DeepSeek 新的 LLM 推理方法DeepSeek 通过强化学习(RL)提出了一种创新的改进大规模语言模型(LLM)推理能力的方法,这在他们最近关于 DeepSeek-R1 的论文中有详细介绍。这项研究代表了在不依赖于大量有监督微调的情况下,通过纯强化学习提升 LLM 解决复杂问题能力的重大进展。
DeepSeek-R1 技术概述
模型架构:
DeepSeek-R1 并不是一个单一的模型,而是一个包含多个模型的系列,包括:DeepSeek-R1-Zero 和 DeepSeek-R1
让我来澄清一下 DeepSeek-R1 和 DeepSeek-R1-Zero 之间的主要区别:
主要区别
DeepSeek-R1-Zero 代表了团队最初的实验,使用纯强化学习而没有任何监督微调。他们从基础模型开始,直接应用强化学习,让模型通过反复试错来发展推理能力。尽管这种方法取得了令人印象深刻的结果(AIME 2024 达到 71% 的准确率),但它存在一些重大局限,特别是在可读性和语言一致性方面。该模型有 6710 亿个参数,采用混合专家(MoE)架构,每个 token 激活相当于 370 亿个参数。该模型展示了涌现的推理行为,例如自我验证、反思和长链思考(CoT)推理。
相比之下,DeepSeek-R1 使用了更复杂的多阶段训练方法。它不是纯粹依赖强化学习,而是首先在一小组精心挑选的示例(称为"冷启动数据")上进行有监督微调,然后再应用强化学习。这种方法解决了 DeepSeek-R1-Zero 的局限,同时实现了更好的性能。这个模型同样保持了 6710 亿个参数,但在回答时提供了更好的可读性和一致性。
训练过程比较
训练方法:
• 强化学习:与传统模型主要依赖有监督学习不同,DeepSeek-R1 广泛使用 RL。训练利用了组相对策略优化(GRPO),专注于准确性和格式奖励,以增强推理能力,而无需大量标注数据。
• 蒸馏技术:为了让更多人能够使用高性能模型,DeepSeek 还发布了 R1 的蒸馏版本,参数范围从 15 亿到 70 亿。这些模型基于像 Qwen 和 Llama 这样的架构,表明复杂的推理可以被压缩到更小、更高效的模型中。蒸馏过程包括使用 DeepSeek-R1 完整模型生成的合成推理数据来微调这些较小的模型,从而在降低计算成本的同时保持高性能。
DeepSeek-R1-Zero 的训练过程较为简单:
• 从基础模型开始
• 直接应用强化学习
• 使用基于准确性和格式的简单奖励
DeepSeek-R1 的训练过程有四个独特的阶段:
-
使用成千上万的高质量示例进行初步有监督微调
-
专注于推理任务的强化学习
-
通过拒绝采样收集新的训练数据
-
在所有类型任务上进行最终的强化学习
性能指标:
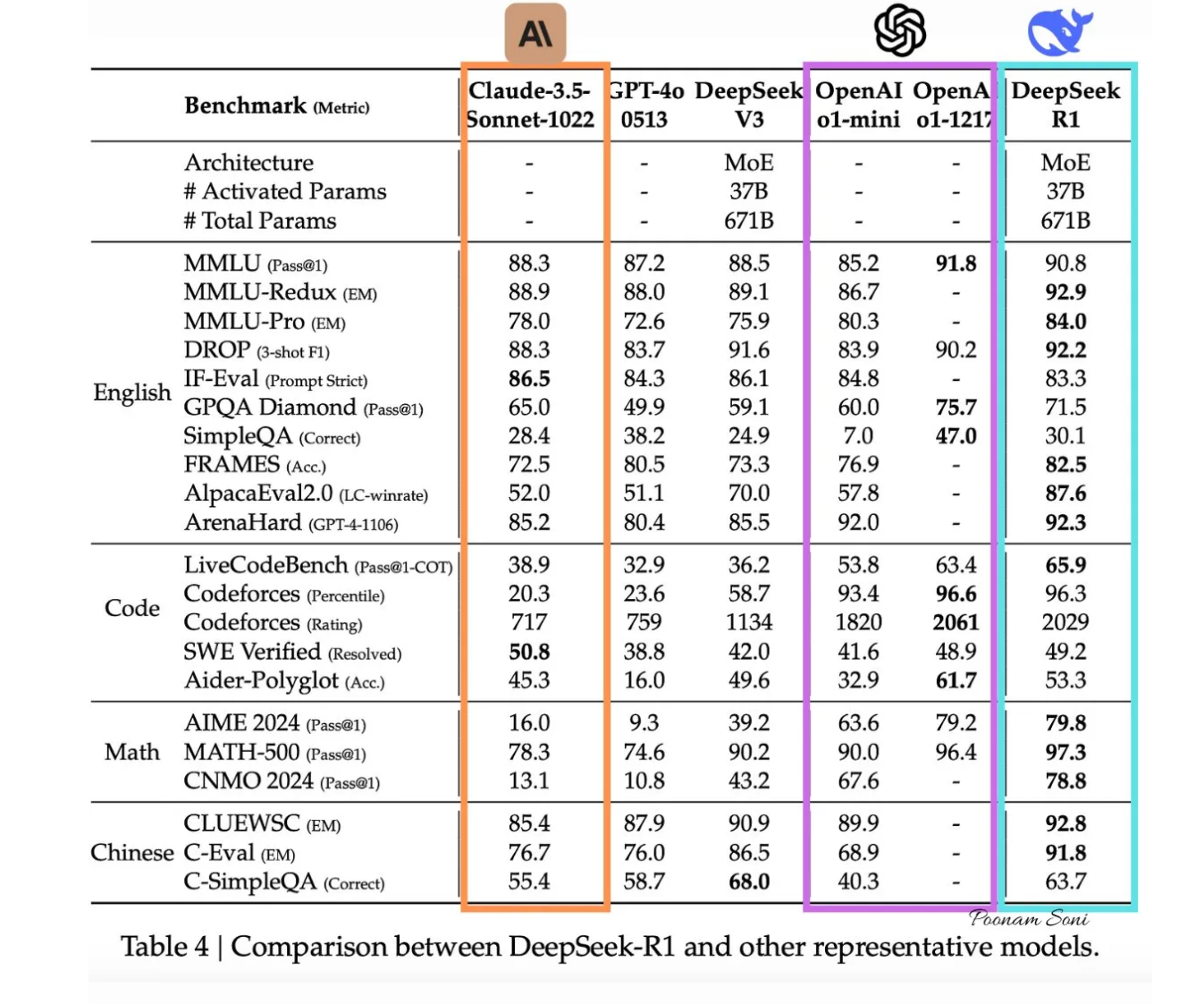
• 推理基准:DeepSeek-R1 在各种基准测试中表现出色:
• AIME 2024:通过率达到 79.8%,相比之下,OpenAI 的 o1--1217 为 79.2%。
• MATH-500:得分 97.3%,稍微领先于 o1--1217 的 96.4%。
• SWE-bench Verified:在编程任务中表现突出,展示了其编程能力。
• 成本效益:DeepSeek-R1 的 API 价格为每百万输入 token 0.14 美元,对于缓存命中来说,比 OpenAI 的 o1 更便宜。
局限性与未来工作
论文中指出了几个需要改进的地方:
• 模型在处理需要特定输出格式的任务时有时会遇到困难
• 在软件工程任务上的表现可以进一步提高
• 在多语言环境中存在语言混合问题
• 少样本提示会 consistently 降低性能
未来的工作将重点解决这些局限,并扩展模型在功能调用、多轮交互和复杂角色扮演场景等方面的能力。
部署与可访问性
• 开源与许可:DeepSeek-R1 及其变体都以 MIT 许可证发布,促进开源合作和商业使用,包括模型蒸馏。这一举措对推动创新和降低 AI 模型开发的进入门槛至关重要。
• 模型格式:
• 模型及其蒸馏版本均提供 GGML、GGUF、GPTQ 和 HF 等格式,允许灵活的本地部署方式。
- 通过 DeepSeek 聊天平台访问:
DeepSeek 聊天平台提供了一个用户友好的界面,可以与 DeepSeek-R1 进行交互,无需任何设置。
• 访问步骤:
• 导航至 DeepSeek 聊天平台
• 注册账号或如果已有账号,则登录。
• 登录后,选择"Deep Think"模式,体验 DeepSeek-R1 的逐步推理能力。
DeepSeek 聊天平台- 通过 DeepSeek API 访问:
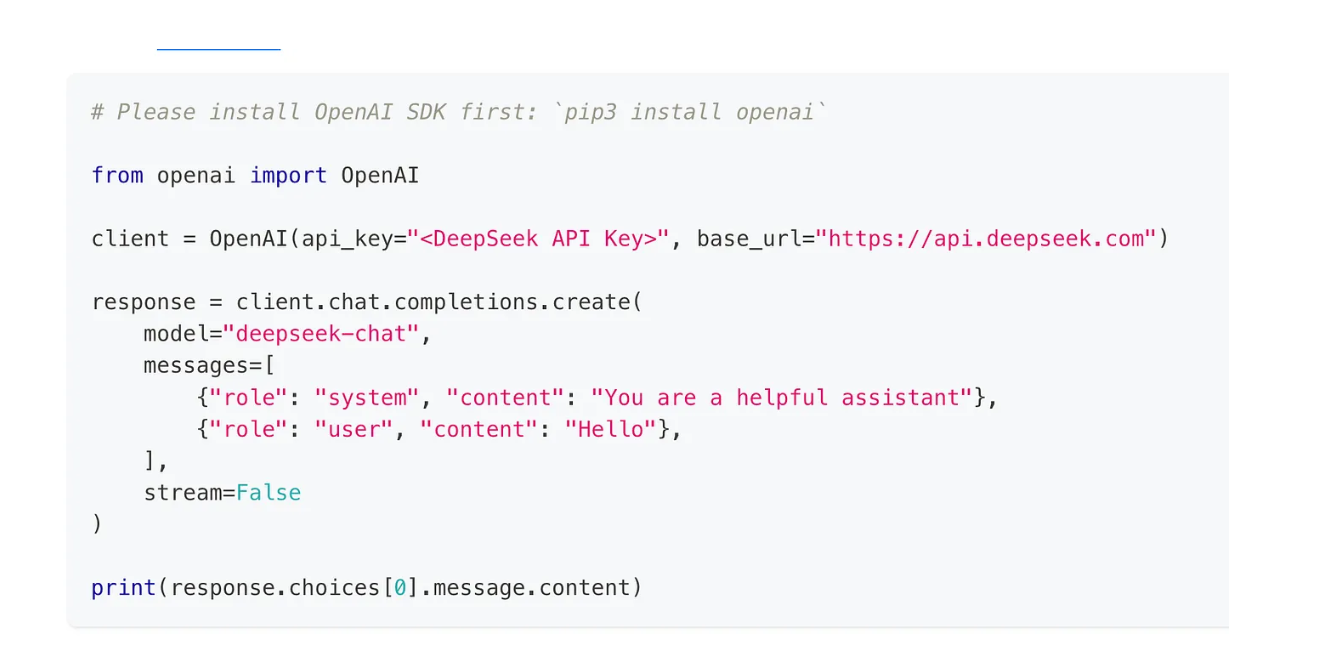
对于程序化访问,DeepSeek 提供了一个兼容 OpenAI 格式的 API,允许将其集成到各种应用程序中。
使用 API 的步骤:
a. 获取 API 密钥:
• 访问 DeepSeek API 平台创建账户并生成唯一的 API 密钥。
b. 配置环境:
• 设置 base_url 为 https://api.deepseek.com/v1。
• 使用 API 密钥进行身份验证,通常通过 Bearer Token 在 HTTP 头中进行身份验证。
c. 调用 API:
• 使用 API 发送提示并从 DeepSeek-R1 获取响应。
• DeepSeek API 文档中有详细的文档和示例。
DeepSeek API 调用示例- 本地运行 DeepSeek-R1:
两个模型(R1 和 R1-Zero):
• 硬件要求:由于模型的规模较大,完整模型需要强大的硬件。推荐使用具有大量 VRAM(如 Nvidia RTX 3090 或更高)的 GPU。如果使用 CPU,至少需要 48GB 的内存和 250GB 的磁盘空间,但没有 GPU 加速的情况下性能会较慢。
• 蒸馏模型:对于资源要求较低的硬件,DeepSeek 提供了蒸馏版本。这些版本从 15 亿到 70 亿参数不等,适用于硬件要求较为适中的系统。例如,7B 模型可以在至少 6GB VRAM 的 GPU 或大约 4GB 内存的 CPU 上运行,适用于 GGML/GGUF 格式。
本地运行软件工具:
- Ollama:
你可以使用 Ollama 本地提供模型:(Ollama 是一个本地运行开源 AI 模型的工具,下载地址:https://ollama.com/download)
接下来,你需要拉取并本地运行 DeepSeek R1 模型。
Ollama 提供了不同的模型大小------基本上,越大的模型越智能,但需要更好的 GPU。以下是模型的选择:
1.5B 版本(最小):
ollama run deepseek-r1:1.5b
8B 版本:
ollama run deepseek-r1:8b
14B 版本:
ollama run deepseek-r1:14b
32B 版本:
ollama run deepseek-r1:32b
70B 版本(最大/最智能):
ollama run deepseek-r1:70b
开始实验 DeepSeek-R1 时,建议从较小的模型开始,以熟悉设置并确保与硬件的兼容性。你可以通过打开终端并执行以下命令来启动:
ollama run deepseek-r1:8b
来自 Reddit 的图片,via r/macapps通过 Ollama 向本地下载的 DeepSeek-R1 发送请求:
Ollama 提供了一个 API 端点,可以通过编程方式与 DeepSeek-R1 进行交互。确保在发送 API 请求之前,Ollama 服务器已在本地运行。你可以通过运行以下命令来启动服务器:
ollama serve
服务器启动后,你可以使用 curl 发送请求:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "deepseek-r1",
"prompt": "Your question or prompt here"
}'
将"Your question or prompt here"替换为你希望提供给模型的实际输入。此命令将 POST 请求发送到本地 Ollama 服务器,服务器使用指定的 DeepSeek-R1 模型处理提示,并返回生成的响应。
本地运行/访问模型的其他方法有:
vLLM/SGLang:用于本地提供模型。可以使用类似 vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --- tensor-parallel-size 2 --- max-model-len 32768 --- enforce-eager 的命令来运行蒸馏版本。

来自 HuggingFace 的图片llama.cpp:你还可以使用 llama.cpp 本地运行模型。
看看其他人是如何使用 DeepSeek-R1 的:
- 在我的 7 台 M4 Pro Mac Mini 和 1 台 M4 Max MacBook Pro 上运行 DeepSeek R1:
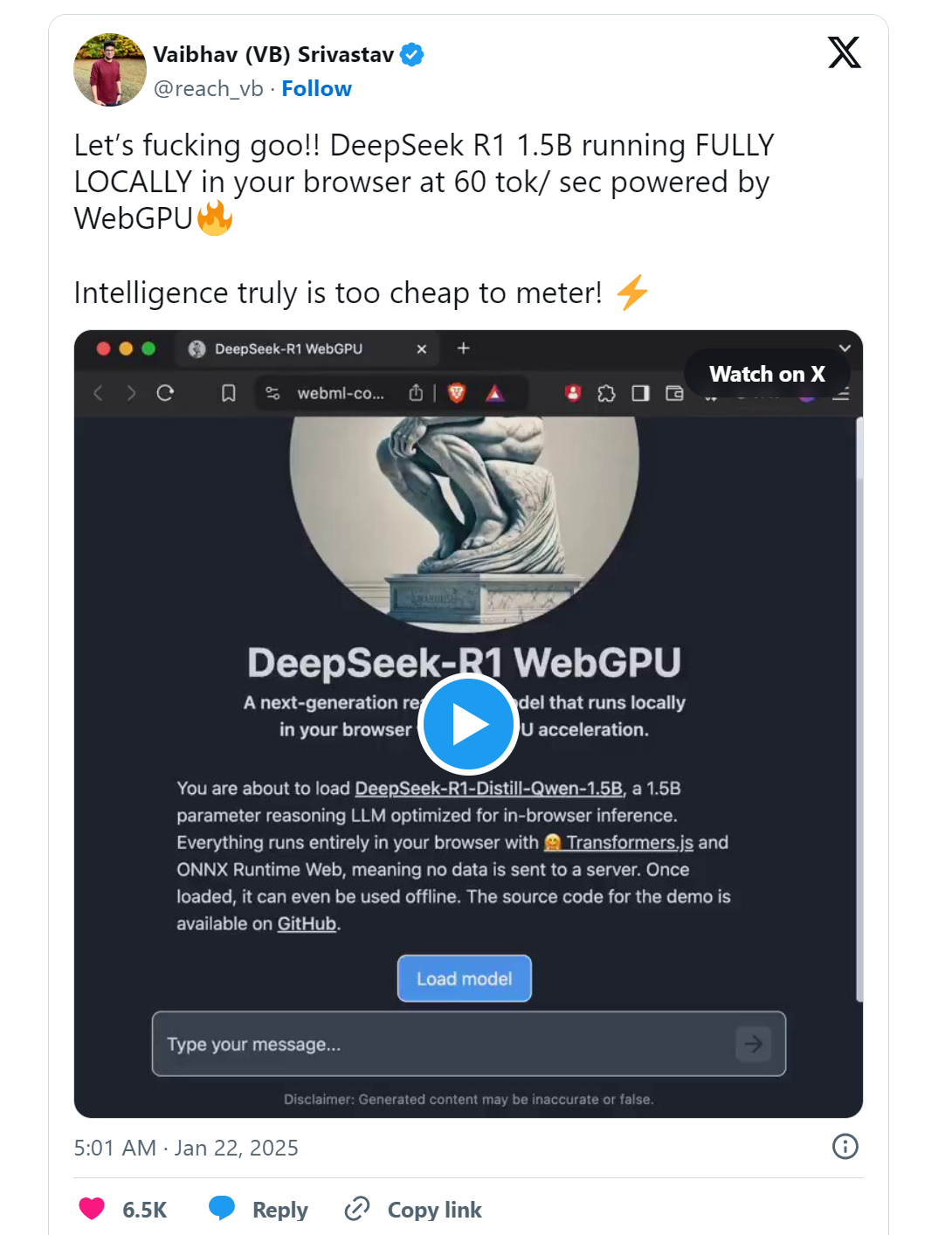
- DeepSeek R1 1.5B 完全本地运行在浏览器中,速度为每秒 60 个 token,由 WebGPU 提供动力:
3 RAG 应用程序,通过 DeepSeek R1 模型与你的 PDF 文件聊天,本地运行在你的计算机上。

4 DeepSeek R1 1.5B 完全在手机上本地运行:
轻松解决复杂的数学问题!(大约 3200 tokens,约 35 秒,运行在 M4 Max 上,使用 mlx-lm)。
结论:
从 DeepSeek-R1-Zero 到 DeepSeek-R1 的进展代表了研究中的一次重要学习过程。虽然 DeepSeek-R1-Zero 证明了纯强化学习可以奏效,但 DeepSeek-R1 展示了如何将有监督学习与强化学习相结合,创造出一个更强大、更实用的模型。