引言
最近遇到了一个 ActiveMQ 消费端的问题:在没有消息时,日志频繁打印,每秒打印2000多条空消息,导致日志文件迅速膨胀,甚至影响系统性能。经过一番排查,最终定位到问题根源并成功解决。本文将详细记录问题的排查过程、原因分析以及解决方案,希望能为遇到类似问题的同学提供参考。
背景
最近优化了一个 ActiveMQ 消费端应用消费速度慢的问题,原先采用 Spring 的@Scheduled定时每秒调用ActiveMQMessageConsumer.receive(2000)拉取消息并同步处理,简化后的代码如下:
java
@Scheduled(cron = "1/0 * * * * ?")
public void consumer(){
new Thread(()->{
try{
logger.info("ActiveMQClient-->receive begin queue_name = {}", QUEUE_NAME);
ActiveMQMessage msg = (ActiveMQMessage )activeMQMessageConsumer.receive(2000);
if(null != msg){
processMsg(msg);//同步处理消息并手动确认
}
} catch(Exception e){
logger.error("ActiveMQClient-->receive error:", e);
}
}).start();
}可以看到在调用receive之前打印了一条日志。当队列无消息时 ,上述代码中的日志每秒打印一次(定时每秒启动一个线程),日志文件每天最多2-3个。
当业务量激增时,以上每秒消费一条消息的方式远远满足不了业务需求,且会造成 ActiveMQ 服务端消息积压,故做了以下优化,简化后的代码如下:
java
ExecutorService THREAD_POOL = Eecutors.newFiexdThreadPool(1)
@PostConstruct
public void startConsumer(){
THREAD_POOL.submit(()->{
while(true){
try{
logger.info("ActiveMQClient-->receive begin queue_name = {}", QUEUE_NAME);
ActiveMQMessage msg = (ActiveMQMessage )activeMQMessageConsumer.receive(2000);
if(null != msg){
processMsg(msg);
}
} catch(Exception e){
logger.error("ActiveMQClient-->receive error:", e);
}
}
});
}上述改造采用单线程(为了保持消息消费的有序性)循环执行消息拉取和处理逻辑,相比原先定时任务1秒消费一条消息消费能力有明显提升,另外当队列无消息时receive方法会阻塞两秒,也不会造成线程空转。上述改造部署后,特意观察了无消息时的日志打印频率,确实为2秒一次,日志量和之前相差无几。准备愉快的上线了。
问题描述
上线前夕,有其他小伙伴在测试环境通过日志排查问题时,发现当天早上日志文件数量就达到了130+,根本不知道该看哪个日志文件。于是我打开其中一个文件统计了一下每秒打印ActiveMQClient-->receive begin queue_name高达2000多条(队列无消息时),貌似队列无消息时receive(2000)阻塞两秒失效了,导致线程在空转,一直拉取消息,导致日志量暴增!
排查过程
1. 初步分析
- 怀疑
receive(2000)方法的超时设置失效,导致立即返回null。 - 检查代码和配置文件,确认
receive(2000)的超时时间为 2 秒。
2. 进一步排查
对此我感到一头雾水,为啥超时时间会失效呢?我明明记得当时在测试环境特意观察了日志,无消息时确实是每两秒打印一次。
-
重启大法:于是我重启消费端程序,观察了一会儿日志,也是每两秒打印一次,这下更懵逼了!
-
观察日志:没办法,只能继续找问题了。我查看服务器日志,文件太多了,每天都是一百多个压缩文件。我随便找了某天的第一个文件和最后一个文件,打开最后一个文件从文件末尾看,日志频繁打印。打开第一个文件,文件开头从零点开始打印,也是非常频繁,然后我按时间查找中午十点多的,发现日志又正常每两秒打印一次(没消息时),太奇怪了。
-
查找日志变化拐点 :然后我想看看是从什么时候开始变得频繁,果然有了新发现。在那天的第一个文件里,从
22:01:07起日志几乎一秒打印2000多条。在此之前紧挨着有几条ActiveMQ的日志,如下图:

貌似ActiveMQ关闭某个线程池,从关闭后日志就变得频繁。根据日志发现等待了10秒,最终停止了线程池。
于是我根据日志位置找到对应源码,这段代码定义了一个名为awaitTermination的静态方法,用于等待线程池的终止。这个方法的主要目的是确保在关闭线程池之前,所有提交给线程池的任务都已完成执行。参数executorService是要等待终止的线程池,shutdownAwaitTermination是等待线程池终止的最大时间,以毫秒为单位。

找到调用awaitTermination的地方,即ThreadPoolUtils#doShutdown,它先调用了线程池的shutdown方法,然后调用awaitTermination等待线程终止,根据日志可以看到等待了10秒线程都没终止,最后强行调用shutdownNow方法,然后输出了Shutdown of ExecutorService:.....日志,对应上图中最后一条日志。

然后继续向上找调用ThreadPoolUtils#doShutdown的地方最终找到是在AbstractInactivityMonitor#stopMonitorThreads。由于调用这个方法的地方非常多,无法准确找到是在哪调用的。这条线索中断。
3. 灵机一动,发现突破口
正当我们有头绪时,突然想到去看看ERROR日志文件,看了一下ERROR日志文件比Info文件更多!于是我解压第一个ERROR日志文件,打开后根据Info日志中线程池关闭的时间22:00:07去搜索,果然发现了猫腻。
几乎相同时间,AbstractInactivityMonitor的246行抛出了InactivityIOException:Channel was inactive for too (>30000) long异常,即"频道长时间处于非活动状态"

在后续的ERROR日志中,全部都是IllegalStateException:The Consumer is closed异常,表明客户端和ActiveMQ服务端的连接已经断开!
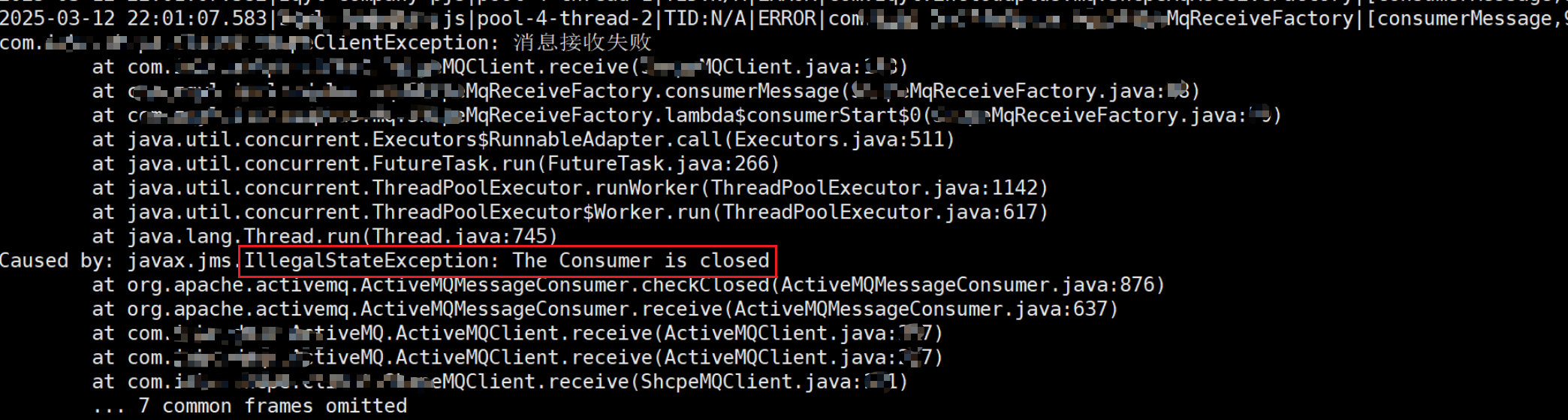
这也就解释了为什么receive(2000)阻塞两秒失效,while循环调用receive拉消息,由于连接已断开,方法立即报错,又不停地拉可不就一直打日志嘛!
为什么连接被断开了?
问了一波AI,给出的回答如下:

- 心跳检测默认是开启的,所以第一个被排除。
- 日志中没有看到重连,被排除。
- 第三种也不符合。
又陷入了僵局~
马上就要上线了,必须赶快排查出根本原因!
这时候原来负责这块儿的同事突然想到测试环境MQ服务端每天晚上十点停机!
???
挖了个渠~好坑
生产环境MQ服务端不会停机
解决方案
解决方法很简单,在原代码逻辑的try-catch的catch模块增加代码使线程休眠1秒。
java
ExecutorService THREAD_POOL = Eecutors.newFiexdThreadPool(1)
@PostConstruct
public void startConsumer(){
THREAD_POOL.submit(()->{
while(true){
try{
logger.info("ActiveMQClient-->receive begin queue_name = {}", QUEUE_NAME);
ActiveMQMessage msg = (ActiveMQMessage )activeMQMessageConsumer.receive(2000);
if(null != msg){
processMsg(msg);
}
} catch(Exception e){
logger.error("ActiveMQClient-->receive error:", e);
try {
Thread.sleep(1000);
} catch (InterruptedException ex) {
logger.error("ActiveMQClient-->sleep error after receive error :", ex);
}
}
}
});
}回过头看,原来的代码确实存在隐患(抛异常后会立马进入下次while循环),幸亏在测试环境发现了。
复盘
现象
- 消费端使用
while循环调用receive(2000)方法拉取消息。 - 当没有消息时,日志应每 2 秒打印一次
ActiveMQClient-->receive begin queue_name"。 - 实际运行时,日志每秒打印高达 2000 次,导致日志刷屏,日志量暴涨。
原因
- 日志分析 :发现Info日志中出现
ActiveMQ InvativityMonitor Worker关闭了某个线程池,且ERROR日志出现InactivityIOException::Channel was inactive for too (>30000) long异常,之后频繁出现IllegalStateException: The Consumer is closed异常。异常日志的打印时间与Info日志开始频繁打印的时间吻合。 - 连接状态 :最终确认连接因服务端关闭,ActiveMQ Client端
InactivityMonitor检测到不活跃而断开。 - 消费者状态 :连接断开后,消费者失效,
receive()立即返回null,线程还在不停while循环调用receive,进而导致日志刷屏,日志量暴涨。
根本原因
- 服务端关闭:服务端每晚关闭,导致连接中断。
- 消费者失效 :连接断开后,消费者继续调用
receive()导致异常。 - 日志刷屏 :
while循环频繁调用失效的receive(),日志频繁打印。
探索ActiveMQ的断连机制
发现 AbstractInactivityMonitor
- 在日志中发现了
AbstractInactivityMonitor关键字,进一步查看源码,了解到其作用。 - 源码分析 :
AbstractInactivityMonitor是 ActiveMQ 中用于监控连接活跃性的核心组件,其readCheckerTask机制用于定期检查连接状态。
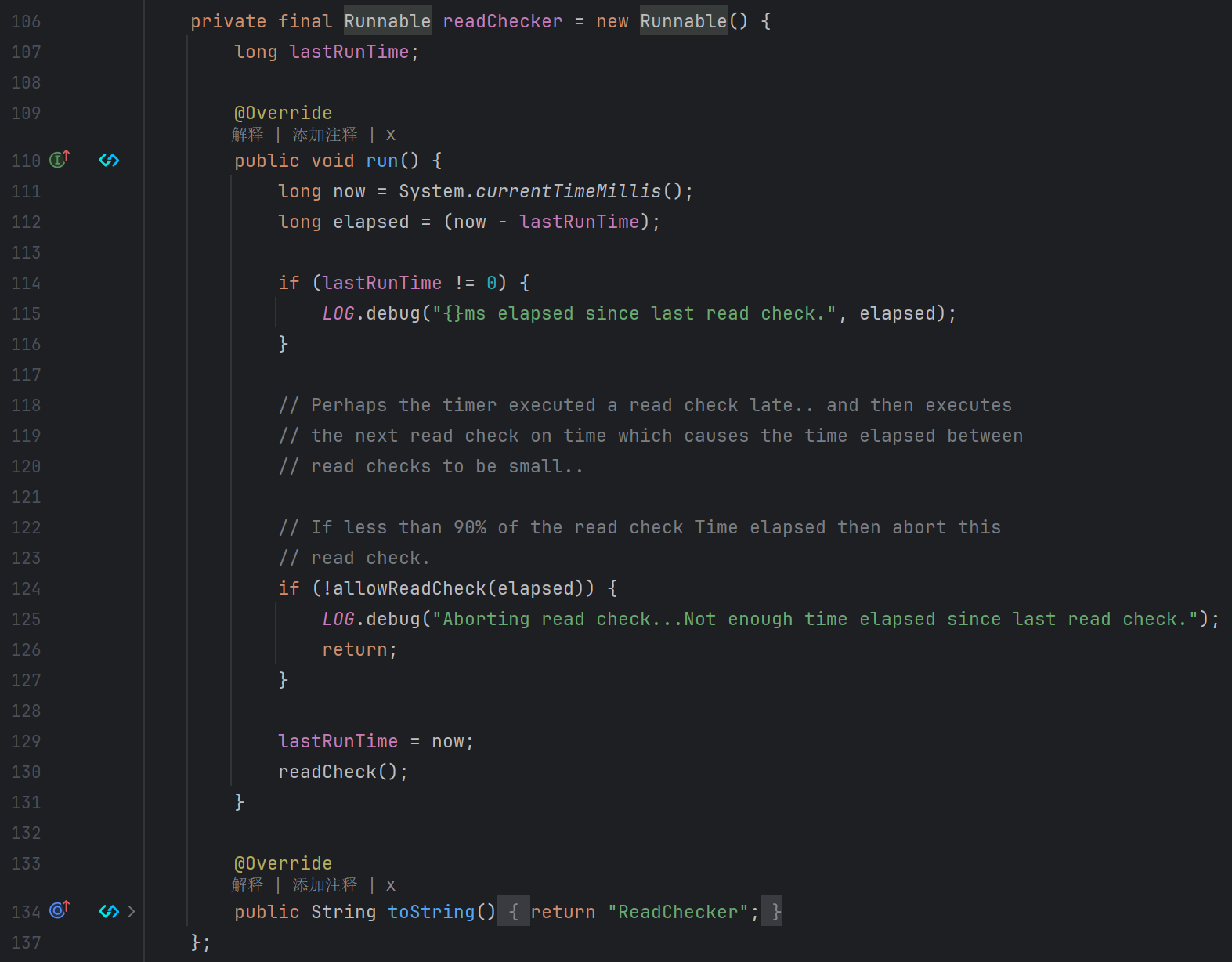
readCheckerTask
readCheckerTask是SchedulerTimerTask实例,通过Java中的Timer定时器周期性的执行任务,默认30秒执行一次。readCheckerTask具体执行的任务如下:
-
实现原理
- 获取当前时间:使用System.currentTimeMillis()获取当前时间。
- 计算时间差:计算当前时间与上次运行时间之间的差值。
- 检查上次运行时间:如果上次运行时间不为0,则记录自上次读取检查以来经过的时间。
- 允许读取检查:如果自上次读取检查以来经过的时间小于90%,则放弃当前的读取检查。
- 执行读取检查 :如果时间足够,则执行
readCheck()。 - 更新上次运行时间:无论是否执行了读取检查,都会更新lastRunTime为当前时间。
-
作用
这段代码确保读取检查不会过于频繁地执行,从而避免资源浪费或潜在的性能问题。当判断通过时执行
readCheck()。
readCheck()
源码如下:
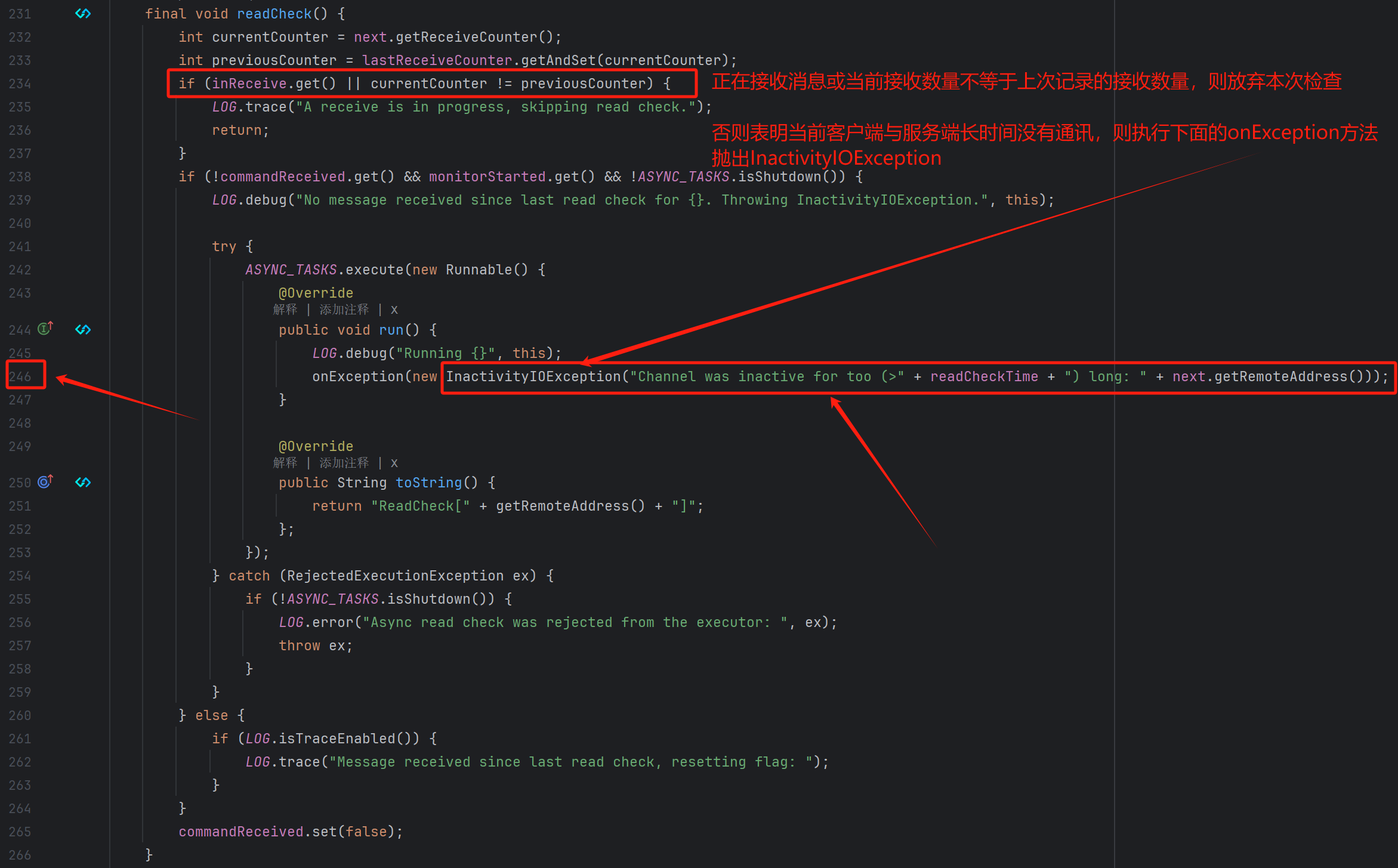
- 实现原理
- 获取接收计数器:获取当前和上一次的接收计数器值,并更新上一次的接收计数器值为当前的接收计数器值。
- 检查是否正在接收:如果当前正在接收消息或者接收计数器值发生了变化,则跳过读取检查。
- 检查是否需要抛出异常 :如果
commandReceived为false即没有接收到命令,且monitorStarted为true即监控已经开始,并且异步任务线程池(ASYNC_TASKS)没有关闭,则抛出InactivityIOException异常。异常处理通过异步任务执行,以避免阻塞当前线程。如果异步任务被拒绝执行,并且异步任务没有关闭,则记录错误并重新抛出异常。 - 重置标志 :最后,重置
commandReceived标志,表示没有接收到命令。
-
作用:定期检查连接状态,确保连接活跃。
-
工作机制:
- 定时任务:默认每隔
readCheckTime(默认30秒) 时间执行一次。 - 活跃性检查:每次执行时,检查自上次执行检查以来的时间间隔。如果超过
readCheckTime的90%且当前没有在接收消息和命令,则认为连接不活跃。 - 处理不活跃连接:关闭连接等相关资源(如定时器、线程池等)并触发
InactivityIOException。
- 定时任务:默认每隔
-
与服务端关闭的关系
- 如果服务端主动关闭连接,客户端与服务端之间的心跳检测中断,
readCheck中的inReceive.get() || currentCounter != previousCounter将为false,从而会触发InactivityIOException。 - 如果服务端未关闭,但客户端长时间无数据传输,
connectCheckerTask也会关闭连接。
- 如果服务端主动关闭连接,客户端与服务端之间的心跳检测中断,
总结
- 问题根源
- 服务端关闭导致连接中断,消费者失效,
receive()立即返回null,while仍循环调用,导致日志刷屏。
- 解决核心
- 休眠一秒:快速减少日志频率。
- 最终效果
- 日志频率显著降低,系统稳定性提升。
- 生产环境运行平稳,问题彻底解决。
经验分享
- 日志分析:遇到问题时,优先分析日志,定位异常类型和时间点。
- 连接管理:ActiveMQ 的连接和消费者状态需要仔细管理,避免资源泄漏。
- 快速解决:在紧急情况下,优先采用简单有效的方案(如休眠一秒),再逐步优化。
互动话题
你是否也遇到过类似的问题?欢迎在评论区分享你的经验和解决方案!如果本文对你有帮助,请点赞、转发支持!
关注公众号,获取更多技术干货!