个人博客地址:调试Hadoop源代码 | 一张假钞的真实世界
Hadoop版本
Hadoop 2.7.3
调试模式下启动Hadoop NameNode
在${HADOOP_HOME}/etc/hadoop/hadoop-env.sh中设置NameNode启动的JVM参数,如下:
export HADOOP_NAMENODE_OPTS="-Xdebug -Xrunjdwp:transport=dt_socket,address=8788,server=y,suspend=y"
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"使用脚本${HADOOP_HOME}/sbin/start-dfs.sh启动HDFS,如果有以下提示信息则说明调试模式下启动NameNode成功:
Listening for transport dt_socket at address: 8788此时,如果执行jps查看java进程信息会有以下信息,是因为NameNode进程被挂起并处于监听状态,直到收到debug确认信息。
$ jps
10638 Jps
10438 -- main class information unavailable
2171
10508 DataNode设置断点
找到hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/namenode/NameNode.java并在main函数中设置断点,如下图:
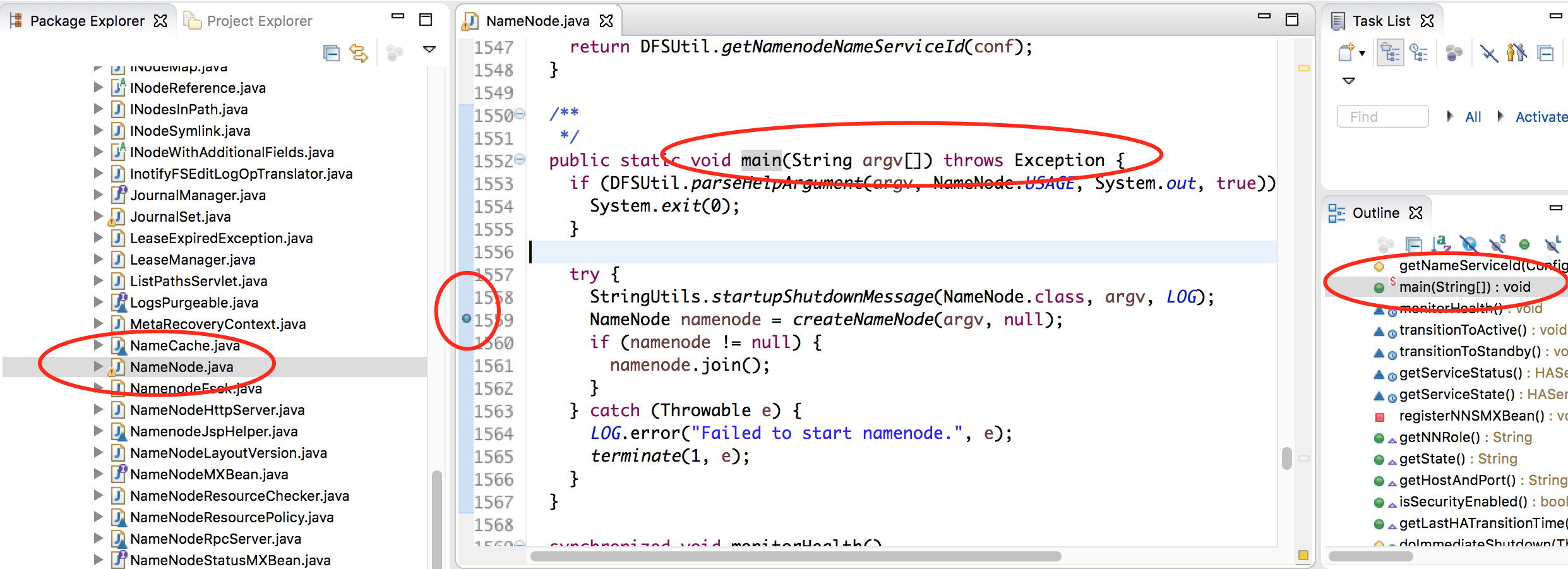
在Eclipse中调试
在NameNode.java代码中点击右键,在弹出的菜单中选择Debug As -> Debug Configurations...,在弹出的对话框中双击Remote Java Application,配置内容如图:
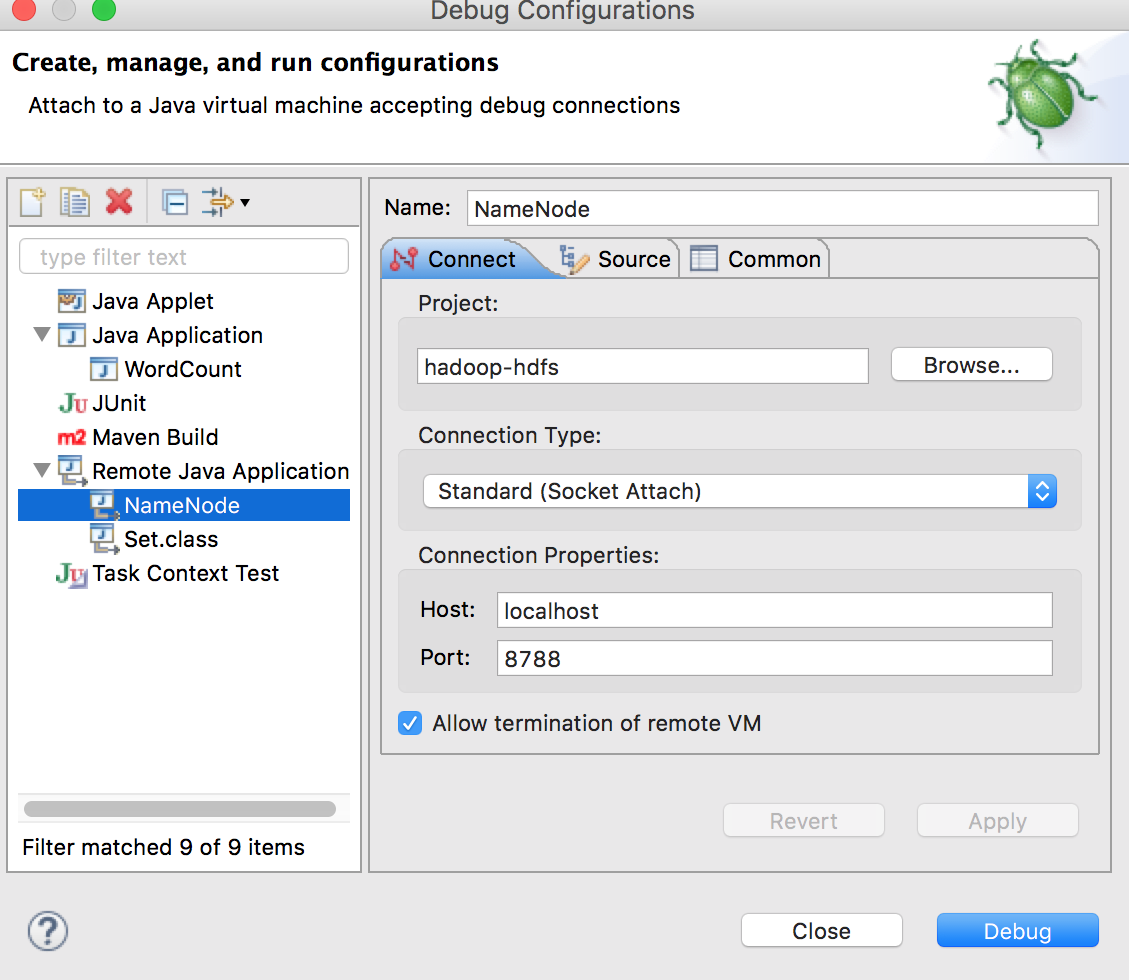
配置完成后点击Debug按钮进入调试界面。