1.图像梯度
知识回顾:处理图像的常用方法。
1.灰度图
2.图像平滑(模糊)也称低通滤波
3.二值化
4.形态学(可选)
图像的核心视觉特征
几何特征:图像的尺寸,面积,弧长等。->几何特征提取
语义特征:高维空间中的像素值 ,目标的检测与分割->深度学习
特征类型 表征层次 信息抽象度 与人类认知的关联 几何特征 底层 / 中层视觉特征 低(具象、可量化) 对应人类的视觉感知(看到形状、大小) 语义特征 高层语义特征 高(抽象、概念化) 对应人类的语义理解(识别类别、含义) 问题产生:
我们应该获取图像中的几何特征?
答:边缘检测(高通滤波),检测原理是dx = t+1px - t-1px计算图像梯度,如果梯度值很大,说明变化量大,就会留下一个很明显的梯度像素值。
2.梯度滤波器
2.1 Sobel算子和Scharr算子
本质:梯度本质就是求导,opencv提供了三种不同的梯度滤波器Sobel,Scharr,Laplacian。
Sobel算子 = 高斯平滑+微分操作
sobel算子原理。 Gx = [[-1, 0, 1],
[-2, 0, 2]
[-1, 0, 1]]
Gx = [[-1, -2, 1],
[0, 0, 0]
[1, 2, 1]]
G = sqrt(Gx**2 + Gy **2)
#使用代码
gx_img = cv2.Sobel(img, -1, 1, 0) # 求x方向
gx_img_abs = cv2.convertScaleAbs(gx_img)
gy_img = cv2.Sobel(img, -1, 0, 1) # 求y方向
gy_img_abs = cv2.convertScaleAbs(gy_img)
concat_gx_gy = cv2.addWeighted(gx_img_abs, 0.5, gy_img_abs, 0.5, 0)Scharr算子 = Sobel算子+3x3卷积核
Scharr算子原理。
Gx = [[-3, 0, 3],
[-10, 0, 10]
[-3, 0, 3]]
Gx = [[-3, -10, -3],
[0, 0, 0]
[3, 10, 3]]
G = sqrt(Gx**2 + Gy **2)
#实例
gx_img = cv2.Scharr(img, -1, 1, 0) # 求x方向
gx_img_abs = cv2.convertScaleAbs(gx_img)
gy_img = cv2.Scharr(img, -1, 0, 1) # 求y方向
gy_img_abs = cv2.convertScaleAbs(gy_img)
concat_gx_gy = cv2.addWeighted(gx_img_abs, 0.5, gy_img_abs, 0.5, 0)简而言之,当Sobel算子的ksize=-1时就会使用3x3的Scharr算子滤波器,本质就是Scharr原理与Sobel相同,相对于Sobal梯度值变大了。
2.2 laplacian算子
本质:拉普拉斯算子本质是二阶导数的形式定义,可假设其离散实现类似于二阶Sobel导数,OpenCV在计算拉普拉斯算子时直接调用Sobel算子。

# Laplacian 梯度值中去噪能力算比较强的。
import cv2 import numpy as np import matplotlib.pyplot as plt def show_img(img, title="img"): cv2.imshow(title, img) cv2.waitKey(0) # 等待 1秒按任意键退出界面 # Scharr 原理与sobel相同。相对于sobel梯度值变大了。 # Laplacian 梯度值中去噪能力算比较强的。 def adjust_gamma(image, gamma=1.0): invgamma = 1.0 / gamma brighter_image = np.array(np.power((image / 255), invgamma) * 255, dtype=np.uint8) return brighter_image img = cv2.imread('./imgs/img.png', 0) img = adjust_gamma(img, gamma=1.5) l_img = cv2.Laplacian(img, -1) show_img(l_img,'Laplacian')


3.Canny边缘检测⭐
本质:高斯滤波 + Sobel算子(X,Y方向) + 对角线的梯度方向(❌方向)
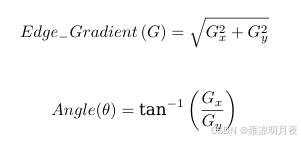
原理:
1.高斯滤波去除噪声。
2.Sobel算子计算图像梯度。
3.图像梯度的临域值进行非极大值抑制(保留梯度方向最大的变化量,去掉弱边缘)
4.滞后阈值(双阈值管理)
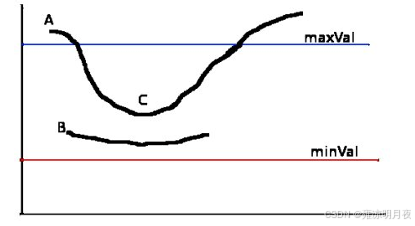
注:双阈值管理:当图像的灰度梯度高于 maxVal 时被认为是真的边界, 那些低于minVal 的边界会被抛弃。如果介于两者之间的话,就要看这个点是 否与某个被确定为真正的边界点相连,如果是就认为它也是边界点,如果不是 就抛弃
双域值管理(经验值)
>指定梯度值,就保留。(上图中A)
<指定梯度值,就丢弃。(上图小于minVal)
中间的,去判断是否是连接的边界点,是,就保留。(C保留,B除去)数据增强的方法:将边缘检测的梯度图与原图进行addWeighted,能够强化特征。对于边缘目标也能够提高检出率【经验】。import cv2
import numpy as np
import matplotlib.pyplot as plt
def show_img(img, title="img"):
cv2.imshow(title, img)
cv2.waitKey(0) # 等待 1秒按任意键退出界面
"""
1. canny算子第1步,高斯滤波,求sobel算子,增加对角线的梯度方向
2. 将梯度图中领域值进行非极大值抑制(保留梯度方向最大的变化量)
去掉弱边缘
3. 双域值管理(经验值)
>指定梯度值,就保留。
<指定梯度值,就丢弃。
中间的,去判断是否是连接的边界点,是,就保留。
4. 先尝试canny,后尝试sobel.
5. 数据增强的方法:将边缘检测的梯度图与原图进行addWeighted,能够强化特征。对于边缘目标也能够提高检出率【经验】。
"""
def adjust_gamma(image, gamma=1.0):
invgamma = 1.0 / gamma
brighter_image = np.array(np.power((image / 255), invgamma) * 255, dtype=np.uint8)
return brighter_image
img = cv2.imread('./imgs/pcb.png', 0)
#canny_img操作
img = adjust_gamma(img, gamma=1.5)
canny_img = cv2.Canny(img, 100, 200)
# show_img(canny_img, 'canny_img')
#canny concat old_img 图片
concat_img = cv2.addWeighted(img, 0.5, canny_img, 0.5, 0)
# show_img(concat_img, 'concat_img')
plt.subplot(121), plt.imshow(img, cmap='gray')
plt.title('canny_concat_Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(canny_img, cmap='gray')
plt.title('Canny Image'), plt.xticks([]), plt.yticks([])
plt.show()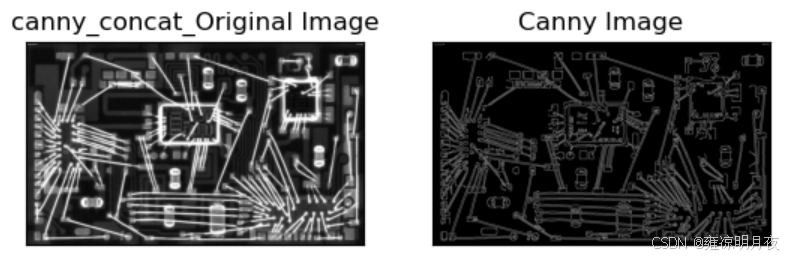
4.图像金字塔
本质:同一图像的不同分辨率的子图集合,我们把最大的图像放在底部,最小的放在顶部,看起来像一座金字 塔,故而得名图像金字塔。与resize功能类似。
实现方法:
cv2.pyrUp(img)
cv2.pyrDown(img)
cv2.pyrUp(img),cv2.pyrDown(img)在OpenCV的imgproc模块中的Image Filtering子模块里。而resize在imgproc 模块的Geometric(几何) Image Transformations子模块里。**高斯金字塔:**用来向下采样,主要的图像金字塔
原理:高斯金字塔的顶部是通过将底部图像中的连续的行和列去除得到的。顶部图像中的每个像素值等于下一层图像中5个像素的高斯加权平均值。
操作一次一个MxN的图像就变成了一个M/2xN/2 的图像。这幅图像的面积就是原图的1/4.称为Octave.
拉普拉斯金字塔: 用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。
本质:拉普拉斯金字塔是通过源图像减去先缩小后再放大的图像的一系列图像构成的。保留的是残差!为图像还原做准备!
"""
一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。
其通过梯次向下采样获得,直到达到某个终止条件才停止采样。
金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。
我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
"""
import cv2
import numpy as np
import cv2
import numpy as np
img = cv2.imread("./imgs/apple.png")
# 多尺度图像训练:+2% 增加泛化能力(适用场景更多)
# 利用图像金字塔,随机选择[0.25,0.5,1.5,2.0]变换,让神经网络学习目标的不同尺寸上的变化。
# 算法工程师:想尽办法,让神经网络更舒服地去学习。
num = 3
if num == 1:
up = cv2.pyrUp(img) # 向上金字塔,变大
print(f"原始尺寸: {img.shape}, 上采样后: {up.shape}")
elif num == 2:
up = cv2.pyrDown(img) # 向下金字塔,变小
print(f"原始尺寸: {img.shape}, 下采样后: {up.shape}")
elif num == 3:
# 正确的拉普拉斯金字塔计算方式
# 1. 先下采样再上采样
down = cv2.pyrDown(img)
up = cv2.pyrUp(down)
# 2. 调整尺寸以匹配原图
if up.shape != img.shape:
up = cv2.resize(up, (img.shape[1], img.shape[0]))
# 3. 计算拉普拉斯金字塔 . 残差
laplacian = cv2.convertScaleAbs(img - up)
up = laplacian
is_normalize = True
if is_normalize:
laplacian = img.astype(np.float32) - up.astype(np.float32)
# 4. 归一化到0-255范围以便显示
laplacian_display = cv2.normalize(laplacian, None, 0, 255, cv2.NORM_MINMAX)
laplacian_display = laplacian_display.astype(np.uint8)
up = laplacian_display
print(f"原始尺寸: {img.shape}")
print(f"下采样后: {down.shape}")
print(f"上采样后: {up.shape}")
print(f"拉普拉斯金字塔尺寸: {laplacian.shape}")
cv2.imshow('Result', up)
cv2.waitKey(0)
cv2.destroyAllWindows()

4.1图像融合
import cv2
import numpy as np
import sys
# 读取图像
A = cv2.imread('imgs/apple.png')
B = cv2.imread('imgs/orange.png')
# 检查图像是否成功读取
if A is None or B is None:
print("错误:无法读取图像文件")
sys.exit(1)
# 确保两个图像大小相同
if A.shape != B.shape:
# 调整图像大小使其相同
B = cv2.resize(B, (A.shape[1], A.shape[0]))
# 生成高斯金字塔 for A
G = A.copy()
gpA = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpA.append(G)
# 生成高斯金字塔 for B
G = B.copy()
gpB = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpB.append(G)
# 生成拉普拉斯金字塔 for A
lpA = [gpA[5]]
for i in range(5, 0, -1):
GE = cv2.pyrUp(gpA[i])
# 调整大小以匹配
if GE.shape != gpA[i-1].shape:
GE = cv2.resize(GE, (gpA[i-1].shape[1], gpA[i-1].shape[0]))
L = cv2.subtract(gpA[i-1], GE)
lpA.append(L)
# 生成拉普拉斯金字塔 for B
lpB = [gpB[5]]
for i in range(5, 0, -1):
GE = cv2.pyrUp(gpB[i])
# 调整大小以匹配
if GE.shape != gpB[i-1].shape:
GE = cv2.resize(GE, (gpB[i-1].shape[1], gpB[i-1].shape[0]))
L = cv2.subtract(gpB[i-1], GE)
lpB.append(L)
# 现在在每个级别上添加图像的左右半部分
LS = []
for la, lb in zip(lpA, lpB):
rows, cols, dpt = la.shape
# 使用整数除法
ls = np.hstack((la[:, 0:cols//2], lb[:, cols//2:]))
LS.append(ls)
# 现在重建
ls_ = LS[0]
for i in range(1, 6):
ls_ = cv2.pyrUp(ls_)
# 调整大小以匹配
if ls_.shape != LS[i].shape:
ls_ = cv2.resize(ls_, (LS[i].shape[1], LS[i].shape[0]))
ls_ = cv2.add(ls_, LS[i])
# 直接连接每个半部分的图像
real = np.hstack((A[:, :cols//2], B[:, cols//2:]))
# 保存结果
cv2.imwrite('Pyramid_blending2.jpg', ls_)
cv2.imwrite('Direct_blending.jpg', real)
print("图像融合完成!")
print(f"金字塔融合图像保存为: Pyramid_blending2.jpg")
print(f"直接融合图像保存为: Direct_blending.jpg")直接融合和金字塔融合:


详细融合代码:
import cv2
import numpy as np
import sys
import os
def create_output_dir():
"""创建输出目录"""
if not os.path.exists('output'):
os.makedirs('output')
def display_images(images, titles, window_name, save_path=None):
"""显示多张图像"""
# 计算网格布局
rows = int(np.ceil(np.sqrt(len(images))))
cols = int(np.ceil(len(images) / rows))
# 找到最大尺寸
max_height = max(img.shape[0] for img in images)
max_width = max(img.shape[1] for img in images)
# 创建画布
canvas = np.zeros((max_height * rows, max_width * cols, 3), dtype=np.uint8)
for idx, (img, title) in enumerate(zip(images, titles)):
row = idx // cols
col = idx % cols
# 调整图像大小
resized_img = cv2.resize(img, (max_width, max_height))
# 放置图像
y_start = row * max_height
y_end = y_start + max_height
x_start = col * max_width
x_end = x_start + max_width
canvas[y_start:y_end, x_start:x_end] = resized_img
# 添加标题
cv2.putText(canvas, title, (x_start + 10, y_start + 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2)
# 显示图像
cv2.imshow(window_name, canvas)
# 保存图像
if save_path:
cv2.imwrite(save_path, canvas)
return canvas
# 创建输出目录
create_output_dir()
# 读取图像
A = cv2.imread('imgs/apple.png')
B = cv2.imread('imgs/orange.png')
# 检查图像是否成功读取
if A is None or B is None:
print("错误:无法读取图像文件")
sys.exit(1)
print(f"图像A尺寸: {A.shape}")
print(f"图像B尺寸: {B.shape}")
# 确保两个图像大小相同
if A.shape != B.shape:
print("调整图像B大小以匹配图像A")
B = cv2.resize(B, (A.shape[1], A.shape[0]))
# 显示原始图像
original_images = [A, B]
original_titles = ['Apple', 'Orange']
display_images(original_images, original_titles, 'Original Images', 'output/01_original_images.jpg')
# 生成高斯金字塔 for A
print("生成高斯金字塔...")
G = A.copy()
gpA = [G]
gpA_images = [G]
gpA_titles = ['Level 0']
for i in range(6):
G = cv2.pyrDown(G)
gpA.append(G)
gpA_images.append(G)
gpA_titles.append(f'Level {i + 1}')
# 显示A的高斯金字塔
display_images(gpA_images, gpA_titles, 'Gaussian Pyramid A', 'output/02_gaussian_pyramid_A.jpg')
# 生成高斯金字塔 for B
G = B.copy()
gpB = [G]
gpB_images = [G]
gpB_titles = ['Level 0']
for i in range(6):
G = cv2.pyrDown(G)
gpB.append(G)
gpB_images.append(G)
gpB_titles.append(f'Level {i + 1}')
# 显示B的高斯金字塔
display_images(gpB_images, gpB_titles, 'Gaussian Pyramid B', 'output/03_gaussian_pyramid_B.jpg')
# 生成拉普拉斯金字塔 for A
print("生成拉普拉斯金字塔...")
lpA = [gpA[5]]
lpA_images = [gpA[5]]
lpA_titles = ['Level 5']
for i in range(5, 0, -1):
GE = cv2.pyrUp(gpA[i])
# 调整大小以匹配
if GE.shape != gpA[i - 1].shape:
GE = cv2.resize(GE, (gpA[i - 1].shape[1], gpA[i - 1].shape[0]))
L = cv2.subtract(gpA[i - 1], GE)
lpA.append(L)
lpA_images.append(L)
lpA_titles.append(f'Level {i - 1}')
# 显示A的拉普拉斯金字塔
display_images(lpA_images, lpA_titles, 'Laplacian Pyramid A', 'output/04_laplacian_pyramid_A.jpg')
# 生成拉普拉斯金字塔 for B
lpB = [gpB[5]]
lpB_images = [gpB[5]]
lpB_titles = ['Level 5']
for i in range(5, 0, -1):
GE = cv2.pyrUp(gpB[i])
# 调整大小以匹配
if GE.shape != gpB[i - 1].shape:
GE = cv2.resize(GE, (gpB[i - 1].shape[1], gpB[i - 1].shape[0]))
L = cv2.subtract(gpB[i - 1], GE)
lpB.append(L)
lpB_images.append(L)
lpB_titles.append(f'Level {i - 1}')
# 显示B的拉普拉斯金字塔
display_images(lpB_images, lpB_titles, 'Laplacian Pyramid B', 'output/05_laplacian_pyramid_B.jpg')
# 现在在每个级别上添加图像的左右半部分
print("融合金字塔层级...")
LS = []
LS_images = []
LS_titles = []
for idx, (la, lb) in enumerate(zip(lpA, lpB)):
rows, cols, dpt = la.shape
# 使用整数除法
ls = np.hstack((la[:, 0:cols // 2], lb[:, cols // 2:]))
LS.append(ls)
LS_images.append(ls)
LS_titles.append(f'Level {5 - idx}')
# 显示融合的金字塔层级
display_images(LS_images, LS_titles, 'Blended Pyramid Levels', 'output/06_blended_pyramid_levels.jpg')
# 现在重建
print("重建融合图像...")
ls_ = LS[0]
reconstruction_images = [ls_]
reconstruction_titles = ['Start Level 5']
for i in range(1, 6):
ls_ = cv2.pyrUp(ls_)
# 调整大小以匹配
if ls_.shape != LS[i].shape:
ls_ = cv2.resize(ls_, (LS[i].shape[1], LS[i].shape[0]))
ls_ = cv2.add(ls_, LS[i])
reconstruction_images.append(ls_)
reconstruction_titles.append(f'After Level {5 - i}')
# 显示重建过程
display_images(reconstruction_images, reconstruction_titles, 'Reconstruction Process',
'output/07_reconstruction_process.jpg')
# 直接连接每个半部分的图像
real = np.hstack((A[:, :cols // 2], B[:, cols // 2:]))
# 保存结果
cv2.imwrite('output/08_pyramid_blending_final.jpg', ls_)
cv2.imwrite('output/09_direct_blending.jpg', real)
# 显示最终结果对比
final_images = [real, ls_]
final_titles = ['Direct Blending', 'Pyramid Blending']
final_comparison = display_images(final_images, final_titles, 'Final Results Comparison',
'output/10_final_comparison.jpg')
print("\n图像融合完成!")
print("所有中间过程和结果已保存到 output/ 目录:")
print("01_original_images.jpg - 原始图像")
print("02_gaussian_pyramid_A.jpg - A的高斯金字塔")
print("03_gaussian_pyramid_B.jpg - B的高斯金字塔")
print("04_laplacian_pyramid_A.jpg - A的拉普拉斯金字塔")
print("05_laplacian_pyramid_B.jpg - B的拉普拉斯金字塔")
print("06_blended_pyramid_levels.jpg - 融合的金字塔层级")
print("07_reconstruction_process.jpg - 重建过程")
print("08_pyramid_blending_final.jpg - 金字塔融合最终结果")
print("09_direct_blending.jpg - 直接融合结果")
print("10_final_comparison.jpg - 最终结果对比")
print(f"\n金字塔融合图像保存为: output/08_pyramid_blending_final.jpg")
print(f"直接融合图像保存为: output/09_direct_blending.jpg")
# 等待按键然后关闭所有窗口
print("\n按任意键关闭所有显示窗口...")
cv2.waitKey(0)
cv2.destroyAllWindows()5.直方图均衡化
本质:一张图片的显示视觉效果是否好,两个关注点:1.对比度是否明显。2.亮度是否欠曝/过曝。
我们的理想图片:
1.对比度高
2.且50<亮度<230
直方图均衡化: 从原来的分布,变得更倾向于满足标准正态分布。 对比度会更强烈,黑的更黑,亮的会更亮。有可能曝光过度。 数据增强策略:把原图像进行直方图均衡化(区域直方图均衡化)。+2-3%
# 创建CLAHE对象 clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)) # 应用CLAHE equ = clahe.apply(img)
简单使用案例:
import cv2 import matplotlib.pyplot as plt # 读取灰度图像 img = cv2.imread('./imgs/demo1.png', 0) # 0表示以灰度模式读取 # 创建CLAHE对象 clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)) # 应用CLAHE equ = clahe.apply(img) # 对比显示原图和增强后的图 plt.subplot(121), plt.imshow(img, cmap='gray'), plt.title('Original') plt.subplot(122), plt.imshow(equ, cmap='gray'), plt.title('CLAHE Enhanced') plt.show()
应用实例:
import cv2
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
# 在服务端调试不显示
matplotlib.use('Agg')
# 计算灰度图的直方图
def calchist_for_gray(imgname):
img = cv2.imread(imgname, cv2.IMREAD_GRAYSCALE)
# [ 放多个图] 一次只能计算1个通道 指定某个区域 x坐标的数值数量 像素值的范围
hist = cv2.calcHist([img], [0], None, [256], [0, 255])
plt.plot(hist, color="r")
plt.savefig("result_gray.jpg")
# plt.show()
# 计算彩色图的直方图
def calchist_for_rgb(imgname):
img = cv2.imread(imgname)
histb = cv2.calcHist([img], [0], None, [256], [0, 255])
histg = cv2.calcHist([img], [1], None, [256], [0, 255])
histr = cv2.calcHist([img], [2], None, [256], [0, 255])
plt.plot(histb, color="b")
plt.plot(histg, color="g")
plt.plot(histr, color="r")
plt.savefig("result_rgba.jpg")
# 计算掩码的直方图
def calchist_for_mask(imgname):
img = cv2.imread(imgname, cv2.IMREAD_GRAYSCALE)
mask = np.zeros(img.shape, np.uint8)
mask[200:400, 200:400] = 255 # 如果是0,就代表不取这个区域。255就代表取这个区域。
histMI = cv2.calcHist([img], [0], mask, [256], [0, 255])
histImage = cv2.calcHist([img], [0], None, [256], [0, 255])
plt.plot(histMI, color="r")
plt.savefig("result_mask.jpg")
# plt.show()
def get_mask(imgname):
image = cv2.imread(imgname, 0)
mask = np.zeros(image.shape, np.uint8)
mask[200:400, 200:400] = 255
mi = cv2.bitwise_and(image, mask)
cv2.imwrite("mi.jpg", mi)
"""
直方图均衡化:
从原来的分布,变得更倾向于满足标准正态分布。
对比度会更强烈,黑的更黑,亮的会更亮。有可能曝光过度。
数据增强策略:把原图像进行直方图均衡化(区域直方图均衡化)。+2-3%
"""
def get_equalizehist_img(imgname):
img = cv2.imread(imgname, cv2.IMREAD_GRAYSCALE)
# equ = cv2.equalizeHist(img) # 直方图均衡化
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
equ = clahe.apply(img)
plt.subplot(221)
plt.imshow(img, plt.cm.gray)
plt.axis('off')
plt.subplot(222)
plt.hist(img.ravel(), 256)
plt.subplot(223)
plt.imshow(equ, plt.cm.gray)
plt.axis('off')
plt.subplot(224)
plt.hist(equ.ravel(), 256)
plt.savefig("result2.jpg")
if __name__ == "__main__":
test_img = "imgs/orange.png"
calchist_for_rgb(test_img)
calchist_for_gray(test_img)
calchist_for_mask(test_img)
get_mask(test_img)
get_equalizehist_img(test_img)