处理 PDF 文档时,提取公司名称、社会保险号或发票号等特定信息可能是一项挑战。在理想情况下,这些数据将存在于结构良好的表单字段中,可以通过编程轻松访问(包括使用 TX Text Control 功能)。但是,许多 PDF 文件都是扁平化的,这意味着表单字段被删除,只留下原始文本。
**++TX Text Control++**是一款功能类似于 MS Word 的文字处理控件,包括文档创建、编辑、打印、邮件合并、格式转换、拆分合并、导入导出、批量生成等功能。广泛应用于企业文档管理,网站内容发布,电子病历中病案模板创建、病历书写、修改历史、连续打印、病案归档等功能的实现。TX Text Control 基于预定义模板区域提供了强大的文本提取解决方案,允许您甚至可以从扁平化的 PDF 中提取结构化信息。
基于模板的文本提取涉及定义一个矩形(边界框),特定文本预计会出现在 PDF 文档中。定义此区域后,TX Text Control 便可提取定义矩形内的文本行,确保数据检索准确。
- 定义模板:识别示例文档中的已知文本字符串并在其周围定义边界框。
- 应用模板:在其他类似文档上使用相同的选择框来提取相关文本。
- 提取文本:TX 文本控件允许您在定义的矩形内搜索文本并从中检索有意义的数据。
实现基于模板的文本提取
第一步,我们希望确定已知文档中已知数据的文本位置。使用示例 PDF,找到在特定位置一致出现的已知文本(例如公司名称或发票号码)。
让我们看一下非常典型的美国税表W9。
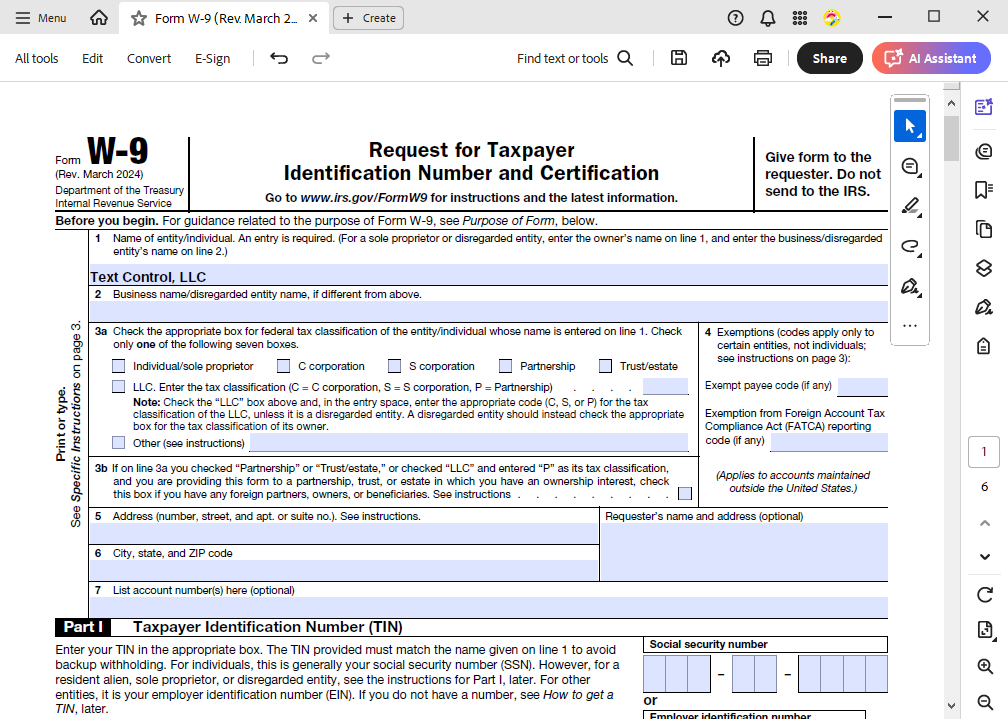
该文档仍然启用了表单字段,如果我们有权访问该文档,则只需遍历表单字段即可使用 TX Text Control 轻松提取数据。
但在这种情况下,我们无法访问源文档,只能访问扁平化版本,其中所有表单字段都已被删除,只有文本可见。
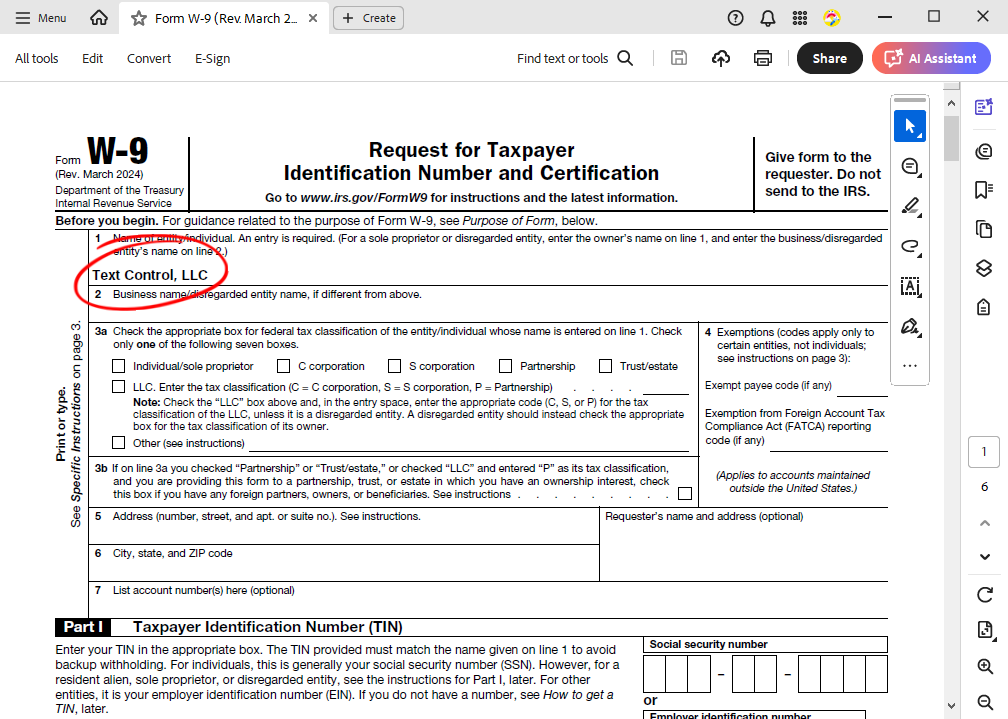
现在我们要定义矩形来搜索公司名称。
创建应用程序
为了演示使用 TX 文本控制库实现这一点有多么简单,我们将使用 .NET 控制台应用程序。
确保您下载了.NET 8 SDK附带的最新版本的 Visual Studio 2022 。
-
在 Visual Studio 2022 中,通过选择*"创建新项目"来创建新项目*。
-
选择控制台应用程序 作为项目模板然后单击下一步确认。
-
为您的项目选择一个名称然后单击下一步确认。
-
在下一个对话框中,选择*.NET 8 (长期支持)* 作为框架 并通过创建进行确认。
添加 NuGet 包
-
在解决方案资源管理器 中,选择您创建的项目,然后从项目 主菜单中选择管理 NuGet 包...。
从包源 下拉菜单中选择文本控制离线包。
安装以下软件包的最新版本:
- TXTextControl.TextControl.ASP.SDK

训练数据
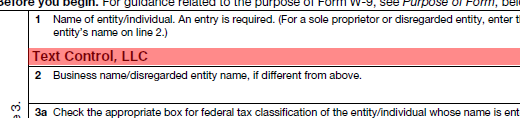
以下代码使用 TX Text Control 查找我们的训练数据"Text Control, LLC"的已知值,并返回稍后将用于所有其他文档的位置。
using TXTextControl.DocumentServer.PDF.Contents;
try
{
string pdfFilePath = "FormW9.pdf";
// Check if the file exists before processing
if (!File.Exists(pdfFilePath))
{
Console.WriteLine($"Error: File '{pdfFilePath}' not found.");
return;
}
// Load PDF lines
var pdfLines = new Lines(pdfFilePath);
// Find the target text
var trainLines = pdfLines.Find("Text Control, LLC");
// Check if any lines were found before accessing the index
if (trainLines.Count > 0)
{
Console.WriteLine(trainLines[0].Rectangle.ToString());
}
else
{
Console.WriteLine("Text not found in the PDF.");
}
}
catch (Exception ex)
{
Console.WriteLine($"An error occurred: {ex.Message}");
}控制台包含找到的文本的位置。
{X=1192,Y=2566,Width=1510,Height=180}
提取文本
下一个代码片段加载第二个文档并在给定的矩形中搜索文本,该文本是我们从训练数据中检索到的。
using System.Drawing;
using TXTextControl.DocumentServer.PDF.Contents;
try
{
string pdfFilePath = "FormW9_2.pdf";
// Check if the file exists before processing
if (!File.Exists(pdfFilePath))
{
Console.WriteLine($"Error: File '{pdfFilePath}' not found.");
return;
}
// Load PDF lines
var pdfLines = new Lines(pdfFilePath);
// Define the search area
var searchRectangle = new Rectangle(1192, 2566, 1510, 180);
// Find text within the defined rectangle (include partial matches)
var contentLines = pdfLines.Find(searchRectangle, true);
// Filter only page 1 content lines
var page1ContentLines = contentLines.Where(cl => cl.Page == 1).ToList();
// Check if any content was found
if (page1ContentLines.Count > 0)
{
Console.WriteLine(page1ContentLines[0].Text);
}
else
{
Console.WriteLine("No content found in the specified rectangle on page 1.");
}
}
catch (Exception ex)
{
Console.WriteLine($"An error occurred: {ex.Message}");
}控制台包含从第二个文档中提取的文本。
Document Processing Enterprises Ltd.
因为我们使用了Findtrue方法的第二个参数,所以搜索将返回整行,即使在这种情况下公司名称更长。
即使公司名称到了行末,它也会找到正确的值。

This is a very long company name - This is a very long company name - This is a very long company name
结论
基于模板的文本提取是一项强大的功能,可用于从 PDF 文档中提取结构化信息。通过在已知文本周围定义一个矩形,TX Text Control 可以从类似文档中提取文本,即使文本不在表单字段中。
慧都是Text Control的官方授权代理商,提供TX Text Control 系列产品免费试用,咨询,正版销售等于一体的专业化服务。