目录
强化学习是一种基于反馈的学习方法,类似于人类通过试错来学习。
从学习信号的角度看,强化学习介于监督学习和无监督学习之间。
与监督学习不同,它没有直接的学习信号(如人类标注的类别),而是通过与环境的交互,根据获得的奖励或惩罚来调整行为,以达到预定目标。
一、基本原理
一个有趣的例子是训练小狗分辨水果。
你希望小狗听到指令后能拿回正确的水果,但小狗无法直接理解你的语言。
为此,可以采用奖励机制来引导它:
当小狗拿对水果时,给予奖励(例如一块骨头);拿错则不给予奖励。经过多次尝试后,小狗就能学会根据指令拿到正确的水果。
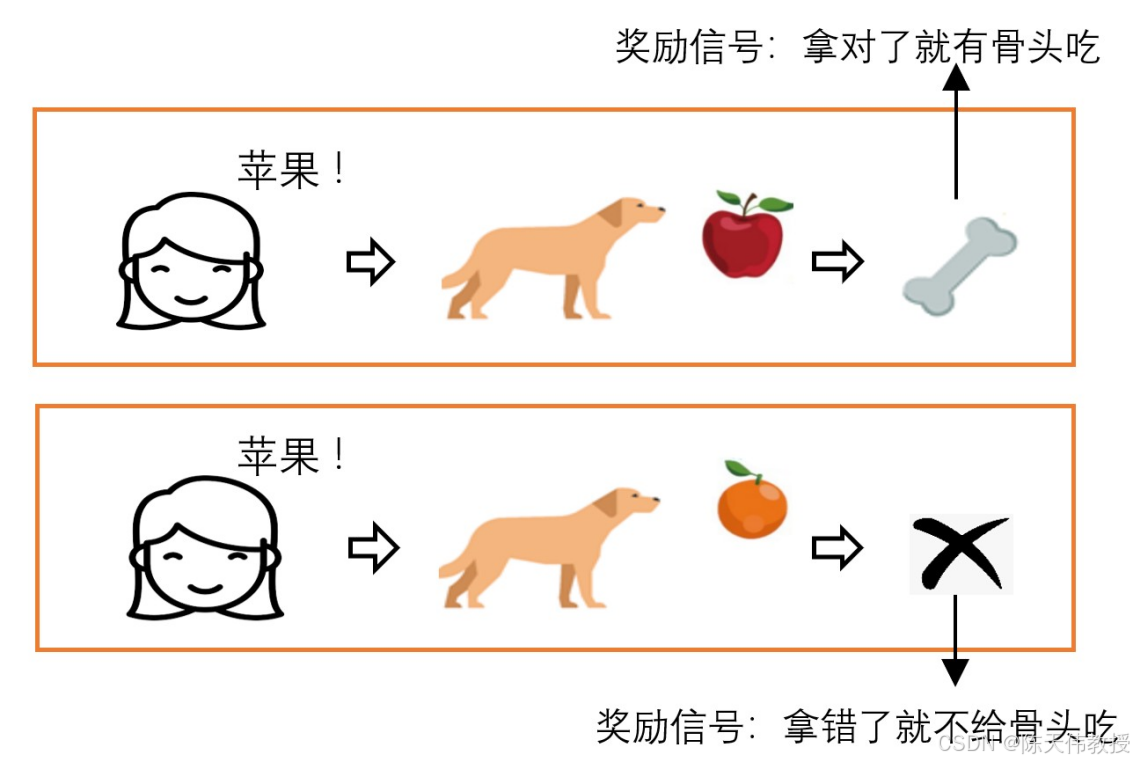
用强化学习训练小狗分辨水果
二、应用场景
强化学习特别适用于那些需要多步决策的任务,
例如机器人行走、投资策略优化以及对弈游戏等。
在这些任务中,每一步决策都会影响最终结果。想象你在下围棋时,每下一子都会收到对手的反馈,这些反馈可能使你处于更有利的位置,也可能使你处于劣势。你会根据反馈不断调整策略,以求获得最终胜利。而高明的棋手不会只关注一个子、一块地的得失,而是着眼于全局胜负。
**强化学习正是如此:通过不断接受环境反馈调整策略,目标是实现总体收益最大化。**这也是 AlphaGo 能够利用深度强化学习战胜人类顶尖棋手的重要原因。