
w_hh: 代表从隐藏层到下一隐藏层其中的权重
ht: 全零初始化,用来存储每一隐藏层的数据
python
#自定义RNN模型
class DiyModel:
def __init__(self, w_ih, w_hh, hidden_size):
# ih:输入层到隐藏层的权重矩阵,维度为(hidden_size, input_size)
self.w_ih = w_ih
# hh:隐藏层到隐藏层的权重矩阵,维度为(hidden_size, hidden_size)
self.w_hh = w_hh
# hidden_size:隐藏层的维度
self.hidden_size = hidden_size2.forward 前向传播
根据RNN的公式计算ux和wh,再将二者相加,作为下一轮的权重ht
python
def forward(self, x):
# 全0初始化
ht = np.zeros((self.hidden_size))
output = []
for xt in x:
# 先做ux,再做wh
ux = np.dot(self.w_ih, xt)
wh = np.dot(self.w_hh, ht)
# 将二者相加
ht_next = np.tanh(ux + wh)
output.append(ht_next)
# 下一轮的ht用这一轮的ht_next,即ux和wh过tanh激活函数的和
ht = ht_next
return np.array(output), ht3.对比试验 构建样本
一个样本,由三个字构成,每个字都是一个三维向量
python
# 一个样本,三个字,三维向量
x = np.array([[1, 2, 3],
[3, 4, 5],
[5, 6, 7]]) #网络输入4.对比实验结果
**注:**RNN输出时有两个输出,output列表中输出句子中每一个字对应的向量,h是句子中最后一个字对应的向量,可以用output\[\]当下一层输入的矩阵,也可以用h做下一层输入的向量
在NLP任务中,我们尽量保持中间张量的第一维的含义总是batch_size
python
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
"""
手动实现简单的神经网络
使用pytorch实现RNN
手动实现RNN
对比
"""
class TorchRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(TorchRNN, self).__init__()
# batch_first层置batch_first=True,表示输入和输出的形状为(batch_size, seq_len, input_size)
# 在NLP任务中加上batch_size = true
# input_size 输入向量的维度 hidden_size 中间向量的维度 bias 是否使用偏置项 batch_first 是否将第一维设置成batch_size,一般都要加入
self.layer = nn.RNN(input_size, hidden_size, bias=False, batch_first=True)
def forward(self, x):
return self.layer(x)
#自定义RNN模型
class DiyModel:
def __init__(self, w_ih, w_hh, hidden_size):
# ih:输入层到隐藏层的权重矩阵,维度为(hidden_size, input_size)
self.w_ih = w_ih
# hh:隐藏层到隐藏层的权重矩阵,维度为(hidden_size, hidden_size)
self.w_hh = w_hh
# hidden_size:隐藏层的维度
self.hidden_size = hidden_size
def forward(self, x):
# 全0初始化
ht = np.zeros((self.hidden_size))
output = []
for xt in x:
# 先做ux,再做wh
ux = np.dot(self.w_ih, xt)
wh = np.dot(self.w_hh, ht)
# 将二者相加
ht_next = np.tanh(ux + wh)
output.append(ht_next)
# 下一轮的ht用这一轮的ht_next,即ux和wh过tanh激活函数的和
ht = ht_next
return np.array(output), ht
# 一个样本,三个字,三维向量
x = np.array([[1, 2, 3],
[3, 4, 5],
[5, 6, 7]]) #网络输入
#torch实验
hidden_size = 4
torch_model = TorchRNN(3, hidden_size)
# print(torch_model.state_dict())
w_ih = torch_model.state_dict()["layer.weight_ih_l0"]
w_hh = torch_model.state_dict()["layer.weight_hh_l0"]
print(w_ih, w_ih.shape)
print(w_hh, w_hh.shape)
new_x = np.array(x)
# 再转换为torch.FloatTensor
torch_x = torch.FloatTensor(new_x)
output, h = torch_model.forward(torch_x)
print(h)
print(output.detach().numpy(), "torch模型预测结果")
print(h.detach().numpy(), "torch模型预测隐含层结果")
print("---------------")
diy_model = DiyModel(w_ih, w_hh, hidden_size)
output, h = diy_model.forward(x)
# output是每一个字对应的向量
print(output, "diy模型预测结果")
# h是最后一维的向量
print(h, "diy模型预测隐含层结果")
七、网络结构 - CNN 卷积神经网络
以卷积操作为基础的网络结构,每个卷积核可以看成一个特征提取器
例:
如图,输入其实是一个 5 × 5 的矩阵,卷积核是 3 × 3 的小方块,对位相乘再求和

NLP任务中流行一维一整行的卷积
卷积操作在图像任务上使用比较多,判断一个点没有意义,要需要从局部区域进行判断,从这个区域中获取特定的信息(每个模块的卷积核)
**nn.Conv2d:**卷积激活函数
**in_channel:**输入数据时图像的通道数量(RGB三通道矩阵)
**out_channel:**有多少卷积核,输出多少个卷积后的结果
**kernel:**卷积窗口的大小,可调节
**bias:**偏置b,加不加都行
每个卷积窗口先进行横向移动,再进行竖向移动
python
nn.Conv2d(in_channel, out_channel, kernel, bias=False)卷积核包含可训练的参数,池化层不包含可训练参数
手动实现CNN卷积神经网络
1.自定义CNN模型
**height:**定义数据的高度
**width:**定义数据的宽度
**weights:**指卷积核的权重
**kernel_size:**卷积核的大小,卷积核在高度和宽度上的尺寸
python
#自定义CNN模型
class DiyModel:
def __init__(self, input_height, input_width, weights, kernel_size):
self.height = input_height
self.width = input_width
self.weights = weights
self.kernel_size = kernel_size2.forward前向传播
**squeeze():**squeeze()是 numpy 库中用于减少数组维度的函数。它会移除数组形状中大小为1的维度
**numpy():**将其他数据结构(比如 PyTorch 中的张量等)转换为 numpy 数组的操作。但有时候需要将其转换为 numpy 数组,以便利用 numpy 库强大的数学运算、数组操作等功能进行后续处理,或者是为了遵循某些接口要求。
**np.zeros():**np.zeros()是numpy 库中的一个函数,用于创建一个指定形状的全零数组。这个数组的数据类型可以是默认的(通常是 float64 ),也可以通过参数指定为其他数据类型。
**np.sum():**它的主要功能是对给定的张量(Tensor)沿着指定的维度(或者对整个张量所有元素)进行求和计算。例如,对于一个二维张量(可以类比为一个矩阵),你可以选择沿着行维度或者列维度进行求和,得到相应的行和或者列和;也可以不指定维度,直接对整个张量中的所有元素进行求和,得到一个标量结果。
python
def forward(self, x):
output = []
for kernel_weight in self.weights:
kernel_weight = kernel_weight.squeeze().numpy() #shape : 2x2
kernel_output = np.zeros((self.height - kernel_size + 1, self.width - kernel_size + 1))
for i in range(self.height - kernel_size + 1):
for j in range(self.width - kernel_size + 1):
window = x[i:i+kernel_size, j:j+kernel_size]
kernel_output[i, j] = np.sum(kernel_weight * window) # np.dot(a, b) != a * b 对位相乘
output.append(kernel_output)
return np.array(output)3.对比试验 构建样本
python
x = np.array([[0.1, 0.2, 0.3, 0.4],
[-3, -4, -5, -6],
[5.1, 6.2, 7.3, 8.4],
[-0.7, -0.8, -0.9, -1]]) #网络输入4.对比试验结果
python
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
"""
手动实现简单的神经网络
使用pytorch实现CNN
手动实现CNN
对比
"""
#一个二维卷积
class TorchCNN(nn.Module):
def __init__(self, in_channel, out_channel, kernel):
super(TorchCNN, self).__init__()
self.layer = nn.Conv2d(in_channel, out_channel, kernel, bias=False)
def forward(self, x):
return self.layer(x)
#自定义CNN模型
class DiyModel:
def __init__(self, input_height, input_width, weights, kernel_size):
self.height = input_height
self.width = input_width
self.weights = weights
self.kernel_size = kernel_size
def forward(self, x):
output = []
for kernel_weight in self.weights:
kernel_weight = kernel_weight.squeeze().numpy() #shape : 2x2
kernel_output = np.zeros((self.height - kernel_size + 1, self.width - kernel_size + 1))
for i in range(self.height - kernel_size + 1):
for j in range(self.width - kernel_size + 1):
window = x[i:i+kernel_size, j:j+kernel_size]
kernel_output[i, j] = np.sum(kernel_weight * window) # np.dot(a, b) != a * b 对位相乘
output.append(kernel_output)
return np.array(output)
x = np.array([[0.1, 0.2, 0.3, 0.4],
[-3, -4, -5, -6],
[5.1, 6.2, 7.3, 8.4],
[-0.7, -0.8, -0.9, -1]]) #网络输入
#torch实验
in_channel = 1
out_channel = 3
kernel_size = 2
torch_model = TorchCNN(in_channel, out_channel, kernel_size)
print(torch_model.state_dict())
torch_w = torch_model.state_dict()["layer.weight"]
# print(torch_w.numpy().shape)
torch_x = torch.FloatTensor([[x]])
output = torch_model.forward(torch_x)
output = output.detach().numpy()
print(output, output.shape, "torch模型预测结果\n")
print("---------------")
diy_model = DiyModel(x.shape[0], x.shape[1], torch_w, kernel_size)
output = diy_model.forward(x)
print(output, "diy模型预测结果")
八、网络结构 - Normalization 归一化层
归一化(Normalization)层在神经网络中用于对输入数据或中间层的特征进行标准化处理,使得数据的分布更加稳定和合理。其主要目的 是加速网络训练过程、提高模型的泛化能力和稳定性。
**公式:**数据减均值 除标准差,使数据进行归一化
bn层可以穿插在线性层或其他网络结构中
batch Normalization 批归一化
**原理:**在训练过程中,对一个小批次(batch)的数据进行归一化。
对于每个特征维度(比如卷积神经网络中的每个通道),计算该批次数据的均值和方差,然后将数据归一化到均值为 0、方差为1的分布。具体公式为 其中Xi是输入数据,μ是批次均值,σ是批次方差,€是一个很小的数(如 1e - 5)用于防止除零错误,yi 是归一化后的输出。
其中Xi是输入数据,μ是批次均值,σ是批次方差,€是一个很小的数(如 1e - 5)用于防止除零错误,yi 是归一化后的输出。
最后,还会进行一个线性变换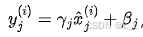 ,其中 γ 和 β 是可学习的参数,用于恢复数据的表达能力,因为简单的归一化可能会改变数据的原始分布特性。
,其中 γ 和 β 是可学习的参数,用于恢复数据的表达能力,因为简单的归一化可能会改变数据的原始分布特性。
横向算均值,再除以其标准差(方差开二次根号)
图像相关任务中使用较多

Layer Normalization 层归一化
原理: 是对每个样本的每个通道(在卷积神经网络中)或者每个特征维度(在一般网络中)独立地进行归一化。它计算每个样本内每个通道的均值和方差,与批归一化和层归一化的计算范围都不同。
纵向算均值,再除以其标准差(方差开二次根号)
NLP相关任务中使用较多

Instance Normalization 实例化归一化
原理: 是对每个样本的每个通道(在卷积神经网络中)或者每个特征维度(在一般网络中)独立地进行归一化。它计算每个样本内每个通道的均值和方差,与批归一化和层归一化的计算范围都不
同。
生成对抗网络中,图像生成比较多
九、网络结构 - Dropout层
model.train():声明模型是在训练模式,dropout层才会起作用
dropout层只在训练过程起作用,在实际预测过程不起作用
作用: 减少过拟合,按照指定概率,随机丢弃一些神经元(将其置为零)
其余元素乘以 **1 / (1-p)**进行放大
如何理解其作用:
1)强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,消除减弱了神经元节点间的联合适应性,增强了泛化能力
2)可以看做是一种模型平均,由于每次随机忽略的隐层节点都不同,这样就使每次训练的网络都是不一样的,每次训练都可以单做一个"新"的模型
3)启示: 计算方式并不是越复杂就越好
测试代码
python
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
"""
基于pytorch的网络编写
测试dropout层
"""
import torch
x = torch.Tensor([1,2,3,4,5,6,7,8,9])
# 50%的概率进行随机丢弃(置0),剩下的值有50%可能性进行翻倍用来训练
# 未被丢弃的神经元的输出会乘以一个缩放因子,通常是 1 / (1 - dropout_rate),其中 dropout_rate 是 Dropout 的概率
dp_layer = torch.nn.Dropout(0.4)
dp_x = dp_layer(x)
print(dp_x)