关于普通聊天对接,目前已经完成了大部分讲解,剩下的就是最后一步,今天我们将重点讨论在返回参数时需要注意的几个关键点。为了更好地说明这些注意事项,我们仍然以OpenAI接口为例,逐步讲解相关的代码实现,帮助大家更清楚地理解这一部分的细节。
接下来,我们就直接看一下这一部分代码,分析其中的注意事项。
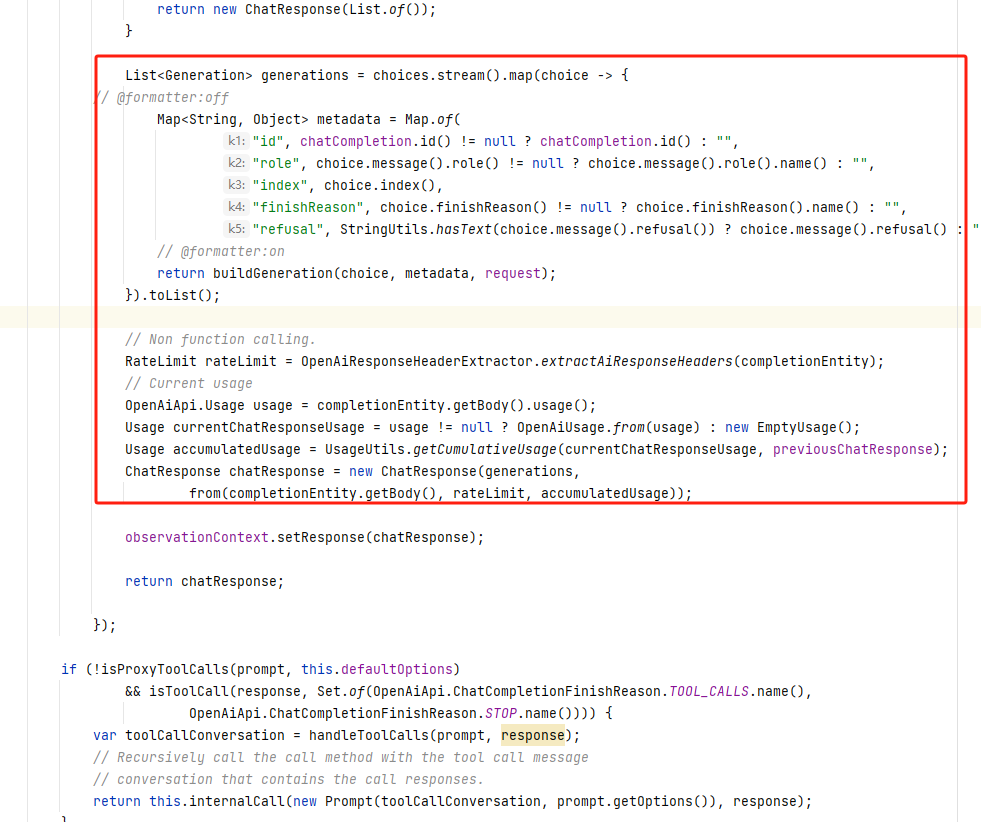
其实,对于这部分代码来说,核心逻辑的重点在于将大模型返回的内容封装到 response 中,从而完成对接工作。然而,值得注意的是,为什么代码中还要额外获取并处理一些看似并未直接使用的值,例如 metadata、rateLimit、usage 等?实际上,这并非多余的操作。这些信息虽然在当前版本的代码中并没有立即被使用,但它们的存在是为了为后续可能的需求变化做准备。
如果我们仅仅是为了简单地将获取到的返回内容输出给用户,其实是可以省去这些额外步骤的,也不需要做如此复杂的处理。如图所示:
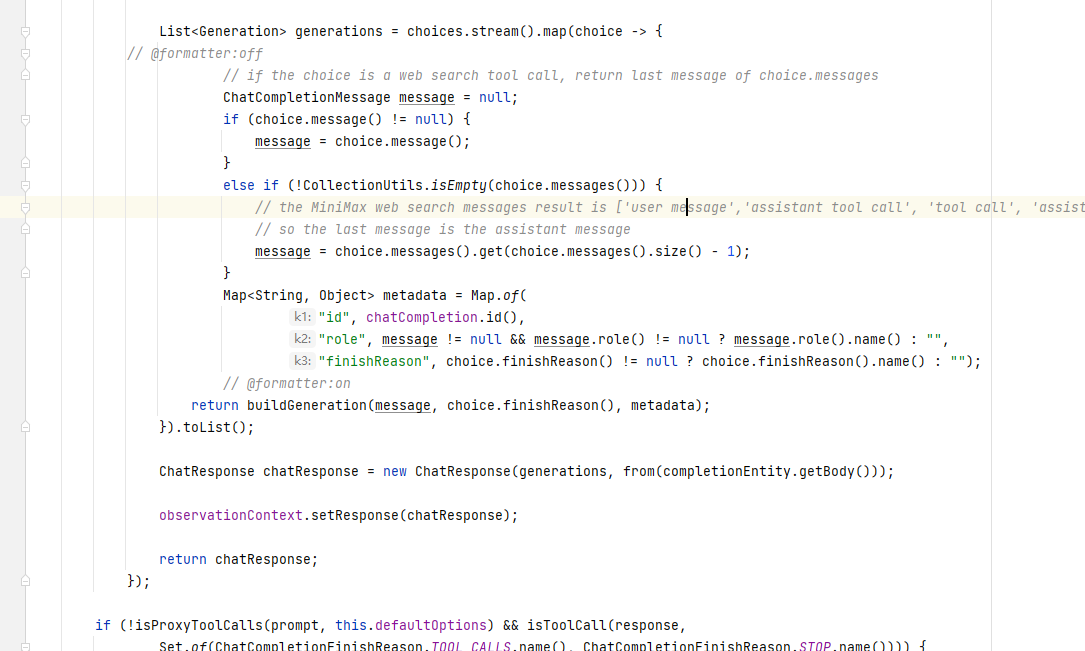
这是Minimax算法的处理方式,相较于OpenAI的处理方式,这里采用的方法显得更加简洁和直观。因此,这部分代码的实现较为简单,理解后可以快速跳过,不必深入细节。在实际应用中,只需要在有用的地方将相应的信息提取并填充到response对象中即可。
如果某些信息在当前上下文中并未使用到,那么就不需要进行封装或处理,避免不必要的复杂度。
ChatGenerationMetadata
buildGeneration的核心逻辑其实就是在寻找需要的工具调用和结束信息,核心代码如下所示,看一下:
java
private Generation buildGeneration(Choice choice, Map<String, Object> metadata, ChatCompletionRequest request) {
List<AssistantMessage.ToolCall> toolCalls = choice.message().toolCalls() == null ? List.of()
: choice.message()
.toolCalls()
.stream()
.map(toolCall -> new AssistantMessage.ToolCall(toolCall.id(), "function",
toolCall.function().name(), toolCall.function().arguments()))
.toList();
String finishReason = (choice.finishReason() != null ? choice.finishReason().name() : "");
var generationMetadataBuilder = ChatGenerationMetadata.builder().finishReason(finishReason);
List<Media> media = new ArrayList<>();
String textContent = choice.message().content();
var audioOutput = choice.message().audioOutput();
if (audioOutput != null) {
String mimeType = String.format("audio/%s", request.audioParameters().format().name().toLowerCase());
byte[] audioData = Base64.getDecoder().decode(audioOutput.data());
Resource resource = new ByteArrayResource(audioData);
Media.builder().mimeType(MimeTypeUtils.parseMimeType(mimeType)).data(resource).id(audioOutput.id()).build();
media.add(Media.builder()
.mimeType(MimeTypeUtils.parseMimeType(mimeType))
.data(resource)
.id(audioOutput.id())
.build());
if (!StringUtils.hasText(textContent)) {
textContent = audioOutput.transcript();
}
generationMetadataBuilder.metadata("audioId", audioOutput.id());
generationMetadataBuilder.metadata("audioExpiresAt", audioOutput.expiresAt());
}
var assistantMessage = new AssistantMessage(textContent, metadata, toolCalls, media);
return new Generation(assistantMessage, generationMetadataBuilder.build());
}无论在何种情况下省略逻辑,toolCalls和finishReason这两个要素是必须要被识别和处理的。除非某个大型模型不支持toolCalls功能,否则我们在实现时不应忽略它们。实际上,绝大多数主流的大型模型都具备这部分功能,因为如果一个模型缺失了toolCalls功能,这意味着它无法支持Agent的开发和运行,进而就失去了介入Spring AI生态系统的基本目的。总之,确保对这两个关键要素的识别,对于实现模型的有效性和功能完整性至关重要。
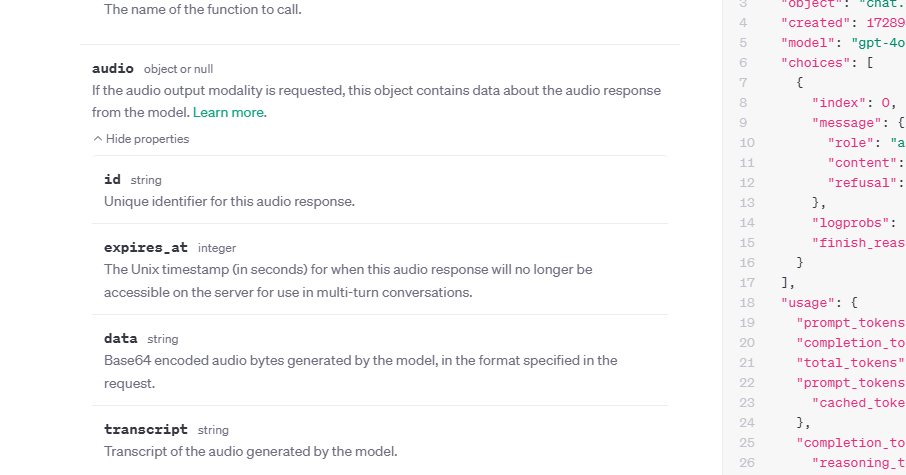
关于media是因为OpenAI接口是会返回此信息字段,看下接口文档:
除此之外ChatGenerationMetadata目前除了finishReason我找到了使用目的,其他的还未找到用处,ChatGenerationMetadata功能基本如下:
- 可以用来测试
- 可以用来观测
- 目前还没咋用上,先留个心
ChatResponseMetadata
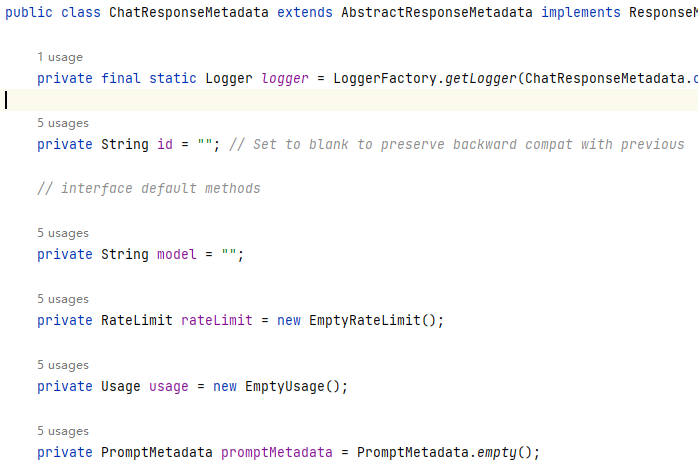
作用也是一样的,仍然是为了观测使用,只不过他封装的信息和上面有一些区别而已。如图所示:
Usage
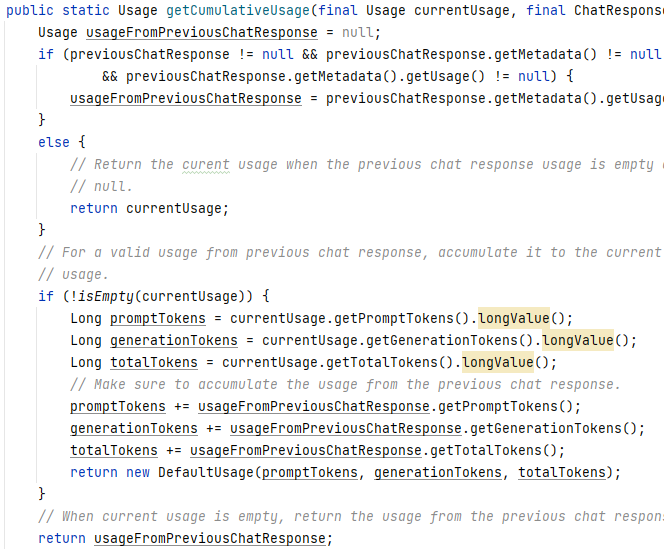
本质上,这只是一个用于统计token使用情况的信息,功能上并没有特别复杂的内容,理解起来并不难。如果你之前不太了解这部分的细节,可以查看它的核心代码,这将帮助你迅速掌握其工作原理。
需要注意的是,绝大多数大型模型接口都提供了类似的字段,因为在实际应用中,了解token的消耗情况非常重要,毕竟资源的投入(如费用)最终需要与使用效果相对应,这也是模型开发者和使用者关心的重点之一。如图所示:
总结
在这一部分的讲解中,我们详细探讨了返回参数处理的关键要点,特别是如何封装与使用相关的字段。尽管某些信息(如metadata、rateLimit等)在当前实现中未直接用到,但它们的引入是为了更好地支持未来的扩展和需求变化。
通过对比不同处理方式,我们也看到不同模型接口在设计上的差异。在实际开发过程中,理解这些细节对于保证接口的扩展性和系统的稳定性至关重要。
我是努力的小雨,一个正经的 Java 东北服务端开发,整天琢磨着 AI 技术这块儿的奥秘。特爱跟人交流技术,喜欢把自己的心得和大家分享。还当上了腾讯云创作之星,阿里云专家博主,华为云云享专家,掘金优秀作者。各种征文、开源比赛的牌子也拿了。
💡 想把我在技术路上走过的弯路和经验全都分享出来,给你们的学习和成长带来点启发,帮一把。
🌟 欢迎关注努力的小雨,咱一块儿进步!🌟