1. 简介
在上篇博文中介绍了如何使用calcite进行sql验证, 但是真正在实际生产环境中我们可能需要使用到
- 用户自定义函数(UDF): 通过代码实现对应的函数逻辑并注册给calcite
- sql验证: 将UDF信息注册给calcite,
SqlValidator.validator验证阶段即可通过验证 - sql执行: calcite通过调用UDF逻辑实现函数逻辑
- sql验证: 将UDF信息注册给calcite,
- 自定义db函数: 数据库中创建的自定义函数
- sql验证: 将自定义的db函数信息注册给calcite,
SqlValidator.validator验证阶段即可通过验证 - sql执行: 下推到db执行对应的db函数
- sql验证: 将自定义的db函数信息注册给calcite,
此时我们需要将自定义的函数注册到calcite中, 用于sql验证和执行. 例如注册一个简单的函数 如: 将数据库中的性别字段值做字典转换.
2. Maven
xml
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.37.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>2. UDF
如上述所说, UDF是将用户自定义的方法注册为函数使用的, 首先看一下calcite是如何注册UDF的
java
SchemaPlus#add(String name, Function function);其Function的实现类如下:
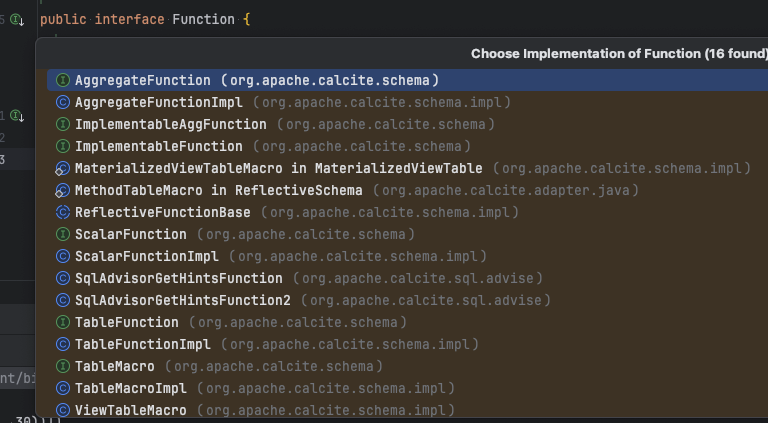
-
定义UDF实现
javapublic class Udf { public static String dictSex(String code) { if (StringUtils.isBlank(code)) { return code; } if (StringUtils.equals(code, "1")) { return "男"; } else if (StringUtils.equals(code, "2")) { return "女"; } else { return "未知"; } } } -
把
dictSex方法注册到calcite中, 因为上述的方法输入返回的都是单一值, 所以直接注册为标量函数即可(如果是聚合函数可以使用AggregateFunction)java// 指定函数名称 和 对应函数的class & method name rootSchema.add("dict_sex", ScalarFunctionImpl.create(Udf.class, "dictSex")); -
测试执行
shellfinal ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`"); printResultSet(resultSet);表数据如下
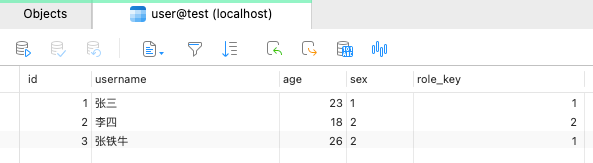
输出结果
shellc.l.c.CalciteFuncTest - [printResultSet,86] - Number of columns: 2 c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=男, username=张三} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=李四} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=张铁牛}
3. 自定义db函数
首先 我们定义一个db 函数实现字典值的转换
sql
DELIMITER //
CREATE FUNCTION dict_sex(code VARCHAR(10))
RETURNS VARCHAR(10)
DETERMINISTIC
BEGIN
-- 如果code为空或只包含空白字符,则直接返回code
IF code IS NULL OR TRIM(code) = '' THEN
RETURN code;
END IF;
-- 如果code为'1'则返回'男'
IF code = '1' THEN
RETURN '男';
-- 如果code为'2'则返回'女'
ELSEIF code = '2' THEN
RETURN '女';
ELSE
RETURN '未知';
END IF;
END //
DELIMITER ;验证函数功能

ok, 函数创建完成, 我们将函数注册到calcite中
calcite中sqlfunction有很多其已经实现的类, 我们这里使用SqlBasicFunction来创建我们的函数
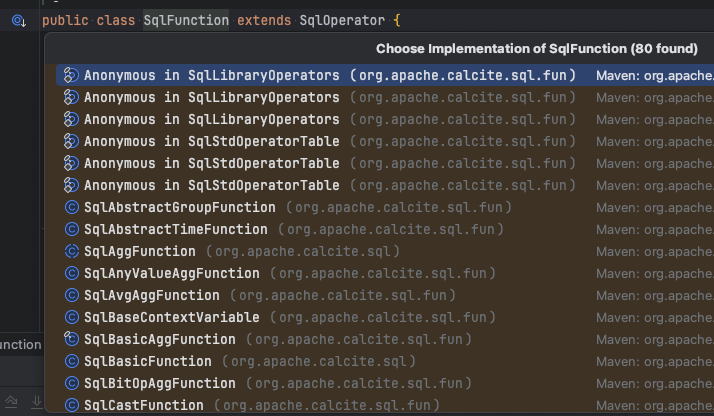
-
定义SqlFunction
java/* * SqlBasicFunction create(String name, SqlReturnTypeInference returnTypeInference, SqlOperandTypeChecker operandTypeChecker) * name: 函数名称 * returnTypeInference: 返回值类型 * operandTypeChecker: 函数入参的校验器 */ SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER)); -
注册SqlFunction
从上篇博文中我们知道, calcite的sql函数都注册到了
SqlStdOperatorTable类中, 所以我们只需要将自定义的函数注册进即可javafinal SqlStdOperatorTable sqlStdOperatorTable = SqlStdOperatorTable.instance(); sqlStdOperatorTable.register(DICT_SEX);对, 就这么简单. 因为
SqlStdOperatorTable类是单例模式, 所以我们可以随时随地的进行注册, 其验证逻辑就可以直接调用了当然, 看了其他博客大多数都是继承
SqlStdOperatorTable类实现自定义SqlStdOperatorTable的 如下, 最后使用自己的SqlStdOperatorTable即可javapublic static class SqlCustomOperatorTable extends SqlStdOperatorTable { private static SqlCustomOperatorTable instance; // 只需要申明为成员变量即可, instance.init() 的时候会反射取变量进行注册 public static final SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER)); public static synchronized SqlCustomOperatorTable instance() { if (instance == null) { instance = new SqlCustomOperatorTable(); instance.init(); } return instance; } /** * 如果想修改获取函数的过程, 可以重写此方法 */ @Override protected void lookUpOperators(String name, boolean caseSensitive, Consumer<SqlOperator> consumer) { super.lookUpOperators(name, caseSensitive, consumer); } } -
测试执行
javafinal ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`"); printResultSet(resultSet);输出结果
shellc.l.c.CalciteFuncTest - [printResultSet,86] - Number of columns: 2 c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=男, username=张三} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=李四} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=张铁牛}经测试: 如果udf 和 sqlfunction 同时存在的时候 优先使用udf
4. 完整代码
4.1 udf
java
package com.ldx.calcite;
import com.google.common.collect.Maps;
import com.mysql.cj.jdbc.MysqlDataSource;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.calcite.adapter.jdbc.JdbcSchema;
import org.apache.calcite.config.Lex;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.schema.impl.ScalarFunctionImpl;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Map;
import java.util.Properties;
import static org.apache.calcite.config.CalciteConnectionProperty.LEX;
@Slf4j
public class CalciteFuncWithUdfTest {
private static Statement statement;
@BeforeAll
@SneakyThrows
public static void beforeAll() {
Properties info = new Properties();
// 不区分sql大小写
info.setProperty("caseSensitive", "false");
info.setProperty(LEX.camelName(), Lex.MYSQL.name());
// 创建Calcite连接
Connection connection = DriverManager.getConnection("jdbc:calcite:", info);
CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class);
// 构建RootSchema,在Calcite中,RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下
SchemaPlus rootSchema = calciteConnection.getRootSchema();
// 设置默认的schema, 如果不设置sql中需要加上对应数据源的名称
calciteConnection.setSchema("my_mysql");
final DataSource mysqlDataSource = getMysqlDataSource();
final JdbcSchema schemaWithMysql = JdbcSchema.create(rootSchema, "my_mysql", mysqlDataSource, "test", null);
final SchemaPlus myMysqlSchema = rootSchema.add("my_mysql", schemaWithMysql);
// 全局注册
rootSchema.add("dict_sex", ScalarFunctionImpl.create(Udf.class, "dictSex"));
statement = calciteConnection.createStatement();
// 只注册到mysql schema中
// myMysqlSchema.add("dict_sex", ScalarFunctionImpl.create(Udf.class, "dictSex"));
// 创建SQL语句执行查询
statement = calciteConnection.createStatement();
}
@Test
@SneakyThrows
public void test_udf_func() {
final ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`");
printResultSet(resultSet);
}
private static DataSource getMysqlDataSource() {
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUser("root");
dataSource.setPassword("123456");
return dataSource;
}
public static void printResultSet(ResultSet resultSet) throws SQLException {
// 获取 ResultSet 元数据
ResultSetMetaData metaData = resultSet.getMetaData();
// 获取列数
int columnCount = metaData.getColumnCount();
log.info("Number of columns: {}",columnCount);
// 遍历 ResultSet 并打印结果
while (resultSet.next()) {
final Map<String, String> item = Maps.newHashMap();
// 遍历每一列并打印
for (int i = 1; i <= columnCount; i++) {
String columnName = metaData.getColumnName(i);
String columnValue = resultSet.getString(i);
item.put(columnName, columnValue);
}
log.info(item.toString());
}
}
}4.2 db func
java
package com.ldx.calcite;
import com.google.common.collect.Maps;
import com.mysql.cj.jdbc.MysqlDataSource;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.calcite.adapter.jdbc.JdbcSchema;
import org.apache.calcite.config.Lex;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.sql.SqlBasicFunction;
import org.apache.calcite.sql.SqlFunction;
import org.apache.calcite.sql.SqlOperator;
import org.apache.calcite.sql.fun.SqlStdOperatorTable;
import org.apache.calcite.sql.type.OperandTypes;
import org.apache.calcite.sql.type.ReturnTypes;
import org.apache.calcite.sql.type.SqlTypeFamily;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Map;
import java.util.Properties;
import java.util.function.Consumer;
import static org.apache.calcite.config.CalciteConnectionProperty.LEX;
@Slf4j
public class CalciteFuncWithDbTest {
private static Statement statement;
public static final SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER));
@BeforeAll
@SneakyThrows
public static void beforeAll() {
Properties info = new Properties();
// 不区分sql大小写
info.setProperty("caseSensitive", "false");
info.setProperty(LEX.camelName(), Lex.MYSQL.name());
// 创建Calcite连接
Connection connection = DriverManager.getConnection("jdbc:calcite:", info);
CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class);
// 构建RootSchema,在Calcite中,RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下
SchemaPlus rootSchema = calciteConnection.getRootSchema();
// 设置默认的schema, 如果不设置sql中需要加上对应数据源的名称
calciteConnection.setSchema("my_mysql");
final DataSource mysqlDataSource = getMysqlDataSource();
final JdbcSchema schemaWithMysql = JdbcSchema.create(rootSchema, "my_mysql", mysqlDataSource, "test", null);
rootSchema.add("my_mysql", schemaWithMysql);
final SqlStdOperatorTable sqlStdOperatorTable = SqlStdOperatorTable.instance();
sqlStdOperatorTable.register(DICT_SEX);
statement = calciteConnection.createStatement();
}
@Test
@SneakyThrows
public void test_db_func() {
final ResultSet resultSet = statement.executeQuery("SELECT dict_sex(sex) sex_name FROM `user`");
printResultSet(resultSet);
}
private static DataSource getMysqlDataSource() {
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUser("root");
dataSource.setPassword("123456");
return dataSource;
}
public static void printResultSet(ResultSet resultSet) throws SQLException {
// 获取 ResultSet 元数据
ResultSetMetaData metaData = resultSet.getMetaData();
// 获取列数
int columnCount = metaData.getColumnCount();
log.info("Number of columns: {}",columnCount);
while (resultSet.next()) {
final Map<String, String> item = Maps.newHashMap();
// 遍历每一列并打印
for (int i = 1; i <= columnCount; i++) {
String columnName = metaData.getColumnName(i);
String columnValue = resultSet.getString(i);
item.put(columnName, columnValue);
}
log.info(item.toString());
}
}
public static class SqlCustomOperatorTable extends SqlStdOperatorTable {
private static SqlCustomOperatorTable instance;
// 只需要申明为成员变量即可, instance.init() 的时候会反射取变量进行注册
public static final SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER));
public static synchronized SqlCustomOperatorTable instance() {
if (instance == null) {
instance = new SqlCustomOperatorTable();
instance.init();
}
return instance;
}
/**
* 如果想修改获取函数的过程, 可以重写此方法
*/
@Override
protected void lookUpOperators(String name, boolean caseSensitive, Consumer<SqlOperator> consumer) {
super.lookUpOperators(name, caseSensitive, consumer);
}
}
}