注:本文为 "Linux Bash" 相关文章合辑。
中文引文,未整理。
英文引文,机翻未校。
第一部分:文件操作
1. 清空文件(清除文件大小为 0)
shell
$ > file这行命令使用输出重定向 操作符 >。输出重定向造成文件被打开并写入。如果文件不存在就创建它,若存在就清除文件大小为 0。由于重定向没给文件任何内容,结果就清空了文件。
如果想用一些字符串文本替换文件里的内容,可用如下命令:
shell
$ echo "some string" > file这将 some string 字符串写入文件
2. 追加字符串写入文件
shell
$ echo "foo bar baz" >> file这行命令使用另一个输出重定向 操作符 >> ,意思追加内容到文件。如果文件不存在就创建它并写入。追加 的内容放到文件尾并放到新行(另起一行)。若不想另起一行,可以使用 echo 命令选项 -n ,形如 echo -n 命令:
shell
$ echo -n "foo bar baz" >> file3. 读取文件首行并赋值到一个变量
shell
$ read -r line < file本命令使用内建命令 read 和重定向符 < 。
解释: read 命令从标准输入读取一行文字到 line 变量。-r 命令选项意味着输入保留原始(raw)-- 意思是字符串中的转义字符反斜杠 () 保持原样。重定向命令 < file 意味着标准输入被 file 代替 -- 从 file 文件中读取数据。
read 命令读入字符串会按照 IFS 环境变量设置,删除读取的一行字符串中行首、行尾的分隔符。IFS 表示 间隔符(Internal Field Separator) 的含义。用于命令行扩展分隔单词和断行,默认 IFS 设置为 空格(space)、制表符(tab)、回车换行(newline \n) 。如果想保留这些,可利用 IFS 即时清除设置命令:
shell
$ IFS= read -r line < file上面命令仅限当前命令,并不会改变 IFS 的设置。只用于将文件中的一行文本真正原样读出。
另外的从文件中读出第一行的方法:
shell
$ line=$(head -1 file)上面方法使用命令执行替换 操作符 $(...) ,它执行括号中 ... 的命令返回其输出。本例中,命令 head -1 file 输出文件的第一行,之后赋值给 line 变量。 使用 $(...) 等同于 ... ,故也可写成:
shell
$ line=`head -1 file`然而,$(...) 是优选方法,它简洁,易于嵌套。
4. 一行行地读取文件
shell
$ while read -r line; do
# do something with $line
done < file这是唯一正确的一行行地读取文件的方法。它将 read 命令放到 while 循环中,当 read 命令遇到文件结束,它返回一个非零正数(代码失败),循环结束。
记住 read 命令会删除前导、结尾的分隔符(空格,tab,回车),若想保留分隔符,使用 IFS 即时清除设置命令:
shell
$ while IFS= read -r line; do
# do something with $line
done < file若不喜欢循环语句尾加 < file 重定向操作,也可使用管道命令:
shell
$ cat file | while IFS= read -r line; do
# do something with $line
done5. 从文件中随机读取一行并赋值变量
shell
$ read -r random_line < <(shuf file)这命令对于 bash ,不是一个明晰的从文件随机读取行的方法。因为它需要借助某些外部程序的帮助。在一台运行现代 Linux 的机器上使用来自 GNU 的核心工具 shut 命令。
这条命令使用进程执行 替换操作符 <(...) ,这个进程执行 替换操作创建匿名管道并连接进程执行的输出部分到某个命名管道的写入部分,然后 bash 执行这个进程,这样就把执行进程的匿名管道替换成了命名管道(用设备文件描述符表示)。
当 bash 解析 <(shuf file) 命令部分时,它打开一个特殊的设备文件 /dev/fd/n ,其中 n 是一个未使用的文件描述符,然后运行 shut file 进程并将它的输出连接到 /dev/fd/n,这样 <(shut file) 被替换成 < /dev/fd/n。实际效果如下:
shell
$ read -r random_line < /dev/fd/n这将从这个被行随机化过的文件中读取第一行。
下面是借助 GNU 的 sort 命令完成同样目标的另一解决方案。GNU 的 sort 命令通过 -R 命令选项随机化输入。
shell
$ read -r random_line < <(sort -R file)另外的获取文件中随机一行并赋值变量的方法:
shell
$ random_line=$(sort -R file | head -1)上面命令通过 sort -R 命令随机化文件后,执行 head -1 取出其第一行。
6. 从文件读取一行并分割前 3 个单词赋值给 3 个变量
shell
$ while read -r field1 field2 field3 throwaway; do
# do something with $field1, $field2, and $field3
done < file如果在 read 命令中指定超过一个的变量名,将会把输入字符串分割成符合变量个数的字段(也称域,依据 IFS 设置的分隔符进行分割。默认是空格、tab、回车),之后,把第 1 个字段分配给第 1 个变量,把第 2 个字段分配给第 2 个变量,以此类推。但是,最后一个字段是字符串剩下的全部。这就是我们最后使用一个不用的变量(throwaway)的原因,若没有它,也许 field3 中并不是我们期望的值。
经常我们会用 _ 更短的形式替换 throwaway 做为弃用的变量名:
shell
$ while read -r field1 field2 field3 _; do
# do something with $field1, $field2, and $field3
done < file当然,若你能保证字符串中只包含 3 个字段,你完全可以不安排这个无用的变量名:
shell
$ while read -r field1 field2 field3; do
# do something with $field1, $field2, and $field3
done < file这里有个例子。我们知道,当想知道一个文件内容有多少行、多少单词,多少字符时,在文件上运行 wc 命令,将输出这 3 个数值和文件名,如下所示:
shell
$ cat file-with-5-lines
x 1
x 2
x 3
x 4
x 5
$ wc file-with-5-lines
5 10 20 file-with-5-lines因此,这个文件有 5 行,10 个单词和 20 个字符(空格、回车都算)。我们可使用 read 命令获取这些数值并放到变量中。演示如下:
shell
$ read lines words chars _ < <(wc file-with-5-lines)
$ echo $lines
5
$ echo $words
10
$ echo $chars
20类似地,可以使用 即入字符串(here-strings) 将字符串分割成多个字段赋值给变量。假设有个字符串 "20 packets in 10 seconds" 保存在 $info 变量中,现将 20 和 10 取出放到 2 个变量中。不久前这个任务我写过:
shell
$ packets=$(echo $info | awk '{ print $1 }')
$ duration=$(echo $info | awk '{ print $4 }')然而,若善用 read 命令和 bash 的能力,使用如下一条简单命令可达成目标:
bash
$ read packets _ _ duration _ <<< "$info"这里的 <<< 是 bash 中的一种重定向机制,被称为 即入字符串(here-strings)重定向 操作符,用于直接将一个字符串重定向到标准输入传递给命令。
7. 获取文件大小并赋值变量
shell
$ size=$(wc -c < file)上面的一行命令使用命令执行替换操作符 $(...)(在第 3 段 --3. 读取文件首行并赋值到一个变量 -- 中已讲过)。本命令中将 wc -c < file 执行结果,即得出的 file 的大小赋值给变量 size 。(译注: 思考并实验这里为什么使用 wc -c < file 而不使用 wc -c file ?)
8. 从全路径字符串中取出文件名
让我们看个例子,假设有个 "/path/to/file.txt" 字符串表示文件的全路径,只想取出其中的文件名 file.txt ,该如何做呢? 一个好的解决方案使用 bash 外壳程序的 参数展开(parameter expansion) 机制。演示如下:
c
$ pvar = "/path/to/file.txt"
$ filename=${pvar##*/}如上命令,使用形如 ${varname##pattern} 的参数展开 操作符。这个展开操作试图从 $varname 变量表示的字符串开始按 pattern 进行模式匹配,若匹配成功,将从 $varname 字符串删除掉匹配的子字符串后的剩余部分返回。(删除匹配)
上面例子的情况 */ 模式将在 "/path/to/file.txt " 中 从头到尾 匹配任意字符后跟 '/' 的模式,由于 */ 是贪心匹配,故匹配结果是 /path/to/ 。按照展开逻辑,表达式将返回 删除匹配 的子串,所以,变量 $filename 将等于 file.txt 。(其中 ## 表示 从头到尾 开始模式匹配)
9. 从全路径字符串中取出目录名
与前一任务命令相似,这次让我们从 "/path/to/file.txt" 中取出目录名 /path/to/ 子串。同样使用 参数展开 操作,命令如下:
c
$ pvar = "/path/to/file.txt"
$ dirname=${pvar%/*}这次 ${varname%pattern} 的参数展开 操作是 从尾到头 的匹配模式(其中 % 表示 从尾到头 开始模式匹配)。
例子中,,模式为 /* 。从尾到头 匹配后,匹配结果为 /file.txt 。将匹配删除后的结果为 /path/to 。
10. 快速创建文件副本
让我们看一下将 /path/to/file 表示的文件,在同目录下拷贝一个副本命令。通常你会写成如下命令:
bash
$ cp /path/to/file /path/to/file_copy然而,你可以使用 大括号展开 机制,命令写成如下简短形式:
bash
$ cp /path/to/file{,_copy}大括号展开 机制是将大括号中的每个条目依次展开(枚举每个条目)。例子中 /path/to/file{,_copy} 将会被展开成 /path/to/file /path/to/file_copy ,整个命令将变成 cp /path/to/file /path/to/file_copy 。
相似地,可以快速移动(改名)一个文件,如下命令:
bash
$ mv /path/to/file{,_old}命令展开成 mv /path/to/file /path/to/file_old。
第二部分:字符串操作
1. 创建输出字母表
bash
$ echo {a..z}以上命令使用 bash 的 大括号展开(brace expansion) 机制,其含义是生成「字面字符串」序列(枚举每个条目)。此例中表达式是 {x...z} ,其中 x 和 z 是单个字符,这个表示字母表中从 x 到 z 的所有字符(包含 x 和 z)(注意:x 和 z 之间是 2 个 . 符号)。
若运行以上命令,其输出 a-z 的所有字母:
bash
$ echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z2. 无空格分隔输出字母表中字母
shell
$ printf "%c" {a..z}这个神奇的 bash 技巧 99.99% 的使用者不知道。如果把一个列表传递个 printf 命令, printf 命令会循环依次处理列表的每个条目,循环结束,命令退出。这是一个极佳的技巧。
以上命令使用 "%c" 作为 printf 命令的格式输出控制符。(与 C 语言中函数类似)它将列表序列中的字母依次输出。
下面是命令运行输出结果:
shell
abcdefghijklmnopqrstuvwxyz这个输出后没有回车,因为列表序列中不包含回车符( '\n' )。加入行终止,只需在字符序列尾加入回车符,方法是在列表序列表达式尾加上 $'\n' ,命令如下:
shell
$ printf "%c" {a..z} $'\n'$'\n' 是 bash 方便表示,代表回车符。命令输出 {a...z} 后,接着输出回车符。(注意:printf 类似 C 语言中的 printf 函数,接受可变参数)。
另一方法使用 echo 命令输出 printf "%c" {a..z} 命令结果。这里使用了命令执行替换机制(第一篇文讲解过)。命令如下:
shell
$ echo $(printf "%c" {a..z})如上命令,使用命令执行替换(command substitution)输出字母表传递给 echo 命令输出, echo 命令默认在命令后输出回车。
想以列方式输出字母?在 printf 命令的格式输出控制中加入回车符!
shell
$ printf "%c\n" {a..z}
a
b
...
z想将 printf 命令展开的列表赋值给变量?使用 -v 命令选项:
shell
$ printf -v alphabet "%c" {a..z}这将 "abcdefghijklmnopqrstuvwxyz" 字符串赋值给 $alphabet 变量。
类似地,可创建整数列表序列,我们试验一下从 1 到 100 :
bash
$ echo {1..100}输出:
bash
1 2 3 ... 100也可使用 seq 命令工具创建数字序列,替换上述的方法:
bash
$ seq 1 1003. 给 0 到 9 数字序列中每个数加前导 0
bash
$ printf "%02d " {0..9}这里我们再次使用 printf 命令的循环能力。 这次 printf 的格式控制字符串是 ""%02d" ,它的意思是输出的数字以 0 前导补足数字到 2 位。后面的命令参数通过大括号展开传递进来从 0 到 9 的数字。
输出:
bash
00 01 02 03 04 05 06 07 08 09如果使用的 bash 版本大于 4,也可使用下面的大括号展开表达式:
shell
$ echo {00..09}老的 bash 版本没有这个特性。
4. 生成 30 个英语单词
bash
$ echo {w,t,}h{e{n{,ce{,forth}},re{,in,fore,with{,al}}},ither,at}上面的命令是对大括号展开(brace expansion) 机制滥用(也能很好理解它)。来看看它的输出:
shell
when whence whenceforth where wherein wherefore wherewith wherewithal whither what then thence thenceforth there therein therefore therewith therewithal thither that hen hence henceforth here herein herefore herewith herewithal hither hat太神奇了!
它怎样做到的!在 大括号展开 机制中,在大括号中的每个被逗号 , 分隔的条目都可以分别交叉放置。例如,如果像下面的命令:
bash
$ echo {a,b,c}{1,2,3}上面的大括号表达式将会产生 a1 a2 a3 b1 b2 b3 c1 c2 c3 ,其首先使用第 1 个大括号中的 a 依次和第 2 个大括号中的 1,2,3 组合,构成 a1 a2 a3 ,接着使用第 1 个大括号中的 b 依次和第 2 个大括号中的 1,2,3 组合,构成 b1 b2 b3 ,接着是 c 。(矩阵乘的概念)
所以,上面生成单词的命令就会构成上面那些单词的输出!
5. 生成 1 个字符串的 10 个副本
bash
$ echo foo{,,,,,,,,,,}上述命令再次使用大括号展开机制。前面的字符串 foo 和后面的 10 个条目都为空的列表的每个条目组合,形成字符串 foo 的 10 个副本:
shell
foo foo foo foo foo foo foo foo foo foo foo6. 合并连接 2 个字符串
shell
$ echo "$x$y"这条命令简单合并连接 2 个变量,如果 x 变量包含字符串 foo ,且 y 变量包含字符串 bar ,结果为 foobar 。
注意命令中 " x x xy" 是被双引号括住的。若不括住它,echo 命令会优先将 x x xy 变量中的值解释为命令行参数或命令选项。因此,若 $x 变量的值与命令行参数或命令选项相同(以 - 开始的字符等),将被按命令参数或命令选项解释,使结果不能按我们的意愿输出:
bash
x=-n
y=" bar"
echo $x$y输出:
shell
foo相反,合并连接 2 个字符串方法:
shell
x=-n
y=" foo"
echo "$x$y"输出:
shell
\-n foo若想合并连接 2 个字符串赋值到另一个变量,就不必要使用双引号括住:
bash
var=$x$y7. 以指定字符分割字符串
若有个字符串变量 $str ,其值为 foo-bar-baz ,你想把它按横杠符 - 分割成 3 个字符串。可以使用 IFS 和 read 命令的组合:
shell
$ str=foo-bar-baz
$ IFS=- read -r x y z <<< "$str"这里,使用 read x y z 命令读取进入的数据并将它分割成 3 个变量,使用 IFS=- 命令行即时设置分隔符为 - ,read 命令选项 -r 表示保持原样。
这行命令结果将使 x ∗ ∗ 被赋值 ∗ ∗ f o o ∗ ∗ , ∗ ∗ x** 被赋值 **foo** , ** x∗∗被赋值∗∗foo∗∗,∗∗y 被赋值 bar , $z 被赋值 baz 。
另外注意 <<< 是 即入字符串(here-string) 的操作符,其使一个字符串重定向为标准输入。这里,$str 变量的字符串做为了 read 命令的输入。
也可把分割开的变量放到一个数组变量中:
bash
$ IFS=- read -ra parts <<< "foo-bar-baz"命令 read 的 -a 命令选项意味着将分割的字符串赋值给数组变量 parts ,之后,可通过 ${parts[0]},${parts[1]} 分别访问数组中的元素,也可使用 ${parts[@]} 访问所有元素。(译注:若直接使用 ** p a r t s ∗ ∗ 将访问 ' parts** 将访问 ` parts∗∗将访问'{parts0}` 即变量中的第 1 个元素。自己实践验证)
8. 依次处理字符串中的字符
bash
$ while IFS= read -rn1 c; do
# 对变量 $c 即字符串中的字符操作
done <<< "$str"这里使用 read 命令选项 -n1 一次从输入字符串中读 1 个字符处理。类似地可以使用 n2 命令选项指示一次从输入字符串中读 2 个字符进行处理等:
9. 在字符串中用 "bar" 替换 "foo"
bash
$ str=baz-foo-bar-foo-foo
$ echo ${str/foo/bar}
baz-bar-bar-foo-foo命令 echo ${str/foo/bar} 使用 bash 的参数展开机制,它在 $str 中找到 foo 最开始出现位置并将其用 bar 替换。很简单吧!
用 bar 替换所有出现的 foo ,如下命令表达式:
shell
$ echo ${str//foo/bar}
baz-bar-bar-bar-bar10. 检查一个字符串模式匹配
shell
$ if [[ $file = *.zip ]]; then
# 执行一些操作
fi这里如果 $file 变量的字符串值模式匹配 .zip (包含 .zip 子字符串)。这是个简单的模式匹配。通配符 ***** 表示匹配任意数量的任意字符(包括空白符),通配符 ? 匹配任意单个字符, ... * 表示匹配 \[\] 中的任一字符。(参考 bash 手册中的文件名展开的模式匹配)
下面是另一个例子,判断屏幕回答是 Y 或 y 开始的字符串:
bash
# read answer
$ if [[ $answer = [Yy]* ]]; then
# 执行一些操作
fi11. 判断一个字符串匹配正则表达式
shell
$ if [[ $str =~ [0-9]+.[0-9]+ ]]; then
# 执行一些操作
fi以上命令以扩展正则表达式 0-9+.0-9+ 判断变量 $str 是否匹配。正则表达式 0-9+.0-9+ 含义,匹配 数字 +1 个任意字符 + 数字 的组合。详见手册 man 3 regex 命令。(译注:命令中双目运算符 =~ 等同 == ,只表示使用扩展正则表达式,前面例子中的 = 等同 == 是为与 POSIX 规范兼容)
12. 获取字符串长度
bash
$ echo ${#str}这里利用参数展开机制,KaTeX parse error: Expected '}', got '#' at position 2: {#̲str}** 表示返回变量 *...str 值的长度,非常简单!(译注:前面第 7 节的例子中,有个数组变量 ** p a r t s ∗ ∗ ,若执行命令 ' parts** ,若执行命令 ` parts∗∗,若执行命令' echo ${#parts}` 将返回数组元素个数,输出 3 )
13. 从字符串中按位置取出子串
bash
$ str="hello world"
$ echo ${str:6}以上命令从字符串 "hello world" 中取出子串 "world" 。它使用子字符串展开机制。更一般的形式 ${var:offset:length} ,注意:1. 字符串位置以 0 开始记,故例子中 offset 值 6 指向字符 w 。2. 若省略 length 将从位置 取到字符串尾。
下面是另一个例子:
shell
$ echo ${str:7:2}输出:
bash
or14. 大写化字符串
bash
$ declare -u var
$ var="foo bar"bash 的 declare 命令声明一个变量的同时也可赋予变量一些特性。本例中,通过命令选项 -u 使声明的变量 var 的值大写化。意味着之后无论给 var 变量赋值什么字符串,都将自动全部变成大写:
bash
$ echo $var
FOO BAR注意命令选项 -u 在 bash 版本 4 之后引入。类似地可以使用 bash 4 的另一参数展开特性完成大写转换的功能,形如: ${var^^} 表达式:
shell
$ str="zoo raw"
$ echo ${str^^}输出:
bash
ZOO RAW15. 小写化字符
shell
$ declare -l var
$ var="FOO BAR"类似于 -u 命令选项, 选项 -l 对于 declare 命令是使变量 var 小写化:
shell
$ echo $var
foo bar选项 -l 也同样是在 bash 版本 4 之后有效。
另一方法使用形如 ${var,,} 的参数展开表达式使 var 变量值转换小写:
bash
$ str="ZOO RAW"
$ echo ${str,,}输出:
shell
zoo raw第三部分:重定向
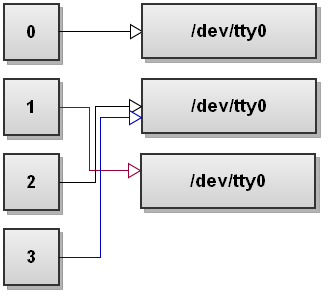
当你理解了 文件描述符(file descriptors) 的操作,将会觉得使用 bash 的重定向非常简单。当 bash 启动时,它将默认打开 3 个标准文件描述符 :stdin(0 号文件描述符) ,stdout(1 号文件描述符) ,stderr(2 号文件描述符) 。你可以打开更多的文件描述符(诸如:3 ,4 ,5 ... ),也可以关闭它们,你可以拷贝文件描述符 ,也可以从它那里读或写入到它。
文件描述符 总是指向某些文件(除非文件被关闭)。通常,bash 启动时会把 3 个标准文件描述符:stdin,stdout,stderr 通通指向终端。输入(stdin)来自终端的键入内容,所有的输出(stdout,stderr)显示在终端里。
假定你的终端是 /dev/tty0 ,下面是终端 与标准文件描述符之间的关系示意图:
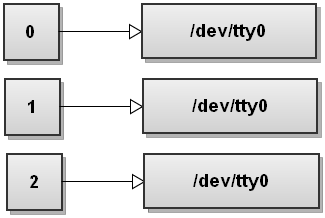
当 Bash 执行一条命令时,它会 分支(fork) 一个子进程,这个子进程继承 fork 它的父进程的一切标准文件描述符(关于 fork ,详情参考手册命令 man 2 fork )。首先按照命令行指示进行 重定向输入 / 输出 后才 执行(exec) 命令(关于 exec ,详情参考手册命令 man 3 exec)。
对于想 bash 重定向 操作进阶的你,永远心中有个蓝图 -- 当重定向发生时,标准文件描述符如何变化 --,这个蓝图将极大地帮助到你。
1. 重定向标准输出到一个文件
shell
$ command >file符号 > 是输出重定向操作符。bash 先尝试打开重定向指向的文件(这里是文件 file )并可写入,如果成功,Bash 将 command 命令子进程的标准输出文件描述符指向打开的文件。如果失败,整个命令失败退出,结束子进程。
命令行 command >file 等同于命令行 command 1>file 。数字 1 代表 stdout ,它是标准输出文件描述符 stdout 的文件描述符号。
下面是标准文件描述符改变的蓝图示意。Bash 打开文件 file 并确定可写入后,替换子进程的标准输出文件描述符 1 为 file 文件的文件描述符,自此,命令的所有输出将写入文件 file 中。
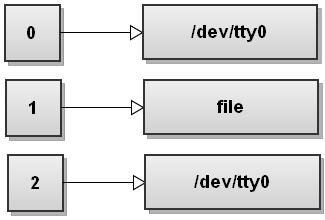
通常,你可使用形如 "command n >file" 的命令,表示此命令的 n 号标准输入 / 输出文件描述符指向 file 。
举例:
bash
$ ls > file_list重定向 ls 命令的输出到 file_list 文件(命令的输出写入到文件)。
2. 重定向命令的标准错误输出到文件
shell
$ command 2> file这里,将命令的标准错误输出(stderr 号 2)文件描述符重定向到文件。这里的数字 2 代表标准错误输出文件描述符。
下面是标准文件描述符表改变蓝图:
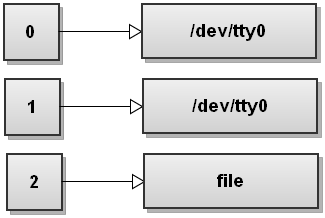
Bash 打开文件 file 并确定可写入后,替换子进程的标准错误输出文件描述符 2 为 file 文件的文件描述符,自此,命令的所有错误输出由原来写入 stderr 中改写入文件 file 中。
3. 重定向标准输出和标准错误输出到文件
shell
$ command &>file上面这行命令中 "&>" 表示把所有的标准输出文件描述符(stdout 和 stderr )重定向到 file 文件描述符。&> 是 Bash 快速引用所有标准输出描述符(1 和 2)的简写。
下图是标准文件描述符改变示意图:
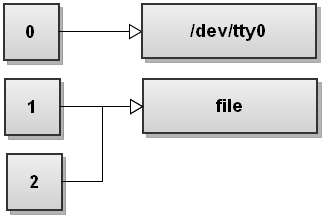
这里你看到所有的标准输出( stdout 和 stderr )都指向 file 文件的文件描述符。
有不同的几个方法将所有标准输出重定向到一个目标。可以按顺序一个接一个地重定向:
shell
$ command >file 2>&1上面命令是较通用的重定向所有标准输出到文件的方法。首先,标准输出(stdout)重定向到 file 文件(这步是先运行 ">file " 的结果)。之后,标准错误输出(stderr)重定向到 已重定向过的 stdout (&1) 上 (通过 "2>&1") 。因此,所有的标准输出都重定向到 file 上。
Bash 在命令行解析时,发现有多个重定向操作时,按从左到右的顺序依次解释处理。让我们按 Bash 执行顺序,单步分析,更好地理解它。一开始,Bash 在执行命令前,其 3 个标准输入 / 输出文件描述符都指向终端。示意图如下:
首先,Bash 处理第一个重定向 ">file" 。之前,我们见过这个示意图。它的标准输出(stdout)指向终端:
下一步解释处理重定向操作 "2>&1",这个操作的含义是使标准错误输出文件描述符(stderr 号 2)成为 1 号标准输出文件描述符(stdout)的副本(重定向 2 到 1 的当前引用)。我们得到如下示意图:
所有的标准输出描述符都重定向到 file 文件。
然而,小心不要把 command >file 2>&1 写成 command 2>&1 >file ,它们是不同的!
Bash 对重定向指令的顺序敏感!后一命令仅仅把标准输出 1(stdout) 重定向到 file 文件,而 标准输出 2(stderr) 仍然输出到终端。理解为什么,让我们再进行单步分析,看看发生了什么。初始示意图如下:
Bash 从左到右一步步处理重定向,首先遇到 "2>&1 " ,因此将 2 (stderr) 重定向与 1(stdout) 相同,即都指向终端,示意图如下:
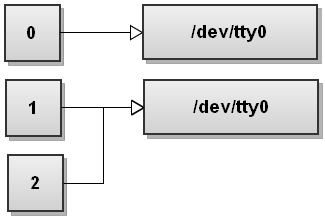
现在,Bash 看到第 2 个重定向操作符 ">file " ,它重定向 1(stdout) 到 file 文件,示意图如下:
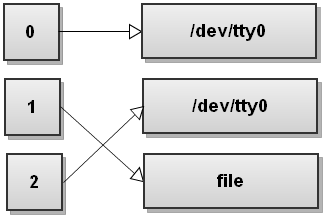
看到了什么,1(stdout) 重定向到了 file 文件,但 2(stderr) 仍指向终端,所有写到 stderr 的都显示到屏幕。所以,在使用重定向时,要非常非常小心给出它的操作循序!
另外在 Bash 中要注意:
shell
$ command &>file操作含义,与下面命令形式完全相同:
shell
$ command >&file但推荐第一种形式写法。
4. 舍弃命令的屏幕输出
bash
$ command > /dev/null特殊文件 /dev/null 抛弃所有写入它的内容(译注:可认为 /dev/null 是一个大小恒为 0 的文件,向它写入任何内容,它都会将它清空,保持文件大小为 0 。把它拷贝覆盖已有文件的动作也是把文件内容清空的方法)。下面是标准文件描述符示意图:
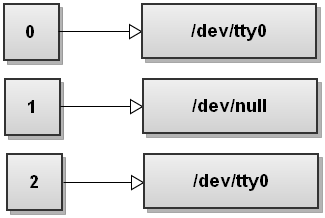
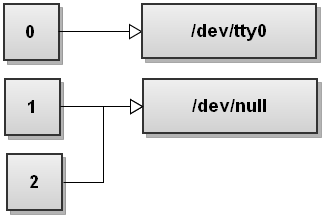
类比地,组合之前学过的命令,我们可以舍弃命令的输出和错误输出,命令如下:
shell
$ command >/dev/null 2>&1或简写成:
shell
$ command &>/dev/null相应的标准输入输出描述符示意图如下:
5. 重定向文件内容作为命令的输入
shell
$ command <file这里, Bash 在执行命令前,试图打开 file 文件并可读。若打开文件失败,命令失败退出。若打开读取文件成功,将使用打开的文件描述符作为命令的标准输入描述符(stdin 号 0)。
上述动作完成后的标准输入输出描述符表示意图如下:
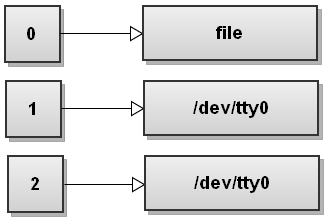
下面是个例子,假定你想从 file 中读取其第 1 行赋值给变量,命令如下:
shell
$ read -r line < fileBash 的内建命令 read 从标准输入读取单行数据。 使用输入重定向操作符 < 使它从 file 文件中读取第 1 行数据。
6. 重定向多行文本到命令的输入
shell
$ command <<EOL
>你
>多行
>文本
>输入
>到这儿
>EOL不是唯一文字
> EOL
>EOL这里,我们使用 即入文档(here-document) 重定向操作符 "<<MARKER " 的功能。这个操作指示 bash 从标准输入(stdin 0)读取多行输入,直到某行(最后一行)只包含 MARKER 且无前导空白即退出输入。最后一行的终止输入标志不会附加到输入中。将最终的多行输入给命令。
下面是个一般的例子。假设你拷贝了一堆的网上的网址(URLs)在系统剪贴板里,你想去掉所有的前缀 http:// ,快速的单行命令如下:
bash
$ sed 's|http://||' <<EOL
http://url1.com
http://url2.com
http://url3.com
EOL这里使用即入文档重定向符,将多行网址记录输入给 sed 命令,"sed " 命令使用正则表达式将所有行记录中的 http:// 删除。
以上例子输出:
shell
url1.com
url2.com
url3.com7. 重定向单行字符串文本到命令输入
shell
$ command <<< "foo bar baz"举个例子,假如你想系统剪贴板里的文本当作某个命令的输入(文本是命令的参数或选项),可能的办法是:
shell
$ echo "粘帖剪贴板内容" | command现在你可以使用下面命令:
shell
$ command <<< "粘帖剪贴板内容"当我学会这个技巧,它改变了我的人生!
8. 重定向所有的错误输出到一个文件
shell
$ exec 2>file
$ command1
$ command2
$ ...上述第一个命令行使用了 Bash 内建命令 exec 的功能,如果使用它重定向了标准输入输出(演示中是 2 号标准输出 stderr ),它在本 shell 中永久有效!除非你再次修改它或退出这个 shell 。
例子中,使用 exec 2>file 命令将 2 号标准输出(stderr)重定向到 file 文件。之后,在这个 shell 环境里所有命令的标准错误输出都重定向到 file 文件中。这是非常有用的一个技巧。当你想把所有命令或脚本中的运行记录到一个日志文件里,而又不想在每条命令中都繁琐地输入重定向操作。
概括地讲,exec 命令的主要功能是不创建子进程地调用一个 bash 命令或脚本并执行,若命令行中指定了命令或脚本,当前 shell 将被替换。我们演示的命令,在 exec 后并未给出任何命令,这仅仅利用了 exec 的执行重定向的功能,并无 shell 被替换。(译注:个人觉得 exec 是个较分裂的命令。推荐参考这个 链接 中对 exec 命令的解释。或直接看这个 AskUbuntu 中的回答)
9. 创建用户的文件描述符做为自定义的输入描述符
bash
$ exec 3<file这里,我们再次使用 exec 命令进行重定向的设置,指定 3<file 的意思是打开 file 文件可读取,并将其分配给当前 shell 的 3 号输入文件描述符。当前 shell 的输入输出文件描述符示意图如下:
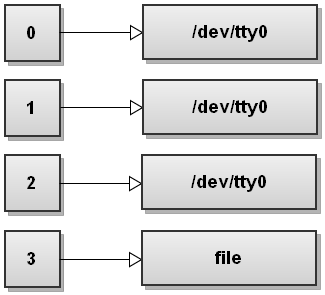
现在就可以从 3 号输入文件描述符读取,如下命令:
shell
$ read -u 3 line上面的命令从 3 号输入文件描述符(重定向到 file 文件)中读取。
或用常规命令,诸如 grep 操作 3 号输入文件描述符:
shell
$ grep "foo" <&3这里,3 号输入文件描述符通过重定向代替了 grep 命令的默认 stdin 输入。一定要记住,资源有限,故使用完用户自打开的文件描述符后,要及时关闭它,释放描述符号。可以再次使用。
使用完 3 号文件描述符后,可以关闭它,使用如下命令:
shell
$ exec 3>&-这里似乎 3 号文件描述符被重定向给 &- 实际上,&- 就是 关闭这个文件描述符 的一种语法。
10. 创建用户的文件描述符做为自定义的输出描述符
shell
$ exec 4>file这里,简单地指示 bash 打开可写 file 文件,并将其文件描述符重定向成为 4 号输出描述符。当前 shell 的输入输出文件描述符示意图如下:
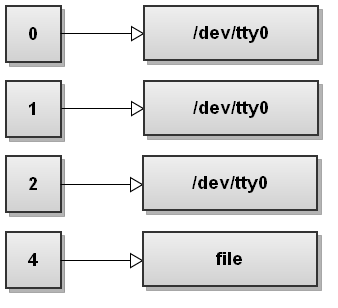
正如你在上图所见,输入输出文件描述符并未按顺序来,用户可自由指定 0 只 255 之间的数字做为自定义打开的文件描述符号。
现在,简单往 4 号输出文件描述符中写入:
bash
$ echo "foo" >&4同样,可以关闭 4 号输出文件描述符:
bash
$ exec 4>&-学会使用自定义输入输出文件描述符,一切都是那么简单!
11. 打开文件用于读写
shell
$ exec 3<>file这里使用 bash 的菱形操作符 <> ,菱形操作符打开 file 文件用于读写。
所以,可以执行如下例子:
shell
$ echo "foo bar" > file # 将字符串 "foo bar" 写入 file 文件。
$ exec 5<> file # 以读写方式打开 file 文件并重定向到5号描述符
$ read -n 3 var <&5 # 从5号输入输出描述符中读取前3个字符。
$ echo $var上面最后命令将输出 "foo" ,只读出前 3 个字符。
也可写一些内容到 file 文件:
shell
$ echo -n + >&5 # 在文件中第4字符位置写入 "+"
$ exec 5>&- # 关闭5号文件描述符
$ cat file上面会输出 foo+bar 。(译注:实践发现以永久重定向文件描述符读写文件,会保持读写位置)
12. 多个命令输出重定向到文件
shell
$ (command1; command2) >file上面例示使用 (commands) 运行命令操作,其中 bash 会将 () 中的命令在一个创建的子进程中运行。
所以这里的 command1 和 command2 运行在当前 shell 的子进程,同时,bash 将他们的输出重定向到 file 文件。
13. 通过文件 shell 之间传递命令执行
打开 2 个 shell 模拟终端,在第 1 个 shell 中,输入命令:
shell
$ mkfifo fifo
$ exec < fifo在第 2 个 shell 中,输入命令:
shell
$ exec 3> fifo; echo 'echo test' >&3现在看第 1 个 shell ,发现 echo test 命令执行输出在第 1 个 shell 里。你可以在第 2 个 shell 中发送命令字符串给 3 号描述符的方式给第 1 个 shell 发送命令。
下面讲解它是如何做到的。
在 shell 1 中,使用 mkfifo 创建 命名管道 -- fifo 。一个命名管道(也称为 FIFO)性质与一般的管道相同,除了它是通过系统文件系统访问之外(创建命名管道将会在当前目录下创建一个以命名管道名命名的文件,这个文件第一个属性为 p 表示它为一个 管道(pipe) ,并且文件大小始终显示为 0)。它可供多进程读写(可供进程间通讯)。当进程间通过 FIFO -- 命名管道 -- 交换数据时,系统内核并不会把数据写入文件存储系统。因此,命名管道文件大小永远为 0 。仅仅把文件系统中的文件名做为进程引用它的一个名称罢了。
下一命令 exec < fifo 重定向 shell 1 的输入为 fifo 。
接着,shell 2 重定向这个命名管道做为用户输出文件描述符,并分配号为 3 。然后给 3 号输出发送字符串 echo test ,这将传给 fifo 文件。
因此,shell 1 连接到 fifo 的标准输入进入 shell 1 命令行并执行!很容易吧!
(译注:原理很简单,自己开两个 shell 去实践练习一下。别的不多说,只提醒一点:当 shell 1 把自己的标准输入重定向成命名管道之后,它就不能接受它自己终端的输入了。如何恢复它回到原始的输入?2 个办法,1. 是重定向前备份。2. 是使用它原始的名称恢复,提示:输入仅可用 /dev/tty 。至于怎样让它执行命令?自己想想,你棒棒哒!)
14. 通过 bash 访问网站
shell
$ exec 3<>/dev/tcp/www.bing.com/80
$ echo -e "GET / HTTP/1.1\n\n" >&3
$ cat <&3Bash 处理 /dev/tcp/host/port 作为特殊文件。它不需要在你的文件系统中存在。这个只为 Bash 通过它打开指定主机的网络接口。
以上例子,首先打开可读写 3 号输入输出文件描述符指向 /dev/tcp/www.bing.com/80 ,它将链接到 www.bing.com 网站的端口 80 。
下一步,向 3 号文件描述符写入 'GET / HTTP/1.1\n\n ' (发送 HTTP 请求),然后使用 cat 命令简单读取 3 号文件描述符的内容。
类似地,你可以通过 /dev/udp/host/port 创建特殊文件用于 UDP 连接。
使用 /dev/tcp/host/port 的方法,你甚至可以在 Bash 中写出端口扫描的命令或脚本!
(译注:原文示例使用的是谷歌,我这里换成了必应。实验了一下,可能由于现在网站都使用 SSL 的缘故,第一次会获得一个包含错误提示的 HTTP 响应内容,连接就关闭了)
15. 当重定向输出时阻止写入已有文件
shell
$ set -o noclobber上面的命令打开当前 shell 的 noclobber 选项。这个选项阻止当前 shell 使用重定向 '>' 操作覆盖写入已有的文件。
如果你输出重定向的文件是一个已有文件,将会得到一个错误提示:
shell
$ > exFile
$ echo test > exFile
bash: exFile: cannot overwrite existing file
#bash: exFile: 不能覆写已有文件如果你完全确定就是要覆盖写入已有文件,可以使用 >| 重定向符:
bash
$ echo test >| exFile
$ cat exFile
test这个操作符成功超越 noclobber 选项。
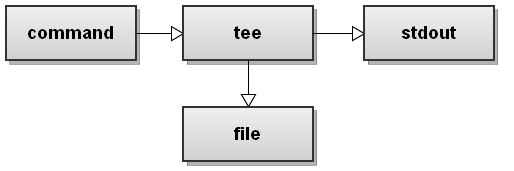
16. 将输入重定向到一个文件和输出到标准输出
shell
$ command | tee file这个 tee 命令超级方便,虽然它不是 bash 的内建命令但很常用。它能把收到的输入流输出到标准输出和一个文件中。
如上例子,它将 command 命令的输出分别输出到 shell 屏幕和一个文件。
下面是它工作原理示意图:
17. 将一个处理进程(命令)的输出重定向到另一个处理进程(命令)的输入
shell
$ command1 | command2这是简单的管道。我确定每个人都熟悉它。我放它到这里只是为了教程的完整。仅仅提醒你,管道 的本质就是将命令 command1 的 输出 重定向到 command2 命令的 输入 。
可以用图示意如下:
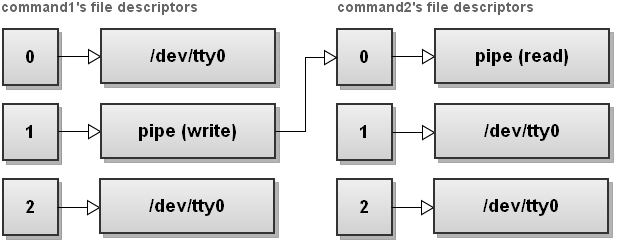
上图可见,所有到达 command1 标准输出(1 stdout)的内容都被重定向到了 command2 的标准输入(0 stdin)。
更进一步请参考手册命令 man 2 pipe .
18. 发送一个命令的标准输出和标准错误输出到另一命令进程
shell
$ command1 |& command2这个操作符在 bash 4.0 版本后出现。 |& 重定向操作符通过管道将 command1 命令的标准输出和标准错误输出都发到 command2 命令的标准输入。
最新的 bash 4.0 版 的新功能未广泛普及前,旧的,方便的方法是:
shell
$ command1 2>&1 | command2下面是标准输入 / 输出描述符 的变化示意图:
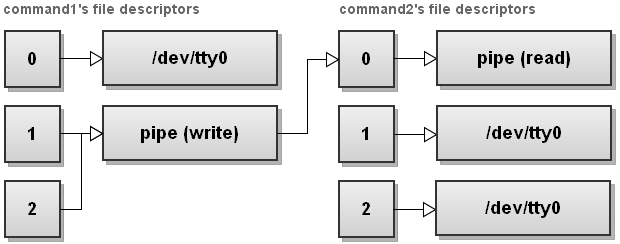
前面的操作先将 command1 的 stderr (2) 重定向到 stdout (1) ,然后通过管道将标准输出重定向到 command2 的标准输入 stdin (0) 。
19. 为创建的文件描述符赋名
shell
$ exec {filew}>output_file
#译注:引用命名文件描述符,使用 &$ 如下命令:
$ echo test >&$filew #译者加的命令命名文件描述符 是 bash 4.1 版后的功能特性。以 {varname}>output_file 定义了名为 varname 的输出文件描述符到指定文件。你可以通过其名称、文件描述符号正常使用它。Bash 在内部会给它分配一个空闲的文件描述符号。(译注:这个命令很容易和临时重定向到一个文件混淆!关于如何用其名称引用它,我写到上面的代码注释里。如何找到其文件描述符号,参见译注 1.)
20. 重定向操作的顺序
你可以把重定向操作放到命令行的任何位置。看看下面 3 个例子,它们效果一样:
bash
$ echo hello >/tmp/example
$ echo >/tmp/example hello
$ >/tmp/example echo hello喜欢上了 bash !
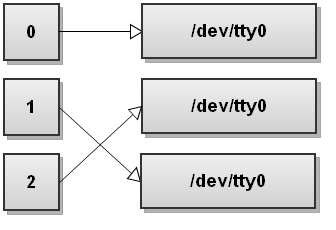
21. 交换标准 stdout 和 stderr
bash
$ command 3>&1 1>&2 2>&3这里,首先将 stdout (&1) 复制一个副本 &3 --3 号文件描述符 -- ,再使 stdout (&1) 成为 stderr (&2) -- 2 号文件描述符 -- 的副本,最后使 stderr (&2) 成为 &3 的副本。这样将 stdout 和 stderr 进行了交换。
让我们用图示展示每步过程。下面是命令开始时的文件描述符状态图示:
然后,3>&1 重定向操作符指示,创建 3 号输出文件描述符指向跟 &1 相同:
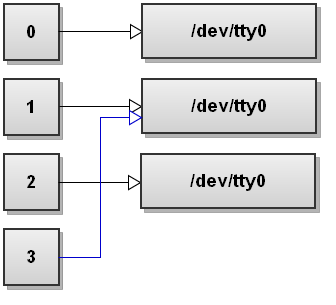
下一个 1>&2 重定向操作符指示,将 1 号标准输出文件描述符指向跟 &2 相同:
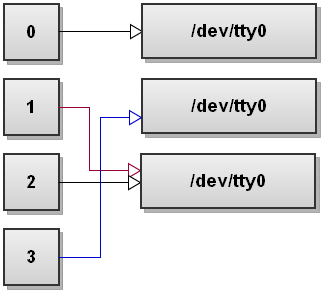
下一个 2>&3 重定向操作符指示,将 2 号标准输出文件描述符指向跟 &3 相同(即原始的 &1):
如果想关闭不再有用的好人 &3 --3 号文件描述符 -- ,见如下命令:
bash
$ command 3>&1 1>&2 2>&3 3>&-之后的文件描述符表示意如下:
如你所见,文件描述符 1 号 和 2 号 已经交换。
22. 重定向 stdout 到一个进程,stderr 到另一进程
shell
$ command > >(stdout_cmd) 2> >(stderr_cmd)这行命令使用了重定向命令替换展开操作符 >() 。它将会运行 () 中的命令。而其标准输入通过匿名管道连接到了 command 的标准输出。接着下一个 >() 操作符将其标准输入连接到了 command 的标准错误输出。
对于上面的例子,第一个命令替换 >(stdout_cmd) 可能使 bash 返回 /dev/fd/60 文件描述符。同时,第二个命令替换 >(stderr_cmd) 可能使 bash 返回 /dev/fd/61 文件描述符。这 2 个文件描述符由 bash 实时创建为等待读取的命名管道。它们都等待某些命令进程往里写,以便它们读取。
所以,上述命令展开后可能是这样:
shell
$ command > /dev/fd/60 2> /dev/fd/61现在可看得清楚些, command 的 stdout 重定向到 /dev/fd/60 , stderr 重定向到 /dev/fd/61 。
当 command 输出,内部进程 'stdout_cmd ' 的命令执行将接受。当 command 的错误输出,内部进程 'stderr_cmd' 的命令执行将接受。
23. 找出每个管道命令的退出码
让我们看一下几个命令用管道串起来的例子,如下命令:
shell
$ cmd1 | cmd2 | cmd3 | cmd4你想找出这里每个命令的退出状态码,该如何做?有没有一个简便的方法获取每个命令的退出状态码,而不是 bash 简单给出的最后一条命令的退出状态码。
Bash 的开发者想到了这点,他们加入了一个名为 'PIPESTATUS' 的数组变量来保留管道命令流中每个命令的运行退出状态码。
数组变量 PIPESTATUS 中的每个数字都对应于相应位置命令的退出状态码。下面是个例子:
shell
$ echo 'men are cool' | grep 'moo' | sed 's/o/x/' | awk '{ print $1 }'
$ echo ${PIPESTATUS[@]}
0 1 0 0上面例子中,命令 grep 'moo' 失败,因此数组变量 PIPESTATUS 中的第 2 个数为 1 。
建议
建议研究 bash 高手们的百科 演示重定向教程 和 bash 版本进化.
译注
1. 如何发现当前 bash 的所有文件描述符
以下内容,译者受网文 Linux: Find All File Descriptors Used By a Process 启发,针对在 bash 中发现其所有文件描述符的任务进行创作。
一、找到当前 bash 进程 ID -- PID
方法 1:使用查看进程命令,如 ps 命令
语法:
shell
ps aux | grep [程序名称]ps 命令,参考本站 wiki ps 命令(查看进程) 。
对于我们的情况,程序名称 是 bash ,命令如下:
shell
$ ps aux | grep bash可能的输出如下:
shell
aman 7146 0.0 0.2 30748 5728 pts/4 Ss 09:42 0:00 bash
aman 7978 0.0 0.2 24432 5516 pts/18 Ss+ 13:56 0:00 bash
aman 8022 0.0 0.0 15964 928 pts/4 S+ 14:10 0:00 grep --color=auto bash这里,我专门打开了 2 个 shell ,哪个是我们当前的 shell 呢?方法很多,使用 tty 命令找出当前的 tty 与上面的输出对比。找到本 shell 的 PID 是 7146 。
方法 2:使用 pidof 命令
语法:
shell
pidof [程序名称]这个方法不适用同时开了多个 shell 的例子,但只有一个 shell 时会很简单,如下命令:
shell
$ pidof bash
7146二、根据 bash 的 PID 找到其使用的所有文件描述符
方法 1:查看 /proc/pid/fd 目录
如下所示命令及输出:
shell
$ ls -l /proc/7146/fd
total 0
lrwx------ 1 aman aman 64 12月 27 09:42 0 -> /dev/pts/4
l-wx------ 1 aman aman 64 12月 27 09:42 1 -> /dev/pts/4
l-wx------ 1 aman aman 64 12月 27 09:42 10 -> /home/aman/test/nFD
lrwx------ 1 aman aman 64 12月 27 09:42 2 -> /dev/pts/4
lrwx------ 1 aman aman 64 12月 27 12:02 255 -> /dev/pts/4我之前在这个 shell 下,使用 $ exec {FD1}> nFD 命令创建了一个永久命名文件描述符重定向到了当前目录下的 nFD 文件。在这里我们看见 bash 内部给它分配了文件描述符号 10 。这样,你在重定向输出时就即可使用 &$FD1 或 &10 都会输出到 nFD 文件。
我的运行示意如下:
bash
$ echo 'line 1' >&10
$ echo 'line 2' >&$FD1 #这行命令与上行输出到相同目的地
$ cat nFD
line 1
line 2方法 2:使用 lsof 命令
语法:
shell
lsof -a -p {输入PID}lsof 命令,参考 ' lsof command ' 。我的命令示意如下:
shell
$ lsof -a -p 7146输出:
shell
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 7146 aman cwd DIR 8,5 4096 178864 /home/aman/test
bash 7146 aman rtd DIR 8,5 4096 2 /
bash 7146 aman txt REG 8,5 1037528 134435 /bin/bash
bash 7146 aman mem REG 8,5 101200 265464 /lib/x86_64-linux-gnu/libresolv-2.23.so
...
...
...
bash 7146 aman 0u CHR 136,4 0t0 7 /dev/pts/4
bash 7146 aman 1w CHR 136,4 0t0 7 /dev/pts/4
bash 7146 aman 2u CHR 136,4 0t0 7 /dev/pts/4
bash 7146 aman 10w REG 8,5 16 178735 /home/aman/test/nFD
bash 7146 aman 255u CHR 136,4 0t0 7 /dev/pts/4见上面输出倒数第二行,可知 nFD 文件的重定向文件描述符号为 10 。
Illustrated Redirection Tutorial
图解重定向教程
This tutorial is not a complete guide to redirection, it will not cover here docs, here strings, name pipes etc... I just hope it'll help you to understand what things like 3>&2, 2>&1 or 1>&3- do.
本教程不是重定向的完整指南,它不会涵盖 here docs、here 字符串、名称管道等......我只是希望它能帮助你理解 3>&2、2>&1 或 1>&3- 之类的东西是做什么的。
stdin, stdout, stderr
stdin、stdout、stderr
When Bash starts, normally, 3 file descriptors are opened, 0, 1 and 2 also known as standard input (stdin), standard output (stdout) and standard error (stderr).
当 Bash 启动时,通常会打开 3 个文件描述符,0、1 和 2 也称为标准输入 (stdin)、标准输出 (stdout) 和标准错误 (stderr)。
For example, with Bash running in a Linux terminal emulator, you'll see:
例如,在 Linux 终端仿真器中运行 Bash 时,您将看到:
shell
# lsof +f g -ap $BASHPID -d 0,1,2
COMMAND PID USER FD TYPE FILE-FLAG DEVICE SIZE/OFF NODE NAME
bash 12135 root 0u CHR RW,LG 136,13 0t0 16 /dev/pts/5
bash 12135 root 1u CHR RW,LG 136,13 0t0 16 /dev/pts/5
bash 12135 root 2u CHR RW,LG 136,13 0t0 16 /dev/pts/5This /dev/pts/5 is a pseudo terminal used to emulate a real terminal. Bash reads (stdin) from this terminal and prints via stdout and stderr to this terminal.
这个 /dev/pts/5 是一个用于模拟真实终端的伪终端。Bash 从此终端读取 (stdin) 并通过 stdout 和 stderr 打印到此终端。
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+When a command, a compound command, a subshell etc. is executed, it inherits these file descriptors. For instance echo foo will send the text foo to the file descriptor 1 inherited from the shell, which is connected to /dev/pts/5.
当执行命令、复合命令、子 shell 等时,它会继承这些文件描述符。例如,echo foo 会将文本 foo 发送到从 shell 继承的文件描述符 1,该文件连接到 /dev/pts/5。
Simple Redirections
简单重定向
Output Redirection "n> file"
输出重定向 "n> file"
> is probably the simplest redirection.
> 可能是最简单的重定向。
shell
echo foo > filethe > file after the command alters the file descriptors belonging to the command echo. It changes the file descriptor 1 (> file is the same as 1>file) so that it points to the file file. They will look like:
命令后面的 > file 会改变属于命令 echo 的文件描述符。它更改文件描述符 1(> file 与 1>file 相同),使其指向文件 file。它们将如下所示:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| file |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+Now characters written by our command, echo, that are sent to the standard output, i.e., the file descriptor 1, end up in the file named file.
现在,由我们的命令 echo 写入的字符被发送到标准输出,即文件描述符 1,最终出现在名为 file 的文件中。
In the same way, command 2> file will change the standard error and will make it point to file. Standard error is used by applications to print errors.
同样,命令 2> file 将更改标准误差并使其指向 file。应用程序使用标准错误来打印错误。
What will command 3> file do? It will open a new file descriptor pointing to file. The command will then start with:
command 3> file 会做什么?它将打开一个指向 file 的新文件描述符。然后,该命令将以以下内容开头:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
new descriptor ( 3 ) ---->| file |
--- +-----------------------+What will the command do with this descriptor? It depends. Often nothing. We will see later why we might want other file descriptors.
命令将对此描述符执行什么操作?这要看情况。通常什么都没有。我们稍后会明白为什么我们可能需要其他文件描述符。
Input Redirection "n< file"
输入重定向 "n< file"
When you run a command using command < file, it changes the file descriptor 0 so that it looks like:
当您使用 command < file 运行命令时,它会更改文件描述符 0,使其如下所示:
shell
--- +-----------------------+
standard input ( 0 ) <----| file |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+If the command reads from stdin, it now will read from file and not from the console.
如果命令从 stdin 读取,它现在将从 file 读取,而不是从控制台读取。
As with >, < can be used to open a new file descriptor for reading, command 3<file. Later we will see how this can be useful.
与 > 一样,< 可用于打开新的文件描述符进行读取,command 3<file。稍后我们将看到这有什么用处。
Pipes |
管道 |
What does this | do? Among other things, it connects the standard output of the command on the left to the standard input of the command on the right. That is, it creates a special file, a pipe, which is opened as a write destination for the left command, and as a read source for the right command.
这个 | 有什么作用?此外,它还将左侧命令的标准输出连接到右侧命令的标准输入。也就是说,它会创建一个特殊文件,即管道,该文件将作为左侧命令的写入目标打开,并作为右侧命令的读取源打开。
shell
echo foo |cat
--- +--------------+ --- +--------------+
( 0 ) ---->| /dev/pts/5 | ------> ( 0 ) ---->|pipe (read) |
--- +--------------+ / --- +--------------+
/
--- +--------------+ / --- +--------------+
( 1 ) ---->| pipe (write) | / ( 1 ) ---->| /dev/pts |
--- +--------------+ --- +--------------+
--- +--------------+ --- +--------------+
( 2 ) ---->| /dev/pts/5 | ( 2 ) ---->| /dev/pts/ |
--- +--------------+ --- +--------------+This is possible because the redirections are set up by the shell before the commands are executed, and the commands inherit the file descriptors.
这是可能的,因为重定向是在执行命令之前由 shell 设置的,并且命令继承了文件描述符。
More On File Descriptors
有关文件描述符的更多信息
Duplicating File Descriptor 2>&1
复制文件描述符 2>&1
We have seen how to open (or redirect) file descriptors. Let us see how to duplicate them, starting with the classic 2>&1. What does this mean? That something written on the file descriptor 2 will go where file descriptor 1 goes. In a shell command 2>&1 is not a very interesting example so we will use ls /tmp/ doesnotexist 2>&1 | less
我们已经了解了如何打开(或重定向)文件描述符。让我们看看如何复制它们,从经典的 2>&1 开始。这是什么意思?文件描述符 2 上写入的内容将转到文件描述符 1 所在的位置。在 shell 中 command 2>&1 不是一个非常有趣的例子,所以我们将使用 ls /tmp/ doesnotexist 2>&1 | less
shell
ls /tmp/ doesnotexist 2>&1 | less
--- +--------------+ --- +--------------+
( 0 ) ---->| /dev/pts/5 | ------> ( 0 ) ---->|from the pipe |
--- +--------------+ / ---> --- +--------------+
/ /
--- +--------------+ / / --- +--------------+
( 1 ) ---->| to the pipe | / / ( 1 ) ---->| /dev/pts |
--- +--------------+ / --- +--------------+
/
--- +--------------+ / --- +--------------+
( 2 ) ---->| to the pipe | / ( 2 ) ---->| /dev/pts/ |
--- +--------------+ --- +--------------+Why is it called duplicating ? Because after 2>&1, we have 2 file descriptors pointing to the same file. Take care not to call this "File Descriptor Aliasing"; if we redirect stdout after 2>&1 to a file B, file descriptor 2 will still be opened on the file A where it was. This is often misunderstood by people wanting to redirect both standard input and standard output to the file. Continue reading for more on this.
为什么叫复制?因为在 2>&1 之后,我们有 2 个文件描述符指向同一个文件。注意不要将此称为"文件描述符别名";如果我们将 2>&1 之后的 stdout 重定向到文件 B,文件描述符 2 仍将在文件 A 上打开。想要将标准输入和标准输出重定向到文件的人经常误解这一点。继续阅读以了解更多信息。
So if you have two file descriptors s and t like:
因此,如果你有两个文件描述符 s 和 t,如下所示:
shell
--- +-----------------------+
a descriptor ( s ) ---->| /some/file |
--- +-----------------------+
--- +-----------------------+
a descriptor ( t ) ---->| /another/file |
--- +-----------------------+Using a t>&s (where t and s are numbers) it means:
使用 t>&s (其中 t 和 s 是数字) 表示:
Copy whatever file descriptor
scontains into file descriptort将 s 包含的任何文件描述符复制到文件描述符 t 中
So you got a copy of this descriptor:
所以你得到了这个描述符的副本:
shell
--- +-----------------------+
a descriptor ( s ) ---->| /some/file |
--- +-----------------------+
--- +-----------------------+
a descriptor ( t ) ---->| /some/file |
--- +-----------------------+Internally each of these is represented by a file descriptor opened by the operating system's fopen calls, and is likely just a pointer to the file which has been opened for reading (stdin or file descriptor 0) or writing (stdout /stderr).
在内部,它们中的每一个都由操作系统的 fopen 调用打开的文件描述符表示,并且可能只是一个指向已打开进行读取(stdin 或文件描述符 0)或写入(stdout /stderr)的文件的指针。
Note that the file reading or writing positions are also duplicated. If you have already read a line of s, then after t>&s if you read a line from t, you will get the second line of the file.
请注意,文件读取或写入位置也是重复的。如果你已经阅读了 s 行,那么在 t>&s 之后,如果你从 t 中阅读了一行,你将得到文件的第二行。
Similarly for output file descriptors, writing a line to file descriptor s will append a line to a file as will writing a line to file descriptor t.
同样,对于输出文件描述符,向文件描述符 s 写入一行会将一行附加到文件中,向文件描述符 t 写入一行也会。
The syntax is somewhat confusing in that you would think that the arrow would point in the direction of the copy, but it's reversed. So it's target>&source effectively.
So, as a simple example (albeit slightly contrived), is the following:
因此,作为一个简单的示例(尽管略显做作),如下所示:
shell
exec 3>&1 # Copy 1 into 3
exec 1> logfile # Make 1 opened to write to logfile
lotsa_stdout # Outputs to fd 1, which writes to logfile
exec 1>&3 # Copy 3 back into 1
echo Done # Output to original stdoutOrder Of Redirection, i.e., "> file 2>&1" vs. "2>&1 >file"
重定向顺序,即"> file 2>&1" vs. "2>&1 >file"
While it doesn't matter where the redirections appears on the command line, their order does matter. They are set up from left to right.
虽然重定向在命令行上的显示位置并不重要,但它们的顺序确实很重要。它们从左到右设置。
2>&1 >file
2>&1 >文件
A common error, is to docommand 2>&1 > fileto redirect bothstderrandstdouttofile. Let's see what's going on. First we type the command in our terminal, the descriptors look like this:
一个常见的错误是执行command 2>&1 > file将stderr和stdout重定向到file。让我们看看发生了什么。首先,我们在终端中键入命令,描述符如下所示:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+Then our shell, Bash sees 2>&1 so it duplicates 1, and the file descriptor look like this:
然后我们的 shell,Bash 看到 2>&1,所以它复制了 1,文件描述符看起来像这样:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+That's right, nothing has changed, 2 was already pointing to the same place as 1. Now Bash sees > file and thus changes stdout:
没错,什么都没有改变,2 已经指向与 1 相同的位置。现在 Bash 看到 > file,因此更改了 stdout:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| file |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+And that's not what we want.
这不是我们想要的。
>file 2>&1
>档案 2>&1
Now let's look at the correctcommand >file 2>&1. We start as in the previous example, and Bash sees> file:
现在让我们看看正确的command >file 2>&1。我们从前面的示例开始,Bash 看到> file:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| file |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+Then it sees our duplication 2>&1:
然后它会看到我们的重复项 2>&1:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| file |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| file |
--- +-----------------------+And voila, both 1 and 2 are redirected to file.
瞧,1 和 2 都被重定向到 file。
Why sed 's/foo/bar/' file >file Doesn't Work
为什么 sed 's/foo/bar/' 文件 > 文件不起作用
This is a common error, we want to modify a file using something that reads from a file and writes the result to stdout. To do this, we redirect stdout to the file we want to modify. The problem here is that, as we have seen, the redirections are setup before the command is actually executed.
这是一个常见的错误,我们想要使用从文件中读取并将结果写入 stdout 的内容来修改文件。为此,我们将 stdout 重定向到我们想要修改的文件。这里的问题是,正如我们所看到的,重定向是在实际执行命令之前设置的。
So BEFORE sed starts, standard output has already been redirected, with the additional side effect that, because we used >, "file" gets truncated. When sed starts to read the file, it contains nothing.
因此,在 sed 启动之前,标准输出已经被重定向,还有一个额外的副作用,因为我们使用了 >,"file" 被截断。当 sed 开始读取文件时,它不包含任何内容。
exec
在 Bash 中,内置 exec 将 shell 替换为指定的程序。那么这和重定向有什么关系呢?exec 还允许我们操作文件描述符。如果未指定程序,则 exec 之后的重定向将修改当前 shell 的文件描述符。
For example, all the commands after exec 2>file will have file descriptors like:
例如,exec 2>file 之后的所有命令都将具有文件描述符,例如:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| file |
--- +-----------------------+All the the errors sent to stderr by the commands after the exec 2>file will go to the file, just as if you had the command in a script and ran myscript 2>file.
exec 2>file 之后的命令发送到 stderr 的所有错误都将发送到文件中,就像您在脚本中有命令并运行 myscript 2>file 一样。
exec can be used, if, for instance, you want to log the errors the commands in your script produce, just add exec 2>myscript.errors at the beginning of your script.
exec 都可以使用,例如,如果您想记录脚本中的命令产生的错误,只需在脚本的开头添加 exec 2>myscript.errors 即可。
Let's see another use case. We want to read a file line by line, this is easy, we just do:
让我们看看另一个用例。我们想逐行读取一个文件,这很简单,我们只需这样做:
shell
while read -r line;do echo "$line";done < fileNow, we want, after printing each line, to do a pause, waiting for the user to press a key:
现在,我们希望在打印每一行后进行暂停,等待用户按下一个键:
shell
while read -r line;do echo "$line"; read -p "Press any key" -n 1;done < fileAnd, surprise this doesn't work. Why? because the shell descriptor of the while loop looks like:
而且,令人惊讶的是,这不起作用。为什么?因为 while 循环的 shell 描述符如下所示:
shell
--- +-----------------------+
standard input ( 0 ) ---->| file |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+and our read inherits these descriptors, and our command (read -p "Press any key" -n 1) inherits them, and thus reads from file and not from our terminal.
我们的 read 继承了这些 Descriptors,我们的命令 (read -p "Press any key" -n 1) 继承了它们,因此从 file 而不是从我们的终端读取。
A quick look at help read tells us that we can specify a file descriptor from which read should read. Cool. Now let's use exec to get another descriptor:
快速浏览一下 help read 告诉我们,我们可以指定一个文件描述符,从中读取 read。凉。现在让我们使用 exec 来获取另一个描述符:
shell
exec 3<file
while read -u 3 line;do echo "$line"; read -p "Press any key" -n 1;doneNow the file descriptors look like:
现在文件描述符如下所示:
shell
--- +-----------------------+
standard input ( 0 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard output ( 1 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
standard error ( 2 ) ---->| /dev/pts/5 |
--- +-----------------------+
--- +-----------------------+
new descriptor ( 3 ) ---->| file |
--- +-----------------------+and it works. 而且它奏效了。
Closing The File Descriptors
关闭文件描述符
Closing a file through a file descriptor is easy, just make it a duplicate of -. For instance, let's close stdin <&- and stderr 2>&-:
通过文件描述符关闭文件很容易,只需将其与 - 重复即可。例如,让我们关闭 stdin <&- 和 stderr 2>&-:
shell
bash -c '{ lsof -a -p $$ -d0,1,2 ;} <&- 2>&-'
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 10668 pgas 1u CHR 136,2 4 /dev/pts/2we see that inside the {} that only 1 is still here.
Though the OS will probably clean up the mess, it is perhaps a good idea to close the file descriptors you open. For instance, if you open a file descriptor with exec 3>file, all the commands afterwards will inherit it. It's probably better to do something like:
尽管操作系统可能会清理混乱,但关闭您打开的文件描述符可能是个好主意。例如,如果你用 exec 3>file 打开一个文件描述符,之后的所有命令都将继承它。执行如下操作可能更好:
shell
exec 3>file
....
#commands that uses 3
....
exec 3>&-
#we don't need 3 any moreI've seen some people using this as a way to discard, say stderr, using something like: command 2>&-. Though it might work, I'm not sure if you can expect all applications to behave correctly with a closed stderr.
我见过有些人用这个作为丢弃的方法,比如 stderr,使用类似命令 2>&- 的东西。虽然它可能有效,但我不确定您是否可以期望所有应用程序在关闭 stderr 的情况下都能正常运行。
When in doubt, I use 2>/dev/null.
如有疑问,我使用 2>/dev/null。
An Example
示例
This example comes from this post (ffe4c2e382034ed9) on the comp.unix.shell group:
此示例来自 comp.unix.shell 组上的此帖子 (ffe4c2e382034ed9):
bash
{
{
cmd1 3>&- |
cmd2 2>&3 3>&-
} 2>&1 >&4 4>&- |
cmd3 3>&- 4>&-
} 3>&2 4>&1The redirections are processed from left to right, but as the file descriptors are inherited we will also have to work from the outer to the inner contexts. We will assume that we run this command in a terminal. Let's start with the outer { } 3>&2 4>&1.
重定向是从左到右处理的,但是由于文件描述符是继承的,我们还必须从外部上下文工作到内部上下文。我们假设我们在终端中运行此命令。让我们从外部 { } 3>&2 4>&1 开始。
bash
--- +-------------+ --- +-------------+
( 0 ) ---->| /dev/pts/5 | ( 3 ) ---->| /dev/pts/5 |
--- +-------------+ --- +-------------+
--- +-------------+ --- +-------------+
( 1 ) ---->| /dev/pts/5 | ( 4 ) ---->| /dev/pts/5 |
--- +-------------+ --- +-------------+
--- +-------------+
( 2 ) ---->| /dev/pts/5 |
--- +-------------+We only made 2 copies of stderr and stdout. 3>&1 4>&1 would have produced the same result here because we ran the command in a terminal and thus 1 and 2 go to the terminal. As an exercise, you can start with 1 pointing to file.stdout and 2 pointing to file.stderr, you will see why these redirections are very nice.
我们只制作了 stderr 和 stdout 的 2 份副本。3>&1 4>&1 在这里会产生相同的结果,因为我们在终端中运行命令,因此 1 和 2 转到终端。作为一个练习,你可以从 1 指向 file.stdout 开始,从 2 指向 file.stderr 开始,你就会明白为什么这些重定向非常好。
Let's continue with the right part of the second pipe: | cmd3 3>&- 4>&-
让我们继续第二个竖井的右侧部分:| cmd3 3>&- 4>&-
bash
--- +-------------+
( 0 ) ---->| 2nd pipe |
--- +-------------+
--- +-------------+
( 1 ) ---->| /dev/pts/5 |
--- +-------------+
--- +-------------+
( 2 ) ---->| /dev/pts/5 |
--- +-------------+It inherits the previous file descriptors, closes 3 and 4 and sets up a pipe for reading. Now for the left part of the second pipe {...} 2>&1 >&4 4>&- |
它继承了前面的文件描述符,关闭 3 和 4 并设置一个用于读取的管道。现在是第二个竖井管 {...} 2>&1 >&4 4>&- | 的左侧部分
shell
--- +-------------+ --- +-------------+
( 0 ) ---->| /dev/pts/5 | ( 3 ) ---->| /dev/pts/5 |
--- +-------------+ --- +-------------+
--- +-------------+
( 1 ) ---->| /dev/pts/5 |
--- +-------------+
--- +-------------+
( 2 ) ---->| 2nd pipe |
--- +-------------+First, The file descriptor 1 is connected to the pipe (|), then 2 is made a copy of 1 and thus is made an fd to the pipe (2>&1), then 1 is made a copy of 4 (>&4), then 4 is closed. These are the file descriptors of the inner {}. Lcet's go inside and have a look at the right part of the first pipe: | cmd2 2>&3 3>&-
首先,将文件描述符 1 连接到管道 (|),然后 2 成为 1 的副本,从而成为管道 (2>&1) 的 fd,然后 1 成为 4 的副本 (>&4),然后 4 关闭。这些是内部 {} 的文件描述符。Lcet 进去看看第一根管子的右侧部分:| cmd2 2>&3 3>&-
shell
--- +-------------+
( 0 ) ---->| 1st pipe |
--- +-------------+
--- +-------------+
( 1 ) ---->| /dev/pts/5 |
--- +-------------+
--- +-------------+
( 2 ) ---->| /dev/pts/5 |
--- +-------------+It inherits the previous file descriptors, connects 0 to the 1st pipe, the file descriptor 2 is made a copy of 3, and 3 is closed. Finally, for the left part of the pipe:
它继承了前面的文件描述符,将 0 连接到第 1 个管道,文件描述符 2 成为 3 的副本,并且 3 被关闭。最后,对于管道的左侧部分:
shell
--- +-------------+
( 0 ) ---->| /dev/pts/5 |
--- +-------------+
--- +-------------+
( 1 ) ---->| 1st pipe |
--- +-------------+
--- +-------------+
( 2 ) ---->| 2nd pipe |
--- +-------------+It also inherits the file descriptor of the left part of the 2nd pipe, file descriptor 1 is connected to the first pipe, 3 is closed.
它还继承了第二个管道左侧部分的文件描述符,文件描述符 1 连接到第一个管道,3 关闭。
The purpose of all this becomes clear if we take only the commands:
如果我们只接受这些命令,这一切的目的就会变得很清楚:
shell
cmd2
--- +-------------+
-->( 0 ) ---->| 1st pipe |
/ --- +-------------+
/
/ --- +-------------+
cmd 1 / ( 1 ) ---->| /dev/pts/5 |
/ --- +-------------+
/
--- +-------------+ / --- +-------------+
( 0 ) ---->| /dev/pts/5 | / ( 2 ) ---->| /dev/pts/5 |
--- +-------------+ / --- +-------------+
/
--- +-------------+ / cmd3
( 1 ) ---->| 1st pipe | /
--- +-------------+ --- +-------------+
------------>( 0 ) ---->| 2nd pipe |
--- +-------------+ / --- +-------------+
( 2 ) ---->| 2nd pipe |/
--- +-------------+ --- +-------------+
( 1 ) ---->| /dev/pts/5 |
--- +-------------+
--- +-------------+
( 2 ) ---->| /dev/pts/5 |
--- +-------------+As said previously, as an exercise, you can start with 1 open on a file and 2 open on another file to see how the stdin from cmd2 and cmd3 goes to the original stdin and how the stderr goes to the original stderr.
如前所述,作为练习,您可以从一个文件的 1 打开开始,在另一个文件上打开 2,以查看 cmd2 和 cmd3 中的 stdin 如何转到原始 stdin,以及 stderr 如何转到原始 stderr。
Syntax
语法
I used to have trouble choosing between 0&<3 3&>1 3>&1 ->2 -<&0 &-<0 0<&- etc... (I think probably because the syntax is more representative of the result, i.e., the redirection, than what is done, i.e., opening, closing, or duplicating file descriptors).
我以前在 0&<3 3&>1 3>&1 ->2 -<&0 &-<0 0<&- 等之间很难选择...(我认为可能是因为语法更能代表结果,即重定向,而不是所做的,即打开、关闭或复制文件描述符)。
If this fits your situation, then maybe the following "rules" will help you, a redirection is always like the following:
如果这符合您的情况,那么以下 "规则" 可能会对您有所帮助,重定向总是如下所示:
shell
lhs op rhslhsis always a file description, i.e., a number:- Either we want to open, duplicate, move or we want to close. If the op is
<then there is an implicit 0, if it's>or>>, there is an implicit 1. - 要么我们想要打开、复制、移动,要么我们想要关闭。如果 op 为 <,则存在隐式 0,如果为 > 或 >>,则存在隐式 1。
- Either we want to open, duplicate, move or we want to close. If the op is
opis<,>,>>,>|, or<>:<if the file decriptor inlhswill be read,>if it will be written,>>if data is to be appended to the file,>|to overwrite an existing file or<>if it will be both read and written.- <是否将读取 LHS 中的文件描述器,>是否将写入该文件,>>是否将数据附加到文件中,>| 覆盖现有文件,<>是否将读取和写入该文件。
rhsis the thing that the file descriptor will describe:- It can be the name of a file, the place where another descriptor goes (
&1), or,&-, which will close the file descriptor. - 它可以是文件名、另一个描述符所在的位置 (&1) 或 &-,这将关闭文件描述符。
You might not like this description, and find it a bit incomplete or inexact, but I think it really helps to easily find that, say&->0is incorrect.
你可能不喜欢这个描述,觉得它有点不完整或不精确,但我认为很容易找到它真的很有帮助,比如说&->0是不正确的。
- It can be the name of a file, the place where another descriptor goes (
A note on style
关于风格的说明
The shell is pretty loose about what it considers a valid redirect. While opinions probably differ, this author has some (strong) recommendations:
shell 对它认为有效的重定向非常宽松。虽然意见可能不同,但笔者提出了一些(强烈)的建议:
- Always keep redirections "tightly grouped" -- that is, do not include whitespace anywhere within the redirection syntax except within quotes if required on the RHS (e.g. a filename that contains a space). Since shells fundamentally use whitespace to delimit fields in general, it is visually much clearer for each redirection to be separated by whitespace, but grouped in chunks that contain no unnecessary whitespace.
始终保持重定向"紧密分组"------也就是说,不要在重定向语法中的任何位置包含空格,除非在 RHS 上需要时在引号内(例如,包含空格的文件名)。由于 shell 通常从根本上使用空格来分隔字段,因此每个重定向都由空格分隔,但分组为不包含不必要空格的块,这在视觉上要清晰得多。 - Do always put a space between each redirection, and between the argument list and the first redirect.
务必始终在每次重定向之间以及参数列表和第一个重定向之间放置一个空格。 - Always place redirections together at the very end of a command after all arguments. Never precede a command with a redirect. Never put a redirect in the middle of the arguments.
始终将重定向放在命令的最末尾所有参数之后。切勿在命令前添加重定向。永远不要在参数中间放置重定向。 - Never use the Csh
&>fooand>&fooshorthand redirects. Use the long form>foo 2>&1. (see: obsolete )
永远不要使用Csh &>foo和>&foo简写重定向。使用长格式>foo 2>&1。
shell
# Good! This is clearly a simple commmand with two arguments and 4 redirections
cmd arg1 arg2 <myFile 3<&1 2>/dev/null >&2
# Good!
{ cmd1 <<<'my input'; cmd2; } >someFile
# Bad. Is the "1" a file descriptor or an argument to cmd? (answer: it's the FD). Is the space after the herestring part of the input data? (answer: No).
# The redirects are also not delimited in any obvious way.
cmd 2>& 1 <<< stuff
# Hideously Bad. It's difficult to tell where the redirects are and whether they're even valid redirects.
# This is in fact one command with one argument, an assignment, and three redirects.
foo=bar<baz bork<<< blarg>blehConclusion
结论
I hope this tutorial worked for you.
我希望本教程对您有所帮助。
I lied, I did not explain 1>&3-, go check the manual.
我撒谎了,我没有解释 1>&3-,去查手册。
Thanks to Stéphane Chazelas from whom I stole both the intro and the example....
感谢 Stéphane Chazelas,我从他那里偷走了介绍和示例...
Discussion
讨论
Armin, 2010/04/28 10:24, 2010/12/16 00:25
Hello,
I was looking for a solution for the following problem: I want to execute a shell script (both remotely via RSH and locally). The output from stdout and stderr should go to a file, to see the scripts progress at the terminal I wanted to redirect the output of some echo commands to the same file and to the terminal. Based on this tutorial I implemented the following solution (I don't know how to produce an ampersand, therefore I use "amp;" instead):
我一直在寻找以下问题的解决方案:我想执行一个 shell 脚本(通过 RSH 远程和本地)。stdout 和 stderr 的输出应该去一个文件,要在终端上查看脚本的进度,我想将一些 echo 命令的输出重定向到同一个文件和终端。基于本教程,我实现了以下解决方案(我不知道如何生成 & 符号,因此我使用 "amp;" 代替):
shell
# save stdout, redirect stdout and stderr to a file
exec 3>&1 1>logfile 2>&1
# do something which creates output to stdout and/or stderr
# "restore" stdout, issue a message both to the terminal and to the file
exec 1>&3
echo "my message" | tee -a logfile
exec 1>>logfile
# do something which creates output to stdout and/or stderr
exitAs soon as output to stderr happens it doesn't work as I expected. E.g.
一旦输出到 stderr 发生,它就不能像我预期的那样工作。例如
shell
exec 3>&1 1>logfile 2>&1
echo "Hello World"
ls filedoesnotexist
exec 1>&3
echo "my message" | tee -a logfile
ls filedoesnotexistyet
exec 1>>logfile
echo "Hello again"
ls filestilldoesnotexist
exitresults in the following content of file logfile:
导致文件 logfile 的内容如下:
shell
Hello World
ls: filedoesnotexist: No such file or directory
ls: filedoesnotexistyet: No such file or directory
ls: filestilldoesnotexist: No such file or directoryI.e. the texts "my message" and "Hello again" have been overwritten by the stderr output of the ls commands.
即文本 "my message" 和 "Hello again" 已被 ls 命令的 stderr 输出覆盖。
If I change in the 1st exec to append stdout to logfile (exec 3>&1 1>>logfile 2>&1), the result is correct:
如果我在第一个 exec 中进行更改以将 stdout 附加到日志文件 (exec 3>&1 1>>logfile 2>&1),则结果是正确的:
shell
Hello World
ls: filedoesnotexist: No such file or directory
my message
ls: filedoesnotexistyet: No such file or directory
Hello again
ls: filestilldoesnotexist: No such file or directoryIf I change the 7th line to exec 1>>logfile **2>&1**, the result looks better, but is not correct (still the line with "my message" is missing):
如果我将第 7 行更改为 exec 1>>logfile **2>&1**,结果看起来更好,但不正确(仍然缺少带有"my message"的行):
shell
Hello World
ls: filedoesnotexist: No such file or directory
ls: filedoesnotexistyet: No such file or directory
Hello again
ls: filestilldoesnotexist: No such file or directoryI finally implemented the following solution, which is maybe not so elegant but works:
我最终实现了以下解决方案,它可能不是那么优雅,但有效:
shell
exec 3>&1 4>&2 1>logfile 2>&1
echo "Hello World"
ls filedoesnotexist
exec 1>&3 2>&4
echo "my message" | tee -a logfile
ls filedoesnotexistyet
exec 1>>logfile 2>&1
echo "Hello again"
ls filestilldoesnotexist
exitThis has the effect that the error output of the 2nd ls goes to the terminal and not to the file which is absolutely ok for my case.
这会产生第二个 ls 的错误输出进入终端而不是文件,这对我来说绝对没问题。
Can anybody explain what exactly happens? I assume it has something to do with file pointers. What is the preferred solution of my problem?
谁能解释一下到底发生了什么?我认为它与文件指针有关。我问题的首选解决方案是什么?
P.S.: I have some problems with formatting, esp. with line feeds and empty lines.
P.S.:我在格式方面有一些问题,尤其是换行和空行。
Jan Schampera, 2010/04/28 20:02, 2010/12/16 00:26
Try this. In short:
试试这个。总之:
- no subsequent set/reset of filedescriptors
无需后续设置/重置 filedescriptors teegets a process substitution as output file, inside acatand a redirection to FD1 (logfile)
tee在cat中获取进程替换作为输出文件,并重定向到 FD1(日志文件)tee's standard output is redirected to FD3 (terminal/original stdout)
tee的标准输出重定向到 FD3(终端/原始标准输出)
shell
echo "my message" | tee >(cat >&1) >&3This is a Bash specific thing.
这是 Bash 特有的事情。
For the wiki quirks: I surrounded your code with <code>...</code> tags. For the ampersand issue I have no solution, sorry. Seems to be a bug in this plugin. It only happens on "preview", but it works for the real view.
对于 wiki 的怪癖:我用 <code>...</code> 标签包围了您的代码。对于与号问题,我没有解决方案,抱歉。似乎是这个插件中的一个错误。它只发生在 "preview" 上,但它适用于真实视图。
typedeaF, 2011/08/15 15:35
I am looking to implement the features of Expect, with bash. That is, to design a wrapper program that will assign the called program to redirect its 0-2 to named pipes. The wrapper will then open the other end of the named pipes. Something like this:
我希望使用 bash 实现 Expect 的功能。也就是说,设计一个包装程序,该程序将分配被调用的程序将其 0-2 重定向到命名管道。然后,包装器将打开命名管道的另一端。像这样:
shell
exec 3<>pipe.out
exec 4<>pipe.in
( PS3="enter choice:"; select choice in one two three; do echo "you choose \"$choice\""; done )0<&4 1>&3 2>&1
while read -u pipe.out line
do
case $line in
*choice:)
echo "$line"
read i; echo i >&4
;;
EOF)
echo "caught \"EOF\", exiting";
break;;
*)
echo "$line"
;;
esac
doneOf course, this doesn't work at all. The first problem is, when using a pipe, the process hangs until both ends of the pipe are established. The second part of the problem is that the bash built-in "read" returns on a newline or the option of N chars or delimiter X --neither of which would be useful in this case. So the input of the while loop never "sees" the "enter choice:" prompt, since there is no newline. There are other problems as well.
当然,这根本不起作用。第一个问题是,使用管道时,进程会挂起,直到管道的两端都建立起来。问题的第二部分是 bash 内置的 "read" 返回换行符或 N 个字符或分隔符 X 的选项------在这种情况下,这两种情况都没有用。所以 while 循环的输入永远不会 "看到" "enter choice:" 提示符,因为没有换行符。还有其他问题。
Is it possible to get Bash to do this? Any suggestions? Here is something that does work.
是否可以让 Bash 执行此操作?有什么建议吗?这是确实有效的东西。
terminal 1:
shell
(exec 3<pipe.out; while read -u 3 line; do case $line in *choice:) echo $line; echo "i should do a read here";; EOF) echo "caught EOF"; break;; *) echo "$line"; esac; done)terminal 2:
shell
(PS3="enter choice:"; select choice in one two three; do echo "you choose $choice"; done)1>pipe.out 2>&1In this case, the program continues when both ends connect to the pipe, but since we are not redirecting stdin from a pipe for the select, you have to enter the choice in terminal 2. You will also notice that even in this scenario, terminal 1 does not see the PS3 prompt since it does not return a newline.
在这种情况下,当管道的两端都连接时,程序会继续运行,但由于我们没有为 select 从管道中重定向 stdin,因此您必须在终端 2 中输入选择。您还会注意到,即使在这种情况下,终端 1 也看不到 PS3 提示符,因为它不会返回换行符。
Tony, 2012/02/10 00:41, 2012/02/10 05:35
Hello,
In my script, I want to redirect stderr to a file and both stderr and stdout to another file. I found this construction works but I don't quite understand how. Could you explain?
在我的脚本中,我想将 stderr 重定向到一个文件,并将 stderr 和 stdout 重定向到另一个文件。我发现这个结构很有效,但我不太明白是怎么做到的。您能解释一下吗?
shell
((./cmd 2>&1 1>&3 | tee /tmp/stderr.log) 3>&1 1>&2) > /tmp/both.log 2>&1Also, if I want to do the same in the script using exec to avoid this kind of redirection in every command in the script, what should I do?
另外,如果我想在脚本中使用 exec 做同样的事情,以避免在脚本中的每个命令中发生这种重定向,我该怎么办?
Jan Schampera, 2012/02/10 05:46
You pump STDERR of the command to descriptor 1, so that it can be transported by the pipe and seen as input by the tee command. At the same time you redirect the original STDOUT to descriptor 3. The tee command writes your original standard error output to the file plus outputs it to its STDOUT.
您将命令的 STDERR 抽取到描述符 1,以便它可以通过管道传输,并被视为 tee 命令的输入。同时,您将原始 STDOUT 重定向到描述符 3。tee 命令将原始标准错误输出写入文件,并将其输出到其 STDOUT。
Outside the whole construct you collect your original standard output (descriptor 3) and your original standard error output (descriptor 1 - through tee) to the normal descriptors (1 and 2), the rest is a simple file redirection for both descriptors.
在整个结构之外,您将原始标准输出(描述符 3)和原始标准错误输出(描述符 1 - 到 tee)收集到普通描述符(1 和 2),其余部分是两个描述符的简单文件重定向。
In short, you use a third descriptor to switch a bypass through tee.
简而言之,您可以使用第三个描述符来切换通过 tee 的旁路。
I don't know a global method (exec or the like) off my head. I can imagine that you can hack something with process substitution, but I'm not sure.
我不知道一个全局方法(exec 或类似方法)。我可以想象你可以用进程替换来破解一些东西,但我不确定。
jack, 2012/03/02 16:41
Many thanks for these explanations! Just one point which confused me. In the example from comp.unix.shell, you wrote: "Now for the left part of the second pipe..." The illustration for the result confused me because I was assuming the fds where coming from the previous illustration, but I then understood that they come from their parent process and hence from the previous previous illustration. I think it would be a little bit clearer if you would put a label on each of your illustrations and make more explicit the transition from one illustration to another. Anyway, many thanks again.)jack(
非常感谢您的解释!只有一点让我感到困惑。在 comp.unix.shell 的示例中,您写道:"现在对于第二个管道的左侧部分..."结果的插图让我感到困惑,因为我假设 fds 来自上图,但随后我明白它们来自它们的父进程,因此来自上图。我认为如果你能在你的每幅插图上贴上一个标签,并更明确地说明从一个插图到另一个插图的过渡,那会更清楚一些。无论如何,再次非常感谢。)杰克(
R.W. Emerson II, 2012/12/09 16:30
Pipes seem to introduce an extraneous line at EOF. Is this true? Try this:
管道似乎在 EOF 处引入了一条无关的线路。这是真的吗?试试这个:
shell
declare tT="A\nB\nC\n" # Should have three lines here
echo -e "tT($tT)" # Three lines, confirmed
echo -e "sort($(sort <<< $tT))" # Sort outputs three lines
echo -e "$tT" | sort # Sort outputs four linesWhen three lines go into the pipe, four lines come out. The problem is not present in the here-string facility.
当三根管线进入管道时,会流出四根管线。在 here-string 工具中不存在问题。
Jan Schampera, 2012/12/16 13:13, 2012/12/16 13:14
I see those additional line coming from the previous echo:
我看到那些额外的行来自前面的 echo:
shell
bonsai@core:~$ echo -e "$tT"
A
B
C
bonsai@core:~$It is the additional newline echo adds itself to finalize the output. In your first echo, this is the newline after the closing bracket.
它是额外的换行符 echo 添加自身以完成输出。在您的第一个 echo 中,这是右括号后的换行符。
You can verify it when you use echo -n (suppresses the newline echo itself generates)
你可以在使用 echo -n 时验证它(抑制换行符 echo 本身生成)
Hans Ginzel, 2015/10/02 09:03
Plase add this example, http://stackoverflow.com/questions/3141738/duplicating-stdout-to-stderr.
bash
echo foo | tee /dev/stderrAre there better/cleaner solutions? It seems that /dev/stderr can have problem in cron.
有没有更好/更清洁的解决方案?似乎 /dev/stderr 在 cron 中可能存在问题。
Jan Schampera, 2015/10/21 04:51
It's a functionality of the shell itself, the shell duplicates the relevant file descriptors when it sees those filenames. So it may depend on the shell (or shell compatibility level) you use in cron.
这是 shell 本身的一个功能,当 shell 看到这些文件名时,它会复制相关的文件描述符。所以这可能取决于你在 cron 中使用的 shell(或 shell 兼容性级别)。
redirection_tutorial.txt Last modified: 2019/02/23 04:49_
acHao 创建于 2020年
via:
-
Bash 单命令行解释(1)--文件操作
https://learnku.com/articles/38449 -
Bash 单命令行解释(2)--字符串操作
https://learnku.com/articles/38528 -
Bash 单命令行解释(3)--重定向
https://learnku.com/articles/38650