Strong Transferable Adversarial Attacks via Ensembled Asymptotically Normal Distribution Learning
-
- 摘要-Abstract
- 引言-Introduction
- [相关工作及前期准备-Related Work and Preliminaries](#相关工作及前期准备-Related Work and Preliminaries)
-
- [1. 黑盒对抗攻击](#1. 黑盒对抗攻击)
- [2. SGD的渐近正态性](#2. SGD的渐近正态性)
- [提出的方法-Proposed Method](#提出的方法-Proposed Method)
-
- [随机 BIM 的渐近正态性分析与优化目标制定](#随机 BIM 的渐近正态性分析与优化目标制定)
- 渐近正态分布攻击(ANDA)
- [ANDA 的多重实现(MultiANDA)](#ANDA 的多重实现(MultiANDA))
- 实验-Experiments
- [结论和展望-Conclusions and Perspectives](#结论和展望-Conclusions and Perspectives)
- 总结
本文"Strong Transferable Adversarial Attacks via Ensembled Asymptotically Normal Distribution Learning"提出了一种名为 "多重渐近正态分布攻击(Multiple Asymptotically Normal Distribution Attacks, MultiANDA)" 的方法,旨在通过学习扰动分布来生成可迁移的对抗样本,从而有效评估和增强深度神经网络的鲁棒性。
摘要-Abstract
强对抗样本在评估和强化深度神经网络的鲁棒性方面起着关键作用。然而,主流攻击方法的性能往往对微小图像变换等因素较为敏感,这主要归因于其所能获取的信息有限,通常仅依赖于单个输入样本、少量白盒源模型以及未明确的防御策略。如此一来,所生成的对抗样本容易对源模型过拟合,进而对其向未知架构的迁移能力造成阻碍。本文提出了一种名为 "多重渐近正态分布攻击(MultiANDA)" 的方法,该方法通过学习到的分布来显式刻画对抗扰动。具体而言,借助随机梯度上升(SGA)的渐近正态性特性来近似扰动的后验分布,并在此过程中运用深度集成策略作为贝叶斯边缘化的有效替代手段,以期估计出一个高斯混合模型,从而更深入地探索潜在的优化空间。所近似得到的后验分布本质上描述了SGA迭代的稳态分布,能够捕捉到局部最优解周边的几何信息。因此,MultiANDA能够为每个输入生成数量不限的对抗扰动,且能可靠地维持其迁移能力。通过在七个正常训练模型和七个防御模型上开展广泛实验,结果表明,我们所提出的方法在有防御或无防御的深度学习模型上,相较于十种前沿的黑盒攻击方法,均展现出更优的性能表现。
- 研究背景
- 强对抗样本对评估和增强深度神经网络鲁棒性很重要。
- 现有流行攻击方法存在问题,其性能易受微小图像变换影响,原因是信息有限,包括仅一个输入示例、少量白盒源模型和未定义防御策略,导致对抗样本易过拟合源模型,影响向未知架构的迁移性。
- 研究方法(MultiANDA)
- 利用随机梯度上升(SGA)的渐近正态性近似扰动的后验分布。
- 采用深度集成策略作为贝叶斯边缘化的有效代理,估计高斯混合模型,探索潜在优化空间,近似的后验分布能描述SGA迭代的稳态分布及局部最优解周围几何信息。
- 研究成果
- MultiANDA可针对每个输入生成无限数量的对抗扰动并保持迁移性。
- 通过在多个正常训练和防御模型上的实验,该方法优于十种先进的黑盒攻击方法。
引言-Introduction
文章的引言部分主要介绍了研究背景、问题提出、本文方法及贡献,具体内容如下:
- 研究背景与问题提出
- 深度神经网络(DNNs)虽在多领域表现出色,但易受对抗攻击,其鲁棒性和稳定性问题限制了在安全关键领域的应用。研究对抗攻击有助于评估和增强DNNs的鲁棒性。
- 现有黑盒和基于迁移的威胁模型下的对抗攻击算法存在诸多问题。例如,生成的对抗样本易过拟合替代模型,对微小变换敏感,在未知架构上的泛化能力有限。尽管已有多种改进策略,但仍无法充分探索高维扰动空间,且随机初始化攻击算法的样本缺乏多样性,限制了对抗样本的迁移性。
- 本文方法(MultiANDA)
- 提出多重渐近正态分布攻击(MultiANDA)方法,通过学习扰动分布来生成可迁移的对抗样本,以解决现有问题。
- 利用随机梯度上升(SGA)的渐近正态性,结合随机数据增强技术(如随机图像平移),提出随机BIM算法,近似对抗扰动的最优后验分布。
- 基于ANDA,应用深度集成策略,通过多次重复ANDA并添加随机初始值,估计高斯混合分布,实现多模态边缘化,提高攻击的泛化性能和多样性。
- 本文贡献
- 提出MultiANDA作为近似贝叶斯推理方法,通过学习扰动分布提升对抗样本的泛化(迁移)能力。
- 设计了随机化的对抗攻击过程,利用SGA的渐近正态性更好地学习扰动分布,并采用深度集成策略有效估计扰动的后验分布。
- 所学习的扰动分布允许为每个输入生成无限数量的对抗样本,实验验证了其在攻击成功率上的有效性,为对抗训练和防御模型设计提供了潜力。
- 通过广泛实验证明MultiANDA优于多种现有黑盒攻击方法,尤其在攻击先进防御模型时表现更优,有望为新防御方法的评估提供基准。

图1. 由ANDA/MultiANDA生成的欺骗所有选定的正常训练(第一行)和防御(第二行)模型的对抗样本的扰动可视化.
相关工作及前期准备-Related Work and Preliminaries
"Related Work and Preliminaries"部分主要聚焦于与本文研究相关的对抗攻击方法及随机梯度下降(SGD)渐近正态性的相关理论,为提出新方法奠定基础,具体内容如下:
1. 黑盒对抗攻击
- 攻击算法本质与优化目标:对抗攻击算法旨在通过最大化损失函数(如分类任务中的交叉熵损失)来寻找对抗样本,同时需满足(l_{\infty})范数约束。常见方法如FGSM及其迭代版本BIM,通过线性化损失函数实现攻击,但在白盒场景下有效,却易过拟合模型参数,难以迁移到未知架构。
- 提升对抗样本迁移性的方法分类
- 改进迭代优化过程:通过引入动量、Nesterov加速梯度和方差减少等方法搜索最优解。
- 攻击中间层:通过破坏关键的对象感知特征来提升迁移性。
- 引入多样性的通用化技术:包括数据增强(如调整大小、填充、平移、组合多种线性变换、修改像素值、集成其他图像信息、使用强度增强图像的梯度和等)。
- 与本文研究类似方法的对比
- PGD通过随机重启策略解决内最大化问题,但随机样本缺乏多样性。
- Nattack在查询式威胁模型下定义学习对抗分布,但需访问黑盒模型输出分数,限制了其在实际应用中的可扩展性。
- ADT通过学习分布进行对抗分布训练,但与本文方法不同,其生成的对抗样本以自然输入为中心,在输入远离边界时可能失败,而本文的ANDA在最优对抗样本周围生成,更易成功攻击。且ADT侧重于从大量训练数据学习分布用于对抗训练,本文方法则收集每个自然输入优化过程中的轨迹信息,适用于不同任务。
2. SGD的渐近正态性
- 理论基础:前人研究指出SGD的轨迹可视为待优化随机变量(如DNN训练中的模型参数)的贝叶斯后验分布。基于此,Maddox等人提出基于SGD迭代前两阶矩的高斯后验近似方法(SWAG)用于模型校准或不确定性量化。Mandt等人进一步分析了具有恒定学习率的SGD迭代的平稳分布(即渐近正态性),该理论可追溯到Polyak - Ruppert平均等相关研究,且仍是SGD的活跃研究方向。
- 对本文的启发:受深度集成策略的启发,Wilson和Izmailov的实证研究表明,仅使用多个随机初始化模型应用SWAG可显著提高模型性能,受益于混合高斯分布的多模态效应。本文借鉴这些理论,创新地对扰动的后验分布进行建模,以寻找有效的对抗样本。
提出的方法-Proposed Method
该部分详细阐述了本文提出的多重渐近正态分布攻击(MultiANDA)方法,包括对随机 BIM 渐近正态分布特性的分析、优化目标的制定以及 ANDA 和 MultiANDA 的具体实现过程:
随机 BIM 的渐近正态性分析与优化目标制定
-
理论基础
- 基于前人研究,在特定条件(如衰减学习率、光滑梯度和满秩平稳分布)下,随机梯度下降(SGD)渐近收敛于以局部最优为中心的高斯分布。Mandt等人进一步指出,在最终搜索阶段,当SGD使用恒定且足够小的学习率时,其迭代会收敛到一个平稳分布,此时梯度噪声(由随机采样的训练批次引入)有助于形成该分布,这为本文利用随机BIM的渐近正态性提供了理论支撑。
-
随机BIM的构建与实验验证
- 传统的BIM优化过程是确定性梯度上升,为模拟高斯极限分布,本文在每次迭代步骤中集成随机数据增强技术(如实验中使用的图像平移),构建了随机BIM。采用小常数学习率策略( a = ϵ / T a = \epsilon / T a=ϵ/T, ϵ \epsilon ϵ 为限制 L ∞ L_{\infty} L∞ 范数的小正数, T T T 为迭代次数),推测此随机BIM可作为近似贝叶斯推理算法。
- 通过对3张随机抽取的ImageNet图像进行300次迭代,使用t - SNE技术可视化对抗扰动(即损失梯度),发现其呈现高斯分布,验证了随机BIM的渐近正态性猜想。同时注意到优化轨迹中梯度噪声明显增加,但不影响扰动收敛,且前10步收敛紧密,表明在非目标攻击中( T T T 常为 10 10 10),早期迭代接近局部最优。

图2. 由随机BIM(a)和所提出的方法(b)生成的对抗扰动的迭代轨迹的渐近正态分布示例.
-
优化目标的改进
-
受上述实验结果启发,提出使用 n n n 个图像变换 A U G i ( ⋅ ) AUG_i(\cdot) AUGi(⋅) 形成对抗攻击的小批量,以进一步增强随机性,优化目标变为最大化所有变换的损失之和(公式(4))。

-
为更充分探索高维潜在扰动空间,进一步将对抗扰动建模为分布 Π δ \Pi_{\delta} Πδ,提出新的优化目标(公式(5)),即最大化对抗扰动分布的预期损失,该目标是对公式(4)的广义化,期望能更好地表征扰动信息以生成可迁移的对抗样本。

-
渐近正态分布攻击(ANDA)
该部分主要介绍了渐近正态分布攻击(ANDA)方法,包括利用SGA的渐近正态性迭代搜索对抗样本、计算相关梯度和扰动、近似扰动的后验分布以及生成对抗样本的过程,具体内容如下:
- 基于渐近正态性的迭代搜索
- 为解决优化问题(公式(5)),利用随机梯度上升(SGA)的渐近正态性,类似于传统的迭代攻击方法进行对抗样本的搜索。在这个过程中,省略不影响SGA渐近正态性的投影函数 Φ ( ⋅ ) \Phi(\cdot) Φ(⋅) 和 s i g n ( ) sign() sign() 函数,计算每次迭代中经过变换后的对抗样本的梯度,将其记为增强感知扰动 δ i ( t ) \delta_{i}^{(t)} δi(t).
- 梯度计算与扰动近似
- 令 s s s 为每次迭代中增强的样本集合( s = { A U G i ( x a d v ( t ) ) } i = 1 n s = \{AUG_{i}(x_{a d v}^{(t)})\}{i = 1}^{n} s={AUGi(xadv(t))}i=1n),根据中心极限定理,将随机梯度 δ ^ S \hat{\delta}{S} δ^S 视为样本 z ∈ S z \in S z∈S 的函数,其期望为全梯度 δ ( z ) \delta(z) δ(z),且随机梯度的梯度噪声 Δ δ ( z ) \Delta\delta(z) Δδ(z) 可假设服从高斯分布,从而得出对抗扰动的先验分布在每次迭代中自然为高斯分布。
- 通过迭代平均来近似对抗扰动的均值 δ ‾ ( t + 1 ) \overline{\delta}^{(t + 1)} δ(t+1),最终得到 δ ‾ = δ ‾ ( T ) \overline{\delta} = \overline{\delta}^{(T)} δ=δ(T)。计算协方差矩阵,通过考虑迭代过程中所有随机梯度来估计后验分布的协方差 σ \sigma σ。
- 对抗样本的生成
- ANDA允许通过从估计的分布 N ( δ ‾ , σ ) N(\overline{\delta}, \sigma) N(δ,σ) 中采样来为一个输入生成一个或多个对抗样本。在生成单个对抗样本时,按照传统方式迭代更新得到最终的对抗样本 x a d v x_{a d v} xadv;在生成多个对抗样本时,从学习到的扰动分布中采样 M M M 个扰动 { δ m } m = 1 M \{\delta_{m}\}{m = 1}^{M} {δm}m=1M,然后生成相应的对抗样本 { x a d v m } m = 1 M \{x{a d v}^{m}\}_{m = 1}^{M} {xadvm}m=1M。

ANDA 的多重实现(MultiANDA)
该部分主要介绍了通过对BIM(基础迭代方法)攻击的收敛性分析,提出了一种改进的攻击方法ANDA(渐近正态分布攻击)及其多重实现MultiANDA,以提高对抗样本的生成效果和攻击性能。具体内容如下:
- ANDA方法
- 优化问题近似求解:利用随机梯度上升(SGA)的渐近正态性,对公式(2)中的最大化问题进行求解,通过迭代计算梯度并近似扰动的后验分布。在计算过程中,对每个变换后的样本计算梯度,形成随机梯度,基于中心极限定理,将其作为对抗扰动先验分布为高斯分布的依据。
- 后验分布估计:通过迭代平均计算对抗扰动的均值,并根据所有随机梯度计算协方差矩阵,从而估计出扰动的后验分布。
- 对抗样本生成:ANDA可以从估计的分布中采样生成一个或多个对抗样本,通过这种方式能够更好地探索扰动空间,提高对抗样本的有效性。
- MultiANDA方法
- 基于ANDA的改进:为克服ANDA在探索优化空间时可能存在的局限性(仅探索单峰优化空间),利用深度集成策略对ANDA进行多重实现。具体做法是多次((K)次)重复ANDA过程,并在原始样本上添加随机初始值,以增加多样性。
- 多模态边缘化实现 :对每次ANDA过程得到的对抗扰动 δ ˉ k \bar{\delta}{k} δˉk 进行平均,得到 δ ˉ m e a n \bar{\delta}{mean} δˉmean,实现了高斯混合分布的多模态边缘化。通过这种方式,MultiANDA能够生成更多样化的对抗样本,进一步提高攻击能力,尤其在针对防御模型时表现出显著的性能提升。
实验-Experiments
该部分通过一系列实验展示了所提方法(ANDA 和 MultiANDA)在不同模型上的攻击性能,包括与多种基线方法的对比、对不同类型模型(正常训练模型和防御模型)的攻击效果、采样对抗样本的攻击性能等,具体内容如下:
实验设置
- 数据集:实验采用ImageNet1k数据集,该数据集包含1000张图像,这些图像是从ImageNet数据集中随机抽取的。选择该数据集是为了与先前的相关研究保持一致,以便在相同的数据基础上对不同方法进行比较和评估。
- 模型
- 正常训练模型:考虑了七类正常训练模型用于评估,包括Inception - v3(Inc - v3)、Resnet - v2 - 50(ResNet50)、Resnet - v2 - 101(ResNet - 101)、Resnet - v2 - 152(ResNet152)、Inception - v4(Inc - v4)、Inception - ResNet - v2(IncRes - v2)和VGG - 19。其中,Inc - v3、ResNet50、IncRes - v2和VGG - 19还被用作白盒源模型来生成对抗样本,通过这些不同结构和特性的模型,可以全面测试所提方法在不同模型架构上的有效性和通用性。
- 防御模型 :选择了七类先进防御模型,包括三个对抗训练模型 I n c − v 3 e n s 3 Inc - v3_{ens3} Inc−v3ens3、 I n c − v 3 e n s 4 Inc - v3_{ens4} Inc−v3ens4 和 I n c R e s − v 2 e n s IncRes - v2_{ens} IncRes−v2ens)、High - level representation Guided Denoiser(HGD)、Neural Representation Purifier(NRP)、Randomized Smoothing(RS)和NIPS 2017防御竞赛中的"Rand - 3"提交(NIPS - r3)。这些防御模型涵盖了多种防御策略,能够有效检验所提方法对不同防御机制的突破能力,从而更全面地评估其性能。
- 基线方法 :选用了三类基于迁移的攻击方法作为基线方法进行对比实验。
- 数据增强类:包括DIM、TIM、SIM和Transferable Attack based on Integrated Gradients(TAIG)等方法,这类方法主要通过数据增强技术来提高对抗样本的迁移性,是当前提高攻击性能的一种重要途径,通过与它们对比可以直接体现所提方法在数据增强方面的优势或不足。
- 特征重要性感知类:选择了FIA,该方法考虑了源模型的中间层信息,在攻击性能上具有一定竞争力,将其作为基线有助于评估所提方法在利用模型特征方面的有效性。
- 优化增强类:涵盖了BIM及其加速版本(如MI - FGSM、NI - FGSM)和使用方差减少策略的方法(如VMI - FGSM、VNI - FGSM)等,这些方法主要通过改进优化过程来提升攻击效果,与它们对比可突出所提方法在优化策略上的创新和改进之处。通过与多种不同类型的基线方法进行对比实验,能够更全面、准确地评估所提方法在对抗攻击领域的性能表现和优势所在。
攻击正常训练模型
该部分主要介绍了针对正常训练模型进行攻击实验的过程和结果,以评估所提方法(ANDA和MultiANDA)在这种情况下的有效性,具体内容如下:
- 实验方法
- 通过在选定的源模型(行)和目标模型(列)网络上生成并测试对抗样本,对所提方法进行交叉验证。在实验中,为了与其他方法进行公平比较,如果未特别说明,所提方法为每个输入生成一个对抗样本,这与算法1中的第一个输出选项一致。
- 实验结果
- 与基线方法对比:从实验数据(表1)可以看出,ANDA和MultiANDA在几乎所有情况下均显著优于其他基线方法,无论是在白盒还是黑盒设置下。例如,在以IncRes - v2、ResNet - 50和VGG - 19为源模型时,它们始终能够击败其他方法;对于Inc - v3作为源模型的情况,ANDA与当前最先进的方法具有竞争力,而MultiANDA则保持更高的成功率。
- 具体案例分析:以ResNet - 50为源模型生成对抗样本,并测试其对其他六个正常训练模型(作为黑盒目标)的攻击效果。结果显示,ANDA和MultiANDA生成的对抗样本在欺骗目标模型方面表现出色。具体而言,ANDA生成的对抗样本中有840/1000成功欺骗了所有六个目标模型,MultiANDA的这一比例为863/1000,而VMI - FGSM仅为517/1000。这表明ANDA和MultiANDA生成的对抗样本更具欺骗性,即它们所生成的对抗样本更强大。
- 可视化分析:通过可视化生成的对抗样本及其扰动(图1),进一步发现ANDA和MultiANDA生成的扰动更聚焦于对象的语义区域,这些区域对预测模型的决策具有重要影响。相比之下,VMI - FGSM的扰动效果相对较差,这从直观上解释了为什么ANDA和MultiANDA在攻击正常训练模型时具有更好的性能。通过以上实验方法、结果对比和可视化分析,充分证明了所提方法在攻击正常训练模型时的有效性和优越性。

表1. 所提方法及基线攻击方法对五个正常训练模型的成功率(%). "Sign"表示在白盒源模型上的结果. 最佳/次佳结果分别以粗体/下划线显示. 由于篇幅限制,此处仅展示对五个目标模型的性能表现. 有关对七个目标模型的完整结果,请参见附录.

图3. 由我们所提出的方法精心制作的多数样本成功欺骗了所有6个黑盒模型
攻击防御模型
该部分主要阐述了针对先进防御模型进行攻击实验的相关内容,包括实验设置、结果分析以及对源模型选择的探讨,具体如下:
- 实验目的与设置
- 旨在评估所提出的方法(ANDA和MultiANDA)对选定的先进防御模型的攻击能力。实验过程中,使用与之前相同的实验设置,但重点关注在面对各种防御机制时,所提方法能否有效地生成对抗样本并突破防御。
- 实验结果与分析
- 成功率提升:从实验数据(表2)来看,在大多数情况下,ANDA和MultiANDA对这些防御模型的攻击成功率持续提高,相较于其他攻击方法,总体上展现出显著的性能提升。尤其在使用ResNet - 50作为源模型时,达到了最佳的攻击效果,这与之前在攻击正常训练模型时的观察结果一致,进一步证明了ResNet - 50在提升攻击性能方面的优势。
- 源模型影响:观察到使用VGG - 19作为源模型时,所有基线方法的性能出现波动且有效性降低,其平均最大攻击成功率仅为28.3%。这表明VGG - 19在特征提取能力方面可能存在不足,导致生成的对抗样本在黑盒攻击中的迁移性降低。这一现象凸显了源模型选择在最大化对抗攻击迁移性方面的关键作用,即合适的源模型对于成功攻击防御模型至关重要。
- 可视化验证 :通过可视化由VMI - FGSM、ANDA和MultiANDA生成的能够欺骗防御模型的对抗样本及其扰动(见附录),发现所提方法生成的扰动更集中于图像的信息丰富区域。这一结果再次验证了ANDA和MultiANDA在生成对抗样本时的有效性和泛化能力,即使面对具有防御机制的模型,它们也能够找到关键区域进行扰动,从而成功实施攻击。

图4. 由ANDA(渐近正态分布攻击)和MultiANDA(多重渐近正态分布攻击)生成的单个对抗样本、多个(从每个输入图像所学习到的扰动分布中采样的20个对抗样本,即 δ m m = 1 20 {\delta_{m}}{m = 1}^{20} δmm=120 )以及对应单个对抗样本攻击成功的输入图像所采样的20个对抗样本(即 S u c . δ m m = 1 20 Suc. {\delta{m}}{m = 1}^{20} Suc.δmm=120)的采样对抗样本的攻击成功率。 δ m m = 1 20 {\delta{m}}{m = 1}^{20} δmm=120 表示从每个输入图像所学习到的扰动分布中采样得到的20个对抗样本;而 S u c . δ m m = 1 20 Suc. {\delta{m}}_{m = 1}^{20} Suc.δmm=120 则是针对那些其对应的单个对抗样本已成功实施攻击的输入图像所采样的20个对抗样本。
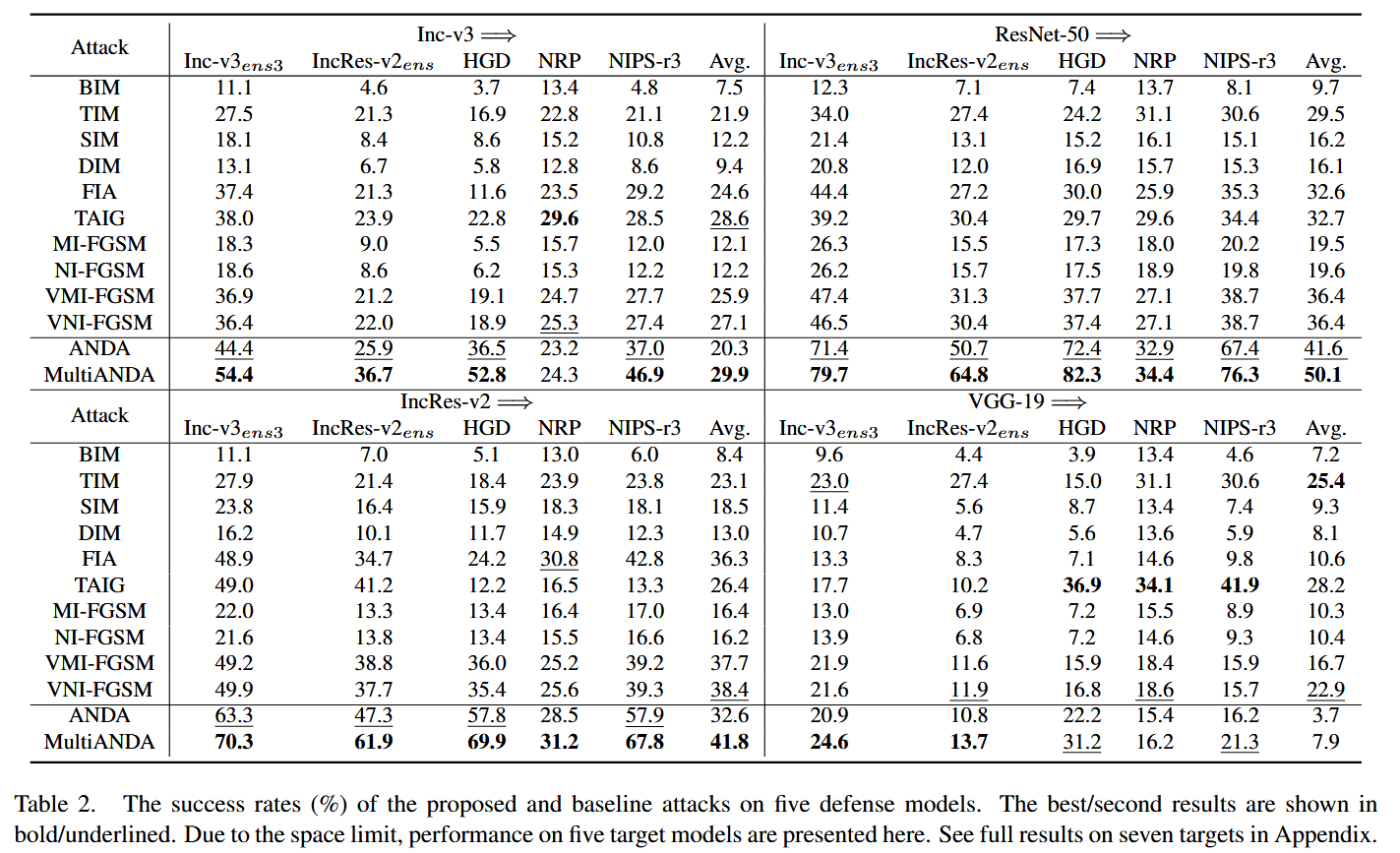
表2. 所提方法及基线攻击方法对五种防御模型的成功率(%). 最佳/次佳结果分别以粗体/下划线显示. 由于篇幅限制,此处仅展示对五个目标模型的性能表现. 有关对七个目标模型的完整结果,请参见附录
采样对抗样本的攻击性能
该部分主要探讨了通过所提方法(ANDA和MultiANDA)采样生成的对抗样本的攻击性能,具体内容如下:
- 研究背景与目的
- 在前面的实验中,主要分析了所提方法为每个输入生成单个最优对抗样本( δ ˉ \bar{\delta} δˉ)的有效性。然而,ANDA和MultiANDA还能够学习扰动的分布 N ( δ ˉ , σ ) N(\bar{\delta}, \sigma) N(δˉ,σ),并通过采样生成任意数量的对抗样本( δ m m = 1 M {\delta_{m}}_{m = 1}^{M} δmm=1M)。本部分实验旨在验证这些采样得到的对抗样本的攻击性能,以进一步评估所提方法的优势和潜力。
- 实验过程与方法
- 对于每个输入图像,从学习到的扰动分布中抽取 20 个( M = 20 M = 20 M=20)对抗样本( δ m m = 1 20 {\delta_{m}}{m = 1}^{20} δmm=120)。同时,分析对应于单个对抗样本攻击成功的输入图像所采样的对抗样本(Suc. δ m m = 1 20 {\delta{m}}_{m = 1}^{20} δmm=120)的攻击性能,即只考虑那些单个对抗样本已经成功攻击的输入图像,并对其再次进行采样得到新的对抗样本,然后测试这些采样对抗样本的攻击成功率。
- 实验结果与分析
- 实验结果(图4)表明,采样得到的对抗样本( δ m m = 1 20 {\delta_{m}}_{m = 1}^{20} δmm=120)与通过单个最优对抗样本( δ ˉ \bar{\delta} δˉ)生成的对抗样本相比,具有相当高的攻击成功率,即使在面对防御模型时也是如此。这一结果证实了所学习的扰动分布的有效性,即通过采样能够获得与单个生成的对抗样本相近的攻击效果,从而证明了所提方法在生成对抗样本方面的稳定性和可靠性。
- 此外,这一结果还展示了所提方法在对抗训练或防御模型设计方面的巨大潜力。由于能够从学习到的分布中采样生成多个有效的对抗样本,这为基于对抗样本的防御策略设计提供了更多的可能性,例如可以利用这些采样对抗样本进行更全面的对抗训练,从而提高模型的鲁棒性。
结论和展望-Conclusions and Perspectives
该部分内容通常是对整篇文章核心要点的总结以及对未来相关研究方向的思考,具体解释如下:
结论部分
- 方法总结:回顾了文章所提出的核心方法,比如此处提到的多重渐近正态分布攻击(MultiANDA)方法,强调其通过特定的方式(近似对抗扰动的后验分布)来达成目标,也就是提高对抗样本在未知深度学习模型上的迁移能力,这是该方法在技术层面的关键所在,也是整个研究围绕开展的重点内容。
- 实验验证:指出通过大量全面的实验对MultiANDA方法进行了验证。实验涵盖了不同类型的模型,包括正常训练模型以及防御模型,且将其与多种现有的黑盒及基于迁移的攻击方法进行对比。结果表明MultiANDA表现更优,这体现了该方法在实际应用场景中的有效性和先进性,也间接说明目前已有的防御技术在应对这类新型攻击方法时还存在有待改进之处。
- 计算开销说明:提及了方法在实际运算过程中的成本问题,像ANDA和MultiANDA的计算开销主要取决于增强过程中的批量样本数量,并且强调其与类似的基线方法计算成本相当,从实际应用角度来看,相对于它们可能给模型安全带来的潜在风险(比如成功突破防御模型等情况),这样的计算成本是相对可以接受的,进一步说明该方法在性价比方面具备一定优势。
展望部分
- 风险关注:认识到虽然当前在对抗攻击领域取得了研究成果,但对抗攻击算法如果被不当使用,是可能带来诸多风险的,比如可能会对依靠深度学习模型的众多安全关键系统造成威胁,影响其正常稳定运行等,所以后续研究需要重视对这类风险的管控。
- 未来研究方向:明确提出未来的研究重心应放在开发更先进的深度学习模型上,目标是让模型更好地契合人类视觉偏好。因为现有的深度学习模型存在一些根本性的缺陷,容易被对抗攻击所利用,所以要从根源上解决问题,通过改进模型架构、优化训练方法以及深入探究人类视觉感知机制并加以模拟等多方面举措,全方位提高模型的安全性和鲁棒性,使模型在面对各类攻击时能有更好的抵御能力,保障其在实际应用中的可靠运行。
总结
创新点
- 提出新方法:提出了多重渐近正态分布攻击(MultiANDA)方法,利用随机梯度上升(SGA)的渐近正态性来近似对抗扰动的后验分布,以此为基础生成可迁移的对抗样本,为解决对抗样本迁移性不足的问题提供了新思路。
- 结合多种策略:将深度集成策略与ANDA相结合形成MultiANDA,通过多次重复ANDA并添加随机初始值,实现对高斯混合分布的多模态边缘化,克服了单峰优化空间探索的局限,有效提高了生成对抗样本的多样性以及攻击的泛化性能。
- 优化目标改进:制定了新的优化目标,将对抗扰动建模为分布,通过最大化预期损失来更充分地探索高维潜在扰动空间,相较于传统的优化目标能更好地表征扰动信息,有助于生成更具迁移性的对抗样本。
- 实验验证优势:通过在ImageNet1k数据集上针对多类正常训练模型和先进防御模型开展大量实验,全面且有效地验证了所提方法在攻击成功率等方面优于多种现有先进的黑盒攻击方法,凸显了所提方法在实际应用中的有效性和优越性。
不足
- 风险未深入应对:虽然在研究中认识到对抗攻击算法存在被滥用的风险,但并没有提出具体、深入的应对措施,只是点明需要关注这一问题,缺乏相应的风险防控机制等内容。
- 模型根本性缺陷解决待完善:文中指出了现代深度学习模型存在根本缺陷,所提方法主要聚焦于攻击层面,对于如何从根源上彻底解决这些模型缺陷,进而打造出更安全、鲁棒的模型,还没有给出具体且成熟的方案,只是提出了大致的研究方向。
未来研究方向
- 强化模型安全性:致力于开发更先进的深度学习模型,使其能更好地与人类视觉偏好对齐,从根本上避免现有模型容易被攻击的缺陷,可从模型架构创新、训练方法改进以及深入理解并模拟人类视觉感知机制等多方面入手,全方位提升模型面对对抗攻击时的安全性和鲁棒性。
- 风险管控研究:针对对抗攻击算法可能被滥用的风险,深入开展相关研究,比如制定有效的风险评估标准、构建合理的管控机制以及探索防御策略的优化方向等,确保这类算法在合理范围内被应用,保障相关依赖深度学习模型的系统安全稳定运行。