🌟想系统化学习爬虫技术? 看看这个:数据抓取 Python 网络爬虫 - 学习手册-CSDN博客
0x01:WebDriver 类基础属性 & 方法
为模仿用户真实操作浏览器的基本过程,Selenium 的 WebDriver 模块提供了一个 WebDriver 类(表示浏览器),该类中提供了一些诸如打开浏览器、关闭浏览器、刷新浏览器、前进、后退等入门操作的方法和属性:
| 属性 OR 方法 | 解析 |
|---|---|
title |
获取当前页面的标题 |
current_url |
获取当前页面的 URL 地址 |
page_source |
获取当前页面的 HTML 代码(渲染后的) |
get() |
根据指定的 URL 地址访问页面 |
maximize_window() |
设置浏览器窗口最大化 |
forward() |
页面前进 |
back() |
页面后退 |
refresh() |
刷新当前页面 |
save_screenshot() |
截取当前浏览器窗口 |
close() |
关闭当前页面 |
quit() |
关闭浏览器 |
0x02:get() 方法 & page_source 属性
使用 get() 方法可以操作浏览器访问的目标网页,使用 page_source 可以获取当前页面整体的源代码(渲染后的),比如下面的例子,我们尝试访问 taobao.com 并抓取渲染好的页面:
python
from selenium import webdriver
import time
driver = webdriver.Chrome() # 创建浏览器对象
driver.get("https://taobao.com") # 访问淘宝首页
# 因为从访问淘宝到淘宝加载商品数据中间有一段时间,所以我们得强制等待一会,等待页面完全加载
time.sleep(3) # 等待 3 秒
print(driver.page_source) # 打印渲染好的页面
# print(driver.title) # 获取当前页面的标题
# print(driver.current_url) # 获取当前页面的 URL 地址
如上,我们成功抓取了淘宝官网动态加载后的页面数据,只要再结合之前学习的数据提取方法,我们就能够很轻松的从动态页面中抓取我们想要的数据啦。
对于 title 属性与 current_url 属性相信聪明如你一定知道是提取啥的了吧,笔者后面就不特意讲了,如果不知道的话,自己跑跑呗(把上面注释去掉就行)。
0x03:maximize_window() 方法
使用 Selenium 启动浏览器后,浏览器的窗口默认不是以最大化形式显示的,此时通过调用 maximize_window() 方法即可实现浏览器窗口最大化:
python
from selenium import webdriver
import time
driver = webdriver.Chrome() # 创建浏览器对象
driver.get("https://taobao.com") # 访问淘宝首页
# 让浏览器窗口最大化
driver.maximize_window()
0x04:forward()、back()、refresh() 方法
经常用浏览器的你肯定对下面三个小按钮非常熟悉,它们就是后退(←)、前进(→)和刷新按钮:

下面介绍 forward()、back()、refresh() 方法就对应上面那几个功能,下面是一个示例代码:
python
from selenium import webdriver
import time
driver = webdriver.Chrome() # 创建浏览器对象
driver.maximize_window() # 让浏览器窗口最大化
driver.get("https://taobao.com") # 访问淘宝首页
time.sleep(3) # 暂停三秒
driver.get("https://www.baidu.com") # 访问百度首页
time.sleep(3) # 暂停三秒
driver.back() # 模拟回退按钮,回退到淘宝首页
time.sleep(3) # 暂停三秒
driver.forward() # 模拟前进按钮,前进到百度首页
time.sleep(3) # 暂停三秒
driver.refresh() # 模拟刷新按钮,刷新页面对于代码的执行效果,还得是观众老爷自己运行看看(笔者建议是自己敲一遍),这里笔者就不放图了。
0x05:save_screenshot()、close()、quit() 方法
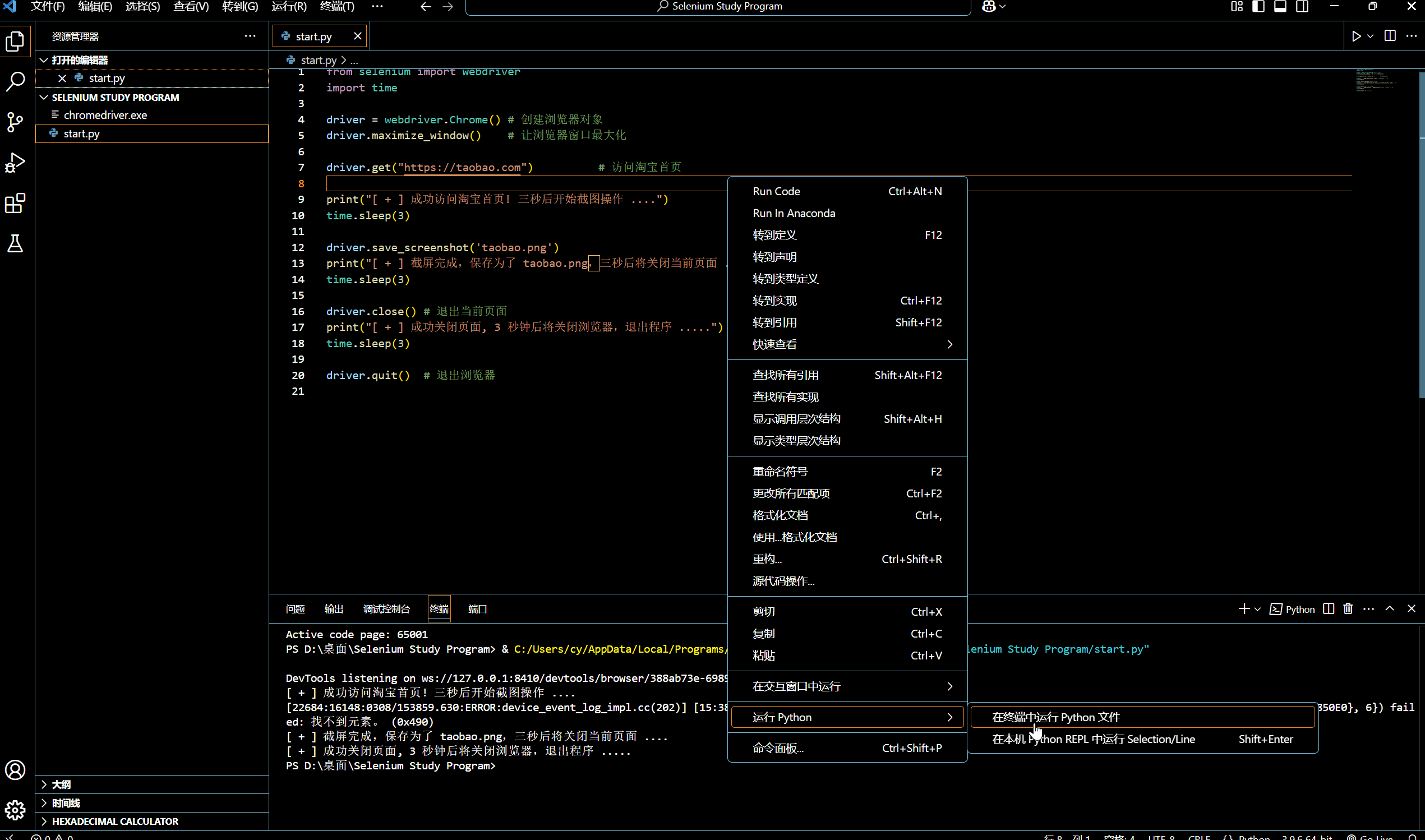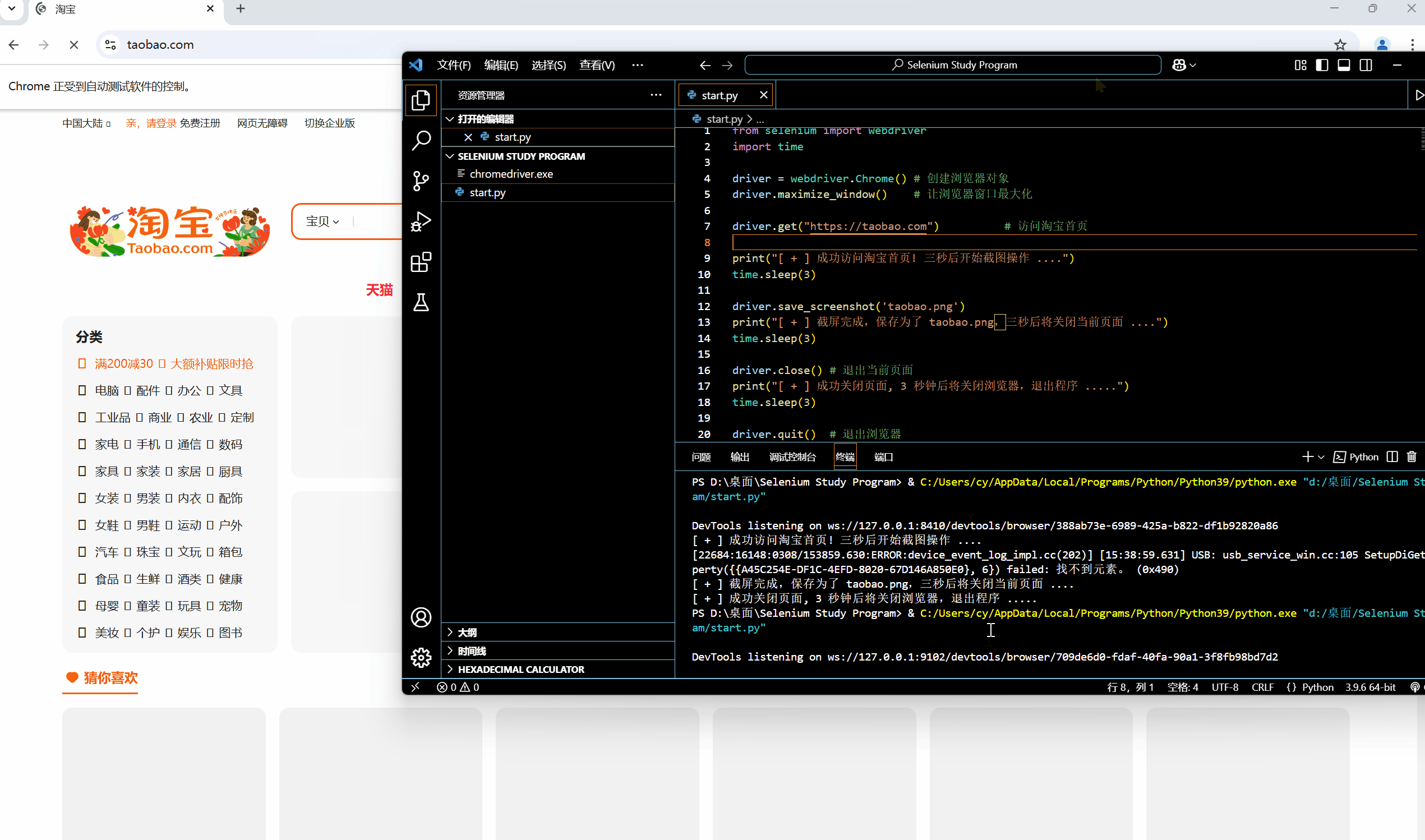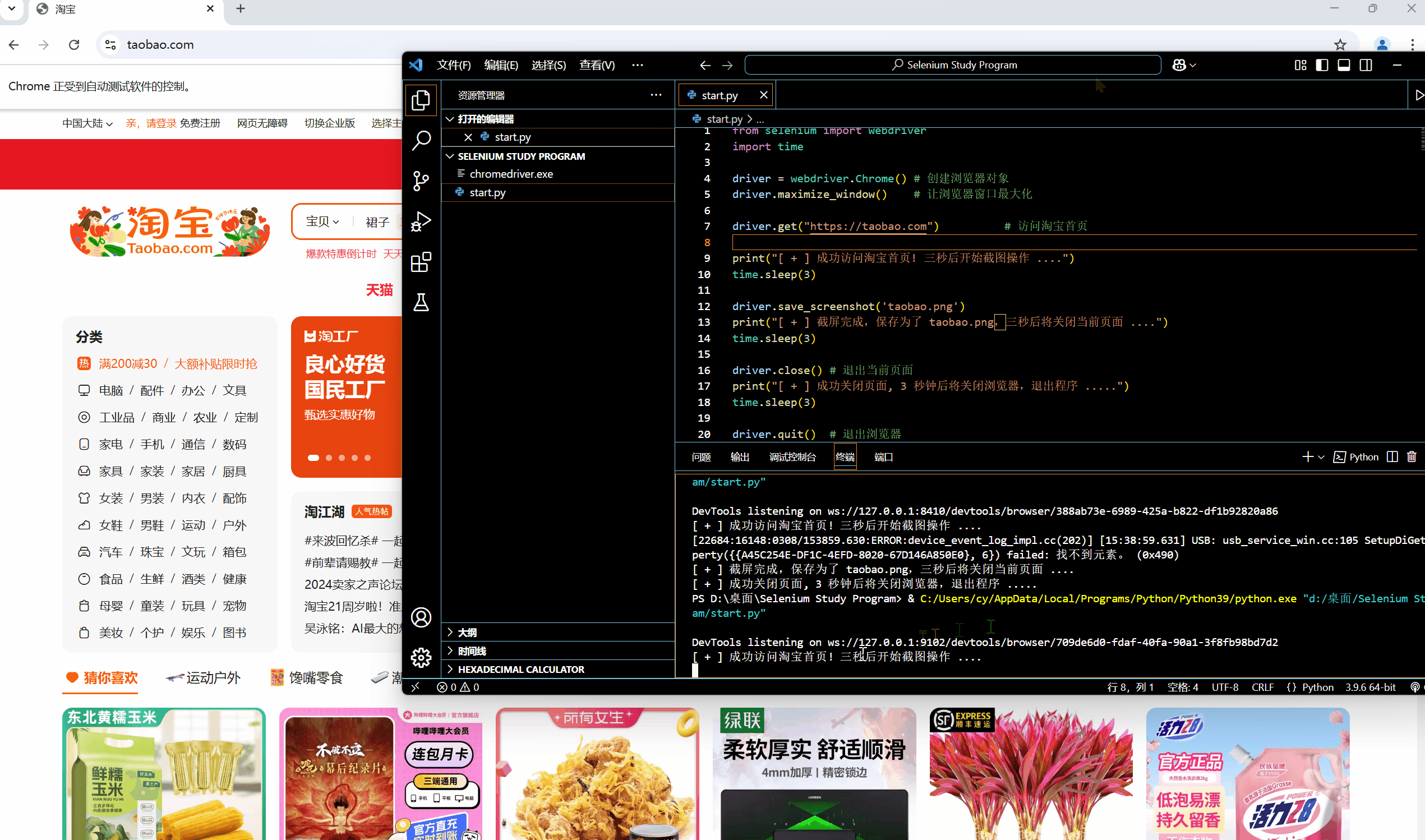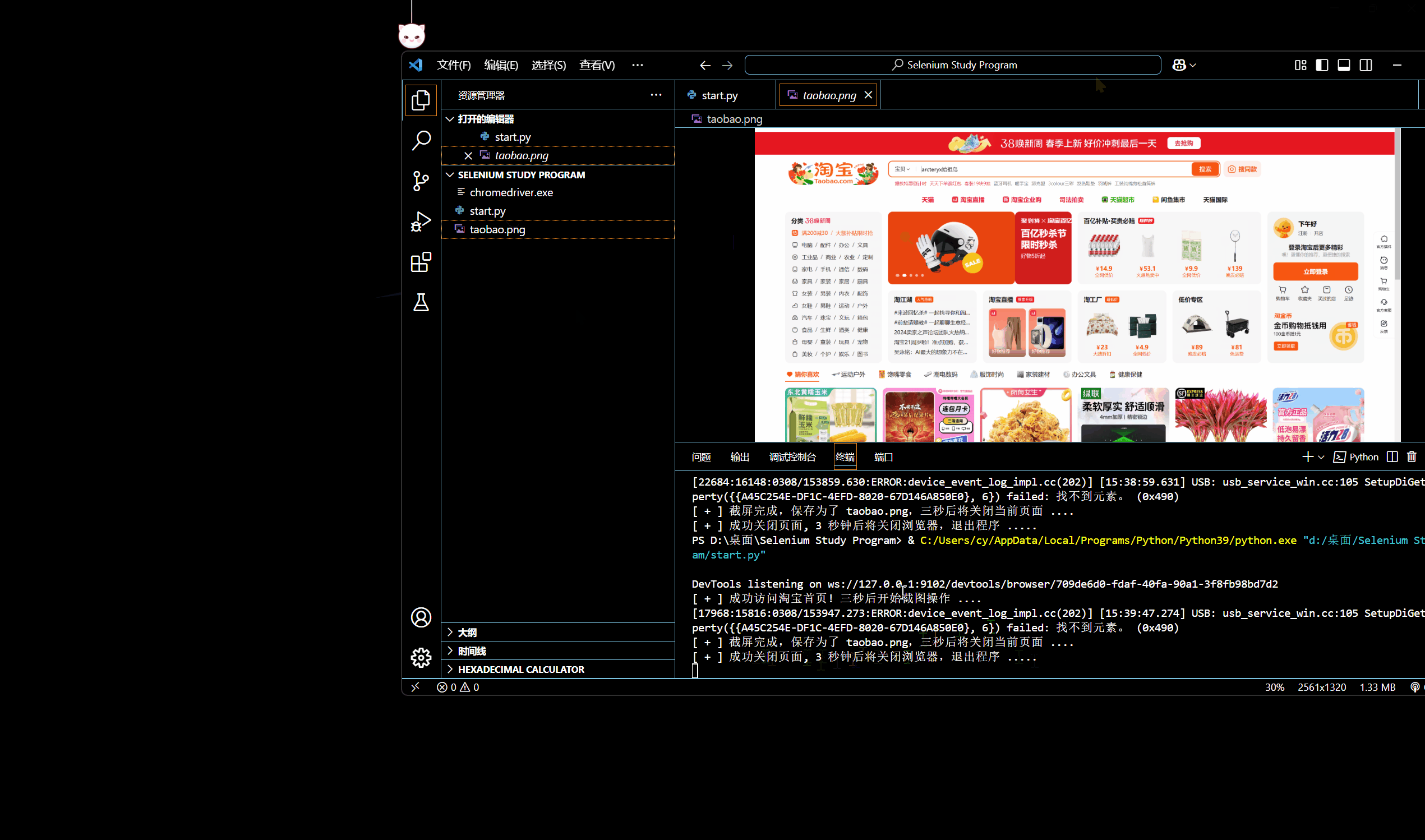
通过 WebDriver 类的 save_screenshot() 放啊我们可以截取当前的窗口并将其保存为 PNG 格式的图像文件,比如下面这个例子,我们尝试截取淘宝首页图片,并保存为 taobao.png:
python
from selenium import webdriver
import time
driver = webdriver.Chrome() # 创建浏览器对象
driver.maximize_window() # 让浏览器窗口最大化
driver.get("https://taobao.com") # 访问淘宝首页
print("[ + ] 成功访问淘宝首页! 三秒后开始截图操作 ....")
time.sleep(3)
driver.save_screenshot('taobao.png')
print("[ + ] 截屏完成,保存为了 taobao.png,三秒后将关闭当前页面 ....")
time.sleep(3)
driver.close() # 退出当前页面
print("[ + ] 成功关闭页面, 3 秒钟后将关闭浏览器,退出程序 .....")
time.sleep(3)
driver.quit() # 退出浏览器