1 问题描述
- 一个长期正常运行的FlinkSqlCdcJob(
Flink 1.12、Flink CDC 1.3.0),运行崩溃,且TaskManager的日志(taskmanager.log)报: akka 异常
- 作业运行崩溃的时间点:
2025/01/01 09:24:17
log
...
2025-01-01 09:22:14,965 INFO org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction [] - FlinkKafkaProducer 1/1 - checkpoint 16699 complete, committing transaction TransactionHolder{handle=KafkaTransactionState [transactionalId=null, producerId=-1, epoch=-1], transactionStartTime=1735694353482} from checkpoint 16699
2025-01-01 09:24:06,449 WARN akka.remote.ReliableDeliverySupervisor [] - Association with remote system [akka.tcp://flink-metrics@flink-236429.ns-69020:45033] has failed, address is now gated for [50] ms. Reason: [Disassociated]
2025-01-01 09:24:06,450 WARN akka.remote.ReliableDeliverySupervisor [] - Association with remote system [akka.tcp://flink@flink-236429.ns-69020:6123] has failed, address is now gated for [50] ms. Reason: [Disassociated]
<end>- 对比
JobManager的日志:无任何异常信息
log
...
2025-01-01 09:19:14,060 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Completed checkpoint 16698 for job 1dd034557a79ca16f8b692f44cbcf5b2 (1578642 bytes in 499 ms).
2025-01-01 09:22:14,232 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Triggering checkpoint 16699 (type=CHECKPOINT) @ 1735694534059 for job 1dd034557a79ca16f8b692f44cbcf5b2.
2025-01-01 09:22:14,963 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Completed checkpoint 16699 for job 1dd034557a79ca16f8b692f44cbcf5b2 (1578642 bytes in 591 ms).
<end>2 问题分析
解读错误日志
Association with remote system [akka.tcp://flink-metrics@flink-236429.ns-69020:45033] has failed, address is now gated for [50] ms. Reason: [Disassociated]
与远程系统akka.tcp://flink-metrics@flink-236429.ns-69020:45033关联失败,地址现在的阈值是50ms。原因:断联/解除关联
- 报错信息提示存在与远程系统的关联问题,具体是与名为
flink的Akka系统在flink-236429.ns-69020主机的6123端口上的关联。
这个报错提示说明
Jobmanager和TaskManager中的某个节点失去了联系 ,导致任务无法正常运行。可能是由于网络中断、节点宕机等原因导致的。
需要检查集群节点 的状态以及网络连接是否正常。
Akka系统
Flink的RPC实现:基于Scala的网络编程库Akka来的
Akka 简介:用于构建可伸缩、高可用性、低延迟的Java和Scala应用程序 的消息传递框架/RPC远程调用框架
Akka是一个用于构建可伸缩、高可用性、低延迟的Java和Scala应用程序 的消息传递框架
常用于构建大数据处理平台
Apache Flink/Spark的actor系统。
Akka是一个构建高度并发 和分布式应用 的工具包 和运行时环境
它基于Scala语言,但也支持Java。
- Akka系统的核心作用和特点,包括:
- 并发性:Akka利用Actor模型来实现并发性,Actor是Akka中的基本并发单元。
对并发模型进行了更高的抽象。
每个Actor都是一个并发执行的对象,它们之间通过消息传递来通信,这样可以避免共享状态和锁的使用,从而简化并发编程。
- 轻量
轻量级事件处理(1GB内存可以以容纳百万级别的Actor)
- 异步、非阻塞、高性能的事件驱动编程模型
事件驱动架构:Akka适合构建事件驱动的架构,因为它可以轻松处理异步事件流,并且可以与各种消息队列和事件源集成。
-
分布式系统:Akka支持构建分布式系统,允许Actor系统跨越多个节点和JVM实例。这意味着你可以在多个服务器上部署你的应用,并且这些服务器上的Actor可以像在同一个JVM中一样相互通信。
-
容错性:Akka提供了监督和监控机制,允许开发者定义Actor如何响应其他Actor的失败。这使得构建容错系统变得更加容易,因为你可以定义恢复策略,如重启失败的Actor或停止它们。
-
可伸缩性:由于Akka的Actor模型天然支持并发和分布式,因此可以轻松地通过增加更多的节点来扩展系统,以处理更多的负载。
-
消息驱动:Akka系统是消息驱动的,Actor通过消息传递来交互,这有助于解耦系统组件,并使得系统更加模块化。
-
持久性和持久状态:Akka支持持久化Actor状态,这意味着即使Actor重启,它们的状态也可以被恢复,这对于需要持久化状态的系统(如CQRS系统)非常有用。
-
插件和模块化:Akka提供了丰富的插件生态系统,允许开发者添加额外的功能,如持久化、分布式缓存、监控等。
-
跨语言支持:虽然Akka最初是为Scala设计的,但它也提供了对Java的支持,使得Java开发者也可以利用Akka构建并发和分布式系统。
-
集成和兼容性:Akka可以与现有的Java和Scala生态系统无缝集成,包括各种数据库、消息队列和Web框架。
Akka系统的设计哲学 是"一切皆Actor",这使得它非常适合构建复杂的并发和分布式系统,同时保持代码的可读性和可维护性。
Akka原理
Akka是一个网络编程库
Akka有2个重要的组成部分:Actor,ActorSystem
txt
可简单的理解为ActorSystem是一个小组,其中的Actor是一个组员。
我们开发过程中不可能是组和组之间的交流吧,肯定是【组员】和【组员】之间的交流,也就是【Actor】和【Actor】之间的通信
假如组员之间是【打电话】的话,那么是不是就【阻塞】了,你打电话啥都干不了了。
所以他们之间可以【发短信】,每个人都有手机,他们通过手机交流。
当然手机是有【手机号】的,也就是: akka.tcp://actorsydtem_name:主机:端口/user/actor_name。
当然组员之间想要通信,知道了他的【手机号】还不够,还得有【短信终端】啊,这个也就是 【ActorRef】。ActorSystem是管理Actor生命周期的组件,Actor是负责进行通信的组件- 每个
Actor都有一个MailBox(在Flink源码中经常可以看到,checkpoint通知就是基于此),别的Actor发送给它的消息都是首先存储在MailBox中,通过这种方式可以实现异步通信 - 单个
Actor可以改变他自身的状态,可以接收消息,也可以发送消息,还可以生成新的Actor - 每个
Actor是单线程 的处理,不断从MailBox中拉取消息执行处理
所以对于
Actor的消息处理,不适合调用阻塞的处理方式。
- 每个
ActorSystem和Actor都在启动时候会给一个Name
如果要从
Actor获取一个Actor,则通过以下方式进行Actor的获取:
akka.tcp://actorsydtem_name:主机:端口/user/actor_name来进行定位的。例如:
akka.tcp://flink@flink-236429.ns-69020:6123
- 如果一个
Actor要和另外一个Actor进行通信,则必须先获取对象的Actor的ActorRef对象,然后通过该对象发送消息即可。 - 通过
tell发送异步消息 ,不接受响应 ;通过ask发送异步消息,得到future返回,通过异步回调返回处理结果。
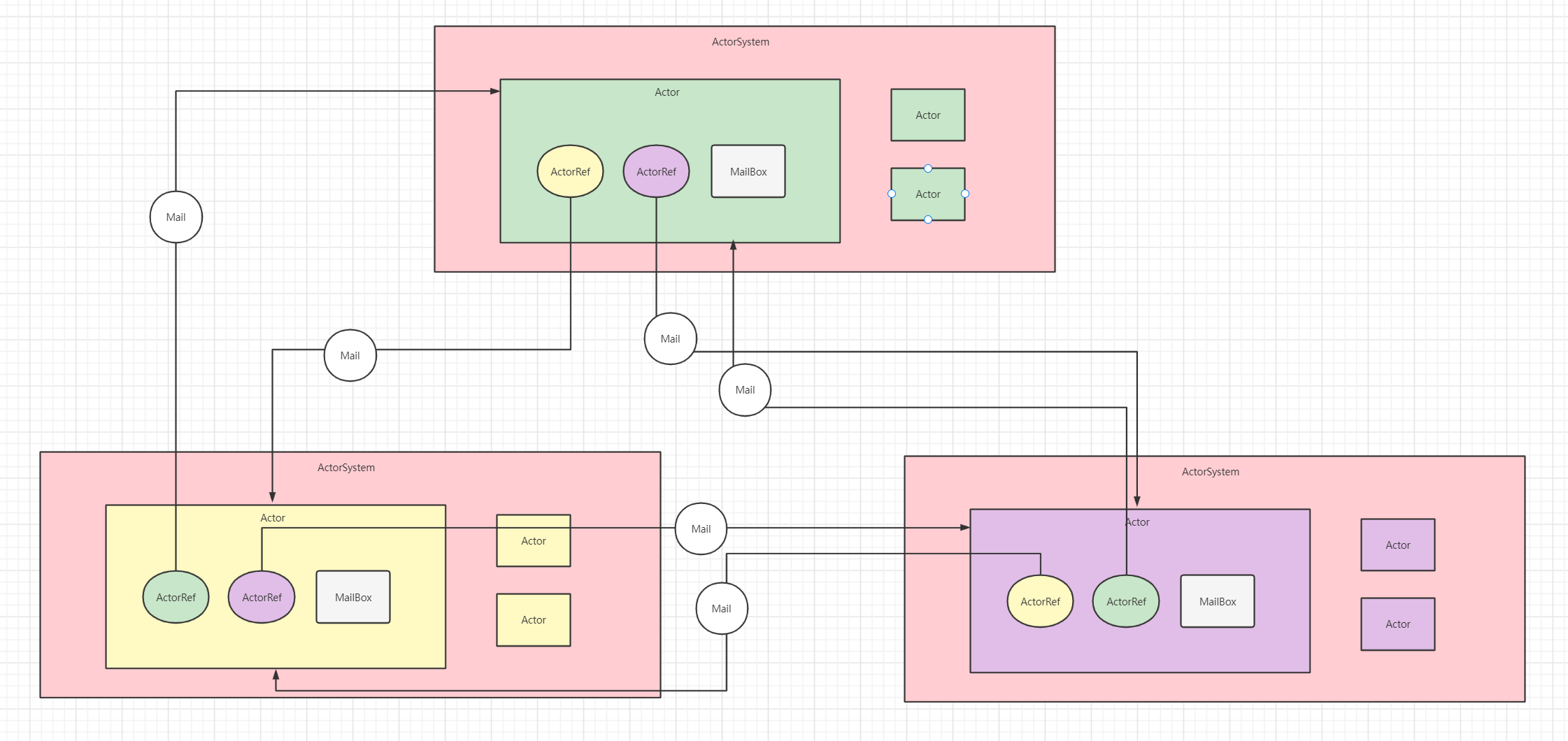
使用Akka模拟实现Flink Standalone集群通信
需求
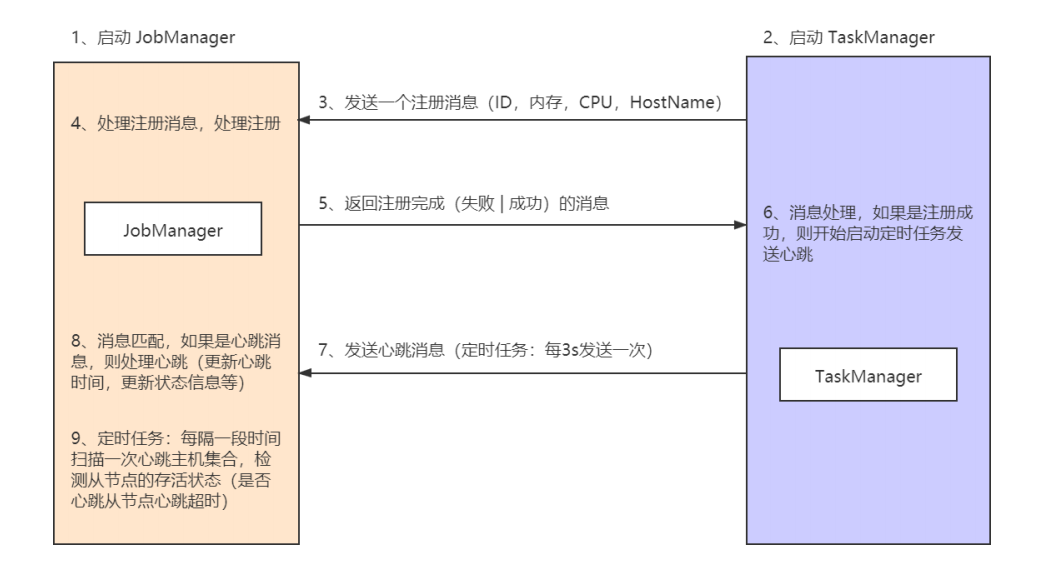
- 需求:
1、两个进程: JobManager、TaskManager
2、当TaskManager启动的时候,向JobManager发送注册信息,报告本地的内存、CPU
3、当JobManager收到注册消息的时候,返回给TaskManager注册成功的消息
4、TaskManager每间隔三秒向JobManager发送心跳消息
5、JobManager每间隔3秒扫描一下,有哪些TaskManager下线了
代码实现: TaskManager
java
public class TaskManager extends UntypedActor {
public static Props props() {
return Props.create(TaskManager.class, () -> new TaskManager());
}
private final static ActorSystem TASKMANAGER_SYSTEM;
private final static ActorRef TASKMANAGER_ACTOR;
private final static int PORT;
private final static StandaloneConfig STANDALONE_CONFIG = new StandaloneConfig();
static {
PORT = STANDALONE_CONFIG.getTaskManagerPort();
Map<String, Object> conf = new HashMap<>();
conf.put("akka.remote.netty.tcp.hostname", STANDALONE_CONFIG.getTaskManagerHost());
conf.put("akka.remote.netty.tcp.port", PORT);
conf.put("akka.actor.provider", "akka.remote.RemoteActorRefProvider");
Config config = ConfigFactory.parseMap(conf);
TASKMANAGER_SYSTEM = ActorSystem.create(STANDALONE_CONFIG.getTaskManagerSystemName(), config);
TASKMANAGER_ACTOR = TASKMANAGER_SYSTEM.actorOf(TaskManager.props(), STANDALONE_CONFIG.getJobManagerActorName());
}
@Override
public void onReceive(Object message) throws Throwable {
}
@Override
public void preStart() throws Exception {
RegistTaskManager registTaskManager = new RegistTaskManager();
registTaskManager.setCpu(64);
registTaskManager.setMemory(128);
registTaskManager.setHostname(STANDALONE_CONFIG.getTaskManagerHost());
registTaskManager.setPort(PORT);
String taskMId = (registTaskManager.getHostname() + ":" + PORT).hashCode() + "";
registTaskManager.setTaskManagerId(taskMId);
String template = "akka.tcp://%s@%s:%d/user/%s";
String jobmanagerUrl = String.format(template, STANDALONE_CONFIG.getJobManagerSystemName(),
STANDALONE_CONFIG.getJobManagerHost(), STANDALONE_CONFIG.getJobManagerPort(), STANDALONE_CONFIG.getJobManagerActorName());
System.out.println(jobmanagerUrl);
ActorSelection jobmanagerActor = getContext().actorSelection(jobmanagerUrl);
Timeout t = new Timeout(Duration.create(10, TimeUnit.SECONDS));
//注册获取回调,并且绑定发送心跳
Future<Object> ask = Patterns.ask(jobmanagerActor, registTaskManager, t);
ask.onSuccess(new OnSuccess<Object>() {
@Override
public void onSuccess(Object result) throws Throwable {
if ("注册成功".equalsIgnoreCase((String)result)) {
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor();
service.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
Heartbeat heartbeat = new Heartbeat();
heartbeat.setTaskId(registTaskManager.getTaskManagerId());
jobmanagerActor.tell(heartbeat,getSelf());
System.out.println("发送心跳");
}
}, 0, 3, TimeUnit.SECONDS);
}
}
}, TASKMANAGER_SYSTEM.dispatcher());
}
public static void main(String[] args) throws Exception {
}代码实现:JobManager
java
public class JobManager extends UntypedActor {
public static Props props() {
return Props.create(JobManager.class, () -> new JobManager());
}
private final static ActorSystem JOBMANAGER_SYSTEM;
private final static ActorRef JOBMANAGER_ACTOR;
private ConcurrentHashMap<String,TaskManagerInfo> taskManagerInfoConcurrentHashMap = new ConcurrentHashMap<>();
static {
StandaloneConfig STANDALONE_CONFIG = new StandaloneConfig();
Map<String, Object> conf = new HashMap<>();
conf.put("akka.remote.netty.tcp.hostname", STANDALONE_CONFIG.getJobManagerHost());
conf.put("akka.remote.netty.tcp.port", STANDALONE_CONFIG.getJobManagerPort());
conf.put("akka.actor.provider","akka.remote.RemoteActorRefProvider");
Config config = ConfigFactory.parseMap(conf);
JOBMANAGER_SYSTEM = ActorSystem.create(STANDALONE_CONFIG.getJobManagerSystemName(), config);
JOBMANAGER_ACTOR = JOBMANAGER_SYSTEM.actorOf(JobManager.props(), STANDALONE_CONFIG.getJobManagerActorName());
}
@Override
public void onReceive(Object message) throws Throwable {
if (message instanceof CheckTimeout){
System.out.println("开始心跳检测");
System.out.println("要检测的taskmanager数量: "+taskManagerInfoConcurrentHashMap.size());
Set<Map.Entry<String, TaskManagerInfo>> entries = taskManagerInfoConcurrentHashMap.entrySet();
Iterator<Map.Entry<String, TaskManagerInfo>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry<String, TaskManagerInfo> entry = iterator.next();
TaskManagerInfo next = entry.getValue();
long l = System.currentTimeMillis();
if ((l - next.getLastHeartbeatTime()) > 6000){
iterator.remove();
taskManagerInfoConcurrentHashMap.remove(next.getTaskManagerId());
System.out.println(next.getTaskManagerId() +" 下线了");
}
}
}
if (message instanceof RegistTaskManager){
RegistTaskManager registTaskManager = (RegistTaskManager) message;
TaskManagerInfo taskManagerInfo = new TaskManagerInfo();
taskManagerInfo.setCpu(registTaskManager.getCpu());
taskManagerInfo.setHostname(registTaskManager.getHostname());
taskManagerInfo.setTaskManagerId(registTaskManager.getTaskManagerId());
taskManagerInfo.setMemory(registTaskManager.getMemory());
taskManagerInfoConcurrentHashMap.put(registTaskManager.getTaskManagerId(),taskManagerInfo);
System.out.println(taskManagerInfo.getTaskManagerId() +" 前来注册了");
getSender().tell("注册成功",getSelf());
}
if (message instanceof Heartbeat){
Heartbeat heartbeat = (Heartbeat) message;
String taskId = heartbeat.getTaskId();
TaskManagerInfo taskManagerInfo = taskManagerInfoConcurrentHashMap.get(taskId);
taskManagerInfo.setLastHeartbeatTime(System.currentTimeMillis());
System.out.println(taskId +" 前来心跳了");
}
}
@Override
public void preStart() throws Exception {
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor();
service.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
CheckTimeout checkTimeout = new CheckTimeout();
getSelf().tell(checkTimeout,getSelf());
}
}, 0, 3, TimeUnit.SECONDS);
}
public static void main(String[] args) throws Exception {
}
}3 解决方法
- 检查网络连接:确保你的机器能够网络连接到 flink-236429.ns-69020 主机的6123端口。
- 延伸:检查所有机器,hosts是否都配置了映射
-
检查所有机器,时间是否一致
-
检查
Akka配置和JobManager配置:确认 akka.tcp 协议、flink 系统名称以及端口号是否正确配置在Flink集群的配置文件中。
- Flink应用中,有时候在与远程系统建立连接时会出现问题,其中一种常见的问题是与远程系统(如:JobManager)的连接失败。
在 Flink 中,
Akka是用于实现分布式通信 和远程调用的框架 。当 Flink 运行时与远程系统建立连接时,它使用
Akka.Remote模块来处理通信。在这个过程中,如果发生了关联失败,通常会出现 "
akka.remote.ReliableDeliverySupervisor - Association with remote system has failed" 的错误信息。解决这个问题的一种方法是重新配置
Flink和Akka的相关参数,以便更好地适应远程系统的环境。
- 关键配置:
AkkaOptions/JobManagerOptionsAkkaOptions
akka.ask.timeout:用于异步futures和阻塞调用Akka的超时,如果flink因为超时而失败,则可以尝试增加此值,超时可能是由于机器速度慢或网络拥挤造成的。超时值需要时间单位说明符(ms/s/min/h/d)。源码默认值:10s。所属源码类:AkkaOptions。akka.tcp.timeout:用于和taskManager之间的通信,如果由于网络速度较慢而在连接TaskManager时遇到问题,则应增加此值。默认值:20s。源码类:AkkaOptions。akka.framesize:用于JobManager和TaskManager之间发送的最大消息大小,如果Flink失败是因为消息超过此限制,可以增加该值。消息大小需要大小单位说明符。默认值:10485760b(10m)。源码类:同上。akka.lookup.timeout:用于查找JobManager的超时。默认值10s。源码类:同上。
java
//demo code
import org.apache.flink.configuration.JobManagerOptions; //导入依赖的package包/类
private static void testFailureBehavior(final InetSocketAddress unreachableEndpoint) throws Exception {
final Configuration config = new Configuration();
config.setString(AkkaOptions.ASK_TIMEOUT, ASK_STARTUP_TIMEOUT + " ms");
config.setString(AkkaOptions.LOOKUP_TIMEOUT, CONNECT_TIMEOUT + " ms");
config.setString(JobManagerOptions.ADDRESS, unreachableEndpoint.getHostName());
config.setInteger(JobManagerOptions.PORT, unreachableEndpoint.getPort());
StandaloneClusterClient client = new StandaloneClusterClient(config);
try {
// we have to query the cluster status to start the connection attempts
client.getClusterStatus();
fail("This should fail with an exception since the endpoint is unreachable.");
} catch (Exception e) {
// check that we have failed with a LeaderRetrievalException which says that we could
// not connect to the leading JobManager
assertTrue(CommonTestUtils.containsCause(e, LeaderRetrievalException.class));
}
}-
检查Flink集群状态:确保Flink集群正在运行,并且所有必要的服务组件都是活跃的。
-
防火墙和安全组设置:确保没有防火墙或安全组规则阻止访问6123端口。
-
日志文件:查看Flink和应用程序的日志文件,以获取更多关于关联失败的详细信息。
-
版本兼容性:确保Flink的版本与尝试连接的版本兼容。
- 延伸:Scala版本是否和Flink兼容
- 延伸:客户端和服务器端的Scala版本是否一致
-
若Flink某个节点长时间FullGC导致akka通信超时,也是一个可能的原因,需针对性排查解决。
-
重启FlinkJob
如果单纯是偶然的网络波动,且短期内无法解决,则可尝试此法。
X 参考文献
- Flink底层实现Akka - CSDN 【参考/推荐】
- 这个意思是 jobmanager 失联了么? - 阿里云 【推荐】
- Handling Unreachable Nodes - Troubleshooting Cluster Issues - sap.com 【推荐】
问题现象:Data Hub未实现自动关闭功能,无法在发生崩溃时删除无法访问的节点。如果某个节点崩溃或由于网络问题而与集群隔离,则所有剩余节点都会报告丢失。
其余节点会重复记录这些警告,直到该节点重新上线,但会继续正常接受请求。当离线节点重新上线时,集群会自行修复,无需干预。
关键日志:`2016-11-14 14:52:15,146 WARN a.r.ReliableDeliverySupervisor Association with remote system akka.ssl.tcp://DataHubActorSystem@10.0.0.3:2552 has failed, address is now gated for 5000 ms. Reason:Disassociated
关键日志:
address is now gated for [50] ms. Reason: [Disassociated]
关键日志:
Association with remote system [akka.tcp://ClusterSystem@euler:9191] has failed, address is now gated for [5000] ms. Reason: [Disassociated]
关键日志:
WARN ReliableDeliverySupervisor: Association with remote system [akka.tcp://sparkMaster@s1:7077] has failed, address is now gated for [5000] ms. Reason: [Disassociated]问题现象:Spark在发布应用的时候,出现连接不上master问题
解决思路:检查所有机器时间是否一致、hosts是否都配置了映射、客户端和服务器端的Scala版本是否一致、Scala版本是否和Spark兼容
2018-11-18 23:24:09,594 ERROR akka.remote.Remoting - Association to [akka.tcp://flink@xxxx:46671] with UID [-435340187] irrecoverably failed. Quarantining address. java.util.concurrent.TimeoutException: Remote system has been silent for too long. (more than 48.0 hours)
关键日志:
WARN akka.remote.ReliableDeliverySupervisor [] - Association with remote system [akka.tcp://flink@localhost:6123] has failed, address is now gated for [50] ms. Reason: [Association failed with [akka.tcp://flink@localhost:6123]] Caused by: [java.net.ConnectException: Connection refused: taskmanager/xxxx:6123]问题现象:Flink集群能够启动,但是拉起任务时报错。检查Flink控制台页面,发现taskmamager注册的地址为127.0.0.1,而正常情况下,taskmanager应该以实际ip地址注册到jobmanager。
解决办法:在 flink-conf.yaml 这个配置文件的最后加一行 taskmanager.host: xxx.xxx.xxx.xxx,其中指定taskmanager的实际本机ip。
关键日志:
WARN akka.remote.ReliableDeliverySupervisor [] - Association with remote system [akka.tcp://flink@bigdata1:42567] has failed, address is now gated for [50] ms. Reason: [Association failed with [akka.tcp://flink@bigdata1:42567]] Caused by: [java.net.ConnectException: 拒绝连接: bigdata1/192.168.239.131:42567]问题现象:Flink-1.11.2 Standalone HA集群实现JobManager高可用主备切换报错。bigdata1节点、bigdata2节点实现JobManager的高可用主备切换,bigdata1被选为Leader,但bigdata2无法和bigdata1通信,bigdata2无法成为备用JobManager。
问题摘要:在Flink 1.11.2 Standalone HA集群中配置JobManager高可用时遇到问题,bigdata1作为Leader,bigdata2无法与其通信。报错信息涉及Akka远程连接失败,原因是网络连接被拒绝。通过调整
flink-conf.yaml中内存参数,重启集群,观察进程和Web UI,确认JobManager主备切换。当kill掉bigdata1的JobManager进程,bigdata2能成功接管,实现主备切换
AkkaOptions/JobManagerOptions