个人说明
1:个人所有技术文章后期将同步在博客园( 木二 IT中国人 )和CSDN( 木二_ )更新;
2:当前Kubernetes最新版 v1.32.2 的部署做了大量优化,部分组件采用helm部署,省略了预下载镜像的操作,采用更新部署的镜像源,containerd在内的部分组件配置进行了优化;
3:有没有合适的运维管理,运维经理,运维工程师内推岗位可以推荐的呢,个人在重新看机会,简历:个人简历
部署组件
该 Kubernetes 部署过程中,对于部署环节,涉及多个组件,主要有 kubeadm 、kubelet 、kubectl。
kubeadm介绍
Kubeadm 为构建 Kubernetes 提供了便捷、高效的"最佳实践" ,该工具提供了初始化完整 Kubernetes 过程所需的组件,其主要命令及功能有:
- kubeadm init:用于搭建 Kubernetes 控制平面节点;
- kubeadm join:用于搭建 Kubernetes 工作节点并将其加入到集群中;
- kubeadm upgrade:用于升级 Kubernetes 集群到新版本;
- kubeadm token:用于管理 kubeadm join 使用的 token;
- kubeadm reset:用于恢复(重置)通过 kubeadm init 或者 kubeadm join 命令对节点进行的任何变更;
- kubeadm certs:用于管理 Kubernetes 证书;
- kubeadm kubeconfig:用于管理 kubeconfig 文件;
- kubeadm version:用于显示(查询)kubeadm 的版本信息;
- kubeadm alpha:用于预览当前从社区收集到的反馈中的 kubeadm 特性。
更多参考:Kubeadm介绍
kubelet介绍
kubelet 是 Kubernetes 集群中用于操作 Docker 、containerd 等容器运行时的核心组件,需要在每个节点运行。通常该操作是基于 CRI 实现,kubelet 和 CRI 交互,以便于实现对 Kubernetes 的管控。
kubelet 主要用于配置容器网络、管理容器数据卷等容器全生命周期,对于 kubelet 而言,其主要的功能核心有:
- Pod 更新事件;
- Pod 生命周期管理;
- 上报 Node 节点信息。
更多参考:kubelet介绍
kubectl介绍
kubectl 控制 Kubernetes 集群管理器,是作为 Kubernetes 的命令行工具,用于与 apiserver 进行通信,使用 kubectl 工具在 Kubernetes 上部署和管理应用程序。
使用 kubectl,可以检查群集资源的创建、删除和更新组件。
同时集成了大量子命令,可更便捷的管理 Kubernetes 集群,主要命令如下:
- Kubetcl -h:显示子命令;
- kubectl option:查看全局选项;
- kubectl <command> --help:查看子命令帮助信息;
- kubelet command PARAMS -o=<format>:设置输出格式,如json、yaml等;
- Kubetcl explain RESOURCE:查看资源的定义。
更多参考:kubectl介绍
方案概述
方案介绍
本方案基于 kubeadm 部署工具实现完整生产环境可用的 Kubernetes 高可用集群,同时提供相关 Kubernetes 周边组件。
其主要信息如下:
- 版本:Kubernetes 1.32.2 版本;
- kubeadm:采用 kubeadm 部署Kubernetes;
- OS:CentOS Stream release 10;
- etcd:采用融合方式;
- HAProxy:以系统systemd形式运行,提供反向代理至3个master 6443端口;
- KeepAlived:用于实现 apiserver 的高可用;
- 其他主要部署组件包括:
- Metrics:度量组件,用于提供相关监控指标;
- Dashboard:Kubernetes 集群的前端图形界面;
- Helm:Kubernetes Helm 包管理器工具,用于后续使用 helm 整合包快速部署应用;
- Ingress:Kubernetes 服务暴露应用,用于提供7层的负载均衡,类似 Nginx,可建立外部和内部的多个映射规则;
- containerd:Kubernetes底层容器时;
- Longhorn:Kubernetes 动态存储组件,用于提供 Kubernetes 的持久存储。
提示:本方案部署所使用脚本均由本人提供,可能不定期更新。
部署规划
节点规划
| 节点主机名 | IP | 类型 | 运行服务 |
|---|---|---|---|
| master01 | 172.24.8.171 | Kubernetes master节点 | kubeadm、kubelet、kubectl、KeepAlived、 containerd、etcd、kube-apiserver、kube-scheduler、 kube-controller-manager、calico、WebUI、metrics、ingress、Longhorn ui节点 |
| master02 | 172.24.8.172 | Kubernetes master节点 | kubeadm、kubelet、kubectl、KeepAlived、 containerd、etcd、kube-apiserver、kube-scheduler、 kube-controller-manager、calico、WebUI、metrics、ingress、Longhorn ui节点 |
| master03 | 172.24.8.173 | Kubernetes master节点 | kubeadm、kubelet、kubectl、KeepAlived、 containerd、etcd、kube-apiserver、kube-scheduler、 kube-controller-manager、calico、WebUI、metrics、ingress、Longhorn ui节点 |
| worker01 | 172.24.8.174 | Kubernetes worker节点 | kubelet、containerd、calico、Longhorn存储节点 |
| worker02 | 172.24.8.175 | Kubernetes worker节点 | kubelet、containerd、calico、Longhorn存储节点 |
| worker03 | 172.24.8.176 | Kubernetes worker节点 | kubelet、containerd、calico、Longhorn存储节点 |
| worker04 | 172.24.8.177 | Kubernetes worker节点 | kubelet、containerd、calico、Longhorn存储节点 |
Kubernetes集群高可用主要指的是控制平面的高可用,多个Master节点组件(通常为奇数)和Etcd组件的高可用,worker节点通过前端负载均衡VIP( 172.24.8.170 )连接到Master。

Kubernetes高可用架构中etcd与Master节点组件混合部署方式特点:
- 所需服务器节点资源少,具备超融合架构特点
- 部署简单,利于管理
- 容易进行横向扩展
- etcd复用Kubernetes的高可用
- 存在一定风险,如一台master主机挂了,master和etcd都少了一个节点,集群冗余度受到一定影响
提示:本实验使用Keepalived+HAProxy架构实现Kubernetes的高可用。
主机名配置
需要对所有节点主机名进行相应配置。
shell
[root@localhost ~]# hostnamectl set-hostname master01 #其他节点依次修改提示:如上需要在所有节点修改对应的主机名。
生产环境通常建议在内网部署dns服务器,使用dns服务器进行解析,本指南采用本地hosts文件名进行解析。
如下hosts文件修改仅需在master01执行,后续使用批量分发至其他所有节点。
shell
[root@master01 ~]# cat >> /etc/hosts << EOF
172.24.8.171 master01
172.24.8.172 master02
172.24.8.173 master03
172.24.8.174 worker01
172.24.8.175 worker02
172.24.8.176 worker03
EOF提示:如上仅需在master01节点上操作。
变量准备
为实现自动化部署,自动化分发相关文件,提前定义相关主机名、IP组、变量等。
shell
[root@master01 ~]# wget http://down.linuxsb.com/mydeploy/k8s/v1.32.2/environment.sh
[root@master01 ~]# vi environment.sh #确认相关主机名和IP
#!/bin/bash
#***************************************************************#
# ScriptName: environment.sh
# Author: xhy
# Create Date: 2025-02-22 01:44
# Modify Author: xhy
# Modify Date: 2025-02-22 01:44
# Version: v1
#***************************************************************#
# 集群 MASTER 机器 IP 数组
export MASTER_IPS=(172.24.8.171 172.24.8.172 172.24.8.173)
# 集群 MASTER IP 对应的主机名数组
export MASTER_NAMES=(master01 master02 master03)
# 集群 NODE 机器 IP 数组
export NODE_IPS=(172.24.8.174 172.24.8.175 172.24.8.176)
# 集群 NODE IP 对应的主机名数组
export NODE_NAMES=(worker01 worker02 worker03)
# 集群所有机器 IP 数组
export ALL_IPS=(172.24.8.171 172.24.8.172 172.24.8.173 172.24.8.174 172.24.8.175 172.24.8.176)
# 集群所有IP 对应的主机名数组
export ALL_NAMES=(master01 master02 master03 worker01 worker02 worker03)提示:如上仅需在master01节点上操作。
互信配置
为了方便远程分发文件和执行命令,本方案配置master01节点到其它节点的 ssh信任关系,即免秘钥管理所有其他节点。
shell
[root@master01 ~]# source environment.sh #载入变量
[root@master01 ~]# ssh-keygen -f ~/.ssh/id_rsa -N ''
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh-copy-id -i ~/.ssh/id_rsa.pub root@${all_ip}
done
[root@master01 ~]# for all_name in ${ALL_NAMES[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_name}...\033[0m"
ssh-copy-id -i ~/.ssh/id_rsa.pub root@${all_name}
done提示:如上仅需在master01节点上操作。
环境初始化
kubeadm本身仅用于部署Kubernetes集群,在正式使用kubeadm部署Kubernetes集群之前需要对操作系统环境进行准备,即环境初始化准备。
环境的初始化准备本方案使用脚本自动完成。
使用如下脚本对基础环境进行初始化,主要功能包括:
- 安装containerd,Kubernetes平台底层的容器组件
- 关闭SELinux及防火墙
- 优化相关内核参数,针对生产环境Kubernetes集群的基础系统调优配置
- 关闭swap
- 设置相关模块,主要为转发模块
- 配置相关基础软件,部署Kubernetes集群所需要的基础依赖包
- 创建container所使用的独立目录
shell
[root@master01 ~]# wget http://down.linuxsb.com/mydeploy/k8s/v1.32.2/k8sconinit.sh
[root@master01 ~]# vim k8sconinit.sh
#!/bin/bash
#***************************************************************#
# ScriptName: k8sconinit.sh
# Author: xhy
# Create Date: 2025-02-22 18:12
# Modify Author: xhy
# Modify Date: 2025-02-23 00:48
# Version: v1
#***************************************************************#
# Initialize the machine. This needs to be executed on every machine.
rm -f /var/lib/rpm/__db.00*
rpm -vv --rebuilddb
#yum clean all
#yum makecache
sleep 3s
# Install containerd
CONVERSION=1.7.25
yum -y install yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sudo sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
sleep 3s
yum -y install containerd.io-${CONVERSION}
mkdir -p /etc/containerd/certs.d/docker.io
mkdir -p /data/containerd
cat > /etc/containerd/config.toml <<EOF
disabled_plugins = ["io.containerd.internal.v1.restart"]
root = "/data/containerd"
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
# sandbox_image = "registry.k8s.io/pause:3.10"
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.10"
[plugins."io.containerd.grpc.v1.cri".containerd]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
[plugins."io.containerd.runtime.v1.linux"]
shim_debug = true
EOF
cat > /etc/containerd/certs.d/docker.io/hosts.toml <<EOF
server = "https://registry-1.docker.io"
[host."https://docker.1ms.run"]
capabilities = ["pull", "resolve", "push"]
[host."https://dbzucv6w.mirror.aliyuncs.com"]
capabilities = ["pull", "resolve", "push"]
[host."https://docker.xuanyuan.me"]
capabilities = ["pull", "resolve", "push"]
EOF
# config crictl & containerd
cat > /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
systemctl restart containerd
systemctl enable containerd --now
# Disable the SELinux.
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
# Turn off and disable the firewalld.
systemctl stop firewalld
systemctl disable firewalld
# Modify related kernel parameters & Disable the swap.
cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.tcp_tw_recycle = 0
vm.swappiness = 0
vm.overcommit_memory = 1
vm.panic_on_oom = 0
net.ipv6.conf.all.disable_ipv6 = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf >&/dev/null
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
modprobe br_netfilter
modprobe overlay
# Add ipvs modules
cat > /etc/modules-load.d/ipvs.conf <<EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
br_netfilter
overlay
EOF
sysctl --system
# Install rpm
yum install -y conntrack ipvsadm ipset jq iptables curl sysstat libseccomp wget iproute-tc
# Update kernel
# rpm --import http://down.linuxsb.com/RPM-GPG-KEY-elrepo.org
# rpm -Uvh http://down.linuxsb.com/elrepo-release-7.el7.elrepo.noarch.rpm
# mv -b /etc/yum.repos.d/elrepo.repo /etc/yum.repos.d/backup
# wget -c http://down.linuxsb.com/myoptions/elrepo7.repo -O /etc/yum.repos.d/elrepo.repo
# yum --disablerepo="*" --enablerepo="elrepo-kernel" install -y kernel-ml
# sed -i 's/^GRUB_DEFAULT=.*/GRUB_DEFAULT=0/' /etc/default/grub
# grub2-mkconfig -o /boot/grub2/grub.cfg
# yum -y --exclude=docker* update
# Reboot the machine.
# nohup bash -c 'sleep 40; shutdown -r now' >/dev/null 2>&1 </dev/null &提示:containerd 镜像加速配置更多可参考:
containerd配置镜像加速器
containerd官方加速配置
提示:如上仅需在master01节点上操作,建议初始化完后进行重启。
- 对于某些特性,可能需要升级内核,内核升级操作见018.Linux升级内核。
- 4.19版及以上内核nf_conntrack_ipv4已经改为nf_conntrack。
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# chmod +x *.sh
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
sleep 2
scp -rp /etc/hosts root@${all_ip}:/etc/hosts
scp -rp k8sconinit.sh root@${all_ip}:/root/
ssh root@${all_ip} "bash /root/k8sconinit.sh"
done提示:如上仅需在master01节点上操作。
Cgroup v2开启
建议开启cgroup v2特性,同时确认cpuset在内核中存在,部分高版本可能此内核需要手动打开,更多cgroup v2知识参考:
升级systemd并启用cgroup v2
容器新体验 - Rootless Container + cgroup V2
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh root@${all_ip} "grep cgroup /proc/filesystems"
ssh root@${all_ip} "sed -i 's/GRUB_CMDLINE_LINUX=\"/GRUB_CMDLINE_LINUX=\"systemd.unified_cgroup_hierarchy=1 /g' /etc/default/grub"
ssh root@${all_ip} "grub2-mkconfig -o /boot/grub2/grub.cfg"
done提示:如上仅需在master01节点上操作。然后等待所有节点重新启动,并完成 cgroup v2 的启用。
验证预配置
验证所有预配置,并建议在全部节点重启一次后进行检查。
重启所有节点:
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
sleep 1
ssh root@${all_ip} "nohup bash -c 'sleep 10; shutdown -r now' >/dev/null 2>&1 </dev/null &"
done重启后如下方式进行验证。
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
sleep 2
ssh root@${all_ip} "getenforce"
ssh root@${all_ip} "systemctl status firewalld containerd | grep -E 'service|Active'"
ssh root@${all_ip} "lsmod | grep -E 'ip|nf_conn*'"
ssh root@${all_ip} "cat /proc/cgroups | grep cpuset"
ssh root@${all_ip} "mount | grep cgroup"
ssh root@${all_ip} "stat -fc %T /sys/fs/cgroup/"
done提示:如上仅需在master01节点上操作。
部署高可用组件
HAProxy安装
HAProxy是可提供高可用性、负载均衡以及基于TCP(从而可以反向代理kubeapiserver等应用)和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种高可用解决方案。
shell
[root@master01 ~]# HAVERSION=3.1.3
[root@master01 ~]# LHAVERSION=$(echo ${HAVERSION} | cut -d. -f1,2)
[root@master01 ~]# wget https://mirrors.huaweicloud.com/haproxy/${LHAVERSION}/src/haproxy-${HAVERSION}.tar.gz
[root@master01 ~]# for master_ip in ${MASTER_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
sleep 2
ssh root@${master_ip} "yum -y install binutils gcc gcc-c++ make libnl3 libnl3-devel libnfnetlink openssl-devel wget openssh-clients systemd-devel zlib-devel pcre2 --skip-broken"
scp -rp haproxy-${HAVERSION}.tar.gz root@${master_ip}:/root/
ssh root@${master_ip} "tar -zxvf haproxy-${HAVERSION}.tar.gz"
ssh root@${master_ip} "cd haproxy-${HAVERSION}/ && make USE_OPENSSL=1 TARGET=linux-glibc USE_PCRE2=1 USE_ZLIB=1 PREFIX=/usr/local/haprpxy && make install PREFIX=/usr/local/haproxy"
ssh root@${master_ip} "cp /usr/local/haproxy/sbin/haproxy /usr/sbin/"
ssh root@${master_ip} "useradd -r haproxy && usermod -G haproxy haproxy"
ssh root@${master_ip} "mkdir -p /etc/haproxy && mkdir -p /etc/haproxy/conf.d && cp -r /root/haproxy-${HAVERSION}/examples/errorfiles/ /usr/local/haproxy/"
done提示:如上仅需在master01节点上操作,,在CentOS 10 Stream上需要明确指定 USE_PCRE2 ,使用 pcre2 和 pcre2-devel 相关库文件。
提示:Haproxy官方参考: https://docs.haproxy.org/ 。
KeepAlived安装
KeepAlived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题。
本方案3台master节点均部署并运行Keepalived,一台为主服务器(MASTER),另外两台为备份服务器(BACKUP)。
Master集群外表现为一个VIP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
shell
[root@master01 ~]# KPVERSION=2.3.2
[root@master01 ~]# LKPVERSION=$(echo ${HAVERSION} | cut -d. -f1,2)
[root@master01 ~]# wget https://www.keepalived.org/software/keepalived-${KPVERSION}.tar.gz
[root@master01 ~]# for master_ip in ${MASTER_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
sleep 2
ssh root@${master_ip} "yum -y install curl gcc gcc-c++ make libnl3 libnl3-devel libnfnetlink openssl-devel"
scp -rp keepalived-${KPVERSION}.tar.gz root@${master_ip}:/root/
ssh root@${master_ip} "tar -zxvf keepalived-${KPVERSION}.tar.gz"
ssh root@${master_ip} "cd keepalived-${KPVERSION}/ && ./configure --sysconf=/etc --prefix=/usr/local/keepalived && make && make install"
ssh root@${master_ip} "systemctl enable keepalived"
done提示:如上仅需在master01节点上操作。
若出现如下报错:undefined reference to `OPENSSL_init_ssl',可带上openssl lib路径:
LDFLAGS="$LDFAGS -L /usr/local/openssl/lib64/" ./configure --sysconf=/etc --prefix=/usr/local/keepalived
提示:KeepAlive官方参考: https://www.keepalived.org/manpage.html 。
创建配置文件
创建集群部署所需的相关组件配置,采用脚本自动化创建相关配置文件。
shell
[root@master01 ~]# wget http://down.linuxsb.com/mydeploy/k8s/v1.32.2/k8sconfig.sh #拉取自动部署脚本
[root@master01 ~]# vim k8sconfig.sh
#!/bin/bash
#***************************************************************#
# ScriptName: k8sconfig.sh
# Author: xhy
# Create Date: 2025-02-23 00:27
# Modify Author: xhy
# Modify Date: 2025-02-23 00:27
# Version: v1
#***************************************************************#
#######################################
# set variables below to create the config files, all files will create at ./kubeadm directory
#######################################
echo -e "\n\n\033[33m[INFO] Define correlation variables ...\033[0m"
export K8SVERSION=v1.32.2
# master keepalived virtual ip address
export K8SHA_VIP=172.24.8.170
# master01 ip address
export K8SHA_IP1=172.24.8.171
# master02 ip address
export K8SHA_IP2=172.24.8.172
# master03 ip address
export K8SHA_IP3=172.24.8.173
# master01 hostname
export K8SHA_HOST1=master01
# master02 hostname
export K8SHA_HOST2=master02
# master03 hostname
export K8SHA_HOST3=master03
# master01 network interface name
export K8SHA_NETINF1=eth0
# master02 network interface name
export K8SHA_NETINF2=eth0
# master03 network interface name
export K8SHA_NETINF3=eth0
# keepalived auth_pass config
export K8SHA_KEEPALIVED_AUTH=ilovek8s
# kubernetes CIDR pod subnet
export K8SHA_PODCIDR=10.10.0.0/16
# kubernetes CIDR svc subnet
export K8SHA_SVCCIDR=10.20.0.0/16
# kubernetes CIDR pod mtu
export K8SHA_PODMTU=1450
##############################
# please do not modify anything below
##############################
echo -e "\n\n\033[33m[INFO] Create the necessary directory ...\033[0m"
sleep 1
mkdir -p kubeadm/${K8SHA_HOST1}/{keepalived,haproxy}
mkdir -p kubeadm/${K8SHA_HOST2}/{keepalived,haproxy}
mkdir -p kubeadm/${K8SHA_HOST3}/{keepalived,haproxy}
mkdir -p kubeadm/keepalived
mkdir -p kubeadm/haproxy
echo -e "\n\n\033[32m[SUCC] Create directory files success ...\033[0m"
sleep 1
# wget all files
echo -e "\n\n\033[33m[INFO] Download the main configuration file ...\033[0m"
sleep 1
wget -c -P kubeadm/keepalived/ http://down.linuxsb.com/mydeploy/k8s/common/k8s-keepalived.conf.tpl
wget -c -P kubeadm/keepalived/ http://down.linuxsb.com/mydeploy/k8s/common/check_apiserver.sh
wget -c -P kubeadm/haproxy/ http://down.linuxsb.com/mydeploy/k8s/common/k8s-haproxy.cfg.tpl
wget -c -P kubeadm/haproxy/ http://down.linuxsb.com/mydeploy/k8s/common/k8s-haproxy.service
wget -c -P kubeadm/ http://down.linuxsb.com/mydeploy/k8s/${K8SVERSION}/k8simage.sh
wget -c -P kubeadm/ http://down.linuxsb.com/mydeploy/k8s/${K8SVERSION}/kubeadm-config.yaml.tpl
wget -c -P kubeadm/calico/ http://down.linuxsb.com/mydeploy/k8s/calico/v3.29.2/calico.yaml.tpl
echo -e "\n\n\033[32m[SUCC] Download configuration file successful ...\033[0m"
sleep 1
# create all kubeadm-config.yaml files
echo -e "\n\n\033[33m[INFO] Configure kubeadm file ...\033[0m"
sleep 1
sed \
-e "s/K8SHA_HOST1/${K8SHA_HOST1}/g" \
-e "s/K8SHA_HOST2/${K8SHA_HOST2}/g" \
-e "s/K8SHA_HOST3/${K8SHA_HOST3}/g" \
-e "s/K8SHA_IP1/${K8SHA_IP1}/g" \
-e "s/K8SHA_IP2/${K8SHA_IP2}/g" \
-e "s/K8SHA_IP3/${K8SHA_IP3}/g" \
-e "s/K8SHA_VIP/${K8SHA_VIP}/g" \
-e "s!K8SHA_PODCIDR!${K8SHA_PODCIDR}!g" \
-e "s!K8SHA_SVCCIDR!${K8SHA_SVCCIDR}!g" \
kubeadm/kubeadm-config.yaml.tpl > kubeadm/kubeadm-config.yaml
echo -e "\n\n\033[32m[SUCC] Configure kubeadm file successful ...\033[0m"
sleep 1
# create all keepalived files
echo -e "\n\n\033[33m[INFO] Configure keepalived file ...\033[0m"
sleep 1
chmod u+x kubeadm/keepalived/check_apiserver.sh
cp kubeadm/keepalived/check_apiserver.sh kubeadm/${K8SHA_HOST1}/keepalived
cp kubeadm/keepalived/check_apiserver.sh kubeadm/${K8SHA_HOST2}/keepalived
cp kubeadm/keepalived/check_apiserver.sh kubeadm/${K8SHA_HOST3}/keepalived
sed \
-e "s/K8SHA_KA_STATE/BACKUP/g" \
-e "s/K8SHA_KA_INTF/${K8SHA_NETINF1}/g" \
-e "s/K8SHA_IPLOCAL/${K8SHA_IP1}/g" \
-e "s/K8SHA_KA_PRIO/102/g" \
-e "s/K8SHA_VIP/${K8SHA_VIP}/g" \
-e "s/K8SHA_KA_AUTH/${K8SHA_KEEPALIVED_AUTH}/g" \
kubeadm/keepalived/k8s-keepalived.conf.tpl > kubeadm/${K8SHA_HOST1}/keepalived/keepalived.conf
sed \
-e "s/K8SHA_KA_STATE/BACKUP/g" \
-e "s/K8SHA_KA_INTF/${K8SHA_NETINF2}/g" \
-e "s/K8SHA_IPLOCAL/${K8SHA_IP2}/g" \
-e "s/K8SHA_KA_PRIO/101/g" \
-e "s/K8SHA_VIP/${K8SHA_VIP}/g" \
-e "s/K8SHA_KA_AUTH/${K8SHA_KEEPALIVED_AUTH}/g" \
kubeadm/keepalived/k8s-keepalived.conf.tpl > kubeadm/${K8SHA_HOST2}/keepalived/keepalived.conf
sed \
-e "s/K8SHA_KA_STATE/BACKUP/g" \
-e "s/K8SHA_KA_INTF/${K8SHA_NETINF3}/g" \
-e "s/K8SHA_IPLOCAL/${K8SHA_IP3}/g" \
-e "s/K8SHA_KA_PRIO/100/g" \
-e "s/K8SHA_VIP/${K8SHA_VIP}/g" \
-e "s/K8SHA_KA_AUTH/${K8SHA_KEEPALIVED_AUTH}/g" \
kubeadm/keepalived/k8s-keepalived.conf.tpl > kubeadm/${K8SHA_HOST3}/keepalived/keepalived.conf
echo -e "\n\n\033[32m[SUCC] Configure ${K8SHA_HOST1} & ${K8SHA_HOST2} & ${K8SHA_HOST3} keepalived file successful ...\033[0m"
sleep 1
# create all haproxy files
echo -e "\n\n\033[33m[INFO] Configure haproxy file ...\033[0m"
sleep 1
sed \
-e "s/K8SHA_IP1/$K8SHA_IP1/g" \
-e "s/K8SHA_IP2/$K8SHA_IP2/g" \
-e "s/K8SHA_IP3/$K8SHA_IP3/g" \
-e "s/K8SHA_HOST1/${K8SHA_HOST1}/g" \
-e "s/K8SHA_HOST2/${K8SHA_HOST2}/g" \
-e "s/K8SHA_HOST3/${K8SHA_HOST3}/g" \
kubeadm/haproxy/k8s-haproxy.cfg.tpl > kubeadm/haproxy/haproxy.conf
echo -e "\n\n\033[32m[SUCC] Configure ${K8SHA_HOST1} & ${K8SHA_HOST2} & ${K8SHA_HOST3} haproxy file successful ...\033[0m"
sleep 1
# create calico yaml file
echo -e "\n\n\033[33m[INFO] Configure calico file ...\033[0m"
sleep 1
sed \
-e "s!K8SHA_PODCIDR!${K8SHA_PODCIDR}!g" \
-e "s!K8SHA_PODMTU!${K8SHA_PODMTU}!g" \
kubeadm/calico/calico.yaml.tpl > kubeadm/calico/calico.yaml
echo -e "\n\n\033[32m[SUCC] Configure calico file successful ...\033[0m"
sleep 1
# scp all file
echo -e "\n\n\033[33m[INFO] Copy the configuration file to ${K8SHA_HOST1} & ${K8SHA_HOST2} & ${K8SHA_HOST3} nodes ...\033[0m"
sleep 1
scp -rp kubeadm/haproxy/haproxy.conf root@${K8SHA_HOST1}:/etc/haproxy/haproxy.cfg
scp -rp kubeadm/haproxy/haproxy.conf root@${K8SHA_HOST2}:/etc/haproxy/haproxy.cfg
scp -rp kubeadm/haproxy/haproxy.conf root@${K8SHA_HOST3}:/etc/haproxy/haproxy.cfg
scp -rp kubeadm/haproxy/k8s-haproxy.service root@${K8SHA_HOST1}:/usr/lib/systemd/system/haproxy.service
scp -rp kubeadm/haproxy/k8s-haproxy.service root@${K8SHA_HOST2}:/usr/lib/systemd/system/haproxy.service
scp -rp kubeadm/haproxy/k8s-haproxy.service root@${K8SHA_HOST3}:/usr/lib/systemd/system/haproxy.service
scp -rp kubeadm/${K8SHA_HOST1}/keepalived/* root@${K8SHA_HOST1}:/etc/keepalived/
scp -rp kubeadm/${K8SHA_HOST2}/keepalived/* root@${K8SHA_HOST2}:/etc/keepalived/
scp -rp kubeadm/${K8SHA_HOST3}/keepalived/* root@${K8SHA_HOST3}:/etc/keepalived/
echo -e "\n\n\033[32m[SUCC] Copy the configuration file to ${K8SHA_HOST1} & ${K8SHA_HOST2} & ${K8SHA_HOST3} nodes successful ...\033[0m"
sleep 1
# chmod *.sh
chmod u+x kubeadm/*.sh[root@master01 ~]# bash k8sconfig.sh解释:如上操作仅需Master01上执行,执行k8sconfig.sh脚本后会生产如下配置文件清单:
启动服务
启动keepalive和HAProxy服务,从而构建master节点的高可用。
- 检查服务配置
确认所有Master节点相关keepalive配置文件和keepalive监测脚本文件。
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for master_ip in ${MASTER_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
ssh root@${master_ip} "cat /etc/keepalived/keepalived.conf"
ssh root@${master_ip} "cat /etc/keepalived/check_apiserver.sh"
done- 启动高可用服务
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for master_ip in ${MASTER_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
ssh root@${master_ip} "systemctl enable haproxy.service --now && systemctl restart haproxy.service"
ssh root@${master_ip} "systemctl enable keepalived.service --now && systemctl restart keepalived.service"
ssh root@${master_ip} "systemctl status keepalived.service | grep Active"
ssh root@${master_ip} "systemctl status haproxy.service | grep Active"
done
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
sleep 2
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh root@${all_ip} "ping -c1 172.24.8.170"
done提示:如上仅需Master01节点操作,从而实现所有节点自动启动服务。
集群部署
相关组件包
需要在每台机器上都安装以下的软件包:
- kubeadm: 用来初始化集群的指令;
- kubelet: 在集群中的每个节点上用来启动 pod 和 container 等;
- kubectl: 用来与集群通信的命令行工具。
kubeadm不能安装或管理 kubelet 或 kubectl ,因此在初始化集群之前必须完成kubelet和kubectl的安装,且能保证他们满足通过 kubeadm 安装的 Kubernetes控制层对版本的要求。
如果版本没有满足匹配要求,可能导致一些意外错误或问题。
具体相关组件安装见;附001.kubectl介绍及使用书
提示:Kubernetes 1.32.2 版本所有兼容相应组件的版本参考:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.32.md 。
正式安装
快速安装所有节点的kubeadm、kubelet、kubectl组件。
shell
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh root@${all_ip} "cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/repodata/repomd.xml.key
EOF"
ssh root@${all_ip} "yum install -y kubelet-1.32.2 kubectl-1.32.2 kubeadm-1.32.2 --disableexcludes=kubernetes"
ssh root@${all_ip} "systemctl enable kubelet"
done
[root@master01 ~]# yum search -y kubelet --showduplicates #查看相应版本 提示:如上仅需Master01节点操作,从而实现所有节点自动化安装,同时此时不需要启动kubelet,初始化的过程中会自动启动的,如果此时启动了会出现报错,忽略即可。
说明:同时安装了cri-tools, kubernetes-cni, socat三个依赖:
socat:kubelet的依赖;
cri-tools:即CRI(Container Runtime Interface)容器运行时接口的命令行工具。
集群初始化
预配置检查
使用 k8sconfig.sh 创建配置的时候会创建主要如下配置文件,集群初始化之前建议再次检查和确认集群配置文件。
- kubeadm-config.yaml:kubeadm初始化配置文件,位于kubeadm/目录,设置了Kubernetes版本、Pod IP段、SVC IP段、nodeport端口范围等,可参考 kubeadm 配置
- keepalived:keepalived配置文件,位于各个master节点的/etc/keepalived目录
- haproxy:haproxy的配置文件,位于各个master节点的/etc/haproxy/目录
- calico.yaml:calico网络组件部署文件,位于kubeadm/calico/目录
shell
[root@master01 ~]# cat kubeadm/kubeadm-config.yaml #检查集群初始化配置
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
etcd:
local:
dataDir: "/data/etcd"
networking:
serviceSubnet: "10.20.0.0/16" #设置svc网段
podSubnet: "10.10.0.0/16" #设置Pod网段
dnsDomain: "cluster.local"
kubernetesVersion: "v1.32.2" #设置安装版本
imageRepository: "registry.aliyuncs.com/google_containers" #设置国内镜像站点
controlPlaneEndpoint: "172.24.8.1700:16443" #设置相关API VIP地址
apiServer:
certSANs:
- localhost
- 127.0.0.1
- K8SHA_HOST1
- K8SHA_HOST2
- K8SHA_HOST3
- K8SHA_IP1
- K8SHA_IP2
- K8SHA_IP3
- K8SHA_VIP
extraArgs:
service-node-port-range: "80-65535"
certificatesDir: "/etc/kubernetes/pki"
imageRepository: "registry.k8s.io"
#clusterName: "example-cluster"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvsKubernetes默认的端口范围为30000-32767,为便于后期大量的应用,建议做端口扩展,如ingress的80、443端口,然后开放全部高端口号。
同时开放全端口范围后,使用的时候需要注意外部应用端口和Kubernetes使用的nodeport端口冲突的情况。
提示:更多config文件参考:kubeadm 配置 (v1beta4)
默认kubeadm配置可使用kubeadm config print init-defaults > config.yaml生成。
Master01上初始化
Master01节点上执行初始化,即完成单节点的Kubernetes,其他节点采用添加的方式部署。
提示:kubeadm init过程会执行系统预检查,预检查通过则继续init,也可以提前执行如下命令进行预检查操作: kubeadm init phase preflight
shell
[root@master01 ~]# kubeadm init --config=kubeadm/kubeadm-config.yaml --upload-certs #保留如下命令用于后续节点添加
[init] Using Kubernetes version: v1.32.2
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
......
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes running the following command on each as root:
kubeadm join 172.24.8.170:16443 --token nogv7g.jwl05pbvzb6i3awt \
--discovery-token-ca-cert-hash sha256:3024fe34a1d8426dfab2599c82d34add24679e92608044db4832b334db087a4f \
--control-plane --certificate-key bc100a04df790ac35fc4d027a45588041e56b5d4d4f0f49f83e05076b5564ee1
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.24.8.170:16443 --token nogv7g.jwl05pbvzb6i3awt \
--discovery-token-ca-cert-hash sha256:3024fe34a1d8426dfab2599c82d34add24679e92608044db4832b334db087a4f 注意:如上token具有默认24小时的有效期,token和hash值可通过如下方式获取:
kubeadm token list
如果 Token 过期以后,可以输入以下命令,生成新的 Token:
shell
kubeadm token create
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'附加:初始化过程大致步骤如下:
- certs:生成相关的各种证书
- control-plane:创建Kubernetes控制节点的静态Pod
- etcd:创建ETCD的静态Pod
- kubelet-start:生成kubelet的配置文件"/var/lib/kubelet/config.yaml"
- kubeconfig:生成相关的kubeconfig文件
- bootstraptoken:生成token记录下来,后续使用kubeadm join往集群中添加节点时会用到
- addons:附带的相关插件
提示:初始化仅需要在master01上执行,若初始化异常可通过kubeadm reset -f kubeadm/kubeadm-config.yaml && rm -rf $HOME/.kube /etc/cni/ /etc/kubernetes/ && ipvsadm --clear重置。
添加Master节点
采用 kubeadm join 将其他Master节点添加至集群。
shell
[root@master01 ~]# JOINS_IP=(172.24.8.172 172.24.8.173)
[root@master01 ~]# for join_ip in "${JOINS_IP[@]}"; do
echo -e "\n\033[33m[INFO] Joining ${join_ip}...\033[0m"
ssh root@${join_ip} "kubeadm join 172.24.8.170:16443 --token nogv7g.jwl05pbvzb6i3awt \
--discovery-token-ca-cert-hash sha256:3024fe34a1d8426dfab2599c82d34add24679e92608044db4832b334db087a4f \
--control-plane --certificate-key bc100a04df790ac35fc4d027a45588041e56b5d4d4f0f49f83e05076b5564ee1"
done提示:如上仅需Master01节点操作,通过循环将master02和master03添加至当前集群的controlplane。
添加kubectl环境
给所有master节点创建相关Kubernetes集群配置文件保存目录,以及相关登录凭证,kubectl命令补全等。
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for master_ip in "${MASTER_IPS[@]}"; do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
ssh -T root@${master_ip} << 'EOF'
mkdir -p $HOME/.kube
cp -f /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
cat << EOB > /etc/profile.d/custom_kubectl.sh
export KUBECONFIG=\$HOME/.kube/config
source <(kubectl completion bash)
EOB
chmod 644 /etc/profile.d/custom_kubectl.sh
EOF
done
[root@master01 ~]# source /etc/profile安装NIC插件
NIC插件介绍
- Calico 是一个安全的 L3 网络和网络策略提供者。
- Canal 结合 Flannel 和 Calico, 提供网络和网络策略。
- Cilium 是一个 L3 网络和网络策略插件, 能够透明的实施 HTTP/API/L7 策略。 同时支持路由(routing)和叠加/封装( overlay/encapsulation)模式。
- Contiv 为多种用例提供可配置网络(使用 BGP 的原生 L3,使用 vxlan 的 overlay,经典 L2 和 Cisco-SDN/ACI)和丰富的策略框架。Contiv 项目完全开源。安装工具同时提供基于和不基于 kubeadm 的安装选项。
- Flannel 是一个可以用于 Kubernetes 的 overlay 网络提供者。
+Romana 是一个 pod 网络的层 3 解决方案,并且支持 NetworkPolicy API。Kubeadm add-on 安装细节可以在这里找到。 - Weave Net 提供了在网络分组两端参与工作的网络和网络策略,并且不需要额外的数据库。
- CNI-Genie 使 Kubernetes 无缝连接到一种 CNI 插件,例如:Flannel、Calico、Canal、Romana 或者 Weave。
提示:本方案使用Calico插件。
部署calico
确认相关配置,如MTU,网卡接口,Pod的IP地址段。
calico原文件可参考官方:https://raw.githubusercontent.com/projectcalico/calico/v3.29.2/manifests/calico.yaml
shell
[root@master01 ~]# vim kubeadm/calico/calico.yaml #检查配置
......
data:
......
veth_mtu: "1450"
......
- name: CALICO_IPV4POOL_CIDR
value: "10.10.0.0/16" #配置Pod网段
......
[root@master01 ~]# kubectl apply -f kubeadm/calico/calico.yaml
[root@master01 ~]# kubectl get pods --all-namespaces -o wide #查看部署的所有Pod
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-kube-controllers-77969b7d87-wpngf 1/1 Running 0 26m 10.10.241.65 master01 <none> <none>
kube-system calico-node-4f8nd 1/1 Running 0 26m 172.24.8.172 master02 <none> <none>
kube-system calico-node-c85pd 1/1 Running 0 26m 172.24.8.171 master01 <none> <none>
kube-system calico-node-d2dkj 1/1 Running 0 26m 172.24.8.173 master03 <none> <none>
kube-system coredns-6766b7b6bb-qklcd 1/1 Running 0 112m 10.10.241.66 master01 <none> <none>
kube-system coredns-6766b7b6bb-s44fx 1/1 Running 0 112m 10.10.241.67 master01 <none> <none>
kube-system etcd-master01 1/1 Running 0 112m 172.24.8.171 master01 <none> <none>
kube-system etcd-master02 1/1 Running 0 42m 172.24.8.172 master02 <none> <none>
kube-system etcd-master03 1/1 Running 0 42m 172.24.8.173 master03 <none> <none>
kube-system kube-apiserver-master01 1/1 Running 0 112m 172.24.8.171 master01 <none> <none>
kube-system kube-apiserver-master02 1/1 Running 0 42m 172.24.8.172 master02 <none> <none>
kube-system kube-apiserver-master03 1/1 Running 0 42m 172.24.8.173 master03 <none> <none>
kube-system kube-controller-manager-master01 1/1 Running 0 112m 172.24.8.171 master01 <none> <none>
kube-system kube-controller-manager-master02 1/1 Running 0 42m 172.24.8.172 master02 <none> <none>
kube-system kube-controller-manager-master03 1/1 Running 0 42m 172.24.8.173 master03 <none> <none>
kube-system kube-proxy-k2nf4 1/1 Running 0 112m 172.24.8.171 master01 <none> <none>
kube-system kube-proxy-ktzmx 1/1 Running 0 42m 172.24.8.173 master03 <none> <none>
kube-system kube-proxy-tv2wv 1/1 Running 0 42m 172.24.8.172 master02 <none> <none>
kube-system kube-scheduler-master01 1/1 Running 0 112m 172.24.8.171 master01 <none> <none>
kube-system kube-scheduler-master02 1/1 Running 0 42m 172.24.8.172 master02 <none> <none>
kube-system kube-scheduler-master03 1/1 Running 0 42m 172.24.8.173 master03 <none> <none>
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane 112m v1.32.2
master02 Ready control-plane 43m v1.32.2
master03 Ready control-plane 43m v1.32.2提示:官方calico参考:https://docs.projectcalico.org/manifests/calico.yaml
添加Worker节点
添加Worker节点
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for node_ip in ${NODE_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${node_ip}...\033[0m"
ssh root@${node_ip} "kubeadm join 172.24.8.170:16443 --token nogv7g.jwl05pbvzb6i3awt \
--discovery-token-ca-cert-hash sha256:3024fe34a1d8426dfab2599c82d34add24679e92608044db4832b334db087a4f"
ssh root@${node_ip} "systemctl enable kubelet.service"
done提示:如上仅需Master01节点操作,从而实现所有Worker节点添加至集群,若添加异常可通过如下方式重置:
shell
[root@worker01 ~]# kubeadm reset
[root@worker01 ~]# ifconfig kube-ipvs0 down
[root@worker01 ~]# ip link delete kube-ipvs0
[root@worker01 ~]# ifconfig tunl0@NONE down
[root@worker01 ~]# ip link delete tunl0@NONE
[root@worker01 ~]# rm -rf /var/lib/cni/确认验证
shell
[root@master01 ~]# kubectl get nodes #节点状态
[root@master01 ~]# kubectl get serviceaccount #服务账户
[root@master01 ~]# kubectl cluster-info #集群信息
[root@master01 ~]# kubectl get pod -n kube-system -o wide #所有服务状态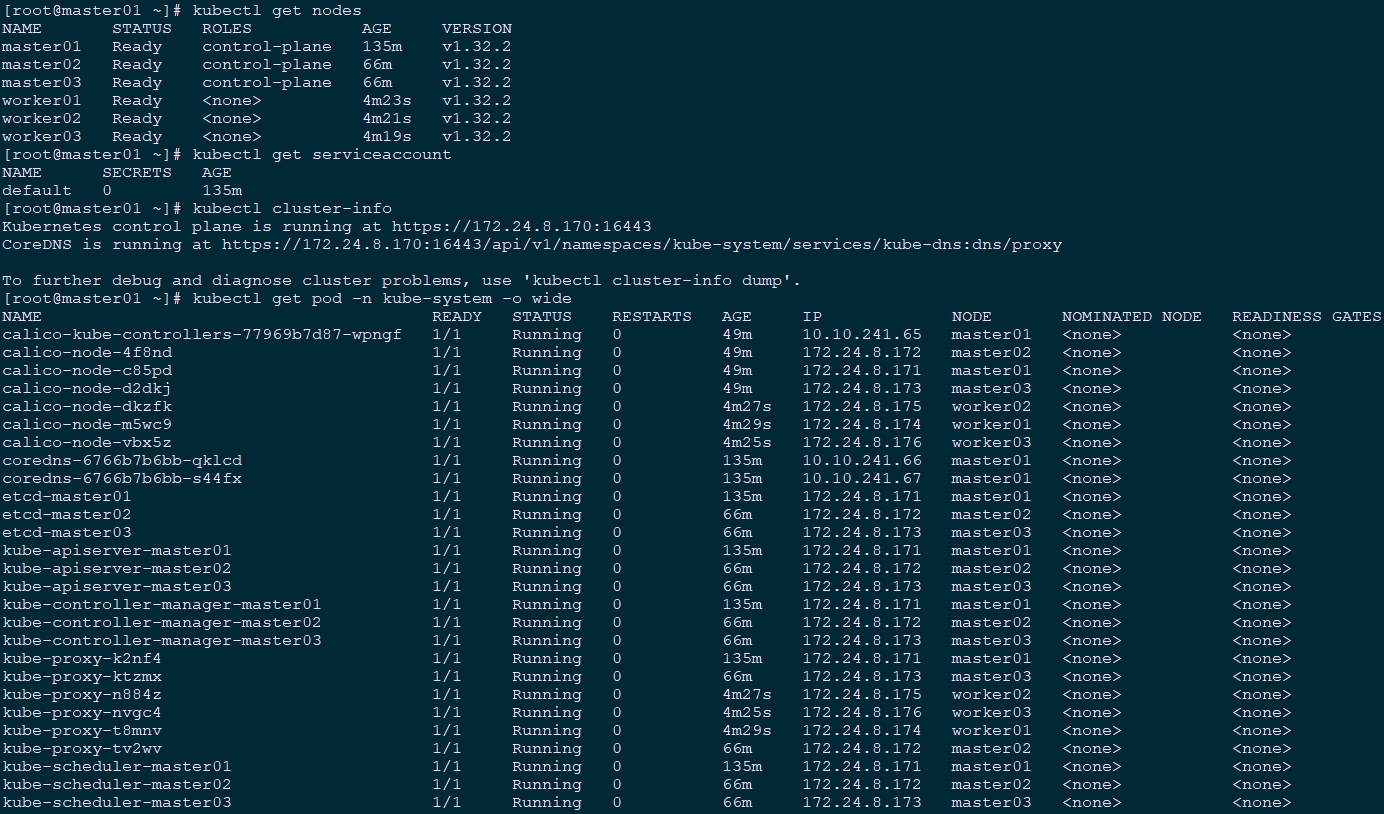
提示:更多Kubetcl使用参考:https://kubernetes.io/docs/reference/kubectl/kubectl/
https://kubernetes.io/docs/reference/kubectl/overview/
更多kubeadm使用参考:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
Metrics部署
Metrics介绍
在Kubernetes新的监控体系中,Metrics Server用于提供核心指标(Core Metrics),包括Node、Pod的CPU和内存使用指标,对其他自定义指标(Custom Metrics)的监控则由Prometheus等组件来完成。
Metrics Server是一个可扩展的、高效的容器资源度量,通常可用于Kubernetes内置的自动伸缩,即自动伸缩可依据metrics的度量指标。
Metrics Server从Kubelets收集资源指标,并通过Metrics API将它们暴露在Kubernetes apisserver中,供Pod水平或垂直自动伸缩使用。\
kubectl top也可以访问Metrics API,可查看相关对象资源使用情况。
提示:当前官方建议Metrics Server仅用于自动伸缩,不要使用它来当做对Kubernetes的监控解决方案,或者监控解决方案的上游来源,对于完整的Kubernetes监控方案,可直接从Kubelet的/metrics/resource endpoint收集指标。
Metrics Server建议场景
使用Metrics Server的场景:
基于CPU/内存的水平快速自动缩放;
自动调整/建议容器所需的资源。
Metrics Server不建议场景
不建议使用Metrics Server的场景:
- 非Kubernetes集群;
- 集群资源对象资源消耗的准确依据;
- 基于CPU/内存以外的其他资源的水平自动缩放。
对于整个集群的准备监控,可参考 Prometheus 。
Metrics特点
Metrics Server主要特点:
- 在大多数集群上可以以单Pod工作;
- 快速自动伸缩,且每15秒收集一次指标;
- 资源消耗极低,在集群中每个节点上仅需1分片CPU和2 MB内存;
- 可扩展支持最多5000个节点集群。
Metrics需求
Metrics Server对集群和网络配置有特定的需求依赖,这些需求依赖并不是所有集群默认开启的。
在使用Metrics Server之前,需要确保集群支持这些需求:
- kube-apiserver必须启用聚合层(aggregation layer);
- 节点必须启用Webhook身份验证和授权;
- Kubelet证书需要由集群证书颁发机构签名(或者通过向Metrics Server传递--kubelet-insecure-tls禁用证书验证);
- 容器运行时必须实现容器度量rpc(或有cAdvisor支持);
- 网络应支持以下通信:
- 控制平面到Metrics Server通信要求:控制平面节点需要到达Metrics Server的pod IP和端口10250(如果hostNetwork开启,则可以是自定义的node IP和对应的自定义端口,保持通信即可);
- Metrics Server到所有节点的Kubelete通信要求:Metrics Server需要到达node节点地址和Kubelet端口。地址和端口在Kubelet中配置,并作为Node对象的一部分发布。.status.address和.status.daemonEndpoints.kubeletEndpoint.port定义地址和端口(默认10250)。Metrics Server将根据kubelet-preferred-address-types命令行标志提供的列表选择第一个节点地址(默认InternalIP,ExternalIP,Hostname)。
开启聚合层
有关聚合层知识参考:https://blog.csdn.net/liukuan73/article/details/81352637
kubeadm方式部署默认已开启。
获取部署文件
根据实际生产环境,对Metrics Server的部署进行个性化修改,其他保持默认即可。
主要涉及:部署副本数为3,追加--kubelet-insecure-tls配置。
shell
[root@master01 ~]# mkdir metrics
[root@master01 ~]# cd metrics/
[root@master01 metrics]# wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
[root@master01 metrics]# vi components.yaml
......
apiVersion: apps/v1
kind: Deployment
......
spec:
replicas: 3 #根据集群规模调整副本数
......
spec:
hostNetwork: true #追加此行
containers:
- args:
- --cert-dir=/tmp
- --secure-port=10300 #修改端口
- --kubelet-insecure-tls #自签名证书场景必须追加此行
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname,InternalDNS,ExternalDNS #建议修改此args
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: registry.aliyuncs.com/google_containers/metrics-server:v0.7.2 #使用阿里云镜像
imagePullPolicy: IfNotPresent
......
ports:
- containerPort: 10300
......提示:默认的10250会被kubelet当做服务监听的端口,因此建议修改端口。\
kubelet各端口作用可参考: Kubelet 各个端口作用 10250
正式部署
shell
[root@master01 metrics]# kubectl apply -f components.yaml
[root@master01 metrics]# kubectl -n kube-system get pods -l k8s-app=metrics-server -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
metrics-server-7954dcb96-dhz7w 1/1 Running 0 26s 172.24.8.176 worker03 <none> <none>
metrics-server-7954dcb96-llgjr 1/1 Running 0 26s 172.24.8.174 worker01 <none> <none>
metrics-server-7954dcb96-ltr5p 1/1 Running 0 26s 172.24.8.175 worker02 <none> <none>查看资源监控
可使用kubectl top查看相关监控项。
shell
[root@master01 ~]# kubectl top nodes
[root@master01 ~]# kubectl top pods --all-namespaces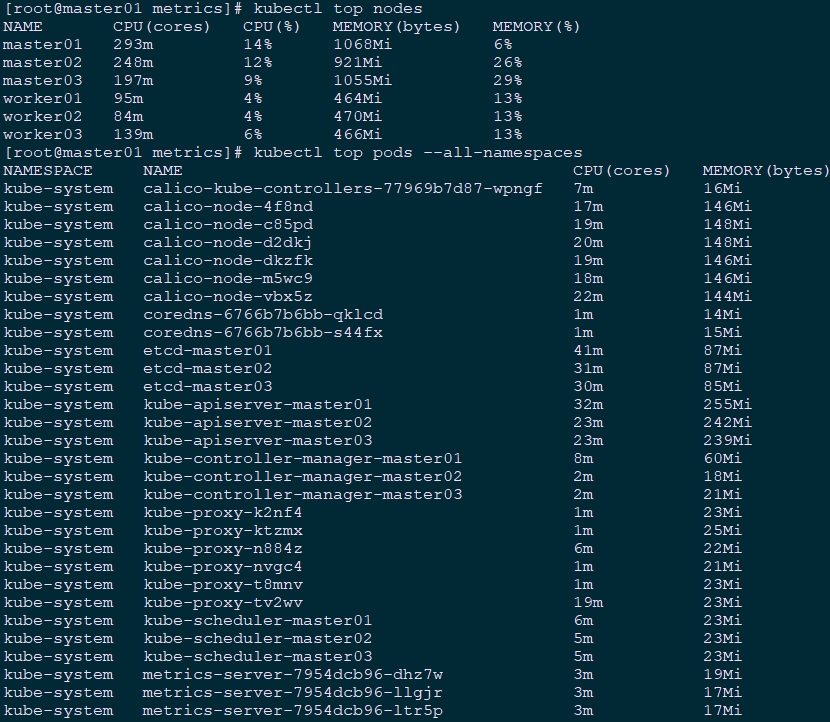
提示:Metrics Server提供的数据也可以供HPA控制器使用,以实现基于CPU使用率或内存使用值的Pod自动扩缩容功能。\
有关metrics更多部署参考:
https://kubernetes.io/docs/tasks/debug-application-cluster/resource-metrics-pipeline/
开启开启API Aggregation参考:
https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/apiserver-aggregation/
API Aggregation介绍参考:
https://kubernetes.io/docs/tasks/access-kubernetes-api/configure-aggregation-layer/
Helm部署
helm介绍
Helm 是 Kubernetes 的软件包管理工具。包管理器类似 Ubuntu 中使用的apt、Centos中使用的yum 或者Python中的 pip 一样,能快速查找、下载和安装软件包。通常每个包称为一个Chart,一个Chart是一个目录(一般情况下会将目录进行打包压缩,形成name-version.tgz格式的单一文件,方便传输和存储)。
Helm 由客户端组件 helm 和服务端组件 Tiller 组成, 能够将一组K8S资源打包统一管理, 是查找、共享和使用为Kubernetes构建的软件的最佳方式。
Helm优势
在 Kubernetes中部署一个可以使用的应用,需要涉及到很多的 Kubernetes 资源的共同协作。
如安装一个 WordPress 博客,用到了一些 Kubernetes 的一些资源对象。包括 Deployment 用于部署应用、Service 提供服务发现、Secret 配置 WordPress 的用户名和密码,可能还需要 pv 和 pvc 来提供持久化服务。并且 WordPress 数据是存储在mariadb里面的,所以需要 mariadb 启动就绪后才能启动 WordPress。这些 k8s 资源过于分散,不方便进行管理。
基于如上场景,在 k8s 中部署一个应用,通常面临以下几个问题:
如何统一管理、配置和更新这些分散的 k8s 的应用资源文件;
如何分发和复用一套应用模板;
如何将应用的一系列资源当做一个软件包管理。
对于应用发布者而言,可以通过 Helm 打包应用、管理应用依赖关系、管理应用版本并发布应用到软件仓库。
对于使用者而言,使用 Helm 后不用需要编写复杂的应用部署文件,可以以简单的方式在 Kubernetes 上查找、安装、升级、回滚、卸载应用程序。
前置准备
Helm 将使用 kubectl 在已配置的集群上部署 Kubernetes 资源,因此需要如下前置准备:
- 正在运行的 Kubernetes 集群;
- 预配置的 kubectl 客户端和 Kubernetes 集群正确交互。
二进制安装Helm
建议采用二进制安装helm。
shell
[root@master01 ~]# mkdir helm
[root@master01 ~]# cd helm/
[root@master01 helm]# HELMVERSION=v3.17.1
[root@master01 helm]# wget https://repo.huaweicloud.com/helm/${HELMVERSION}/helm-${HELMVERSION}-linux-amd64.tar.gz
[root@master01 helm]# tar -zxvf helm-${HELMVERSION}-linux-amd64.tar.gz
[root@master01 helm]# cp linux-amd64/helm /usr/local/bin/
[root@master01 helm]# helm version #查看安装版本
[root@master01 helm]# echo 'source <(helm completion bash)' >> /etc/profile.d/custom_helm.sh #helm自动补全
[root@master01 helm]# source /etc/profile提示:更多安装方式参考官方手册:https://helm.sh/docs/intro/install/ 。
Helm操作
查找chart
helm search:可以用于搜索两种不同类型的源。
helm search hub:搜索 Helm Hub,该源包含来自许多不同仓库的Helm chart。
helm search repo:搜索已添加到本地头helm客户端(带有helm repo add)的仓库,该搜索是通过本地数据完成的,不需要连接公网。
shell
[root@master01 ~]# helm search hub #可搜索全部可用chart
[root@master01 ~]# helm search hub wordpress添加repo
类似CentOS添加yum源,可以给helm仓库添加相关源。
shell
[root@master01 ~]# helm repo list #查看repo
[root@master01 ~]# helm repo add azure https://mirror.azure.cn/kubernetes/charts
[root@master01 ~]# helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
[root@master01 ~]# helm repo add bitnami https://charts.bitnami.com/bitnami
[root@master01 ~]# helm search repo azure
[root@master01 ~]# helm search repo aliyun
[root@master01 ~]# helm search repo bitnami #搜索repo中的chart
[root@master01 ~]# helm repo update #更新repo的chart提示:bitnami chart更多信息参考:Kubernetes Bitnami chart
提示:更多helm知识可参考: Kubernetes集群管理-Helm部署及使用 。
Nginx ingress部署
ingress介绍
Kubernetes中的应用通常以Service对外暴露,而Service的表现形式为IP:Port,即工作在TCP/IP层。
对于基于HTTP的服务来说,不同的URL地址经常对应到不同的后端服务(RS)或者虚拟服务器(Virtual Host),这些应用层的转发机制仅通过Kubernetes的Service机制是无法实现的。
从Kubernetes 1.1版本开始新增Ingress资源对象,用于将不同URL的访问请求转发到后端不同的Service,以实现HTTP层的业务路由机制。
Kubernetes使用了一个Ingress策略规则和一个具体的Ingress Controller,两者结合实现了一个完整的Ingress负载均衡器。
使用Ingress进行负载分发时,Ingress Controller基于Ingress策略规则将客户端请求直接转发到Service对应的后端Endpoint(Pod)上,从而跳过kube-proxy的转发功能,kube-proxy不再起作用。
简单的理解就是:ingress使用DaemonSet或Deployment在相应Node上监听80或443,然后配合相应规则,因为Nginx外面绑定了宿主机80端口(就像 NodePort),本身又在集群内,那么向后直接转发到相应ServiceIP即可实现相应需求。
ingress controller + ingress 策略规则 ----> services。
同时当Ingress Controller提供的是对外服务,则实际上实现的是边缘路由器的功能。
典型的HTTP层路由的架构:

设置标签
建议对于非业务相关的应用,构建集群所需的应用(如Ingress),部署在master节点,从而复用master节点的高可用。
采用标签,结合部署的yaml中的tolerations,实现ingress部署在master节点的配置。
shell
[root@master01 ~]# kubectl label nodes master0{1,2,3} ingress=enable获取资源
获取部署所需的yaml资源。
shell
[root@master01 ~]# mkdir ingress
[root@master01 ~]# cd ingress/
[root@master01 ingress]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.12.0/deploy/static/provider/baremetal/deploy.yaml提示:ingress官方参考:https://github.com/kubernetes/ingress-nginx
https://kubernetes.github.io/ingress-nginx/deploy/
修改配置
为方便后续管理和排障,对相关Nginx ingress挂载时区,以便使Pod时间正确,从而相关记录日志能具有时效性。
同时对ingress做了简单配置,如日志格式等。
shell
[root@master01 ingress]# vi deploy.yaml
......
---
apiVersion: v1
data:
allow-snippet-annotations: "true"
client-header-buffer-size: "512k" #客户端请求头的缓冲区大小
large-client-header-buffers: "4 512k" #设置用于读取大型客户端请求标头的最大值number和size缓冲区
client-body-buffer-size: "128k" #读取客户端请求body的缓冲区大小
proxy-buffer-size: "256k" #代理缓冲区大小
proxy-body-size: "50m" #代理body大小
server-name-hash-bucket-size: "128" #服务器名称哈希大小
map-hash-bucket-size: "128" #map哈希大小
ssl-ciphers: "ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA" #SSL加密套件
ssl-protocols: "TLSv1 TLSv1.1 TLSv1.2" #ssl 协议
log-format-upstream: '{"time": "$time_iso8601", "remote_addr": "$proxy_protocol_addr", "x-forward-for": "$proxy_add_x_forwarded_for", "request_id": "$req_id","remote_user": "$remote_user", "bytes_sent": $bytes_sent, "request_time": $request_time, "status": $status, "vhost": "$host", "request_proto": "$server_protocol", "path": "$uri", "request_query": "$args", "request_length": $request_length, "duration": $request_time,"method": "$request_method", "http_referrer": "$http_referer", "http_user_agent": "$http_user_agent" }' #日志格式
kind: ConfigMap
......
---
apiVersion: v1
kind: Service
metadata:
......
spec:
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- appProtocol: http
name: http
port: 80
protocol: TCP
targetPort: http
nodePort: 80 #追加此行
- appProtocol: https
name: https
port: 443
protocol: TCP
targetPort: https
nodePort: 443 #追加此行
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
type: NodePort
externalTrafficPolicy: Local #追加此行
......
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.11.1
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
replicas: 3 #配置副本数
......
spec:
containers:
- args:
- /nginx-ingress-controller
......
#image: registry.k8s.io/ingress-nginx/controller:v1.11.1 #修改image镜像
image: registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:v1.12.0 #修改为国内仓库
......
volumeMounts:
......
- mountPath: /etc/localtime #挂载localtime
name: timeconfig
readOnly: true
dnsPolicy: ClusterFirst
nodeSelector:
kubernetes.io/os: linux
ingress: enable
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule #追加nodeSelector和tolerations
......
volumes:
- name: webhook-cert
secret:
secretName: ingress-nginx-admission
- name: timeconfig #将hostpath配置为挂载卷
hostPath:
path: /etc/localtime
......
image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v1.5.0 #修改image镜像
......
image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v1.5.0 #修改image镜像
......
[root@master01 ingress]# kubectl apply -f deploy.yaml提示:添加默认backend需要等待default-backend创建完成controllers才能成功部署,新版本ingress不再推荐添加default backend。
确认验证
查看Pod部署进度,是否成功完成。
shell
[root@master01 ingress]# kubectl get pods -n ingress-nginx -o wide
[root@master01 ingress]# kubectl get svc -n ingress-nginx -o wide
提示:参考文档: https://github.com/kubernetes/ingress-nginx/blob/master/docs/deploy/index.md 。
提示:其他更多ingress学习知识可参考此博客: Ingress-Nginx使用指南上篇 。
Dashboard部署
dashboard介绍
dashboard是基于Web的Kubernetes用户界面,即WebUI。
可以使用dashboard将容器化应用程序部署到Kubernetes集群,对容器化应用程序进行故障排除,以及管理集群资源。
可以使用dashboard来查看群集上运行的应用程序,以及创建或修改单个Kubernetes资源(例如部署、任务、守护进程等)。
可以使用部署向导扩展部署,启动滚动更新,重新启动Pod或部署新应用程序。
dashboard还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。
通常生产环境中建议部署dashboard,以便于图形化来完成基础运维。
从7.0.0版本开始,社区已放弃了对基于manifest安装的支持,现在只支持基于helm的安装。 由于多容器设置和对Kong网关API代理的严重依赖,原有基于yaml清单安装的方式已不可行。
同时基于helm的安装,部署速度更快,并且可以更好地控制Dashboard运行所需的所有依赖项。并且已经改变了版本控制方案,并从Helm chart中删除了appVersion。
因为,使用多容器设置,每个模块现在都是单独的版本,Helm chart版本现在可以被视为应用版本。
设置标签
基于最佳实践,非业务应用,或集群自身的应用都部署在Master节点。
shell
[root@master01 ~]# kubectl label nodes master0{1,2,3} dashboard=enable提示:建议对于Kubernetes自身相关的应用(如dashboard),此类非业务应用部署在master节点。
创建证书
默认dashboard会自动创建证书,同时使用对应证书创建secret。生产环境可以启用相应的域名进行部署dashboard,因此需要将对于的域名制作为TLS证书。
本实验已获取免费一年的证书,免费证书获取可参考:https://freessl.cn 。
将已获取的证书上传至对应目录。
shell
[root@master01 ~]# mkdir -p /root/dashboard/certs
[root@master01 ~]# cd /root/dashboard/certs
[root@master01 certs]# mv web.linuxsb.com.crt tls.crt
[root@master01 certs]# mv web.linuxsb.com.key tls.key
[root@master01 certs]# ll
total 12K
-rw-r--r-- 1 root root 4.4K Feb 23 22:23 tls.crt
-rw-r--r-- 1 root root 1.7K Feb 23 22:23 tls.key提示:也可手动如下操作创建自签证书:
[root@master01 ~]# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/C=CN/ST=ZheJiang/L=HangZhou/O=Xianghy/OU=Xianghy/CN=webui.linuxsb.com"
手动创建secret
自定义证书的场景,建议提前使用对应的证书创建secret。
shell
[root@master01 ~]# kubectl create ns kubernetes-dashboard #v3版本dashboard独立ns
[root@master01 ~]# kubectl create secret generic kubernetes-dashboard-certs --from-file=/root/dashboard/certs/ -n kubernetes-dashboard
[root@master01 ~]# kubectl get secret kubernetes-dashboard-certs -n kubernetes-dashboard -o yaml #查看证书信息添加repo
添加kubernetes-dashboard的repo仓库。
shell
[root@master01 ~]# helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
[root@master01 ~]# helm repo list
NAME URL
......
kubernetes-dashboard https://kubernetes.github.io/dashboard/ 编辑配置
根据实际情况修改默认的chart values,未配置的项表示使用默认值。
如下yaml主要做了几项自定义配置:
- 指定dashboard部署在master节点,将其归属为集群自有应用,而非业务应用;
- 指定了使用自有的TLS证书,及https的ingress域名;
- 指定了污点能接受master节点;
- 指定了Pod挂载本地时间文件,使Pod时钟正确。
kubernetes-dashboard默认的values值参考 Kubernetes dashboard chart values ,没有自定义的参数将自动沿用默认配置。
shell
[root@master01 ~]# cd /root/dashboard/
[root@master01 dashboard]# vi myvalues.yaml
app:
mode: 'dashboard'
image:
pullPolicy: IfNotPresent
pullSecrets: []
scheduling:
nodeSelector: {"dashboard": "enable"}
ingress:
enabled: true
hosts:
# - localhost
- web.linuxsb.com
ingressClassName: nginx
useDefaultIngressClass: false
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
tls:
enabled: true
secretName: "kubernetes-dashboard-certs"
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
auth:
nodeSelector: {"dashboard": "enable"}
# API deployment configuration
api:
scaling:
replicas: 3
containers:
volumeMounts:
- mountPath: /tmp
name: tmp-volume
- mountPath: /etc/localtime
name: timeconfig
volumes:
- name: tmp-volume
emptyDir: {}
- name: timeconfig
hostPath:
path: /etc/localtime
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"
# WEB UI deployment configuration
web:
role: web
scaling:
replicas: 3
revisionHistoryLimit: 10
containers:
volumeMounts:
- mountPath: /tmp
name: tmp-volume
- mountPath: /etc/localtime
name: timeconfig
volumes:
- name: tmp-volume
emptyDir: {}
- name: timeconfig
hostPath:
path: /etc/localtime
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"
# Metrics Scraper
metricsScraper:
scaling:
replicas: 3
containers:
volumeMounts:
- mountPath: /tmp
name: tmp-volume
- mountPath: /etc/localtime
name: timeconfig
volumes:
- name: tmp-volume
emptyDir: {}
- name: timeconfig
hostPath:
path: /etc/localtime
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"
kong:
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"正式部署
根据生产环境最佳实践进行调优,调优完成后开始部署。
shel
[root@master01 dashboard]# helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard -f myvalues.yaml提示:对于国内环境,可能如上直接部署会由于网络原因失败,可单独将dashboard包下载至本地,然后通过命令部署。
shell
[root@master01 dashboard]# wget https://github.com/kubernetes/dashboard/releases/download/kubernetes-dashboard-7.10.4/kubernetes-dashboard-7.10.4.tgz
[root@master01 dashboard]# helm upgrade --install kubernetes-dashboard ./kubernetes-dashboard-7.10.4.tgz \
--create-namespace --namespace kubernetes-dashboard \
-f myvalues.yaml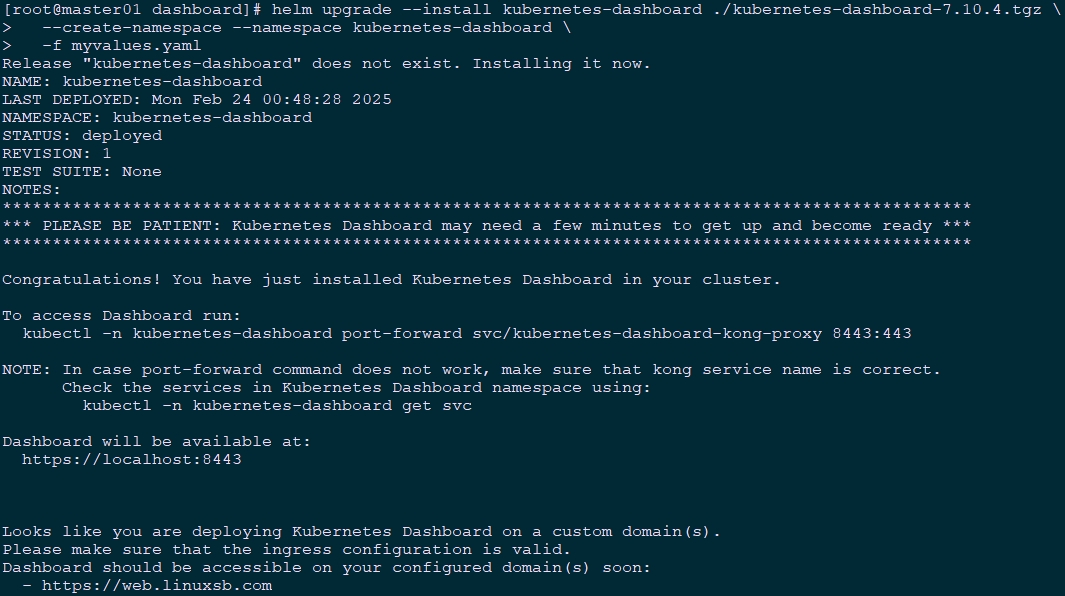
shell
[root@master01 dashboard]# helm -n kubernetes-dashboard list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kubernetes-dashboard kubernetes-dashboard 1 2025-02-24 00:48:28.184210752 +0800 CST deployed kubernetes-dashboard-7.10.4
[root@master01 dashboard]# kubectl -n kubernetes-dashboard get all
[root@master01 dashboard]# kubectl -n kubernetes-dashboard get deployments.apps
[root@master01 dashboard]# kubectl -n kubernetes-dashboard get services
[root@master01 dashboard]# kubectl -n kubernetes-dashboard get pods -o wide
[root@master01 dashboard]# kubectl -n kubernetes-dashboard get svc
[root@master01 dashboard]# kubectl -n kubernetes-dashboard get ingress -o wide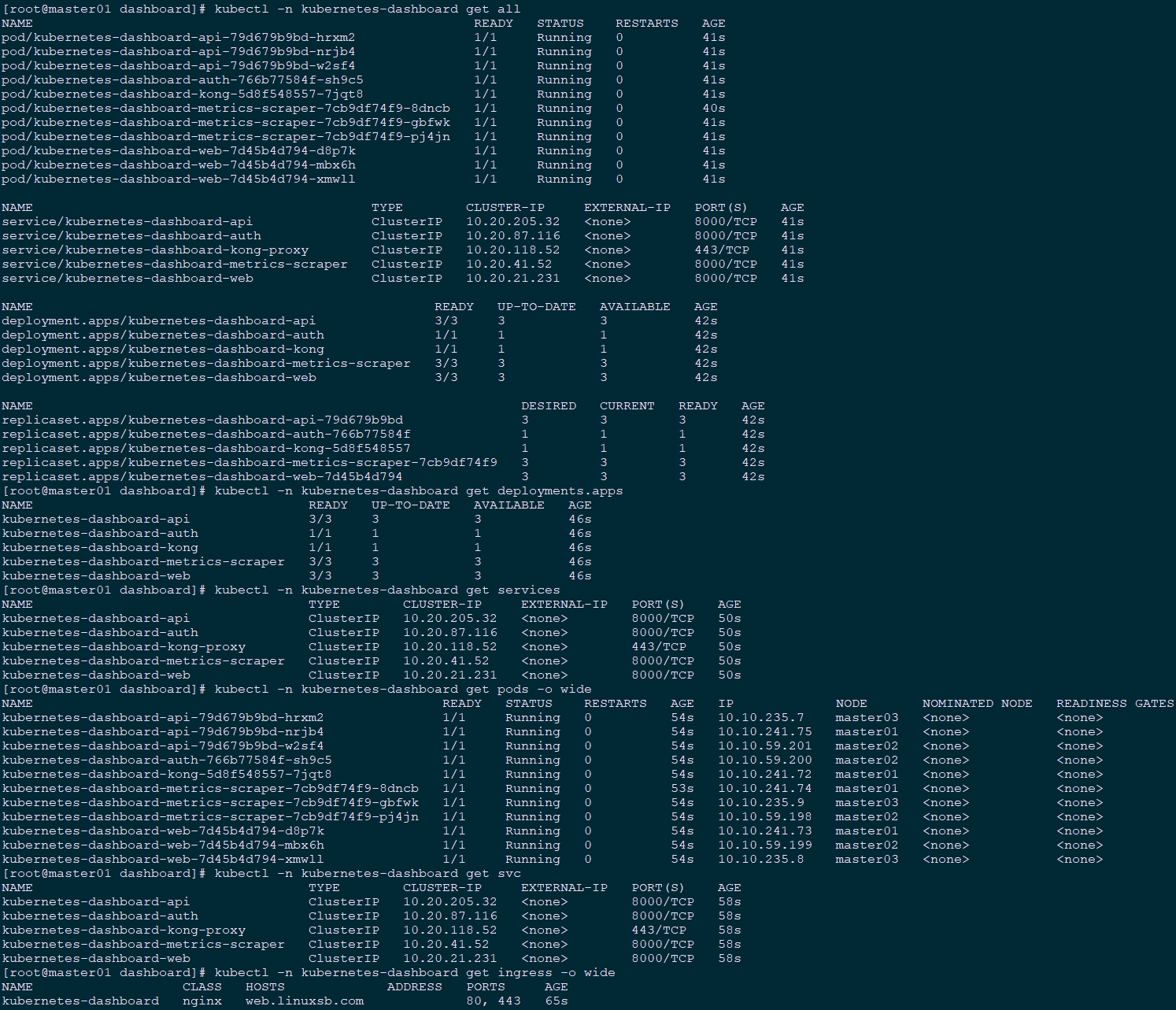
默认配置中,会自动为dashboard创建ingress规则,部署ingress之后可直接如上图所示存在dashboard的ingress对象。
创建管理员账户
建议创建管理员账户,dashboard默认没有创建具有管理员权限的账户,同时v7版本登录只支持token方式。
因此建议创建管理员权限的用户,然后创建此用户的token,然后使用此token进行登录。
shell
[root@master01 dashboard]# cat <<EOF > dashboard-admin.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin
namespace: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: admin
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: "admin"
EOF
[root@master01 dashboard]# kubectl apply -f dashboard-admin.yaml查看token
使用token相对复杂,可将token添加至kubeconfig文件中,使用KubeConfig文件访问dashboard。
shell
[root@master01 dashboard]# ADMIN_SECRET=$(kubectl -n kubernetes-dashboard get secret | grep admin | awk '{print $1}')
[root@master01 dashboard]# DASHBOARD_LOGIN_TOKEN=$(kubectl describe secret -n kubernetes-dashboard ${ADMIN_SECRET} | grep -E '^token' | awk '{print $2}')
[root@master01 dashboard]# echo ${DASHBOARD_LOGIN_TOKEN}提示:也可通过如下方式获取name为admin的secret的token。
kubectl -n kubernetes-dashboard get secret admin -o jsonpath={".data.token"} | base64 -d
将web.linuxsb.com.crt证书文件导入,以便于浏览器使用该文件登录。
导入证书
将web.linuxsb.com.crt证书导入浏览器,并设置为信任,可规避证书不受信任的弹出。
测试访问dashboard
本实验采用ingress所暴露的域名:https://web.linuxsb.com
使用对应admin用户的token进行访问。
登录后默认进入的是default命名空间,可切换至其他对应的namespace,对整个Kubernetes进行管理和查看。
提示:更多dashboard访问方式及认证可参考附004.Kubernetes Dashboard简介及使用。
dashboard登录整个流程可参考:https://www.cnadn.net/post/2613.html
Longhorn存储部署
Longhorn概述
Longhorn是用于Kubernetes的开源分布式块存储系统。
当前Kubernetes 1.32.2版本建议使用Longhorn 1.8.0 。
提示:更多介绍参考:https://github.com/longhorn/longhorn 。
安装要求
安装 Longhorn 的 Kubernetes 集群中的每个节点都必须满足以下要求:
- 与 Kubernetes 兼容的容器运行时,如Docker v1.13+、containerd v1.3.7+ ;
- Kubernetes >= v1.25;
- open-iscsi已安装,并且iscsid守护程序在所有节点上运行,此为必要条件,Longhorn 依赖 iscsiadm 主机为 Kubernetes 提供持久卷;
- RWX 支持要求每个节点都安装 NFSv4 客户端;
- 有关安装 NFSv4 客户端;
- 主机文件系统支持file extents存储数据的功能,当前支持:ext4、xfs;
- 其他必要命令工具:bash、curl、findmnt、grep、awk、blkid、lsblk;
- 为了正确部署和运行 Longhorn,Longhorn 工作负载必须能够以 root 身份运行。
本指南旨在使用longhorn给Kubernetes提供持久化存储,通常由Kubernetes的应用操作Longhorn,Longhorn也支持直接通过longhornctl命令操作存储。
longhornctl命令更多使用参考:longhornctl命令工具 。
shell
curl -sSfL -o /usr/local/bin/longhornctl https://github.com/longhorn/cli/releases/download/v1.8.0/longhornctl-linux-amd64
chmod +x /usr/local/bin/longhornctlroot权限说明可参考: Root和特权权限说明
安装准备
- 脚本检查
最新版官方已提供完整的环境检查脚本。
shell
[root@master01 ~]# curl -sSfL https://raw.githubusercontent.com/longhorn/longhorn/v1.8.0/scripts/environment_check.sh | bash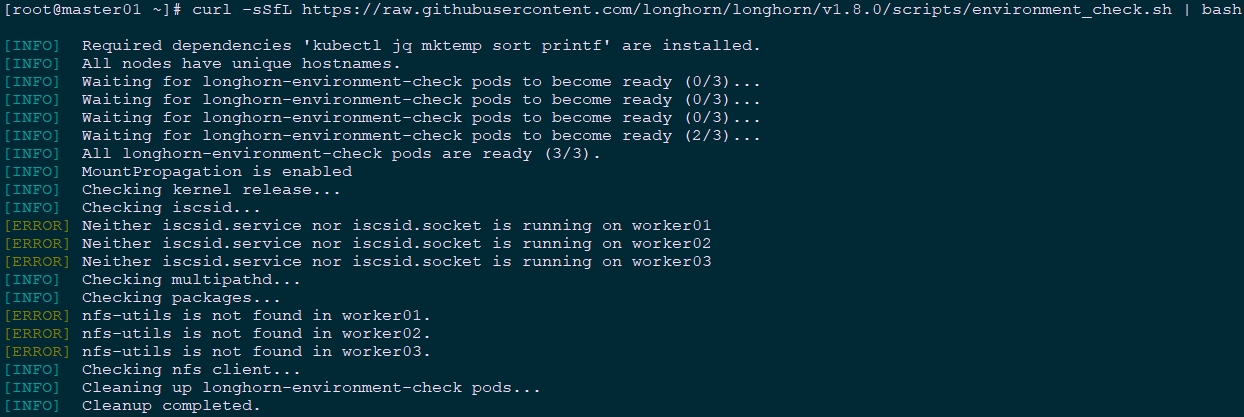
由上可知iscsid和nfs组件没有安装。
- 环境准备
后续业务应用可能运行在任意节点位置,挂载操作需要在任何节点可正常执行。
所有节点均需要安装基础以来软件。
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh root@${all_ip} "cat /boot/config-`uname -r`| grep CONFIG_NFS_V4"
ssh root@${all_ip} "yum -y install iscsi-initiator-utils nfs-utils cryptsetup &"
ssh root@${all_ip} "systemctl enable iscsid --now && modprobe iscsi_tcp"
ssh root@${all_ip} "cat > /etc/modules-load.d/iscsid.conf <<EOF
iscsi_tcp
EOF"
done提示:如上仅需Master01节点操作,从而实现所有Worker节点的组件安装。
设置标签
在Master节点上部署存储组件的图形界面。
[root@master01 ~]# kubectl label nodes master0{1,2,3} longhorn-ui=enabled
提示:ui图形界面可复用master高可用,因此部署在master节点。
准备磁盘
Longhorn的分布式存储,建议独立磁盘设备专门作为存储卷,可提前挂载。
longhorn默认使用/var/lib/longhorn/作为设备路径,可提前挂载/dev/nvme0n2设备。
不同环境下裸磁盘的设备名不一样,且根据启动时识别的顺序可能设备名不一样,因此建议采用UUID挂载设备,保持挂载一致性。
[root@worker01 ~]# fdisk -l #判断新增的独立磁盘
[root@worker01 ~]# mkfs.xfs -f /dev/nvme0n1 && mkdir -p /var/lib/longhorn/ #格式化磁盘为xfs
[root@worker01 ~]# blkid | grep nvme0n1 #判断独立磁盘的UUID
/dev/nvme0n1: UUID="8f4196d4-5aeb-4fbf-a223-e88c66f3212c" BLOCK_SIZE="512" TYPE="xfs"
[root@worker01 ~]# echo "UUID=8f4196d4-5aeb-4fbf-a223-e88c66f3212c /var/lib/longhorn/ xfs defaults 0 0" >> /etc/fstab提示:如上操作需要在所有worker节点根据相应的UUID进行挂载操作。
shell
[root@master01 ~]# source environment.sh
[root@master01 ~]# for node_ip in ${NODE_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${node_ip}...\033[0m"
ssh root@${node_ip} "systemctl daemon-reload"
ssh root@${node_ip} "mount -a"
echo -e "\n\n\033[34m[WARN] >>> ${node_ip} check result...\033[0m"
sleep 1
ssh root@${node_ip} "df -hT | grep longhorn"
done配置Longhorn
根据实际生产环境,对Longhorn进行优化配置。
存储节点使用worker01、worker02、worker03,图形界面可部署在master节点,复用Kubernetes的高可用。
提示:也可使用helm进行安装,helm安装参考官方: 使用 Helm 安装
kubectl和helm安装时均可自定义相关配置,更多自定义配置可参考官方:Longhorn自定义配置
shell
[root@master01 ~]# mkdir longhorn
[root@master01 ~]# cd longhorn/
[root@master01 longhorn]# wget https://raw.githubusercontent.com/longhorn/longhorn/v1.8.0/deploy/longhorn.yaml
[root@master01 longhorn]# vi longhorn.yaml
#......
apiVersion: apps/v1
kind: DaemonSet
metadata:
#......
name: longhorn-manager
namespace: longhorn-system
#......
spec:
containers:
- name: longhorn-manager
#......
volumeMounts:
#......
- mountPath: /etc/localtime
name: timeconfig
readOnly: true
#......
volumes:
#......
- name: timeconfig
hostPath:
path: /etc/localtime
#......
apiVersion: apps/v1
kind: Deployment
#......
name: longhorn-ui
namespace: longhorn-system
#......
containers:
- name: longhorn-ui
#......
volumeMounts:
#......
- mountPath: /etc/localtime #保持容器时钟正确
name: timeconfig
readOnly: true
#......
volumes:
#......
- name: timeconfig
hostPath:
path: /etc/localtime
#......
nodeSelector: #追加标签选择
longhorn-ui: enabled
tolerations:
- key: node-role.kubernetes.io/control-plane #添加容忍
effect: NoSchedule
#......对于longhorn-ui的svc建议不直接通过nodeport暴露,保持默认的ClusterIP,然后通过ingress对外暴露。
有关计数器支持的解释参考: 修改计数器
正式部署
基于优化的yaml进行部署。
shell
[root@master01 ~]# cd longhorn/
[root@master01 longhorn]# kubectl apply -f longhorn.yaml
[root@master01 longhorn]# kubectl -n longhorn-system get pods -o wide #查看所有已部署的Pod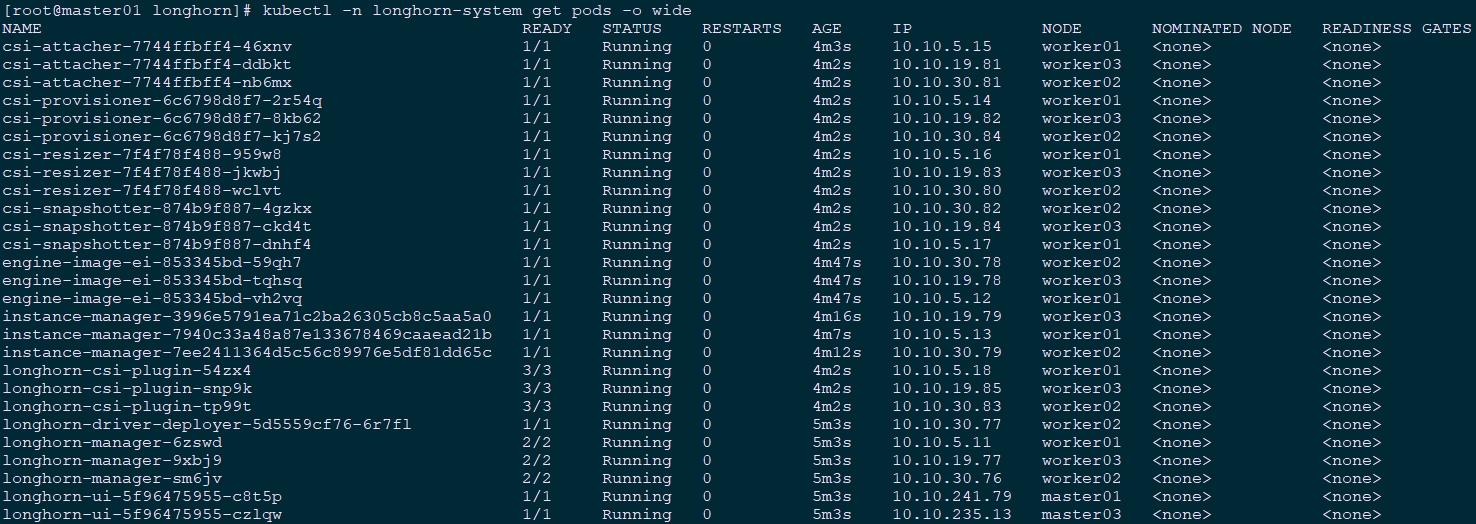
提示:若部署异常可删除重建,若出现无法删除namespace,可通过如下操作进行删除:
shell
wget https://github.com/longhorn/longhorn/blob/master/uninstall/uninstall.yaml
kubectl apply -f uninstall.yaml
kubectl get job/longhorn-uninstall -n longhorn-system -w
kubectl delete -f uninstall.yaml #等待任务完成再次执行delete
rm -rf /var/lib/longhorn/* && rm -rf /data/longhorn/*
若依旧无法释放,参考《附098.Kubernetes故障排查记录》。动态sc创建
部署Longhorn后,默认已创建一个名为longhorn的sc。
shell
[root@master01 longhorn]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 16m
longhorn-static driver.longhorn.io Delete Immediate true 16m也可以通过如下方式创建一个新的sc。
shell
[root@master01 longhorn]# cat <<EOF > longhornpsc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880" # 48 hours in minutes
fromBackup: ""
fsType: "ext4"
EOF
[root@master01 longhorn]# kubectl apply -f longhornpsc.yaml测试PV及PVC
使用常见的Nginx Pod进行测试,模拟生产环境常见的Web类应用的持久性存储卷。
shell
[root@master01 longhorn]# cat <<EOF > longhornpvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 50Mi
EOF #创建PVC
[root@master01 longhorn]# cat <<EOF > longhornpod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: longhorn-pod
namespace: default
spec:
containers:
- name: volume-test
image: nginx:stable-alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- name: volv
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: volv
persistentVolumeClaim:
claimName: longhorn-pvc
EOF #创建Pod
[root@master01 longhorn]# kubectl apply -f longhornpvc.yaml -f longhornpod.yaml
[root@master01 longhorn]# kubectl get pods -o wide
[root@master01 longhorn]# kubectl get pvc -o wide
[root@master01 longhorn]# kubectl get pv -o wide
Ingress暴露Longhorn
使用已部署完成的ingress将Longhorn UI暴露,以便于使用URL形式访问Longhorn图形界面进行Longhorn的基础管理。
shell
[root@master01 longhorn]# yum -y install httpd-tools
[root@master01 longhorn]# htpasswd -c auth admin #创建用户名和密码
New password: [输入密码]
Re-type new password: [输入密码]提示:也可通过如下命令创建:
USER=admin; PASSWORD=admin1234; echo "${USER}:$(openssl passwd -stdin -apr1 <<< ${PASSWORD})" >> auth
shell
[root@master01 longhorn]# kubectl -n longhorn-system create secret generic longhorn-basic-auth --from-file=auth
[root@master01 longhorn]# cat <<EOF > longhorn-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: longhorn-ingress
namespace: longhorn-system
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: longhorn-basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required '
spec:
ingressClassName: "nginx"
rules:
- host: longhorn.linuxsb.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: longhorn-frontend
port:
number: 80
EOF
[root@master01 longhorn]# kubectl apply -f longhorn-ingress.yaml
[root@master01 longhorn]# kubectl -n longhorn-system get svc longhorn-frontend
[root@master01 longhorn]# kubectl -n longhorn-system get ingress longhorn-ingress
[root@master01 longhorn]# kubectl -n longhorn-system describe svc longhorn-frontend
[root@master01 longhorn]# kubectl -n longhorn-system describe ingress longhorn-ingress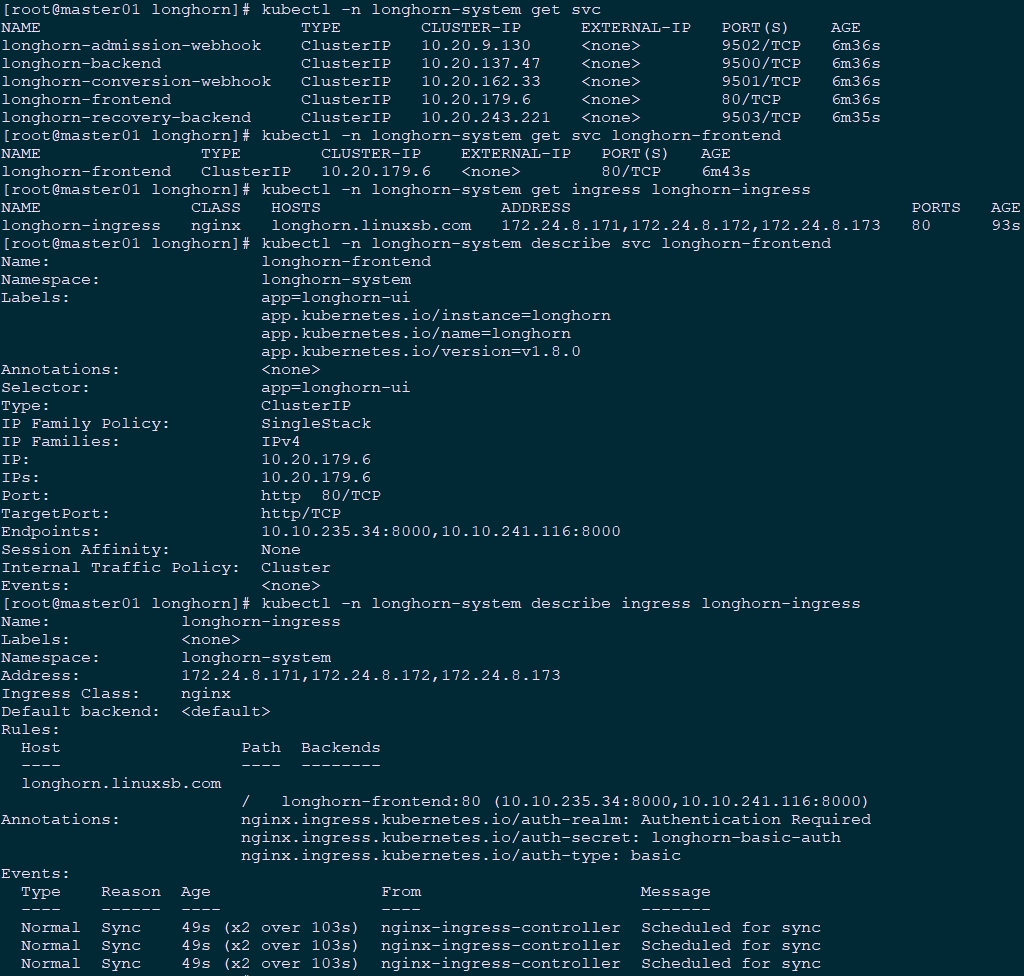
确认验证
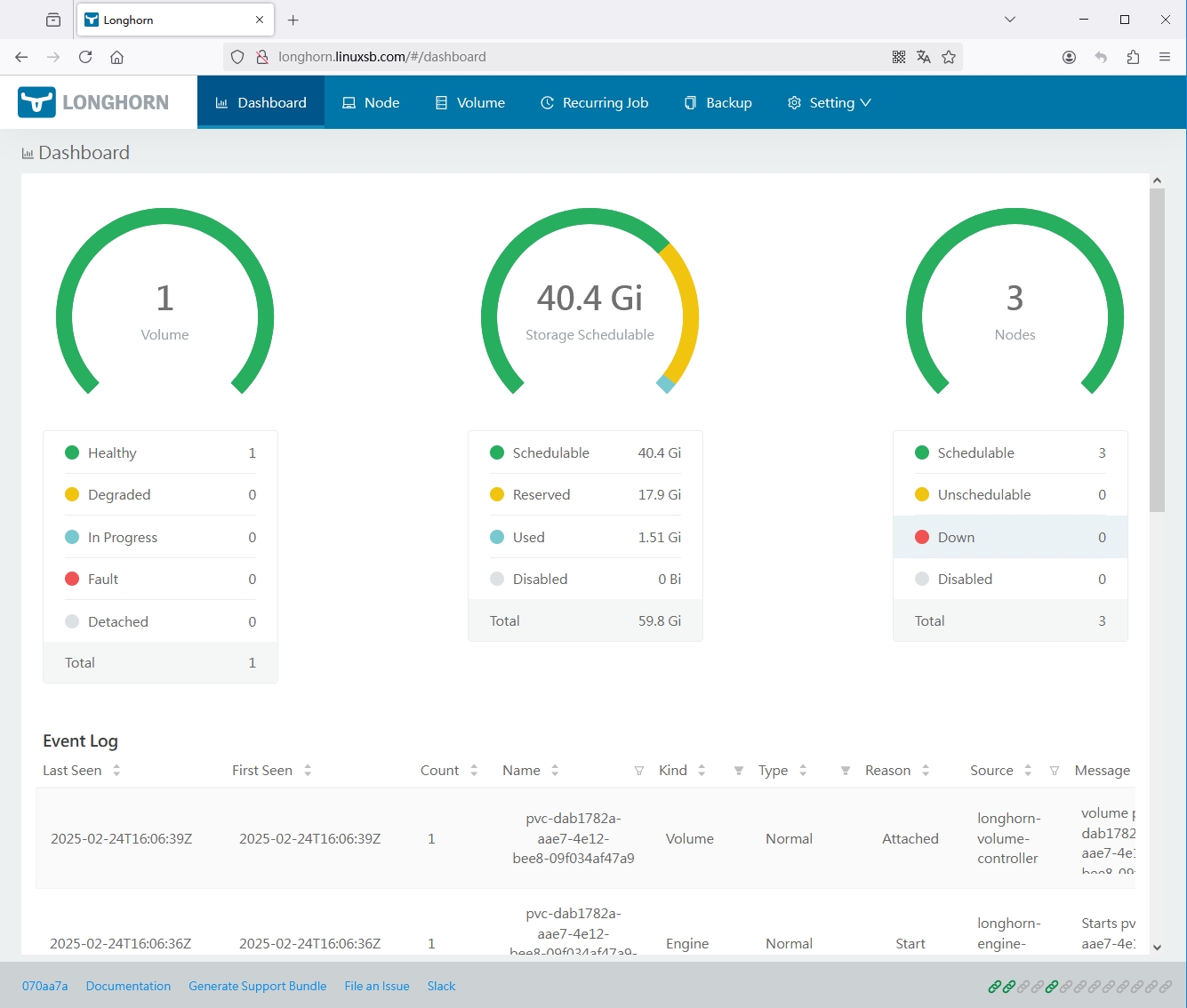
浏览器访问:longhorn.linuxsb.com ,并输入设置的账号和密码。

使用admin/密码登录查看。
扩展:集群扩容及缩容
集群扩容
- master节点扩容
参考:添加Master节点 步骤 - worker节点扩容
参考:添加Worker节点 步骤
集群缩容
- master节点缩容
Master节点缩容的时候会自动将Pod迁移至其他节点。
shell
[root@master01 ~]# kubectl drain master03 --delete-emptydir-data --force --ignore-daemonsets
[root@master01 ~]# kubectl delete node master03
[root@master03 ~]# kubeadm reset -f && rm -rf $HOME/.kube- worker节点缩容
Worker节点缩容的时候会自动将Pod迁移至其他节点。
shell
[root@master01 ~]# kubectl drain worker04 --delete-emptydir-data --force --ignore-daemonsets
[root@master01 ~]# kubectl delete node worker04
[root@worker04 ~]# kubeadm reset -f
[root@worker04 ~]# rm -rf /etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf