我自己的原文哦~https://blog.51cto.com/whaosoft/11888989
#MambaOcc
Mamba再下一城,杀入Occupancy!更快更强的MambaOcc来了(中科院&美团)
在自动驾驶系统当中,感知作为自动驾驶车辆检测周围静态和动态障碍物的重要途径,其准确性和稳定性的重要程度不言而喻。然而,当自动驾驶汽车在开放场景中行驶时,准确和稳定的感知模块变得尤其具有挑战性,因为它们必须检测看不见的或不规则的物体。
最近,由于占用预测具有更加细粒度的通用感知能力,它在自动驾驶系统的感知和规划流程中引起了越来越广泛的关注。虽然占用预测网络相比于原有的3D障碍物感知算法具有更加细粒度和通用的感知能力,但是占用预测网络需要确定当前感知的3D场景中每个体素的状态,这会导致感知模型开发过程中对计算和内存的需求很高。
基于栅格预测的相关优势以及现有存在的诸多不足,我们的核心思路是提高基于BEV空间的占用预测的性能,同时减少参数数量和计算成本。考虑到先前的研究工作中强调了Transformers算法模型在长距离建模方面的优势,但它们的计算负担也非常的大。最近,状态空间模型 (SSM)(例如 Mamba)已成为长距离建模的更有效解决方案。这一发展促使我们探索状态空间模型在改进占用预测任务方面的潜力。
因此,本文提出了一种基于Mamba框架的新型占用率预测方法,旨在实现轻量级,同时提供高效的远距离信息建模,我们称之为MambaOcc算法模型。
论文链接:https://arxiv.org/pdf/2408.11464
网络模型的整体架构&细节梳理
在详细介绍本文提出的MambaOcc算法模型的技术细节之前,下图展示了我们提出的MambaOcc算法的整体网络结构。通过下图可以看出,MambaOcc算法模型主要包括四个模块,分别是基于Mamba的图像主干网络用于图像特征的提取,用于获取BEV形式特征和聚合多帧特征的视角转换模块以及时间融合模块,带有自适应局部重排模块LAR-SS2S混合BEV编码器模块以及占用预测头模块。
MambaOcc算法模型的整体网络结构
整体而言,我们采用四种方向的视觉Mamba来提取图像特征。同时为了减轻与3D体素相关的高计算负担,我们使用BEV特征作为占用预测的中间特征表示,并设计了结合卷积层和Mamba层的混合BEV编码器。考虑到Mamba架构在特征提取过程中对标记排序的敏感性,我们引入了一个利用可变形卷积层的局部自适应重新排序模块。该模块旨在动态更新每个位置的上下文信息,使模型能够更好地捕获和利用数据中的局部依赖关系。这种方法不仅可以缓解标记序列相关的问题,还可以通过确保在提取过程中优先考虑相关的上下文信息来提高占用预测的整体准确性。
VM-Backbone(视觉Mamba主干网络)
为了从多视图图像中提取深层特征,我们使用VMamba作为特征提取的主干网络。与卷积神经网络和Transformer网络相比,基于 Mamba的网络架构模型可以高效地捕获上下文信息。Mamba网络框架的核心是选择性状态空间模型,该模型通过线性时变系统定义隐藏状态和输出的更新规则,可以用四个参数,,,表示如下:
其中,和是在时刻的输入、隐藏和输出状态。,是和的离散形式:
在中,值定义为模型的参数,,和的值通过一个由以输入为条件的投影层生成:
其中,是系统的参数,,和是映射层,是softplus函数。S6和序列化的操作一起构成了至关重要的SS2D模块。为了获得输入的token序列,多视角的图像从四个不同的方向被分成了图像块。序列被独立的喂入到S6模块中,并且S6模块的输出通过重新映射token到2D特征图的方式实现空间上的对齐。这些2D特征被加在一起以融合不同的上下文。
View Transformation and Temporal Fusion(视角转换以及时序融合)
在MambaOcc算法模型中,我们采用LSS算法模型实现从图像平面到BEV平面的空间视图变换。首先,将图像主干网络的输出特征组织成2D格式的地图。然后通过深度预测网络生成每个像素的一系列离散深度。最后,使用体素池化在预定义的BEV平面上聚合每个网格内的深度预测。
在使用了时间域融合的情况下,视角转换模块提供了一种方便的方式融合来自不同视角以及不同时间戳的图像特征。利用来自前几帧的 BEV空间特征,首先基于自车运动信息进行特征转换操作。然后,应用采样和插值操作来生成与当前帧BEV空间特征图对齐的特征。最后,将对齐的特征合并到一起来实现融合时序的上下文特征信息。
LAR-SS2D Hybrid BEV Encoder(LAR-SS2D混合BEV编码器)
在BEV空间特征的提取方面,我们首先设计了基于Mamba网络模型的架构,该架构由三个块组成,其中每个块包含两个SS2D组。考虑到 SSM层对序列中token的顺序很敏感,我们进一步探索局部自适应伪重排序机制来优化上下文信息的嵌入。然后使用LAR组替换每个块中的一个SS2D组。
具体而言,给定输入的序列,如果我们定义的索引函数代表重新排序的规则,然后重新排序的序列可以用如下的形式进行表达:
对于严格的重排机制,是从的双映射,表示原来位于位置的元素的新位置。考虑到BEV特征的局部相关性,我们对上述重排序过程做了如下三点修改,并提出了伪重排序机制,具体细节如下所示。
首先,我们将排序函数设置为一个可学习的模型,该模型以作为输入。即排序结果由模型参数和输入的特征共同决定
其次,考虑到直接从输入数据生成全局重排序结果是比较困难的,我们改为引入映射锚点,其中的生成由锚定。具体来说,锚点用于学习相对位置偏移,然后用于构建置换函数。置换函数可以表示为如下的形式:其中,代表的原始位置,代表用于学习相对位置的偏移
然后,我们将的映射从双射放宽到单射,从而允许重新排序后的序列中不同位置的元素源自原始序列中的相同元素
通过上述的修改,我们建立了一个灵活的局部伪重排序机制。此外,所提出的重排序过程可以通过可变形卷积算子高效实现,从而确保较高的计算效率并保持较快的处理速度。
除了上面描述的一对一映射之外,我们还提出了多对一映射过程。这种方法聚合了原始序列中多个位置的特征,并将它们映射到新序列中的单个位置。为了整合来自多个位置的特征,我们采用注意力机制来自适应地融合这些特征,从而使模型能够专注于最相关的信息。为了更好地捕捉位置关系,我们在LAR和SS2D组中引入了位置嵌入。
Occupancy预测头(Occupancy Prediction Head)
我们采用了FlashOcc算法当中的实现思路,我们同样使用了channel-to-height操作从生成的BEV特征图的通道维度当中恢复出高度信息。这个过程允许我们在整个网络的最后来获得3D占用的特征表达。随后,我们使用线性层来预测3D空间中每个位置的类别,从而提供整个3D空间中详细完整的占用预测信息。
实验结果&评价指标与其它SOTA算法的对比试验
为了验证我们提出的MambaOcc算法模型的有效性,我们在Occ3D-nuScenes数据集上进行了相关实验,相关的实验结果如下表所示。
不同算法模型在Occ3D-nuScenes数据集上的结果汇总
通过实验结果可以看出,与最先进的方法相比,我们提出的MambaOcc算法模型在计算效率和参数数量方面具有更加显著的优势。与以Swin-Transformer为主干网络的FlashOcc算法模型相比,MambaOcc取得了更好的性能,同时减少了42%的参数和39%的计算成本。此外,MambaOcc-Large比FlashOcc高出了0.77的mIoU,减少了14%的参数和32%的计算成本。与以ResNet-101为主干网络的PanoOcc算法相比,MambaOcc的性能高出1.23 mIoU,同时减少了19%的参数。这些结果均表明,与基于CNN和Transformer的方法相比,所提出的Mamba框架在参数量、计算效率和感知能力方面具有显著优势。
此外,为了更加直观的展示我们提出的MambaOcc算法模型的有效性,下图可视化了MambaOcc算法模型占用预测的结果。如图所示,MambaOcc可以为人类和车辆等典型物体提供精确的感知结果,同时还能有效检测电线杆、交通灯和路锥等结构不规则的物体。
MambaOcc算法模型的占用预测结果可视化
此外,为了直观的展示我们提出的MambaOcc和FlashOcc预测占用的效果对比,我们也对两个模型的结果进行了可视化,如下图所示。
MambaOcc与FlashOcc结果可视化对比
通过可视化两个模型的预测结果对比可以看出,MambaOcc算法模型在长距离平面感知方面的卓越性能,能够提供更全面的地面预测,而FlashOcc算法模型通常会将这些区域预测为空。
消融对比实验
为了清楚地展示提出的MambaOcc算法模型中每个组件的贡献,我们在下表中展示了我们进行的消融研究结果,以强调每个模块的有效性。
通过汇总的消融实验结果可以看出,用Mamba网络结构替换CNN网络架构,可使mIoU显著增加3.96,凸显了Mamba网络架构的有效性。此外,我们提出的LAR-SS2D BEV编码器模块比基于CNN的编码器额外增加了1.12的mIoU。此外,通过结合位置编码,可以进一步提高模型的预测性能。
此外,我们也进行了相关实验来验证不同的图像主干网络初始化方法对于网络模型占用预测的影响效果,相关的实验结果如下表所示。
通过实验结果可以明显的看出,良好的参数初始化方法会显著影响性能。使用ImageNet分类预训练初始化占用预测网络与随机初始化相比,对于Mamba和卷积网络,效果明显更好。例如与使用随机值初始化的相比,使用ImageNet预训练的VM-Backbone的MambaOcc在mIoU方面的性能高出10.01。
我们也对不同的BEV编码器对于占用预测任务的影响进行了相关的实验,实验结果汇总在下表所示。
如上表所示,BEV编码器的结构显著影响了占用预测性能。纯SS2D优于纯CNN,mIoU指标提高了0.56。混合CNN-SS2D网络架构的性能优于纯CNN和纯SS2D的网络架构,mIoU分别提高了0.77和0.21。所提出的LAR-SS2D混合架构取得了最佳效果,比CNN-SS2D混合架构高出0.48 mIoU。
除此之外,我们比较了LAR层中不同映射方法的效果。对于多对一映射,我们使用不同的条目数3×3和5×5进行了实验,其中原始序列中多个位置的信息在映射到新序列中的相同位置之前进行加权和融合。相关的实验结果汇总在下表中。
通过表格结果可以看出,多对一映射方法优于一对一方法。具体而言,与一对一方法相比,5×5和3×3配置分别将性能提高了0.07和0.32 mIoU,表明多对一映射可以成为提高性能的有效策略。
为了更全面地了解映射模式,我们对每个LAR层应用了四种不同的映射模式,并在分组特征通道中执行这些模式。相关的结果分别可视化在下图。
Group0 & 1的可视化结果
Group 2 & 3的可视化结果
我们观察到,不同群体之间的映射模式存在显著差异,这表明这种多样性可能有助于模型在元素之间建立更全面的联系。
结论
在本文中,我们提出了首个基于Mamba的占用预测网络模型,我们命名为MambaOcc。与基于Transformer网络模型的方法相比,MambaOcc超越了基于CNN的方法,并且实现了更好的检测效率。
#ThinkGrasp
波士顿动力最新!通过GPT-4o完成杂乱环境中的抓取工作
在杂乱的环境中,由于遮挡和复杂的物体排列,机器人抓取仍然是一个重大的挑战。ThinkGrasp是一个即插即用的视觉语言抓取系统,它利用GPT-4o的高级上下文推理能力,为杂乱环境制定抓取策略。ThinkGrasp能够有效地识别和生成目标物体的抓取姿态,即使它们被严重遮挡或几乎看不见,也能通过使用目标导向的语言来指导移除遮挡物。这种方法逐步揭露目标物体,并最终在几步内以高成功率抓取它。在模拟和真实实验中,ThinkGrasp均取得了高成功率,并在杂乱环境或各种未见过的物体中显著优于最先进的方法,展示了强大的泛化能力。
行业背景介绍
近年来,机器人抓取领域取得了显著进展,深度学习和视觉语言模型推动了更加智能和适应性强的抓取系统的发展。然而,在高度杂乱的环境中,机器人抓取仍然是一个重大挑战,因为目标物体经常被严重遮挡或完全隐藏。即使是最先进的方法也难以在这种场景下准确识别和抓取物体。
为了应对这一挑战,这里提出了ThinkGrasp,它将大规模预训练的视觉语言模型的强大功能与遮挡处理系统相结合。ThinkGrasp利用像GPT-4o这样的模型的先进推理能力,来获得对环境和物体属性(如锐利度和材料组成)的视觉理解。通过基于结构化提示的思维链整合这些知识,ThinkGrasp可以显著提高成功率,并通过战略性地消除遮挡物来确保抓取姿态的安全性。例如,它优先处理较大且位于中央的物体,以最大化可见性和可接近性,并专注于抓取最安全、最有利的部分,如手柄或平面。与依赖RoboRefIt数据集进行机器人感知和推理的VL-Grasp不同,ThinkGrasp受益于GPT-4o的推理和泛化能力。这使得ThinkGrasp能够直观地选择正确的物体,并在复杂环境中实现更高的性能,正如对比实验所示。
主要贡献如下:
• 开发了一个即插即用的遮挡处理系统,该系统高效地利用视觉和语言信息来辅助机器人抓取。为了提高可靠性,利用LangSAM和VLPart实现了一个健壮的错误处理框架用于分割。GPT-4o提供目标物体的名称,LangSAM和VLPart负责图像分割。这种任务分工确保了语言模型中的任何错误都不会影响分割过程,从而在多样化和杂乱的环境中实现更高的成功率和更安全的抓取姿态。
• 在模拟环境中,通过对具有挑战性的RefCOCO数据集进行了广泛的实验,展示了最先进的性能。ThinkGrasp在杂乱场景中的成功率达到98.0%,并且所需步骤更少,优于先前的方法,如OVGNet(43.8%)和VLG(75.3%)。尽管存在未见过的物体和严重的遮挡情况,目标物体几乎不可见或完全不可见,但ThinkGrasp仍然保持了78.9%的高成功率,展现了其强大的泛化能力。在现实世界中,系统也实现了高成功率,并且所需步骤较少。
• 系统的模块化设计使其能够轻松集成到各种机器人平台和抓取系统中。它与6自由度两指夹爪兼容,展示了强大的泛化能力。通过简单的提示,它能够快速适应新的语言目标和新型物体,使其具有高度灵活性和可扩展性。
相关工作介绍
杂乱环境中的机器人抓取:由于遮挡的复杂性和物体的多样性,杂乱环境中的机器人抓取仍然是一个重大挑战。传统方法严重依赖于手工特征和启发式算法,在多样化、非结构化环境中的泛化能力和鲁棒性方面存在困难。使用卷积神经网络(CNNs)和强化学习(RL)的深度学习方法在抓取规划和执行方面表现出改进。然而,这些方法通常需要收集和标记大量数据,这使得它们在各种情况下的实用性降低。最近的方法,如NG-Net和Sim-Grasp,在杂乱环境中取得了进展。然而,这些方法在处理具有多样物体的严重杂乱情况时仍然存在局限性。
用于机器人抓取的预训练模型:视觉语言模型(VLMs)和大型语言模型(LLMs)通过整合视觉和语言信息,在增强机器人抓取方面展现出了潜力。如CLIP和CLIPort等模型提高了任务性能,VL-Grasp为杂乱场景开发了交互式抓取策略。此外,像ManipVQA、RoboScript、CoPa和OVAL-Prompt这样的模型使用视觉语言模型和上下文信息来提高抓取任务的性能。Voxposer和GraspGPT展示了LLMs如何生成与任务相关的动作和抓取策略。尽管有这些进展,但它们并没有考虑到严重的遮挡情况,从而导致其有效性受到限制。
ThinkGrasp方法介绍
在严重杂乱的环境中,机器人抓取面临着由于遮挡和多个物体的存在而带来的重大挑战。主要问题在于:为自然语言指令指定的目标物体设计合适的抓取姿态。
一个显著的挑战是遮挡,即物体常常被其他物品部分或完全遮挡,这使得机器人难以识别和抓取目标物体。另一个问题是自然语言指令的模糊性。这些指令可能含糊不清,需要机器人准确解读用户的意图,并在众多可能性中识别出正确的物体。此外,环境的动态性意味着抓取策略必须随着物体位置和方向的变化实时调整。确保安全性和稳定性至关重要,因为抓取姿态不仅要可行,而且要稳固,以避免损坏物体或机器人。效率也至关重要,因为减少实现成功抓取所需步骤的数量可以使过程更快、更有效。
为了克服这些挑战,我们需要一个系统,该系统能够准确理解环境、解释自然语言命令、即使目标物体部分遮挡也能定位、根据当前环境调整其抓取方式、确保安全稳定的抓取,并高效运行以用最少的努力完成任务。
提出的方法通过一个迭代流程(图1)解决了杂乱环境中抓取的战略部分。给定一个初始的RGB-D场景观测O0(模拟中为224×224,真实机器人为640×480)和一个自然语言指令g。
首先,系统利用GPT-4o执行我们称之为"想象分割"的过程。在这个过程中,GPT-4o将视觉场景和自然语言指令g作为输入。GPT-4o将生成视觉理解和分割假设,识别出与给定指令最匹配的潜在目标物体或部分。对于每个识别的物体,GPT-4o通过想象最优分割并在3×3网格内提出具体的抓取点,来建议最合适的抓取位置。
GPT-4o利用目标语言条件来识别当前场景中的潜在物体。然后,它确定哪个物体在移动后最有可能揭示目标物体,或者如果目标物体已经可见,则直接选择目标物体作为目标。它根据视觉输入和语言指令来想象分割后的物体,利用3×3网格方法,专注于对抓取来说最安全、最有利的物体部分。3×3网格策略将包含提议的目标物体或部分的裁剪框划分为3×3网格,并建议一个1到9之间的数字,指示最优抓取区域(1代表左上角,9代表右下角)。这种策略特别适用于低分辨率图像,它侧重于选择最优区域而不是精确的点,同时也考虑了机械臂和夹爪成功抓取的约束条件。
接下来,系统根据GPT-4o识别的是物体还是物体部分,使用LangSAM 或VLPart 进行分割,并裁剪包含这些物体的点云。GPT-4o将在每次抓取后根据新的视觉输入调整其选择,更新其"想象分割"以及对目标物体和首选抓取位置的预测,使用裁剪后的点云。
为了确定最优抓取姿态,系统基于裁剪后的点云生成一组候选抓取姿态A。为了验证我们的系统,我们在实验中保持变量一致。使用不同的抓取生成网络进行模拟和真实机器人测试。具体来说,我们在所有模拟比较中使用Graspnet-1Billion ,而在真实机器人比较中使用FGC-Graspnet 。这种方法确保了我们的结果是可靠的,并且观察到的任何差异都归因于抓取系统本身,而不是抓取生成网络的不一致性。候选抓取姿态A根据其接近GPT-4o建议的首选位置的程度以及各自抓取生成模块的抓取质量评分进行评估。系统对选定的目标执行最优姿态。
这个闭环过程展示了系统的适应性,它根据每次抓取尝试后的更新场景观测生成下一个抓取策略。该流程根据需要调整其抓取策略,直到任务成功完成或达到最大迭代次数。它有效地管理了严重杂乱环境带来的挑战。
1)GPT-4o在目标物体选择中的角色与约束求解器
我们的抓取系统利用GPT-4o这一最先进的视觉语言模型(VLM),无缝集成视觉和语言信息。GPT-4o在上下文推理和知识表示方面表现出色,使其特别适用于杂乱环境中的复杂抓取任务。
目标物体选择:GPT-4o在识别与给定指令最匹配的物体方面表现出色,有效地关注相关区域并避免无关选择,即使在没有深度信息的情况下也是如此。这确保了系统不会尝试抓取不太可能隐藏目标物体的物体。例如,在图2中,左上角的小包裹被正确地忽略,因为它下面很可能没有任何隐藏物。
在目标物体选择过程中,GPT-4o使用语言指令g和场景上下文来选择最相关的物体。它考虑诸如物体与指令的相关性、抓取的难易程度以及潜在的障碍物等因素。这种有针对性的方法通过优先考虑最有可能导致任务成功完成的物体,确保了抓取的高效性和有效性。
该过程可以表述为:

其中,是选定目标物体的颜色和名称,g是语言指令,是场景的颜色观测值,表示选择函数,该函数评估在指令和场景背景下每个物体o的适用性。
处理遮挡和杂乱:GPT-4o策略性地识别和选择物体,即使在物体被严重遮挡或部分可见时也能确保准确抓取。系统智能地移除遮挡物以提高可见性和抓取准确性。
2)3×3网格策略用于最优抓取部分选择
3×3网格策略通过从选择精确点转变为在3×3网格内选择最优区域,增强了系统处理低分辨率图像(224×224)的能力。这种转变利用了更广泛的上下文信息,即使像素密度较低,也使抓取选择过程更加健壮和可靠。网格将目标物体(由分割算法得分最高的输出得出的边界框表示)划分为九个单元格。每个单元格都根据安全性、稳定性和可访问性进行评估。GPT-4o根据其对物体的想象分割,在此网格内输出一个优选的抓取位置,指导后续的分割和姿态生成步骤。
与依赖单一最佳抓取姿态选择的传统方法不同,我们的系统首先根据它们与优选位置的接近程度评估多个潜在的抓取姿态(前k名)。然后,从这些顶级候选者中,选择得分最高的姿态。这种方法与3×3网格策略相结合,以确定最优抓取区域,确保了所选抓取姿态既是最优的又是稳定的,从而显著提高了整体性能和成功率。
3)目标物体分割与裁剪区域生成
分割与裁剪:在我们的系统中,当GPT-4o识别出一个物体时,使用LangSAM框架来生成精确的分割掩码和边界框,这对于分割低分辨率图像特别有效。当GPT-4o识别出物体的特定部分(如手柄)时,利用VLPart进行详细的部件分割。如果VLPart无法准确分割该部件,会退回到LangSAM与3×3网格策略相结合,以确保我们的方法仍然能够准确地考虑和处理物体部件。
抓取姿态生成:为了确定最优抓取姿态Pg,系统基于裁剪后的点云生成一组候选抓取姿态A。候选抓取姿态A根据它们与GPT-4o建议的优选位置的接近程度以及各自抓取生成模块的抓取质量分数进行评估。经过评估后,得分最高的抓取姿态被选为最优抓取姿态。
鲁棒性和错误处理:尽管GPT-4o具有先进的功能,但偶尔也可能发生误识别。为了解决这个问题,采用迭代细化方法。如果抓取尝试失败,系统会捕获新图像,更新分割和抓取策略,并再次尝试。这种闭环过程确保了基于实时反馈的持续改进,从而显著提高了鲁棒性和可靠性。
消融实验(表1)表明,当我们将LangSAM与GPT-4o结合用于抓取点选择时,与单独使用GPT-4o相比,系统性能显著提高。通过将GPT-4o的上下文理解与LangSAM的精确分割和VLPart的详细部件识别相结合,我们的系统实现了更高的成功率和更高的效率。这种协同作用确保了更准确的抓取和更复杂场景的更佳处理。
4)抓取姿态生成与选择
候选抓取姿态生成:使用局部点云,系统生成一组候选抓取姿态:
抓取姿态评估:使用一种分析计算方法对每个抓取进行评分。基于来自GraspNet-1Billion的改进力封闭度量标准,通过逐渐将摩擦系数µ从1减小到0.1(直到抓取不再是对极的)来计算得分。摩擦系数µ越低,成功抓取的概率越高。我们的得分s定义为:
每个候选抓取姿态都根据其与优选抓取位置的对齐程度进行评估。通过最大化一个考虑每个姿态适用性的得分函数来选择最优抓取姿态:
5)针对重度杂乱环境的闭环鲁棒系统
我们的系统通过闭环控制机制增强了在重度杂乱环境中的鲁棒性,该机制在每次抓取尝试后都会不断更新场景理解,确保使用最新的信息。裁剪区域和抓取姿态会根据实时反馈进行动态调整,从而使系统能够专注于最相关的区域并选择最优抓取姿态。
如图2所示,图像序列展示了根据用户指令选择目标物体的过程。首先,用户给出目标物体"芒果"并输入命令"给我一个水果"。初始的彩色输入图像来自模拟。GPT-4o根据提示选择一个物体(例如绿色瓶子)和一个优选位置,并将其分割成3×3网格。这些信息将被传递给LangSAM进行分割。LangSAM将图像中所有绿色瓶子进行分割,并裁剪出包含所有绿色瓶子的点云。然后,它在裁剪后的点云中生成所有可能的抓取姿态。具有最高LangSAM分割得分的姿态被选为目标物体。目标点是GPT-4o提供的优选物体位置的中心。然后,系统评估距离目标点最近的前10个姿态,并选择得分最高的姿态,最后在绿色瓶子上执行该姿态。即使GPT-4o的初步选择与目标不匹配(例如选择瓶子而不是芒果),由于颜色特征的明显差异,LangSAM的分割和评分过程也会纠正错误并锁定在目标物体上。
实验对比分析
我们的系统设计用于在模拟和现实世界环境中都能有效工作,并针对每个环境的独特挑战和限制进行了量身定制的适应。
模拟环境使用PyBullet构建,包括一个UR5机械臂、一个ROBOTIQ-85夹爪和一个Intel RealSense L515相机。原始图像被调整为224×224像素,并通过LangSAM进行分割以获得精确的对象掩码。我们将解决方案与最先进的方法Vision-Language Grasping (VLG)和OVGrasp进行了比较,这些方法使用相同的GraspNet主干以确保公平比较。此外,还将我们的方法与直接使用GPT-4o选择目标抓取点而不进行额外处理或与其他模块集成的方法进行了比较。
我们的杂乱环境实验集中在各种任务上,如抓取圆形物体、取用餐具或饮料等物品,以及其他特定请求。每个测试用例包括15次运行,通过两个指标来衡量:任务成功率和动作次数。任务成功率是指在15次测试运行中,在15次动作尝试内成功完成任务的平均百分比。动作次数是指每完成任务一次所需的平均动作数。
结果。表1总结了结果,表明我们的系统在整体成功率和效率指标上显著优于基线方法。在杂乱环境中的平均成功率为0.980,平均步数为3.39,平均成功步数为3.32(如图3所示)。这些结果表明,我们的系统不仅在完成抓取任务方面表现出色,而且效率更高,成功完成任务所需的步数更少。
还评估了系统在重度杂乱场景中的性能,其中物体被部分或完全遮挡。这些场景(如图4所示)包含多达30个未见过的物体,并且每次运行允许最多50次动作尝试。表1中的结果表明,在这些具有挑战性的条件下,我们的系统显著优于基线方法,实现了最高的成功率2,并且成功抓取所需的步数最少。
消融研究。为了评估我们系统中不同组件的贡献,这里进行了消融研究。这些消融研究的结果如表1所示,研究突出了我们完整系统的有效性。一种配置标记为"无3×3",它不会将对象分割为3×3网格来选择抓取点,而是使用对象边界框的中心。另一种配置"GPT裁剪"使用GPT-4o来确定点云的裁剪坐标,从而专注于与抓取相关的区域。"无GPT4o"配置则完全排除了GPT-4o的使用。这些实验表明,我们集成了所有组件的完整系统实现了优越的性能,证明了每个部分在提升整体有效性方面的重要性。
真实世界场景实验
我们将系统的功能扩展到现实世界环境中,以处理复杂多变的场景。设置包括一个具有6个自由度的UR5机械臂和一个Robotiq 85夹爪。使用RealSense D455相机捕获观测数据,提供用于点云构建的彩色和深度图像。使用MoveIt运动规划框架和RRT*算法确定抓取的目标姿态。ROS管理通信,运行在一台配备12GB 2080Ti GPU的工作站上。我们的ThinkGrasp模型部署在具有双3090 GPU的服务器上,使用Flask,通过GPT-4o API在10秒内提供抓取姿态预测。
在我们的现实世界实验中,将系统与VL-Grasp进行了比较,使用了相同的FGCGraspNet下游抓取模型,以确保对我们的战略部分抓取和重度杂乱处理机制引入的改进进行公平评估。
结果。我们的结果(表3)表明,即使在杂乱的环境中,系统在识别和抓取目标物体方面也具有较高的成功率。VLPart和GPT-4o的集成显著提高了系统的鲁棒性和准确性。然而,由于单幅图像数据的局限性、下游模型产生的低质量抓取姿态以及UR5机器人稳定性和控制的差异,也发生了一些失败情况。这些失败凸显了稳健的图像处理对于确保准确的场景解释、精确的抓取姿态生成以提高成功率以及稳定的机器人控制操作的重要性。解决这些因素对于进一步提升系统性能至关重要。附录(表A)中提供了更多技术细节和实验设置。
#OmniRe
仿真迎来终局?上交&英伟达提出OmniRe:性能直接拉爆StreetGS四个点!!!
自动驾驶仿真重建的终局???上交和英伟达等团队最新的工作OmniRe,性能直接拉爆了一众算法,PSNR超越StreetGS四个多点!!!可谓是3DGS的集大成者。具体来说,OmniRe将动态目标分为刚体和非刚体,车辆和行人/骑行人的步态重建的性能非常惊艳!背景是比较常见的background+sky。静态要素的重建效果也非常棒,像红绿灯,车道线等等。
写在前面&笔者的个人理解
本文介绍了OmniRe,这是一种高效重建高保真动态城市场景的整体方法。最近使用神经辐射场或高斯splatting对驾驶序列进行建模的方法已经证明了重建具有挑战性的动态场景的潜力,但往往忽视了行人和其他非车辆动态参与者,阻碍了动态城市场景重建的完整流程。为此,我们提出了一种用于驾驶场景的全面3DGS框架,称为OmniRe,它允许对驾驶过程中的各种动态目标进行准确、完整的重建。OmniRe基于高斯表示构建动态神经场景图,并构建多个局部规范空间,对各种动态参与者进行建模,包括车辆、行人和骑行人等。这种能力是现有方法无法比拟的。OmniRe允许我们全面重建场景中存在的不同目标,随后能够实时模拟所有参与者参与的重建场景(~60 Hz)。对Waymo数据集的广泛评估表明,我们的方法在定量和定性上都大大优于先前最先进的方法。我们相信,我们的工作填补了推动重建的关键空白。
项目主页:https://ziyc.github.io/omnire/
文章简介
随着自动驾驶越来越多地采用端到端模型,对可扩展且无域差异的仿真环境的需求变得更加明显,这些环境可以在闭环仿真中评估这些系统。尽管使用艺术家生成资源的传统方法在规模、多样性和逼真度方面达到了极限,但数据驱动方法在生成数字孪生体方面的进展,通过从设备日志中重建仿真环境,提供了强有力的替代方案。确实,神经辐射场(NeRFs)和高斯点云(GS)已经成为重建具有高视觉和几何保真度的3D场景的强大工具。然而,准确且全面地重建动态驾驶场景仍然是一个重大挑战,特别是由于现实环境中多样化的参与者和运动类型的复杂性。
已经有若干工作尝试解决这一挑战。早期的方法通常忽略动态参与者,仅专注于重建场景的静态部分。后续的工作则旨在通过以下两种方式之一来重建动态场景:(i) 将场景建模为静态和时间依赖的神经场的组合,其中不同场景部分的分解是一种自发属性,或者(ii) 构建一个场景图,其中动态参与者和静态背景被表示为节点,并在其标准框架中重建和表示。场景图的节点通过编码相对变换参数的边连接,这些参数表示每个参与者随时间的运动。尽管前者是一种更通用的公式化方法,后者提供了更高的可编辑性,并且可以直接用经典行为模型进行控制。然而,场景图方法仍然主要关注可以表示为刚体的车辆,从而在很大程度上忽略了其他在驾驶仿真中至关重要的易受伤害的道路使用者(VRUs),如行人和骑自行车者。
为了填补这一关键空白,本文的工作旨在对所有动态参与者进行建模,包括车辆、行人和骑自行车者等。与在工作室中使用多视角系统建模目标不同,从室外场景中重建动态参与者极具挑战性。以人类为例,从部分观察中重建人类本身就是一个具有挑战性的问题,在驾驶场景中,由于传感器观察分布不利、环境复杂且频繁遮挡,这一问题变得更加复杂。事实上,即使是最先进的人体姿态预测模型,也常常难以预测出准确的姿态,特别是对于那些距离较远或被其他物体遮挡的行人(例如图3)。此外,还有其他动态参与者,如轮椅上的个人或推婴儿车的人,这些都无法简单地用参数化模型来进行建模。
为了应对这些相互强化的挑战,本文提出了一个能够处理多样化参与者的"全景"系统。本文的方法OmniRe高效地重建了包含静态背景、驾驶车辆和非刚性运动动态参与者的高保真动态驾驶场景(见图1)。具体来说,本文基于高斯点云表示构建了一个动态神经场景图,并为不同的动态参与者构建了专用的局部标准空间。遵循"因材施教"的原则,OmniRe利用了不同表示方法的集体优势:(i) 车辆被建模为静态高斯,通过刚体变换模拟其随时间的运动;(ii) 近距离行走的行人使用基于模板的SMPL模型进行拟合,通过线性混合蒙皮权重(linear blend skinning weights)实现关节级控制;(iii) 远距离和其他无模板的动态参与者则使用自监督变形场(deformation fields)进行重建。这种组合允许对场景中大多数感兴趣的目标进行准确表示和可控重建。更重要的是,本文的表示方法可以直接适用于自动驾驶仿真中常用的行为和动画模型(例如图1-(c))。总结来说,本文的主要贡献如下:
本文提出了OmniRe,这是一种动态驾驶场景重建的整体框架,在参与者覆盖和表示灵活性方面体现了"全景"原则。OmniRe利用基于高斯表示的动态神经场景图来统一重建静态背景、驾驶车辆和非刚性运动的动态参与者(第4节)。它能够实现高保真的场景重建,从新视角进行传感器仿真,以及实时可控的场景编辑。
本文解决了从驾驶日志中建模人类和其他动态参与者所面临的挑战,例如遮挡、复杂环境以及现有人体姿态预测模型的局限性。本文的研究结果基于自动驾驶场景,但可以推广到其他领域。
本文进行了大量实验和消融研究,以展示本文整体表示方法的优势。OmniRe在场景重建和新视点合成(NVS)方面达到了最先进的性能,在完整图像指标上显著超越了以往的方法(重建提高了1.88的PSNR,NVS提高了2.38的PSNR)。对于动态参与者,如车辆(提高了1.18的PSNR)和人类(重建提高了4.09的PSNR,NVS提高了3.06的PSNR),差异尤为显著。
相关工作回顾
动态场景重建。神经表征是主导的新视角合成。这些已经以不同的方式进行了扩展,以实现动态场景重建。基于变形的方法和最近的DeformableGS提出使用规范空间的3D神经表示来对动态场景进行建模,并结合将时间依赖观测值映射到规范变形的变形网络。这些通常仅限于运动受限的小场景,不足以应对具有挑战性的城市动态场景。基于调制的技术通过直接将图像时间戳(或潜码)作为神经表示的额外输入来操作。然而,这通常会导致公式构建不足,因此需要额外的监督,例如深度和光流(Video NeRF和NSFF),或从同步相机捕获的多视图输入(DyNeRF和Dynamic3DGS)。D2NeRF提出通过将场景划分为静态和动态场来扩展这一公式。在此之后,SUDS和EmerNeRF在动态自动驾驶场景中表现出了令人印象深刻的重建能力。然而,它们使用单个动态场对所有动态元素进行建模,而不是分别建模,因此它们缺乏可控性,限制了它们作为传感器模拟器的实用性。将场景显式分解为单独的代理可以单独控制它们。这些代理可以表示为场景图中的边界框,如神经场景图(NSG),该图在UniSim、MARS、NeuRAD、ML-NSG和最近的基于高斯的作品StreetGaussians、DrivingGaussians和HUGS中被广泛采用。然而,由于时间无关表示的限制或基于变形的技术的限制,这些方法仅处理刚性目标。为了解决这些问题,OmniRe提出了一种高斯场景图,该图结合了刚性和非刚性目标的各种高斯表示,为各种参与者提供了额外的灵活性和可控性。
人体重建。人体具有可变的外观和复杂的运动,需要专门的建模技术。NeuMan建议使用SMPL身体模型将射线点扭曲到规范空间。这种方法能够重建非刚性人体,并保证精细控制。同样,最近的研究,如GART、GauHuman和HumanGaussians,将高斯表示和SMPL模型相结合。然而,这些方法在野外并不直接适用。然而,这些方法仅关注形状和姿态估计,在外观建模方面存在局限性。相比之下,我们的方法不仅对人体外观进行建模,还将这种建模整合到一个整体的场景框架中,以实现全面的解决方案。城市场景通常涉及众多行人,观察稀少,通常伴随着严重的遮挡。
OmniRe方法详解
如图2所示,OmniRe构建了一个高斯场景图表示,它全面覆盖了静态背景和各种可移动实体。
Dynamic Gaussian Scene Graph Modeling
Gaussian Scene Graph:为了在不牺牲重建质量的情况下灵活控制场景中的各种可移动目标,本文选择高斯场景图表示。我们的场景图由以下节点组成:(1)一个表示远离自车的天空的天空节点,(2)一个代表建筑物、道路和植被等静态场景背景的背景节点,(3)一组刚性节点,每个节点代表一个可刚性移动的物体,如车辆,(4)一组模拟行人或骑行人的非刚性节点。类型为(2,3,4)的节点可以直接转换为世界空间高斯分布。这些高斯分布被连接起来,并使用17中提出的光栅化器进行渲染。天空节点由一个优化的环境纹理贴图表示,单独渲染,并与具有简单阿尔法混合的光栅化高斯图像组成。
Background Node:背景节点由一组静态高斯表示。这些高斯是通过累积激光雷达点和随机生成的额外点来初始化的。
Rigid Nodes:刚性目标由该目标的局部空间和车辆位姿表示。
Non-Rigid Nodes:与刚性车辆不同,行人和骑行人等非刚性动态类都与人类有关,需要额外考虑他们在世界空间中的全局运动和在局部空间中的连续变形,以准确重建他们的动态。为了能够完全解释底层几何结构的重建,我们将非刚性节点进一步细分为两类:用于步行或跑步行人的SMPL节点,具有支持关节水平控制的SMPL模板,以及用于分布外的非刚性实例(如骑自行车者和其他无模板的动态实体)的可变形节点。
Non-Rigid SMPL Nodes:SMPL提供了一种表示人体姿态和变形的参数化方法,因此我们使用模型参数来驱动节点内的3D高斯分布。
Non-Rigid Deformable Nodes:这些节点充当分布外非刚性实例的回退选项,例如,即使是最先进的SMPL预测器也无法提供准确估计的极其遥远的行人;或长尾模板较少的非刚性实例。因此,我们建议使用通用的变形网络来拟合节点内的非刚性运动。具体来说,对于节点h,世界空间高斯分布定义为:
Sky Node:同6,47一样,本文使用单独的环境地图来适应观察方向的天空颜色。我们得到的最终渲染结果如下:
Reconstructing In-the-Wild Humans
为了初始化非刚性SMPL节点的参数,我们扩展了一个现成的预测器4D Humans,该预测器根据原始视频输入估计人体姿势。然而它存在几个实际限制,阻碍了它在我们的环境中的可用性。我们通过以下模块讨论并解决这些挑战,以在频繁遮挡的情况下,从野外拍摄的多视图图像中预测准确且时间一致的人体姿势。
Human ID Matching:4D Humans仅设计用于处理单目视频。在我们的环视设置中,这种限制导致同一个人在不同视图之间失去联系(图3(a))。为了解决这个问题,我们使用检测和GT框之间的mIoU将检测到的人的估计姿态与数据集中的GT ID进行匹配,确保在环视中一致地识别出每个行人。
Missing Pose Completion:4D Humans很难预测被占用个体的SMPL姿势,这在自动驾驶场景中很常见,导致预测缺失。我们通过从相邻帧中插值姿势来恢复丢失的姿势。如图3(b)所示,该过程能够为被占用的个体恢复准确的姿势,从而实现暂时完整的姿势序列。
Scene-Pose Alignment:作为一个与相机无关的通用模型,4D Humans假设一个虚拟相机的所有视频输入参数都是固定的。相比之下,真实的相机具有不同的参数。这会导致预测姿势的比例和位置与现实世界坐标系之间的错位。我们使用每个人可用的box大小和位置数据来校正预测姿势的比例和位置。
Pose Refinement:姿态预测器、插值和对齐估计的误差会导致人体姿态噪声。我们利用这些嘈杂的姿态来初始化SMPL节点的动态,并在训练过程中通过优化重建损失来联合细化每个个体的每帧姿态。我们的消融研究表明,人体姿态细化对于提高重建质量和姿态精度至关重要。
整体的训练损失如下:
实验结果
我们使用每10帧作为NVS的测试集,在场景重建和新视图合成(NVS)任务中评估我们的方法。我们报告了完整图像以及与人类和车辆相关区域的PSNR和SSIM评分,以评估动态重建能力。表1中的定量结果表明,OmniRe优于所有其他方法,在与人类相关的区域有显著的优势,验证了我们对动态参与者的整体建模。此外,虽然StreetGS和我们的方法以类似的方式对车辆进行建模,但我们观察到,即使在车辆区域,OmniRe也略优于StreetGS。这是由于StreetGS中缺乏人体建模,这使得来自人体区域的监控信号(如颜色、激光雷达深度)会错误地影响车辆建模。StreetGS面临的问题是我们对场景中几乎所有内容进行整体建模的动机之一,旨在消除错误的监督和意外的梯度传播。
此外,我们在图4中显示了可视化,以定性评估模型性能。尽管PVG在场景重建任务中表现良好,但在高度动态的场景中,它难以完成新颖的视图合成任务,导致新颖视图中的动态目标模糊(图4-f)。HUGS(图4-e)、StreetGS(图4-d)和3DGS(图10-h)无法恢复行人,因为它们无法对非刚性物体进行建模。DeformableGS(图10-g)在具有快速运动的室外动态场景中会出现极端运动模糊,尽管在室内场景和小运动的情况下取得了合理的性能。EmerNeRF在一定程度上重建了移动的人类和车辆的粗略结构,但难以处理精细的细节(图4-c)。与所有这些方法相比,我们的方法忠真实地重建了场景中任何目标的精细细节,处理了遮挡、变形和极端运动。我们建议读者查看我们的项目页面,了解这些方法的视频比较。
几何形状。除了外观,我们还研究了OmniRe是否可以重建城市场景的精细几何。我们评估了训练帧和新帧上激光雷达深度重建的均方根误差RMSE和CD。附录中提供了评估程序的详细信息。表4报告了结果。我们的方法远远优于其他方法。图5显示了与其他方法相比,我们的方法实现的动态参与者的精确重建。
结论
我们的方法OmniRe使用高斯场景图进行全面的城市场景建模。它实现了快速、高质量的重建和渲染,为自动驾驶和机器人模拟带来了希望。我们还为复杂环境中的人体建模提供了解决方案。未来的工作包括自我监督学习、改进的场景表示和安全/隐私考虑。
更广泛的影响。我们的方法旨在解决自动驾驶模拟中的一个重要问题。这种方法有可能加强自动驾驶汽车的开发和测试,从而可能带来更安全、更高效的自动驾驶系统。以安全可控的方式进行模拟仍然是一个开放且具有挑战性的研究问题。
道德与隐私。我们的工作不包括收集或注释新数据。我们使用符合严格道德准则的成熟公共数据集。这些数据集确保敏感信息(包括可识别的人类特征)被模糊或匿名化,以保护个人隐私。我们致力于确保我们的方法以及未来的应用程序以负责任和道德的方式使用,以维护安全和隐私。
限制。OmniRe仍然存在一些局限性。首先,我们的方法没有明确地模拟光照效果,这可能会导致模拟过程中的视觉和谐问题,特别是在组合在不同光照条件下重建的元素时。应对这一不平凡的挑战需要我们在当前工作范围之外做出不懈的努力。对光效建模和增强模拟真实感的进一步研究对于实现更令人信服和和谐的结果仍然至关重要。其次,与其他每场景优化方法类似,当相机明显偏离训练轨迹时,OmniRe会产生不太令人满意的新视图。我们认为,整合数据驱动的先验,如图像或视频生成模型,是未来探索的一个有前景的方向。
#CoVLA
东京大学最新!用于自动驾驶的综合视觉-语言-动作数据集
原标题:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
论文链接:https://arxiv.org/pdf/2408.10845
作者单位:Turing Inc. 东京大学 University of Tsukuba Keio Research Institute at SFC National Institute of Informatics
论文思路:
自动驾驶,特别是在复杂和意外场景中的导航,要求具备复杂的推理和规划能力。虽然多模态大语言模型(MLLMs)在这方面提供了一个有前途的途径,但其应用主要局限于理解复杂的环境上下文或生成高层次的驾驶指令,只有少数研究将其应用扩展到端到端路径规划。一个主要的研究瓶颈是缺乏包含视觉、语言和动作的大规模标注数据集。为了解决这个问题,本文提出了CoVLA(Comprehensive Vision-Language-Action)数据集,这是一个包含超过80小时真实驾驶视频的广泛数据集。该数据集利用了一种基于自动数据处理和描述(caption)生成流程的新颖且可扩展的方法,生成了与详细自然语言描述的驾驶环境和操作相匹配的精确驾驶轨迹。这种方法利用了车内传感器的原始数据,使其在规模和标注丰富性上超越了现有的数据集。使用CoVLA,本文研究了能够在各种驾驶场景中处理视觉、语言和动作的MLLMs的驾驶能力。本文的结果显示了本文的模型在生成连贯的语言和动作输出方面的强大能力,强调了视觉-语言-动作(VLA)模型在自动驾驶领域的潜力。通过提供一个全面的平台用于训练和评估VLA模型,该数据集为构建稳健、可解释和数据驱动的自动驾驶系统奠定了基础,助力于更安全和更可靠的自动驾驶车辆。
主要贡献:
本文介绍了CoVLA数据集,这是一个大规模数据集,提供了多种驾驶场景的轨迹目标,以及详细的逐帧情境描述。
本文提出了一种可扩展的方法,通过传感器融合准确估计轨迹,并自动生成关键驾驶信息的逐帧文本描述。
本文开发了CoVLA-Agent,这是一种基于CoVLA数据集的新型VLA模型,用于可解释的端到端自动驾驶。本文的模型展示了持续生成驾驶场景描述和预测轨迹的能力,为更可靠的自动驾驶铺平了道路。
论文设计:
自动驾驶技术面临的一个关键挑战在于应对多样且不可预测的驾驶环境的"长尾"问题35, 63。自动驾驶车辆不仅需要在常见场景中导航,还必须应对罕见和复杂的情况,这就需要广泛的世界知识和高级推理能力20。这要求对环境有深刻的理解,并且具备超越物体识别的推理能力,能够解释其行为并据此规划行动。视觉-语言-动作(VLA)模型通过无缝整合视觉感知、语言理解和动作规划,已成为实现这一目标的有前途的途径。近期在VLA领域的进展,特别是在机器人4, 28, 40和自动驾驶45方面,展示了其在实现更健壮和智能的驾驶系统方面的潜力。
然而,将VLA模型应用于自动驾驶的一个主要障碍是缺乏有效结合视觉数据、语言描述和驾驶动作的大规模数据集。现有的数据集在规模和全面标注方面往往不足,尤其是语言方面,通常需要繁重的人工工作。这限制了能够处理现实世界驾驶复杂性的健壮VLA模型的发展和评估。
本文介绍了CoVLA(Comprehensive Vision-Language-Action)数据集,这是一个旨在克服现有局限性的新型大规模数据集。CoVLA数据集利用可扩展的自动化标注和描述生成方法,创建了一个包含10,000个真实驾驶场景、总计超过80小时视频的丰富数据集。每个30秒的场景都包含精确的驾驶路径和详细的自然语言描述,这些描述来源于同步的前置相机录像和车内传感器数据。这个丰富的数据集允许对驾驶环境和代理行为进行更深入的理解。为了展示其在推进自动驾驶研究方面的有效性,本文开发了CoVLA-Agent,这是一种基于本文数据集进行训练的VLA模型,用于轨迹预测和交通场景描述生成。本文的研究结果表明,即使在需要复杂和高级判断的情况下,本文的VLA模型也能够做出一致且精确的预测。
本节深入介绍了CoVLA数据集,详细描述了其结构、内容以及用于创建这一宝贵自动驾驶研究资源的方法。本文重点介绍了其对多样化真实世界驾驶场景的覆盖、同步的多模态数据流(前置相机、车内信号及其他传感器)以及大规模标注数据:10,000个驾驶场景,总计超过80小时的视频,每个场景都包含精确的逐帧轨迹和描述标注。为了创建这个广泛的VLA数据集,本文开发了一种新颖且可扩展的方法,从原始数据中自动生成场景描述和真实轨迹。
图1. CoVLA框架概述。本文开发了CoVLA数据集,这是一个用于自动驾驶的综合数据集,包含独特的10,000个视频片段、描述驾驶场景的逐帧语言描述以及未来的轨迹动作。本文还展示了CoVLA-Agent,这是一种基于VLM的路径规划模型,能够预测车辆的未来轨迹,并提供其行为和推理的文本描述。
表1. 含有语言和动作数据的驾驶数据集比较。
图2. 数据集生成 pipeline 概述。本文自动标注视频帧和传感器信号以生成轨迹和其他标签。此外,本文对视频帧应用自动描述生成,以生成行为和推理的描述。
图3. CoVLA数据集的示例帧。显示了估计的轨迹(绿色线)和由描述生成模型生成的描述。关键对象以蓝色粗体文本突出显示,而描述中的错误以红色粗体文本显示。
图4. 车辆速度和转向角的数据分布。红色条表示采样前的分布,而黄色条显示采样后的分布。请注意,为了清晰展示,(b)中使用了对数刻度。
在本节中,本文介绍了基线模型CoVLA-Agent的开发和评估方法,该模型利用CoVLA数据集的丰富性来完成自动驾驶任务。本文详细描述了实验设置,包括数据集、模型配置、训练过程和评估指标,并对结果进行了分析。
架构:如图5所示,CoVLA-Agent是一个为自动驾驶设计的VLA模型。本文使用预训练的Llama-2(7B)52作为语言模型,并使用CLIP ViT-L(224×224像素)43作为视觉编码器。此外,本文的模型将自车速度作为输入,通过多层感知器(MLP)转换为嵌入向量。CLIP ViT-L提取的视觉特征与速度嵌入和文本嵌入拼接在一起,然后输入到Llama-2模型中。对于轨迹预测,使用特殊的 tokens 作为轨迹查询。这些轨迹查询的输出经过MLP层处理,生成10个(x, y, z)坐标的序列,表示车辆相对于当前位置的预测轨迹,覆盖三秒的时间范围。
训练:基于这种架构,本文在两个任务上训练CoVLA-Agent,分别是交通场景描述生成和轨迹预测。对于交通场景描述生成,本文使用交叉熵损失作为损失函数;对于轨迹预测,本文采用均方误差损失。最终,训练的目标是最小化一个组合损失函数,其中两个损失被等权重对待。
图5. CoVLA-Agent的架构。
实验结果:
图6. CoVLA-Agent在各种交通场景下的轨迹预测结果。红线表示在预测描述条件下的预测轨迹,蓝线表示在真实描述条件下的预测轨迹,绿线表示真实轨迹。
表2. 不同条件的定量比较。
表3. 平均ADE和FDE最大的前10个单词。这些单词对应的是从单帧中难以估计的运动。明确表示运动的单词以粗体显示。
总结:
本文介绍了CoVLA数据集,这是一个用于自动驾驶的VLA模型的新型数据集。通过利用可扩展的自动化方法,本文构建了一个大规模、全面的数据集,并丰富了详细的语言标注。基于这个稳健的数据集,本文开发了CoVLA-Agent,这是一种先进的VLA自动驾驶模型。评估结果强调了该模型在生成连贯的语言和动作输出方面的强大能力。这些发现突显了VLA多模态模型的变革潜力,并为未来的自动驾驶研究创新铺平了道路。
#端到端~离不开的仿真闭环
"端到端"(End-to-End)无疑是今年自动驾驶行业最热的关键词,无论是学术圈还是工业圈,这一概念都引起了广泛的关注和讨论。它指的是一种直接将输入数据映射到输出结果的计算模型,无需复杂的中间处理步骤。在自动驾驶领域,这意味着可以通过深度学习算法直接从原始传感器数据(如摄像头图像、雷达信号等)学习到驾驶决策和车辆控制命令,而不需要传统的、基于规则的多层次数据处理流程。下图展示了特斯拉自动驾驶从模块化到端到端深度学习的演进。
图片来源 How Tesla will transition from Modular to End-To-End Deep Learning
端到端的方法在自动驾驶技术中的应用,带来了几个显著的优势。首先,它简化了系统架构,减少了对复杂软件和硬件的需求,从而降低了成本。其次,通过直接从数据中学习,端到端模型能够捕捉到更多的细微模式和复杂关系,这在传统的基于规则的方法中很难实现。此外,这种方法还有助于提高系统的适应性和泛化能力,因为它能够从大量的实际驾驶场景中学习,而不是仅仅依赖于预先定义的规则。
端到端的本质应当是感知信息的无损传递。感知模块输出对环境的检测和识别信息,是对复杂驾驶场景采用人为定义的显式抽象。然而,对于一些边缘场景中,显式抽象很难准确和完整的表达场景中影响自动驾驶表现的所有因素。广义的端到端系统,作用便是存在一种全面的场景表征方法,将信息无损传递到规划控制模块。
为了更好的定义端到端自动驾驶的概念,需要加上明确的描述词,主要分为四个阶段/架构:感知"端到端"、决策规划模型化、模块化端到端、One Model/ 单一模型端到端。
端到端自动驾驶仿真的挑战
当前的量产算法普遍还是采用模块化的算法框架,在测试的时候无论是logsim还是worldsim,都可以针对模块或者模块之间的组合进行测试,仿真或者测试系统能够去构造显示的输入,接收显示的输出进行闭环控制以及结果评价。实车测试验证的成本高昂,针对经典的自动驾驶架构,行业已经有一套行之有效的方案进行模型上车前的测试验证,即感知算法使用回灌数据进行离线开环测试,规控算法基于模拟器进行闭环测试验证。
对于感知"端到端"、决策规划模型化,传统的测试方法依然有效,显示的输出能够被定义和构造。但对于模块化端到端、One Model/ 单一模型端到端,隐示的表达可以被捕捉,但无法评测,也无法构造,这就造成传统方法的失效。在基于数据回灌的开环测试条件下,端到端系统无法与环境交互,系统一旦出现偏离采集路径的操作,后续系统的响应将无法评估。
图片来源Building the Next-Generation of Autonomous Vehicles in Simulation
当然这里的传统测试方法主要指的是SIL,对于HIL而言,现在主流的测试已经是信号级传感器的注入,对完整的功能进行测试验证,端到端的改变并没有很大影响。此外,目前模块化端到端、One Model/ 单一模型端到端还处在一个研发阶段,实际上车还需要很长一段时间。所以本文所讨论的内容,既有落地的方案,也有处在预研阶段的路线。
端到端仿真的技术路线
端到端仿真需要更加真实的传感器输入,尤其是视觉传感器,这是行业的共识。实现高保真模拟的技术路线包括基于光线追踪的游戏引擎、基于三维重建的仿真器以及基于世界模型的仿真器。
基于游戏引擎的仿真器
全球最大最顶尖的端到端算法比赛,即CVPR 2024 Autonomous Grand Challenge,是采用CARLA测试,同时也有基于CARLA的算法比赛项目。CARLA基于Epic Games的虚幻引擎4构建,这意味着它可以生成高保真的3D环境,提供视觉上的真实性,这对于测试车辆感知系统尤其重要。也就是说从技术角度,Carla 这一类基于物理引擎架构的仿真平台在一定程度上可以完成自动驾驶感知端到端模型的训练和测试。
基于三维重建的仿真器
近年来,自动驾驶技术的迅猛发展不断推动着相关领域的技术革新。自ECCV 2020会议上NeRF(神经辐射场)技术的首次亮相,我们见证了三维重建技术跨入了一个全新的发展阶段。NeRF通过先进的深度学习算法,能够从稀疏的二维图像中重建出连续的三维场景,这一突破为自动驾驶领域提供了前所未有的感知能力。
紧接着,SIGGRAPH 2023会议上提出的3DGS(3D高斯泼溅)技术,进一步加速了三维重建技术的发展。3DGS通过更高效的数据处理和更精细的模型构建,使得三维模型的生成更加迅速和准确,为自动驾驶系统提供了更为丰富和细致的环境理解。
清华AIR提出的首个开源自动驾驶NeRF仿真工具MARS,Waabi和多伦多大学在CVPR 2023上的工作汇报中介绍了UniSim,浙大&理想在ECCV 2024上Street Gaussians,一种新的显式场景表示。此外还有GaussianPro、LidaRF等相继被提出。
尽管三维重建的热点不断,但从实际表现来看,局限性比较多,重建效果非常依赖数据,而且当视角与原车视角变换大时,效果不可控。此外,动态场景的添加、场景与车辆的交互、光影的变换,也存在一些实现难点。
基于世界模型的仿真器
2023年2月16日凌晨,OpenAI 发布了视频大模型 Sora,能够根据用户提供的文本描述生成长达 60 秒的视频,视频精准反映提示词内容,复杂且逼真,效果惊艳。广义上,Sora 也属于世界模型的范畴。世界模型也是对物理世界"常识"的理解 。
世界模型可以有效赋能智驾。在自动驾驶领域, 能够准确预测驾驶场景未来的演变至关重要,通过对场景 即将发生的事件进行 预判,汽车可以自如地进行规划和控制做出更明智的决策 。
图片来源World Models for Autonomous Driving: An Initial Survey
采用自回归的模型,将数据压缩和提炼,在潜在空间通过无监督的训练构建模型对未来进行预测,之后通过不同的解码器将预测好的信息解码成为需要的表达方式进而构建世界模型。在自动驾驶领域, 世界模型可以用来生成场景,也可以直接用来做决策规划。具体而言:
- 可以生成诸多逼真的场景 ,生成稀缺、难以采集的场景, 为模型训练提供足量的数据;
- 同样生成的场景亦可以作为仿真测试工具 对算法进行闭环验证;
- 多模态的世界模型亦可以直接生成 驾驶策略来指导自动驾驶行为。
OASIS SIM V3.0如何赋能
端到端仿真
OASIS SIM 3.0是基于游戏引擎的仿真器,也就是技术路线中的第一个。对于端到端的仿真,OASIS SIM能够提供高保真场景模拟与传感器以及高质量、规模化的测试用例场景搭建,提升仿真的置信度以及测试覆盖度。
高保真传感器模型
OASIS SIM V3.0通过精确的物理模型,实现了传感器仿真的高精度模拟,能够实现传感器采集层、模型层、协议层的全流程仿真。摄像头可模拟长焦、广角、鱼眼、双目等各种镜头类型,仿真畸变、运动模糊、晕光、过曝、脏污、噪声等特性。激光雷达模型通过对扫描特性、传播特性进行物理建模,实现运动畸变、 噪声、强度的模拟,可以仿真不同型号的激光雷达,并生成接近真实雷达的点云数据。
摄像头仿真
激光雷达仿真
OASIS SIM将在新版本中使用UE5,使用更加精细的素材以及全新的光照和天气系统,丰富细节,提升真实度。
交通流仿真模型
OASIS SIM V3.0交通流能够在仿真环境中自定义交通流,重现真实世界的交通情景,帮助测试和优化自动驾驶算法。交通流场景控制功能支持基于规则的控制模型以及基于AI的控制模型。基于规则的控制模型能够自动识别并适配不同道路拓扑结构,可以根据周车的交互行为做出相应的驾驶行为,如车辆跟驰、换道、车道侵入、超车、避障、遵守交通规则等,无需预先定义原子场景。
大规模城镇场景程序化建模
OASIS SIM 3.0支持直接导入OpenDrive文件,并自动识别和解析道路网络等关键信息自动化生成三维场景,无需复杂的建模和人工编辑,提高了场景构建的速度和效率。在后续的版本中,会逐渐丰富场景的个性化参数,包括场景的风格、植被的密度、建筑的密度,并添加围栏、路灯、街道障碍物等。虽然建筑等并不是自动驾驶感知的感兴趣区域,但会影响光影效果,进而影响感知结果。
OASIS SIM V3.0三维场景生成
基于3DGS的融合策略
3D高斯泼溅(3DGS)技术的突破彻底改变了场景建模和渲染。利用显式3D高斯体的强大功能,3DGS在新视图合成和实时渲染方面取得了最佳效果,同时相比传统的表示方法(如网格或体素)显著降低了参数复杂性。这项技术无缝集成了基于点的渲染和splatting的原理,通过基于splatting的栅格化促进了快速渲染和可微分计算。
基于原始的 3DGS 算法,对自动驾驶场景进行进一步的动静态元素建模,对场景背景信息和交通参与者同时进行还原。
在此基础上, OASIS SIM V3.0 实现了 3DGS 场景和存量建模场景的渲染融合表达,支持对融合场景进行深度编辑,例如添加/移动车辆,改变天气光照等。
下图为真实数据展示
下图为OASIS重建场景演示,并且进行了车辆添加和天气改变
测试之外
合成数据
自动驾驶进入深水区,端到端逐步成为未来方向,世界模型重要性凸显。一方面随着自动驾驶走入深水区,玩家对数据的要求日益提升,厂家希望数据能够模拟复杂交通流、具有丰富的场景、广泛收集各类长尾场景、并且具备 3D标注信息。而现实状态下,数据的采集成本居高不下,部分危险的场景如车祸等难以采集,长尾场景稀缺,同时3D标注的成本高昂,因此采用合成数据来助力自动驾驶模型训练测试成为颇具前景的发展方向 ,而世界模型恰为良好的场景生成和预测器 。
另一方面, 随着端到端自动驾驶成为未来的发展方向, 开发者需要依靠数据将驾驶知识赋予模型,数据需求会伴随模型体量的增加而扩大。此外更重要的影响在于,在仿真和验证环节,传统的模块化算法时代可以对感知和规控模块分别进行验证,感知端可以进行开环的检测(即将感知的结果和带有标注的真实世界状况直接对比即可,不需要反馈和迭代),规控环节可以依靠仿真工具,将世界的状况(各类场景)输入,通过环境的变化来给予模型反馈,进而闭环的(外部环境可以根据 智能体的输出变化而改变, 形成反馈 )验证规控算法的性能。
这其中,感知环节更注重仿真环境的逼真性,而规控环节更注重逻辑的丰富度。在端到端时代,感知和规控合二为一,这要求仿真工具既可以逼真地还原外部环境,同时能够给予模型反馈实现闭环测试,尽管 NeRF、3DGS等等算法层出不穷,但能够很好的做到自动驾驶全过程完整的闭环测试亦难度较高,而世界模型则能够很好的应对类似的场景 。
深度强化学习
在强化学习中,智能体学习如何在环境中做出决策和行动,以最大化累积奖励信号。在自主智能体的背景下,强化学习为这些智能体提供了一种通过试错学习来学习如何在没有明确编程的情况下执行任务和做出决策的方法。智能体是强化学习框架中的学习者。它与环境相互作用,并采取行动实现某些目标。环境是代理与之交互的外部系统。
深度Q学习(Deep Q-Network,DQN)是一种改进的Q学习算法,它使用神经网络来估计Q值。DQN的主要优势是它可以处理大规模的状态空间,从而能够应用于复杂的环境中。
展望
对于端到端模型的开发,仿真测试相比道路测试具有更大的优势:闭环。通过基于大模型实现的世界模型,我们可以建立可闭环、逼近物理级交互的世界仿真器。同时,借助于强化学习,来实现人类驾驶经验、交通法规的信息注入,引导模型更好迭代。
另外,著名 AI 科学家李飞飞近期的创业方向-空间智能说到
多年来我一直强调,拍照和真正地「看」并理解是两回事。今天,我想补充一点。仅仅看见是不够的。真正的「看」是为了行动和学习。当在三维空间和时间中采取行动时,我们将通过观察来学习如何做得更好。自然界通过「空间智能」创造了一个良性循环,将视觉和行动联系起来。
自动驾驶车辆作为智能体,也可以赋予空间智能的能力,由其所处的空间来决定下一步的动作,也许也是端到端仿真的技术方向。
#DriveGenVLM
挑战更复杂场景!首个基于VLM的自动驾驶世界模型
自动驾驶技术的进步需要越来越复杂的方法来理解和预测现实世界场景。视觉语言模型(VLMs)正作为具有显著潜力影响自动驾驶的革命性工具而崭露头角。本文提出了DriveGenVLM框架,用于生成驾驶视频并利用VLMs进行理解。为实现这一目标,采用了一种基于去噪扩散概率模型(DDPM)的视频生成框架,旨在预测现实世界中的视频序列。随后,利用一种称为"基于第一人称视频的高效上下文学习"(EILEV)的预训练模型,探索了生成的视频在VLMs中使用的充分性。该扩散模型使用Waymo开放数据集进行训练,并通过FVD评分进行评估,以确保生成视频的质量和真实性。EILEV为这些生成的视频提供了相应的叙述,这可能在自动驾驶领域带来益处。这些叙述可以增强对交通场景的理解,辅助导航,并提高规划能力。DriveGenVLM框架中将视频生成与VLMs相结合,标志着在利用先进AI模型解决自动驾驶复杂挑战方面迈出了重要一步。
当前领域背景概述
自动驾驶领域中将先进的预测模型集成到车辆系统或交通系统中,对于提高安全性和效率变得越来越关键。在众多的传感技术中,基于camera的视频预测脱颖而出,成为了一个核心组成部分,它提供了动态且丰富的现实世界数据源。通过采用前沿的扩散模型方法,本研究不仅促进了自动驾驶技术的发展,还为在提升车辆安全性和导航精度方面应用预测模型设立了新的基准。
目前,AI生成的内容是计算机视觉和人工智能领域的主要研究方向之一。由于内存和计算时间的限制,生成逼真且连贯的视频是一个具有挑战性的领域。在自动驾驶领域,从车辆前置camera预测视频尤为重要,这在自动驾驶和高级驾驶辅助系统(ADAS)的上下文中尤为关键,本文利用车辆周围camera的视频来预测未来的帧。
生成模型也已被应用于交通和自动驾驶领域,这些模型因其理解驾驶环境的能力而越来越受到认可。目前,视觉语言模型(VLMs)正被用于自动驾驶应用。为了提高VLMs的实用性并探索生成模型在VLMs中视频内容的应用,验证生成模型的预测以确认其在现实场景中的相关性和准确性至关重要。DriveGenVLM引入了上下文中的VLM作为一种方法,通过提供驾驶场景的文本描述来验证基于扩散的生成模型预测的视频。
扩散模型是一类深度生成模型,其特点主要包括两个阶段:(i)前向扩散阶段,其中初始数据通过在多个步骤中添加高斯噪声而逐渐被破坏;(ii)反向扩散阶段,其中生成模型旨在通过逐步学习反转扩散过程来从添加噪声的版本中重建原始数据,逐步进行。去噪扩散概率模型(DDPM)是一种常见的生成模型类型,旨在通过扩散过程学习和生成特定的目标概率分布。DDPM已被验证比传统的生成模型(如GANs和VAE)更为有效。
生成长视频需要大量的计算资源。一些工作通过基于自回归的模型克服了这一挑战。然而,自回归模型可能导致不现实的场景转换和长视频序列中的持续不一致性,因为这些模型缺乏从更长片段中同化模式的机会。为了克服这一点,MCVD 采用了一种训练方法,通过独立且随机地屏蔽所有先前或后续帧来为各种视频生成任务准备模型。同时,FDM 引入了一个基于扩散概率模型(DDPMs)的框架,该框架能够生成扩展的视频序列,并在不同设置下实现现实且连贯的场景完成。NUWAXL 介绍了一种"扩散之上的扩散"架构,旨在通过"粗到细"的方法生成扩展视频。
近年来,基于文本的大型语言模型(LLMs)的受欢迎程度急剧上升。此外,在自动驾驶领域还引入了各种生成式视觉语言模型(VLMs)。提出了RAGDriver ,以利用上下文学习来实现高性能、可解释的自动驾驶。我们利用EILEV 的上下文学习能力来生成驾驶场景的描述。在DriveGenVLM中,上下文VLMs使我们能够处理由扩散框架预测的视频,这些视频随后可以被其他基于视觉的模型识别,从而可能为自动驾驶中的决策算法做出贡献。据我们所知,DriveGenVLM是首个将视频生成模型和视觉语言模型(VLM)集成到自动驾驶领域的工作。
主要有那些创新点?
将条件去噪扩散概率模型应用于驾驶视频预测领域;
在Waymo开放数据集的不同camera角度下测试视频生成框架,以验证其在现实世界驾驶场景中的可行性。
利用上下文视觉语言模型生成预测视频的描述,并验证这些视频是否可应用于基于视觉语言模型的自动驾驶。
一些基础预备知识1)DDPM
去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM)是一种在机器学习和计算机视觉领域备受关注的生成模型。DDPM通过一个前向过程将数据转换为噪声,以及一个后向过程从噪声中重建原始数据来工作。前向过程的目标是将任何数据转换为基本先验分布,而后续的目标则是开发转换核以撤销这种转换。为了生成新的数据点,首先从先验分布中抽取一个随机向量,然后通过反向马尔可夫链进行祖先采样。这种采样技术的关键在于训练反向马尔可夫链以准确复制前向马尔可夫链的时间反向进程。
对于条件扩展,其中建模的x依赖于观测值y。给定数据分布x0 ∼ q(x0),前向过程生成一系列随机变量x1, x2,..., xT。x0表示原始的无噪声数据,而x1则包含了少量的噪声。这个过程一直持续到xT,此时xT几乎与x0无关,并且类似于从单位高斯分布中抽取的随机样本。xt的分布仅依赖于xt−1,转移核是:
联合分布由等式2中的扩散过程和数据分布q(x0, y)定义。
将这些模型称为扩散概率模型(Diffusion Probabilistic Models,DPMs),这些模型通过反转扩散序列来工作。对于给定的xt和y,我们使用神经网络来估计θ,作为的近似。这个估计使我们能够通过从标准高斯分布中采样开始来获取的样本,这是因为扩散过程的初始状态类似于高斯分布。随后,我们通过θ从迭代地向后采样到。在给定y的条件下,采样得到的x0:T的联合分布可以表示为:
在这里,表示与θ无关的单位高斯分布。训练条件DPM涉及调整θ,以使其在全范围的t、和y值上与紧密匹配。
2)在视觉语言模型(VLMs)上的上下文学习
In-context学习最初在GPT-3的论文中提出,它指的是模型能够在单次交互中根据提供的上下文学习或调整其响应的能力,而无需对其基础模型进行任何显式更新或再训练。
这里采用了EILEV,这是一种训练技术,旨在增强第一人称视频中的视觉语言模型(VLMs)的上下文学习能力。如图3所示,EILEV在交错上下文-查询场景下的架构涉及使用来自BLIP-2的未修改视觉transformer来处理视频片段。得到的压缩标记与初始上下文-查询实例序列中的文本标记混合。然后,将这些组合标记输入到BLIP-2的静态语言模型中,以生成新的文本标记。该方法可以泛化到分布外的视频和文本,以及通过上下文学习罕见的动作。我们利用预训练模型为驾驶视频生成语言叙述,以验证生成的结果是否可解释且现实。
DriveGenVLM方法
生成长时间、连贯且逼真的视频仍然是一个挑战。灵活扩散模型(Flexible Diffusion Model, FDM)通过使用条件生成模型来解决这个问题。在DriveGenVLM中,采用了类似的方法。为了采样具有大量帧的连贯视频,可以使用生成模型在少量帧的条件下采样任意长度的视频。我们的目标是在一些帧的条件下,采样出连贯且逼真的驾驶场景视频。这里采用了一种顺序程序,通过生成模型来采样任意长度的视频,该模型一次只能采样或基于少量帧进行条件处理。
广义上,我们将采样方案定义为一系列元组,其中每个元组由一个向量组成,表示要采样的帧的索引,以及一个向量,表示在阶段s = 1,...,S中用作条件的帧的索引。
1)训练框架
DDPM图像框架采用了U-net结构。该架构的特点是一系列层,这些层首先降低空间维度,然后再进行上采样,其间穿插着卷积残差网络块和专注于空间注意力的层。
该架构如图2所示。DDPM迭代地将噪声XT转换为视频帧X0。带有红色边框的框表示条件。右侧显示了每个DDPM步骤的UNet架构。
算法1展示了如何使用采样方案来采样视频。生成模型可以根据视频帧的其他子集来采样任何子集。模型可以生成任何选择的X和Y。
2)Sampling Schemes
每种采样方案的相对效率在很大程度上取决于手头的数据集,且没有普遍最优的选择。在本文中,尝试了三种采样方案,如表I所示。第一个也是最直接的方案是Autoreg,它通过在每个步骤中对前十个帧进行条件设置来采样十个连续帧。另一个方案是Hierarchy2,它采用多层采样方法,第一层有十个等距选择的帧,覆盖视频中未观察到的部分,这些帧以十个观察到的帧为条件。在第二层中,以组为单位连续采样帧,同时考虑最近的先前帧和后续帧,直到所有帧都被采样。最后使用了Adaptive Hierarchy-2(Ad),这只能通过实现FDM来实现。Adaptive Hierarchy-2在测试期间战略性地选择条件帧,以优化帧多样性,这通过它们之间的成对LPIPS距离来衡量。
实验对比分析1)数据集
Waymo-open数据集是一个广泛应用的数据集,它利用多种传感器来辅助自动驾驶技术的进步。该数据集包含来自Waymo自动驾驶汽车群组的高质量传感器数据,并由超过1000小时的视频组成。这些视频是通过各种传感器拍摄的,如激光雷达、雷达和五个camera(前后及侧面),它们始终提供汽车周围的完整视图,即我们所说的360度视野。这组数据有着非常细致的标注,包括车辆、行人、骑自行车者以及道路上其他物体的标记。这使得它对于该领域的研究人员或工程师来说非常有用,可以帮助他们提升自动驾驶汽车中的感知(理解)、预测(猜测接下来会发生什么)和模拟算法的技能。数据集V2格式旨在与Apache Parquet文件格式及其支持的组件一起使用。在这里,组件是一组相关的字段/列,它们是理解每个单独字段所必需的。
2)实验设置
为了验证算法在真实驾驶场景中的有效性,利用了Waymo开放数据集,该数据集涵盖了多个城市的不同真实世界环境。我们从数据集中提取了所有五个现有camera的数据。然后对数据集进行了预处理,并从三个camera(前camera、前左camera和前右camera)中提取了数据,总共处理了138个视频。其中,包含所有三个camera的108个视频被平均分配用于训练,而每个camera各有10个视频用于测试集。训练视频中发现的最大帧数为199帧,最小帧数为175帧左右。因此,将所有视频的帧数限制为175帧,分辨率降低到了128×128,并转换成了4D张量。
该模型在Debian GNU/Linux 11系统上运行,该系统配备了8核Intel Cascade Lake处理器和具有24GB内存的NVIDIA L4 GPU。我们使用了bs大小为1、学习率为0.0001的设置。每个camera训练的详细信息如表II所示。前camera是从头开始训练的,没有使用任何预训练权重,迭代了200,000次。前右camera使用了来自camera1的预训练权重,并训练了150,000次迭代,而前左camera则使用了来自camera3的预训练权重,训练了100,000次迭代。总共花费了108个GPU小时进行训练。
利用FVD(Frechet视频距离)评估,这是一种用于评估模型在视频生成或未来帧预测等任务中生成的视频质量的度量标准。类似于用于图像的Frechet Inception Distance(FID),FVD衡量生成视频分布与真实视频分布之间的相似性。FVD对于评估视频的时间一致性和视觉质量非常有用,因此它是视频合成模型基准测试的一个宝贵工具。
3)结果
表III、表IV和表V总结了我们在Waymo开放数据集上对三个camera进行实验得到的FVD分数,这些实验采用了不同的采样方案。结果表明,自适应层次-2采样方法优于其他两种方法。
图4-6展示了使用自适应层次-2采样方案(产生最低FVD分数)为每个camera生成的预测视频。每个子图包含每个camera生成的2个视频示例。带有红色边界框的帧是真实帧,预测帧位于每个对应帧的下方。生成的视频以每个示例的前40帧为条件。
FDM在Waymo数据集上的训练展示了其在连贯性和逼真度方面的能力。然而,它仍然难以准确解释现实世界驾驶中的复杂逻辑,如交通和行人的导航。这种局限性很可能是由于现实场景中存在的额外挑战,这些挑战在模拟环境中是不存在的。
为了验证我们生成的视频是否可解释且可用于视觉语言模型,我们在Ego4D数据集上使用了预训练的EILEV模型,即eilev-blip2-opt-2.7b ,来测试我们生成的驾驶视频。我们利用了描述camera角度、驾驶环境和一天中时间的视频片段和文本对。结果如图7所示。模型生成的动作叙述显示在橙色框中。值得注意的是,前两个视频中没有共享任何动词和名词类别组合,如蓝色框所示。我们可以观察到,模型能够识别出车辆正在高速公路上行驶,且摄像头位于前方。对于第二个视频,模型识别出车辆正在夜间使用前置摄像头行驶。在VLMs上进行上下文学习预训练的模型与生成的模型配合良好,表明这些视频是可解释的,并且有可能被基于VLMs的算法所使用。
#多视图重建
一览NeRF/3DGS等多种方法
近年来,随着深度学习技术的发展,基于学习的MVS方法相较于传统方法取得了显著的进展。本综述1(Learning-based Multi-View Stereo: A Survey)对这些基于学习的方法进行了分类:
基于深度图
基于体素
基于NeRF(神经辐射场)
基于3D高斯投影
大规模前馈方法。
其中,基于深度图的方法因其简洁、灵活和可扩展性被广泛关注。在综述中,文章对当前文献进行了全面回顾,探讨了各类基于学习的MVS方法的表现,并对这些方法在流行基准上的效果进行了总结。文章还讨论了该领域未来的研究方向,旨在推动3D重建技术的发展。
基础知识
基于深度图的多视图立体视觉(MVS)方法,包括大多数传统和基于学习的方法,通常由几个组件组成:相机校准、视图选择、多视图深度估计和深度融合。在本节中,我们介绍这些组件,以便读者能够清晰地了解MVS问题。需要注意的是,相机校准和视图选择也是其他基于学习的方法的组成部分。
相机校准
相机校准是确定相机的内参和外参以准确理解其几何和特性的重要过程。它是MVS的基础步骤,确保后续的重建过程基于准确且一致的几何信息,最终导致更加可靠和精确的场景3D表示。通常,通过运行现成的结构光或SLAM算法来获取校准后的相机参数。这些相机参数包括外参矩阵T = R\|t和内参矩阵K。基于深度图的MVS方法通常需要一个限定的深度范围dmin, dmax以提高估计的准确性。对于离线方法,深度范围可以通过将稀疏点云从结构光投影到每个视角并计算最小和最大z值来估算。相比之下,在线方法通常设置恒定的深度范围,例如0.25m, 20.00m,因为场景规模通常是固定的。
视图选择
视图选择是重建中的一个重要步骤,平衡三角测量质量、匹配精度和视图视锥体的重叠非常重要。目前,视图选择主要有两种策略。
首先,对于大多数在线MVS深度估计方法,当一个帧的姿态与先前关键帧的姿态有足够的差异时,该帧会被选择为关键帧。然后,每个关键帧采用几个先前的关键帧来估计深度。GP-MVS提出了一种启发式的姿态-距离度量策略,用于选择合适的视图。
其次,对于大多数离线MVS方法,视图选择是通过使用结构光获得的稀疏点云来完成的。对于参考视图i,MVSNet通过计算与其邻近视图j的得分来选择视图,该得分根据两个视图观察到的3D点P之间的基线角度计算而来。几乎所有后续的离线MVS方法都使用了相同的策略。
基于平面扫描的多视图深度估计
为了形成更适合卷积操作的结构化数据格式,大多数基于学习的MVS方法依赖于平面扫描算法来计算匹配代价。平面扫描算法通过沿深度方向离散化深度空间为一组前平行平面,并评估这些平面上的几何表面分布。它的操作通过在目标空间中扫描概念平面、计算图像之间的单应性,并根据不同视图的一致性选择深度值,从而最终实现精确的3D重建。
深度融合
对于基于深度图的MVS方法,在估计所有深度图后,需要将它们融合成稠密的3D表示,如点云或网格。在线MVS方法通常采用TSDF(截断的有符号距离函数)融合,将深度图融合成一个TSDF体积,然后使用Marching Cubes算法提取网格。然而,深度图中通常存在异常值,这可能会降低重建精度。为了克服这个问题并提高准确性,离线MVS方法通常在融合为点云之前进行深度图过滤,主要采用光度一致性过滤和几何一致性过滤。
数据集和基准
常用的公共MVS数据集和基准通常用于训练和评估。数据集如ScanNet、7-Scenes、DTU、Tanks and Temples和ETH3D等提供了相应的真值数据,包括相机姿态、深度图、点云和网格。不同数据集的目标不同,涵盖了室内外各种场景的3D重建任务。
评估指标
根据真值数据,评估指标可以分为2D指标和3D指标。2D指标通常用于在线MVS方法来评估深度图的精度,而3D指标则被广泛用于离线MVS方法来评估重建的点云质量。常见的3D评估指标包括精度/准确性、召回率/完整性和F-Score,F-Score是精度和召回率的调和平均值,用于衡量重建方法的整体性能。
基于深度估计的监督方法
这些方法通过深度估计来进行3D重建。典型的基于深度图的MVS流程主要包括特征提取、代价体积构建、代价体积正则化和深度估计。以MVDepthNet和MVSNet为代表,分别展示了在线和离线MVS方法的流程。
特征提取
考虑到效率,大多数方法使用简单的卷积神经网络(CNN)结构从图像中提取深度特征,例如ResNet、U-Net和FPN。对于在线MVS方法,特征提取网络通常与实时操作目标相结合。DeepVideoMVS结合了MNasNet(轻量级且低延迟)与FPN,而SimpleRecon则利用ResNet18的前两个块和EfficientNet-v2编码器,在保持效率的同时显著提高了深度图的精度。对于离线MVS方法,MVSNet使用了堆叠的八层2D CNN来为所有图像提取深度特征。多尺度方法进一步使用多尺度RGB图像或FPN来进行多尺度特征提取,以便在多个尺度上进行估计。最近,许多后续工作更加注重特征提取,以提高深度特征的表示能力。
代价体积构建
对于在线和离线MVS方法,代价体积通过平面扫描算法构建。
在线MVS: 为了减少计算量并提高在线应用的效率,在线MVS方法通常构建3D代价体积,存储每个像素及深度采样的单一匹配代价。MVDepthNet和GP-MVS计算参考视图与每个源视图之间的逐像素强度差异作为匹配代价。如果有多个源视图,代价体积将被平均。DeepVideoMVS和MaGNet则计算参考特征与变换后的源特征之间的逐像素相关性作为代价。
离线MVS: 离线MVS方法主要关注通过高分辨率图像重建高质量的稠密几何体。为了编码更多的匹配信息并提高质量,离线方法通常构建4D代价体积,每个像素及深度采样对应一个匹配代价。MVSNet提出了一种基于方差的代价度量,将N个源视图的特征体积求平均,然后通过方差计算匹配代价。为了减少维度,CIDER引入了分组相关性来计算参考视图和每个变换后的源视图之间的轻量级代价体积。
代价体积正则化
通常,原始代价体积可能存在噪声,因此需要通过正则化引入平滑性约束,以进行深度估计。代价体积正则化是一个关键步骤,通过从大的感受野中聚合匹配信息来对代价体积进行细化。
- 在线MVS: 2D编码器-解码器架构通常用于信息聚合。MVDepthNet将参考图像与代价体积连接起来,然后输入到一个带有跳跃连接的编码器-解码器架构中。DeepVideoMVS在代价体积上应用了2D U-Net,并在所有分辨率上添加了图像编码器和代价体积编码器之间的跳跃连接。
- 离线MVS: 大多数使用4D代价体积的离线MVS方法有三种主要的正则化策略:直接3D CNN、粗到细和RNN。MVSNet采用3D U-Net对代价体积进行正则化,从较大的感受野中聚合上下文信息。
迭代更新
与传统方法不同,一些方法采用迭代更新来逐步细化深度图。迭代方法引入了一种动态的深度图估计方法,通过多次迭代逐步改进重建过程。这种迭代细化特别适用于初始估计可能较为粗糙或不准确的场景。
一些方法结合了迭代PatchMatch与深度学习。PatchMatch算法主要包括随机初始化、向邻居传播假设和评估以选择最佳解。PatchMatchNet提出了自适应传播和代价聚合模块,使得PatchMatch能够更快收敛并生成更精确的深度图。
深度估计
对于一个4D代价体积,通常在代价体积正则化后生成一个概率体积,然后用于深度估计。目前,几乎所有基于学习的MVS方法都使用回归(软argmax)或分类(argmax)来预测深度。
MVSNet使用软argmax通过计算概率体积沿深度方向的期望值来回归深度图。对于粗到细方法,软argmax在每个阶段应用,用于回归深度图。而RNN正则化方法则主要采用argmax操作,将概率最高的深度样本作为最终预测。
深度细化
由于MVS生成的初始深度估计可能存在噪声,因此通常使用细化来提高精度。许多方法采用不同的策略来进一步优化深度图,从而获得更高质量的重建结果。
置信度估计
光度一致性置信度在离线MVS方法的深度融合过程中非常重要。大多数离线MVS方法从概率体积中提取置信度来过滤掉不可靠的估计值。此外,一些方法还通过深度学习来估计置信度,用于进一步细化结果。
损失函数
在线MVS: 许多方法通过对预测的反深度图进行回归损失计算来进行训练。
离线MVS: 基于深度估计策略,损失函数主要分为回归和分类。使用软argmax的回归方法通常采用L1损失,而采用argmax的分类方法则使用交叉熵损失。
基于深度估计的无监督与半监督方法
前面介绍的监督式MVS方法高度依赖于通过深度传感设备获得的准确的深度图真值数据。这不仅使数据收集过程变得复杂、耗时且昂贵,还将这些方法的应用限制在少数数据集和主要室内场景中。为了使MVS在更广泛的现实世界场景中得到实际应用,必须考虑替代的无监督学习方法,这些方法在不依赖真值深度数据的情况下,能够提供与监督方法相媲美的精度。目前的无监督方法基于光度一致性假设,即同一3D点的不同视图中对应像素应具有相似的特征。这些方法分为端到端方法和多阶段方法。SGT-MVSNet是目前唯一的半监督方法。
光度一致性假设
在无监督深度图预测领域,现有方法通常通过增强参考视图与源视图之间的相似性来实现光度一致性。这个关键概念围绕着通过将源视图对齐到参考视图的方式来提升图像间的相似度。
具体来说,给定参考图像的深度估计,使用公式将参考像素投影到后续图像中。
然后,通过在由于投影过程导致的像素偏移位置上进行双线性采样,生成源图像的扭曲版本。此外,通常生成一个二进制掩码,用于排除投影到图像边界之外的无效像素。
光度一致性损失可以表示为:
其中, 表示像素级的梯度,而
结构相似性损失通过结构相似性指数(SSIM)来评估合成图像与参考图像之间的上下文一致性,SSIM的定义如下:
其中, 和 分别表示图像的均值和方差, 和
平滑损失项的引入是为了在图像和深度图对齐时促进深度信息的连续性。平滑损失的计算如下:
其中, 和 分别表示沿x和y轴的梯度,
端到端无监督方法
端到端方法是指从头开始训练的无监督MVS方法,这些方法与监督方法使用相同的输入信息(如第II节中介绍的),但不使用真值深度进行监督。相反,它们通常将光度一致性、结构相似性和光滑性约束作为损失函数的一部分。
然而,无监督MVS的瓶颈在于找到准确的光度对应关系。实际场景中,非朗伯表面、相机曝光变化和遮挡会使光度一致性假设失效,从而导致"模糊监督"的问题。
为了解决这个问题,JDACS除了光度一致性外,还引入了语义一致性。它通过预训练网络提取语义特征,并通过非负矩阵分解生成语义分类图。然后计算跨视图语义一致性,监督信号通过交叉熵损失来指导分类。RC-MVSNet引入了神经渲染,通过结合神经辐射场(NeRF)的强大表示能力和代价体积的强大泛化能力,提出了一个新的无监督方法。ElasticMVS通过引入分块感知PatchMatch算法,来处理基于光度损失的几何信息中缺失数据和伪影的问题。
CL-MVSNet提出了一种框架,通过在常规分支与两个对比分支之间确保对比一致性来增强正样本对之间的接近性。
需要注意的是,这些端到端方法均不需要预处理,减少了训练时间并降低了在实际场景中应用的复杂性。
多阶段无监督方法
多阶段方法需要对特定模块进行预训练或对训练数据进行预处理。这些方法基于伪标签生成的思想。
Self-supervised CVP-MVSNet通过在CVP-MVSNet框架上进行自监督训练生成伪深度标签,并通过交叉视图深度一致性检查和点云融合来进行多次迭代,逐步提高性能。U-MVSNet通过预训练光流估计网络,利用密集2D光流一致性来生成伪标签,并提出了一个不确定性自训练一致性模块,以减少背景中的无效监督。
最近,KD-MVS通过知识蒸馏策略实现了卓越的性能。它在自监督方式下训练了一个教师模型,然后通过交叉视图一致性检查和概率编码生成伪标签,并通过这些伪标签将教师模型的知识传递给学生模型。
半监督方法
SGT-MVSNet提出仅使用少量稀疏真值3D点来估计参考视图的深度图。3D点一致性损失通过最小化从对应像素反投影的3D点与真值之间的差异来进行监督。为了处理边缘和边界上的不准确估计,SGT-MVSNet引入了一个从粗到细的可靠深度传播模块,来修正错误的预测。
不依赖深度估计的基于学习的MVS方法
尽管通过平面扫描预测单个深度图的基于学习的MVS方法是主流,但近年来还有许多其他类型的方法在3D重建方面取得了显著的效果。这里讨论了四种主要的类别:基于体素的方法、基于NeRF(神经辐射场)的方法、基于3D高斯投影的方法,以及大规模前馈方法。
基于体素的方法
这些方法通过隐函数(如有符号距离函数,SDF)利用体素表示估计场景几何。具体来说,Atlas和NeuralRecon试图通过将2D图像特征提升到3D特征体积来预测TSDF(截断的有符号距离函数)体积。Atlas使用3D卷积神经网络基于从所有场景图像中累积的特征体积来回归TSDF体积,从而展示出较高的重建完整性。NeuralRecon则通过分块式和粗到细的方式逐步重建场景,提高了效率。TransformerFusion通过两个Transformer将粗细图像特征融合到体素网格中,然后预测场景几何的占据场。VoRTX使用了与TransformerFusion相似的设计,通过3D卷积神经网络处理由不同级别Transformer输出的特征,从而获得场景几何。
基于NeRF的方法
在新视图合成领域,神经辐射场(NeRF)开启了一种新兴的3D表示方式,利用可微分的体积渲染方案,通过2D图像级损失对基于辐射的3D表示进行监督。NeRF使用多层感知机(MLP)将一个位置(x, y, z)和归一化视角方向(θ, ϕ)映射到相应的颜色和体积密度。对于新视角的特定射线,NeRF使用近似的数值体积渲染来计算累积颜色。许多后续研究进一步改进了NeRF的质量、训练速度、内存效率以及实时渲染能力。
尽管NeRF最初的目的是实现新视图合成,VolSDF和NeuS将NeRF与SDF结合,用于表面重建。SDF被转化为用于体积渲染的密度。
基于3D高斯投影的方法
基于3D高斯投影的方法最近在3D重建和新视图合成中表现出色。DreamGaussian和SuGaR是代表性的基于3D高斯投影的方法,它们通过在稀疏点云上进行3D高斯投影,将场景的稠密表面和颜色信息编码为3D高斯体积,并使用体积渲染进行监督。这些方法具有较高的渲染速度和出色的重建质量,特别是在大规模和复杂场景中表现尤为突出。
大规模前馈方法
大规模前馈方法主要使用大型Transformer模型直接从给定的图像中学习3D表示。这些方法通常需要大量的计算资源,因为它们依赖于巨大的网络结构,但在某些对象级别的场景中表现得非常出色。这些方法通过直接学习整个场景的3D表示,跳过了传统方法中的逐帧深度估计步骤,因此在某些场景中可以显著提升重建速度和质量。
总结一下
该综述涵盖了截至2023年最新的基于学习的MVS方法文献,包括四个主要类别:基于深度图、基于体素、基于NeRF、基于3D高斯投影以及大规模前馈方法。
- 提供了对不同方面的全面回顾和见解,包括各类算法的工作流程和复杂性。
- 总结了所回顾方法在不同基准上的表现,并讨论了深度学习MVS方法未来的潜在研究方向。
#EMMA
Waymo玩明白了!全新多模态端到端算法EMMA:感知规划一网打尽~
本文介绍了EMMA,一种用于自动驾驶的端到端多模态模型。EMMA建立在多模态大型语言模型的基础上,将原始摄像头传感器数据直接映射到各种特定于驾驶的输出中,包括规划者轨迹、感知目标和道路图元素。EMMA通过将所有非传感器输入(如导航指令和自车状态)和输出(如轨迹和3D位置)表示为自然语言文本,最大限度地利用了预训练的大型语言模型中的世界知识。这种方法允许EMMA在统一的语言空间中联合处理各种驾驶任务,并使用任务特定的提示为每个任务生成输出。根据经验,我们通过在nuScenes上实现最先进的运动规划性能以及在Waymo开放运动数据集(WOMD)上取得有竞争力的结果来证明EMMA的有效性。EMMA还为Waymo开放数据集(WOD)上的相机主3D目标检测提供了有竞争力的结果。我们表明,将EMMA与规划器轨迹、目标检测和道路图任务联合训练,可以在所有三个领域取得进步,突显了EMMA作为自动驾驶应用的通用模型的潜力。然而,EMMA也表现出一定的局限性:它只能处理少量的图像帧,不包含激光雷达或雷达等精确的3D传感方式,计算成本很高。我们希望我们的研究结果能够激发进一步的研究,以缓解这些问题,并进一步发展自动驾驶模型架构的最新技术。
总结来说,本文的主要贡献如下:
- EMMA在端到端运动规划方面表现出色,在公共基准nuScenes上实现了最先进的性能,在Waymo开放运动数据集(WOMD)上取得了有竞争力的结果。我们还表明,通过更多的内部训练数据和思维链推理,我们可以进一步提高运动规划质量。
- EMMA展示了各种感知任务的竞争结果,包括3D目标检测、道路图估计和场景理解。在相机主Waymo开放数据集(WOD)上,EMMA在3D物体检测方面比最先进的方法具有更好的精度和召回率。
- 我们证明了EMMA可以作为自动驾驶领域的多面手模型,为多个与驾驶相关的任务联合生成输出。特别是,当EMMA与运动规划、目标检测和道路图任务共同训练时,它的性能可以与单独训练的模型相匹配,甚至超过单独训练模型的性能。
- 最后,我们展示了EMMA在复杂的长尾驾驶场景中推理和决策的能力。
尽管有这些SOTA的结果,但EMMA并非没有局限性。特别是,它面临着现实世界部署的挑战,原因是:(1)由于无法将相机输入与LiDAR或雷达融合,3D空间推理受到限制,(2)需要真实且计算昂贵的传感器仿真来为其闭环评估提供动力,以及(3)相较于传统模型,计算要求增加。我们计划在未来的工作中更好地理解和应对这些挑战。
详解EMMA
EMMA建立在Gemini之上,Gemini是谷歌开发的MLLM家族。我们利用经过训练的自回归Gemini模型来处理交错的文本和视觉输入,以产生文本输出:
如图1所示,我们将自动驾驶任务映射到基于Gemini的EMMA公式中。所有传感器数据都表示为拼接图像或视频V;所有路由器命令、驱动上下文和任务特定提示都表示为T;所有输出任务都以语言输出O的形式呈现。一个挑战是,许多输入和输出需要捕获3D世界坐标,例如用于运动规划的航路点BEV(鸟瞰图)位置(x,y)以及3D框的位置和大小。我们考虑两种表示方式:第一种是直接将文本转换为浮点数,表示为。RT-2在机器人控制中举例说明了这种方法。第二种方法使用特殊的标记来表示每个位置或动作,表示为,分辨率由学习或手动定义的离散化方案确定。MotionLM利用这种方法进行运动预测。我们注意到,这两种方法各有优缺点。我们选择文本表示,这样所有任务都可以共享相同的统一语言表示空间,并且它们可以最大限度地重用预训练权重中的知识,即使文本表示可能比专门的标记化产生更多的标记。
End-to-End Motion Planning
EMMA采用统一的端到端训练模型,直接从传感器数据生成自动驾驶汽车的未来轨迹。然后,这些生成的轨迹被转化为特定于车辆的控制动作,如自动驾驶车辆的加速和转弯。EMMA的端到端方法旨在仿真人类驾驶行为,重点关注两个关键方面:(1)第一,使用导航系统(如谷歌地图)进行路线规划和意图确定;(2)第二,利用过去的行动来确保平稳、一致的驾驶。
们的模型结合了三个关键输入,以与这些人类驾驶行为保持一致:
- 环视视频(V):提供全面的环境信息。
- 高级意图命令(Tintent):源自路由器,包括"直行"、"左转"、"右转"等指令。
- 历史自车状态集(Tego):表示为鸟瞰图(BEV)空间中的一组航路点坐标。所有航路点坐标都表示为纯文本,没有专门的标记。这也可以扩展到包括更高阶的自我状态,如速度和加速度。
该模型为运动规划生成未来轨迹,表示为同一BEV空间中自车的一组未来轨迹航路点:表示未来Tf时间戳,其中所有输出航路点也表示为纯文本。将所有内容放在一起,完整的公式表示为:
然后,我们使用此公式对Gemini进行微调,以生成端到端的规划器轨迹,如图1所示。我们强调了这种配方的三个特点:
- 自监督:唯一需要的监督是自车的未来位置。不需要专门的人类标签。
- 仅限摄像头:所需的唯一传感器输入是全景摄像头。
- 无高清地图:除了谷歌地图等导航系统的高级路线信息外,不需要高清地图。
2.2 Planning with Chain-of-Thought Reasoning
思维链提示是MLLM中的一个强大工具,可以增强推理能力并提高可解释性。在EMMA中,我们通过要求模型在预测最终未来轨迹航路点Otrajectory的同时阐明其决策原理Orationale,将思维链推理纳入端到端规划器轨迹生成中。
我们按层次结构构建驱动原理,从4种粗粒度信息到细粒度信息:
- R1:场景描述广泛地描述了驾驶场景,包括天气、时间、交通状况和道路状况。例如:天气晴朗,阳光明媚,现在是白天。这条路是四车道不可分割的街道,在中间有人行横道。街道两边都停着汽车。
- R2:关键目标是可能影响自车驾驶行为的道路代理,我们要求模型识别其精确的3D/BEV坐标。例如:行人位于9.01,3.22,车辆位于11.58,0.35。
- R3:关键目标的行为描述描述了已识别关键目标的当前状态和意图。一个具体的例子如下:行人目前正站在人行道上,朝着路看,也许正准备过马路。这辆车目前在我前方,朝着同一个方向行驶,它的未来轨迹表明它将继续笔直行驶。
- R4:元驾驶决策包括12类高级驾驶决策,总结了之前观察到的驾驶计划。一个例子是,我应该保持目前的低速。
我们强调,驱动原理说明是使用自动化工具生成的,没有任何额外的人工标签,确保了数据生成管道的可扩展性。具体来说,我们利用现成的感知和预测专家模型来识别关键代理,然后使用精心设计的视觉和文本提示的Gemini模型来生成全面的场景和代理行为描述。元驾驶决策是使用分析自车地面真实轨迹的启发式算法计算的。
在训练和推理过程中,该模型在预测未来的航路点之前预测了驾驶原理的所有四个组成部分,即:
EMMA Generalist
虽然端到端的运动规划是最终的核心任务,但全面的自动驾驶系统需要额外的功能。具体来说,它必须感知3D世界,识别周围的物体、道路图和交通状况。为了实现这一目标,我们将EMMA制定为一种多面手模型,能够通过混合训练来处理多种驾驶任务。
我们的视觉语言框架将所有非传感器输入和输出表示为纯文本,提供了整合许多其他驾驶任务所需的灵活性。我们采用指令调优(LLM中一种成熟的方法)来联合训练所有任务以及方程1的输入T中包含的任务特定提示。我们将这些任务分为三大类:空间推理、道路图估计和场景理解。图2显示了整个EMMA概化图。
空间推理是理解、推理和得出关于物体及其在空间中的关系的结论的能力。这使得自动驾驶系统能够解释周围环境并与之交互,以实现安全导航。
我们空间推理的主要重点是3D目标检测。我们遵循Pix2Seq,将输出的3D边界框表示为Oboxes。我们通过写两位小数的浮点数将7D框转换为文本,每个维度之间用空格隔开。然后,我们使用固定提示Tdetect_3D表示检测任务,例如"检测3D中的每个目标",如下所示:
道路图估计侧重于识别安全驾驶的关键道路元素,包括语义元素(如车道标记、标志)和物理属性(如车道曲率)。这些道路元素的集合形成了一个道路图。例如,车道段由(a)节点表示,其中车道遇到交叉口、合并或分割,以及(b)这些节点之间沿交通方向的边缘。完整的道路图由许多这样的折线段组成。
虽然每条折线内的边是有方向的,但每条折线相对于其他元素不一定有唯一的顺序。这与目标检测相似,其中每个框由有序属性(左上角、右下角)定义,但框之间不一定存在相对顺序。已有数篇研究使用Transformers对折线图进行建模,与语言模型有相似之处。
我们在EMMA中的一般建模公式如下:
本文特别关注预测可行驶车道,即自车在场景中可以行驶的车道。这些是同一交通方向上的相邻车道和从当前自我车道分叉的车道。为了构建Oroadgraph,我们(a)将车道转换为有序的航路点集,(b)将这些航路点集转换为文本。使用样本排序的航路点来表示交通方向和曲率是有益的。与检测一样,我们还发现按近似距离对车道进行排序可以提高预测质量。我们的折线文本编码的一个例子是:"(x1,y1和...以及xn,yn);..."其中"x,y"是精度为小数点后2位的浮点航点,";"分隔折线实例。
场景理解任务测试模型对整个场景上下文的理解,这可能与驾驶有关。例如,道路可能会因施工、紧急情况或其他事件而暂时受阻。及时检测这些障碍物并安全绕过它们对于确保自动驾驶汽车的平稳安全运行至关重要;然而,需要场景中的多个线索来确定是否存在堵塞。我们使用以下公式重点研究我们的模型在这个临时堵塞检测任务中的表现:
Generalist Training
我们统一的视觉语言公式能够使用单个模型同时训练多个任务,允许在推理时通过任务提示Ttask的简单变化进行特定任务的预测。训练方式既简单又灵活。
实验结果表明,在多个任务中训练的通才模型明显优于在单个任务上训练的每个专家模型。这突出了通才方法的优势:增强了知识转移,提高了泛化能力,提高了效率。
实验结果


我们在图8、9和10中展示了12个不同的视觉示例,每个示例都是为了突出EMMA模型在一系列场景中的通用性。在所有场景中,我们显示模型的预测(从左到右):端到端运动规划、3D目标检测和道路图估计。
我们按场景类型对视觉示例进行分组:示例(a)-(d)展示了EMMA如何安全地与路上罕见、看不见的物体或动物互动。示例(e)-(f)的特点是EMMA在施工区域导航。示例(g)-(j)展示了EMMA在有交通信号灯或交通管制员的十字路口遵守交通规则的情况。示例(k)-(l)强调了EMMA尊重摩托车手等弱势道路使用者。
鉴于这些示例,我们展示了EMMA的以下功能:
- 泛化能力:能够很好地适应不同环境中的各种现实驾驶场景,并关注其微调类别之外的目标,如松鼠。
- 预测性驾驶:主动适应其他道路使用者的行为,实现安全平稳的驾驶。
- 避障:持续调整轨迹,避开障碍物、碎片和堵塞的车道。
- 适应性行为:安全地处理复杂的情况,如屈服、施工区和遵循交通管制信号。
- 精确的3D检测:有效识别和跟踪道路代理人,包括车辆、骑自行车的人、摩托车手和行人。
- 可靠的道路图估计:准确捕捉道路布局,并将其整合到安全轨迹规划中。
总之,这些场景突出了EMMA在各种具有挑战性和多样性的驾驶场景和环境中安全高效运行的能力。

限制、风险和缓解措施
在前面的部分中,我们在nuScenes规划基准上展示了最先进的端到端运动规划。我们还在WOD规划基准上实现了端到端的运动规划和WOD上的相机主3D检测的竞争性能。此外,我们的通才设置通过联合训练提高了多项任务的质量。尽管取得了这些有希望的结果,但我们承认我们工作的局限性,并提出了在此基础上进一步发展和在未来研究中应对这些挑战的方向。
内存和视频功能:目前,我们的模型只处理有限数量的帧(最多4帧),这限制了它捕获驾驶任务所必需的长期依赖关系的能力。有效的驾驶不仅需要实时决策,还需要在更长的时间范围内进行推理,依靠长期记忆来预测和应对不断变化的场景。增强模型执行长期推理的能力是未来研究的一个有前景的领域。这可以通过集成存储模块或扩展其高效处理较长视频序列的能力来实现,从而实现更全面的时间理解。
扩展到激光雷达和雷达输入:我们的方法严重依赖于预训练的MLLM,这些MLLM通常不包含激光雷达或雷达输入。扩展我们的模型以集成这些3D传感模式带来了两个关键挑战:1)可用相机和3D传感数据量之间存在显著不平衡,导致与基于相机的编码器相比,3D传感编码器的通用性较差。2) 3D传感编码器的发展尚未达到基于相机的编码器的规模和复杂程度。解决这些挑战的一个潜在解决方案是使用与相机输入仔细对齐的数据对大规模3D传感编码器进行预训练。这种方法可以促进更好的跨模态协同作用,并大大提高3D传感编码器的泛化能力。
预测驾驶信号的验证:我们的模型可以直接预测驾驶信号,而不依赖于中间输出,如物体检测或道路图估计。这种方法给实时和事后验证带来了挑战。我们已经证明,我们的多面手模型可以联合预测额外的人类可读输出,如目标和道路图元素,并且可以用思维链驱动原理进一步解释驾驶决策。然而,尽管经验观察表明这些输出通常确实是一致的,但不能保证它们总是一致的。此外,额外的输出会给部署带来巨大的运行时延迟开销。
闭环评估的传感器仿真:人们普遍认为,开环评估可能与闭环性能没有很强的相关性。为了在闭环环境中准确评估端到端的自动驾驶系统,需要一个全面的传感器仿真解决方案。然而,传感器仿真的计算成本通常比行为仿真器高几倍。除非进行大量优化,否则这种巨大的成本负担可能会阻碍端到端模型的彻底测试和验证。
车载部署的挑战:自动驾驶需要实时决策,由于推理延迟增加,在部署大型模型时面临重大挑战。这就需要优化模型或将其提炼成适合部署的更紧凑的形式,同时保持性能和安全标准。实现模型尺寸、效率和质量之间的微妙平衡对于自动驾驶系统在现实世界中的成功部署至关重要,也是未来研究的关键领域。
结论
在本文中,我们提出了EMMA,一种基于Gemini的自动驾驶端到端多模式模型。它将双子座视为一等公民,并将自动驾驶任务重新定义为视觉问答问题,以适应MLLM的范式,旨在最大限度地利用双子座的世界知识及其配备思维链工具的推理能力。与具有专门组件的历史级联系统不同,EMMA直接将原始摄像头传感器数据映射到各种特定于驾驶的输出中,包括规划轨迹、感知目标和道路图元素。所有任务输出都表示为纯文本,因此可以通过任务特定的提示在统一的语言空间中联合处理。实证结果表明,EMMA在多个公共和内部基准和任务上取得了最先进或具有竞争力的结果,包括端到端的规划轨迹预测、相机主要3D目标检测、道路图估计和场景理解。我们还证明,单个联合训练的EMMA可以联合生成多个任务的输出,同时匹配甚至超越单独训练的模型的性能,突出了其作为许多自动驾驶应用的多面手模型的潜力。
虽然EMMA显示出有希望的结果,但它仍处于早期阶段,在机载部署、空间推理能力、可解释性和闭环仿真方面存在挑战和局限性。尽管如此,我们相信我们的EMMA发现将激发该领域的进一步研究和进展。
#深度学习论文上的注意力可视化话图怎么来?
泻药。自从DINO被提出后,注意力图的可视化瞬间成为热点。这篇tutorial就来讨论一下训练完Transformer后,如何可视化注意力图。典型的注意力图例子如下图:
DINO首先提出了一种方法。对于ViT的第 l 层的第 k 个头,首先计算出自注意力矩阵:
其中

其中 为softmax函数, d 为内积, Q,K为输入 X 的线性变换,为第 l 层第 i 个token的表示。
这个式子的意思是,取出某一层中的一个token,计算这个token的仿射与CLS token的仿射间的相似度。算出这一层中每个token的相似度后,对全层做softmax,就可以获得每个token与CLS token的相对相似度。由于在ViT中token在一开始tokenization的时候就被flatten过了,所以这里的 z 都是长度为 N 的向量。最后得到的 就是一个标量。为什么这里是呢?这个操作相当于拿着CLS这个token的vector representation去一个database里面搜索,找到第 i 个token对应的词条的分数。
因为每个 都是标量,所以自注意力矩阵的形状是一个长度为 N 的向量。我们逆一下tokenize过程,就相当于reshape成一个 的矩阵。这个矩阵的大小就等于输入图像的patch数。因此这里每个patch的长度不能太大,否则图中的patch数会很小,导致可视化粒度太大。仔细观察上图,大概一行有64个patch,出来的粒度还可以,所以总体的可视化效果还是比较好的。
CRATE提出,将 Q,K都替换成同一个矩阵 U 之后,ViT本身很差的segmentation能力瞬间涌现了出来。一个demo可以玩:https://colab.research.google.com/drive/1rYn_NlepyW7Fu5LDliyBDmFZylHco7ss?
上图中的最右边一列就是ViT,最左边一列就是CRATE。下图里还有一些例子:
#PARTNR
Meta最新!具身多智能体任务中规划与推理的基准测试框架
本文提出了一个人机协作中的规划与推理任务基准(PARTNR),旨在研究家庭活动中的人机协调。PARTNR任务展现了日常任务的特点,如空间、时间和异构agent能力约束。我们采用大型语言模型(LLMs)构建了一个半自动化的任务生成流程,并融入了循环中的模拟以进行实现和验证。PARTNR是同类基准中规模最大的,包含10万个自然语言任务,涉及60栋房屋和5819个独特物品。围绕规划、感知和技能执行等维度,对PARTNR任务上的最新大语言模型(SoTA)进行了分析。分析结果显示,SoTA模型存在显著局限性,如协调性差、任务跟踪失败以及错误恢复能力不足。当大型语言模型与人类真实用户配对时,它们所需的步骤数是两人协作的1.5倍,比单个人类多1.1倍,这凸显了这些模型有待提升的潜力。论文还进一步表明,使用规划数据对较小的大型语言模型进行微调,可以实现与体积为其9倍的大型模型相当的性能,同时在推理速度上快8.6倍。PARTNR凸显了协作式实体agents面临的重大挑战,并旨在推动该领域的研究发展。
Code: https://github.com/facebookresearch/partnr-planner
Website: https://aihabitat.org/partnr****
一些介绍
想象这样一个家用机器人:它能像人与人之间的互动那样,使用自然语言与人类在日常活动中协作。这种场景需要两个关键特性:机器人与人类之间的动态协作,以及使用自然语言进行交流。当前具身人工智能(embodied AI)的基准测试通常只满足其中一个条件;要么机器人是独立运作的,要么任务不是用自然语言指定的。尽管具身人工智能领域取得了显著进展,但在评估机器人在协作环境中的表现的现实基准测试方面仍存在空白。为了弥补这一空白,我们推出了人机协作中的规划与推理任务基准(PARTNR),这是一个新颖的基准测试,用于评估具身人工智能agent在模拟室内环境中与人类在各种家庭活动上的协作能力。
PARTNR由10万个自然语言指令和与之配套的评价函数组成,重点关注四种任务类型:(1)无约束任务,其中子任务可以由任一agent以任何方式完成,(2)包含空间约束的空间任务,(3)需要按顺序执行的时间任务,以及(4)包含无法由其中一个agent完成的动作的异构任务。除了长时规划、新型部分可观察环境以及大状态和动作空间等传统挑战外,PARTNR还强调了有效协作动态(如任务分配和跟踪合作伙伴的进度)的必要性。
创建这样一个具有大规模自然语言任务和定制评价函数的基准测试面临着重大挑战。当前的基准测试通常依赖于模板化任务或由人类设计的任务和评价,这可能限制了数据集的多样性或规模。为了克服这一问题,本文提出了一种使用大型语言模型(LLMs)并结合循环模拟接地(simulation-in-the-loop grounding)的半自动化生成方法。首先,大型语言模型生成任务和评价函数,这些函数与模拟房屋中的物品和家具相关联。接下来,采用循环模拟来过滤掉幻觉和不可行的指令,并通过人工标注来增强多样性和准确性。然后,利用一套经过验证的1000条指令和评价函数以及多样化的模拟房屋,通过上下文提示引导大型语言模型创建10万个任务。
由于PARTNR包含自然语言任务,且大型语言模型(LLMs)在规划方面已展现出显著成效,我们探索了如何提示和微调LLMs,以评估它们在协作场景中的有效性。我们研究了环境可观性(即完全可观或部分可观)、集中式与分散式多智能体控制、学习到的或特权机器人技能、以及基于LLMs的规划中对3D世界信息进行接地的不同方式的影响。除了这些使用合成人类伙伴进行的自动化评估外,还进行了包含真实人类参与的评估,让人们单独执行任务、与人类伙伴一起执行任务或与LLMs指导的机器人伙伴一起执行任务。总体而言,发现LLMs在协调、任务跟踪以及处理感知和技能错误方面存在困难。虽然人类能够解决93%的PARTNR任务,但在非特权条件下,当前最先进(SoTA)的LLMs仅能成功完成30%的任务。此外,在分散式多智能体设置中,由于跟踪伙伴动作的能力较差,导致出现了多余动作,完成任务所需的步骤比单智能体多1.3倍。相比之下,在我们的包含真实人类参与的实验中,人类搭档的表现优于单独的人类,这凸显了改进LLMs协作策略的潜力。LLMs还难以从技能失败和感知接地错误中恢复,当移除特权技能和特权感知时,其性能会降低。在比较模型大小时,我们发现经过微调的较小模型Llama3.1-8B的性能与未经微调的Llama3.1-70B相当,但推理速度却快了8.6倍。在与真实人类共同参与的评估中,这一更快的推理速度发挥了重要作用,因为经过微调的模型所需步骤更少,为人类分担了更多任务。
PARTNR能够在各种协作场景中实现对具身智能体的可重复、大规模和系统性的评估。通过系统性的评估,我们揭示了当前基于LLM的规划器的关键局限性,为未来的研究指明了有趣的方向。
相关工作一览
基于语言的具身人工智能基准测试。大量关于具身人工智能中语言基准测试的工作都集中在导航或具身问答上,这些任务涉及导航和信息收集,但不需要智能体修改其环境。与本文的工作更为接近的是指令遵循基准测试,在这些基准测试中,智能体通过与环境的交互来完成通过语言描述的任务,尽管任务的多样性有限。相比之下,我们利用大型语言模型(LLMs)生成多样化的任务定义和场景初始化,并将其扩展到多智能体设置中。使用LLMs扩大任务生成的规模这一想法在最近的一些工作中得到了探索。然而,这些工作往往侧重于相对短期内的单智能体任务,而本文考虑的是长期的多智能体问题。表1将相关基准测试与PARTNR进行了比较。
具身多智能体基准测试。多项工作已经提出了具身多智能体基准测试。其中许多基准测试都集中在简单2D环境中的协调问题上,这限制了它们在现实世界场景中的应用。最近的工作开发了研究更真实环境和活动中协作的基准测试,这些基准测试关注在大型、部分可观察的3D环境中重新排列物体或家具,或在柜台空间内操作物体。然而,这些基准测试通常局限于一组预定义且数量有限的任务,这些任务往往不是用自然语言描述的,并且主要涉及物体的重新排列。相比之下,PARTNR涵盖了一个开放的任务集,每个任务都用自然语言描述,要求智能体在空间和时间的约束下重新排列物体,并要求执行只能由人类智能体完成的异构动作(例如洗碗或打开烤箱)。
Benchmark生成
我们推出了PARTNR基准测试,旨在训练和评估机器人与人类合作解决自然语言任务的能力。PARTNR涵盖了四种类型的任务:(1)无约束任务,即子任务可以由任一智能体以任何方式完成。例如,"让我们把所有脏盘子移到水槽里。"(2)空间任务,需要推理物体的空间位置。例如,"让我们把书放在书架上,彼此紧挨着。"(3)时间任务,子任务的执行顺序很重要。例如,"让我们先把餐桌上的蜡烛拿走,再把盘子端到桌上。"(4)异构任务,涉及超出机器人能力的动作。例如,"让我们在把盘子放到架子上之前先把它们洗干净。"在机器人的技能不支持洗涤的场景中,完成这项任务需要对智能体的能力进行推理。我们的基准测试包括自然语言指令和相应的评估函数,这两者都是使用大型语言模型(LLMs)大规模生成的。具体来说,我们生成了1000条经过人工验证的指令和相应的评估函数,并将它们作为即时提示示例,扩展到其他具有不同布局和物体的场景中的100000项任务。我们自动生成的一个独特之处在于,在生成循环中整合了一个实体模拟器,这大大减少了大型语言模型可能出现的幻觉和不可行动作等错误。
1 基于仿真循环的任务指令生成
尽管基于大型语言模型(LLM)的任务生成在之前的文献中已有研究,但这些生成的任务并未超出用户创建的 in-context prompts的范围。在PARTNR中,使用了基于仿真循环的生成技术,将大语言模型与环境、智能体和可用动作相结合。具体来说,在Habitat 3.0模拟器中实例化了一个仿真环境,该环境填充了HSSD数据集,包含60栋独特的房屋和5819个OVMM对象。模拟房屋被解析为房间和可用家具的列表,并与所有可用目标一起传递给大语言模型。利用这些信息,要求大语言模型在场景中生成自由形式、可行的任务,以及初始场景状态描述。例如,如果生成的任务是"清理客厅的餐具",大型语言模型应该生成一个客厅内有多个餐具的初始场景。在这个阶段,还会向场景中添加额外的目标,以在环境中制造混乱。任务、初始状态和混乱一旦生成,就会在模拟器中实例化,并过滤掉不可行的指令。例如,如果房屋没有客厅,"清理客厅的餐具"就是无效的。同样,如果生成的任务需要模拟器不支持的动作,如折叠,则该任务会被过滤掉。通常,幻觉的产生率很高,导致大量情节被丢弃。我们观察到,在过滤掉不可行的指令后,生成指令的多样性通常受到限制。例如,大多数指令都使用相同的对象(如餐具)或类似的房间(如厨房或餐厅)。为了增加生成任务的多样性,我们进行了手动标注,以确保任务和对象的多样性,例如,通过修改指令以激发特定特征,来维持无约束、空间、时间和异构任务的平衡分布。这一过程产生了1000个经过人工标注和仿真验证的任务。
对于大规模生成而言,这种手动标注并不实际。相反,我们利用这1000条经过人工标注的指令作为提示中的示例,来扩展生成规模。向大语言模型提供房屋描述和一个示例任务,并指示它修改任务以适应新的房屋。例如,将任务"清理客厅里的所有餐具"修改为"清理卧室里的所有玩具"。这样做可以在保持原始标注指令集多样性的同时,确保在模拟器中成功实例化的高可能性。从质量上看,我们过滤或编辑了约90%的自由形式生成的指令,而只有约10%的扩展指令需要这样做。使用LLama3-70B-Instruct来生成所有指令。最后,所有任务都经过基于人类反馈的循环过滤。在这一步中,人类使用我们的基于人类反馈的工具尝试完成任务,并消除难以检测的物理上不可行的指令,比如要求一个物体同时出现在两个位置。图2概述了我们的流程。
2 评价函数生成
为了判断智能体是否成功完成了指令"清理客厅里的所有餐具",我们需要一个评价函数来验证是否已从任何客厅中移除了所有勺子、叉子和其他餐具。然而,手动标注任务所需的所有重新排列和状态变化既耗时又由于每个任务的独特性而在大规模上难以实现。与指令生成类似,我们采用大型语言模型(LLM)来创建一个评价函数,该函数无需任何手动标注即可评估任务完成情况。具体来说,利用大型语言模型生成基于谓词的Python程序的能力,这需要使用三种类型的API:一个命题列表,指示实体之间必须满足的关系;一组依赖项,指示何时应查询命题;以及一组约束,指示命题必须如何满足。为这些组件中的每一个定义了一个富有表达力的词汇,以便对基准测试中的所有任务进行评估(例如,图3)。密切相关的评价系统包括使用PDDL或BDDL定义任务。选择构建一个新的基于Python的评价系统,因为这两个系统都无法在保持人类和大型语言模型可解释性的同时评估PARTNR任务;例如,BDDL不支持随时间变化的评估。由于PARTNR任务具有时间依赖性(例如,多步骤重新排列),因此评价函数的输入是任务执行期间模拟器状态的完整序列。评价函数返回三个指标:(1)完成百分比(PC ∈ 0, 1),即相对于约束而言已满足的命题的百分比;(2)成功(S ∈ {True, False}),衡量任务是否成功完成,定义为S := (PC = 1);以及(3)失败解释(FE),一种人类和大型语言模型可解释的语言描述,用于说明智能体未能完成任务的原因。
使用CodeLLama-70B-instruct来生成评价函数。如图3所示,生成完美的评价函数并非易事。大型语言模型(LLM)必须根据自然语言指令和特定的模拟环境,正确分类所有可能的动作空间,这可能相当复杂。例如,在图3中,指令"把植物放在架子上"指的是"架子",但房间里有两个架子。评价函数必须允许选择任意一个架子,同时要求放置所有植物,并最终考虑相邻关系。命题或约束中的任何错误或缺失值都会导致评价函数失效。因此,我们观察到LLM生成的错误率很高,特别是关于错误命题和时间顺序约束的错误。
为了减轻这些不准确性,遵循与指令生成相似的半自动化程序。首先为1000条人工标注的指令生成评价函数,并进行手动标注以进行修正。这产生了包含1000对经过人工验证的指令和评价函数的数据集。接下来,为扩展的100000条指令集生成评价。请注意,扩展指令是通过向LLM提供标注集中的示例指令来生成的。我们检索相应的标注评价函数,并将其提供给LLM。这与检索增强生成等方法类似,并通过人工检查发现,将评价函数生成的准确率从50%提高到92%。最后一步是,要求人类用户使用我们基于人类反馈的评价工具解决所有PARTNR任务。所有在人类用户6次尝试(3次单人尝试,3次多人尝试)后仍未解决的任务都被视为不可行,并从数据集中删除。我们发现,自动化生成的指令中约有90%准确,评价函数中约有92%准确,综合生成准确率为90% × 92% = 83%。
3 PARTNR Dataset
PARTNR数据集由来自HSSD数据集的37个训练场景中的100,000个片段、13个验证场景中的1,000个片段和10个测试场景中的1,000个片段组成。在扩展生成后,所有验证集和测试集的片段都经过了人工标注以确保正确性,同时训练集的一个包含2,000个片段的子集也进行了人工标注。关于扩展生成片段的正确性分析。下面分析下该数据集的特点和多样性。
特点:如前所述,PARTNR数据集侧重于四种任务类型:无约束、空间、时间和异构。在图4中展示了这些任务类型在测试集中的分布情况;验证集的分布情况与之相似。PARTNR数据集在这些维度上独立且联合地评估协作。其他值得关注的特性包括依赖重排(例如,"把它们放在同一张桌子上")和同一对象的多步重排(例如,"把杯子拿到水槽边,洗干净,然后放进橱柜里")。7%的任务包含依赖重排,6%的任务包含多步重排。任务平均需要满足4.7个命题(表明完成任务所需的步骤数量)。
多样性:PARTNR数据集中任务的多样性在很大程度上得益于循环模拟生成,该生成方法利用了丰富的HSSD场景和OVMM对象集。因此,PARTNR数据集中的任务涉及并需要对155种独特对象类型、20类家具和13种房型进行推理。请注意,每条指令在每个房屋中的实例化都带来了其自身的多样性。例如,"把笔记本电脑搬到办公桌上",这条指令在每个房屋中都独特地指定了办公室和桌子的位置,以及不同指令中不同的笔记本电脑实例。
实验和分析
我们利用PARTNR探究了最先进的规划和感知方法如何在新环境中处理自然语言任务,以及如何与未见过的伙伴进行协调。由于PARTNR包含由语言指定的各种时空任务,这里主要在基线中使用大型语言模型(LLMs)进行规划,并研究了以下变体:(1)零样本提示、检索增强生成或微调,(2)集中式规划与分散式规划,(3)部分可观察环境与完全可观察环境,(4)学习得到的低级机器人技能与理想的低级机器人技能,以及(5)特权感知与非特权感知。
实验是在Habitat 3.0模拟器中进行的,使用了模拟的Spot机器人。我们为机器人和模拟人类采用了一种两层分级控制架构,如图5所示。在高层级上,规划器从预定义的技能库(例如,导航、拾取、放置、打开、关闭)中选择技能。我们还使用了一个具有三层层次结构的文本世界图,分别表示房间、家具和可移动物体。图中的每个节点都存储了一个语义类别(例如,厨房、桌子或杯子)、三维信息(例如,位置或边界框)和状态(例如,干净、已通电)。
1 Baselines
我们按照以下维度对基线进行评估:
1.高级规划器的变体:
- 启发式专家:这种方法利用专家设计的启发式方法和关于任务、环境和评估函数的特权信息,基于人类和机器人的能力预先规划所有步骤。例如,两个agent都可能重新排列物体,但只有人类执行清洁、填充和开关任务。
- 零样本ReAct(ReAct):使用ReAct及其API函数库或工具库,使大语言模型(LLM)能够执行动作。作为观察,向LLM提供简洁、当前的世界图描述以及动作历史。LLM利用这些信息从探索房间、导航、打开家具、关闭家具、拾取物体、放置物体、等待、完成中为机器人选择一个动作。
- 带有检索增强生成(RAG)的ReAct(ReAct-RAG):还评估了带有RAG的ReAct,以研究在类似任务上的规划示例是否能提高ReAct的性能。通过从ReAct在2000个任务训练子集中的成功轨迹中收集数据,构建了一个规划示例数据库。在测试时,基于句子相似性从训练数据集中选择最相关的规划轨迹,并将其添加到LLM的提示中。
- 微调后的LLM(Finetuned):本文还研究了使用ReAct基线中成功的轨迹来微调一个较小的LLM(Llama3.1-8B)作为高级规划器,这些基线使用Llama3.1-70B。这里使用React-RAG数据集,将每个片段拆分为一系列高级规划动作,仅筛选成功执行的动作。对于每个动作,构建一个包含世界图和动作历史的输入,类似于ReAct。然后使用低秩适配器微调一个LLM,以在给定此输入的情况下从ReAct片段中预测动作。该模型降低了延迟和计算需求,适合现实世界中的部署。
所有模型生成都受到约束生成的限制,仅输出对观察到的对象有效的动作。约束生成极大地减少了LLM典型的幻觉和"语法"错误。当两个agent都调用Done或达到最大模拟步骤或LLM调用时,一个片段即结束。
- 集中式与分散式规划:
为了研究多agent PARTNR任务中协调的开销,这里比较了集中式规划器和分散式规划器。在集中式规划中,单个大型语言模型(LLM)根据两个agent的完整状态信息为它们决定动作,从而有效地消除了agent之间的任何协调需求。在分散式规划中,每个agent由不同的LLM控制,每个LLM都需要推断另一个agent的动作。
- 部分可观察与完全可观察:
为了评估当前最先进(SoTA)的语言模型是否能够探索新环境并识别与任务相关的对象,考虑了一个部分可观察的设置,其中规划器知道房屋的布局但不知道目标的位置,因此需要探索。这与完全可观察的设置形成对比,在完全可观察的设置中,所有目标的位置都是事先已知的。
- 学习到的与先知低级别机器人技能:
本文研究了学习到的神经网络技能与先知技能(具有特权模拟信息)对PARTNR任务整体性能的影响。这里为拾取、放置、导航、打开和关闭动作创建了一个学习到的技能库,并与先知技能进行了性能比较。
- 特权与非特权感知:
为了研究诸如检测不准确和定位近似等感知挑战,使用了带有修改后的ConceptGraphs的非特权世界图,该图仅根据agent的RGBD观测结果构建。随着agent的探索和动作,这个世界图将使用机载传感器进行更新。相比之下,在特权感知下,这些信息可以直接从模拟中获取。
2 Results and Analysis
指标。使用四个关键指标来评估不同设置下的性能。首先,模拟步数指标衡量了agent在模拟环境中完成任务所需的步数,作为效率的一个指标。其次,成功率反映了任务的完成情况,即是否满足"所有"任务约束。鉴于PARTNR任务的复杂性和长期性,agent通常只能部分完成任务。为了考虑这一点,还报告了完成百分比,它量化了已完成任务"命题"的比例(对于成功的任务,完成百分比为1)。最后,我们通过规划周期指标来评估规划器的推理效率,该指标计算每个规划器在一个情节过程中进行的高级大型语言模型(LLM)调用的次数。在所有实验中,将规划器的最大调用次数限制在50次以内。
任务性能分析
表2展示了使用Llama3.1-70B-Instruct模型作为ReAct基线,以及使用微调后的Llama3.1-8B基础模型作为微调基线。由于PARTNR任务是多agent任务,还需要一个模拟的人类伙伴,使用Llama3.1-70B-Instruct模型并通过ReAct方法对其进行控制。主要发现如下所述。
基于LLM的规划器在处理PARTNR任务时面临挑战。在所有可观察性和可控性条件下,基于LLM的基线性能均不如具有特权的启发式专家,原因是任务跟踪中出现错误(未完成所有步骤、步骤顺序错误或撤销已完成的步骤),以及语义错误(将对象放置在错误的家具上或移动错误的对象),这表明LLM在任务规划方面存在差距。
LLM在分散式设置中的协调方面表现不佳。没有特权访问伙伴意图的分散式ReAct基线在任务完成速度上显著慢于集中式ReAct。这表明,对伙伴进行推理(例如,了解或推断伙伴的意图)可以提高PARTNR任务的效率,而当前最先进的LLM在这方面表现不佳。此外,有两个agent的分散式ReAct甚至慢于单个agent的ReAct(行(e)中的多agent需要3295步,而行(a)中的单agent需要2519步),这表明LLM在协调方面承受着巨大的"负担"。在4.2.2节关于额外努力的分析中,我们进一步强调了这种协调负担,我们发现,在分散式设置中,agent最终会更高频率地重复任务的部分内容或执行不相关的动作。
LLM(大型语言模型)无法从已学习技能的失败中恢复。当用已学习技能替换Oracle技能时,成功率从0.73下降到0.57(行(e)对比行(h))。这种下降可以归因于,与具有特权的Oracle技能相比,已学习技能的失败率更高,且所需的模拟步骤更多。LLM在应对技能错误(如未能拾取物体或执行不完整的探索)时难以恢复,从而导致成功率降低。未来的研究可以探索训练包含低级技能循环的大型模型,使它们能够在面对此类失败时学习恢复和重新规划策略。
LLM对感知错误表现出高度敏感性。当用现成的感知模块替换具有特权的感知时,成功率显著下降(从行(h)中具有特权、部分世界图的0.57下降到行(i)中使用Concept-Graphs的0.30)。LLM严重依赖世界图提供的准确世界描述,并且难以纠正诸如误分类(例如,将架子误认为是桌子)或房间分配错误(例如,将客厅的桌子错误地标记为在卧室)等错误。像VLM(视觉语言模型)这样的多模态模型可能在从这类失败中恢复方面更强大,这留待未来的工作来研究。
微调后的8B模型在性能上与使用70B模型的ReAct相当,但推理速度却快了8.6倍。我们发现,使用较小8B模型的微调规划器与使用更大70B模型的ReAct性能相当(在行(e)中,70B模型的成功率为0.73,而在行(g)中,微调后的8B模型的成功率为0.70)。同时发现微调模型在推理速度上快了8.6倍。这表明微调有效地从训练集中提取了与任务相关的信息,并将其泛化到新的测试任务中。当与人类共同部署时,微调模型所需的步骤更少,并且能够分担比70B模型更多的子任务(见表3)。
协作行为与效率分析
表2中的分析揭示了大型语言模型(LLM)在协作中面临的挑战,这促使我们更深入地研究具体的协作行为。
机器人承担了高达60%的任务。我们评估了机器人在从人类那里分担任务方面的能力,具体方法是测量在成功的PARTNR任务中,机器人执行的子任务占总子任务的比例。尽管单智能体和多智能体的成功率相似(0.73对比0.74),但在去中心化的多智能体环境中,机器人承担了约60%的子任务,从而减轻了人类的负担。
去中心化的智能体容易执行多余的任务。智能体有时会执行对任务无用的子任务,如重新排列任务中不需要的物体或重复另一个智能体已经完成的子任务。为了衡量这种多余的努力,我们计算了在一次任务中,智能体的无效动作(即未增加任务完成百分比、未对任务进展做出贡献的动作)占总成功动作的比例。我们发现,与单智能体相比,在去中心化的多智能体环境中,无效努力增加了300%(见表12),这表明协调负担显著增加。
时间和异构任务对LLM来说具有挑战性。LLM在时间和异构任务上表现困难。与ReAct的无约束任务相比,时间任务的成功率下降了27%,异构任务的成功率下降了20%(见表13)。这凸显了LLM在推理智能体能力和遵循严格顺序约束方面的局限性。
人机交互评估
我们基于Habitat 3.0中的Human-in-the-loop基础设施进行了构建,并将其调整为服务器-客户端架构,其中服务器托管在AWS上,能够支持多个客户端。这使我们能够使用129名非专业人类参与者对任务进行大规模评估。使用该工具从验证集和测试集中收集了1000个任务的单用户和多用户数据。在单用户设置中,一名参与者通过键盘/鼠标控制在模拟器中的人类角色来完成整个任务(附录中的图14展示了我们的HITL界面)。在多用户设置中,两名参与者分别控制一个人类角色和一个机器人角色来共同完成任务。这些实验的目的是研究PARTNR任务中的多用户动态,并观察多名人类协作是否比单个人类更高效。最后,我们进行了一项人机实验,其中一名人类参与者与由大型语言模型(LLM)控制的机器人协作。该实验旨在评估LLM控制的智能体在与未见过的真实人类协作时的表现。表3显示了验证集中任务在单用户、多用户、人类-ReAct和人类-微调设置下的成功率(SR)和完成百分比(PC)。此外,我们还测量了每种方法完成任务所需的步数,以及机器人完成的工作量比例(即任务分担)。我们还通过测量选择第一个对象所需的步数和无用努力(指对任务完成没有帮助的动作)来衡量人在回路中的探索效率。这些结果总结在表3中。
人类在PARTNR任务上的表现明显优于LLM。在单人和多人环境中,人类在PARTNR基准上的成功率均为0.93。相比之下,没有任何特权信息的ReAct模型的成功率显著降低至0.30(表2的第(i)行)。这凸显了LLM在规划任务性能上的巨大差距。值得注意的是,当与真实人类一起评估时,像ReAct和微调这样的LLM基线模型的成功率分别为0.92和0.91(表3),因为人类能够适应LLM的错误。另一方面,表2中的模拟人类是一个LLM,它无法从合作伙伴的错误中恢复。
在与真实人类协作时,微调后的LLM表现优于ReAct。当与真实人类在回路中一起部署时,微调模型在任务完成上比ReAct更快(微调模型3443步,ReAct 4267步)。它还能从人类那里分担更多任务(微调模型26%,ReAct 16%)。这表明具有更快推理速度的小型模型可以改善真实世界部署中的人类体验。
LLM在协调方面存在困难,阻碍了人类的表现。尽管在与人类协作时微调模型比ReAct更快,但两种方法都比人类单独完成任务要慢。相比之下,两名人类一起工作比单个人类完成任务更快(多人2369步,单人3046步)。这一结果与我们在表1中观察到的自动化评估结果一致,其中多智能体LLM也比单智能体LLM更慢。这一结果进一步证实,LLM在协调方面存在问题;而人类能够相互协调并分配任务,但去中心化的LLM却无法做到这一点。
LLM能够从人类那里分担任务。尽管上述任务完成步数有所增加,但由微调模型指导的机器人成功地从人类那里分担了26%的任务。这表明,在与真实人类合作伙伴协作时,LLM仍然能够提供帮助。尽管如此,仍有很大的改进空间。
一些结论
PARTNR是一个针对多智能体实体任务中的推理与规划基准,其特点是在60个模拟的多房间房屋中实例化了100,000项自然语言任务,这些房屋中包含5,819个独特物体。我们采用半自动化的基于大型语言模型(LLM)的pipeline,用于大规模指令和评估功能的生成,该过程使用了基于模拟的循环接地技术。PARTNR展现了日常任务的特点,如时间和空间的限制,并允许对规划方法进行系统评估。我们发现,在PARTNR任务上,当前最先进的LLM与人类水平的性能之间存在显著差距。尽管我们最佳的LLM基线在没有特权信息的情况下仅成功完成了30%的任务,但人类却能解决93%的任务。此外,LLM在与基于LLM的智能体以及真实人类伙伴的协调中都面临着挑战。人类参与的评估(即真实人类与LLM指导的机器人合作)表明,与单独工作相比,LLM指导的伙伴会降低人类的工作效率。这表明,基于LLM的智能体需要显著改进,才能在实体任务中成为有效的合作伙伴。PARTNR作为一个具有挑战性的基准,凸显了当前模型的重大局限性。
#关于思维链,尤其是自动驾驶思维链该如何落地?
前言
CoT prompting的核心思想是通过让模型生成中间推理步骤,从而促进其推理能力,特别是在解决复杂问题如数学题或逻辑推理时。传统 prompting 方法可能直接问答案,而CoT则是让模型一步步思考,比如先分解问题,再逐步解决,最后得出答案。COT从最初在语言模型中提出基于文本的链式思维推理(few-shot,zero-shot),逐步扩展至多模态领域,并进一步结合垂直场景需求(如自动驾驶中的结构化决策、运动预测),通过引入分阶段推理、知识蒸馏、轻量化部署及结构化标注数据,推动CoT从通用推理工具向可解释、高效率、场景适配的认知智能范式演进,最终实现复杂任务中"逻辑透明性"与"性能优越性"的统一,是大模型迈向类人推理的关键技术路径。
思维链(Chain-of-thought)论文汇总
Chain-of-thought prompting elicits reasoning in large language models
论文链接:https://arxiv.org/abs/2201.11903

核心思想:
- 提出思维链(chain of thought)概念,通过少量样本(few shot)提示引导模型生成中间推理步骤,模拟人类"逐步思考"的过程,最终得出答案。
- 在输入中插入3-5个带有详细推理过程的示例(如:"问题→分步推导→答案"),即可激活模型的隐式推理能力,无需对模型参数进行任何微调。
Large Language Models are Zero-Shot Reasoners

核心思想:
- 提出"零样本思维链"(Zero-Shot CoT)方法,通过向模型提供通用推理指令(如"Let's think step by step"),直接引导其生成中间推理步骤,而无需提供任何任务相关的示例(Few-shot CoT需要人工设计示例。
- 首次证明大型语言模型在完全零样本条件下(无示例、无微调)能够自主分解问题并生成逻辑连贯的推理链条,最终输出正确答案。
Self-Consistency Improves Chain of Thought Reasoning in Language Models

核心思想:
- 突破传统思维链(CoT)仅生成单一推理路径的限制,提出同时生成多个不同推理路径。引入"自我一致性"概念,认为正确的答案往往隐含在多数推理路径的共识中。通过统计多个推理路径的最终答案,采用多数投票机制选择出现频次最高的答案作为最终结果。
- 使用人工写好的COT prompting来提示语言模型,从LLM decoder中采样(温度采样/top-k/核采样)生成一系列候选推理路径,最后根据投票选择最终推理结果。
Automatic Chain of Thought Prompting in Large Language Models

核心思想:
- Zero-Shot-CoT 通过在问题前添加引导词(如"Let's think step by step")触发模型的逐步推理。缺点是提示过于笼统,缺乏针对性,可能导致推理不精确。Manual-CoT需要人工设计示例问题及其分步解答作为提示模板。缺点是依赖人工设计,成本高且示例覆盖范围有限,难以泛化到多样化问题。针对Zero-Shot-CoT 和 Manual-CoT 的不足,提出了Retrieval-Q-CoT方法;
- 通过自动化检索相关示例,动态生成适配当前问题的CoT prompt。
- 聚类备选问题库:对大量候选问题按语义或主题聚类,形成问题组。
- 生成演示答案:调用模型(如ChatGPT)为每个聚类中的问题生成分步解答,构建"问题-答案对"库。
- 相似度检索:当遇到新问题时,计算其与问题库中各聚类的相似度,检索最匹配的示例作为提示模板。
- 无需人工设计示例,通过数据驱动选择最相关提示,提升推理的精准性和泛化能力。
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models

核心思想:
- 提出"由简至繁"(Least-to-Most)的提示策略,将复杂问题系统性分解为有序子问题序列。通过引导模型先解决基础性、前提性的子问题,逐步构建解决最终复杂问题的能力,类似于数学证明中"引理→定理"的递进结构。
- 常规的COT单次生成连续推理步骤(可能因步骤过长导致逻辑断层),Least-to-Most策略显式构建问题依赖图,通过中间答案的渐进式验证,确保每个子结论的正确性传导。
Tree of Thoughts: Deliberate Problem Solving with Large Language Models

核心思想:
- 提出"思维树"(Tree of Thoughts, ToT)框架,颠覆传统语言模型从左到右的token级生成模式**。通过构建树状推理结构,允许模型在多个候选推理路径(称为"思维节点")间进行主动探索、回溯与全局决策,模拟人类解决复杂问题时的系统性思考过程。
- 将经典搜索算法(如广度优先搜索/BFS、深度优先搜索/DFS)与语言模型结合。
- 与现有方法的本质差异:Chain-of-Thought (CoT)单一路径的线性推理,无法纠正错误或优化路径;Self-Consistency:生成多条独立推理链后投票,缺乏路径间的交互验证;ToT构建显式搜索空间,通过前瞻(lookahead)与回溯(backtracking)实现系统性探索,在规划类任务(如解谜/创作)中展现显著优势。
Multimodal Chain-of-Thought Reasoning in Language Models

核心思想:
- 现有CoT研究聚焦单一语言模态,无法利用视觉信息(如图像、图表)进行跨模态逻辑推导,导致复杂问题(如科学问答、场景理解)的推理受限或产生"幻觉"(错误推理)。该研究提出多模态思维链(Multimodal Chain-of-Thought, CoT)推理框架,将视觉与语言信息深度融合,解决传统单模态CoT在复杂推理任务中的局限性。
- 提出两阶段多模态CoT框架:
- 第一阶段(Rationale Generation):融合文本与图像特征,生成多模态推理链(例如结合图像中的物体位置与文本描述推断物理原理)。
- 第二阶段(Answer Inference):将第一阶段生成的推理链与输入信息拼接输到LLM中进行答案预测,避免多模态噪声干扰。
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step

核心思想:
- 在通用VLM(如LLaVA)基础上,提出四阶段自主推理流程(总结→视觉解释→逻辑推理→结论生成),替代传统链式思维(CoT)的线性提示方法。例如,面对"图中为何交通拥堵"的提问,模型依次做如下四阶段推理:
- 总结:提取图像关键元素(如车辆密度、信号灯状态);
- 视觉解释:识别具体视觉线索(红灯时长、车道占用);
- 逻辑推理:结合常识(长红灯导致车辆堆积);
- 结论生成:综合得出"信号灯故障引发拥堵"。
- 提出阶段级束搜索(Stage-level Beam Search)策略,在推理时动态优化各阶段输出的候选路径,提升多步推理的准确性与效率(如优先保留视觉解释正确的路径)
- 提出LLaVA-CoT-100k数据集,首个面向多阶段视觉推理的结构化数据集,涵盖科学问答、场景理解等任务,标注包括四阶段中间推理步骤,为模型提供明确的逻辑链学习目标。
DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving

核心思想:
- 通过引入思维链(Chain-of-Thought, CoT)推理机制,提升端到端自动驾驶系统的可解释性和可控性,在开环和闭环测试中,性能优于传统端到端方法,验证了方法的有效性。
- 数据集:基于CARLA模拟器创建DriveCoT数据集,涵盖传感器数据、控制决策及细粒度的思维链标注(如"是否需要变道""目标车道选择"等推理步骤)。
- 思维链标注:利用规则驱动的策略,在复杂场景(高速行驶、变道)中生成思维链标注,为模型提供逻辑推理训练数据;
CoT-Drive:Efficient Motion Forecasting for Autonomous Driving with LLMs and Chain-of-Thought Prompting

核心思想:
- 首次将LLM的复杂推理能力引入自动驾驶运动预测,利用CoT prompting技术生成细粒度语义标注,增强对动态场景的理解。
- 构建首个面向自动驾驶的结构化CoT标注数据集(超1000万token),涵盖背景统计→交互分析→风险评估→预测的完整逻辑链,支撑轻量模型的微调与泛化。
- 设计双编码器结构,语言指导编码器:处理CoT生成的语义标注;交互感知编码器:提取时空特征(动态交互、运动轨迹)。
- 利用知识蒸馏策略,将GPT-4 Turbo(教师模型)的场景理解能力迁移到轻量级语言模型(学生模型),实现实时边缘计算(如Qwen-1.5-0.6B仅需0.17秒/场景)。在保持LLM级推理性能的同时,模型参数量降低达90%。
#DexGrasp Anything
实现通用机器人灵巧抓取
能够抓取任何物体的灵巧手,对于通用具身智能机器人的发展至关重要。然而,由于灵巧手的自由度高,且物体种类繁多,以稳健的方式生成高质量、可用的抓取姿态是一项重大挑战。我们这里提出了DexGrasp Anything方法,该方法将物理约束有效地集成到基于扩散的生成模型的训练和采样阶段,在几乎所有开放数据集上均取得了最先进的性能。此外,还展示了一个新的灵巧抓取数据集,其中包含超过15000个不同物体的340多万个多样的抓取姿态,证明了其在推动通用灵巧抓取方面的潜力。
代码和数据集:https://github.com/4DVLab/DexGrasp-Anything

领域介绍
灵巧抓取作为机器人操作任务的一项基本能力,受到了广泛关注。与简单的夹具(如平行夹爪、真空吸盘)相比,五指灵巧手的结构与人类手部相近,具有更高的灵活性、操作精度和通用性。随着机器人在人类环境中的应用日益广泛,灵巧手能够像人类一样与各种物体进行交互,并使用为人类设计的工具,因此其重要性也日益凸显。因此,一种精确、稳健且通用的灵巧抓取方法,是具身智能交互的核心。
早期的灵巧抓取方法主要依赖于分析方法,通过优化抓取姿态来满足特定的物理约束。然而,由于搜索空间大,以及优化灵巧手高自由度的复杂性,这些方法面临着巨大挑战,导致成功率较低。相比之下,数据驱动的方法利用大规模数据集来学习有用的先验知识,缩小了搜索空间,并为搜索初始化提供了有力指导。基于回归的方法通常直接从物体输入中预测抓取参数,这种方法往往会出现模式崩溃和平均化问题,导致生成的抓取姿态多样性有限。最近,生成方法因其能够提高生成抓取姿态的多样性而受到广泛关注。其中,扩散模型通过迭代将简单分布(如高斯分布)转换为复杂的高维分布,在捕捉灵巧抓取的复杂性和生成多样抓取姿态方面表现出强大的能力。然而,尽管有这些优势,目前基于扩散的方法经常生成次优的抓取姿态,导致手与物体穿透或接触不足,成功率不理想。这些问题的出现是由于缺乏强制执行物理规则的约束。
这里我们提出了一种新颖的灵巧抓取生成方法DexGrasp Anything,该方法在扩散模型的训练和采样阶段都集成了三个精心设计的物理约束目标。DexGrasp Anything具有卓越的稳健性和强大的泛化能力。我们引入表面拉力,通过将手的内表面拉向物体表面来确保抓取的可行性,同时避免对已经足够远的部分产生干扰。还引入外部穿透排斥力,通过有效防止物体与灵巧手之间的严重碰撞,来保持交互的几何准确性;引入自穿透排斥力,通过在手指关节之间保持最小距离,并在距离过近时施加排斥力,来维持手的几何形状。通过我们的物理感知训练方案和物理引导采样器,这些物理约束使我们基于扩散的生成器能够为各种物体生成实用且稳健的灵巧抓取姿态。通过大量实验,证明了该方法在几乎所有开放数据集上都达到了最先进的性能。
为了进一步提高基于扩散的生成方法的通用性,大量高质量的训练数据是必不可少的。尽管人们在构建抓取数据集方面做出了很多努力,但这些数据集存在数据分布狭窄、物体类别有限和可扩展性问题。鉴于此,我们致力于进一步扩大灵巧抓取数据集的规模、增加其多样性并提高其质量。首先从多个来源收集可用的灵巧抓取数据,包括模拟数据、真实捕获数据和人类手部抓取数据,以确保数据分布的多样性和全面性。受SAM中使用的方法启发,采用"模型在环"策略,使用我们的抓取方法和过滤方法继续生成高质量数据,从而进一步扩大数据集规模。最终得到了一个非常大规模的灵巧抓取数据集:DexGrasp Anything(DGA)数据集,其中包含超过15000个物体的340多万个抓取姿态。实验结果表明,这个新数据集为相关领域的抓取方法带来了显著的益处。
主要贡献如下:
提出了一种用于生成灵巧抓取姿态的物理感知扩散生成器,该生成器在扩散模型的训练和采样阶段有效地集成了三个关键物理约束。
在五个灵巧抓取数据集上达到了最先进的性能。
展示了一个新的高质量灵巧抓取数据集,这是目前最大且最多样化的数据集,显著提高了现有方法的泛化能力。
相关工作介绍灵巧抓取生成
灵巧抓取是各种复杂的类人操作任务的基本组成部分,长期以来一直是机器人学的研究领域。早期的工作主要使用基于某些物理约束的手动推导分析方法。这些方法受到极大的搜索空间和复杂的优化过程的限制,导致成功率较低。
最近,数据驱动的方法成为灵巧抓取领域一个有前途的方向。基于回归的方法通常生成的抓取姿态多样性有限,因为它们依赖于从输入数据的直接预测,可能无法探索所有可能的抓取配置。相比之下,生成方法明确地对给定目标物体的灵巧手姿态的条件概率分布进行建模,理论上可以生成多样的姿态。基于扩散模型的方法,因其在建模各种复杂数据分布和生成多样且高度逼真样本方面的卓越能力,成为实现更通用、更稳健的机器人灵巧抓取的一个有前途的方向。然而,现有的基于扩散模型的方法在训练和采样过程中由于缺乏物理约束,会产生次优的抓取姿态。在这项工作中,我们深入研究将物理约束融入扩散模型,为灵巧手生成稳健的抓取姿态。
灵巧抓取数据集
由于手部结构的复杂性,收集3D灵巧抓取姿态的成本非常高。大多数现有数据集是在模拟器(如GraspIt!和IssacGym)中,通过在特征抓取空间中搜索或在参数空间中基于优化的方法收集的。然而,基于搜索的数据通常由于低维特征抓取空间而分布狭窄,而最近基于优化的数据仍然存在成功率较低和包含的物体类别数量有限的问题。一些真实世界的数据集是通过人类操作员控制的遥操作系统收集的。虽然这些数据集捕获了类人的抓取姿态,但数据收集过程成本高昂且难以扩展。最近的进展探索了将人类手部姿态重定向到灵巧机器人手的方法,为在机器人手训练中利用人类手部数据提供了一条有前途的途径。尽管取得了这些进展,现有数据集在多样性、可扩展性和质量方面仍然存在限制。为了应对这些挑战,我们引入了目前最大且最多样化的灵巧抓取数据集,并证明我们的数据集显著提高了生成的灵巧抓取姿态的质量和多样性,为现有的数据驱动抓取生成器提供了重要价值。
DexGrasp Anything方法
DexGrasp Anything是一种有效的方法,通过集成精心设计的物理约束来增强基于扩散的灵巧抓取生成器。图2展示了该方法的概述。

问题定义
我们的目标是生成能够稳定抓取给定物体的高质量抓取姿态。给定一个3D物体观测,旨在从条件分布中采样一组多样的灵巧抓取姿态,其中灵巧姿态,由灵巧手关节角度(对于ShadowHand)、全局旋转和全局平移向量组成。条件分布使用扩散模型进行建模,该模型将各向同性高斯分布迭代转换为所需的数据分布:
物理约束
基于扩散模型的方法在缺乏适当物理约束的情况下,往往无法达到最佳性能。为了解决这个问题,我们为DexGrasp Anything生成器提出了三个定制的物理约束目标,使其能够为各种物体生成通用且稳健的灵巧抓取姿态。
表面拉力对于确保抓取可行性至关重要。它强制机器人指骨的内表面(由采样点云表示)与物体表面接近。这个引导信号仅对距离小于指定阈值的点施加拉力,确保手指内表面的点在靠近物体表面时被拉向物体表面,但不影响已经足够远的点。计算每个内表面点到其在物体表面最近邻点的平方欧几里得距离:。我们计算表面拉力为:
其中表示在阈值距离内的点集,是一个数值稳定常数。
外部穿透排斥力保持手与物体交互的空间准确性。它通过利用有符号距离来最小化手与物体点云之间不期望的相交。给定一个带有表面法向量的物体点云和一个手点云,我们首先计算中每个点到的最近邻距离:。然后,使用物体法向量计算手与物体点之间的有符号距离:
最后,外部穿透排斥力定义为批次中所有点的最大有符号距离,再对bs大小求平均:
自穿透排斥力维护手的结构几何形状。它通过在手部点之间强制保持最小距离,解决了手部点相互交叉的问题。这确保了手保持逼真、符合物理规律的形状,避免手指碰撞。给定一组手部点,我们计算所有点之间的成对欧几里得距离:。当小于阈值时,施加排斥力,自穿透排斥力定义为:
物理感知训练
扩散模型通常使用简单的均方误差(MSE)目标进行训练:
其中是原始数据的损坏版本。数据损坏遵循固定的噪声调度:
令且,损坏过程可以直接以为条件:
由于训练目标本质上是负对数似然的重新加权变分下界,它没有包含任何关于物理约束的显式监督。因此,如先前工作中所观察到的,扩散模型在直接生成灵巧抓取参数时,往往表现不佳。为了帮助我们的扩散生成器在训练过程中捕捉物理先验,引入了物理感知训练范式。仅涉及损坏数据的训练目标不太适合纳入物理约束。使用前面定义的扩散过程,估计样本:可以作为将物理约束引入扩散模型训练过程的良好agent。
我们将物理感知训练目标定义为标准均方目标和多个物理约束目标的线性组合:
其中是第个物理约束,是相应的权重系数。梯度通过估计的干净样本传播到,如下所示:
物理引导采样
利用学到的物理先验知识,训练良好的扩散生成器能够为给定物体生成符合物理规律的灵巧抓取姿态。在采样过程中,通过采用先进的采样技术,可以进一步强化物理约束。
分类器引导方法探索了使用与时间相关的分类器,将扩散模型引导至特定的条件分布。这种引导可以近似为后验均值的偏移:
其中,是引导强度。通过基于估计,引导信号可以从与时间相关的分类器扩展到干净样本上的任意目标函数。这可以通过将目标映射到类似密度的函数来实现:
其中,是归一化常数。我们将物理引导采样器定义如下:
在实际应用中,为了减轻对的估计偏差,我们采用带有加权梯度方向的球形高斯约束。其表达式为:
其中,,,并且:
在训练过程中融入物理约束,有助于将噪声分布引导至更纯净、更适合抓取的形式。然而,由于训练阶段的监督较为稀疏,在采样过程中利用反向过程,在每一步获取和,并通过后验采样迭代优化抓取配置。这种迭代优化使得物理引导采样器能够在物理约束下逐步调整,最终将分布引导至符合物理规律的可行抓取配置。通过这种分布框架,我们的模型能够有效地泛化到各种不同的物体,在抓取任务中展现出强大的稳健性和适应性。
大语言模型增强的特征提取
为了针对目标物体实现稳健的灵巧抓取生成,通过从强大的大语言模型(LLM)中获取语义先验知识,对传统的物体特征表示进行了增强。我们使用point Transformer对物体点云进行编码,生成一个的特征向量,其中代表点Transformer定义的组数。为了用大语言模型丰富的语义先验知识充实这些特征,我们使用这样的提示:"我想要抓取一个物体标签。首先,给出它的物体类别,然后在成功抓取前详细描述其形状。"然后,我们解析响应,并使用预训练的BERT-large-uncased模型对每个句子进行编码。从每个句子中提取CLS标记,并对它们应用最大池化操作。这会生成一个的语义特征向量,其中包含了来自大语言模型的丰富先验知识。随后,通过交叉注意力机制,将拼接后的特征矩阵整合到扩散模型的主干网络中,从而增强模型生成精确且与上下文相关的抓取姿态的能力。
数据集说明
数据集的质量、多样性和规模对于推动灵巧抓取研究至关重要,特别是对于基于扩散的生成方法。在更广泛的数据分布上进行训练,能够使模型学习到更丰富、更具适应性的针对任意物体的抓取策略。为了激发各种方法在通用灵巧抓取方面的潜力,我们开发了一个全面的数据集,其在规模和多样性上都显著超越了现有的灵巧抓取数据集。在以下部分,我们将详细介绍数据构建过程,展示关键统计信息,并突出我们的DexGrasp Anything(DGA)数据集的特点。

数据构建
数据构建过程始于整合来自不同来源的现有数据集。我们收集了三个模拟数据集、一个由人类操作员收集的真实世界数据集,以及大规模的人类手部数据集GRAB,以最大化数据的多样性和丰富性。利用诸如AnyTeleop这样的机器人遥操作系统的进展,将人类手部数据集GRAB重定位到灵巧手参数,创建了DexGRAB,并对其进行过滤,仅保留手与物体接触的帧。接下来,检查在IsaacGym中收集的所有数据,应用严格的条件来确保稳定性和接触完整性。要求:(1)物体在受力时在任何方向上的位移不超过2厘米;(2)手与物体的穿透深度保持在10毫米以下,物体与手的穿透深度保持在1毫米以下。计算穿透深度的详细过程在补充材料中提供。这个严格的过滤过程保证了所有数据源的数据质量始终保持高水平。
在这个数据集上训练我们的物理感知扩散生成器,能够在对未见物体进行零样本灵巧抓取时,实现更高的成功率、更强的多样性和更快的生成速度。我们的模型作为一个数据引擎,以"模型在环"的方式促进了数据集的进一步扩展。从Objaverse数据集中精心挑选物体网格,目标是确保广泛的类别覆盖,并在这些类别中保持均匀分布。为了实现这一目标,检查了18个选定类别中的所有物体,最终选择了10034个不同的物体,涵盖了Objaverse数据配置中的6994个唯一标签。我们对每个网格应用近似凸分解,以降低复杂性并确保封闭性。然后,训练好的生成器迭代生成灵巧抓取姿态,并按照相同的严格标准进行过滤。最后将整理后的数据和生成的数据合并,形成一个大规模、多样化的数据集,旨在推动灵巧抓取研究的发展。
统计信息
在表1中对我们的数据集与其他现有数据集的关键指标进行了对比分析。我们的DGA数据集主要由两部分组成:第一部分DGA-curated包含从各种现有不同数据源整理而来的大约88万个抓取姿态,涉及5664个不同的物体;第二部分DGA-generated是使用我们的DexGrasp Anything生成器从Objaverse数据集生成的,包含大约252万个抓取姿态,涵盖10034个不同的物体,涉及6994个唯一标签。数据集包含来自不同数据分布的15698个物体的超过340万个抓取姿态,为深入研究灵巧抓取提供了支持。
特点
数据集具有高度的多样性和全面性,旨在捕捉广泛的物体和姿态变化,以提升灵巧手在复杂现实环境中的性能,关键特点如下:
- 数据规模大:我们的数据集包含超过340万个经过严格测试的抓取姿态,比之前所有的数据集都要大得多。
- 物体种类多样:数据集涵盖了来自广泛类别和来源的15698个物体,确保了高度的多样性。在图3中,我们使用预训练的point Transformer提取的特征,展示了数据集与现有数据集的物体特征的t-SNE可视化对比。数据集中的物体特征在特征空间中分布得更广泛,这表明数据集捕捉到了更广泛的独特特征,而这些特征在现有数据集中可能并不存在。
- 抓取姿态多样:丰富多样的物体种类带来了各种各样的抓取姿态。大量实验结果表明,数据集在保持甚至提高抓取成功率的同时,显著增强了现有方法生成结果的多样性。

实验分析对比对比实验
- 评估指标:遵循先前的工作,我们评估抓取成功率(Suc. 6/Suc. 1)和最大穿透深度(Pen.,单位为毫米),以衡量生成姿态的质量。如果在施加外力时,物体在3D坐标系的六个轴向方向中至少一个方向(Suc. 1)或所有方向(Suc. 6)上的位移小于2厘米,则认为抓取姿态成功。此外,使用成功抓取的姿态参数的平均标准差(Div.,单位为毫米)来评估多样性。所有姿态均在IsaacGym模拟器中,使用与之前工作相同的配置进行评估。
- 实现细节:采用UNet结构作为扩散模型的主干网络。一个基于物体条件的point Transformer编码器处理点云,并通过交叉注意力机制注入到扩散模型中。在编码之前,所有点云都下采样到2048个点。我们的模型使用PyTorch平台实现,使用Adam算法以0.0001的学习率进行优化。我们遵循所有数据集的官方训练-测试划分。所有对比方法均按照其官方代码实现进行训练和推理。训练和评估在配备四个NVIDIA Tesla A40 GPU的Linux服务器上进行,直至收敛。
- 实验结果:表2展示了定量对比结果。我们的方法利用物理感知训练范式和物理引导采样器,在所有五个基准测试中,与之前的方法相比,在姿态质量(Suc. 1、Suc. 6和Pen.)和多样性(Div.)方面均表现出卓越的性能。定性结果如图4所示,进一步说明我们的方法能够生成更准确的抓取姿态,这得益于在训练和采样阶段引入的有效物理约束。


消融实验
这里进行消融实验,以评估我们提出的物理约束目标以及DexGrasp Anything生成器中LLM增强表示的贡献。这些实验在DexGraspNet数据集的测试集上进行。定量结果如表3所示,我们逐步添加三个物理约束和LLM增强(a - e行),并与仅使用物理感知训练(不包括物理引导采样器)的模型(f行)进行比较。定性结果如图5所示,补充材料中提供了更多示例。这些分析强调了每个物理约束、LLM增强以及物理感知训练范式和物理引导采样器在提升系统整体性能方面的关键作用。


DexGrasp Anything数据集评估
通过从多种现有来源收集高质量数据,并利用我们基于物理的扩散生成器进行数据增强,构建了迄今为止规模最大、多样性最丰富的灵巧抓取数据集。这不仅提升了生成器的性能,也为其他灵巧抓取生成方法带来了益处。
实验设置:在 DexGraspNet 和 DexGrasp Anything 数据集的训练集上训练了 DexGrasp Anything 生成器、SceneDiffuser、UGG 和 GraspTTA 模型,并在 DexGraspNet 和 RealDex 数据集的测试集上对这些模型进行了评估。
实验结果:如表 4 所示,研究结果表明,使用 DexGrasp Anything 数据集进行训练显著提升了 DexGrasp Anything 生成器、UGG、SceneDiffuser 和 GraspTTA 的采样结果多样性。这一改进并未影响抓取成功率和穿透率指标,在某些情况下甚至有所提升。为了进一步验证我们的方法,我们在补充材料中提供了更全面的评估。定性对比结果如图 6 所示。对于各种目标物体,使用 DGA 数据集训练的模型生成了显著更多样化的抓取姿态,同时保持了高质量的结果。


实际应用
结合物理和语义先验知识,并在我们多样化、高质量的数据集上进行训练,DexGrasp Anything 能够在真实环境中生成鲁棒且实用的抓取姿态。为了验证其性能,我们将模型部署在真实的 ShadowHand 机器人上,如图 7 所示。真实世界实验表明,抓取动作对于未见过的真实物体是合理且稳定的,证明了DexGrasp Anything的通用性和实用性。

参考
1 DexGrasp Anything: Towards Universal Robotic Dexterous Grasping with Physics Awareness.
#下一代量产方案MindVLA
理想贾鹏英伟达GTC演讲
1228字省流版:
VLM是由端到端+VLM两个模型组成的,VLM的两个快慢系统都是输出的轨迹。VLA是一个模型具备快慢思考能力。
李想在24Q4电话会议上比喻端到端是猴子开车,VLM是副驾的人类,给猴子一些指令,VLA是主驾就是人类在开车。
VLA的快思考与慢思考输出的都是action token。Action token是对周围环境和自车驾驶行为的编码,整个模型推理过程都实时发生在车端,输出action token后,再通过diffusion进一步优化轨迹。
VLA可以让用户直接与模型对话,给它下达指令,模型会自动拆解并执行任务。
6个关键技术点:
1.MindVLA的设计过程
2.MindVLA的训练过程
3.MindVLA 3D空间理解能力如何获得
4.如何从0设计和训练语言模型,使其具备驾驶知识和推理能力
5.Diffusion如何与语言模型结合
6.如何解决VLA在车端芯片的实时推理
3D高斯具备出色的多尺度3D几何表达能力也能承载丰富语义,最关键的是通过图片RGB进行自监督训练,从而充分利用真实数据区获得优秀3D表征。
从0开始设计和训练适合VLA的基座模型,任何开源的llm模型都不具备良好的3D空间理解能力。
VLA基座设计里稀疏化是关键,实现参数量扩容时,不大幅度增加推理负担。
理想通过两个维度实现稀疏化,第一采用MoE架构,通过多个专家实现模型扩容,保证计划参数量不会大幅增加。第二引入Sparse Attention进一步提升稀疏化率与端侧推理效率。新的基座模型训练过程中,花很多时间去找最佳数据配比,融入了大量3D数据和自动驾驶相关的图文数据,减少了文史类数据的比例。
为了模型的3D空间理解和推理能力,加入了未来帧的预测生成和稠密深度的预测等训练任务。训练模型去学习人类的思考过程,并自主切换快思考和慢思考。
慢思考经过思维链CoT再输出action token,为了实时性,使用固定且简短的CoT模板。快思考不经过CoT直接输出action token。
采用小词表和投机推理,大幅提升CoT效率。针对action token推理,创新使用并行解码,即同一个阐述方法模型两种推理模式,语言逻辑的推理,通过因果注意力机制逐字输出,action token采用双向注意力机制一次性全部输出。
经过上面一系列设计和优化,实现模型的参数规模与实时推理性能之间的平衡。
利用diffusion将action token解码成最终的驾驶轨迹,不仅生成自车轨迹,还预测其他车辆和行人轨迹,大幅度提升复杂交通环境中的博弈能力。
Diffusion另外一个巨大优势,根据外部的条件输入改变生成结果,在图像生成领域被称为多风格生成,理想使用了多层的Dit去实现理想同学开快点我赶时间这样的功能。
采用了常微分方程的ode采样器大幅加速的diffusion生成过程,使其在2~3步内就可以生成稳定的轨迹,解决生成效率低的问题。
使用强化学习,让系统超越人类驾驶水平,过去主要有两个限制。
限制1:早期架构未实现端到端的可训,强化学习作为稀疏弱监督,如果无法实现高效无损信息传递,强化学习效果会大打折扣。
限制2:强化学习高度依赖良好交互环境,过于基于3D游戏引擎,真实度不足,另外场景建设效率低于与规模小,容易让模型学片,去hack reward model。
理想此前已获得端到端可训的VLA模型,解决限制1。通过特意在不同视角下添加噪音来训练生成模型,恢复模糊视角。让生成模型具备多视角生成能力,与3D重建联合优化后,获得各视角都接近真实世界的3D环境,来解决限制2。
真实用车场景展示:
场景1:口述去星巴克,无导航信息自主漫游找到目的地,中途可以随时人工干预,如说车开慢点,应该走左边等。
场景2:拍附近环境照片给汽车,让车自己来找车主。
场景3:商场下车,让车自己找车位。
完整视频:
完整图文:
我是理想自动驾驶的贾鹏,感谢英伟达邀请,接下来30分钟我将通过以下四个部分展开我们的分享。首先我花几分钟和大家一起看一下自动驾驶在中国面临的挑战。其次会总结一下2024年我们如何使用端到端加VLM双系统去尝试解决这些挑战的,以及最终呈现给用户什么样的产品体验。第三我会详细介绍我们的最新思考,以及在VLA技术上的突破。最后会通过几个实车demo来展示一下VLA技术可能给用户带来哪些革命性的产品体验。
在开始深入探讨之前,我想先和大家一起来看一下自动驾驶在中国面临的独特挑战。作为全球自动驾驶的典范,在tesla 2024的财报会议上,马斯克也提到FSD的中国的落地也遇到了很大的挑战。其中之一就是复杂而多样的公交车道。确实除了到处乱窜的电动车和高强度的人车博弈外,中国的道路结构本身也足够复杂。为了提升出行效率,公交车道被广泛使用。然而各地的标识方法和使用规则非常多样,采用了比如地面的文字标识,空中指示牌或者路边高标牌。同时会以不同的文字形式说明这些车道的时段限制。这些多变的规则和文字表达为自动驾驶带来了巨大的挑战。
有朋友可能会说,我会通过地图或者先验信息来解决,其实挑战也很大。中国城市快速发展,常常出现新增的公交车道,或者因为施工导致的部分标识的不清或者重刷,任何先验信息都会面临着鲜度不足的问题。如果想从根本上去解决公交车道的挑战,车端需要具备实时识别和理解这些文字的能力。
公交车道还只是诸多挑战之一,随着数字城市的不断深入,很多车道和区域被赋予了动态变化的能力,越来越多的城市出现了动态可调的可变车道和潮汐车道,同时为了充分利用入口的空间,也增加了如待转区,待行区。这些车道和待行区域的进入时机,也是有多样化的信号灯或者LED文字牌来控制的。
同时咱们城市的建设日新月异,每天都会面临着设备的新增故障和维护,自动驾驶系统需要时刻保持对这些变化的理解,如果想打造一套无缝的点到点的智能驾驶体验,智能驾驶车辆还需要能够顺利通过ETC和收费站,而这也要求系统能够识别和理解全国各地的各种各样的ETC标识和支付方式标识。
综上所述,在中国自动驾驶系统不仅要应对高强度的人车博弈,还需要能够读懂文字,具备常识和很强的逻辑推理能力。特斯拉向中国用户推送了FSD的功能,我们也看到FSD的公交车道待行区等特殊场景上的表现确实是有所不足的。那么理想汽车是如何应对这些挑战的?在去年的GTC 2024大会上,我有幸介绍了我们的自动驾驶框架,这个框架是基于诺贝尔奖获得者丹尼尔卡尼曼提出的快慢思考双系统理论,简单的说人的思维可以分为两个系统,快思考系统一和慢思考系统二,快系统依赖于直觉判断,大多数情况下人类日常决策都使用该系统,而当我们面临复杂问题时,才会调用慢系统去想一想,思考一下再行动。

我们也在车站实现了这样的双系统,首先车端通过端到端的模型实现了快速,它是一个单一的模型,实现了传感器的输入,直接到轨迹的输出,类比于人类的直觉反应,该系统通过模仿人类的驾驶行为来应对各种各样的场景,完全基于数据驱动中间无需人为设定规则,而且不使用任何高精地图或者先验信息,他的训练和执行效率都很高。
另外一方面慢系统则依托于一个22亿参数规模的视觉语言大模型VLM,在需要文字理解能力常识和逻辑推理的场景中,VLM会通过思维链CoT进行复杂的逻辑分析,给出驾驶决策并指挥快系统去执行。
端到端模型和VLM模型分别跑在一颗Orin-X芯片上。这套双系统的一些技术细节我们也发表在CoRL 2024的DriveVLM这篇论文中,双系统采用了数据驱动的范式,迭代效率提高。在过去半年的量产实践中,我们实现了每周3~4次的模型发版,然而如果快速的进行测试和验证,也逐渐成为了我们的瓶颈。考虑到中国拥有数百万公里的道路,通过实车进行测试,既不现实,效率和成本也难以接受。因此我们在云端构建了一个世界模型,它提供了一个3D的交互环境,使得双系统可以在此环境中进行高效的闭环仿真测试。
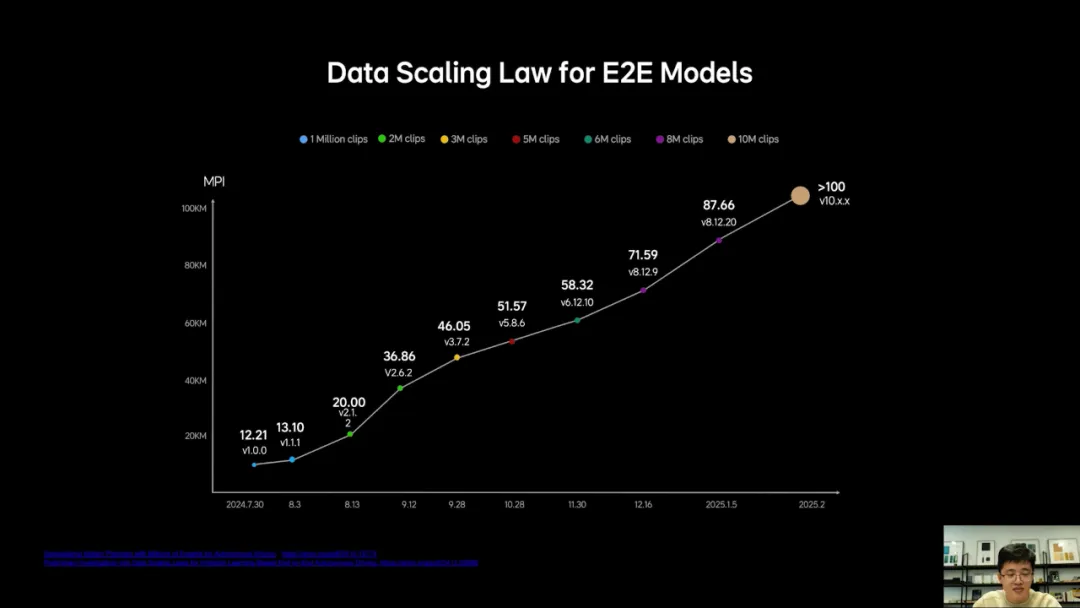
以上三个模型就构成了理想自动驾驶的整个体系,简洁而高效。在这一过程中我们非常惊喜的发现,双系统同样遵循scaling law,随着训练数据的增加,模型在实际驾驶场景中的表现逐步提升,我们在最早期的早鸟测试中使用了100万clips训练出来的模型,其平均接管里程MPI仅有十几公里,但是经过半年的持续迭代和数据量的持续提升,到今年年初我们1000万clips训出来的模型已经实现了超过100公里的MPI,这些重要的发现也发表在下面的这两篇论文中。
基于双系统架构,我们成功的在英伟达Orin-X平台上推出了全球首个车位到车位的智能驾驶产品,目前已经推送了超过40万台车。所谓车位到车位指的是从停车位出发,穿越车库,经过园区进入公共道路,直到通过ETC进入高速公路的整个过程中,没有任何的系统降级和退出。同时借助VLM的通识能力,我们在这一产品中实现了多个行业首创的功能,比如实现了不依赖于地图或者先验信息的全国ETC自由通行,全国潮汐车道和可变车道的自由通行,在待转区待行区的自主进出,以及在坑洼路面积雪路面积水路面的自动减速,这些突破性的功能目前在其他车上都尚未实现,极大的提升了我们用户的用户体验,赢得了广泛的好评,也推动了我们的销量在持续增长。

同时我们知道用户可能会担心端到端模型是个黑盒子,比如说有的用户会想知道模型在想什么,下一步的动作是什么,那么为了解决这一问题,我们创新性的引入了AI推理交互功能,用户可以直观的看到模型在关注哪些点,即将执行的动作以及整体的思考过程,透明化的设计显著提升了用户的信心,让用户用得更加安心放心,也得到了大量的积极反馈。
在2024年10月理想汽车量产双系统方案后,端到端加VLM的模式逐渐成为了行业的标杆。许多同行开始采用这一路线,不仅在自动驾驶领域,在通用机器人领域也得到了应用。例如上个月Figure发布的机器人系统也使用了类似的架构,在过去几年的实践中,自动驾驶团队形成了一种高效的工作模式。
在产品交付的同时,我们不断反思和总结现有架构的不足,并留出一部分资源用于探索下一代的技术。在端到端加VLM的量产过程中,我们也发现了一些需要改进的地方。
首先虽然我们可以通过异步联合训练,让端到端和VLM协同工作,但由于它们是两个独立的模型,而且运行于不同的频率,整体的联合训练和优化是非常困难的。其次我们的VLM模型是基于开源的llm大语言模型,它使用了海量的互联网二级图文数据做预训练,但是在3D空间理解和驾驶知识方面是有所不足的。虽然可以通过后训练进行一定程度的弥补,但是它的上限还不是很高。
第三,自动驾驶芯片如Orin-X和Thor-U它的内存带宽和算力是不及服务器GPU的,如何进一步提升模型的参数量和能力,同时还能实现高效的推理,这是个巨大的挑战。
第四,目前驾驶行为的学习更多的依赖于transformer进行回归建模,但这种方法难以处理人类驾驶行为的多模态性。这里的多模态性是指在相同的场景下,不同人的选择是不同的,即使是同一个驾驶员不同心情的时候,驾驶行为也是不同的。那么有什么方法能够进一步提升模型的上限,让用户体验到更加丝滑的产品?同时我们认为不仅仅要提升模型的上限,同时也要提升模型的下限,如何对齐到人类的价值观也是急需要解决的问题。
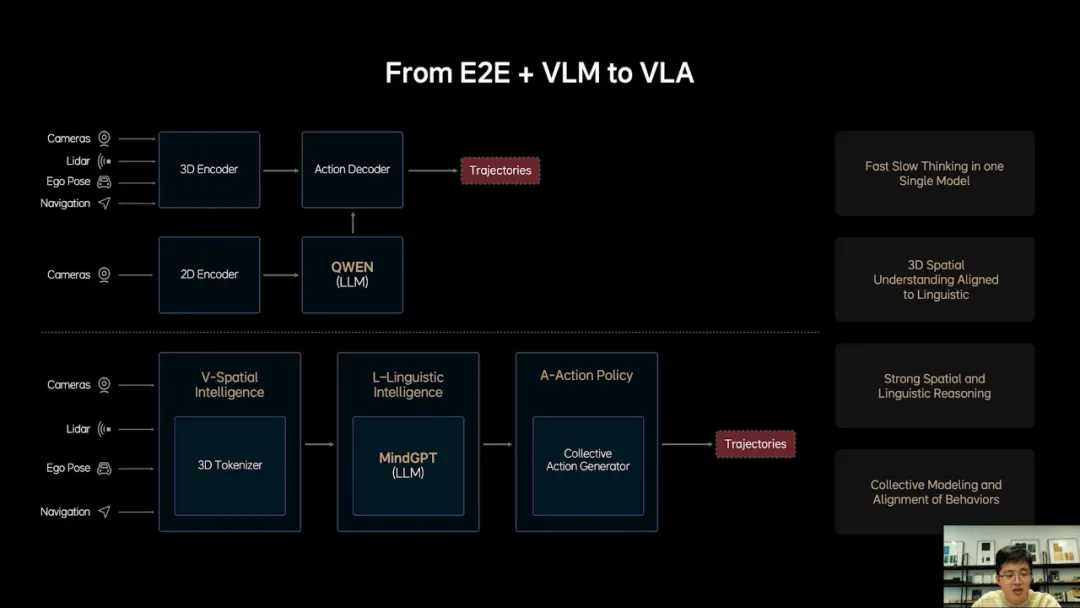
幸运的是在我们交付端到端加VLM的期间,空间智能AIGC和具身智能有了快速发展,也给了我们很多启示。我们在思考能不能将端到端模型和VLM模型合二为一,像GPT o1和DeepSeek R1一样,模型自己学会快慢思考,同时赋予模型强大的3D空间理解能力和行为生成能力,将双系统天花板进一步打开。
基于以上的思考,我们提出了理想的VLA模型MindVLA,VLA是视觉语言行为大模型,它将空间智能、语言智能和行为智能统一在一个模型里,VLA是Physical AI的最新范式,它赋予自动驾驶这样的物理系统感知思考和适应环境的能力。
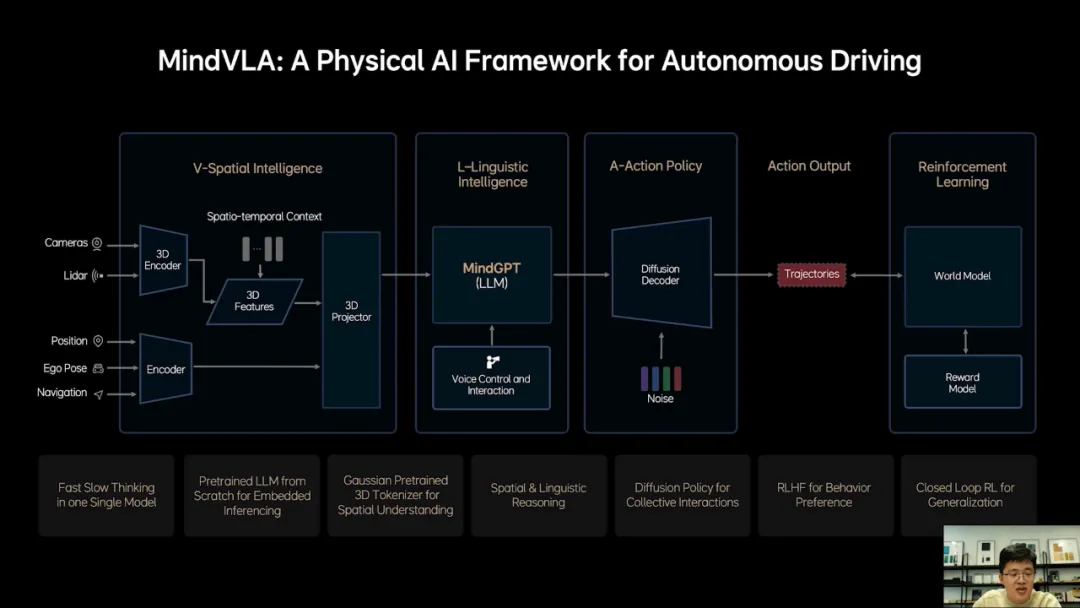
MindVLA不是简单的将端到端模型和VLM模型结合在一起,所有的模块都是全新设计的,3D空间编码器通过语言模型和逻辑推理结合在一起后给出合理的驾驶决策,并输出一组action token,最终通过diffusion进一步优化出最佳的驾驶轨迹。这里所谓的action token是对周围环境和自车驾驶行为的编码,整个模型推理过程都要发生在车端,而且要做到实时运行。
接下来我会从6个关键技术点去详细介绍MindVLA的设计和训练过程,包括MindVLA强大的3D空间理解能力是如何获得的,我们是如何从0设计和训练语言模型,使其具备驾驶知识和推理能力的,diffusion是如何与语言模型结合在一起的,以及我们是如何解决VLA在车端芯片的实时推理。
好,咱们一起看一下这6个关键技术,首先Physical AI和物理世界的交互需要强大的空间智能,也就是对3D物理世界的感知理解和推理能力。回顾自动驾驶技术的发展历程,对空间的理解,我们经历了从单目二D特征到单目三D车的特征,再到多相机的鸟瞰图BEV特征和占用网格特征等不同的阶段,这个演变过程也体现出咱们工程师对物理世界几何和语义信息精确提取的不懈追求。
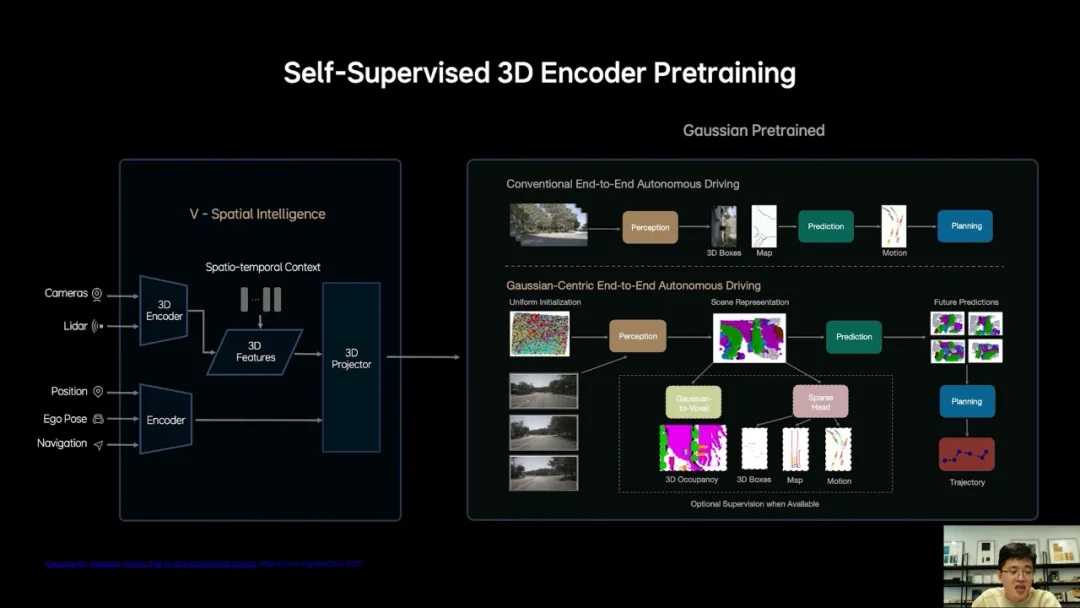
然而这些方法大多依赖于监督学习,需要精确的标注数据效率和数据利用率都很低下。
我们前面提到在双系统的实践中,我们欣喜地发现了数据量的能力随着数据量的提升,系统的表现会同步提升。
如果充分利用我们海量的数据,在研发世界模型时,我们发现3D高斯是一个极其优良的中间表征,它不仅具备出色的多尺度3D几何表达能力,同时也有方法承载丰富的语义,最为关键的是可以通过图片RGB进行自监督训练,这使得我们有机会去充分利用海量的真实数据获得一个优秀的3D表征。
我们的研究成果显示,采用自监督训练得到的高斯表征,能够极大地促进下游任务的性能提升。部分实验结果和能力我们展示到我们的论文高斯AD,大家如果有兴趣可以进一步查阅,解决了3D表征,接下来如何将它和语言智能结合在一起, llm已经被证明是一个强大的通用模型,它可以兼容视觉语言的多种模态,但是如果想要llm同时具备3D的空间理解能力,3D空间推理能力及强大的语言能力,需要在模型的预训练阶段就要加入大量的相关数据。
同时车载芯片如Orin-X和Thor-U它的算力和内存带宽都有限,如何设计模型架构,让模型参数进一步提升,还能在有限的资源下实施实现实时推理,这里解释一下为什么我们还要进一步增加模型参数量,因为数据参数规模和能力强弱可以划等号,越大越好。为了解决这些问题,我们需要从0开始设计和训练一个适合VLA的基座模型,因为任何开源的llm模型都不具备这样的能力。在这个过程中稀疏化是模型设计的关键,它可以实现模型容量扩容的同时,不会大幅度增加推理负担。
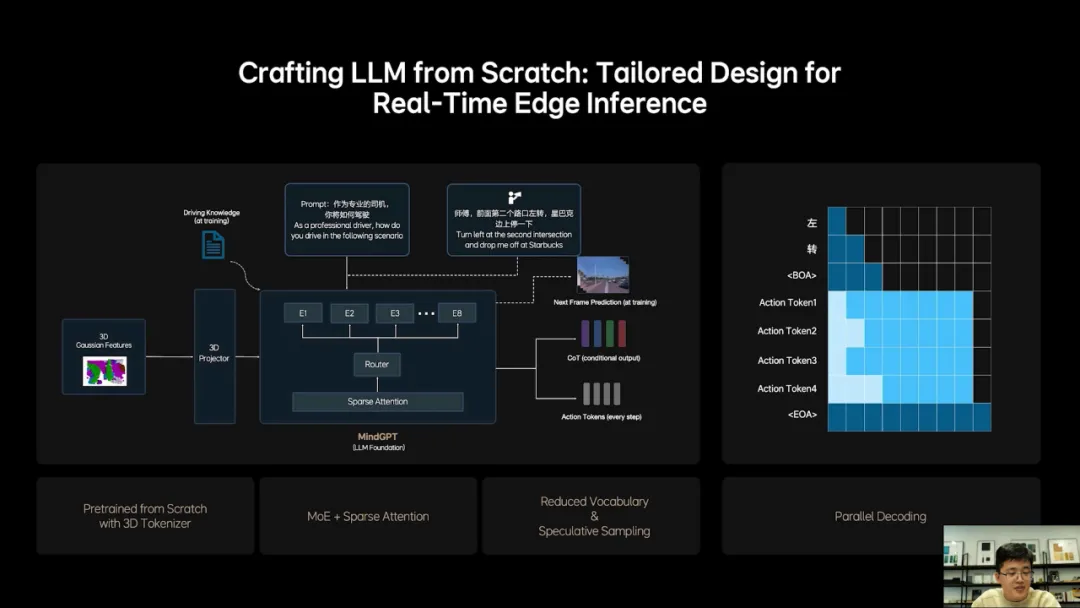
我们通过两个维度来实现稀疏化,首先我们采用了MoE的架构,通过多个专家实现模型扩容,还可以保证激活参量不会大幅度增加。第二我们引入了Sparse Attention等来进一步提升稀疏化率,提升端侧的推理效率。在这个新的基座模型训练过程中,我们花了很多时间去找到最佳的数据配比,融入了大量的3D数据和自动驾驶相关的图文数据,并减少了文史类数据的比例。
最后为了进一步激发模型的3D空间理解和推理能力,我们加入了未来帧的预测生成和稠密深度的预测等训练任务。lIm在获得3D空间智能的同时,在逻辑推理方面也需要进一步的提升。我们训练模型去学习人类的思考过程,并自主切换快思考和慢思考。
在慢思考模式下,模型会经过思维链CoT再输出action token,由于自动驾驶不需要冗长的CoT,同时也因为实时性的要求,所以我们使用了固定且简短的CoT模板,在快思考模式下,模型则不需要经过CoT就可以直接输出action token,这也是我们将快慢思考有机结合在同一个模型中的体现。
很多人会问llm是token by token的输出,推理速度能够支撑自动驾驶吗?确实即便有了上述的结构设计和优化,想要实现VLA超过10赫兹的推理速度还是具有挑战的。我们做了大量的工程工作去压榨Orin-X和Thor-U的性能。针对CoT过程,我们采用了小词表和投机推理,大幅提升CoT的效率。针对action token的推理,我们采用了创新性的并行解码的方法,也就是在同一个阐述方法模型中加入了两种推理模式,语言逻辑的推理,通过因果注意力机制逐字输出,而action token则采用双向注意力机制一次性全部输出。
经过上面一系列的设计和优化,我们终于实现了模型的参数规模与实时推理性能之间的平衡。
最后在这个架构图中还有一个亮点,VLA的强大之处在于用户可以直接与模型对话,给它下达指令,模型会自动拆解并执行任务,我稍后会介绍这一特性是如何改变自动驾驶产品形态的。在成功构建了一个强大的基座模型之后,我们利用diffusion将action token解码成最终的驾驶轨迹。在日常的驾驶过程中,车辆与周围的交通参与者,如车辆、行人骑行人存在着密切的交互关系,并会最终影响自车的行为。
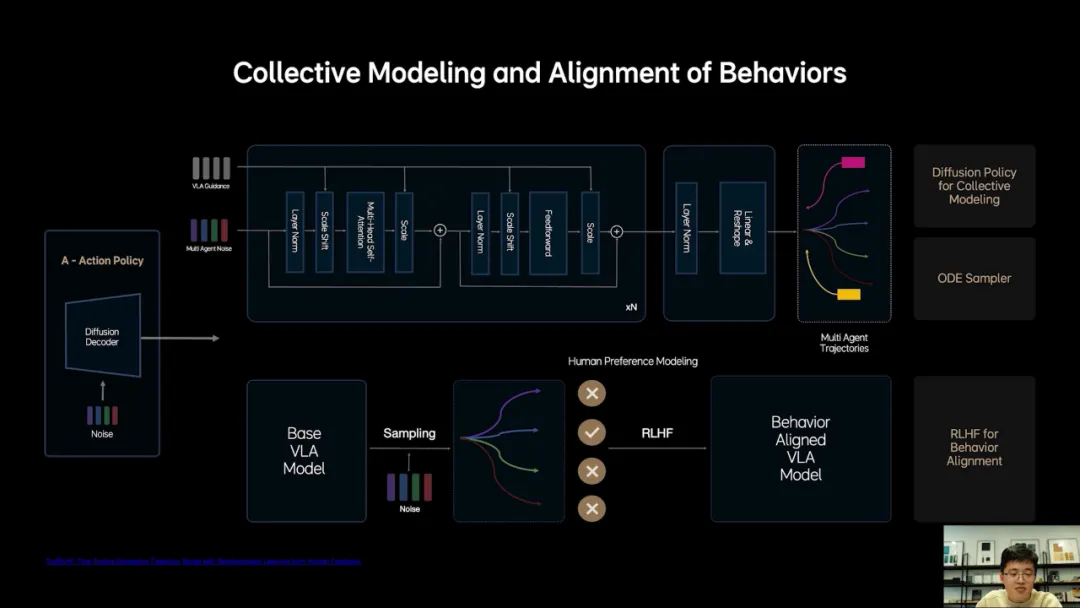
因此在diffusion模型中,我们不仅生成自车的轨迹,还预测其他车辆和行人的轨迹,大大提升了标准模型在复杂交通环境中的博弈能力。此外diffusion还有一个巨大的优势,就是可以根据外部的条件输入改变生成结果,这在图像生成领域被称为多风格生成,有了这样的特性,类似李想同学开快点我改时间,这样的功能就很容易实现了。我们使用了多层的Dit去实现了diffusion。
然而diffusion模型有一个显著的挑战,就是它的生成效率极低,需要很多步才能成功生成稳定的轨迹。为了解决这一问题,我们采用了基于常微分方程的ode采样器大幅加速的diffusion生成过程,使其在2~3步内就可以生成稳定的轨迹。
至此我完整介绍了VLA的架构和基础的训练过程,VLA模型在绝大多数场景下能够接近人类的价值水平,然而在某些长尾工况下,VLA仍然存在着不符合人类价值观的问题,为解决这个问题,我们增加了后训练的阶段,希望能够既对齐人类驾驶员的行为,在过去几年里,我们不仅积累了大量的人类司机的驾驶数据,也有很多NOA的接管数据,这些接管都是不符合人类预期的表现。
我们筛选了大量的接管数据,建立了一个人类偏好的数据集,应用RLHF去微调模型的采样过程,使模型能够从这些偏好数据中学习和对其人类行为,这一创新性的步骤,让我们在模型性能上取得了进一步的提升。随着偏好数据的逐步丰富,模型的表现也逐步接近了专业司机的水平,安全下限也得到了巨大的提升。有关RLHF与diffusion结合的具体细节,我们也在近期的论文中进行了详细的阐述,欢迎大家查阅,也能希望给大家一些启发,要实现真正的自动驾驶,仅仅达到人类司机的水平还是不够的。
那么如何让系统有机会超越人类驾驶水平,或许大家第一反应是强化学习,强化学习在自动驾驶领域已经不算新鲜事儿,但是过去的尝试都没有取得很好的效果,我认为这里面有两个主要的限制因素,第一,早期的生成架构未能实现端到端的可训,强化学习作为一种稀疏的弱监督过程,若无法实现高效的无损的信息传递,强化学习的效果就会大打折扣。
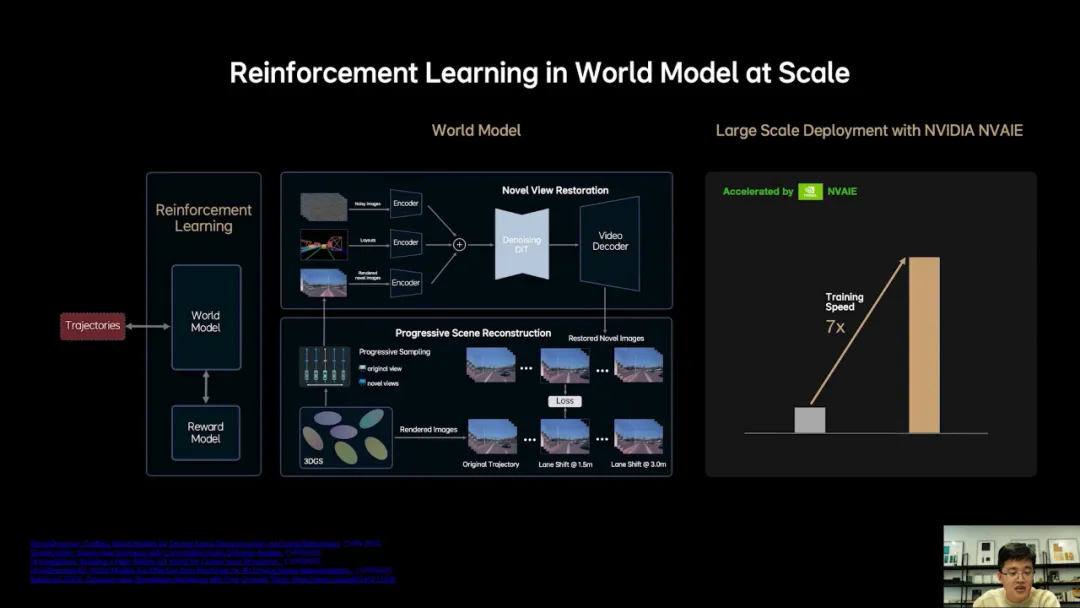
第二,Physical AI 需要与真实世界进行交互,以获取奖励信号,因此自动驾驶作为Physical AI 最直接的应用,它的强化学习也高度依赖于良好的交互环境。然而过去的尝试都是基于3D的游戏引擎,场景真实度不足,限制了强化学习在真实驾驶场景中的应用,同时因为场景建设效率低下,场景规模小,模型很容易学偏,去hack reward model,导致强化出来的模型完全不可用。
我们已经获得了一个端到端可训的VLA模型,它解决了第一个限制。
至于良好的交互环境,我们的做法是结合场景重建与生成,纯生成模型的优势在于其良好的泛化能力能够生成多变的场景,但是可能会出现不符合物理规律的幻觉,难以满足自动驾驶的严格要求。相反纯重建模型则依托于真实数据呈现出3D场景,但是在大视角变换下可能会出现空洞和变形,也没办法满足自动驾驶的要求,我们选择以真实数据的3D重建为基础,同时特意在不同的视角下添加噪音来训练生成模型,恢复这些模糊的视角。
这样一来生成模型就具备了多视角的生成能力,在与3D重建联合优化后,可以获得一个各个视角下都接近真实世界的3D环境,这在很大程度上解决了上面提到的第二个限制。
关于生成和重建是如何结合的,很多细节发表在我们的论文里,其中4篇还中了今年的CVPR 2025,突破了这两个线之后,我们终于有机会尝试大规模的自动驾驶强化学习,但规模化需要解决效率的问题,无论重建和生成效率都不高。
过去一年里,我们与英伟达团队密切合作,进行了大量的工程优化,显著提升了场景生成和重建的效率。其中一项工作是将3DGS的训练速度提高了7倍以上,这项工作也已经投保到SIGGRAPH 2025上。
好,以上就是MindVLA最关键的6个技术点,总结下来MindVLA成功整合了空间智能、语言智能和行为智能可以说是一个巨大的突破。并且通过创新性的预训练和后训练方法,我们发现VLA实现了卓越的泛化性能和涌现特性,它不仅在驾驶场景下表现良好,在室内环境中也展示出了一定的适应性和延展性,这是Physica AI能够大规模落地的关键,一旦跑通这套范式,理想将有望为更多行业赋能。
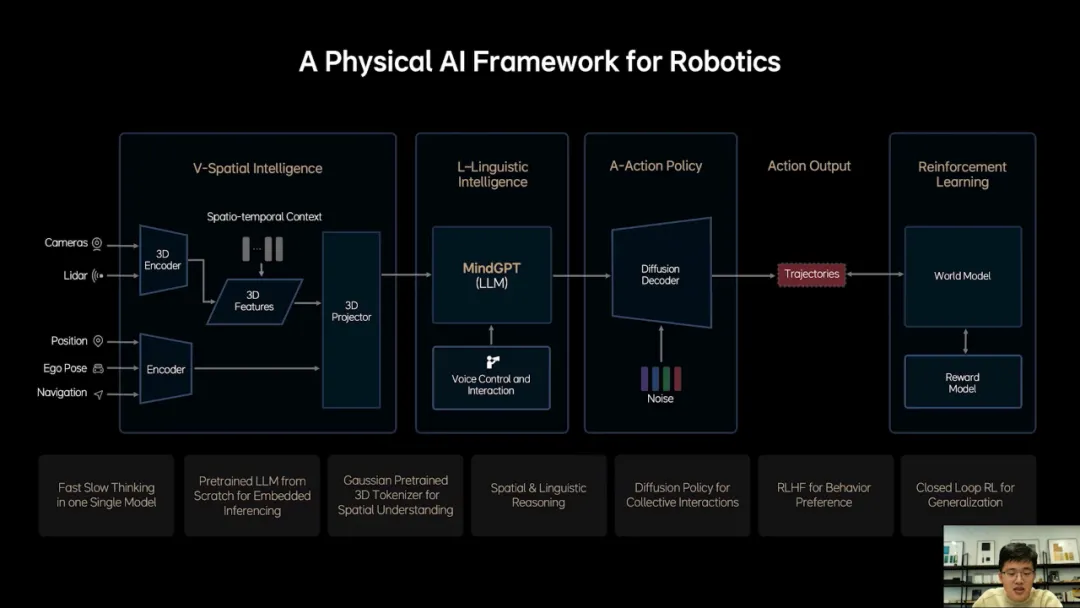
我把之前提到的相关论文也总结在这里,大家有兴趣可以看一看。

那么在技术分享之后,让我们转向用户更关心的产品形态和体验。VLA模型究竟能够为用户带来什么不同的产品体验,一句话总结,有MindVLA赋能的车不再只是一个驾驶工具,而是一个能够与用户沟通理解用户意图的司机。最后我们也展示一下在研发过程中的三个实车demo,也对应了我们日常生活中用车的三个场景。

首先来看第一个,当你来到一个陌生园区,想去某个特定商店,比如星巴克,但是具体的位置你不知道,在这种情况下,你只需要告诉车辆带我去星巴克,车辆将在没有导航信息的情况下,通过自主漫游找到目的地,在执行任务的过程中,你还可以随时进行人工干预,比如说开太快了开慢点了,或者说我觉得你应该走左边,感觉右边会绕远,通过这样的自然对话来改变它的路线和行为,MindVLA能够理解并执行这些指令,而且在认出目标商店后将你放在附近。
我要去星巴克,好的,开慢一点。
再快一点吧,前方路口左转,不要右转。明白。
还有一个大家经常遇到的情景,在一个陌生的城市打车时,你不知道如何描述你的位置,最终你找不到司机,司机也找不到你,当你拥有MindVLA赋能的车辆,就没有这样的烦恼了,你不需要描述你的位置,只需要拍一张附近环境的照片发给汽车,让车子自己来找你,他可以自己从车库开出来开出园区,经过一些城市道路找到图片中的位置把你介绍。
当你驾车来到商场地库找车位是件非常麻烦的事儿。
有了MindVLA,你只需要在超市门口下车,然后对车说自己去找个车位停好,MindVLA威能够理解你的指令,并利用他强大的空间推理能力自主寻找停车位,即使遇到了死胡同,他也会自如的倒车,然后重新寻找合适的车位停下。
整个过程中不依赖于地图或导航信息,只依赖于VLA强大的空间和逻辑推理能力。
这些场景展示了自动驾驶车辆如何从单纯的运输工具转变为贴心的专职司机,他能听得懂看得见找得到,想象一下,将来每个人拥有一个这样的司机,你可以让他接孩子,带老人去菜市场买菜,那将是一个多么令人愉悦的体验。
我们希望MindVLA能为自动驾驶车辆赋予类似人类的认知和适应能力,将它转变为能够思考的智能体,就像iPhone重新定义了手机,MindVLA也将重新定义自动驾驶。
#如何评价 CVPR 2025 的审稿结果
mtfy的回答
不会再审了,
但还是希望好的文章能够尽可能多地走到读者面前吧。
现在的书写套路太固化了,必须有公开的dataset,必须有公开的benchmark,必须有公开的baseline,必须有ablation,还得有帅帅的pipeline和满满的实验。其实,都到在现在这个时候了,这种套路反而是非常限制创新的,而且也没有做难题的土壤了。
如果没这些东西,那就几乎中不了,我真的不知道这到底是卷还是懒,还是说既卷又懒,再加上一堆一堆提前勾兑打招呼的,甚至还有不少直接造假的,真的没意思。
上一届分到我手里的,确实有几篇论文,很有新意,用新方法做了新问题,也能看出来作者做的很不容易,于是我给了高分,但其他审稿人只是喷没有dataset,没有benchmark,没有baseline,没有ablation,最后这几篇论文也没中。
哎,导师的难处,学生的难处,大厂研究者的难处,我也都理解,但我真的不知道这风气啥时候是个头。
总之我还是不审了。
CogitoErgoSum的回答
没卡=做不了火热的LLM/VLM/VLA/Video Generation/Diffusion...=none of sense.
做的low level vision的工作,得分223,被认为是none of sense....
哎,没卡没活路了呀~~~
ArthurMoon的回答
本菜鸟文章被拒习惯了,第一次这么生气
科普+质疑:更高分辨率图像生成的入门
随着扩散模型的迅猛发展,简单输入文字即可生成高质量的图片。当下最流行的生成模型主要有两种结构,旧时代的经典UNet(代表模型SDXL),暂时登基的新王DiT(代表模型FLUX)。然而两者都只能生成有限分辨率的结果,如果强制模型直接生成更高的分辨率(通俗说就是尺寸更大),会因为推理阶段的行为和训练阶段产生偏差导致各种问题。"更高分辨率生成"这个任务应运而生,其中一个主流分支就是不通过微调,直接纠正模型在推理阶段的偏差来获得更好的结果。
然而如上图所示,在直接生成更高分辨率的实验中,UNet模型遇到的问题是重复的物体随着分辨率的提高不断变多,而DiT模型遇到的问题是画质随着分辨率的提高不断退化。虽然两者的任务相同,但由于框架的区别,导致本身面临的问题也不同。之前绝大部分这个分支的论文,都是单独解决其中一者。举个例子,都是肠胃炎,细菌性肠胃炎和病毒性肠胃炎的诱因完全不同,所需要的治疗方式也大为不同。专业的审稿人既然拉满置信度,想必这么入门的知识不会不懂吧。
干货部分结束,下面是私货部分:然而某篇论文声称可以同时解决两者,经过实测,这个方法的其中三分之一,确实能起到一定作用,但远远达不到解决的程度,另外三分之二更是完全不兼容。最后这篇文章呢也没有被顶会录用,只能退而求其次找其他会议。但是偏偏凑巧,刚录用完甚至还没正式发表,俩审稿人就马上将之奉为榜样,全然无视之前那一年内的十几篇顶会都是只支持UNet,说不支持DiT就不配发。我一开始limitation主动提这个局限性,我觉得大家都没解决列出来完全没问题,然后这俩审稿人就用他们的榜样来贬低我的工作。我一看他们说的榜样,就这效果也好意思说兼容俩框架?欣然摆出实验反驳说按这个这么低的标准我也能兼容效果还更好些。结果他们双标到说哦你这个只有一部分生效了,其他部分不生效,所以还是要拒你。天呢你忘了你自己提的榜样也是只有一部分生效?我都明确说了这一点还故意视而不见是吧。
光荣与梦想的回答
结论 : 审稿质量依旧底下
证据 : 有两个审稿人在major weakness 里说: 你在文章里提到 1 使用了GAN. 但是1根本没用GAN. 拒稿.
我的反驳 : 1明明说了 "we used a ForkGAN mode to ..."
评论: 我不知道在PDF 文件里搜索一下GAN 这个词到底有多么难. 眼睛不要可以捐献
谁知我这种男孩子的回答
第一次投论文,就来挑战cvpr2025了,反正是初生牛犊不怕虎,哈哈哈。分数232(434),第一个2分,问我为啥不和sota比,然后又说我这个和sota比没有分数优势,和最新的idea比没有足够的创新,然后又说为什么我不去跑一跑别人的论文基线,而是直接采用他们论文中的数据,然后又问我在第二章相关工作中,为什么谈到了一些方法(2016 2017年的),但是最后没有拿出来比,但是我在最后的模型比较里面比的都是最新的论文2018-2024年的。然后就是经典的质疑:"你说你要在最后版本放出代码,那你真有这么好的效果吗,你的模型看起来一点也不复杂,我感觉这种简单模型不可能有好效果,所以我对你的代码保持高度质疑"
第二个评审人给的3分,主要是提了我的图片画的不够好,然后表格中最好把标准差这些也画出来,然后说我的图5可以删掉。
第三个评审人给的2分,主要是说我的创新不够,然后又说我的论文有些地方拼写错误,格式有瑕疵(有些地方忘了打空格),然后又说我最后的结论写的不够详细。
我已经准备润了,去试一试期刊把。哈哈哈。
看见大家都比较好奇,我就再补充一点,评审并没有全提那种抽象的意见,也提了一些画图的意见和全文组织布局的意见,然后评委格外关注我的公式的推导过程,我有一步跳步了,就被三个评委都问了。
然后就是评委也说了,你这个尽量要和最新的相关工作多做比较,写明他们方法的劣势,你从中得出的启发,从而如何设计出你的方法。
但是第一个评委有点抽象,他问我:"你这个和别人都是做特征对齐的工作,既然别人的方法已经很优秀了,为什么你还要做你这个方法,请列出你的必要性。这个方向已经有人在做了,你这工作应该算是增量性的,而不是创新性的"。我都无大语了,照你这么说,别人(sota)谈了一个好方法,我们这后来的方法只要效果比不上他,那就都没有必要了哇?而且他在这个方向提了一个方法,我再提出我的方法,那我这个就不是创新了吗?不过这就是我在口嗨,我根本没去回复他。哈哈哈,只敢意淫一下咯。