关于Transformer模型的Encoder-Decoder模块网上介绍的文章非常多,写的非常详尽,可谓汗牛充栋,尤其关于注意力计算这块,不仅给出了公式而且还有具体的计算步骤。关于Transformer模型我觉得大部分文章语焉不详的有两块(可能是我的理解力比较差):
一是关于FNN层的,就是FNN层是如何升维的。 升维使用的核函数是什么?为何升维能提升语义的表达并产生"记忆"功能?为何将维度升4倍,而不是6倍,8倍?
关于FNN层也有一些文章进行解读,大部分都会以CNN的卷积神经网络进行类比:即一个是Token mixer,关注在L这个维度的表达;一个是Channel mixer,专注于d这个维度的表达。至于为何升维4倍,没有什么理论基础,就像8头注意力一样,可能4倍的实验数据效果最好,是性价比最优的选择。
另一个是关于Decoder层最终输出的,就是如何给目标token打分的。 相较于注意力机制的计算,大部分文章对最终输出这块几乎都是一笔带过,大体描述为:需要一个线性层(Linear)变换给目标词汇打分,然后使用Softmax对所有分数归一化,从而找出下一个token的概率分布,概率最高的就是要输出的token。
这种描述好像说了什么,但好像什么也没说。就好比说注意力机制就是计算各个token对其它token的打分,从而进行加权求和。大道理大方向是这么回事,但还是无法落地,也就是具体的计算步骤到底是什么?即使是给出了Python代码实现,也是对内部计算的封装,这就意味着你还是无法了解其具体的实现方法。
对于GPT这种Decoder-Only模型,因为没有Encoder模块协助全局语义关系的捕捉,因此其最终的输出要更加困难和复杂。它只能根据前面输入的所有token来预测下一个token。注意力机制解决的是已输入token间的关注度,从而提升各个token对现有上下文的理解程度,但这并意味着能直接预测出下一个token。
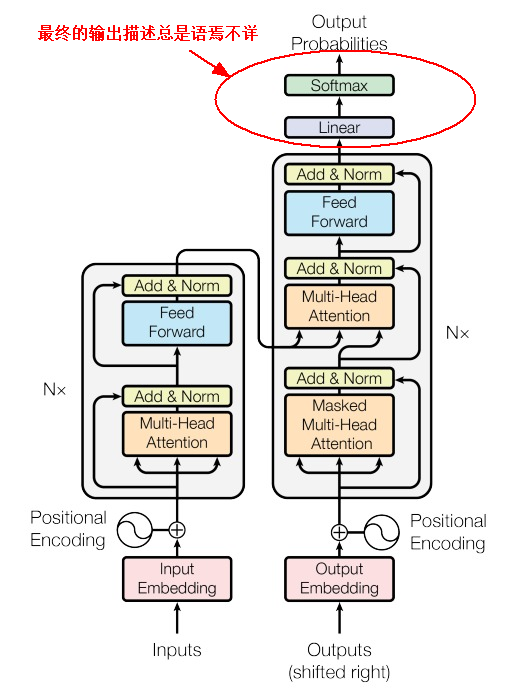
下面给出Decoder层最后输出token的计算方法。
1、假设已输入token: \\text{x}_1 、\\text{x}_2、\\text{x}_3 ,现在要预测下一个token: \\text{x}_4
2、经过Decoder模块上述3个token对应的特征向量为: \\text{z}_1 、 \\text{z}_2、\\text{z}_3
3、目标词汇表c,共有N个token:
\\\text{c}_1、\\text{c}_2、\\text{c}_3 、\\text{c}_4 ......,\\text{c}_{n-1} ,\\text{c}_n \\
现在的问题是: Decoder层在预测下一个token时,是如何进行线性变换并在目标词汇表c中找出 \\text{x}_4 的。
1、计算当前每个输入token x与目标词汇表中每个c的注意力分数
\\\text{Attention Score} = \\text{softmax}(\\frac{QK\^T}{\\sqrt{d_k}}) \\
这一个步和注意力机制中的计算方式一样,就是计算当前已输入的每个x与目标词汇所有c的关注度,为了方便描述,不考虑QKV,只是计算向量间的内积:
\对于第1个token:\\text{x}_1,则有:\\text{z}_1 \\text{c}_1、\\text{z}_1 \\text{c}_2、\\text{z}_1 \\text{c}_3....., \\text{z}_1 \\text{c}_n \\
\对于第2个token:\\text{x}_2,则有:\\text{z}_2 \\text{c}_1、\\text{z}_2\\text{c}_2、\\text{z}_2 \\text{c}_3....., \\text{z}_2 \\text{c}_n \\
\对于第3个token:\\text{x}_3,则有:\\text{z}_3 \\text{c}_1、\\text{z}_3\\text{c}_2、 \\text{z}_3 \\text{c}_3 .....,\\text{z}_3 \\text{c}_n \\
通过Softmax对关注度分数进行归一化操作。此时每个x会计算出目标词汇的注意力分数"Attenttion Score"。
注:上述的z是x经过Decoder模块运算后包含了注意力信息和上下文语义信息的向量,就是最后一步Linear的输入参数之一(见上图红色框)。
2、使用上述注意力分数来加权目标词汇的值向量并求和
\\\text{Context Vector} = \\sum_{i} \\text{Attention Score}_i \\times \\text{Value}_i \\
\对于第1个目标词汇\\text{c}_1则有:\\text{z}(c_1)= \\text{z}_1 \\text{c}_1+ \\text{z}_2 \\text{c}_1+\\text{z}_3 \\text{c}_1 \\
\对于第2个目标词汇\\text{c}_2则有:\\text{z}(c_2)= \\text{z}_1 \\text{c}_2+ \\text{z}_2 \\text{c}_2+\\text{z}_3 \\text{c}_2 \\
\对于第3个目标词汇\\text{c}_3则有:\\text{z}(c_3)= \\text{z}_1 \\text{c}_3+ \\text{z}_2 \\text{c}_3+\\text{z}_3 \\text{c}_3 \\
..........
\对于第n个目标词汇\\text{c}_n则有:\\text{z}(c_n)= \\text{z}_1 \\text{c}_n+ \\text{z}_2 \\text{c}_n+\\text{z}_3 \\text{c}_n \\
直观的理解就是将每个已输入token x对每个目标词汇c的值向量求和,从而产生新的目标向量: \\text{z}(c_n)。这个新产生的目标向量融合了已输入所有token(本案例中的3个输入x)对其的关注度,并包含了当前上下文的语义信息,这一点非常重要。
到了这一步还是无法预测出下一个token,这时的输出是 N 个目标词汇 c 的新特征向量 \\text{z}(c_n)。此时无法根据该值来预测下一个token。接下来,使用这个加权的上下文向量和当前解码器的隐藏状态来生成针对下一个token的分数,也就是下面最重要的一步,也是目前很多文档语焉不详的地方。
3、如何给每个目标词汇打分
\\\text{Score} = \\text{Output Layer}(\[\\text{Context Vector}; \\text{Decoder Hidden State}) \]
这个公式比较难以理解,其实就是: \\text{c}_n与新产生的特征向量 \\text{z}(c_n)进行内积,公式为: \\text{Score}_n=\\text{c}_n \* \\text{z}(c_n)
其目的就是计算目标token与该token在当前上下文中产生新特征后的投影大小。为何要这样计算呢?词汇表中的N个词(token)就意味着N个输出,但只有一个目标词汇的特征最能融入当前的上下文,融入新特征的向量与其自己的内积越大,则说明该词最合适。
到了这一步下面的工作就非常简单,只需要通过Softmax对N个目标词汇分数进行归一化,算出概率最大的就是要输出的token。
最后我想说的的是,以上都是我猜的,如果有误概不负责但欢迎指正。