1. 前言
到目前为止,MySQL 对于我们来说还是一个"黑盒子",我们只知道如何使用客户端同服务器交互,但是内部将数据存放到了哪里?存放的格式和组织形式是什么?是怎么样获取数据的?这些问题我们统统不知道
事实上 MySQL 服务器当中负责写入数据和读取数据的工作交由 存储引擎 来完成,MySQL 中又支持不同的存储引擎,比如 InnoDB、MyISAM、Memory,不同存储引擎的原理和底层存储格式均不一样,目前主流开发都使用的是 InnoDB 存储引擎,因此接下来讲述的也主要是 InnoDB 存储引擎当中的记录存储格式
2. InnoDB 页简介
我们都知道 MySQL 存储数据一定是存储在硬盘上进行持久化的(因为电脑重启后数据仍然存在不会丢失),但是我们在插入或者删除一条记录,每次都要和硬盘交互吗?这样的话效率就太低了,因此 InnoDB 使用页结构作为内存和磁盘交互的基本单位,即一次最少从硬盘中读取一页的数据加载到内存,一次最少从内存写入一页的数据到硬盘上
💡 注意:在 InnoDB 存储引擎中,可以使用
innodb_page_size系统变量查看页大小,默认是16384个字节即16KB,只会在服务器第一次初始化数据目录指定,后续不可更改!

3. InnoDB 行格式
事实上,我们在 MySQL 当中插入一条记录的时候,MySQL 存储到硬盘上对应的格式就叫做行格式,InnoDB 设计者设计了多种行格式,比如 COMPACT、REDUND ANT、DYNAMIC、COMPRESSED 格式,不同行格式之间大同小异
3.1 指定行格式的语法
我们可以手动在创建表或者修改表的时候指定行格式:
- 创建表:
CREATE TABLE 表名 (列信息) ROW_FORMAT=行格式名称; - 修改表:
ALTER TABLE 表名 ROW_FORMAT=行格式名称;
比如我们可以在 xiaohaizi 数据库当中创建一个演示表 record_format_demo
sql
mysql> use xiaohaizi;
Database changed
mysql> create table record_format_demo (
-> c1 varchar(10),
-> c2 varchar(10) not null,
-> c3 char(10),
-> c4 varchar(10)
-> ) charset=ascii row_format=compact;
Query OK, 0 rows affected (0.04 sec)此时我们创建的表的行格式就是 COMPACT 类型,并且我们还指定字符集使用 ASCII,即只能存储英文、数字、标点符号(不能存储中文),现在我们向该表中插入两条记录:
sql
mysql> insert into record_format_demo (c1, c2, c3, c4) values ('aaaa', 'bbb', 'cc', 'd'), ('eeee', 'fff', null, null);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0现在我们表中的数据如下图所示:

3.2 COMPACT 行格式
COMPACT 行格式存储结构如下图所示:

从图中可以看出,一条行格式记录可以分为两部分组成:额外信息区和真实数据区,下面就来分别看下这两部分的组成:
3.2.1 记录的额外信息区
这部分信息是为了更好的管理行记录不得不添加的一些额外信息,主要包含三部分构成:变长字段长度列表、NULL 空值列表、记录头信息
3.2.1.1 变长字段长度列表
因为 MySQL 支持一些可变长字段,比如 VARCHAR(M)、TEXT、BLOB类型,这些可变长字段占用的存储空间是不确定的,因此需要额外空间记录这些字段占用的实际长度,在 COMPACT 行格式中,各个变长字段实际占用长度会按照列的顺序逆序存放(至于为什么要逆序,下一章会介绍)
我们拿 record_format_demo 表中第一条记录进行举例:c1、c2、c4都是 varchar 类型,实际值为 'aaaa', 'bbb', 'd',使用 ascii 编码,分别占用的存储空间是 04,03,01(单位是字节),因此在内部记录的行格式如下:

由于第一条记录当中存储的值非常小,'aaaa'仅用四个字节就可以存储,但是有些情况下列值很大,使用一个字节可能表示不了其长度,此时就可能使用两个字节表示其长度,那么具体是使用一个字节还是两个字节,InnoDB 有其自身的一套规则,为了更好地解释这个规则,我们考虑引入 W、M、L这几个符号,先来看看符号各自的含义:
- W:对于某个字符集,最多需要用 W 个字节来表示一个字符,比如 utf8mb4 字符集就最多需要用 4 个字节表示一个字符,utf8 字符集中 W 就是3,gbk 中 W 就是 2,ASCII 中 W 就是 1
- M:最多存储 M 个字符,比如 VARCHAR(256) 就表示最多存储 256 个字符
- L:表示真实列值实际占用的存储长度
具体使用一字节还是两字节规则如下:
- 如果 M x W <= 255,则使用 1 字节来表示长度
- 如果 M x W > 255,则分为以下两种情况:
- 如果 L <= 127 ,使用 1 字节表示
- 如果 L > 127,使用 2 字节表示
⭐ 扩展知识:MySQL 在读取变长字段长度的时候如何确定是使用 1 个字节还是 2 个字节表示呢?InnoDB 设计者使用第一个比特位作为标志位,如果为 0 则使用 1 个字节,为 1 则使用 2 个字节,这也解释了为什么上面提到的 L 的分隔是 127
3.2.1.2 NULL 空值列表
我们又会发现,一条记录中某些列的值可以为 null,如果把这些 null 值都存放到真实数据区会特别占用存储空间,因此 InnoDB 设计者统一使用 NULL 空值列表来管理这些信息,其过程如下:
- 首先统计哪些列可以为 null:其中主键列、使用 not null 约束修饰的列都不能存储 null 值
- 如果表中没有列可以为 null 就没有 NULL 空值列表了,否则就使用 1 个比特位对应 1 个列中记录是否为 null,如果该位为 1 ,则对应列为 null;若该位为 0 ,则表示不为 null (也是逆序存放)
- MySQL 规定:NULL 值列表必须使用整数个字节来表示,若不足则高位补 0,以第二条记录为例,其中 c1、c3、c4 列值可以为 null ,实际值中 c3、c4 列为 null,因此 NULL 空值列表使用 1 字节表示:00000110
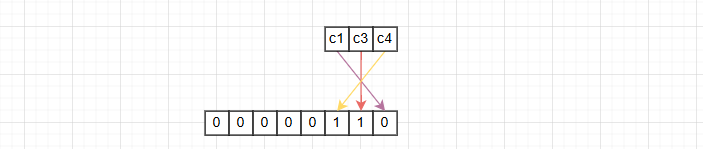 第二条记录的行格式如下图所示:
第二条记录的行格式如下图所示:

❗ 注意:如果一个可变长字段值为 null,则不会存放到变长字段长度列表当中,只会保存到 NULL 空值列表中
3.2.1.3 记录头信息
除了变长字段长度列表、NULL 空值列表以外,还有一块区域叫做记录头信息,占用固定 5 字节大小,主要用于保存记录的一些信息,一共 40 个比特位,其存储格式如下图所示:

| 名称 | 大小(位) | 描述 |
|---|---|---|
| 预留位1 | 1 | 没有使用 |
| 预留位2 | 1 | 没有使用 |
| delete_flag | 1 | 标记该记录是否被删除 |
| min_rec_flag | 1 | B+树每层非叶子节点最小的目录项为1 |
| n_owned | 4 | 一个页面的记录会分成若干组,每个组有一个带头大哥,记录组内小弟数目 |
| heap_no | 13 | 记录在堆中的相对位置 |
| record_type | 3 | 记录类型。0为普通记录;1为目录项;2为Infimum;3为Supremum |
| next_record | 16 | 下一条记录的相对位置 |
PS:这些字段现在不了解没有关系,后续都会逐步介绍的,现在留个印象就可以了。
3.2.2 记录的真实数据区
对于 record_format_demo 这张表来说,除了用户自定义的列以外,还会添加一些隐藏列,这些隐藏列信息如下:
| 名称 | 是否必须 | 描述 |
|---|---|---|
| DB_ROW_ID | 否 | 行ID,标识唯一一条记录 |
| DB_TRX_ID | 是 | 事务ID |
| DB_ROLL_PTR | 是 | 回滚指针 |
这里就有必要提到 主键生成策略 了:如果用户表中定义了主键,则使用用户定义的主键列,如果用户没有显式指定主键,就使用表中不为 null 值且具有 unique 约束的列作为主键,如果上述列都不存在就会自动添加 DB_ROW_ID 的列作为主键
所以 InnoDB 存储引擎的完整行格式如下:

3.2.3 CHAR(M) 列的存储格式
我们已经知道对于 VARCHAR 等变长字段的长度会存放到变长字段长度列表当中,但是如果是 CHAR 类型也是有可能存放到变长字段长度列表中的,只要当前所采用的字符集是一个变长编码字符集(比如 gbk 使用 1-2 个字节存储一个字符)就会把其实际长度存放到变长字段列表中
另外还有一点需要注意:设计 COMPACT 行格式的人规定对于采用变长编码集的 CHAR(M) 类型至少需要占用 M 个字节,即如果采用 utf8 编码使用 CHAR(10) 列,则其存储范围就是为 10-30 字节,这是为了防止更新一个更小数据时需要重新分配空间的问题
3.3 REDUNDANT 行格式
3.3.1 存储结构
掌握了 COMPACT 行格式以后,其他行格式就是依葫芦画瓢了,为了知识的完整性还是得介绍一下,REDUNDANT 行格式存储结构如下图所示:

我们直接来比较两种行格式的区别:
字段长度偏移列表:首先它没有变长两字,说明它不会区分变长字段和非变长字段,全部逆序存放到列表当中,另外它使用偏移量差值来表示字段的长度
记录头信息:REDUNDANT 行格式记录头信息占用 6 个字节,总计 48 个比特位,各个位含义如下:
| 名称 | 大小(位) | 描述 |
|---|---|---|
| 预留位1 | 1 | 没有使用 |
| 预留位2 | 1 | 没有使用 |
| delete_flag | 1 | 标记该记录是否被删除 |
| min_rec_flag | 1 | B+树每层非叶子节点最小的目录项为1 |
| n_owned | 4 | 一个页面的记录会分成若干组,每个组有一个带头大哥,记录组内小弟数目 |
| heap_no | 13 | 记录在堆中的相对位置 |
| n_field | 10 | 记录列的数量 |
| 1byte_offs_flag | 1 | 标记每个列对应偏移量使用1字节还是2字节 |
| next_record | 16 | 下一条记录的相对位置 |
那么对于每个列的偏移量来说到底是使用 1 个字节存储还是使用 2 个字节存储呢?REDUNDANT 行格式比较粗暴:直接采用整个记录的真实数据长度决定:
- 当整个记录长度 <= 127 时采用 1 字节表示
- 当整个记录长度 > 127 并且 <= 32767 时使用 2 字节
- 当整个记录长度 > 32767 时也是使用 2 字节,但溢出部分存放到溢出列当中
为了在解析数据时能够清楚知道是使用 1 字节还是 2 字节,还特意保留了一个1byte_offs_flag,若该值为 0则使用 2 字节,若该值为 1 则使用 1 字节
3.3.2 NULL 值处理
因为 REDUNDANT 行格式中没有 NULL 空值列表,因此设计改行格式的大佬使用偏移列表中第一个比特位作为是否为 NULL 的依据,若该位为1则该值为 NULL,否则不为 NULL,这也解释了为什么上述讲到的为什么整条记录长度 <= 127 采用 1 字节
3.3.3 CHAR(M) 列的存储格式
REDUNDANT 行格式对于 CHAR(M) 列处理就比较粗暴,不管是变长编码集还是定长编码集,占用的存储空间就是 M * W 的结果,比如对于 UTF8 编码集,CHAR(10) 就固定占用 30 字节,虽然会浪费一些空间,但是省去了重新分配空间的开销
3.3.4 溢出列
如果插入的一条数据列值很大,但是一个页的大小只有 16 KB,如果一个页都存放不了一条记录,那不是很尴尬么?因此在 COMPACT 和 REDUNDANT 行格式中,如果列值很大此时就只会存储一部分真实数据,并将其余数据保存在其他页中,原先真实数据列值部分只会存储前 768 字节数据以及存储 20 字节的其他页的偏移地址,从而找到剩余的数据页,这些剩余的页就叫做溢出页,该列称为溢出列
溢出列临界点 :下面我们来简单计算下溢出列的临界点,InnoDB 规定一页至少存放两条记录(后续章节会解释),假设只有一个列值占用大小为 n,此时符合以下公式的会成为溢出列:132 + 2 * (27 + n) >= 16384
- 一个页中除记录外其余的一些存储信息(比如页目录、页头、页尾、文件头)占用 132 字节
- 每条记录需要的额外信息占用情况如下:2 字节存储真实长度、1 字节表示是否为 NULL、5 字节记录头信息,6 字节 ROW_ID、6 字节 TRX_ID、7 字节 ROLL_PTR 列
3.4 DYNAMIC 和 COMPRESSED 行格式
这两个行格式与 COMPACT 行格式非常类似,区别在于处理溢出列的过程上:它们不会在记录的真实数据上存储该列真实数据的前 768 个字节,而是全部存放到溢出页当中,只在记录的真实数据处保留 20 字节大小的指向溢出页的偏移地址,另外,COMPRESSED 行格式相较于 DYNAMIC 不同的一点就是会使用压缩算法对页面进行压缩,这里不再赘述