For natural scene OCR, our model mainly supports Chinese and English. The image data
sources come from LAION 31 and Wukong 13 , labeled using PaddleOCR 9 , with 10M data samples each for Chinese and English. Like document OCR, natural scene OCR can also control whether to output detection boxes through prompts.
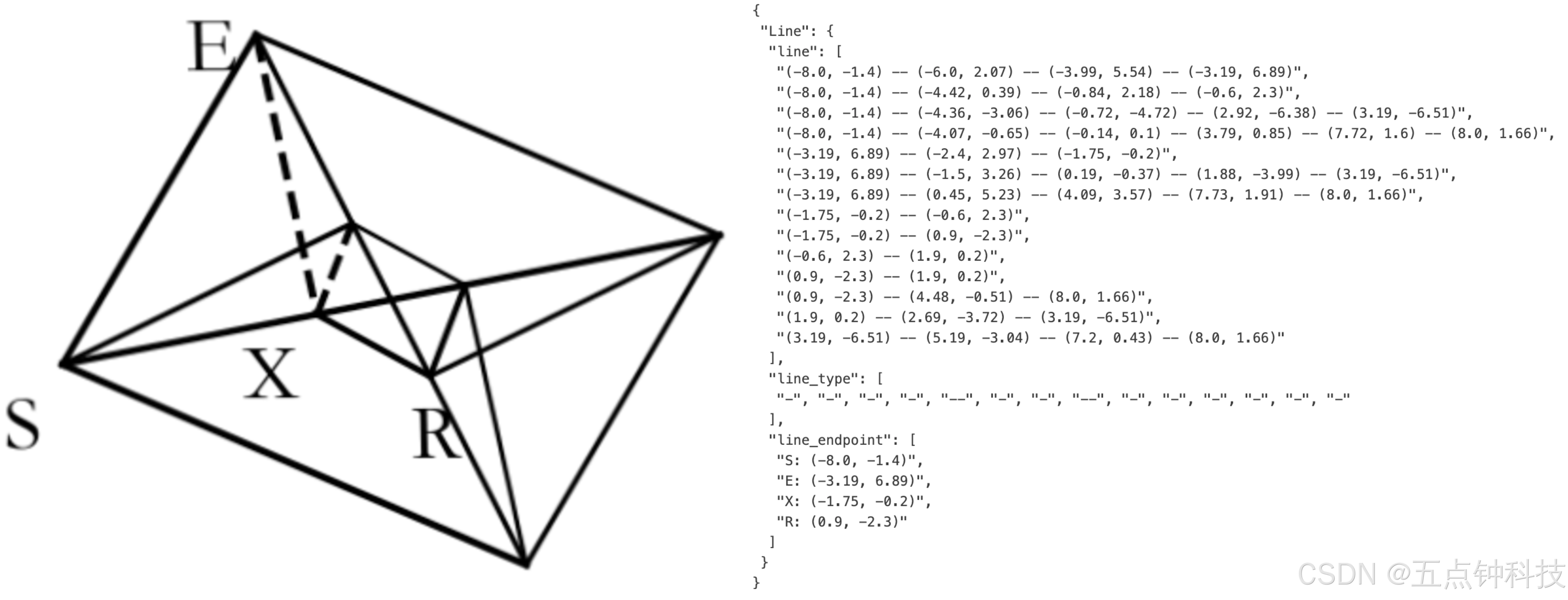
Following GOT-OCR2.0 38 , we refer to chart, chemical formula, and plane geometry parsing data as OCR 2.0 data. For chart data, following OneChart 7 , we use pyecharts and matplotlib to render 10M images, mainly including commonly used line, bar, pie, and composite charts. We define chart parsing as image-to-HTML-table conversion task, as shown in Figure 6(a). For chemical formulas, we utilize SMILES format from PubChem as the data source and render them into images using RDKit, constructing 5M image-text pairs. For plane geometry images, we follow Slow Perception 39 for generation. Specifically, we use perception-ruler size as 4 to model each line segment. To increase the diversity of rendered data, we introduce geometric translation-invariant data augmentation, where the same geometric image is translated in the original image, corresponding to the same ground truth drawn at the centered position in the coordinate system. Based on this, we construct a total of 1M plane geometry parsing data, as illustrated in Figure 6(b).
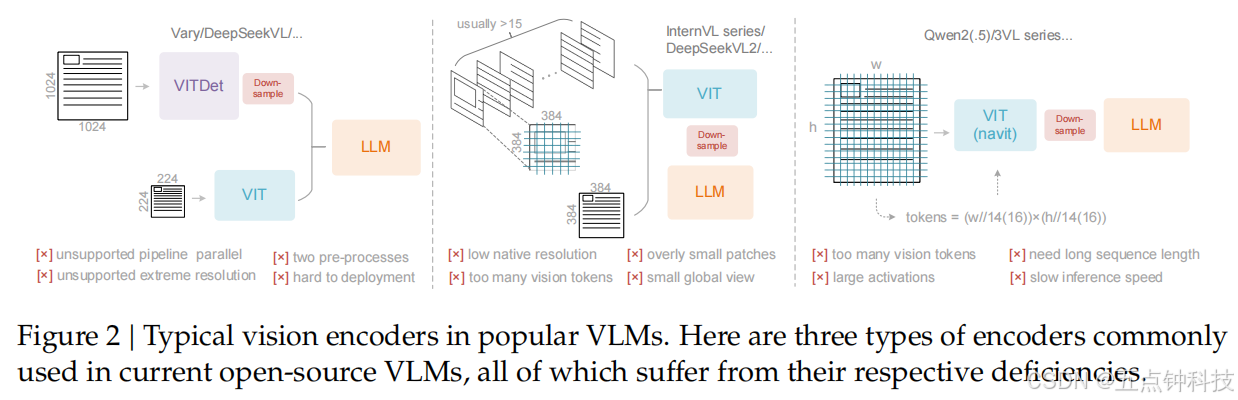
DeepEncoder can benefit from CLIP's pretraining gains and has sufficient parameters to in
corporate general visual knowledge. Therefore, we also prepare some corresponding data for
DeepSeek-OCR. Following DeepSeek-VL2 40 , we generate relevant data for tasks such as
caption, detection, and grounding. Note that DeepSeek-OCR is not a general VLM model, and
this portion of data accounts for only 20% of the total data. We introduce such type of data
mainly to preserve the general vision interface, so that researchers interested in our model and
general vision task can conveniently advance their work in the future.
To ensure the model's language capabilities, we introduced 10% of in-house text-only pretrain
data, with all data processed to a length of 8192 tokens, which is also the sequence length
for DeepSeek-OCR. In summary, when training DeepSeek-OCR, OCR data accounts for 70%,
general vision data accounts for 20%, and text-only data accounts for 10%.
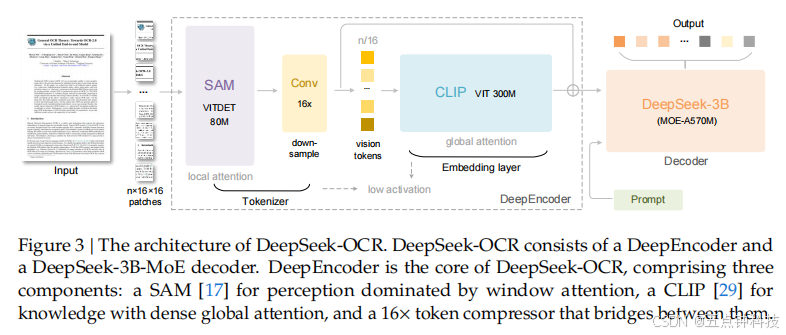
Our training pipeline is very simple and consists mainly of two stages: a).Training DeepEncoder
independently; b).Training the DeepSeek-OCR. Note that the Gundam-master mode is obtained
by continuing training on a pre-trained DeepSeek-OCR model with 6M sampled data. Since the
training protocol is identical to other modes, we omit the detailed description hereafter.
Following Vary 36 , we utilize a compact language model 15 and use the next token prediction
framework to train DeepEncoder. In this stage, we use all OCR 1.0 and 2.0 data aforementioned,
as well as 100M general data sampled from the LAION 31 dataset. All data is trained for
2 epochs with a batch size of 1280, using the AdamW 23 optimizer with cosine annealing
scheduler 22 and a learning rate of 5e-5. The training sequence length is 4096.
After DeepEncoder is ready, we use data mentioned in Section 3.4 to train the DeepSeek-OCR.
with the entire training process conducted on the HAI-LLM 14 platform. The entire model
uses pipeline parallelism (PP) and is divided into 4 parts, with DeepEncoder taking two parts
and the decoder taking two parts. For DeepEncoder, we treat SAM and the compressor as the
vision tokenizer, place them in PP0 and freeze their parameters, while treating the CLIP part as
input embedding layer and place it in PP1 with unfrozen weights for training. For the language
model part, since DeepSeek3B-MoE has 12 layers, we place 6 layers each on PP2 and PP3. We
use 20 nodes (each with 8 A100-40G GPUs) for training, with a data parallelism (DP) of 40 and
a global batch size of 640. We use the AdamW optimizer with a step-based scheduler and an
initial learning rate of 3e-5. For text-only data, the training speed is 90B tokens/day, while for
multimodal data, the training speed is 70B tokens/day.
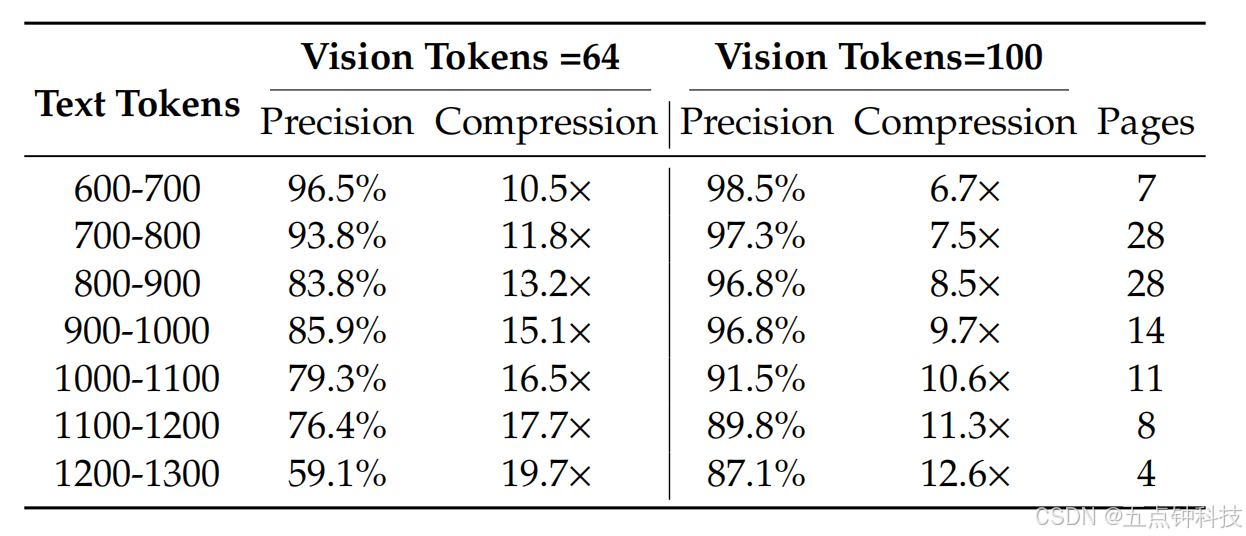
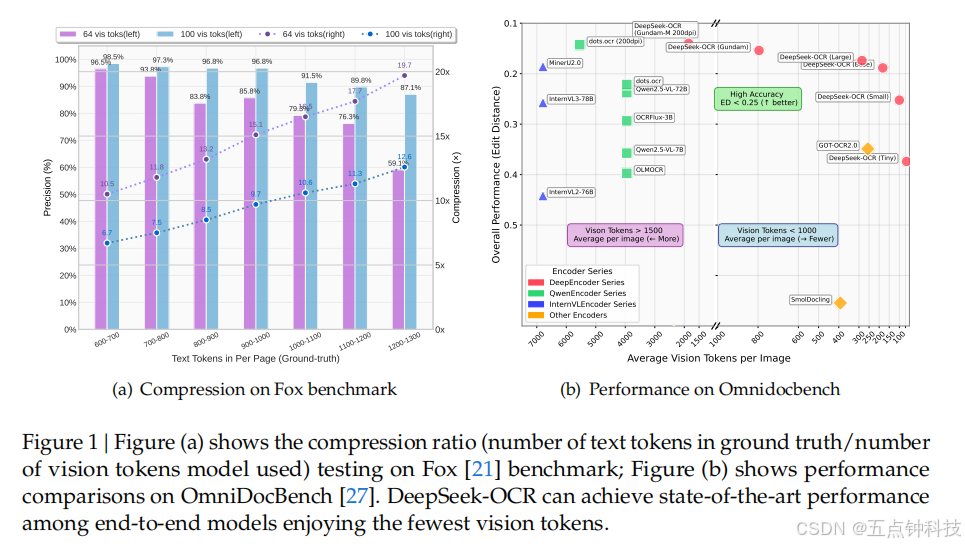
We select Fox 21 benchmarks to verify DeepSeek-OCR's compression-decompression capability for text-rich documents, in order to preliminarily explore the feasibility and boundaries of contexts optical compression. We use the English document portion of Fox, tokenize the ground truth text with DeepSeek-OCR's tokenizer (vocabulary size of approximately 129k), and select documents with 600-1300 tokens for testing, which happens to be 100 pages. Since the number of text tokens is not large, we only need to test performance in Tiny and Small modes, where Tiny mode corresponds to 64 tokens and Small mode corresponds to 100 tokens. We use the prompt without layout: "<image>\nFree OCR." to control the model's output format. Nevertheless, the output format still cannot completely match Fox benchmarks, so the actual performance would be somewhat higher than the test results.
下面是对表2的再次说明。
As shown in Table 2, within a 10 × compression ratio, the model's decoding precision can
reach approximately 97%, which is a very promising result. In the future, it may be possible to
achieve nearly 10 × lossless contexts compression through text-to-image approaches. When the
compression ratio exceeds 10 × , performance begins to decline, which may have two reasons:
one is that the layout of long documents becomes more complex, and another reason may be
that long texts become blurred at 512 × 512 or 640 × 640 resolution. The first issue can be solved
by rendering texts onto a single layout page, while we believe the second issue will become a feature of the forgetting mechanism. When compressing tokens by nearly 20× , we find that
precision can still approach 60%. These results indicate that optical contexts compression is
a very promising and worthwhile research direction, and this approach does not bring any
overhead because it can leverage VLM infrastructure, as multimodal systems inherently require
an additional vision encoder.
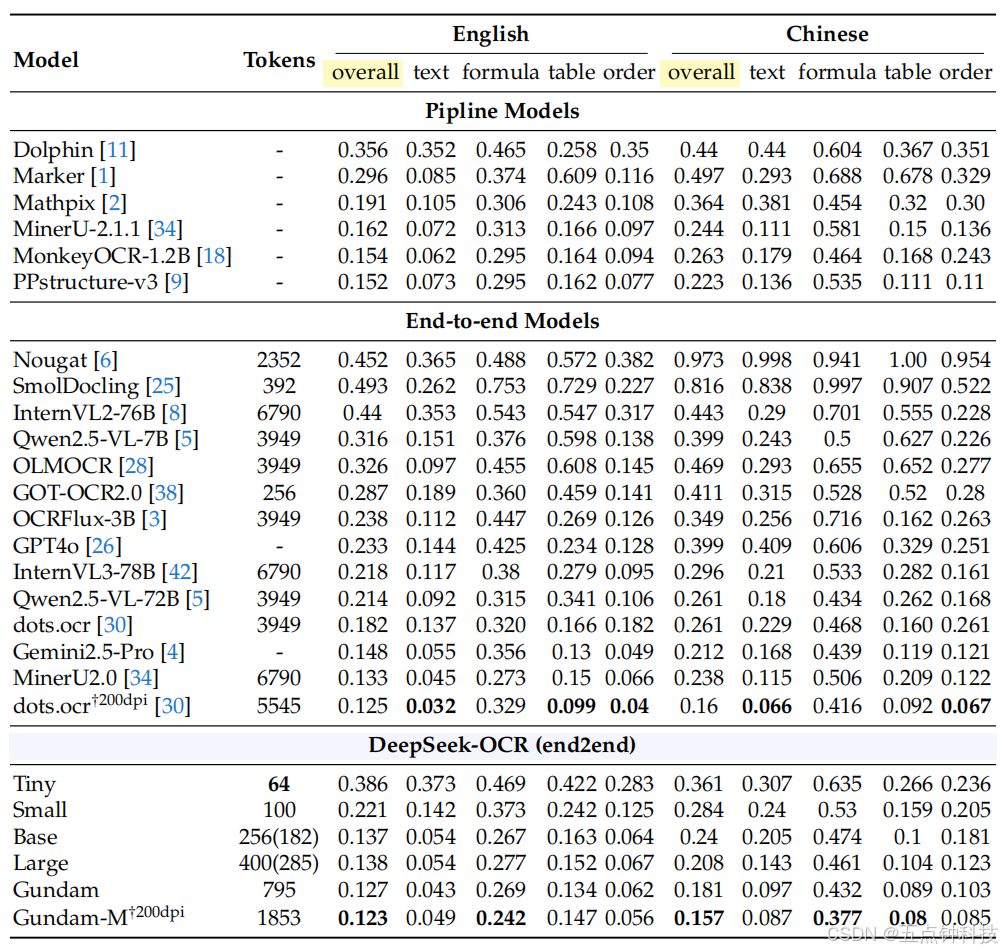
DeepSeek-OCR is not only an experimental model; it has strong practical capabilities and can
construct data for LLM/VLM pretraining. To quantify OCR performance, we test DeepSeek
OCR on OmniDocBench 27 , with results shown in Table 3. Requiring only 100 vision tokens
(640 × 640 resolution), DeepSeek-OCR surpasses GOT-OCR2.0 38 which uses 256 tokens; with
400 tokens (285 valid tokens, 1280 × 1280 resolution), it achieves on-par performance with state
of-the-arts on this benchmark. Using fewer than 800 tokens (Gundam mode), DeepSeek-OCR
outperforms MinerU2.0 34 which needs nearly 7,000 vision tokens. These results demonstrate
that our DeepSeek-OCR model is powerful in practical applications, and because the higher
tokens compression, it enjoys a higher research ceiling.
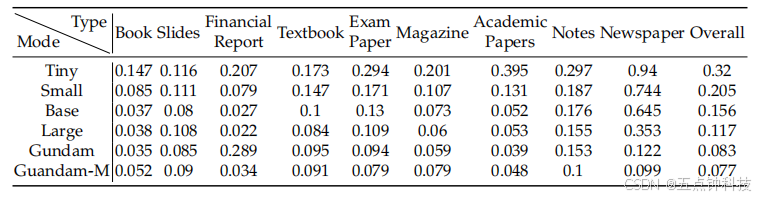
As shown in Table 4, some categories of documents require very few tokens to achieve
satisfactory performance, such as slides which only need 64 vision tokens. For book and
report documents, DeepSeek-OCR can achieve good performance with only 100 vision tokens.
Combined with the analysis from Section 4.1, this may be because most text tokens in these
document categories are within 1,000, meaning the vision-token compression ratio does not
exceed 10 × . For newspapers, Gundam or even Gundam-master mode is required to achieve
acceptable edit distances, because the text tokens in newspapers are 4-5,000, far exceeding the
10 × compression of other modes. These experimental results further demonstrate the boundaries
of contexts optical compression, which may provide effective references for researches on the
vision token optimization in VLMs and context compression, forgetting mechanisms in LLMs.
DeepSeek-OCR possesses both layout and OCR 2.0 capabilities, enabling it to further parse
images within documents through secondary model calls, a feature we refer to as "deep parsing".
As shown in Figures 7,8,9,10, our model can perform deep parsing on charts, geometry, chemical
formulas, and even natural images, requiring only a unified prompt.
PDF data on the Internet contains not only Chinese and English, but also a large amount of
multilingual data, which is also crucial when training LLMs. For PDF documents, DeepSeek
OCR can handle nearly 100 languages. Like Chinese and English documents, multilingual data
also supports both layout and non-layout OCR formats. The visualization results are shown in
Figure 11, where we select Arabic and Sinhala languages to demonstrate results.
We also provide DeepSeek-OCR with a certain degree of general image understanding capabili
ties. The related visualization results are shown in Figure 12.
Our work represents an initial exploration into the boundaries of vision-text compression, inves
tigating how many vision tokens are required to decode 𝑁 text tokens. The preliminary results
are encouraging: DeepSeek-OCR achieves near-lossless OCR compression at approximately
10 × ratios, while 20 × compression still retains 60% accuracy. These findings suggest promising
directions for future applications, such as implementing optical processing for dialogue histories
beyond 𝑘 rounds in multi-turn conversations to achieve 10 × compression efficiency
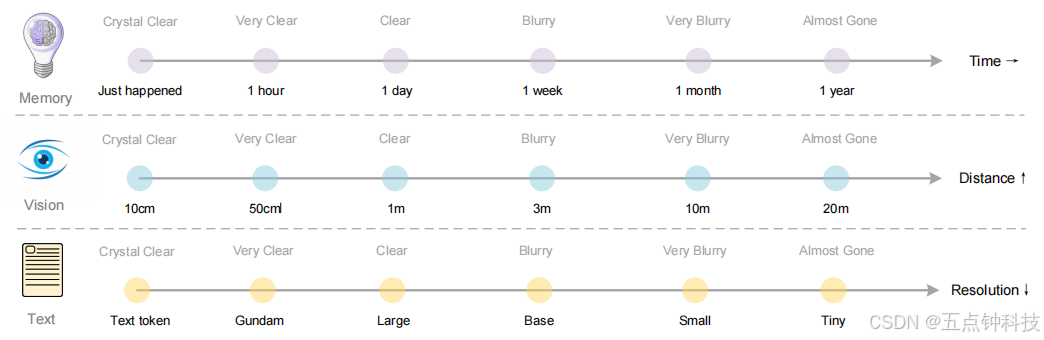
遗忘机制是人类记忆最基本的特征之一。上下文光学压缩方法可以模拟这种机制:将前几轮的历史文本渲染到图像上进行初步压缩,然后逐步调整旧图像的尺寸以实现多级压缩,在此过程中,标记数量逐渐减少,文本变得越来越模糊,从而实现文本遗忘。
For older contexts, we could progressively downsizing the rendered images to further reduce
token consumption. This assumption draws inspiration from the natural parallel between
human memory decay over time and visual perception degradation over spatial distance---both
exhibit similar patterns of progressive information loss, as shown in Figure 13. By combining
these mechanisms, contexts optical compression method enables a form of memory decay that
mirrors biological forgetting curves, where recent information maintains high fidelity while
distant memories naturally fade through increased compression ratios.
While our initial exploration shows potential for scalable ultra-long context processing,
where recent contexts preserve high resolution and older contexts consume fewer resources,
we acknowledge this is early-stage work that requires further investigation. The approach
suggests a path toward theoretically unlimited context architectures that balance information
retention with computational constraints, though the practical implications and limitations of
such vision-text compression systems warrant deeper study in future research.
In this technical report, we propose DeepSeek-OCR and preliminarily validate the feasibility of
contexts optical compression through this model, demonstrating that the model can effectively
decode text tokens exceeding 10 times the quantity from a small number of vision tokens. We
believe this finding will facilitate the development of VLMs and LLMs in the future. Addi
tionally, DeepSeek-OCR is a highly practical model capable of large-scale pretraining data
production, serving as an indispensable assistant for LLMs. Of course, OCR alone is insufficient
to fully validate true context optical compression and we will conduct digital-optical text in
terleaved pretraining, needle-in-a-haystack testing, and other evaluations in the future. From
another perspective, optical contexts compression still offers substantial room for research and
improvement, representing a promising new direction.











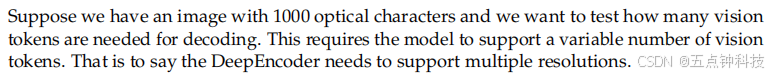






,