python黑马程序员
python
"""
文件,按JSON字符串存储
1. 城市按销售额排名
2. 全部城市有哪些商品类别在售卖
3. 上海市有哪些商品类别在售卖
"""
from pyspark import SparkConf, SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = r"D:\anaconda\envs\py10\python.exe"
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 1. 城市按销售额排名
# 读取文件,获得rdd
file_rdd = sc.textFile("第15章资料\资料\orders.txt")
# 取出每个json字符串
json_str_rdd = file_rdd.flatMap(lambda x: x.split("|"))
# 将每个json字符串转换为字典
dict_rdd = json_str_rdd.map(lambda x: json.loads(x))
# 取出城市和销售额数据
# (城市,销售额)
city_with_money_rdd = dict_rdd.map(lambda x: (x['areaName'], int(x['money'])))
# 按城市分组,对销售额聚合
city_result_rdd = city_with_money_rdd.reduceByKey(lambda a, b: a+b)
# 销售额降序排列
result1 = city_result_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)
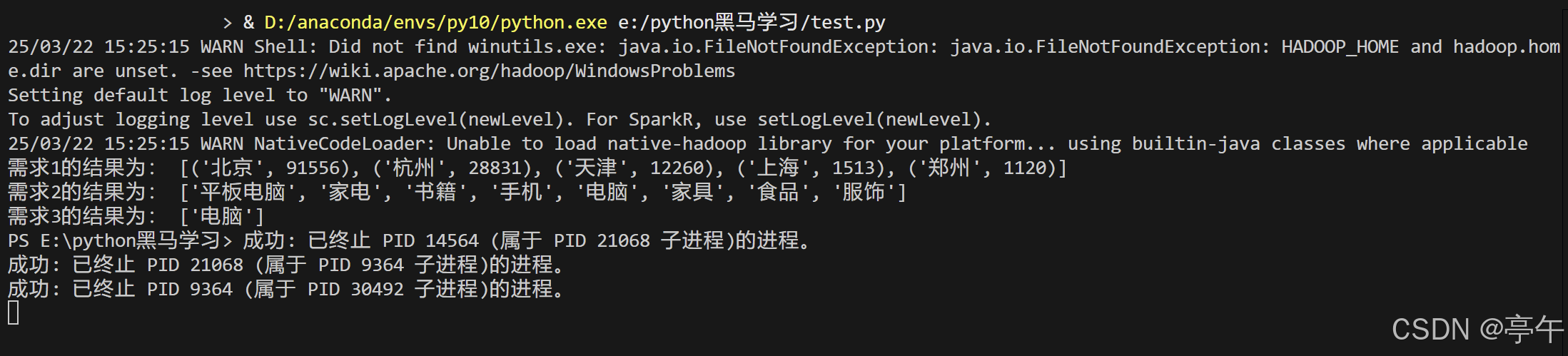
print("需求1的结果为:", result1.collect())
# 2. 全部城市有哪些商品类别在售卖
# 取出全部的商品类别
category_rdd = dict_rdd.map(lambda x: x['category']).distinct()
print("需求2的结果为:", category_rdd.collect())
# 3. 上海市有哪些商品类别在售卖
# 过滤出上海市的数据
beijing_data_rdd = dict_rdd.filter(lambda x: x['areaName'] == '上海')
result3 = beijing_data_rdd.map(lambda x:x['category']).distinct()
print("需求3的结果为:", result3.collect())
sc.stop()结果: