一、网络IO的基本介绍
在java提起网络编程的时候,我们一般是用到两种,一种是基本的网络IO,也就是阻塞IO,另一种就是NIO,非阻塞IO。对于NIO(多路复用IO),我们知道其通过一个线程就能管理处理多个IO事件。
我们要深入了解socket网络编程、还有NIO的话。我们就要明白TCP/IP网络协议、socket、select、epoll这些,因为不管是基本的网络IO,还是NIO其底层是都是对操作系统提供的socket、select、epoll相关接口函数的调用。要对网络编程socket、select、epoll这些有更深入的了解,我们需要通过c语言以及linux内核才能更彻底的了解。所以我们这篇文章主要是涉及到c语言、glib库、还有linux内核代码。对应c语言不是很升入了解的话,应该影响也不大,毕竟编程语言的基本逻辑结构都是大同小异的,对于c语法我也不是很了解,不过这篇文章我是debug了linux内核源码网络相关函数后写的,如果是直接看c语言的逻辑,我目前应该也是搞不明白的。
1)、TCP/IP网络协议:这个我们一般是比较了解的,不多解释了。
2)、socket:对于socket,其的解释是:Linux Socket接口是Linux操作系统提供的一套用于网络通信的API,它允许不同进程间进行数据交换。Socket接口抽象了复杂的底层网络通信细节,为开发者提供了一个简洁、统一的编程接口。
对于socket,更通俗的解释就是其是操作系统linux提供给用户层进行网络传输操作的接口。例如对于传输层TCP协议来说,其的三次握手、4次挥手、传输数据这些具体实现在linux都实现了,但我们知道linux内核态、用户态是隔开的。
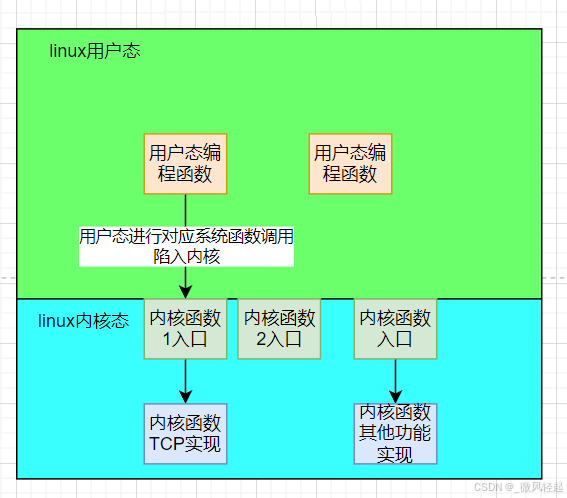
linux内核与硬件的网络传输交互
例如对于TCP协议的具体实现,内核已经写好了,所以对于linux网络编程,内核对网络通信进行抽象,在网络协议(例如TCP/IP)的具体实现上面,抽象封装了几个接口出来,并提供对应内核入口函数出来(用户态与内核态是隔开的,用户态也不能随便调用内核态的函数,除非内核提供了对应的内核函数入口),让你不用关注网络协议的实现,只需要按这几个提供的内核入口就能进行网络传输操作。
例如我们网络编程最基本的函数,开启socket获取句柄,socket(AF_INET, SOCK_STREAM, 0),这个我们看到glib(c库,类似我们java native 调jvm方法的概念),这个就是封装去调linux内部入口函数,这个SOCKETCALL就是进行内核调用,这个是内核提供出来的函数。
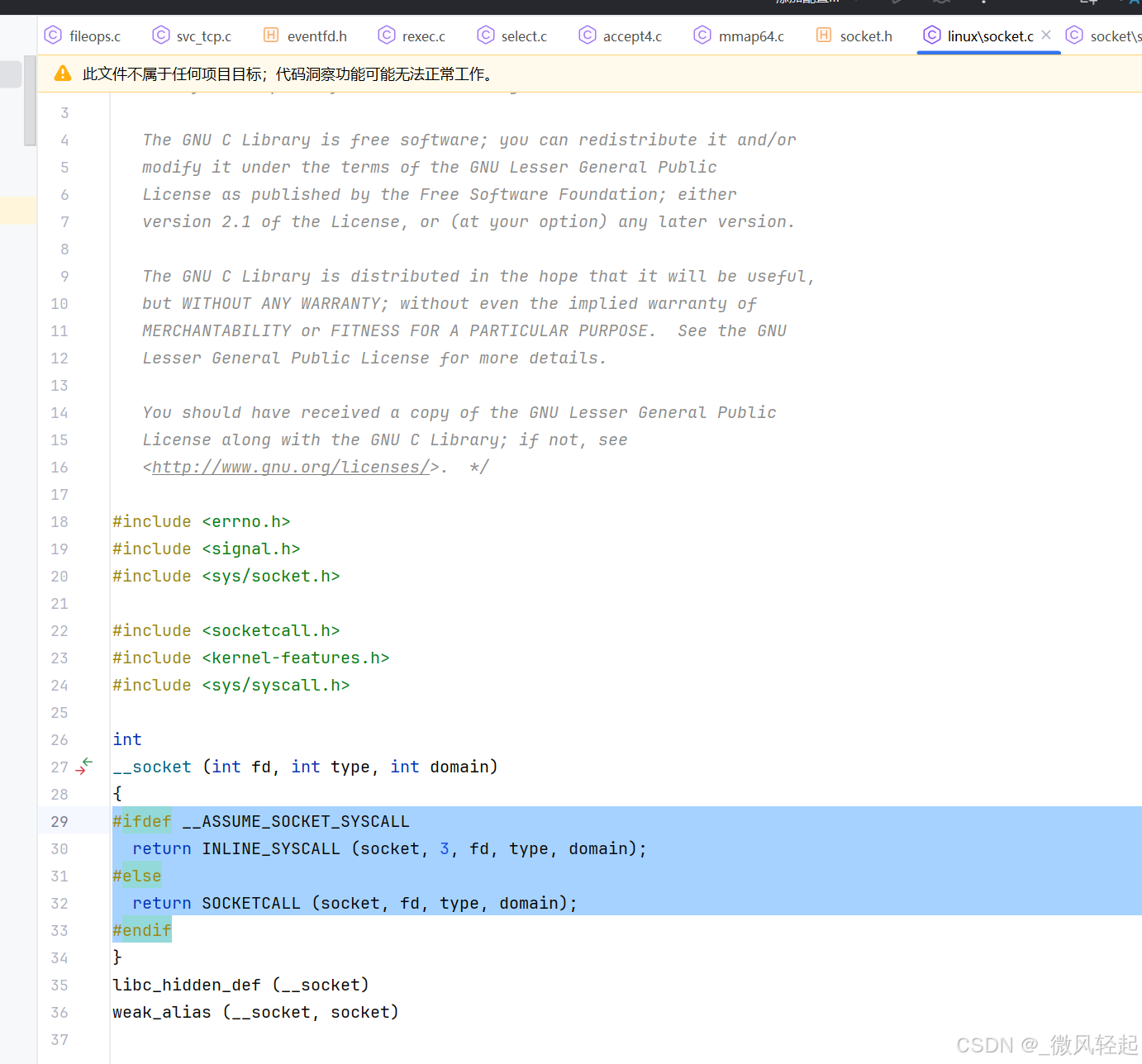
这个对应到linux就是内核提供的这个入口函数
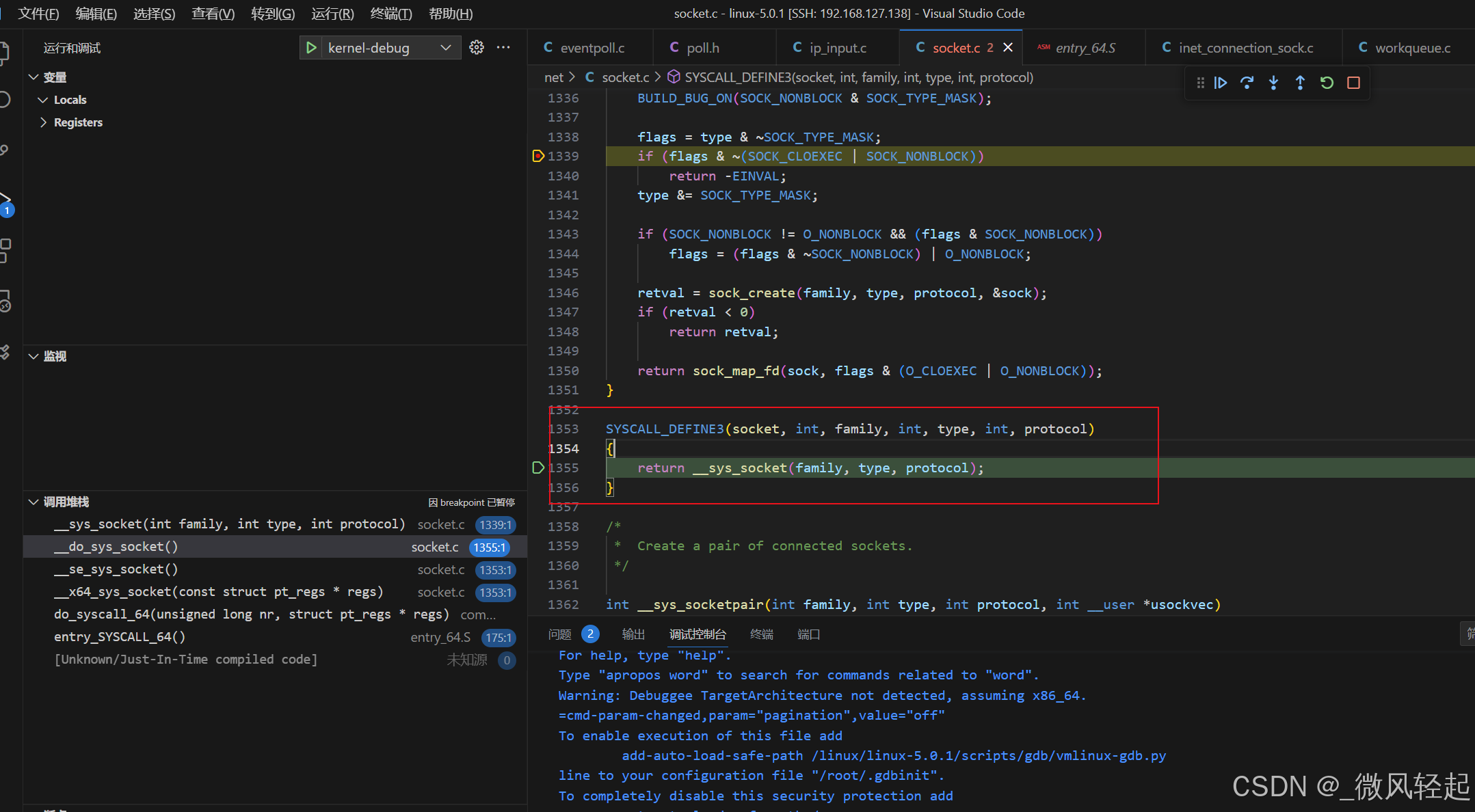
我们再看do_syscall_64(unsigned long nr, struct pt_regs *regs),这个是linux用户态系统调用陷入内核的入口,可以看到这个是根据传入的nr内核入口函数编码,找到对应的入口函数进行处理。
二、c语言对于网络编程socket、select、epoll的使用案例
下面我们来看这两种的简单使用案例,主要是服务端的:
对于基本的IO案例:
c
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <string.h>
#define PORT 5116
#define BUF_SIZE 256
int main(int argc, char** argv) {
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd == -1) {
printf("created socket error\n");
return 0;
}
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(PORT);
addr.sin_addr.s_addr = INADDR_ANY; // 表示使用本机IP
int len = sizeof(addr);
if (-1 == bind(fd, (struct sockaddr*)&addr, len)) {
printf("bind socket fail\n");
close(fd);
return 0;
}
listen(fd, 10);
int clientFd;
struct sockaddr_in clientAddr;
int clientLen = sizeof(clientAddr);
printf("The server is waiting for connect...\n");
clientFd = accept(fd, (struct sockaddr*)&clientAddr, &clientLen);
char szMsg[BUF_SIZE];
int n;
if (clientFd > 0) {
printf("Accept client from %s:%d\n", inet_ntoa(clientAddr.sin_addr), clientAddr.sin_port);
while ((n = read(clientFd, szMsg, BUF_SIZE)) > 0) {
szMsg[n] = 0;
printf("Recv Msg : %s\n", szMsg);
}
close(clientFd);
}
close(fd);
return 0;
}对于非阻塞select使用案例
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <sys/time.h>
#include <sys/types.h>
#include <sys/select.h>
#define PORT 5116
#define MAX_CLIENTS 10
#define BUF_SIZE 256
int main() {
int master_socket, addrlen, new_socket, client_socket[MAX_CLIENTS], activity, valread, sd;
int max_sd;
struct sockaddr_in address;
fd_set readfds;
char buffer[BUF_SIZE];
// 创建主socket
if ((master_socket = socket(AF_INET, SOCK_STREAM, 0)) == 0) {
perror("socket failed");
exit(EXIT_FAILURE);
}
// 设置socket选项
int enable = 1;
if (setsockopt(master_socket, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &enable, sizeof(int)) < 0) {
perror("setsockopt");
close(master_socket);
exit(EXIT_FAILURE);
}
// 设置地址和端口
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
addrlen = sizeof(address);
// 绑定socket到地址和端口
if (bind(master_socket, (struct sockaddr *)&address, sizeof(address)) < 0) {
perror("bind failed");
close(master_socket);
exit(EXIT_FAILURE);
}
// 监听连接
if (listen(master_socket, 3) < 0) {
perror("listen");
close(master_socket);
exit(EXIT_FAILURE);
}
// 初始化客户端socket数组
for (int i = 0; i < MAX_CLIENTS; i++) {
client_socket[i] = 0;
}
// 主循环
while (1) {
// 初始化readfds
FD_ZERO(&readfds);
// 添加主socket到readfds
FD_SET(master_socket, &readfds);
max_sd = master_socket;
// 添加所有客户端socket到readfds
for (int i = 0; i < MAX_CLIENTS; i++) {
// 如果客户端socket是有效的,则添加到readfds
sd = client_socket[i];
if (sd > 0)
FD_SET(sd, &readfds);
// 查找最大的socket描述符
if (sd > max_sd)
max_sd = sd;
}
// 等待读事件
activity = select(max_sd + 1, &readfds, NULL, NULL, NULL);
if ((activity < 0) && (errno != EINTR)) {
printf("select error");
}
// 处理读事件
if (FD_ISSET(master_socket, &readfds)) {
if ((new_socket = accept(master_socket, (struct sockaddr *)&address, (socklen_t*)&addrlen)) < 0) {
perror("accept");
exit(EXIT_FAILURE);
}
printf("New connection , socket fd is %d , ip is : %s , port : %d \n", new_socket, inet_ntoa(address.sin_addr), ntohs(address.sin_port));
// 将新连接添加到客户端socket数组
for (int i = 0; i < MAX_CLIENTS; i++) {
if (client_socket[i] == 0) {
client_socket[i] = new_socket;
printf("Adding to list of sockets as %d\n", i);
break;
}
}
}
// 处理客户端的读事件
for (int i = 0; i < MAX_CLIENTS; i++) {
sd = client_socket[i];
if (FD_ISSET(sd, &readfds)) {
if ((valread = read(sd, buffer, BUF_SIZE)) == 0) {
// 连接关闭
getpeername(sd, (struct sockaddr*)&address, (socklen_t*)&addrlen);
printf("Host disconnected , ip %s , port %d \n", inet_ntoa(address.sin_addr), ntohs(address.sin_port));
close(sd);
client_socket[i] = 0;
} else {
buffer[valread] = '\0';
send(sd, buffer, strlen(buffer), 0);
printf("Received message: %s\n", buffer);
}
}
}
}
return 0;
} 对于非阻塞的epoll使用案例
c
#include <stdio.h>
............
#define MAX_EVENTS 10
#define BUFFER_SIZE 1024
#define PORT 8080
void set_nonblocking(int sockfd) {
int flags = fcntl(sockfd, F_GETFL, 0);
fcntl(sockfd, F_SETFL, flags | O_NONBLOCK);
}
int main() {
int listen_fd, conn_fd, epoll_fd;
struct sockaddr_in server_addr;
struct epoll_event ev, events[MAX_EVENTS];
// 创建监听套接字
listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_fd == -1) {
perror("socket");
exit(EXIT_FAILURE);
}
// 设置监听套接字为非阻塞模式
set_nonblocking(listen_fd);
// 绑定地址和端口
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(PORT);
if (bind(listen_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
perror("bind");
close(listen_fd);
exit(EXIT_FAILURE);
}
// 开始监听
if (listen(listen_fd, SOMAXCONN) == -1) {
perror("listen");
close(listen_fd);
exit(EXIT_FAILURE);
}
// 创建 epoll 实例
epoll_fd = epoll_create1(0);
if (epoll_fd == -1) {
perror("epoll_create1");
close(listen_fd);
exit(EXIT_FAILURE);
}
// 添加监听套接字到 epoll 实例中
ev.events = EPOLLIN;
ev.data.fd = listen_fd;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev) == -1) {
perror("epoll_ctl: listen_fd");
close(listen_fd);
close(epoll_fd);
exit(EXIT_FAILURE);
}
// 事件循环
while (1) {
int n = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
if (n == -1) {
perror("epoll_wait");
close(listen_fd);
close(epoll_fd);
exit(EXIT_FAILURE);
}
for (int i = 0; i < n; ++i) {
if (events[i].data.fd == listen_fd) {
// 新的连接
while ((conn_fd = accept(listen_fd, NULL, NULL)) != -1) {
set_nonblocking(conn_fd);
ev.events = EPOLLIN;
ev.data.fd = conn_fd;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, conn_fd, &ev) == -1) {
perror("epoll_ctl: conn_fd");
close(conn_fd);
}
}
if (errno != EAGAIN && errno != EWOULDBLOCK) {
perror("accept");
close(listen_fd);
close(epoll_fd);
exit(EXIT_FAILURE);
}
} else {
// 处理客户端连接上的数据
int fd = events[i].data.fd;
char buffer[BUFFER_SIZE];
ssize_t count = read(fd, buffer, sizeof(buffer));
if (count == -1) {
perror("read");
close(fd);
} else if (count == 0) {
// 客户端关闭连接
close(fd);
} else {
// 回显数据
if (write(fd, buffer, count) != count) {
perror("write");
close(fd);
}
}
}
}
}
close(listen_fd);
close(epoll_fd);
return 0;
} 这里我贴的是用AI写的c语言的,对于对应的还是也带了注释。上面的demo从基本的socket,到select以及后面的epoll是逐步递进的,并且我们看的话,对于基本socket网络函数对应的socket()、bind()、listener()、accpet()函数,在后面的select、epoll相关demo也是有使用的。这里有一个关键我们需要明白,对于TCP协议来说,socket相关的函数是在TCP协议实现上面抽象出来几个socket函数用来网络编程的,例如listern进行网络端口监听,accept用来等待客户端连接,这个是TCP网络编程本身就要这么做的,所以其实不管我们后面使用的select、还是epoll,其本身都是内核层面对socket基本网络接口的再次加强、封装实现,用来提升网络通信的处理效率,网络通信还是建立在socket()创建套接字、bind()&listener()服务器监听、accpet()等待连接上的。最开始我对linux下一切皆文件,还有socket、select、epoll的了解不够,一直以为socket、select、epoll是完全不同的网络底层定义逻辑概念,其实select、epoll是对socket再次具体使用,并不是与socket并列的网络编程定义。
下面我们就来具体看下这几个案例的基本逻辑
1、socket函数网络使用
首先我们简化demo案例,看下其整体的逻辑架构
#define PORT 5116
#define BUF_SIZE 256
int main(int argc, char** argv) {
int fd = socket(AF_INET, SOCK_STREAM, 0);
............
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(PORT);
addr.sin_addr.s_addr = INADDR_ANY; // 表示使用本机IP
int len = sizeof(addr);
if (-1 == bind(fd, (struct sockaddr*)&addr, len)) {
printf("bind socket fail\n");
...........
}
listen(fd, 10);
int clientFd;
.............
clientFd = accept(fd, (struct sockaddr*)&clientAddr, &clientLen);
char szMsg[BUF_SIZE];
int n;
if (clientFd > 0) {
printf("Accept client from %s:%d\n", inet_ntoa(clientAddr.sin_addr), clientAddr.sin_port);
.................
}
} 这个交互是一个最基本的网络编程交互,下面的select、epoll也是建立在这个基本的基础上的
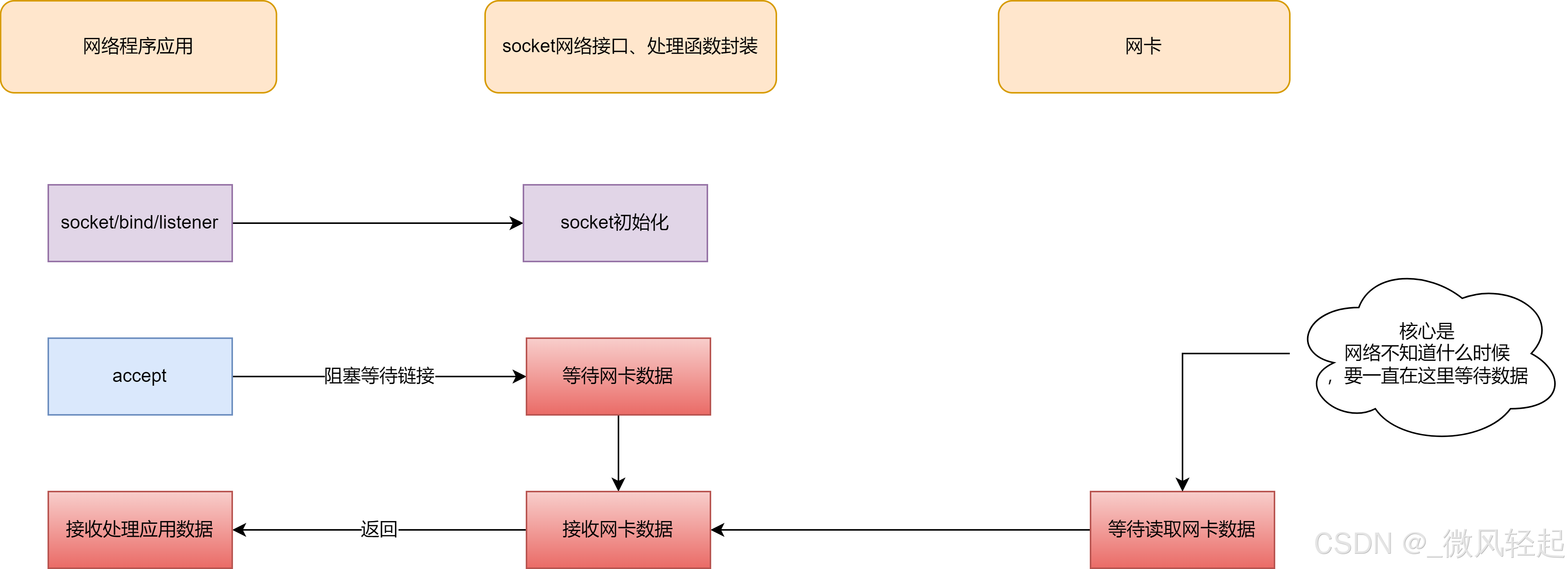
在这个交互逻辑中,由于accept/read是阻塞的,所以我们如果要进行多个socket连接管理的话,是需要多个线程,并且在socket关闭连接前,这个线程是不能被释放的。
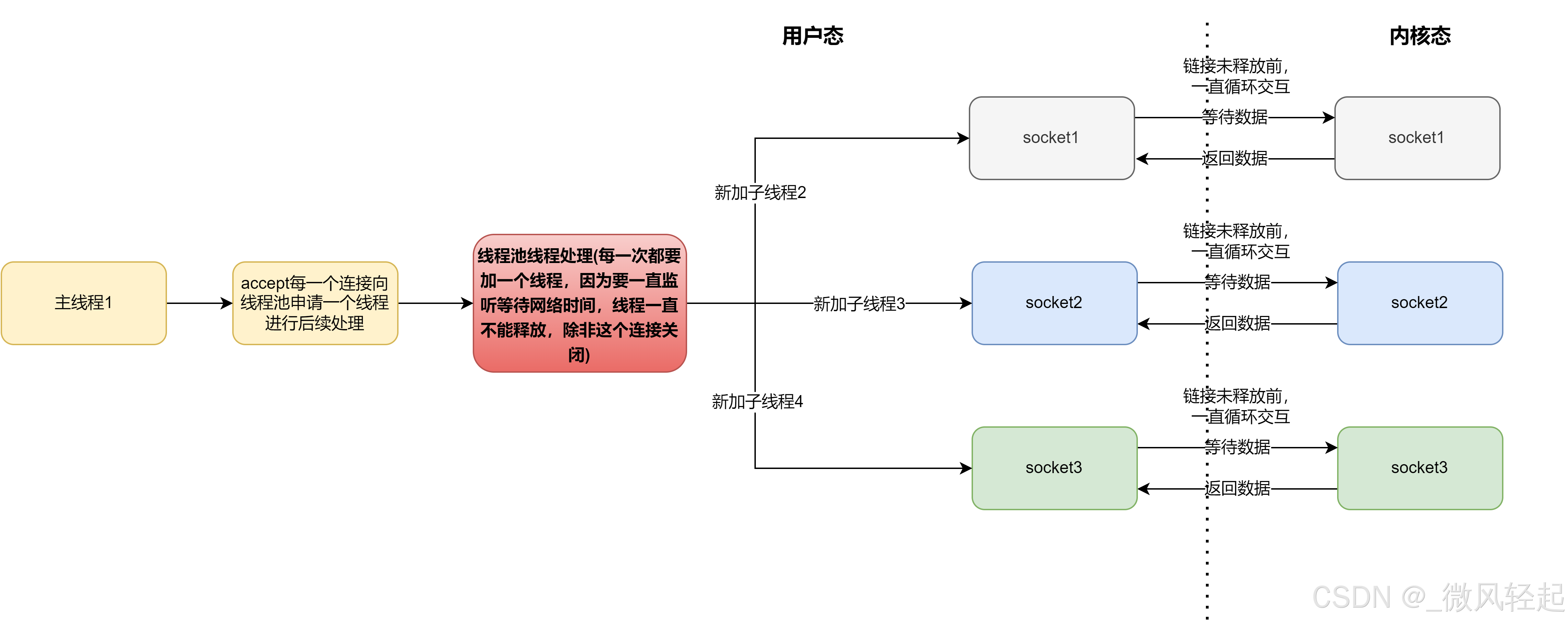
2、select+socket函数使用
c
#define PORT 5116
#define MAX_CLIENTS 10
#define BUF_SIZE 256
int main() {
int master_socket, addrlen, new_socket, client_socket[MAX_CLIENTS], activity, valread, sd;
int max_sd;
struct sockaddr_in address;
fd_set readfds;
char buffer[BUF_SIZE];
// 创建主socket
if ((master_socket = socket(AF_INET, SOCK_STREAM, 0)) == 0) {
exit(EXIT_FAILURE);
}
// 设置socket选项
int enable = 1;
if (setsockopt(master_socket, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &enable, sizeof(int)) < 0) {
...........
}
// 设置地址和端口
..........
// 绑定socket到地址和端口
if (bind(master_socket, (struct sockaddr *)&address, sizeof(address)) < 0) {
exit(EXIT_FAILURE);
}
// 监听连接
if (listen(master_socket, 3) < 0) {
.......
}
// 主循环
while (1) {
// 初始化readfds
...........
// 添加所有客户端socket到readfds
for (int i = 0; i < MAX_CLIENTS; i++) {
// 如果客户端socket是有效的,则添加到readfds
sd = client_socket[i];
if (sd > 0)
FD_SET(sd, &readfds);
// 查找最大的socket描述符
if (sd > max_sd)
max_sd = sd;
}
// 等待读事件
activity = select(max_sd + 1, &readfds, NULL, NULL, NULL);
............
// 处理读事件
if (FD_ISSET(master_socket, &readfds)) {
if ((new_socket = accept(master_socket, (struct sockaddr *)&address, (socklen_t*)&addrlen)) < 0) {
perror("accept");
exit(EXIT_FAILURE);
}
// 将新连接添加到客户端socket数组
for (int i = 0; i < MAX_CLIENTS; i++) {
if (client_socket[i] == 0) {
client_socket[i] = new_socket;
printf("Adding to list of sockets as %d\n", i);
break;
}
}
}
// 处理客户端的读事件
for (int i = 0; i < MAX_CLIENTS; i++) {
sd = client_socket[i];
if (FD_ISSET(sd, &readfds)) {
if ((valread = read(sd, buffer, BUF_SIZE)) == 0) {
// 连接关闭
close(sd);
} else {
printf("Received message: %s\n", buffer);
}
}
}
}
} 这里我们有一个数组client_socket[MAX_CLIENTS],有accept新连接socket,就添加到client_socket进行管理。
同时,我们会调用select(max_sd + 1, &readfds, NULL, NULL, NULL)进行遍历readfds中的句柄哪些是可读的了(所以select在linux内部要遍历所有的socket,看下哪些是可读的了,进行对应设置到readfds)。然后再通过for (int i = 0; i < MAX_CLIENTS; i++)再次遍历(MAX_CLIENTS,是当前管理的句柄编号的最大值),使用FD_ISSET(sd, &readfds)判断当前句柄是不是可读的。
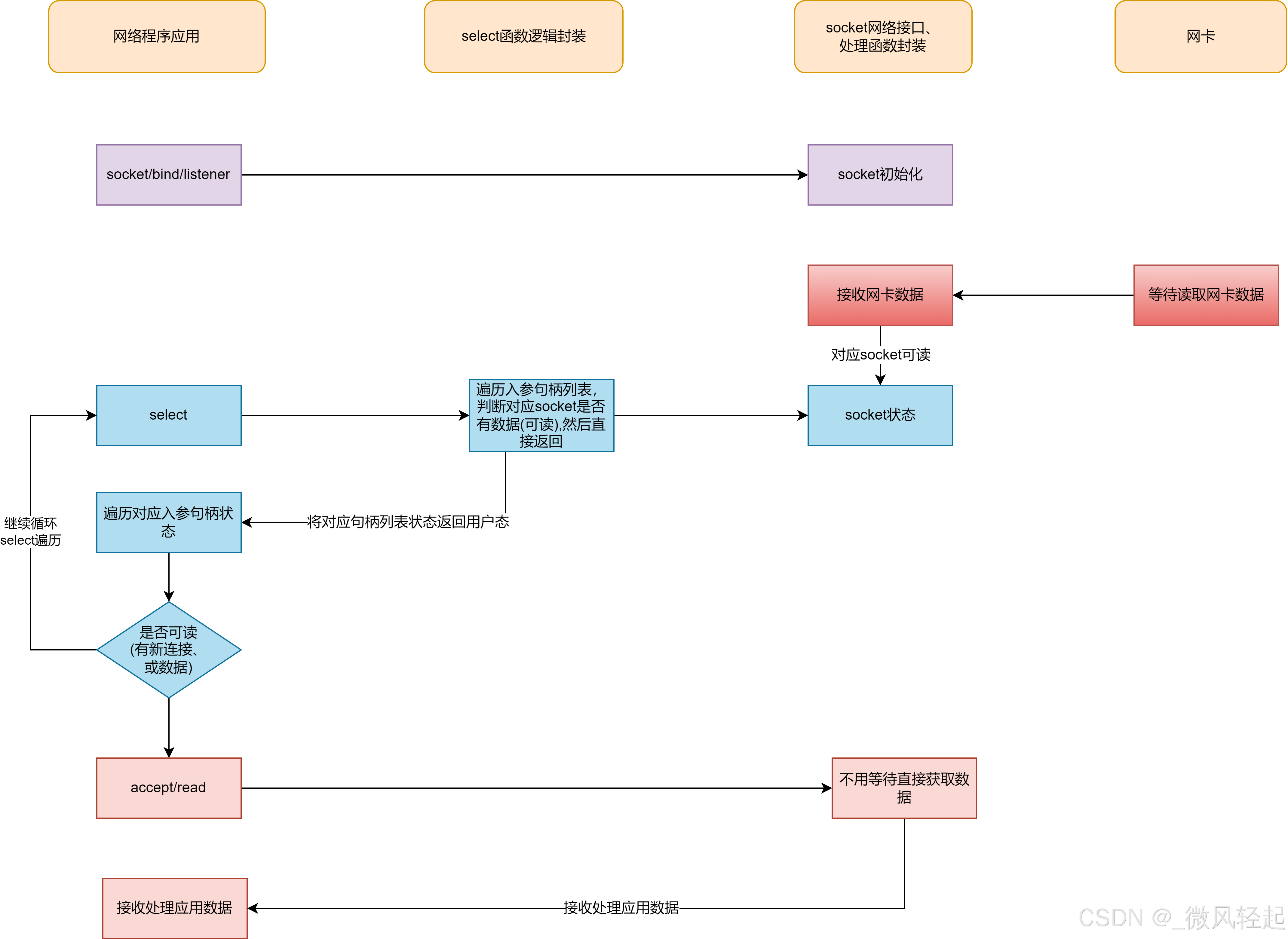
所以这前面进程的socket模型与这个select+socket模型中,由前面阻塞式的变成了select查询交互直接返回了,同时我们可以在一个线程中管理多个socket了,因为不是阻塞式的(不过我们在同时读取多个socket的时候,要不阻塞还是要多线程,但由于我们循环select,就是说,在处理完后,这个处理线程可以直接释放了,等待下次select再次知道它有数据了),
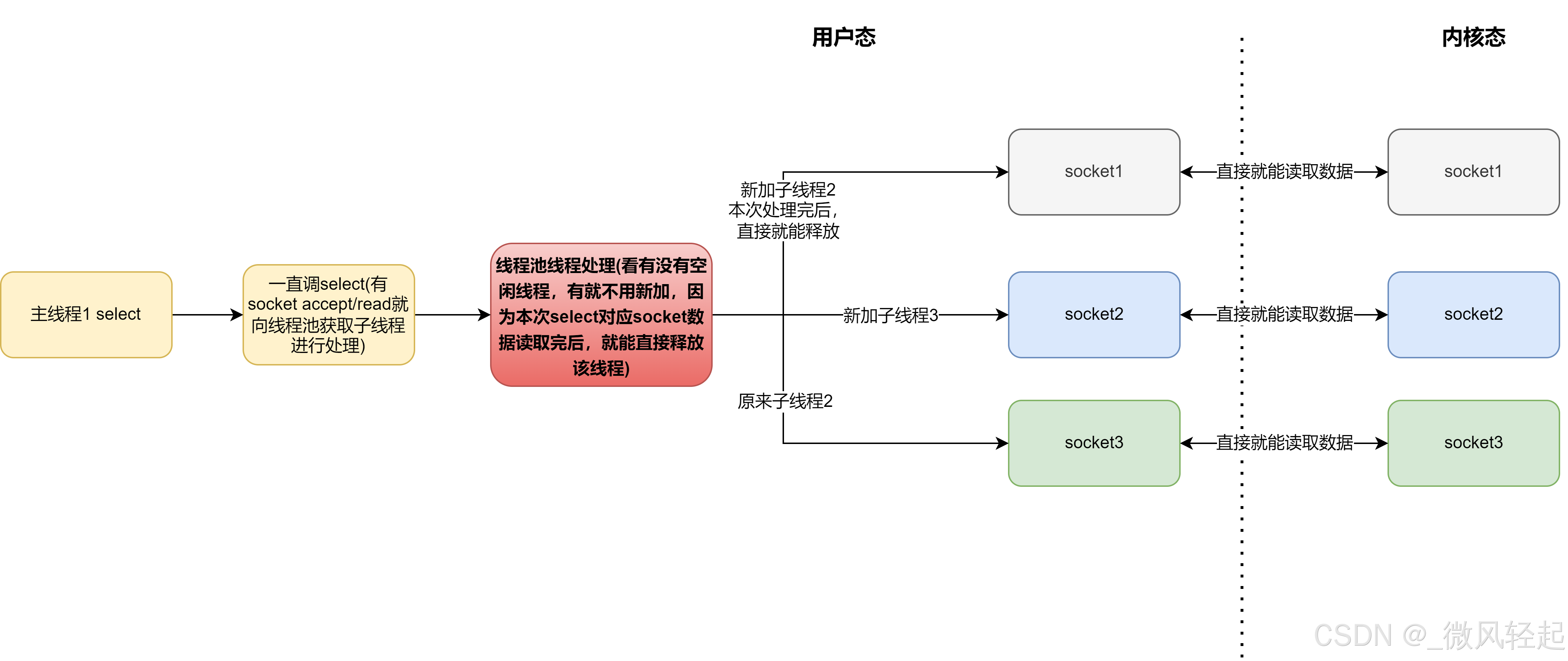
这种交互逻辑比我们前面基本的socket,其select是非阻塞的了,由遍历socket状态直接返回替代了前面要一直accept到有数据才能返回,并且我们还可以回收用户态的线程,不需要为每个socket都分配一个线程。但这种交互,就是需要遍历每个socket的状态,不单在用户态,内核态也要遍历一次。这个如果socket多了,处理效率就不好。所以这个交互更进一步就是epoll。
3、socket+epoll函数使用
c
#define MAX_EVENTS 10
#define BUFFER_SIZE 1024
#define PORT 8080
void set_nonblocking(int sockfd) {
int flags = fcntl(sockfd, F_GETFL, 0);
fcntl(sockfd, F_SETFL, flags | O_NONBLOCK);
}
int main() {
int listen_fd, conn_fd, epoll_fd;
struct sockaddr_in server_addr;
struct epoll_event ev, events[MAX_EVENTS];
// 创建监听套接字
listen_fd = socket(AF_INET, SOCK_STREAM, 0);
// 设置监听套接字为非阻塞模式
set_nonblocking(listen_fd);
// 绑定地址和端口
if (bind(listen_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
exit(EXIT_FAILURE);
}
// 开始监听
if (listen(listen_fd, SOMAXCONN) == -1) {
exit(EXIT_FAILURE);
}
// 创建 epoll 实例
epoll_fd = epoll_create1(0);
// 添加监听套接字到 epoll 实例中
ev.events = EPOLLIN;
ev.data.fd = listen_fd;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev) == -1) {
exit(EXIT_FAILURE);
}
// 事件循环
while (1) {
int n = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
if (n == -1) {
exit(EXIT_FAILURE);
}
for (int i = 0; i < n; ++i) {
if (events[i].data.fd == listen_fd) {
// 新的连接
while ((conn_fd = accept(listen_fd, NULL, NULL)) != -1) {
set_nonblocking(conn_fd);
ev.events = EPOLLIN;
ev.data.fd = conn_fd;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, conn_fd, &ev) == -1) {
perror("epoll_ctl: conn_fd");
close(conn_fd);
}
}
} else {
// 处理客户端连接上的数据
int fd = events[i].data.fd;
char buffer[BUFFER_SIZE];
ssize_t count = read(fd, buffer, sizeof(buffer));
}
}
}
return 0;
} 可以看到在这种交互逻辑中,我们的epoll_wait函数会返回n,就表示有n个socket事件需要处理,然后只需要处理events数组的前n条就可以了,不用再遍历的。它基本原理就是,在内核态通过eventpoll数据结构去维护所有的socket事件(封装到对应的epitem数据结构中),当socket对应事件有数据了,通过回调,将其添加到eventpoll数据结构的rdlist(就绪列表)变量中,用户态每次获取rdlist的数据就可以了,就不用遍历了。
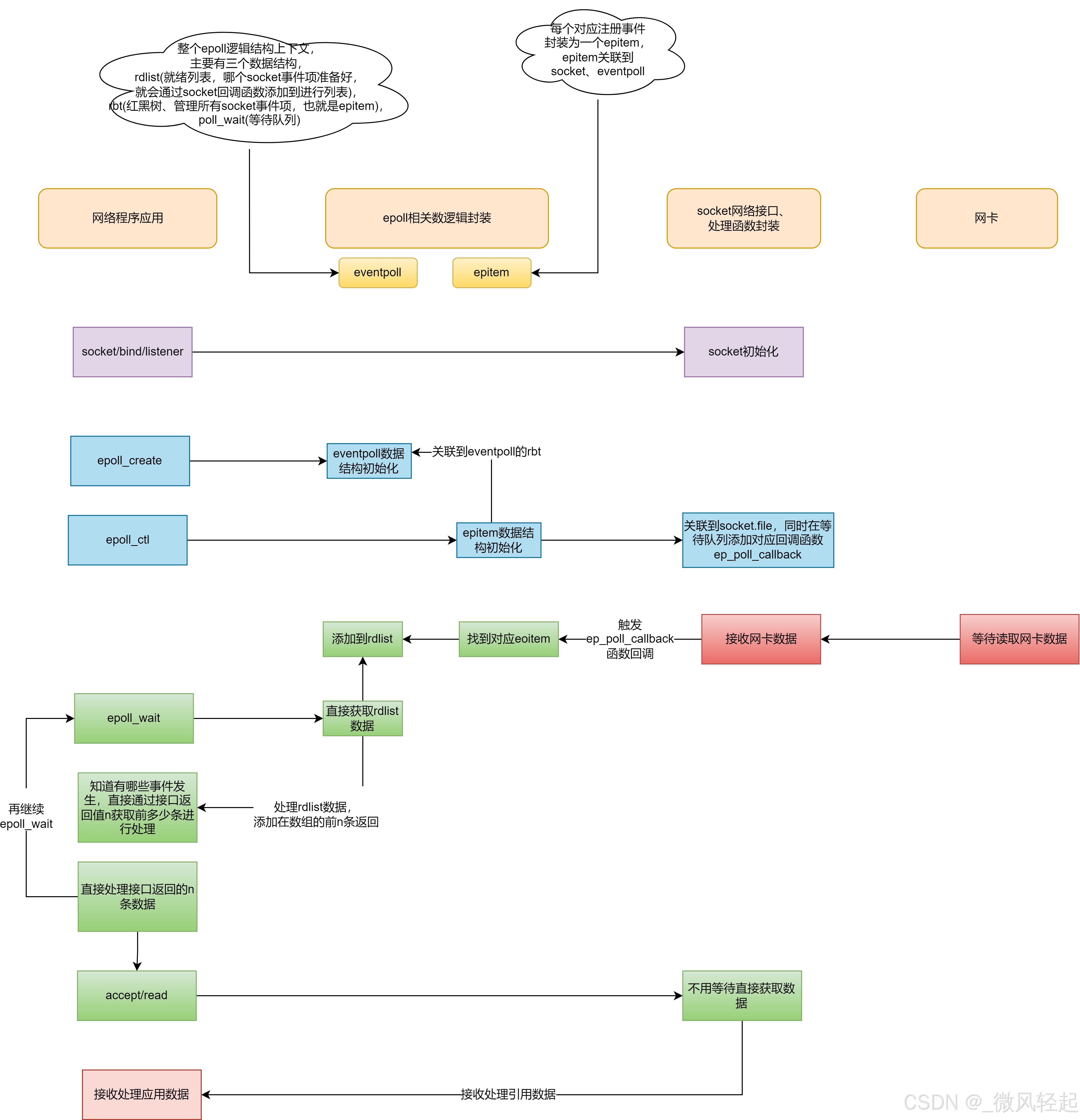
下面我们就来从API使用、以及底层源码来看下epoll的具体实现过程
一、epoll逻辑内核debug
下面我们就来通过上面epoll 使用的demo案例,debug下epoll在内核是怎么流转的。虽然我们是java程序员,对c语言的一些不是很清楚。但这个的话,我们并不要写,只是看其的函数调用。我们了解其的一些函数基本作用以及流转逻辑就可以了,不要扣一些具体的细节。
1、代码基本流转逻辑
对于上面epoll的代码解释:
1)、其首先是通过listen_fd = socket(AF_INET, SOCK_STREAM, 0)创建了一个socket,然后拿到了这个socket对应的句柄,然后再通过bind(listen_fd, (struct sockaddr*)&server_addr, sizeof(server_addr))则将这个socket绑定了服务端对应的Port端口,之后通过listen(listen_fd, SOMAXCONN)函数,就进行对应端口的监听。
2)、再之后的epoll_create1(0)就是进行对应的epoll相关的处理初始化,epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev)就是在当前句柄上,我们对哪些事件感兴趣,如果发生了这些事件,你要给我反馈,也就是int n = epoll_wait(epoll_fd, events, MAX_EVENTS, -1)的时候,查询有没有这些事件发生,如果有这些事件发生,就将这些事件添加到入参events中,然后发生了几个这些事件,就通过返回参数n进行返回,然后我们再对events进行对应遍历处理。例如对于events[i].data.fd == listen_fd也就是发生时间对应的句柄是等于listen_fd,也就是监听句柄,就表明有了新连接,或者其他读、写事件,我们则进行其他的处理。
流转逻辑说明
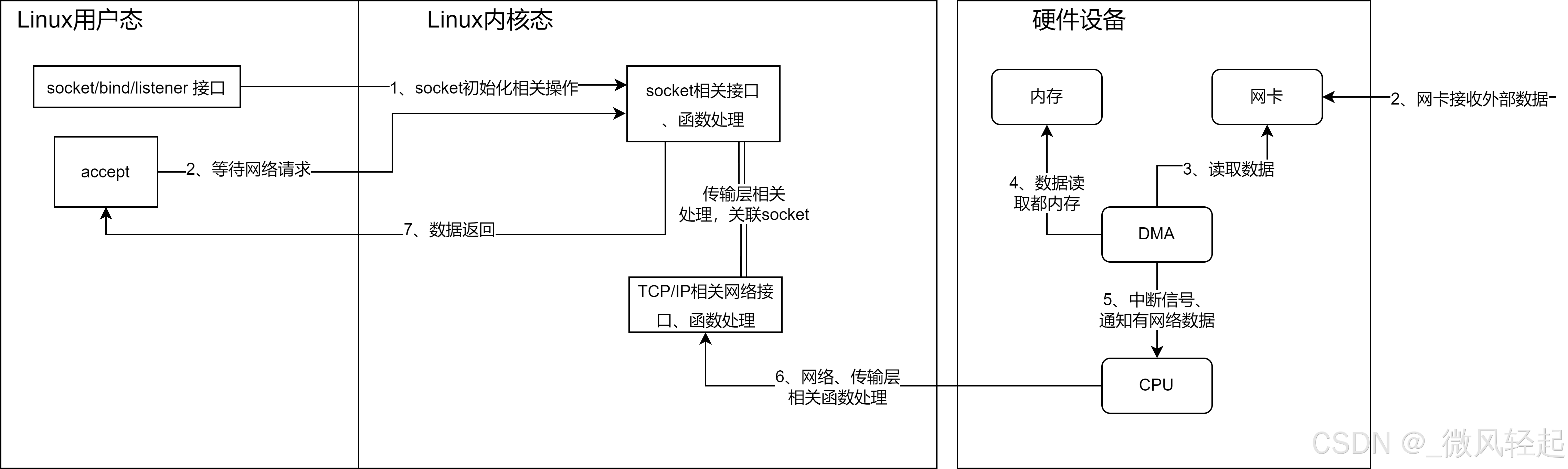
在linux中,一切皆文件,上面这个逻辑我们简单理解,就是我们向linux申请了一个文件空间,其返回了这个文件的名称也就是句柄,然后linux内核对于在这个网络端口Port获取到的网络数据都是会推送到这个文件空间,然后去做对应的数据处理。当然这个我只是简单形象的说明。
这个更专业的表述就是,网卡会接受到网络数据,然后回触发操作系统的中断程序,中断程序就会处理这个程序,会将这些数据封装为到一个个sk_buff数据结构中,交给linux内核中TCP/IP协议进行对应的网络处理,在TCP协议进行对应处理后交个对应的socket来处理,到达socket后,socket在唤醒epoll底层的处理逻辑,这个我们下面就会来看这一部分,其底层是等待队列来处理的,socket通过唤醒等待队列,等待队列通过对应事件的回调,就表明当前事件有数据了,这个ep_poll_callback就是对应的回调函数。
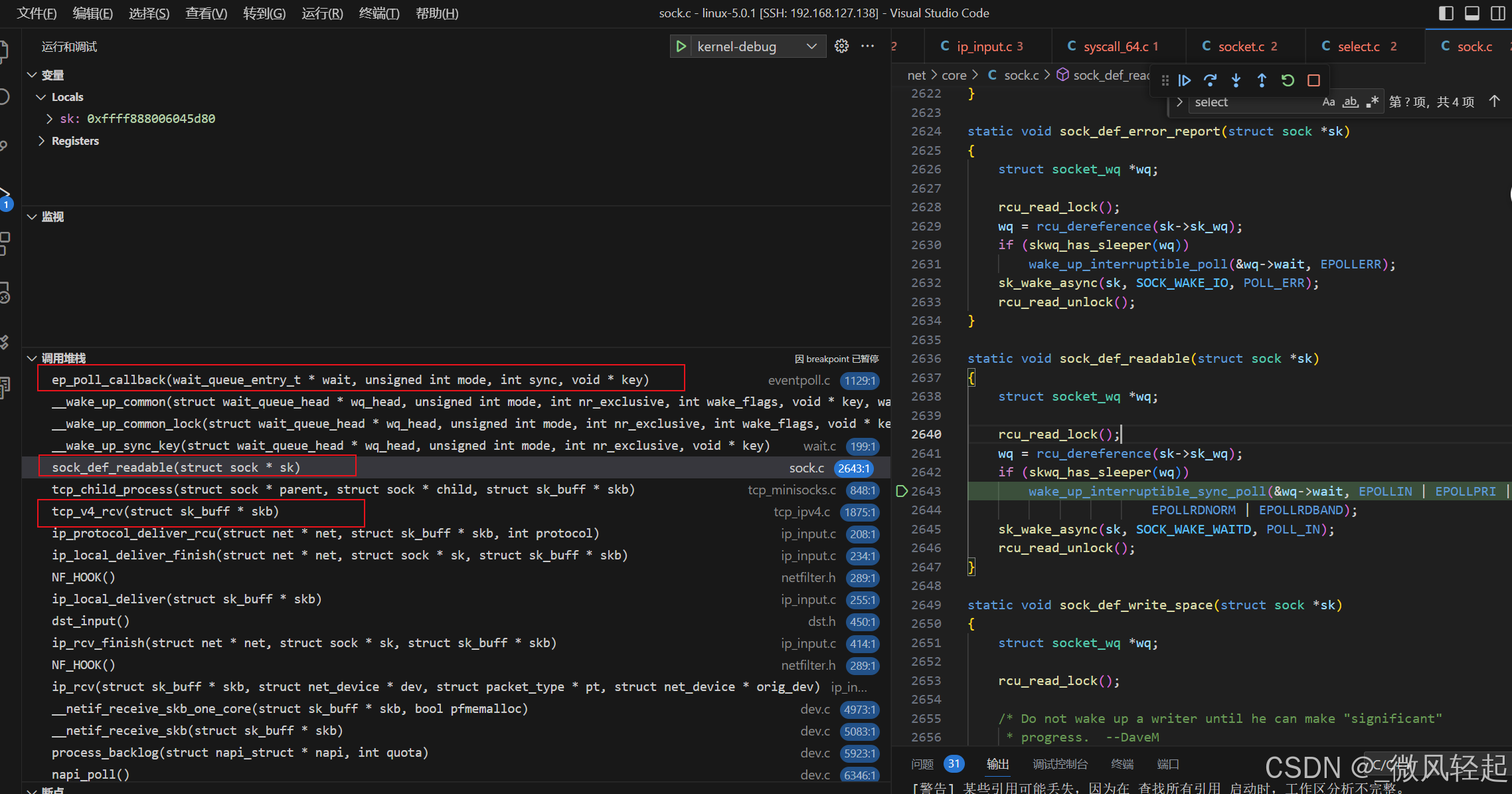
在ep_poll_callback就会将当前就绪事件添加到就绪队列中,然后在通过epoll_wait函数进行查询时,就能知道当前时间准备好了。
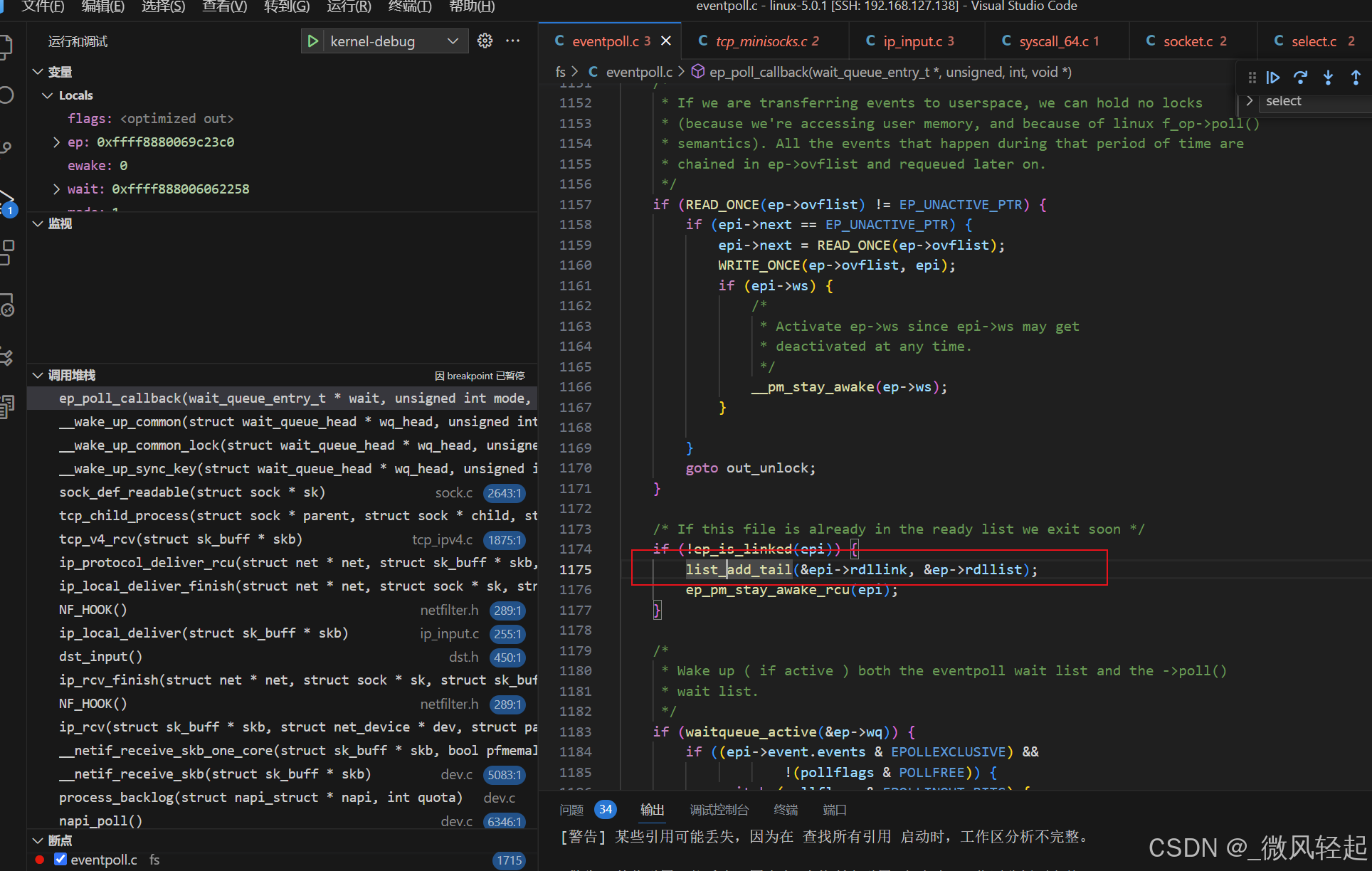
2、linux内核源码分析
下面我们就从内核源码的角度来具体分析下epoll使用的流转过程,整个流转过程过程如下
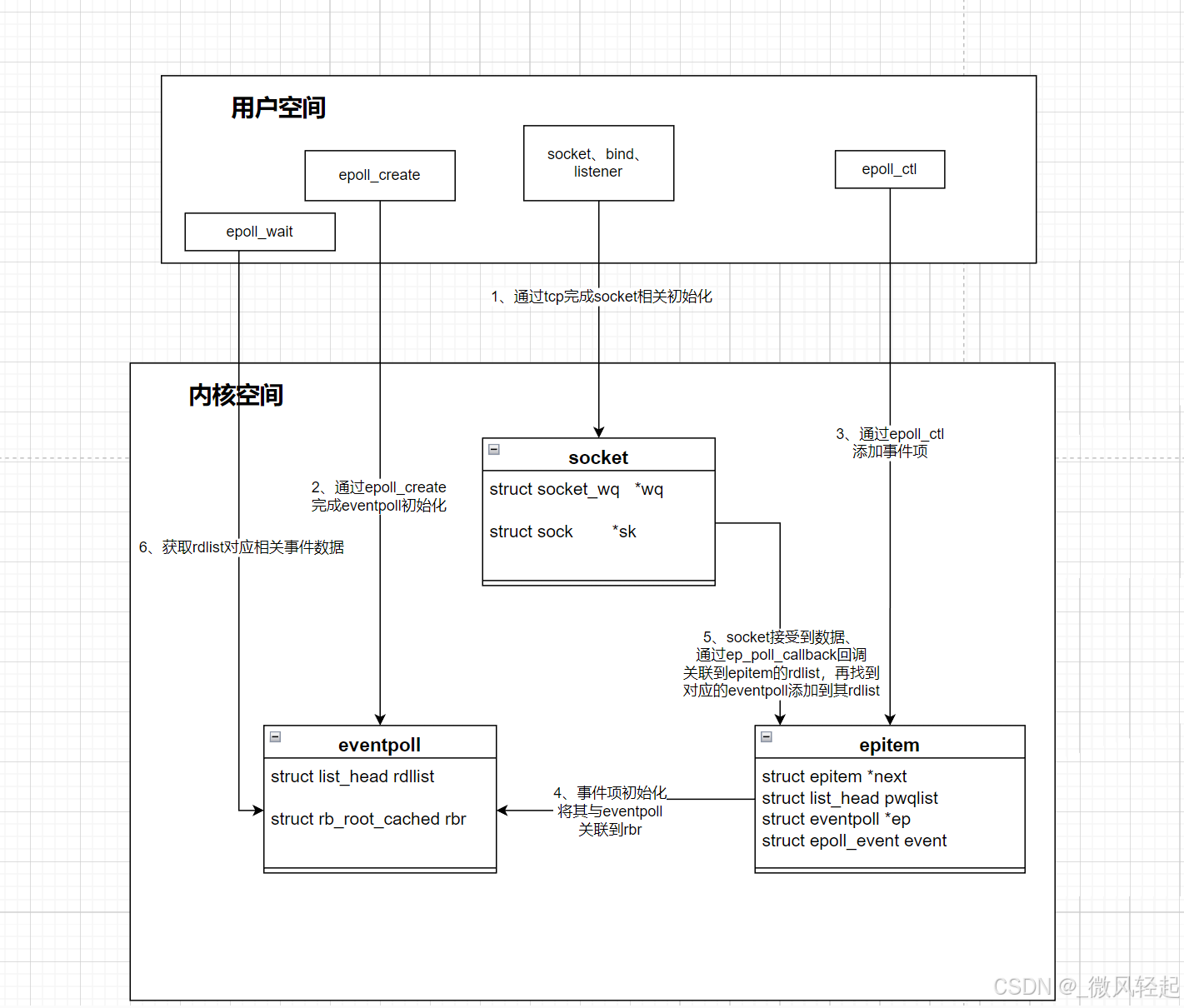
1、linux内核调用
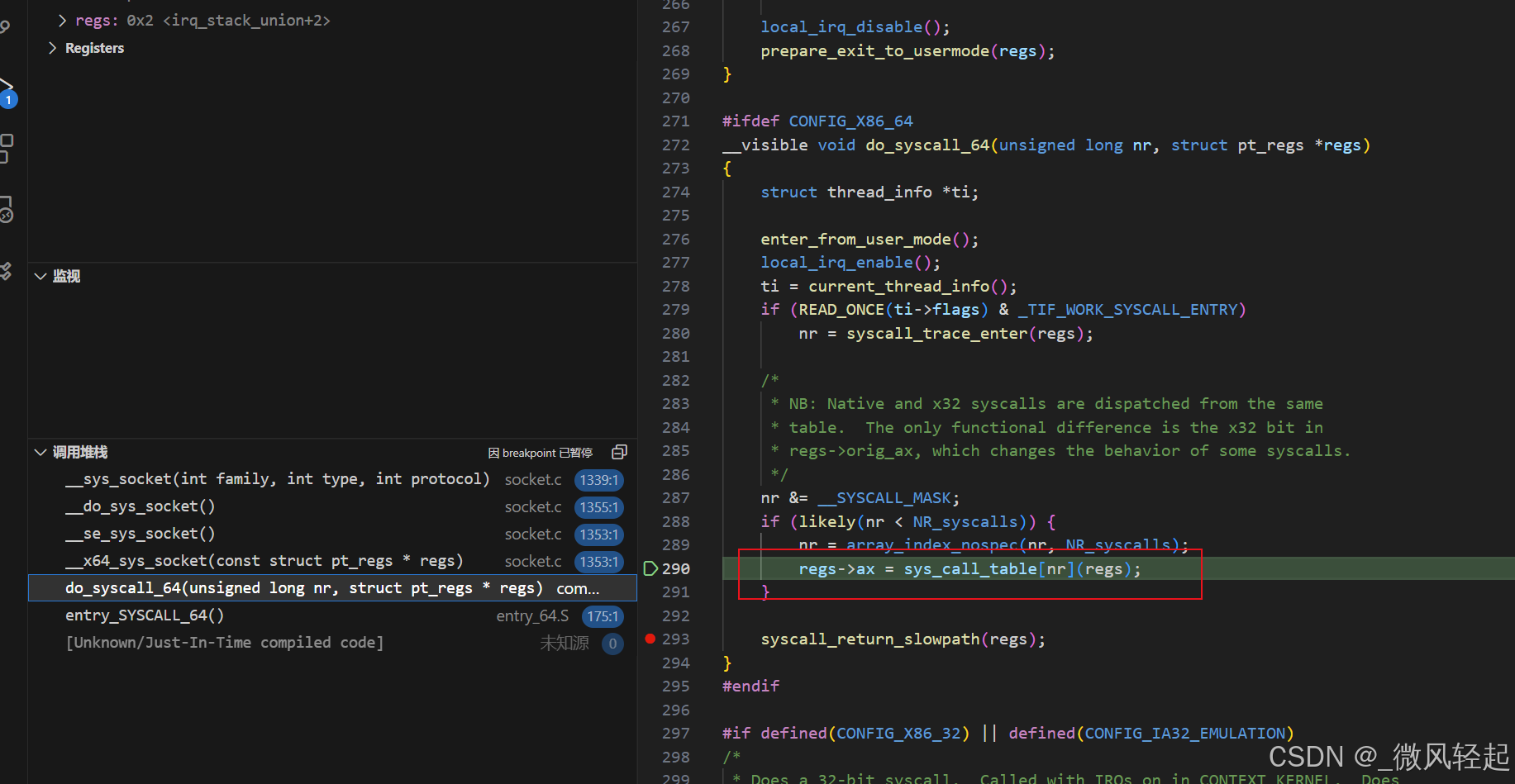
这里我们看下entry_64.S以及do_syscall_64逻辑,我们通过socket(AF_INET, SOCK_STREAM, 0)创建socket的时候,进行了内核调用,可以看到这里的sys_call_table[nr](regs),传入了入参nr,其对应到sys_call_table数组的其中一个内核函数进行对应处理。
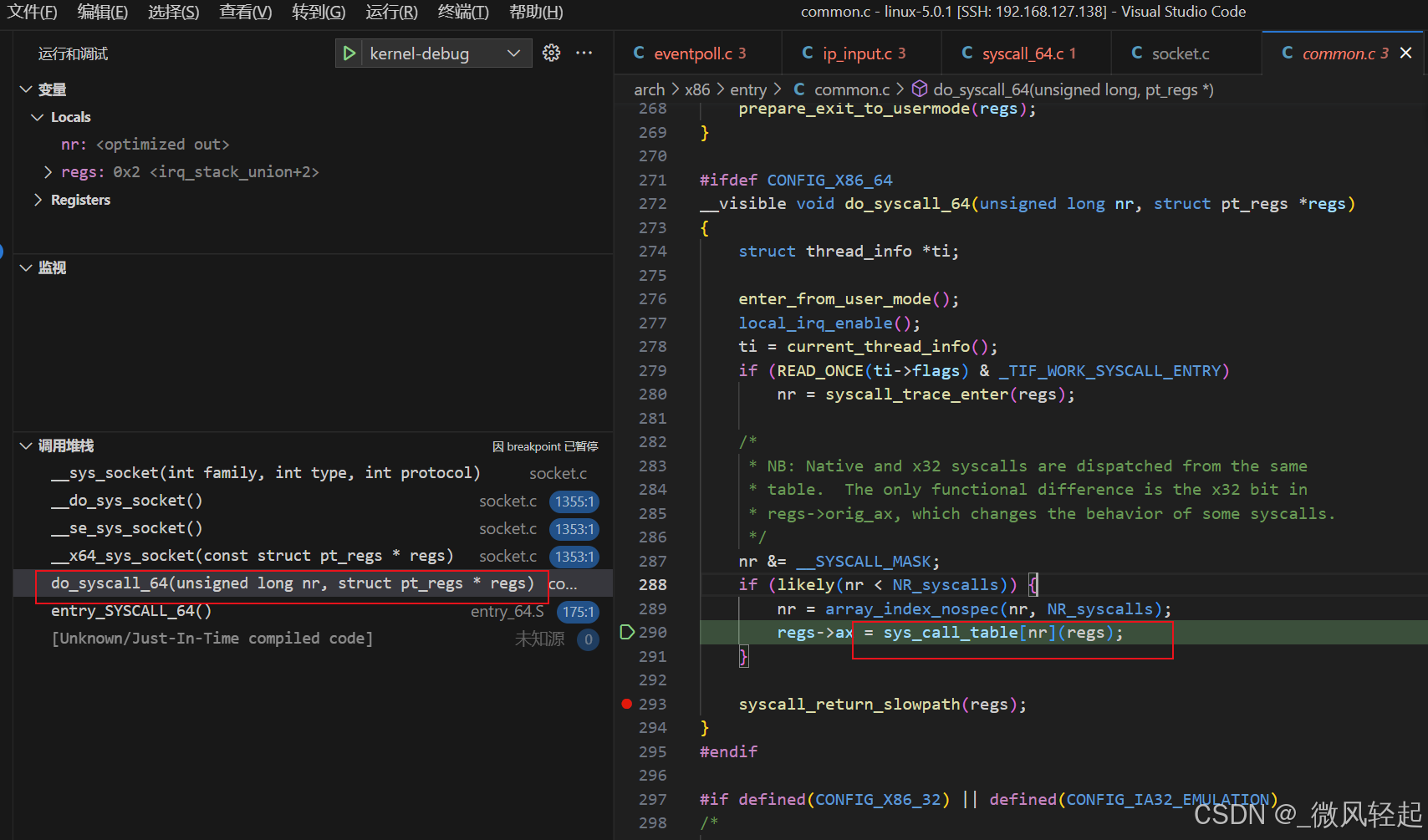
2、socket(AF_INET, SOCK_STREAM, 0)创建过程
这里对于socket的创建,就是__sys_socket函数

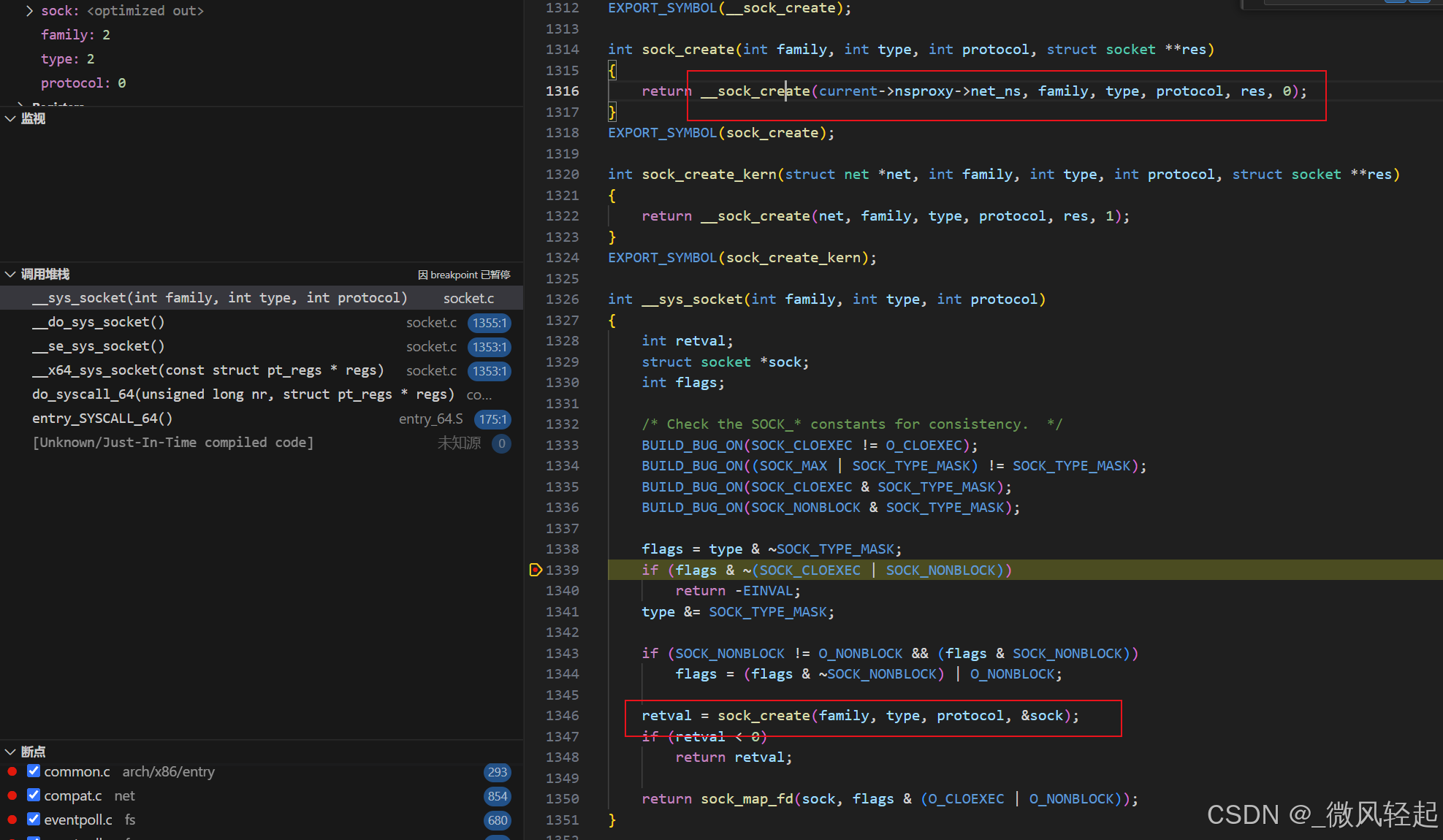
可以看到这里进行了socket的创建,我们再看socket的数据结构,其有等待队列wq、对应文件结构struct file *file
c
/**
* struct socket - general BSD socket
* @state: socket state (%SS_CONNECTED, etc)
* @type: socket type (%SOCK_STREAM, etc)
* @flags: socket flags (%SOCK_NOSPACE, etc)
* @ops: protocol specific socket operations
* @file: File back pointer for gc
* @sk: internal networking protocol agnostic socket representation
* @wq: wait queue for several uses
*/
struct socket {
socket_state state;
short type;
unsigned long flags;
struct socket_wq *wq;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};3、bind与listener
再之后就是socket的绑定与监听了,这个往更底层应该就内核、tcp协议,网络驱动相关了,我们就先不深究了。
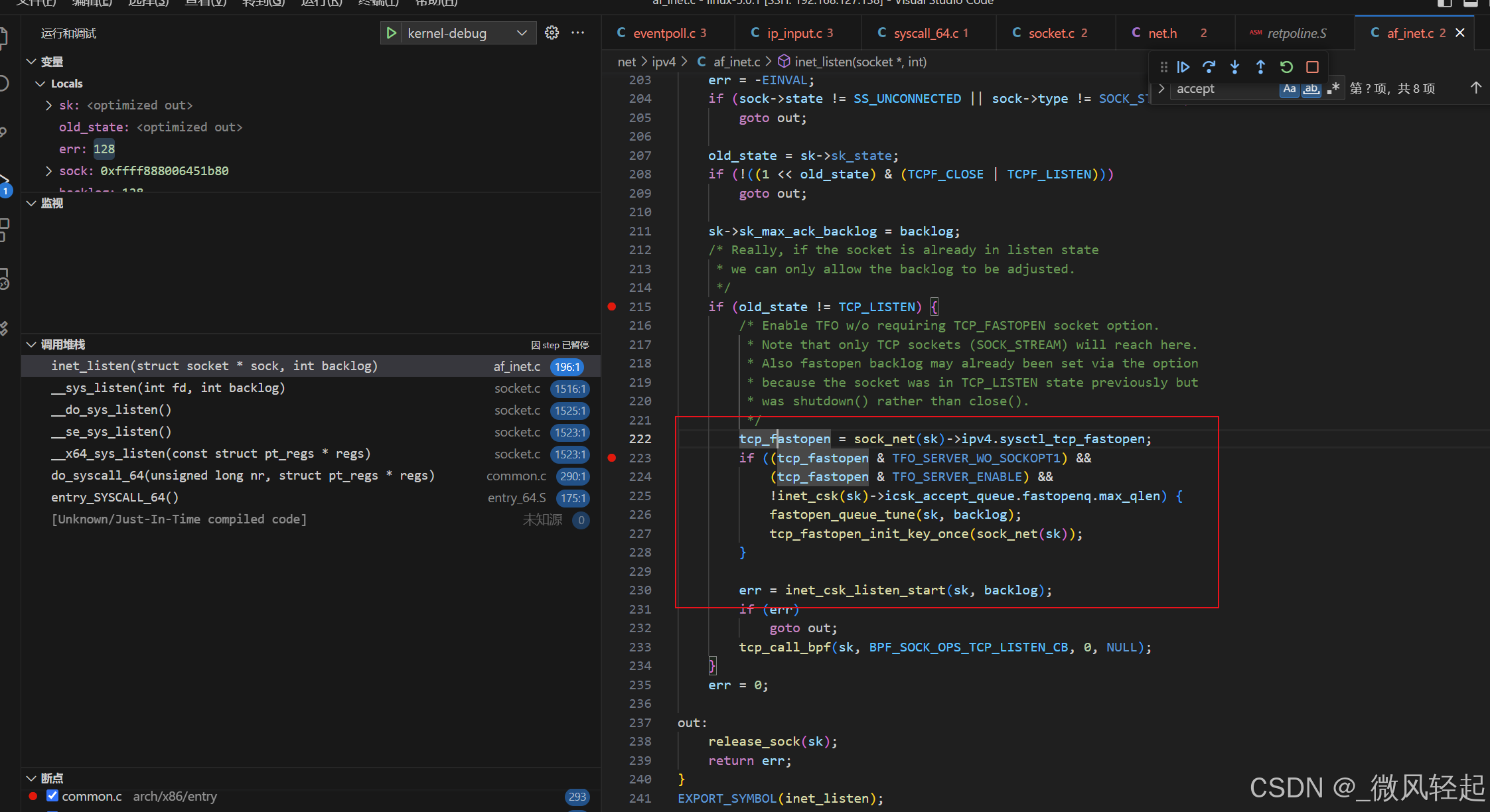
3、epoll_create内核函数
下面我们就来看epoll_create的创建逻辑
这里其主要就是创建一个eventpoll,这个就是epoll实例的初始化,然后获取inode文件节点,再将ep与对应文件关联。
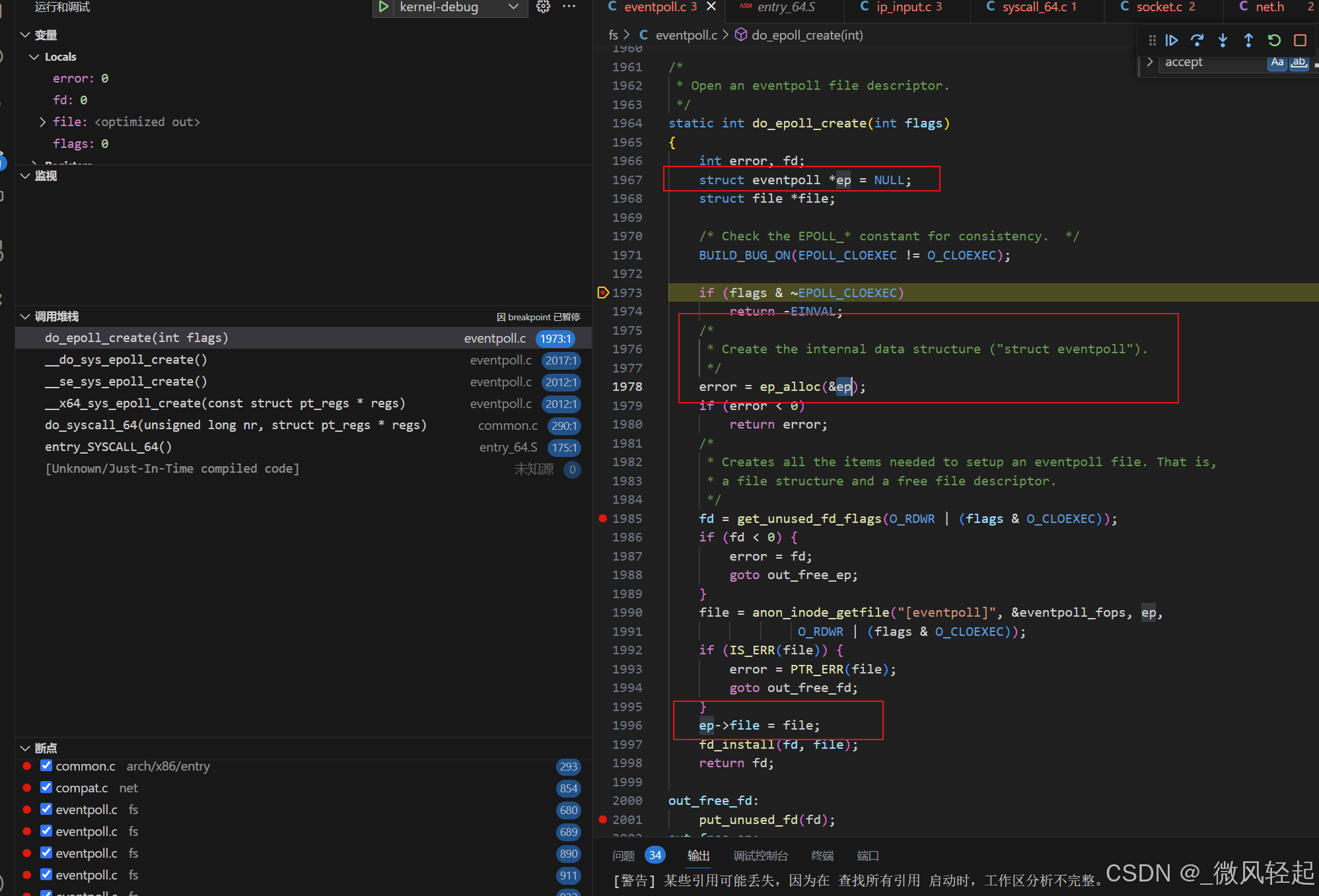
4、epoll相关eventpoll数据结构
c
/*
* This structure is stored inside the "private_data" member of the file
* structure and represents the main data structure for the eventpoll
* interface.
*
* Access to it is protected by the lock inside wq.
*/
struct eventpoll {
struct mutex mtx;
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root_cached rbr;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transferring ready events to userspace w/out
* holding ->wq.lock.
*/
struct epitem *ovflist;
/* wakeup_source used when ep_scan_ready_list is running */
struct wakeup_source *ws;
/* The user that created the eventpoll descriptor */
struct user_struct *user;
...........
}; 这里有两个核心的数据结构,也是我们在看epoll相关文章常提到的就绪列表-rdllist也就是哪些事件准备好了,就会将该事件节点添加到这里,以及对所有注册事件文件描述符进行管理的数据结构-红黑树-rbr,还有就是等待队列-wait_queue_head_t,这个主要是当socket有数据的时候进行对应回调,将对应事件节点添加到rdllist
5、epoll_ctl内核调用函数
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev)
对于epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev),主要就是在epollvent结构上面添加对应listen_fd关注的事件,这里就是在listen_fd添加EPOLL_CTL_ADD,也就是关注有新连接连接到服务端。这里有事件节点添加、删除、修改。还有数据输入EPOLLIN、数据输出EPOLLOUT这些。
/* Valid opcodes to issue to sys_epoll_ctl() */
#define EPOLL_CTL_ADD 1
#define EPOLL_CTL_DEL 2
#define EPOLL_CTL_MOD 3
/* Epoll event masks */
#define EPOLLIN (__force __poll_t)0x00000001
#define EPOLLPRI (__force __poll_t)0x00000002
#define EPOLLOUT (__force __poll_t)0x00000004
#define EPOLLERR (__force __poll_t)0x00000008
#define EPOLLHUP (__force __poll_t)0x00000010
#define EPOLLNVAL (__force __poll_t)0x00000020
#define EPOLLRDNORM (__force __poll_t)0x00000040
#define EPOLLRDBAND (__force __poll_t)0x00000080
#define EPOLLWRNORM (__force __poll_t)0x00000100
#define EPOLLWRBAND (__force __poll_t)0x00000200
#define EPOLLMSG (__force __poll_t)0x00000400
#define EPOLLRDHUP (__force __poll_t)0x00002000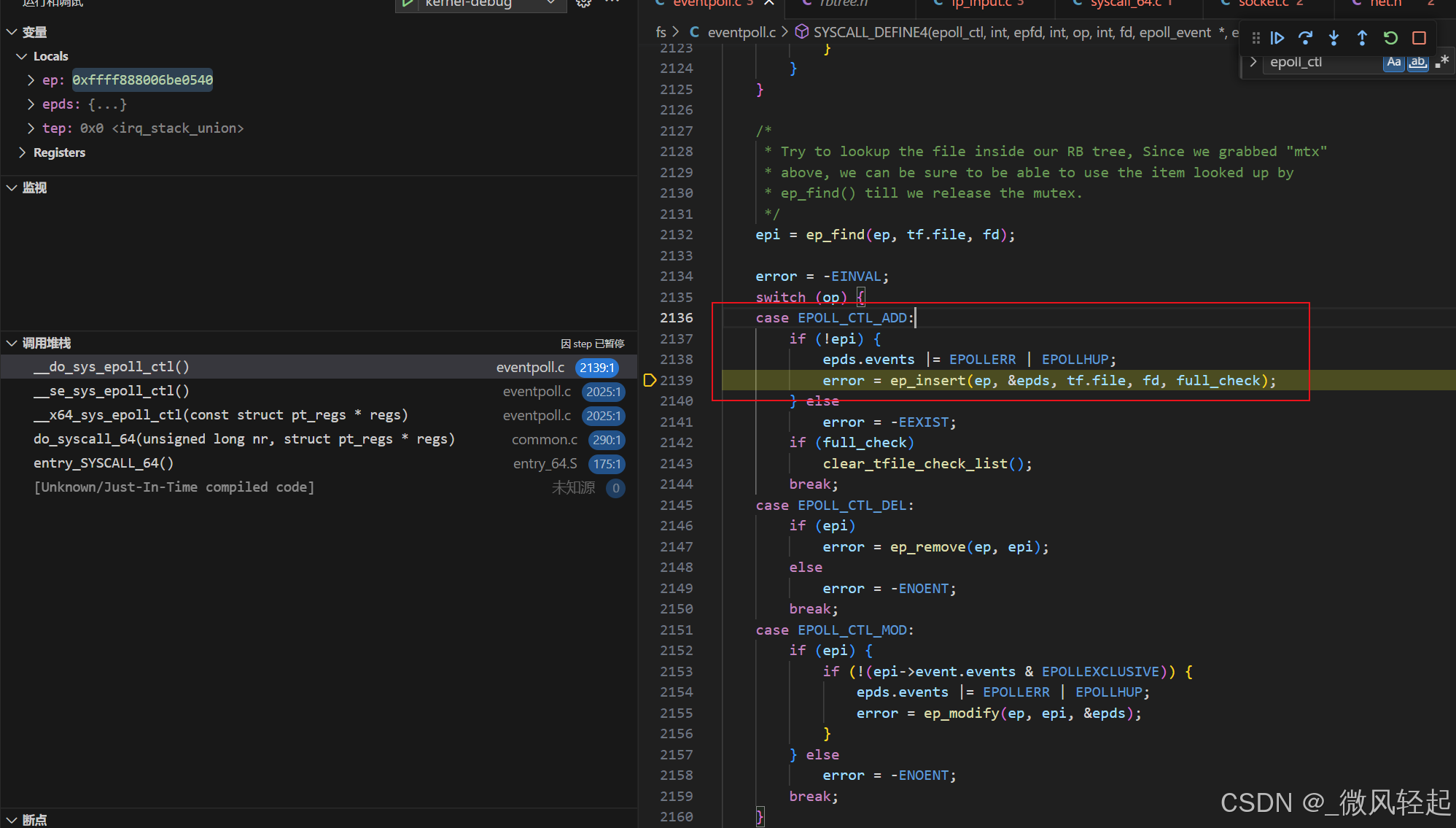
在这个函数中,主要就是进行事件节点的添加这里主要有一个新的数据结构,就是epitem,这个就是对我们epoll_ctl添加的事件描叙的封装,然后将其与eventpoll关联上,通过ep_rbtree_insert将其添加到eventpoll的红黑树rbr上面进行对应管理。
struct epitem {
union {
/* RB tree node links this structure to the eventpoll RB tree */
struct rb_node rbn;
/* Used to free the struct epitem */
struct rcu_head rcu;
};
/* List header used to link this structure to the eventpoll ready list */
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
struct epitem *next;
/* The file descriptor information this item refers to */
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
/* List containing poll wait queues */
struct list_head pwqlist;
/* The "container" of this item */
struct eventpoll *ep;
..........
/* The structure that describe the interested events and the source fd */
struct epoll_event event;
}; 同时这里的init_poll_funcptr(&epq.pt, ep_ptable_queue_proc)就是与就绪队列rdllist相关的逻辑
c
/*
* Must be called with "mtx" held.
*/
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
int error, pwake = 0;
__poll_t revents;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
.....
/* Item initialization follow here ... */
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
............
/* Initialize the poll table using the queue callback */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
revents = ep_item_poll(epi, &epq.pt, 1);
..........
/*
* Add the current item to the RB tree. All RB tree operations are
* protected by "mtx", and ep_insert() is called with "mtx" held.
*/
ep_rbtree_insert(ep, epi);
......
return error;
} 在这个ep_ptable_queue_proc中,主要是在就绪队列里面添加一个回调函数ep_poll_callback
c
/*
* This is the callback that is used to add our wait queue to the
* target file wakeup lists.
*/
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
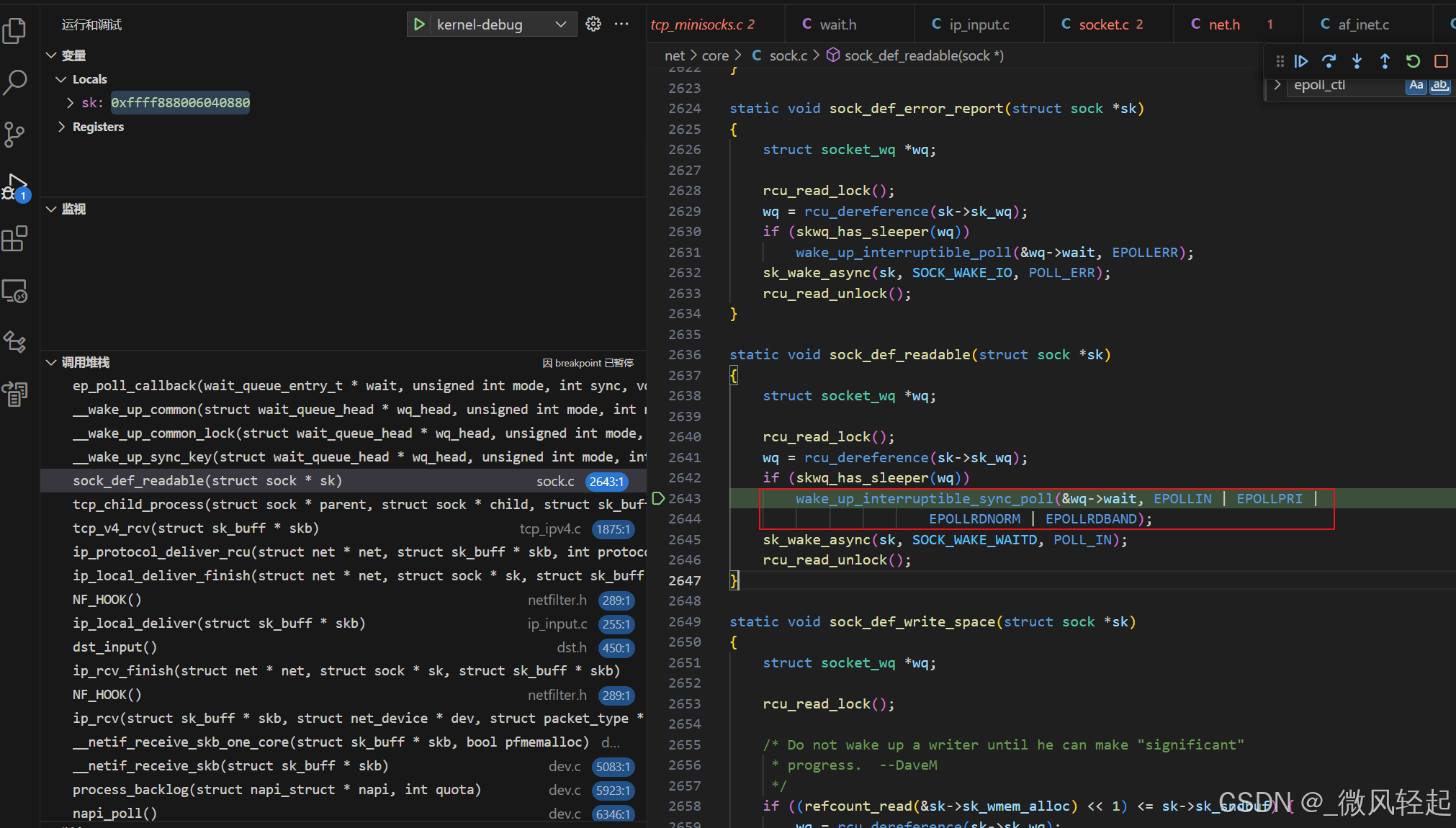
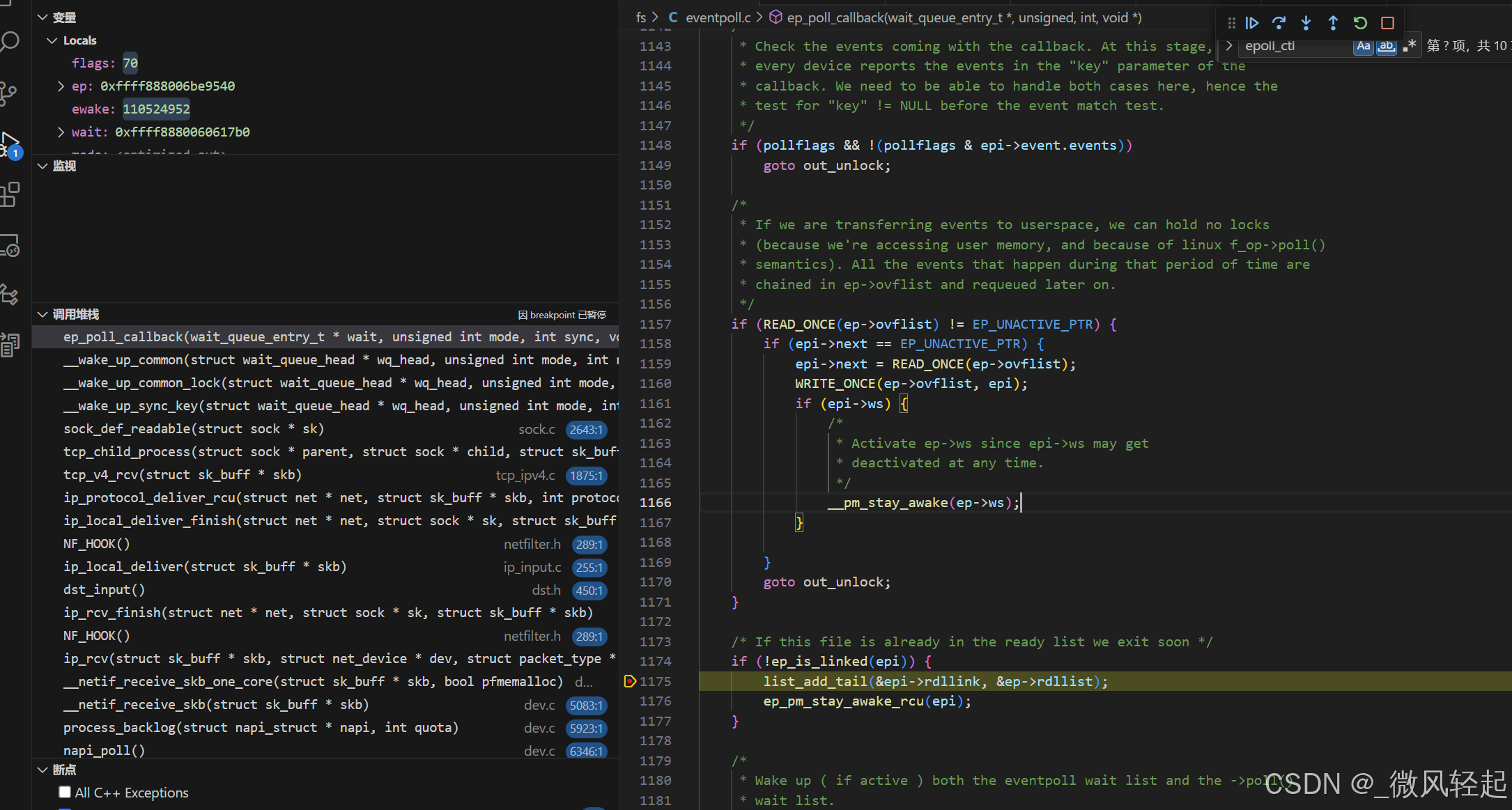
} 这里在socket接受到tcp对应数据的时候,通过等待队列回调,就是这个函数ep_poll_callback,这里主要就是将这个回调事件对应节点添加到eventpoll的rdllink -> list_add_tail(&epi->rdllink, &ep->rdllist),供我们之后epoll_wait对就绪队列的查询
c
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
__poll_t pollflags = key_to_poll(key);
int ewake = 0;
...........
/* If this file is already in the ready list we exit soon */
if (!ep_is_linked(epi)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake_rcu(epi);
}
/*
* Wake up ( if active ) both the eventpoll wait list and the ->poll()
* wait list.
*/
if (waitqueue_active(&ep->wq)) {
if ((epi->event.events & EPOLLEXCLUSIVE) &&
!(pollflags & POLLFREE)) {
switch (pollflags & EPOLLINOUT_BITS) {
case EPOLLIN:
if (epi->event.events & EPOLLIN)
ewake = 1;
break;
case EPOLLOUT:
if (epi->event.events & EPOLLOUT)
ewake = 1;
break;
case 0:
ewake = 1;
break;
}
}
wake_up_locked(&ep->wq);
}
...........
return ewake;
} tcp触发对应等待队列的回调
6、epoll_wait内核函数
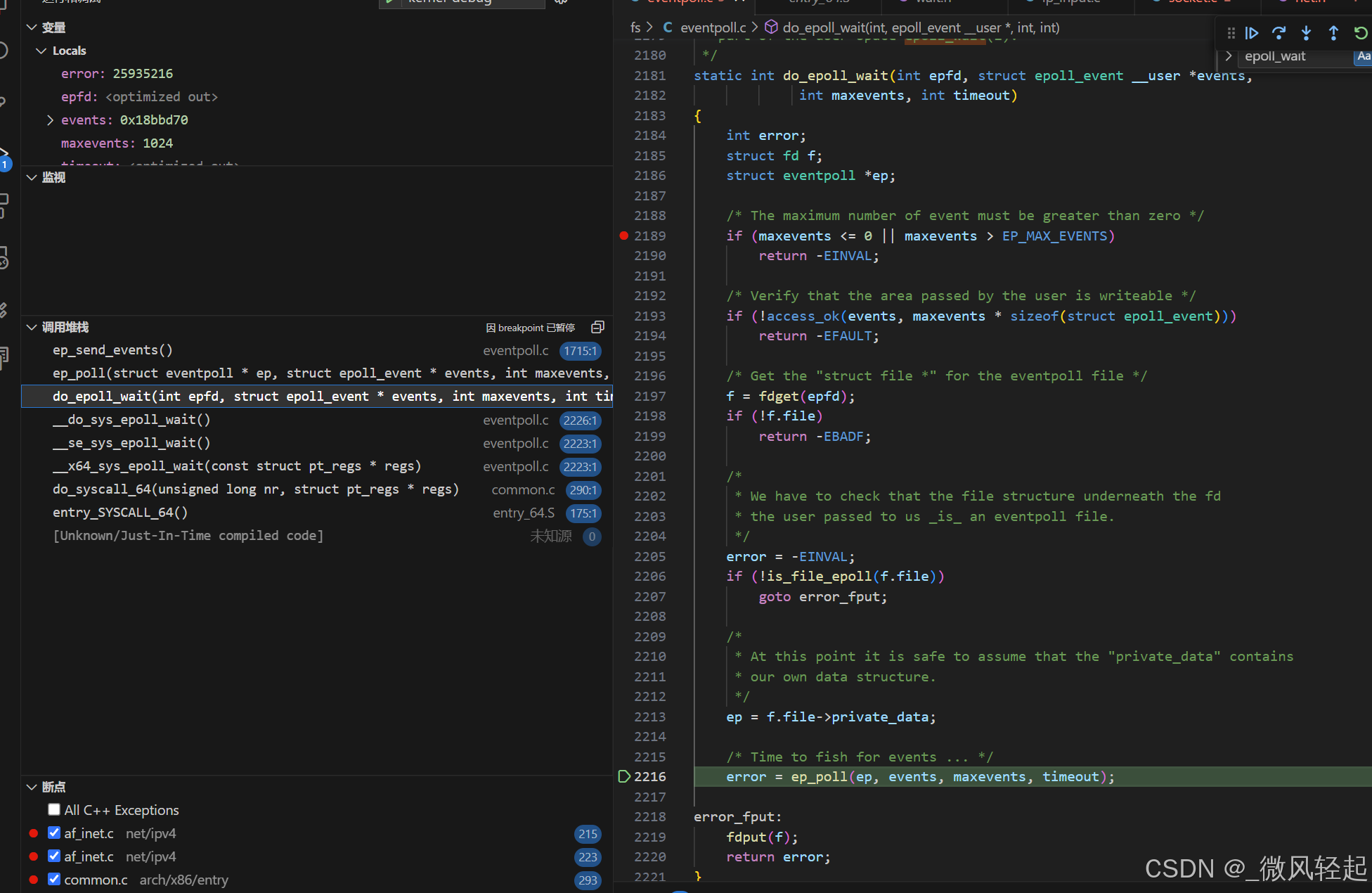
epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
下面我们再来看下epoll_wait函数,这个就是我们获取目前有哪些事件节点是准备好的
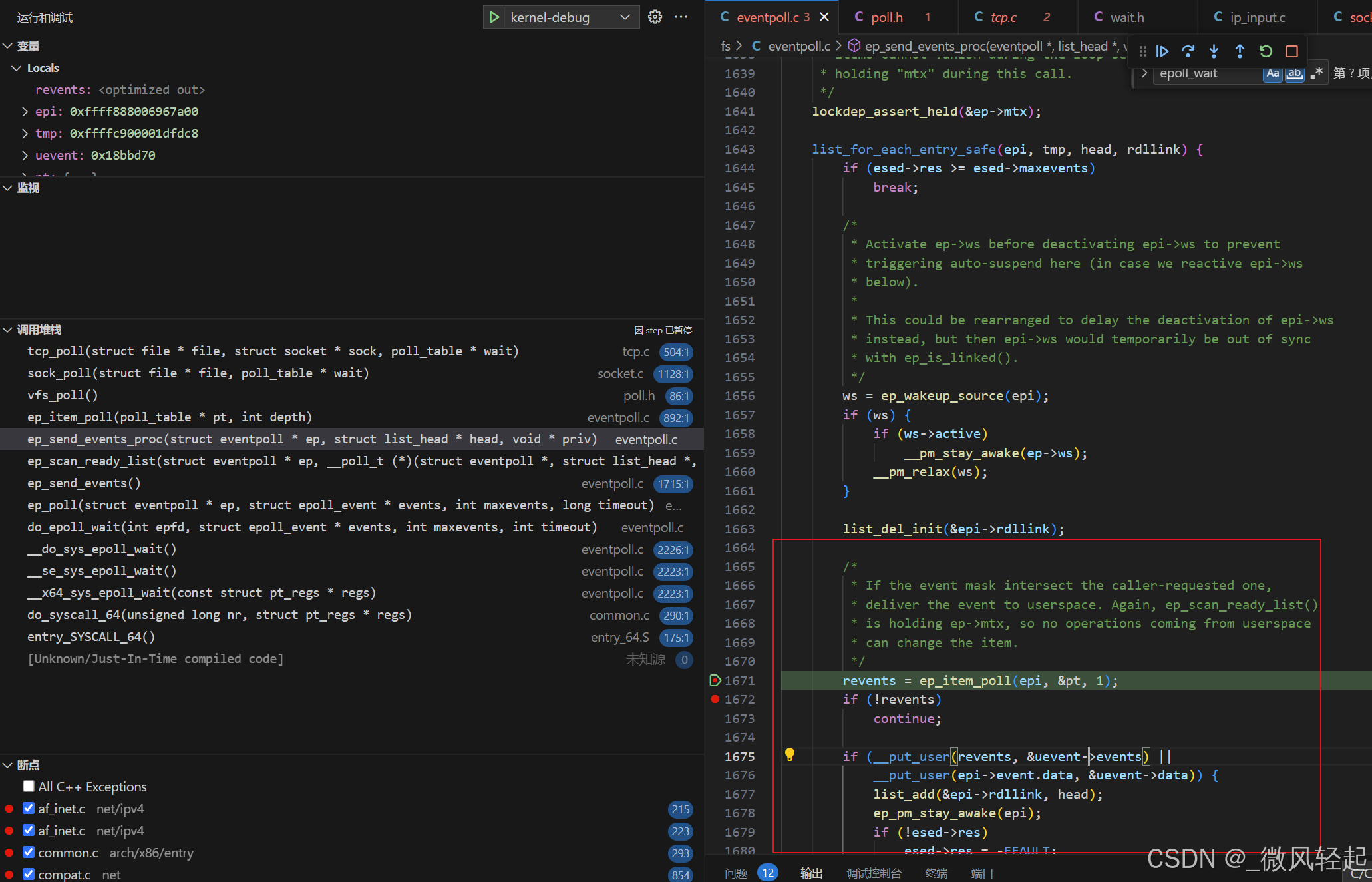
c
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
struct ep_send_events_data *esed = priv;
__poll_t revents;
struct epitem *epi, *tmp;
struct epoll_event __user *uevent = esed->events;
struct wakeup_source *ws;
poll_table pt;
init_poll_funcptr(&pt, NULL);
esed->res = 0;
/*
* We can loop without lock because we are passed a task private list.
* Items cannot vanish during the loop because ep_scan_ready_list() is
* holding "mtx" during this call.
*/
lockdep_assert_held(&ep->mtx);
list_for_each_entry_safe(epi, tmp, head, rdllink) {
..........
list_del_init(&epi->rdllink);
/*
* If the event mask intersect the caller-requested one,
* deliver the event to userspace. Again, ep_scan_ready_list()
* is holding ep->mtx, so no operations coming from userspace
* can change the item.
*/
revents = ep_item_poll(epi, &pt, 1);
if (!revents)
continue;
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
list_add(&epi->rdllink, head);
ep_pm_stay_awake(epi);
if (!esed->res)
esed->res = -EFAULT;
return 0;
}
esed->res++;
uevent++;
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
/*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, no one can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_scan_ready_list() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
return 0;
} 这里主要就是去遍历就绪列表rdllink,进行对应处理以及将就绪的事件项放到events进行对应返回到用户
7、accept接收请求的内核函数
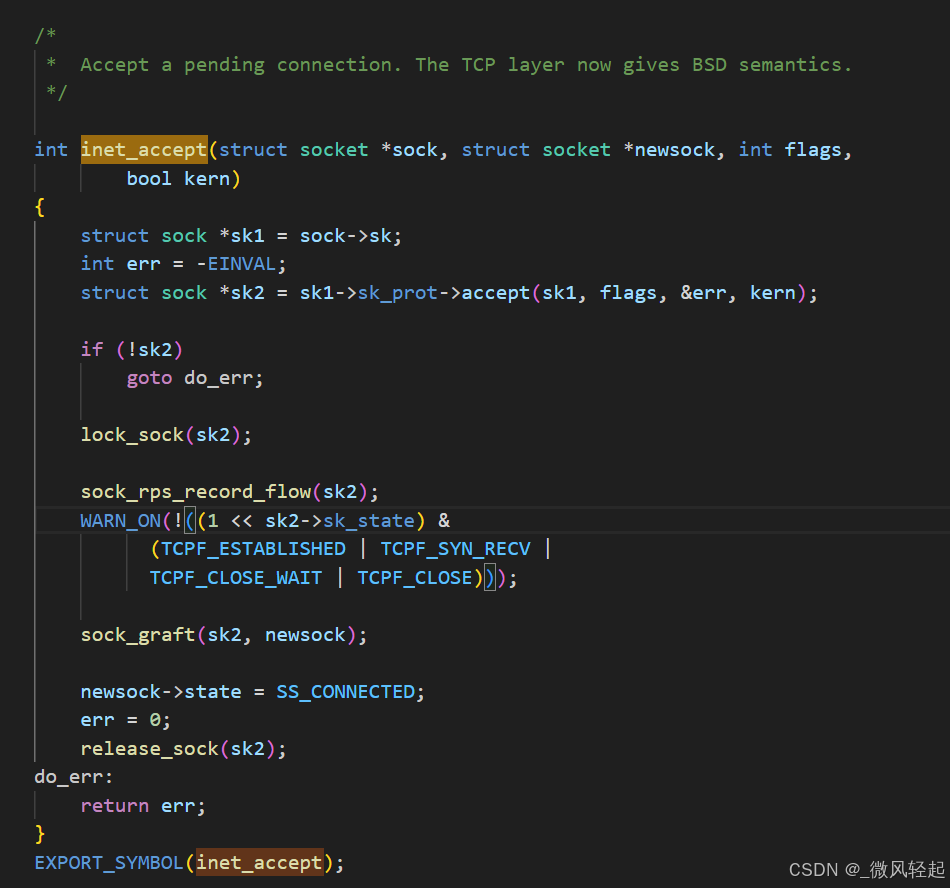
accept对应的内核调用的主要处理事在inet_csk_accept,这个会一直阻塞等待有新的socket连接来
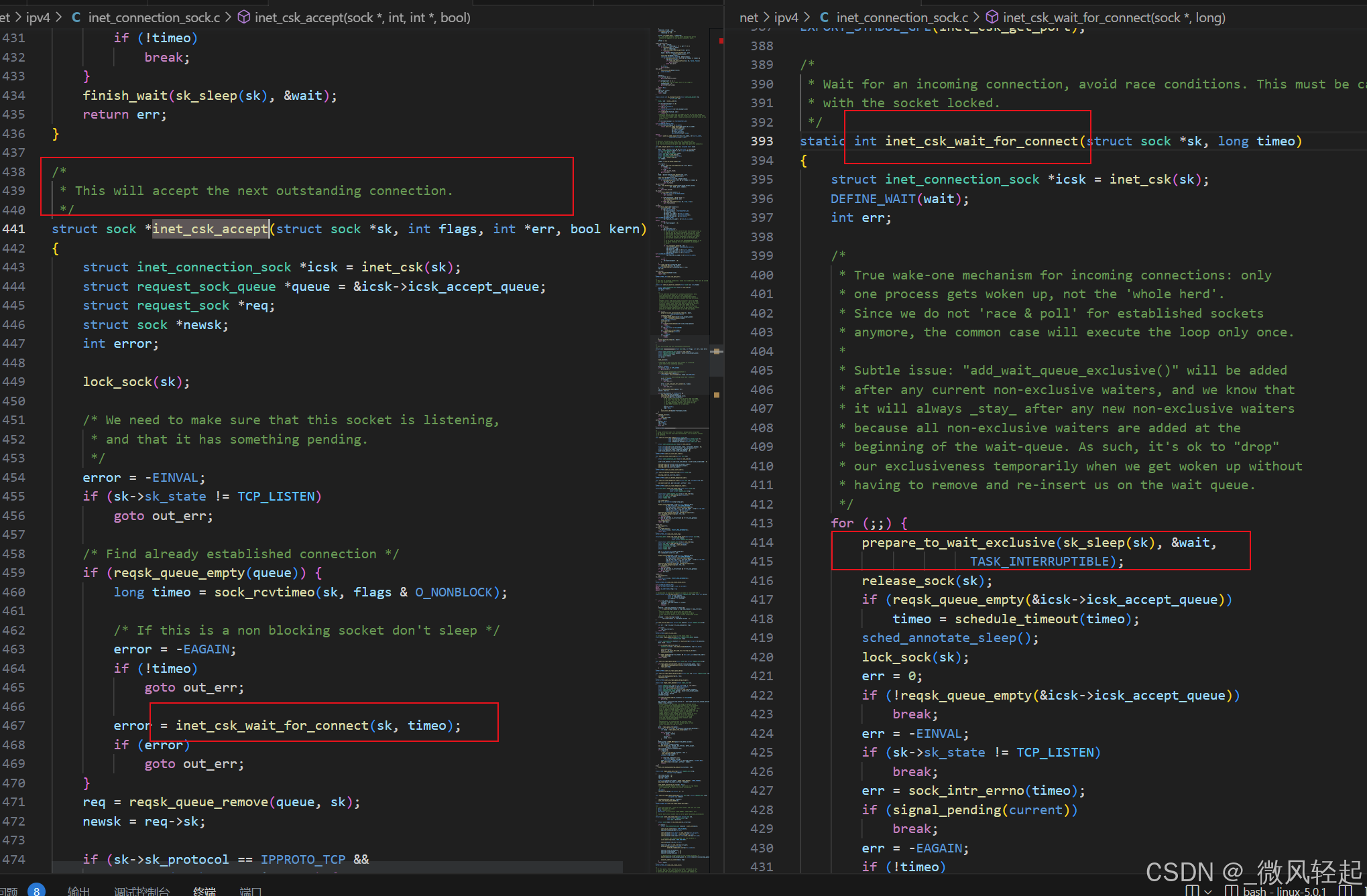
其会通过prepare_to_wait_exclusive,来一直阻塞等待
void
prepare_to_wait_exclusive(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry, int state)
{
unsigned long flags;
wq_entry->flags |= WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&wq_head->lock, flags);
if (list_empty(&wq_entry->entry))
__add_wait_queue_entry_tail(wq_head, wq_entry);
set_current_state(state);
spin_unlock_irqrestore(&wq_head->lock, flags);
} 上面这些就是关于linux下,socket、select、epoll原理的整体梳理,但由于目前对linux内核、还有c语言的了解不深,应该还是有些地方了解的不是足够透彻,但主要概念,流转逻辑应该就是这样的。